
Кукусики!
Меня зовут Юля, и я Mobile QA в компании Vivid Money.
В тестировании уже давно — столько всего интересного видела. ? Но как показывает практика, проблемы и заботы у всех одинаковые. Разница только в анализе, подходах и реализации решений.
В этой статье я расскажу, КАК ОБЛЕГЧИТЬ ЖИЗНЬ ТЕСТИРОВЩИКУ ВО ВРЕМЯ РЕГРЕССА!
Расскажу по порядку:
Наши процессы (для полноты картины)
Основную проблему
Анализ
Методы решения, с полученными результатами
Немного о наших процессах
Итак, релиз приложений происходит раз в неделю. Один день закладывается на регрессионное тестирование, второй на smoke. Остальное время на разработку новых фич, исправление дефектов, написание и обновление документации, улучшение процессов.
Регрессионное тестирование — это набор тестов, направленных на обнаружение дефектов в уже протестированных, но затронутых изменениями, участках приложения.
Практически все позитивные сценарии проверки покрыты тест кейсами, которые ведутся в Allure TestOps.
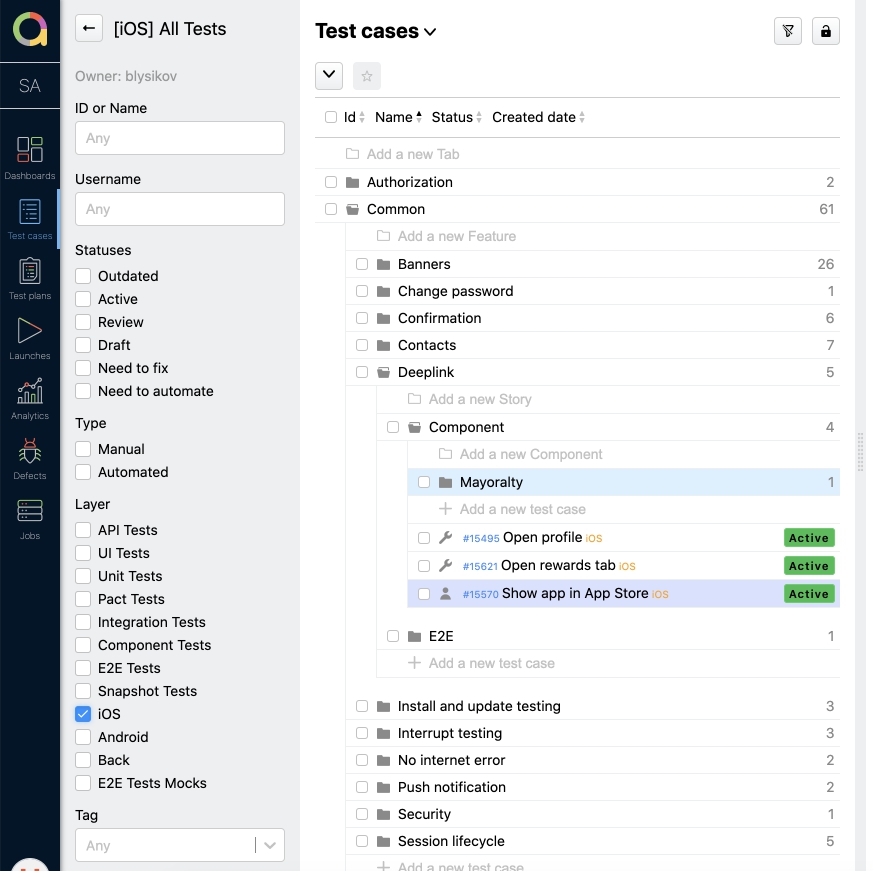
У каждой платформы (я имею ввиду iOS, Android) своя документация и автотесты, но все хранится в одном месте. Любой QA из команды может посмотреть и отредактировать их. Если добавляются новые кейсы, то они обязательно проходят ревью. Тестировщик Android проводит ревью для iOS, и наоборот. Это актуально для ручных тестов.
