
Использование сложения вместо умножения для свертки результирует в меньшей задержке, чем у стандартной CNN


Вашему вниманию представлен обзор статьи AdderNet: действительно ли нам нужно умножение в глубоком обучении?, (AdderNet), Пекинского университета, Huawei Noah's Ark Lab и Сиднейского университета.
Действительно ли нам нужно умножение в глубоком обучении?
Структура статьи
Свертка AdderNet
Прочие моменты: BN, производные, скорость обучения
Результаты экспериментов
1. Свертка AdderNet
1.1. Обобщенные фильтры
Как правило, выходной признак Y указывает на сходство между фильтром и входным элементом:
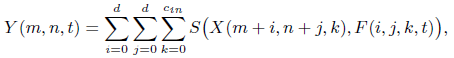
где S - мера сходства.
1.2. Стандартная свертка с использованием умножения

Если в качестве меры стандартного отклонения принимается взаимная корреляция, то используется умножение. Так мы получаем свертку.
1.3. Свертка AdderNet с использованием сложения

Если используется сложение, то вычисляется l1-мера стандартного отклонения между фильтром и входным признаком:

с помощью l1-меры стандартного отклонения можно эффективно вычислить сходство между фильтрами и признаками.
Сложение требует гораздо меньших вычислительных ресурсов, чем умножение.
Вы могли заметить, что приведенное выше уравнение относится к сопоставлению шаблонов в компьютерном зрении, цель которого - найти части изображения, соответствующие определенному шаблону.
2. Прочие моменты: BN, производные, скорость обучения
2.1. Пакетная нормализация (Batch Normalization - BN)
После сложения, используется пакетная нормализация (BN) для нормализации Y к соответствующему диапазону, чтобы все функции активации, используемые в обычных CNN, после этого могли использоваться в предлагаемых AdderNets.
Хотя слой BN включает в себя умножения, его вычислительные затраты значительно ниже, чем у сверточных слоев, и ими можно пренебречь.
(Появятся ли в будущем какие-нибудь BN, использующие сложение?)
2.2. Производные
Производная l1-меры не подходит для градиентного спуска. Таким образом, мы рассматриваем производную l2-меры:

Использование точного градиента позволяет точно обновлять фильтры.
Чтобы избежать взрыва градиента, градиент X обрезается до [-1,1].
Затем вычисляется частная производная выходных признаков Y по отношению к входным характеристикам X как:

где HT - функция HardTanh:
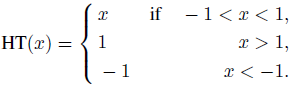
2.3. Скорость адаптивного обучения

Как показано в этой таблице, меры градиентов фильтров в AdderNets намного меньше, чем в CNN, что может замедлить обновление фильтров в AdderNets.
В AdderNets используется адаптивная скорость обучения для разных уровней:
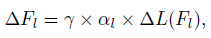
где ? - глобальная скорость обучения всей нейронной сети (например, для сумматора и BN слоев), ?L(Fl) - градиент фильтра в слое l, а ?l - соответствующая локальная скорость обучения.
Таким образом, локальная скорость обучения может быть определена как

где k обозначает количество элементов в Fl, а ? - гиперпараметр для управления скоростью обучения фильтров сумматора.
3. Результаты экспериментов
3.1. MNIST
CNN достигает точности 99,4% при 435K умножений и 435K сложений.
Заменяя умножения в свертке на сложения, предлагаемая AdderNet достигает точности 99,4%, такой же показатель как у CNN, с 870K сложениями и почти без умножений.
Теоретическая задержка умножения в ЦП также больше, чем задержка сложения и вычитания.
Например, на модели VIA Nano 2000 задержка умножения и сложения с плавающей запятой составляет 4 и 2 соответственно. AdderNet с моделью LeNet-5 будет иметь задержку 1.7M, в то время как CNN будет иметь задержку 2.6M на том же CPU.
3.2. CIFAR


