
Какие есть причины переходить на новые версии Java? Кто-то это сделает из-за новых языковых возможностей вроде выражений switch, блоков текста или записей. Кому-то понадобятся новые интересные возможности вроде модулей или низкопаузных сборщиков мусора. Кто-то это сделает просто из-за того, что обновив версию Java, их программа станет быстрее и будет есть меньше памяти. Но есть ещё одна, не менее важная причина. Это новые API, которые позволят писать меньше кода и избежать траты времени на поиск нужной функциональности во внешних библиотеках. А в некоторых случаях сделают ваш код быстрее.
В предыдущих двух частях мы уже рассмотрели по 10 новых API, которые появились в Java 9 и более поздних версиях (часть 1, часть 2). Сегодня мы рассмотрим ещё 10.
1. Stream.toList()
Появился в: Java 16
Для какой задачи чаще всего используется Stream в Java? Конечно же, для трансформации списков: у нас есть список, над которым нужно совершить какое-то преобразование и вернуть новый. Такой паттерн вы наверняка видели в своём проекте множество раз:
List<T> targetList = sourceList
.stream()
// промежуточные операции
.collect(Collectors.toList());Нельзя сказать, что collect(Collectors.toList()) является очень уж громоздкой конструкцией, но всё же хочется для такой частой операции писать поменьше кода. И в Java 16 это стало возможно с помощью нового метода Stream.toList():
List<T> targetList = sourceList
.stream()
// промежуточные операции
.toList();Есть ли какая-то разница между toList() и collect(Collectors.toList())? Оба ли способа ведут себя одинаково? С практической точки зрения можно сказать, что нет: если toList() возвращает неизменяемый список, то collect(Collectors.toList()) возвращает некий список, о котором неизвестно, неизменяемый он или нет. То есть если вы нигде в коде не используете негарантированную вам спецификацией изменяемость списка (надеюсь, вы из такой категории людей), то смело можете заменять collect(Collectors.toList()) на toList().
Однако Stream.toList() делает код не только короче, но и эффективнее! Дело в том, что Stream.toList() использует внутри себя Stream.toArray(), который выделяет массив точной длины, если Spliterator имеет характеристику SIZED. В то время как Collectors.toList() никак эту характеристику не использует и всегда начинает с пустого ArrayList, накапливая в нём элементы с постоянными переаллокациями.
Давайте напишем несколько бенчмарков. Для начала рассмотрим самый простейший случай: замерим, как быстро создаётся копия исходного списка, т.е. проверим цепочку вообще без промежуточных операций. Так как для такого сценария Stream по идее вообще не нужен, и того же самого можно добиться просто вызвав new ArrayList<>(sourceList) или List.copyOf(sourceList), то замерим и эти два случая тоже:
import org.openjdk.jmh.annotations.*;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Thread)
public class ToList {
@Param({"10", "100", "1000"})
private int size;
private List<Integer> sourceList;
@Setup
public void setup() {
sourceList = IntStream
.range(0, size)
.boxed()
.collect(Collectors.toList());
}
@Benchmark
public List<Integer> newArrayList() {
return new ArrayList<>(sourceList);
}
@Benchmark
public List<Integer> toList() {
return sourceList.stream().toList();
}
@Benchmark
public List<Integer> copyOf() {
return List.copyOf(sourceList);
}
@Benchmark
public List<Integer> collectToList() {
return sourceList.stream().collect(Collectors.toList());
}
@Benchmark
public List<Integer> collectToUnmodifiableList() {
return sourceList.stream().collect(Collectors.toUnmodifiableList());
}
}OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
Intel Core i5-9500 3.00GHZ
Опции запуска: -f 3 -wi 3 -w 5 -i 5 -r 5 -t 6 -jvmArgs -XX:+UseParallelGC
Результаты говорят нам о том, что Stream.toList() не только существенно быстрее collect(Collectors.toList()), но и может быть быстрее даже List.copyOf()! Это объясняется тем, что в List.copyOf() существенное время тратится на проверку requireNonNull для каждого входного элемента, поскольку он запрещает null-элементы, в то время как Stream.toList() не запрещает null и в нём такая проверка не нужна. На малых размерах List.copyOf() всё же выигрывает, потому что проверка нескольких элементов на null быстрее церемоний, которые есть у Stream: создание Spliterator, ReferencePipeline и т.д.