Про тест план для регресса
Для проведения регрессионного тестирования, составляется тест план с ручными тест кейсами и автотестами, отдельно для Android и iOS. Тестировщик собирает лаунч (запуск тест плана), в котором указывает версию релизной сборки и платформу. После создания лаунча, запускаются автотесты с выбранными кейсами, а ответственный за ручное тестирование назначает мануальные тест кейсы на себя. Каждый проходимый кейс отмечается статусом: Passed, Failed или Skipped. В ходе проверки сразу отображаются результаты.
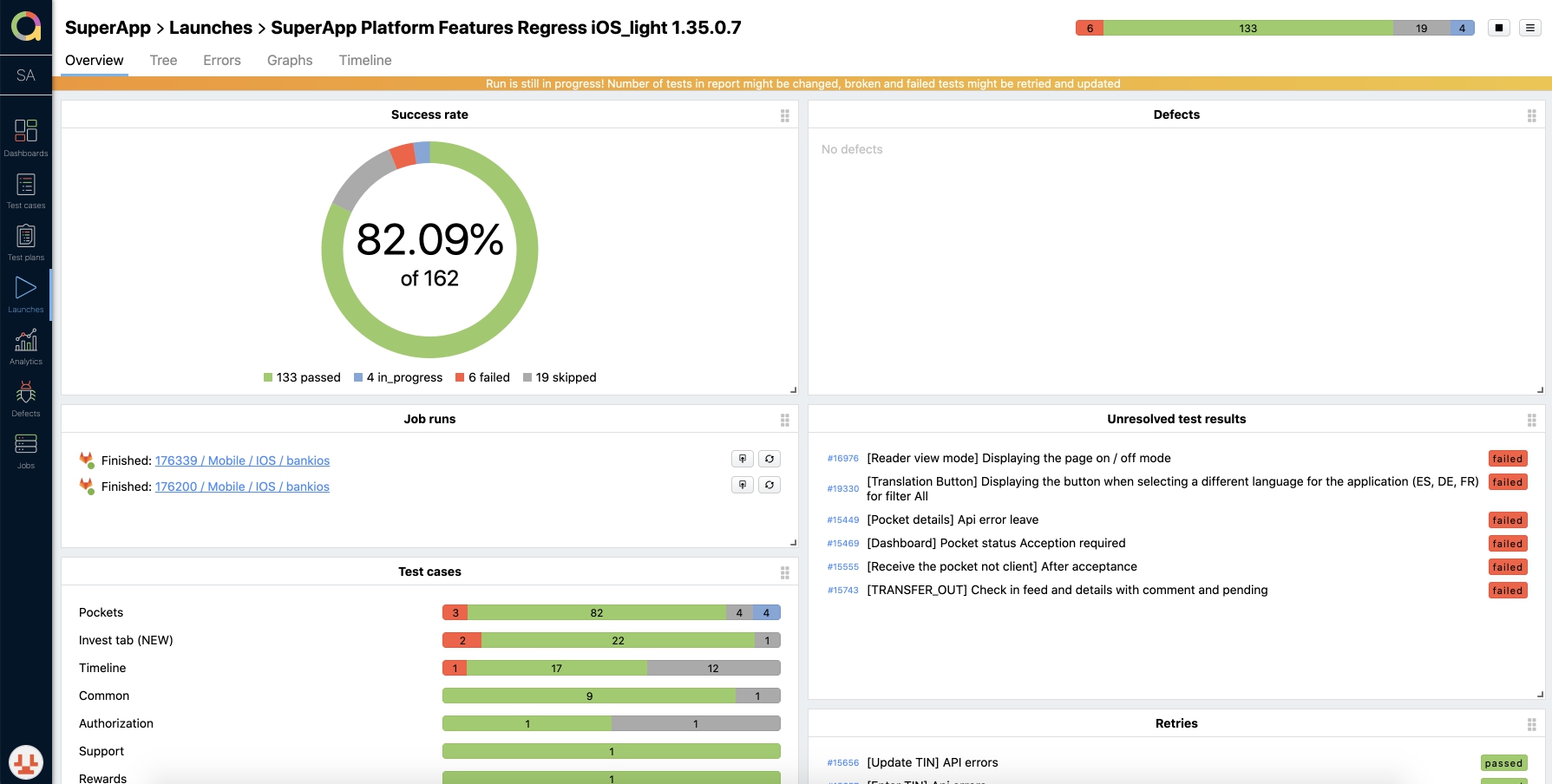
По окончании проверки лаунч закрывается. А на основании результов выносится решение о готовности к релизу. Вроде все классно и логично, но конечно же есть проблемы из-за которых грустят тестировщики ?

