
Приветствую всех. В этой статье мы сделаем жизнь чуточку легче, написав легкий парсер сайта на python, разберемся с возникшими проблемами и узнаем все муки пайтона что-то новое.
Статья ориентирована на новичков, таких же как и я.
Для начала разберем задачу. Взял я малоизвестный сайт новостей об Израиле, так как сам проживаю в этой стране, и хочется читать новости без рекламы и не интересных новостей. И так, имеется сайт, на котором постятся новости: есть новости помеченные красным, а есть обычные. Те что обычные — не представляют собой ничего интересного, а отмеченные красным являются самым соком. Рассмотрим наш сайт.
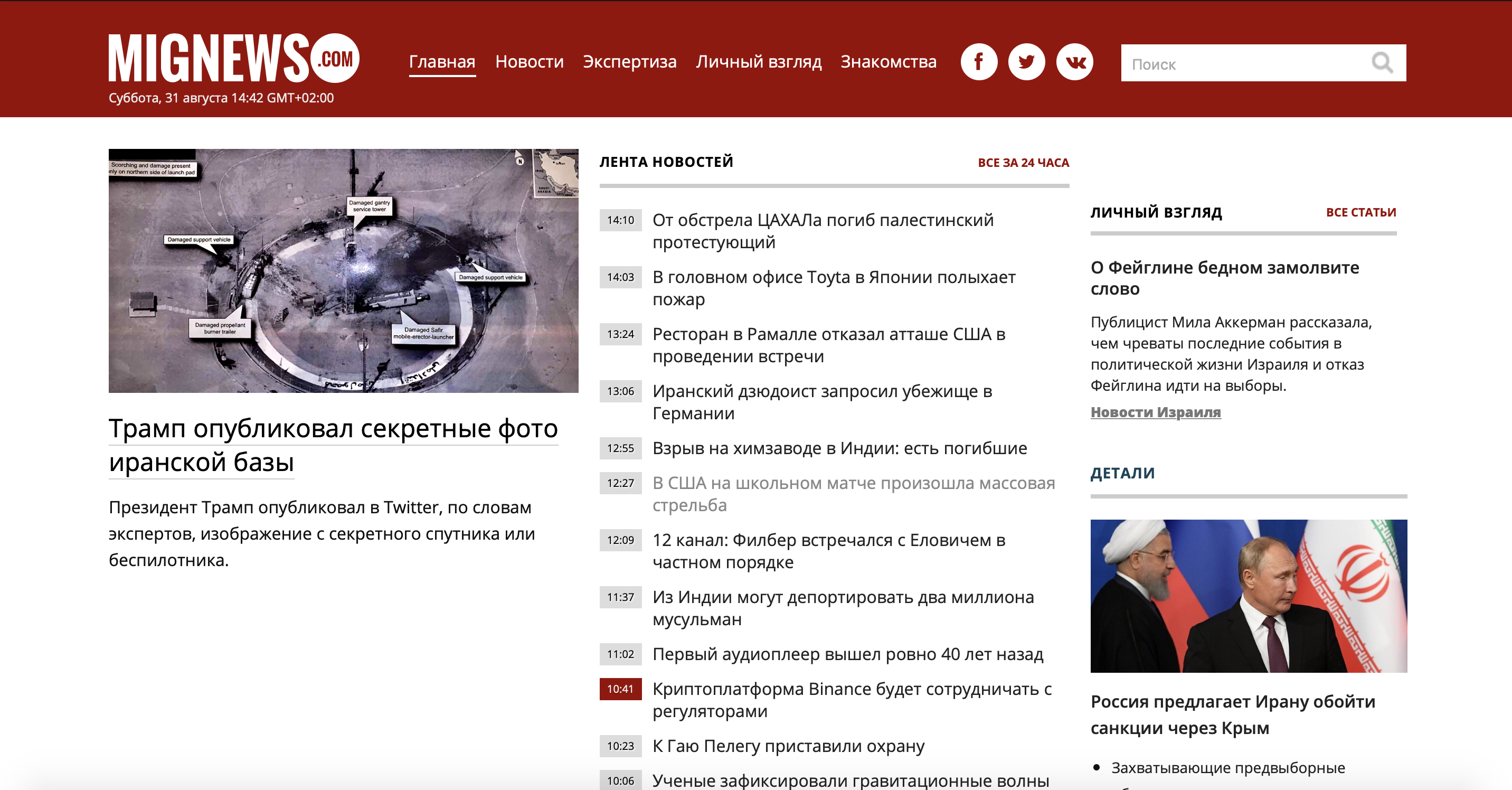
Как видно сайт достаточно большой и есть много ненужной информации, а ведь нам нужно использовать лишь контейнер новостей. Давайте использовать мобильную версию сайта,
чтобы сэкономить себе же время и силы.