Теперь рассмотрим случай, когда точный размер неизвестен. Например, добавим одну промежуточную операцию filter():
import org.openjdk.jmh.annotations.*;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Thread)
public class ToListFilter {
@Param({"10", "100", "1000"})
private int size;
private List<Integer> sourceList;
@Setup
public void setup() {
sourceList = IntStream
.range(0, size)
.boxed()
.collect(Collectors.toList());
}
@Benchmark
public List<Integer> toList() {
return sourceList.stream().filter(i -> i % 2 == 0).toList();
}
@Benchmark
public List<Integer> newArrayList() {
var list = new ArrayList<Integer>();
for (var i : sourceList) {
if (i % 2 == 0) {
list.add(i);
}
}
return list;
}
@Benchmark
public List<Integer> collectToList() {
return sourceList.stream().filter(i -> i % 2 == 0).collect(Collectors.toList());
}
@Benchmark
public List<Integer> collectToUnmodifiableList() {
return sourceList.stream().filter(i -> i % 2 == 0).collect(Collectors.toUnmodifiableList());
}
}OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
Intel Core i5-9500 3.00GHZ
Опции запуска: -f 3 -wi 3 -w 5 -i 5 -r 5 -t 6 -jvmArgs -XX:+UseParallelGC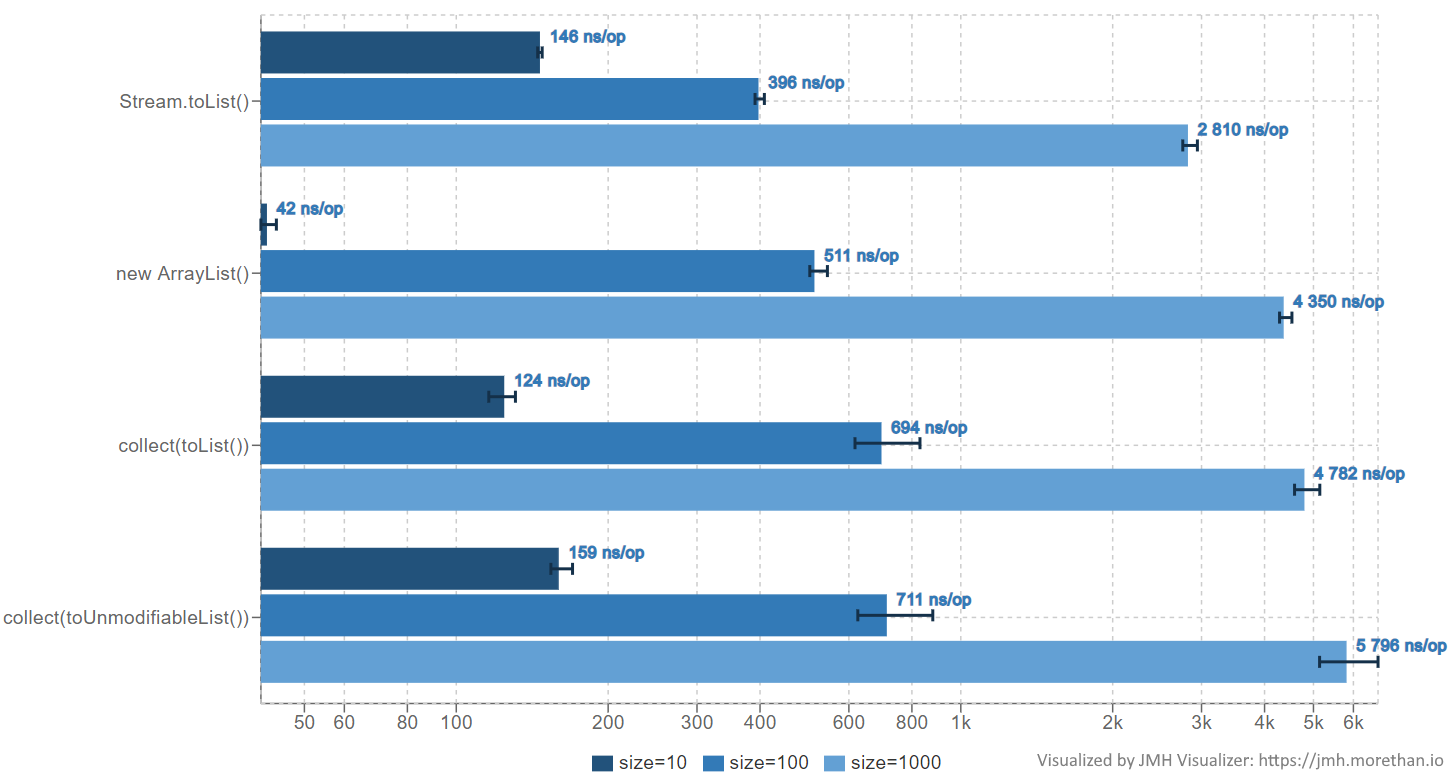
В этом случае мы тоже получили большое ускорение! И в этот раз Stream.toList() на большом количестве элементов выиграл даже у простого new ArrayList() с последующим заполнением в цикле. Как так получается? Дело в том, что при неизвестном размере Stream.toArray() использует структуру данных SpinedBuffer, которая более эффективна для накопления элементов, чем ArrayList. Она представляет собой массив массивов, где подмассивы имеют длины в виде возрастающих степеней двойки (каждый следующий chunk в два раза больше предыдущего). Структуру SpinedBuffer можно легко понять из этого рисунка, где изображён буфер со 100 элементами (Integer от 0 до 99):

Также ArrayList проигрывает ещё и потому, что расширяется всего лишь в 1.5 раза при заполнении внутреннего массива, а значит делает это намного чаще, что приводит к дополнительным накладным расходам. ArrayList вынужден балансировать между экономией памяти и скоростью операции add(), поэтому и проигрывает SpinedBuffer, который заточен исключительно на скорость. Излишний расход памяти для него не играет роли, так как это недолгоживующая структура, которая сразу же отбрасывается после завершения терминальной операции.
Вывод: Stream.toList() короче, чище и почти всегда быстрее, чем collect(Collectors.toList()). Так что о втором способе можно забыть и использовать всегда первый (хотя Collectors.toList() сам по себе всё ещё может быть нужен, например как downstream Collector для других Collector'ов). Если же нужен гарантированно изменяемый список, то можно использовать collect(Collectors.toCollection(ArrayList::new)).
2. String: formatted(), stripIndent() и translateEscapes()
Появились в: Java 15
В Java 15 появились блоки текста – строковые литералы, которые могут состоять из одной или нескольких линий:
String str = """
Привет,
Юзер!""";При этом довольно часто блоки будут использоваться в качестве шаблонов с последующей заменой:
String str = String.format("""
Привет,
%s!""", user);Не кажется ли вам, что код выше выглядит несколько громоздким? Мне вот тоже кажется. Но у нас есть способ, как сделать его немножко чище. Это новый метод String.formatted(), который является нестатическим эквивалентом String.format():
String str = """
Привет,
%s!""".formatted(user);Вы, конечно, скажете, что разница лишь в трёх символах сэкономленного кода, но, во-первых, второй вариант гораздо проще печатать на клавиатуре (проверьте сами), а во-вторых, он более читабелен.