Определим проблему
Увеличение объема тестируемого функционала при проведении регресса, и выход из временных рамок.
Или — тест кейсов все больше и больше, а времени у нас только 8 часов максимум!
Раньше в тест план попадали все кейсы. А с добавлением нового функционала, тест план увеличился до 300 тестов и прохождение его стало занимать больше времени, чем было заложено. Мы перестали укладываться в рабочий день. В связи с этим было решено пересмотреть подход к тестированию, учитывая временные рамки и возможность сохранения качества.
Анализ и решение
Ручное тестирование перегружено из-за того, что с каждой новой фичей добавляются тест кейсы, они могут быть как простые, так и сложные (состоящие из переходов между экранами). Также приходилось проводить тестирование взаимодействия с бэкендом. Мы тратили много времени на такие проверки, особенно когда возникали баги и приходилось разбираться на чьей стороне проблемы.
Расписав слабые места, мы решили доработать подход к автоматизации, а еще воспользовались импакт-анализом для выделения методов решения.
Impact Analysis (импакт анализ) — это исследование, которое позволяет указать затронутые места в проекте при разработке новой или изменении старой функциональности.
Что же мы решили изменить, чтобы разгрузить ручное тестирование и сократить регресс:
Увеличение количества автотестов и разработка единого сценария перевода тест кейсов в автоматизацию
Разделение тестируемого функционала на фронтенд и бэкенд
Изменение подхода к формированию тест плана на регресс и смоук
Подключение автоматического анализа изменений, входящих в релизную сборку
Ниже я расскажу про каждый пункт более подробно и какие результаты были получены после введения.
Увеличение количества автотестов
Зачастую, когда в процессе тестирования хотят сократить время на регресс, начинают с автоматизации. Но у нас все этапы проходили параллельно. И естественно, часть проверок перешло в автоматизацию. Подробнее о том, как построен процесс автоматизации у нас в компании, будет расписано в другой статье.
Чтобы процесс был одинаковым для обеих платформ, была написана инструкция. В ней расписаны критерии перевода, шаги и инструменты. Я коротко распишу как происходит перевод тест кейсов в автоматизацию:
Определяется какие варианты проверок можно автоматизировать. Это делает ручной тестировщик самостоятельно, или обсудив с командой на митинге.
В Allure TestOps дорабатываются тест кейсы, например добавляется больше описания или json.
Переводятся соответствующие тест кейсы в статус need to automate (так же в Allure TestOps)
Создается задача в Youtrack. В ней описывается, что нужно автоматизировать. Прикладываются ссылки на тест кейсы из Allure TestOps. И назначается ответственный AQA.
Затем, задачи из Youtrack берутся в работу исходя из приоритетов. После того как изменения влиты в нужные ветки и прошли ревью, задачи закрываются, а тест кейсы в Allure переводятся в Automated со статусом Active. Ревью кода автотестов проводят разработчики.
Зачастую это происходит за несколько дней до следующего релиза, и ко дню проведения регресса, часть тест кейсов уже может быть автоматизирована.
Результаты:
Сокращение нагрузки на ручное тестирование.
Четкий и простой механизм перевода в автоматизацию. Все заняты - нет простоев.
Больше функционала покрыто автотестами, которые гоняются каждый день. Раньше обнаруживаются баги.
Backend и frontend отдельно
Автоматизация тестирования у нас разделена для backend и frontend.
Но есть E2E тесты, которые тестируют взаимодействие.
E2E (end-to-end) или сквозное тестирование — это когда тестируется вся система от начала до конца. Включает в себя обеспечение того, чтобы все интегрированные части приложения функционировали и работали вместе, как ожидалось.
Многие сквозные автотесты прогонялись со стороны мобильного тестирования, приходилось писать сложные тест кейсы. Зачастую они не проходили из-за проблем со стороны сервисов или на бэкенде.
Поработав в таком формате, мы решили, что много времени уходит на починку автотестов. И тогда E2E тесты приходится проходить вручную.