Двоичные нейронные сети (Binary neural networks - BNN): могут использовать операции XNOR для замены умножения, что мы также используем для сравнения.
Для модели VGG-small, AdderNets без умножения достигает почти таких же результатов (93,72% в CIFAR-10 и 72,64% в CIFAR-100) как и CNNs (93,80% в CIFAR-10 и 72,73% в CIFAR-100).
Хотя размер модели BNN намного меньше, чем у AdderNet и CNN, ее точность намного ниже (89,80% в CIFAR-10 и 65,41% в CIFAR-100).
Что касается ResNet-20, CNN достигают наивысшей точности (т.е. 92,25% в CIFAR-10 и 68,14% в CIFAR-100), но с большим числом умножений (41,17M).
Предлагаемые AdderNets достигают точности 91,84% в CIFAR-10 и 67,60% точности в CIFAR-100 без умножения, что сравнимо с CNN.
Напротив, BNN достигают точности только 84,87% и 54,14% в CIFAR-10 и CIFAR-100.
Результаты ResNet-32 также предполагают, что предлагаемые AdderNets могут достигать результатов аналогичных обычным CNN.
3.3. ImageNet

CNN достигает 69,8% точности top-1 и 89,1% точности top-5 в RESNET-18. Однако, при 1.8G умножениях.
AdderNet обеспечивает 66,8% точности top-1 и 87,4% точности top-5 в ResNet-18, что демонстрирует, что фильтры сумматора могут извлекать полезную информацию из изображений.
Несмотря на то, что BNN может достигать высокой степени ускорения и сжатия, он достигает только 51,2% точности top-1 и 73,2% точности top-5 в ResNet-18.
Аналогичные результаты для более глубокого ResNet-50.
3.4. Результаты визуализации

LeNet++ обучался на наборе данных MNIST, который имеет шесть сверточных слоев и полносвязный слой для извлечения выраженных 3D признаков.
Количество нейронов в каждом сверточном слое составляет 32, 32, 64, 64, 128, 128 и 2 соответственно.
AdderNets использует l1-меру для различения разных классов. Признаки имеют тенденцию быть сгруппированными относительно центров разных классов.
Результаты визуализации демонстрируют, что предлагаемые AdderNets могут обладать аналогичной способностью распознавания для классификации изображений как и CNN.

Фильтры предлагаемых adderNets по-прежнему имеют некоторые схожие паттерны со сверточными фильтрами.
Эксперименты по визуализации дополнительно демонстрируют, что фильтры AdderNets могут эффективно извлекать полезную информацию из входных изображений и признаков.
 и CNN (справа).")
Распределение весов с AdderNets близко к распределению Лапласа, тогда как распределение с CNN больше походит больше на распределение Гаусса. Фактически, априорным распределением l1-меры является распределение Лапласа.
3.5. Абляционное исследование

AdderNets, использующие адаптивную скорость обучения (adaptive learning rate - ALR) и увеличенную скорость обучения (increased learning rate - ILR), достигают точности 97,99% и 97,72% со знаковым градиентом, что намного ниже, чем точность CNN (99,40%) .
Поэтому мы предлагаем использовать точный градиент для более точного обновления весов в AdderNets.
В результате AdderNet с ILR достигает точности 98,99% при использовании точного градиента. Используя адаптивную скорость обучения (ALR), AdderNet может достичь точности 99,40%, что демонстрирует эффективность предложенного метода.
Ссылка на статью
[2020 CVPR] [AdderNet]
AdderNet: Do We Really Need Multiplications in Deep Learning?
Классификация изображений
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Dropout] [Maxout] [NIN] [ZFNet] [SPPNet] [Distillation]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock] [Group Norm (GN)]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss]
2020: [Random Erasing (RE)] [SAOL] [AdderNet]
Перевод материала подготовлен в преддверии старта курса "Deep Learning. Basic".
Также приглашаем всех желающих посетить бесплатный демо-урок по теме: "Knowledge distillation: нейросети обучают нейросети".