Кстати, formatted() никто не запрещает использовать и с обычными литералами:
String str = "Привет, %s!".formatted(user);Лично мне метод очень нравится, и я планирую взять его на вооружение в качестве основного рабочего варианта.
Второй метод, появившийся в Java 15 – это String.stripIndent(), который удаляет общие пробельные символы в начале всех линий. К примеру, если есть файл hello.txt с такими строками:
Привет,
Юзер!Тогда чтобы убрать пробелы слева, как раз и можно воспользоваться stripIndent():
String str = Files.readString(Path.of("hello.txt")).stripIndent();
System.out.println(str);Вывод:
Привет,
Юзер!Наконец, третий метод – это String.translateEscapes(). Он делает простую вещь: заменяет экранирующие последовательности на их соответствующие символы.
Например, есть файл hello.txt:
Привет,\nЮзер!String str = Files.readString(Path.of("hello.txt")).translateEscapes();
System.out.println(str);Вывод:
Привет,
Юзер!3. CharSequence.isEmpty(), CharSequence.compare() и StringBuilder.compareTo()
Появились в: Java 15 / Java 11
Если уж мы начали тему строк, то давайте добьём её до конца.
Тот, кто писал на Java 1.5 или на более старых версиях, должен помнить, что в классе String в те времена не было метода isEmpty(). Поэтому для проверки строки на пустоту каждый раз приходилось использовать length():
if (str.length() != 0) {
...
}Это было не совсем удобно, и в Java 1.6 метод String.isEmpty() наконец-то завезли:
if (!str.isEmpty()) {
...
}Однако про то, что String – далеко не единственная реализация CharSequence (хоть и самая популярная), почему-то не подумали, и этот метод туда добавлять не стали (впрочем, без default-методов они бы этого сделать и не смогли). Например, для проверки на пустоту StringBuilder всё ещё приходилось использовать length():
if (stringBuilder.length() != 0) {
...
}Но спустя 14 лет всё-таки решили исправить и это: начиная с Java 15, метод isEmpty() есть не только у String, но и у любой CharSequence:
if (!stringBuilder.isEmpty()) {
...
}Также иногда приходится тестировать два CharSequence на равенство. Метод equals() использовать нельзя: а вдруг он не переопределён в реализации? Поэтому приходится изворачиваться: либо конвертировать каждый CharSequence в String и сравнивать их, что может быть накладно, либо писать свою реализацию посимвольного сравнения.
Однако, начиная с Java 11, всё это не нужно, потому что появился метод CharSequence.compare():
if (CharSequence.compare(charSeq1, charSeq2) == 0) {
...
}Метод compare() также можно использовать не только для просто теста на равенство, но и для лексикографического сравнения.
Также в Java 11 класс StringBuilder стал реализовывать интерфейс Comparable, а значит для сравнения двух StringBuilder можно использовать compareTo():
if (stringBuilder1.compareTo(stringBuilder2) == 0) {
...
}4. Collectors.filtering() и Collectors.flatMapping()
Появились в: Java 9
Часто ли вам приходится использовать Collectors.groupingBy()? К примеру, вы ведёте базу данных фильмов:
record Movie(String title, String genre, double rating) {
}Допустим, вы хотите сгруппировать фильмы по жанру:
Stream<Movie> allMovies = Stream.of(
new Movie("Коммандо", "Боевик", 7.385),
new Movie("Терминатор", "Боевик", 7.974),
new Movie("Терминатор 2", "Боевик", 8.312),
new Movie("Молчание ягнят", "Триллер", 8.33),
new Movie("Криминальное чтиво", "Триллер", 8.619),
new Movie("Титаник", "Мелодрама", 8.363),
new Movie("Семьянин", "Комедия", 7.699)
);
Map<String, List<Movie>> groups = allMovies.collect(
Collectors.groupingBy(Movie::genre));
groups.forEach((genre, movies) -> {
System.out.println(genre + ":");
movies.forEach(movie ->
System.out.printf(" %s: %.2f%n", movie.title(), movie.rating()));
});Вывод:
Мелодрама:
Титаник: 8.36
Боевик:
Коммандо: 7.39
Терминатор: 7.97
Терминатор 2: 8.31
Триллер:
Молчание ягнят: 8.33
Криминальное чтиво: 8.62
Комедия:
Семьянин: 7.70Однако, допустим, вы не хотите видеть все фильмы, а только те, у кого рейтинг выше 8. Какой метод вы в этом случае используете? Конечно же, Stream.filter():
Map<String, List<Movie>> groups = allMovies
.filter(movie -> movie.rating() > 8)
.collect(Collectors.groupingBy(Movie::genre));Мелодрама:
Титаник: 8.36
Боевик:
Терминатор 2: 8.31
Триллер:
Молчание ягнят: 8.33
Криминальное чтиво: 8.62Но вот проблема: вам вдруг захотелось видеть все жанры, даже те, в которые не попало ни одного фильма с рейтингом выше 8. Что делать? Ответ: перейти на новую версию Java, потому что в ней есть Collectors.filtering():
Map<String, List<Movie>> groups = allMovies.collect(
Collectors.groupingBy(Movie::genre,
Collectors.filtering(movie -> movie.rating() > 8,
Collectors.toList())));
groups.forEach((genre, movies) -> {
System.out.println(genre + ":");
if (movies.isEmpty()) {
System.out.println(" <Фильмов с рейтингом выше 8 нет>");
} else {
movies.forEach(movie ->
System.out.printf(" %s: %.2f%n", movie.title(), movie.rating()));
}
});В этом случае фильтрация будет перенесена внутрь groupingBy(), и потери жанров не произойдёт:
Мелодрама:
Титаник: 8.36
Боевик:
Терминатор 2: 8.31
Триллер:
Молчание ягнят: 8.33
Криминальное чтиво: 8.62
Комедия:
<Фильмов с рейтингом выше 8 нет>Очень хорошо. Теперь добавим в фильмы актёров:
record Movie(String title, String genre, double rating, List<String> actors) {
}И теперь хотите увидеть всех актёров с группировкой по жанру:
Stream<Movie> allMovies = Stream.of(
new Movie("Коммандо", "Боевик", 7.385,
List.of("Шварценеггер", "Чонг", "Хедайя")),
new Movie("Терминатор", "Боевик", 7.974,
List.of("Шварценеггер", "Бин", "Хэмилтон")),
new Movie("Терминатор 2", "Боевик", 8.312,
List.of("Шварценеггер", "Хэмилтон", "Ферлонг", "Патрик")),
new Movie("Молчание ягнят", "Триллер", 8.33,
List.of("Фостер", "Хопкинс")),
new Movie("Криминальное чтиво", "Триллер", 8.619,
List.of("Траволта", "Уиллис", "Джексон", "Турман")),
new Movie("Титаник", "Мелодрама", 8.363,
List.of("ДиКаприо", "Уинслет")),
new Movie("Семьянин", "Комедия", 7.699,
List.of("Кейдж", "Леони"))
);Но какой коллектор нужно подсунуть в groupingBy(), чтобы собрать всех актёров в Set? Можно попробовать Collectors.mapping():
Map<String, Set<List<String>>> groups = allMovies.collect(
Collectors.groupingBy(Movie::genre,
Collectors.mapping(Movie::actors, Collectors.toSet())));Но смотрите, у нас получилось множество списков, а нужно просто множество. Что же делать? И тут на помощь приходит Collectors.flatMapping(), ещё один новый метод, появившийся в Java 9:
Map<String, Set<String>> groups = allMovies.collect(
Collectors.groupingBy(Movie::genre,
Collectors.flatMapping(movie -> movie.actors().stream(),
Collectors.toSet())));И вот сейчас тип правильный! Если вывести это, то получится:
Мелодрама:
ДиКаприо
Уинслет
Боевик:
Бин
Ферлонг
Хедайя
Патрик
Шварценеггер
Хэмилтон
Чонг
Триллер:
Траволта
Уиллис
Хопкинс
Фостер
Джексон
Турман
Комедия:
Кейдж
ЛеониЧто и требовалось.
5. StackWalker
Появился в: Java 9
Приходилось ли вам иметь дело со стеками? Не со стеками в смысле структур данных, а со стеком потоков? Например, вы пишете простенький логгер:
public final class MyLogger {
public static void log(String message) {
System.out.println(message);
}
}Однако вы хотите писать в консоль не просто голое сообщение, а ещё имя класса, метода, файла и номер строки, откуда вызывается метод log(). В Java 8 единственным стандартным способом для этого является получение массива StackTraceElement[], например, с помощью метода Thread.getStackTrace():
public static void log(String message) {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
StackTraceElement stackTraceElement = stackTrace[2];
String msg = stackTraceElement.getClassName() + "."
+ stackTraceElement.getMethodName() + "("
+ stackTraceElement.getFileName() + ":"
+ stackTraceElement.getLineNumber() + ") "
+ message;
System.out.println(msg);
}Можно предположить, что такой способ получения получения номеров строк является довольно дорогим. Ведь нам надо заполнить полностью весь стек, который может быть очень глубоким (особенно в энтерпрайзе, где фреймворк на фреймворке), а потом ещё и сконвертировать внутренние структуры JVM в Java-массив. И всё это ради того, чтобы отбросить его почти полностью и достать только второй элемент. Давайте замерим производительность такого подхода:
@Benchmark
public String stackTrace() {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
StackTraceElement stackTraceElement = stackTrace[2];
return stackTraceElement.getClassName() + "."
+ stackTraceElement.getMethodName() + "("
+ stackTraceElement.getFileName() + ":"
+ stackTraceElement.getLineNumber() + ")";
}OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
Intel Core i5-9500 3.00GHZ
Опции запуска: -f 1 -wi 3 -w 3 -i 5 -r 5 -t 6Benchmark Mode Cnt Score Error Units
Stack.stackTrace avgt 5 103,704 ? 1,123 us/op104 микросекунды на каждый вызов! Это невероятно медленно! Есть ли возможность это ускорить? Есть: с помощью нового класса StackWalker, который появился в Java 9. Давайте рассмотрим этот класс поподробнее.
StackWalker предоставляет возможность «гулять» по стеку. Чтобы это сделать, сначала нужно получить экземпляр StackWalker с помощью метода StackWalker.getInstance(). Этот метод возвращает StackWalker по умолчанию. Также есть возможность передать в метод getInstance() опции и получить StackWalker с более богатыми возможностями. Но об этом чуть позже.
После того, как мы получил объект StackWalker, у нас есть следующие варианты:
- Выполнить на нём метод
forEach()и пройтись по всем фреймам стека. - Вызвать метод
getCallerClass()и получить класс, который вызвал наш метод (работает только с опциейRETAIN_CLASS_REFERENCE). - Вызвать метод
walk(), который принимает функцию изStream<StackFrame>вT, гдеT– это что угодно. Это самый гибкий метод.
Для нашего логгера мы воспользуемся третьим вариантом. Вот как будет выглядеть реализация метода log():
public static void log(String message) {
String msg = StackWalker
.getInstance()
.walk((Stream<StackFrame> frames) -> {
StackFrame frame = frames.skip(2).findFirst().get();
return frame.getClassName() + "."
+ frame.getMethodName() + "("
+ frame.getFileName() + ":"
+ frame.getLineNumber() + ") "
+ message;
});
System.out.println(msg);
}Теперь давайте замерим производительность варианта со StackWalker:
@Benchmark
public String stackWalker() {
return StackWalker
.getInstance()
.walk(frames -> {
StackFrame frame = frames.skip(2).findFirst().get();
return frame.getClassName() + "."