Было принято четко разделить функционал на модули с выделением логики на фронтенде и бэкенде. Оставить минимальное количество Е2Е тестов для ручного тестирования. Остальные сценарии упростить и автоматизировать. И так на бэкенде мы проверяем бизнес логику, а на клиенте корректное отображение данных от бэке и ui элементы.
Мы перестали запускать тесты на stable окружении и перевели их полностью на моки.
Это позволило нам определить области с наибольшей критичностью, сократить время ручного тестирования, сделать прогон автотестов более стабильным.
Для наглядности вот табличка:
Описание функционала | Локализация тестов |
Простая валидация полей (например при смене пароля) | клиент |
Размещение ui элементов на экране | клиент |
Отрисовка ui элементов | клиент |
Отображение информации от бэка | клиент |
Навигация по экранам | клиент |
Корректная обработка и отображение ошибок | клиент |
Сложная валидация (например проверка формата TIN) | бэк |
Сбор данных для профиля | бэк |
Сбор и обработка данных по операциям | бэк |
Создание и сохранение данных при работе с картами | бэк |
Работа сервисов | бэк |
Взаимодействие с БД | бэк |
Обработка ошибок | бэк |
Результаты
После разделения:
Стало проще локализовать проблему
Раньше определяются проблемы и соответственно решаются быстрее
Есть четкое разграничение зон ответственности. Нет лишних проверок на клиенте.
Автотесты стали гораздо стабильнее, т.к. не завязаны на сервисы, которые могут отваливаться в любой момент. (А этот любой момент обычно самый неподходящий)
Сократилось время на реализацию автотестов, не нужно добавлять json в тест кейсы дополнительно при написании
Отфильтровали тест кейсы в тест плане на регресс
Тест план на регресс формируется исходя из того, в каких блоках были внесены изменения, а также из основных постоянных сценариев проверки.
Для того, чтобы проще было формировать план, мы стали использовать теги.
Пример: Regress_Deeplink, Regress_Profile, Regress_CommonMobile
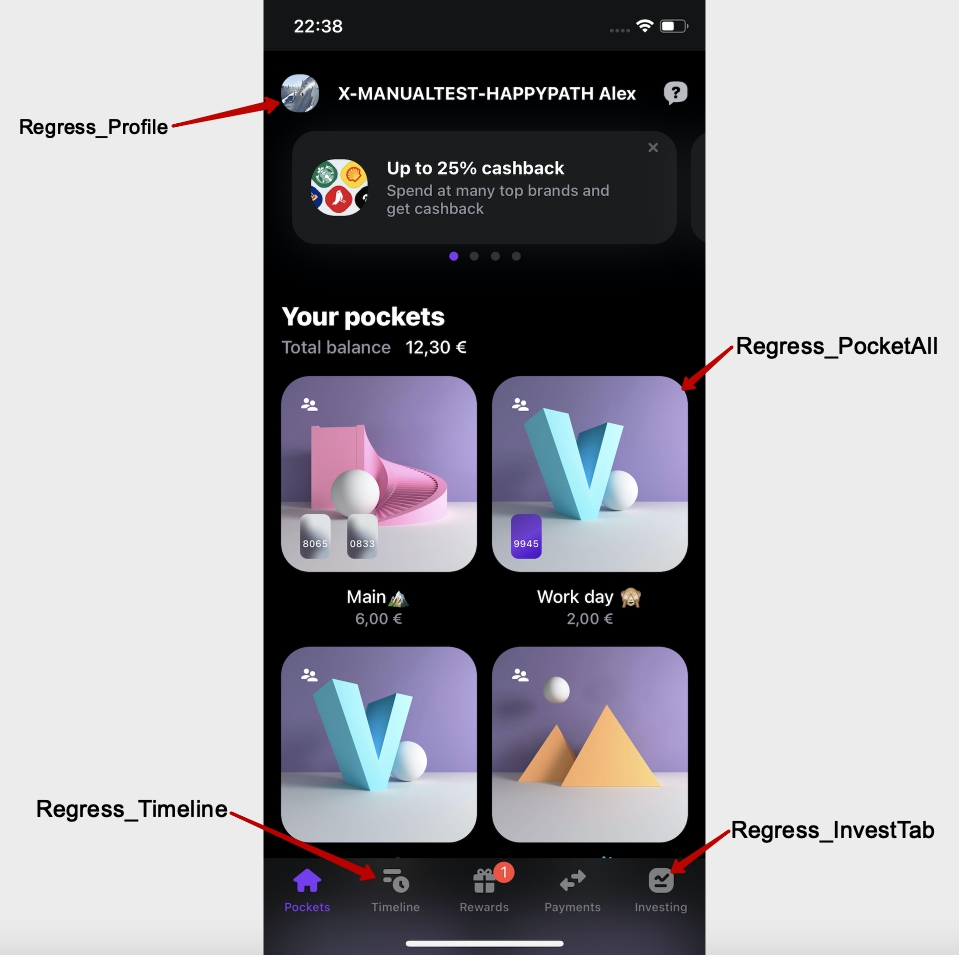
Теперь, все тест кейсы у нас поделены на блоки, которые отмечены определённым тегом! Есть также обязательные кейсы, которые входят в каждый тест план на регресс и отдельные тест кейсы для smoke-тестирования на проде.
