
Привет, Хабр. Для будущих студентов курса "Highload Architect" подготовили перевод материала.
Также приглашаем на открытый вебинар по теме «Репликация как паттерн горизонтального масштабирования хранилищ». На занятии участники вместе с экспертом разберут репликацию — одну из техник масштабирования баз данных, обсудят смысл и ее назначение, рассмотрят преимущества и недостатки различных видов репликации.

Микросервисы на Java замечательны тем, что с помощью них можно создавать большие и сложные системы из множества независимых компонент. Вместо одного приложения получается несколько мини-приложений или сервисов. Компоненты могут тестироваться, развертываться и обслуживаться независимо друг от друга. Так что, если убрать один кирпич, то здание не разрушится полностью.
Тем не менее очевидное преимущество микросервисов может стать и причиной возникновения проблем. Если раньше вы уже работали с микросервисами на Java, то знаете, что для получения высокой производительности без потери функциональности могут потребоваться усилия. Но если вы справитесь с этим, то получите потрясающие результаты.
Spring Boot — это быстрый способ создания микросервисов на Java. В этой статье мы рассмотрим, как улучшить производительность Spring Boot-микросервиса.
Что будем использовать
Мы будем использовать два микросервиса:
External-service (внешний сервис): "реальный" микросервис, доступный по HTTP.
Facade-service (фасад): микросервис, который будет читать данные из external-service и отправлять результат клиентам. Будем оптимизировать этот сервис.
Что нам нужно
Java 8
Jmeter 5.3
Java IDE
Gradle 6.6.1
Исходный код
Прежде всего, скачайте исходный код, который мы будем улучшать, отсюда.
External service
Сервис был создан с помощью Spring Initializer. В нем один контроллер, имитирующий нагрузку:
@RestController
public class ExternalController {
@GetMapping(“/external-data/{time}”)
public ExternalData getData(@PathVariable Long time){
try {
Thread.sleep(time);
} catch (InterruptedException e) {
// do nothing
}
return new ExternalData(time);
}
}Запустите ExternalServiceApplication. Сервис должен быть доступен по адресу https://localhost:8543/external-data/300 .
Facade service
Этот сервис также был создан с помощью Spring Initializer. В нем два основных класса: ExternalService и ExternalServiceClient.
Класс ExternalService читает данные из сервиса External Service с помощью externalServiceClient и вычисляет сумму.
@Service
public class ExternalService {
@Autowired
private ExternalServiceClient externalServiceClient;
public ResultData load(List<Long> times) {
Long start = System.currentTimeMillis();
LongSummaryStatistics statistics = times
.parallelStream()
.map(time -> externalServiceClient.load(time).getTime())
.collect(Collectors.summarizingLong(Long::longValue));
Long end = System.currentTimeMillis();
return new ResultData(statistics, (end — start));
}
}Для чтения данных из external service класс ExternalServiceClient использует библиотеку openfeign. Реализация HTTP-клиента на основе OKHttp выглядит следующим образом:
@FeignClient(
name = “external-service”,
url = “${external-service.url}”,
configuration = ServiceConfiguration.class)
public interface ExternalServiceClient {
@RequestMapping(
method = RequestMethod.GET,
value = “/external- data/{time}”,
consumes = “application/json”)
Data load(@PathVariable(“time”) Long time);
}Запустите класс FacadeServiceApplication и перейдите на http://localhost:8080/data/1,500,920,20000.
Ответ будет следующим:
{
“statistics”: {
“count”: 4,
“sum”: 1621,
“min”: 1,
“max”: 920,
“average”: 405.25
},
“spentTime”: 1183
}Подготовка к тестированию производительности
Запустите Jmeter 5.3.1 и откройте файл perfomance-testing.jmx в корне проекта.
Конфигурация теста:
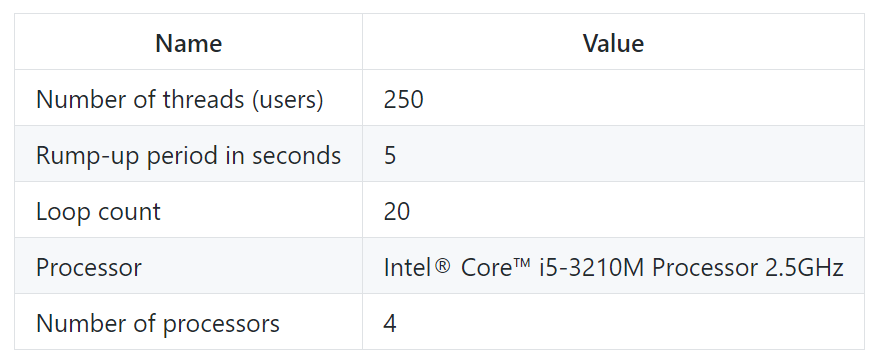
Нагрузочный тест будем проводить по следующему URL-адресу: http://localhost:8080/data/1,500,920,200
Перейдите в Jmeter и запустите тест.