+ frame.getMethodName() + "("
+ frame.getFileName() + ":"
+ frame.getLineNumber() + ")";
});
}OpenJDK 64-Bit Server VM (build 16+36-2231, mixed mode, sharing)
Intel Core i5-9500 3.00GHZ
Опции запуска: -f 1 -wi 3 -w 3 -i 5 -r 5 -t 6Benchmark Mode Cnt Score Error Units
Stack.stackTrace avgt 5 103,704 ? 1,123 us/op
Stack.stackWalker avgt 5 2,781 ? 0,156 us/opСкорость выросла в 37 раз! Это огромный выигрыш. Конечно, 2.8 микросекунды это всё ещё далеко не бесплатно, но такой вариант кажется уже вполне приемлемым, чтобы включить его в боевом приложении.
Так как метод StackWalker.walk() даёт нам Stream, то наши возможности по обходу стека практически безграничны: можно получить все фреймы, можно отфильтровать, можно пропустить сколько-то. Например, усложним наш логирующий «фреймворк», добавив туда уровни:
package org.mylogger;
public final class MyLogger {
public enum Level {
ERROR, WARN, INFO
}
public static void error(String message) {
log(Level.ERROR, message);
}
public static void warn(String message) {
log(Level.WARN, message);
}
public static void info(String message) {
log(Level.INFO, message);
}
public static void log(Level level, String message) {
...
}
}Сейчас мы уже не можем использовать конструкцию frames.skip(2), потому что метод log() может быть вызван как напрямую, так и через методы error(), warn(), log(), а значит фрейм надо искать немножко умнее. Самое простое – через Stream.dropWhile():
public static void log(Level level, String message) {
String msg = StackWalker
.getInstance()
.walk((Stream<StackFrame> frames) -> {
StackFrame frame = frames
.dropWhile(f -> f.getClassName().startsWith("org.mylogger"))
.findFirst()
.get();
return level + " "
+ frame.getClassName() + "."
+ frame.getMethodName() + "("
+ frame.getFileName() + ":"
+ frame.getLineNumber() + ") "
+ message;
});
System.out.println(msg);
}Какие ещё применения есть у StackWalker?
Как вы знаете, в Java 9 появились модули. Но мало кто использует их в своих проектах, и подавляющее большинство всё ещё препочитает класть всё в classpath. Но тогда у нас теряется весьма ценная возможность – экспортировать из модуля часть пакетов, а остальные скрывать. Представим, что у нас есть пакет org.example.mylib.internal, который мы хотим, чтобы не использовал никто кроме нашего модуля:
package org.example.mylib.internal;
public final class Handler {
public static void handle() {
...
}
}Класс Handler публичный, а значит компилятор уже никак не помешает кому угодно использовать этот класс. Но, может быть, можно сделать хотя бы проверку в рантайме? И действительно, это можно сделать через StackWalker.getCallerClass(), и выглядеть этот будет примерно так:
package org.example.mylib.internal;
public final class Handler {
public static void handle() {
if (!StackWalker
.getInstance(Option.RETAIN_CLASS_REFERENCE)
.getCallerClass()
.getPackageName()
.startsWith("org.example.mylib.")) {
throw new RuntimeException("Security error");
}
...
}
}Здесь мы использовали опцию RETAIN_CLASS_REFERENCE, иначе получить Class не получилось бы. В принципе, подобную функциональность можно было бы реализовать и через Stream.walk(), но getCallerClass() работает немного быстрее.
6. System.Logger
Появился в: Java 9
Если уж мы начали говорить про логирование, то нельзя не рассказать про новое стандартное API для логирования, которое появилось в Java 9. Это API очень маленькое и состоит всего из трёх классов: интерфейса System.Logger, абстрактного класса System.LoggerFinder и перечисления System.Logger.Level.
Использовать System.Logger чрезвычайно просто:
public final class Main {
private static final Logger LOGGER = System.getLogger("");
public static void main(String[] args) {
LOGGER.log(Level.ERROR, "Critical error!");
}
}Вывод:
апр. 17, 2021 6:24:57 PM org.example.Main main
SEVERE: Critical error!System.Logger – это не новый очередной фреймворк для логирования, как вы могли бы подумать сначала, а только фронтенд для логирования. Если вы знакомы с существующими фреймворками, то вам должно быть это знакомо: например, SLF4J – это фронтенд, а его соответствующим бэкендом является Logback. Или Log4j API – это фронтенд для Log4j Core. Так вот, System.Logger – это фронтенд для знакомого вам фреймворка java.util.logging, который находится в отдельном модуле java.logging.
При этом нам ничего не мешает для SLF4J использовать другой бэкенд, например, Log4j или java.util.logging. Или для Log4j API использовать SLF4J как бэкенд или java.util.logging. Точно так же и с System.Logger: он спроектирован так, чтобы реализация могла быть абсолютно любой. Если не нравится неудобный и старый java.util.logging, то можно использовать что-то другое. Например, можно его настроить на современный Log4j, для чего потребуется подключить следующие зависимости:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.14.1</version> <!-- Последняя версия на момент написания статьи -->
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.1</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-jpl</artifactId>
<version>2.14.1</version>
<scope>runtime</scope>
</dependency>При этом саму программу изменять не потребуется: то, что log4j-jpl окажется в classpath, уже будет достаточно. Java через ServiceLoader найдёт нужную реализацию LoggerFinder в виде Log4jSystemLoggerFinder и будет направлять логи в Log4j:
18:24:57.941 [main] ERROR - Critical error!После этого модуль java.logging можно будет даже вообще исключить из JRE/JDK, ведь он больше не нужен (если вы конечно нигде не вызываете java.util.logging напрямую).