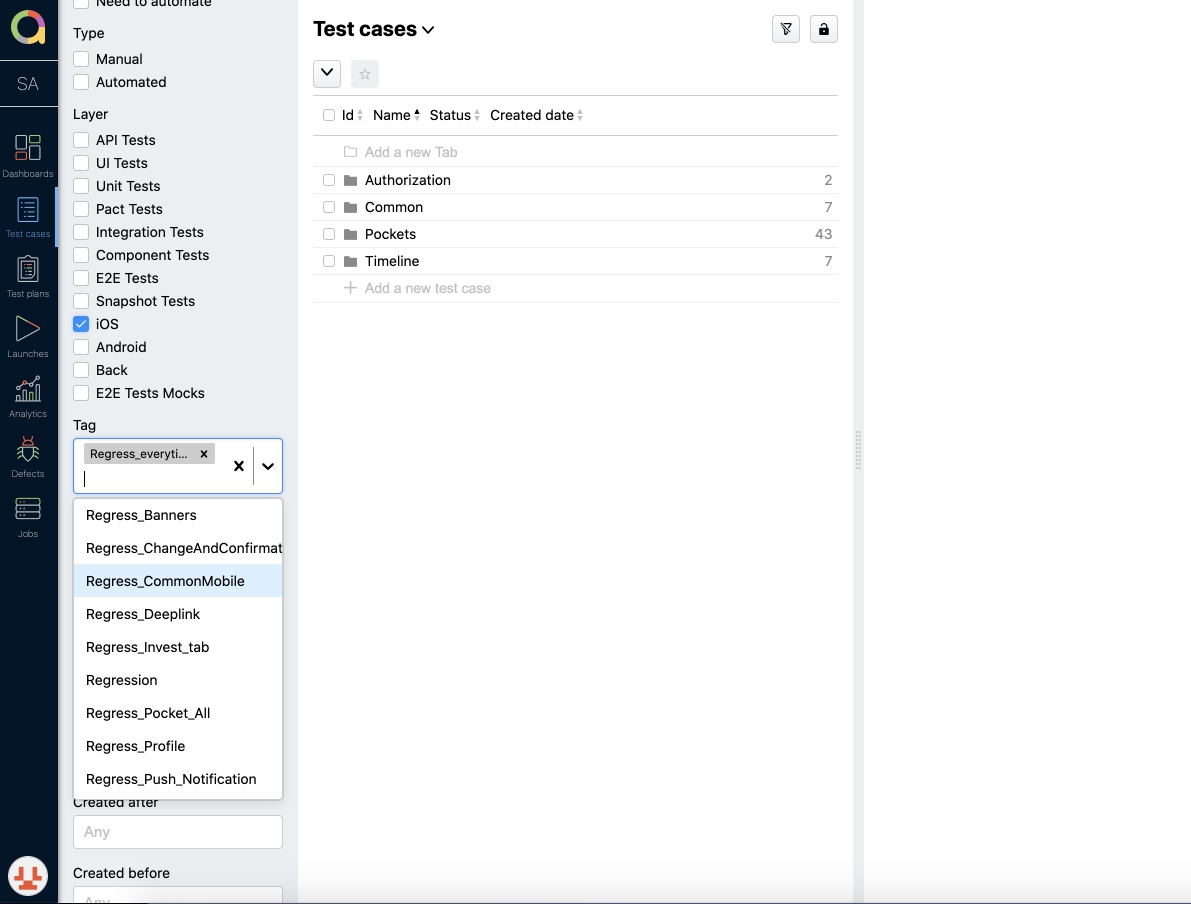
Это позволяет нам оперативно отфильтровать и быстро сформировать определённый план в соответствии с вносимыми изменениями, а не тратить время на проверку того, что не было затронуто.