Первый запуск Jmeter
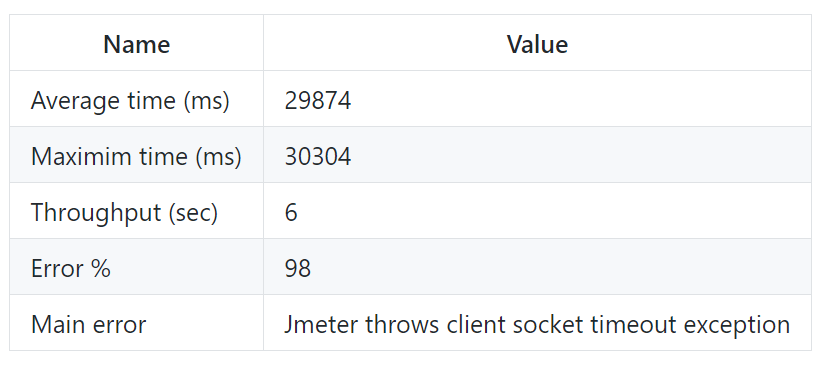
Сервер стал недоступен. Это связано с тем, что в ExternalService мы использовали parallelStream(). Stream API для параллельной обработки данных использует ForkJoinPool. А по умолчанию параллелизм ForkJoinPool рассчитывается на основе количества доступных процессоров. В моем случае их три. Для операций ввода-вывода это узкое место. Итак, давайте увеличим параллелизм ForkJoinPool до 1000.
-Djava.util.concurrent.ForkJoinPool.common.parallelism=1000И запустим Jmeter еще раз.
Второй запуск Jmeter

Как вы видите, пропускная способность (throughput) увеличилась с 6 до 26 запросов в секунду. Это хороший результат. Кроме того, сервис работает стабильно без ошибок. Но тем не менее среднее время (average time) составляет 9 секунд. У меня есть предположение, что это связано с затратами на создание HTTP-соединение. Давайте добавим пул соединений:
@Configuration
public class ServiceConfiguration {
…
@Bean
public OkHttpClient client()
throws IOException, CertificateException, NoSuchAlgorithmException, KeyStoreException, KeyManagementException, NoSuchProviderException {
…
okhttp3.OkHttpClient client = new okhttp3.OkHttpClient.Builder()
.sslSocketFactory(sslContext.getSocketFactory(), trustManager)
.hostnameVerifier((s, sslSession) -> true)
.connectionPool(new ConnectionPool(2000, 10, TimeUnit.SECONDS))
.build();
OkHttpClient okHttpClient = new OkHttpClient(client);
return okHttpClient;
}Таким образом, приложение может поддерживать до 2000 HTTP-соединений в пуле в течение 10 секунд.
Третий запуск Jmeter
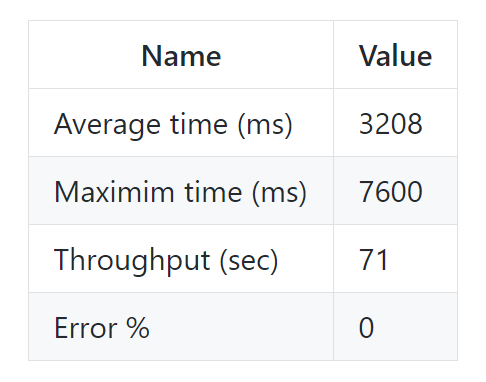
Пропускная способность улучшилась почти в три раза: с 26 до 71 запросов в секунду.
В целом пропускная способность улучшилась в 10 раз: с 6 до 71 запросов / сек, но мы видим, что максимальное время запроса (maximum time) составляет 7 секунд. Это много и влияет как на общую производительность, так и на задержку в UI.