Как видите, сервер отдал нам красивый контейнер новостей (которых, кстати, больше чем на основном сайте, что нам на руку) без рекламы и мусора.
Давайте рассмотрим исходный код, чтобы понять с чем мы имеем дело.

Как видим каждая новость лежит по-отдельности в тэге 'a' и имеет класс 'lenta'. Если мы откроем тэг 'a', то заметим, что внутри есть тэг 'span', в котором находится класс 'time2', либо 'time2 time3', а также время публикации и после закрытия тэга мы наблюдаем сам текст новости.
Что отличает важную новость от неважной? Тот самый класс 'time2' или 'time2 time3'. Новости помеченые 'time2 time3' и являются нашими красными новостями. Раз уж суть задачи понятна, перейдем к практике.
Для работы с парсерами умные люди придумали библиотеку «BeautifulSoup4», в которой есть еще очень много крутых и полезных функций, но об этом в следующий раз. Нам также понадобиться библиотека Requests позволяющая отправлять различные http-запросы. Идем их скачивать.
(убедитесь, что стоит последняя версия pip)
Переходим в редактор кода и импортируем наши библиотеки:
Для начала сохраним наш URL в переменную:
Теперь отправим GET()-запрос на сайт и сохраним полученное в переменную 'page':
Проверим подключение:
Код вернул нам статус код '200', значит это, что мы успешно подключены и все в полном порядке.
Теперь создадим два списка (позже я объясню для чего они нужны):
Самое время воспользоваться BeautifulSoup4 и скормить ему наш page, указав в кавычках как он нам поможет 'html.parcer':
Если попросить его показать, что он там сохранил:
Нам вылезет весь html-код нашей страницы.
Теперь воспользуемся функцией поиска в BeautifulSoup4:
Давайте разберём поподробнее, что мы тут написали.
В ранее созданный список 'news' (к которому я обещал вернуться), сохраняем все с тэгом 'а' и классом 'news'. Если попросим вывести в консоль все, что он нашел, он покажет нам все новости, что были на странице:

Как видите, вместе с текстом новостей вывелись теги 'a', 'span', классы 'lenta' и 'time2', а также 'time2 time3', в общем все, что он нашел по нашим пожеланиям.
Продолжим:
Тут мы в цикле for перебираем весь наш список новостей. Если в новости мы находим тэг 'span' и класc 'time2 time3', то сохраняем текст из этой новости в новый список 'filteredNews'.
Обратите внимание, что мы используем '.text', чтобы переформатировать строки в нашем списке из 'bs4.element.ResultSet', который использует BeautifulSoup для своих поисков, в обычный текст.
Однажды я застрял на этой проблеме надолго в силу недопонимания работы форматов данных и неумения использовать debug, будьте осторожны. Таким образом теперь мы можем сохранять эти данные в новый список и использовать все методы списков, ведь теперь это обычный текст и, в общем, делать с ним, что нам захочется.
Выведем наши данные:
Вот что мы получаем:

Мы получаем время публикации и лишь интересные новости.
Дальше можно построить бот в Телеге и выгружать туда эти новости, либо создать виджет на рабочий стол с актуальными новостями. В общем, можно придумать удобный для себя способ узнавать о новостях.
Надеюсь эта статья поможет новичкам понять, что можно делать с помощью парсеров и поможет им немного продвинуться вперед с обучением.
Спасибо за внимание, был рад поделиться опытом.
Статья ориентирована на новичков, таких же как и я.
Начало
Для начала разберем задачу. Взял я малоизвестный сайт новостей об Израиле, так как сам проживаю в этой стране, и хочется читать новости без рекламы и не интересных новостей. И так, имеется сайт, на котором постятся новости: есть новости помеченные красным, а есть обычные. Те что обычные — не представляют собой ничего интересного, а отмеченные красным являются самым соком. Рассмотрим наш сайт.
Как видно сайт достаточно большой и есть много ненужной информации, а ведь нам нужно использовать лишь контейнер новостей. Давайте использовать мобильную версию сайта,
чтобы сэкономить себе же время и силы.
Как видите, сервер отдал нам красивый контейнер новостей (которых, кстати, больше чем на основном сайте, что нам на руку) без рекламы и мусора.
Давайте рассмотрим исходный код, чтобы понять с чем мы имеем дело.
Как видим каждая новость лежит по-отдельности в тэге 'a' и имеет класс 'lenta'. Если мы откроем тэг 'a', то заметим, что внутри есть тэг 'span', в котором находится класс 'time2', либо 'time2 time3', а также время публикации и после закрытия тэга мы наблюдаем сам текст новости.
Что отличает важную новость от неважной? Тот самый класс 'time2' или 'time2 time3'. Новости помеченые 'time2 time3' и являются нашими красными новостями. Раз уж суть задачи понятна, перейдем к практике.
Практика
Для работы с парсерами умные люди придумали библиотеку «BeautifulSoup4», в которой есть еще очень много крутых и полезных функций, но об этом в следующий раз. Нам также понадобиться библиотека Requests позволяющая отправлять различные http-запросы. Идем их скачивать.
(убедитесь, что стоит последняя версия pip)
pip install beautifulsoup4 pip install requestsПереходим в редактор кода и импортируем наши библиотеки:
from bs4 import BeautifulSoup
import requestsДля начала сохраним наш URL в переменную:
url = 'http://mignews.com/mobile'Теперь отправим GET()-запрос на сайт и сохраним полученное в переменную 'page':
page = requests.get(url)Проверим подключение:
print(page.status_code)Код вернул нам статус код '200', значит это, что мы успешно подключены и все в полном порядке.
Теперь создадим два списка (позже я объясню для чего они нужны):
filteredNews = []
allNews = []
Самое время воспользоваться BeautifulSoup4 и скормить ему наш page, указав в кавычках как он нам поможет 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")Если попросить его показать, что он там сохранил:
print(soup)Нам вылезет весь html-код нашей страницы.
Теперь воспользуемся функцией поиска в BeautifulSoup4:
allNews = soup.findAll('a', class_='lenta')Давайте разберём поподробнее, что мы тут написали.
В ранее созданный список 'news' (к которому я обещал вернуться), сохраняем все с тэгом 'а' и классом 'news'. Если попросим вывести в консоль все, что он нашел, он покажет нам все новости, что были на странице:
Как видите, вместе с текстом новостей вывелись теги 'a', 'span', классы 'lenta' и 'time2', а также 'time2 time3', в общем все, что он нашел по нашим пожеланиям.
Продолжим:
for data in allNews:
if data.find('span', class_='time2 time3') is not None:
filteredNews.append(data.text)Тут мы в цикле for перебираем весь наш список новостей. Если в новости мы находим тэг 'span' и класc 'time2 time3', то сохраняем текст из этой новости в новый список 'filteredNews'.
Обратите внимание, что мы используем '.text', чтобы переформатировать строки в нашем списке из 'bs4.element.ResultSet', который использует BeautifulSoup для своих поисков, в обычный текст.
Однажды я застрял на этой проблеме надолго в силу недопонимания работы форматов данных и неумения использовать debug, будьте осторожны. Таким образом теперь мы можем сохранять эти данные в новый список и использовать все методы списков, ведь теперь это обычный текст и, в общем, делать с ним, что нам захочется.
Выведем наши данные:
for data in filteredNews:
print(data)
Вот что мы получаем:
Мы получаем время публикации и лишь интересные новости.
Дальше можно построить бот в Телеге и выгружать туда эти новости, либо создать виджет на рабочий стол с актуальными новостями. В общем, можно придумать удобный для себя способ узнавать о новостях.
Надеюсь эта статья поможет новичкам понять, что можно делать с помощью парсеров и поможет им немного продвинуться вперед с обучением.
Спасибо за внимание, был рад поделиться опытом.

yakimka8
Это можно было сделать гораздо проще с помощью RSS — практически любой новостной сайт отдает свою ленту в RSS.
Вот так
никто не пишет, в пайтоне это делают так:
А если кроме самого элемента нужно иметь и доступ к индексу, то пользуются enumerate:
tobbymarshall815 Автор
Спасибо, возьму на заметку.
Rss у них, к сожалению, отдает не фильтрованные новости, по этому не мог им пользоваться.
yakimka8
Всмысле нефильтрованные? В RSS те же новости что и в блоке «Лента новостей».
RSS разбирать гораздо проще и надежнее чем парсить html
tobbymarshall815 Автор
Да, проблема лишь в том что отличить важные новости, от не важных невозможно.
Использовал парсинг html, ибо там можно отличить такие новости — по красному бекграунду времени поста и легко найти по специфическому классу элемента.