К сожалению, адаптера System.Logger для SLF4J/Logback нет. Но тут проблема более глобальная – похоже, что сам проект SLF4J мёртв. Последний коммит в GitHub был полтора года назад. Так что Log4j сейчас это самый нормальный вариант – он активно развивается и поддерживается.
Несколько примеров использования System.Logger:
LOGGER.log(Level.INFO, "Information");
LOGGER.log(Level.DEBUG, "Sum of {} and {} is {}:", 2, 3, 2+3);
LOGGER.log(Level.TRACE, () -> "Lazy message");
LOGGER.log(Level.ERROR, "Log exception", new Exception());7. Lookup.defineHiddenClass()
Появился в: Java 15
В прошлый раз мы рассказывали про метод MethodHandles.Lookup.defineClass(), с помощью которого можно во время выполнения легко загрузить класс в том же пакете, не создавая при этом новый загрузчик класса. Это очень удобный метод, но у него есть существенный минус: класс, который загружен таким образом, будет до конца жизни висеть в памяти (по крайней мере до конца жизни текущего загрузчика класса). Это не очень подходит для приложений, которым требуется динамически генерировать и загружать много временных классов на лету. Но с Java 15 появилась альтернатива в виде нового вида классов, которые называются скрытыми.
Скрытые классы создаются с помощью нового метода Lookup.defineHiddenClass(). По сути этот метод очень похож на старый нестандартный метод Unsafe.defineAnonymousClass(), который много лет используется различными фреймворками, поскольку решает проблему неконтролируемого роста количества временных классов в памяти. При этом сам Unsafe.defineAnonymousClass() с Java 15 стал deprecated for removal.
Скрытые классы имеют следующие особенности:
- На них не могут прямо ссылаться другие классы. Всё их использование может осуществляться исключительно через рефлексию.
- Они являются необнаружимыми. Их нельзя найти ни по имени, ни обнаружить с помощью загрузчиков классов (через
Class.forName(),ClassLoader.loadClass(),ClassLoader.findLoadedClass()и т.д.). Однако скрытые классы не являются анонимными и всё-таки имеют имя в формате<имя класса в байт-коде>/<suffix>(например,org.example.Temp/0x0000000800cb8000). - Они реализованы таким способом, что не связаны сильной ссылкой с загрузчиком класса, а значит могут быть собраны сборщиком мусора, когда их
Classстановится недостижимым (но если хочется, то это можно переопределить, передав опциюClassOption.STRONGвdefineHiddenClass()). - Они не появляются в стектрейсах, если только не включить опции
-XX:+UnlockDiagnosticVMOptions -XX:+ShowHiddenFrames.
Кстати, вы уже должны быть хорошо знакомы со скрытыми классами, поскольку используете их каждый день. Это лямбды:
jshell> Runnable runnable = () -> {}
runnable ==> $Lambda$26/0x0000000800c0aa00@443b7951
jshell> runnable.getClass().isHidden()
$2 ==> trueДавайте создадим небольшой примерчик и определим свой скрытый класс «с нуля». Пусть он для простоты складывает два int'а. Для разнообразия будем это делать не с помощью javac, а через ByteBuddy.
Для начала нужно создать представление класса в байт-коде в виде массива байтов:
byte[] bytes = new ByteBuddy()
.subclass(Object.class)
.name("org.example.Temp")
.defineMethod("sum", int.class, Modifier.PUBLIC)
.withParameters(int.class, int.class)
.intercept(new Implementation.Simple(
MethodVariableAccess.INTEGER.loadFrom(1),
MethodVariableAccess.INTEGER.loadFrom(2),
Addition.INTEGER,
MethodReturn.INTEGER))
.make()
.getBytes();По сути мы скомпилировали вот такой класс, но сделали это в рантайме непосредственно через манипуляции с байт-кодом:
package org.example;
public class Temp {
public int sum(int x, int y) {
return x + y;
}
}Теперь, когда у нас есть байт-код класса, можно его загружать и что-то с ним делать:
Lookup lookup = MethodHandles
.lookup()
.defineHiddenClass(bytes, false);
// Для разнообразия будем использовать MethodHandle вместо reflection
Object obj = lookup
.findConstructor(lookup.lookupClass(), MethodType.methodType(void.class))
.invoke();
MethodHandle sumHandle = lookup.findVirtual(lookup.lookupClass(), "sum",
MethodType.methodType(int.class, int.class, int.class));
// Вызовем метод sum. Должен напечатать 5
System.out.println(sumHandle.invoke(obj, 3, 2));Вот и всё.
Кстати, так как скрытые классы необнаружимы, то загружать один и тот же класс можно сколько угодно раз. По сути каждый раз будет определяться новый уникальный скрытый класс:
Lookup lookup1 = MethodHandles.lookup().defineHiddenClass(bytes, false);
Lookup lookup2 = MethodHandles.lookup().defineHiddenClass(bytes, false);
Lookup lookup3 = MethodHandles.lookup().defineHiddenClass(bytes, false);
System.out.println(lookup1.lookupClass()); // class org.example.Temp/0x0000000800cb4000
System.out.println(lookup2.lookupClass()); // class org.example.Temp/0x0000000800cb4400
System.out.println(lookup3.lookupClass()); // class org.example.Temp/0x0000000800cb48008. Новые методы в Math
Появились в: Java 9 / Java 15
Наверное, практически все, кто начинал работать с большими числами в Java, совершал вот такую ошибку:
int x = ...
int y = ...