Поэтому давайте ограничим количество обрабатываемых запросов. Сделать это можно, используя указанные ниже свойства Tomcat в application.properties:
server.tomcat.accept-count=80
server.tomcat.max-connections=80
server.tomcat.max-threads=160Приложение будет отклонять запросы на подключение и отвечать ошибкой "Connection refused" (отказ соединения) всем клиентам, как только количество подключений достигнет 160.
Четвертый запуск Jmeter

Теперь максимальное время составляет меньше пяти секунд и число запросов увеличилось с 71 до 94 запросов в секунду. Процент ошибок ожидаемо увеличился до 29%. Это все ошибки "Connection refused".
Заключение
В этой статье мы продемонстрировали реальный сценарий повышения производительности в 15 раз с 6 до 94 запросов / сек без каких-либо сложных изменений кода. Кроме того, упомянутые выше шаги позволяют снизить стоимость инфраструктуры, такой как AWS. Возможно, для вашего следующего проекта вам стоит подумать об использовании микросервисов. Хотя одна из тенденций последних лет — переход к бессерверной архитектуре, но вы должны всё взвесить при переходе к такой архитектуре.
Мы рассмотрели общий подход к улучшению производительности Java-приложений, который вы можете использовать на практике. Однако в статье не рассматриваются некоторые специфичные случаи, такие как работа с базами данных. В мире Java-микросервисов есть еще много места для открытий и экспериментов.
Узнать подробнее о курсе "Highload Architect".
Смотреть открытый вебинар по теме «Репликация как паттерн горизонтального масштабирования хранилищ».
mmMike
Лучший способ увеличить быстродействие микросервисов — отказаться от SpringBoot
«Магия» SpringBot которая позволяет писать «быстро» и «меньше» кода, она не просто так…
Все эти обходы классов при старте и обработка аннотаций она дает приличную задержку.
Как то, просто из за спора, нарисовал альтернативу серверной части на jersey конкретного модуля (довольного простого… с 10к API функций и работа с БД через простые select и вызовы PL/SQL процедур).
Так вот без SpringBoot стартует до момента «готов принимать HTTP» на 500 ms дольше.
Объем кода — практически тот же.
Чет все помешались на этом SpringBoot…
G1yyK
так тут фишка не в том что бы уменьшить время для «готов принимать HTTP», а время на обработку запросов. И статья, как сделать пару тривиальных действий и можно улучшить перфоманс.
Как по мне не очень критично сколько грузится сервис — 4 сек или 10. Зато профита больше(как минимум поддерживать проще проект будет)
mmMike
Не скажите… время на поднятие инстанса иногда то же очень важно.
Но а то что в статье описано — это вообще прямого отношения к SpringBoot не имеет.
Размер пула соединений у HTTP клиента и игры с количеством нитей на входящие соединения и количетвом открытых сокетов у HTTP сервера (tomcat ли, jetty, grizzly) в режиме не NIO — это вообще азы.
Тем более такие несуразные игры.
Ага… щаз… Connection refused после 80
Нахрена, если сервис — «труба» и всего 80 входящих одновременно.
Автор либо не понимает зачем он крутит эти параметры либо просто тяп ляп статья.
Показывать, что повышаешь производительность сервера тем что усовершенствуешь функцию (сбора статистики производительности — это вообще лютый бред.
parallelStream со сбором результата обращений в динамике. Мда… Ну то же «решение» с подкручиванием через java.util.concurrent.ForkJoinPool.common.parallelism
Причем тут вообще SpringBoot я не понял, но возмутился именно тому, что все описанное вообще прямого отношения к framework (SpringBoot) не имеет.
G1yyK
Да, Вы все правильно говорите — нужно комплексно подходить и подкручивать только там где необходимо и понимать зачем крутишь.
Важности не отрицаю, но разница в 10 секунд не критичная. Приложение редко перезапускаем, а если и перезапускаем всегда есть еще как минимум одно плечо, которое возьмет на себя нагрузку.
За автора отвечать не буду, но выглядит так, что автор хотел показать что вообще можно сделать и Spring тут как каркас, который сейчас очень(ну прям очень) много где используется. Да это и не плохо.
Думаю, статья имеет право на жизнь. Да она будет не очень полезна продвинутым разработчикам, но ребятам у кого не было опыта — покажет какие инструменты есть и надеюсь они пойдут читать как это все работает, что бы осознанно тюнить свое приложение