long z = x * y;Это один из тех примеров в Java, когда можно угодить в ловушку даже на простом умножении: произведение двух int – это тоже int, а значит то, что переменная z имеет тип long, от переполнения никак не спасает. Для исправления этой ошибки нужно явно прикастовать хотя бы один из множителей к long:
long z = (long) x * y;В то время как такое решение абсолютно рабочее, у меня в моём перфекционистском подсознании остаётся какой-то мелкий осадок. Во-первых, мне не нравится этот явный каст, который применяется то ли к первому множителю, то ли ко всему произведению. Во-вторых, не нравится эта асимметрия, что одна из переменных кастуется, а другая нет. В общем, я хочу кристальную ясность и отсутствие магии. Способ написать вот такое:
Возьми два int и перемножь их в long с учётом переполненияИ с Java 9 такой способ есть. Это метод Math.multiplyFull():
long z = Math.multiplyFull(x, y);Вообще обработка переполнений в Java реализуется довольно муторно, и чтобы облегчить жизнь программистам, в Java 8 появилась целая пачка методов для этого в классе Math:
int toIntExact(long value)int incrementExact(int a)long incrementExact(long a)int decrementExact(int a)long decrementExact(long a)int negateExact(int a)long negateExact(long a)int addExact(int x, int y)long addExact(long x, long y)int subtractExact(int x, int y)long subtractExact(long x, long y)int multiplyExact(int x, int y)long multiplyExact(long x, long y)
Все эти методы выбрасывают ошибку в случае переполнения, что во многих случаях лучше, чем просто тихое переполнение – лучше уж упадёт сразу, чем где-нибудь позже с совсем другой ошибкой. Но все ли возможные случаи тут покрыты? Похоже, что нет. Например, я не вижу модуль, который хоть и в очень редком случае, но всё же может переполниться:
jshell> Math.abs(Integer.MIN_VALUE)
$1 ==> -2147483648Как же так, ведь модуль – это положительное число? Это так, но дело в том, что 2147483648 просто не влезает в int, поэтому этот отдельный случай является исключением. Чтобы вот так по чистой случайности не напороться на такое, можно обезопасить себя методом Math.absExact(), который появился в Java 15:
jshell> Math.absExact(Integer.MIN_VALUE)
| Exception java.lang.ArithmeticException: Overflow to represent absolute value of Integer.MIN_VALUE
| at Math.absExact (Math.java:1392)
| at (#1:1)
jshell> Math.absExact(Long.MIN_VALUE)
| Exception java.lang.ArithmeticException: Overflow to represent absolute value of Long.MIN_VALUE
| at Math.absExact (Math.java:1438)
| at (#2:1)А знаете ли вы, сколько будет, если найти целое от деления -11 на 3? А остаток? Давайте проверим:
jshell> -11 / 3
$1 ==> -3
jshell> -11 % 3
$2 ==> -2Ну вроде бы логично, ведь -11 = 3 * (-3) - 2. Однако если вы выполните то же самое, например, на Python, то получите совсем иной результат:
>>> -11 / 3
-4
>>> -11 % 3
1И этот результат тоже по-своему верный: -11 = 3 * (-4) + 1. Дело в том, что есть два способа деления целых чисел: с обрезанием в сторону нуля и с обрезанием в сторону минус бесконечности. Java выбрала первый способ, Python – второй. Ну а что делать, если я хочу в Java делить по-питоновски? Для этого в Java 9 появились методы Math.floorDiv() и Math.floorMod():
jshell> Math.floorDiv(-11, 3)
$1 ==> -4
jshell> Math.floorMod(-11, 3)
$2 ==> 1Также для совсем упоротых математиков в Java 9 появились два метода Math.fma(float, float, float) и Math.fma(double, double, double), которые делают то же самое, что и a * b + c, но только точнее, потому что используют специальную отдельную инструкцию процессора:
jshell> Math.fma(2.99, 5.91, 7.1)
$1 ==> 24.7709
jshell> 2.99 * 5.91 + 7.1
$2 ==> 24.7709000000000059. Аннотация java.io.Serial
Появилась в: Java 14
Используете ли вы стандартную сериализацию в Java? Этот механизм далеко не идеальный и со своими недостатками, но иногда он может быть очень удобным, потому что позволяет из коробки очень просто сделать сереализацию и десериализацию Java-объектов. Рассмотрим пример:
public class Point {
private static final long serialVersionUID = 1L;
public int x;
public int y;
}Чтобы сконвертировать объект Point в массив байтов, нужно написать всего несколько строчек:
var point = new Point();
point.x = 1;
point.y = 2;
var baos = new ByteArrayOutputStream();
try (var oos = new ObjectOutputStream(baos)) {
oos.writeObject(point);
}
byte[] bytes = baos.toByteArray();Очень удобно. Кстати, вы заметили ошибку в моём коде? Конечно же, я забыл реализовать интерфейс Serializable! (Я специально добавил поле serialVersionUID, чтобы отвлечь ваше внимание.)
Правильный код будет таким:
public class Point implements Serializable {
private static final long serialVersionUID = 1;
public int x;
public int y;
}И вот это как раз и есть одна из главных проблем сериализации – при её использовании можно очень легко допустить ошибку: забыть Serializable, опечататься в названии поля serialVersionUID, забыть сделать его статическим и т.д. Чтобы немного обезопаситься от такого, в Java 14 ввели новую аннотацию Serial.
Этой аннотацией теперь рекомендуется помечать все поля и методы, относящиеся к механизму сериализации:
public class Point implements Serializable {
@Serial
private static final long serialVersionUID = 1;
...
}Теперь, если будет допущена ошибка, то появится предупреждение:
public class Point {
@Serial // Annotated member is not a part of the serialization mechanism
private static final long serialVersionUID = 1;
...
}Или:
public class Point implements Serializable {
@Serial // Annotated member is not a part of the serialization mechanism
private static final int serialVersionUID = 1;
...
}Аннотация будет делать проверки на всех полях и методах, которые относятся к сериализации: serialVersionUID, serialPersistentFields, writeObject(), readObject() и т.д.
К сожалению, на текущий момент предупреждения хорошо работают только в IntelliJ IDEA. В компиляторе JDK 16 проверки выполняются только с включённым флагом -Xlint:serial и работают не все. Например, для двух примеров выше javac ругается только во втором случае:
> javac -Xlint:serial Point.java
Point.java:6: warning: [serial] serialVersionUID must be of type long in class Point
private static final int serialVersionUID = 1;
^Возможно, это исправят в Java 17.
10. Методы Objects: checkIndex(), checkFromIndexSize(), checkFromToIndex()
Появились в: Java 9 / Java 16
Завершим нашу статью несколькими полезными методами для проверки индексов.
Иногда приходится писать функции, принимающие в качестве входных параметров индексы или диапазоны индексов, и чтобы начать использовать эти индексы, нужно сначала убедиться, что они не выходят за границы. То есть приходится писать подобные проверки в начале методов:
private static void getAt(int index, int length) {
if (index < 0) {
throw new IllegalArgumentException("index < 0");
}
if (index >= length) {
throw new IllegalArgumentException("index >= length");
}
...
}Если подобных функций в проекте становится уже несколько, то чтобы не повторяться, такие проверки удобнее вынести в отдельные утилитные методы:
public final class PreconditionUtils {
public static void checkIndex(int index, int length) {
if (index < 0) {
throw new IllegalArgumentException("index < 0");
}
if (index >= length) {
throw new IllegalArgumentException("index >= length");
}
}
}Но с Java 9 теперь это больше не нужно, потому что в классе Objects теперь есть стандартные методы проверок индексов.
Метод Objects.checkIndex() проверяет, что индекс находится в диапазоне [0, length):
jshell> Objects.checkIndex(-3, 10)
| Exception java.lang.IndexOutOfBoundsException: Index -3 out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckIndex (Preconditions.java:70)
| at Preconditions.checkIndex (Preconditions.java:248)
| at Objects.checkIndex (Objects.java:372)
| at (#1:1)
jshell> Objects.checkIndex(10, 10)
| Exception java.lang.IndexOutOfBoundsException: Index 10 out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckIndex (Preconditions.java:70)
| at Preconditions.checkIndex (Preconditions.java:248)
| at Objects.checkIndex (Objects.java:372)
| at (#2:1)Метод Objects.checkFromIndexSize() проверяет, что диапазон [fromIndex, fromIndex + size) находится в диапазоне [0, length):
jshell> Objects.checkFromIndexSize(3, 8, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [3, 3 + 8) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromIndexSize (Preconditions.java:82)
| at Preconditions.checkFromIndexSize (Preconditions.java:343)
| at Objects.checkFromIndexSize (Objects.java:424)
| at (#3:1)
jshell> Objects.checkFromIndexSize(-2, 8, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [-2, -2 + 8) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromIndexSize (Preconditions.java:82)
| at Preconditions.checkFromIndexSize (Preconditions.java:343)
| at Objects.checkFromIndexSize (Objects.java:424)
| at (#4:1)
jshell> Objects.checkFromIndexSize(3, -4, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [3, 3 + -4) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromIndexSize (Preconditions.java:82)
| at Preconditions.checkFromIndexSize (Preconditions.java:343)
| at Objects.checkFromIndexSize (Objects.java:424)
| at (#5:1)Наконец, метод Objects.checkFromToIndex() проверяет, что диапазон [fromIndex, toIndex) находится в диапазоне [0, length):
jshell> Objects.checkFromToIndex(3, 11, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [3, 11) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromToIndex (Preconditions.java:76)
| at Preconditions.checkFromToIndex (Preconditions.java:295)
| at Objects.checkFromToIndex (Objects.java:398)
| at (#6:1)
jshell> Objects.checkFromToIndex(-4, 8, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [-4, 8) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromToIndex (Preconditions.java:76)
| at Preconditions.checkFromToIndex (Preconditions.java:295)
| at Objects.checkFromToIndex (Objects.java:398)
| at (#7:1)
jshell> Objects.checkFromToIndex(6, 4, 10)
| Exception java.lang.IndexOutOfBoundsException: Range [6, 4) out of bounds for length 10
| at Preconditions.outOfBounds (Preconditions.java:64)
| at Preconditions.outOfBoundsCheckFromToIndex (Preconditions.java:76)
| at Preconditions.checkFromToIndex (Preconditions.java:295)
| at Objects.checkFromToIndex (Objects.java:398)
| at (#8:1)Кроме того, в Java 16 появились перегрузки этих функций для long:
Заключение
Сегодня я рассказал про 10 интересных API, некоторые из которых появились в буквально только что вышедшей Java 16, а некоторые уже присутствуют довольно давно ещё с 9-й версии. Надеюсь, что после прочтения данной статьи вы стали более заинтересованными в миграции на последнюю версию Java. Помните, что в новых версиях Java появляются не только новые возможности, но и изменения, ломающие обратную совместимость (1, 2, 3, 4, 5, 6, 7, 8). И чем больше вы тянете с переходом с Java 8 на последнюю версию, тем сложнее вам будет осуществить этот переход.
Продолжение следует...






welovelain
Вау, нормальные строки завезли в 2021 году.
Интересно, кто-нибудь юзает Jigsaw? Я так понимаю, оно больше не в серверной разработке, а для разработки всяких либ полезно, но вроде позиционировали это как нечто большое и значимое, а по факту просто головная боль с JavaFX, например.
gsaw
11-я LTE и будет такой кажется до 24 года, так что все эти вкушняшки только года через три попробуем.
furic
Java 17 LTS выходит в сентябре 2021
mspain
Капитан подсказывает — то что в 2021 появится 17я не значит, что 11я исчезнет.
furic
Тут салага хотел вкусняшек попробовать, и то что капитан настаивает на 11-ой ему до фени