Результаты
Введение дополнительного анализа, при формировании тест планов, помогло сократить общее время прохождения регрессионного тестирования всего до 2 часов с 8ми изначальных. У нас есть несколько тест планов — full и light. Обычно мы проходим light и он состоит из 98 кейсов (автотестов+ручных). Как видно на скрине, полный план регресса состоит из 297 тест кейсов!
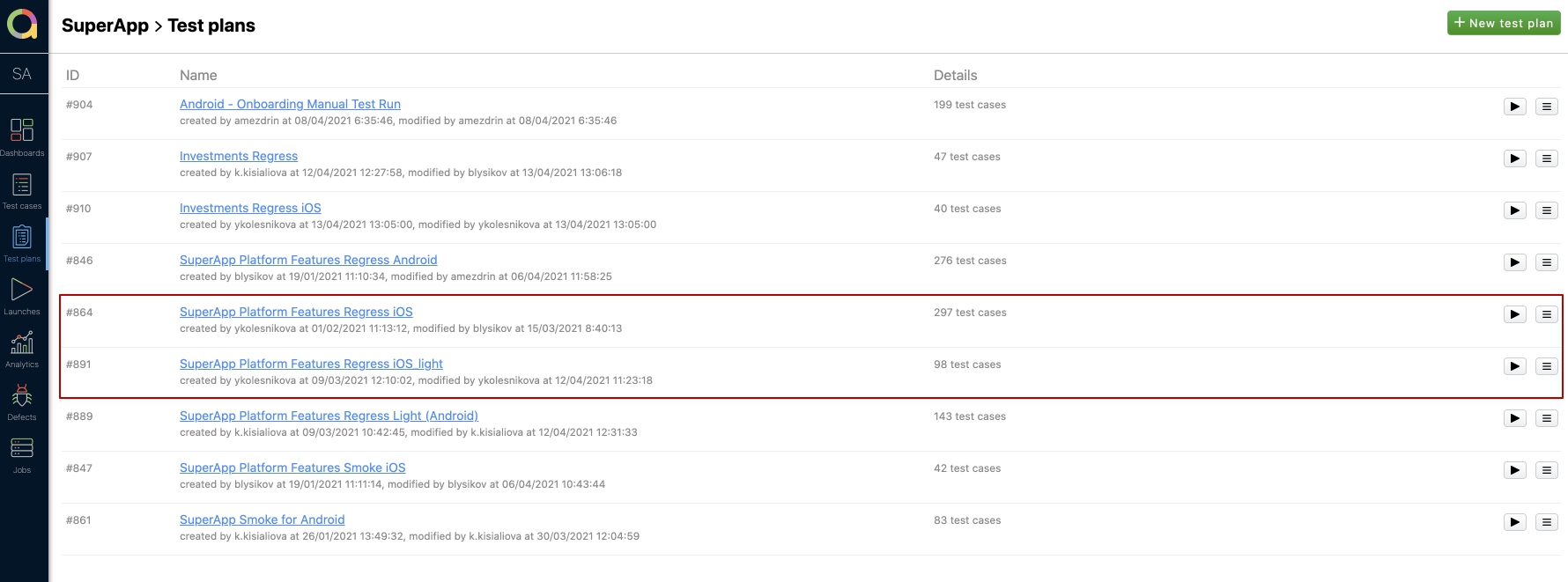
Время на прохождение Regress iOS light в среднем составляет около 2 часов, но когда изменения были только в паре модулей, то можно провести регресс и за час. Это большой плюс, потому что остается запас на багофиксы (если понадобится что-то срочно исправить). Также, в будущем, всегда есть возможность посмотреть по отчетам, в какой сборке что проверялось.
Разработали скрипт с анализом изменений и оповещением через Slack
Качество продукта полностью зависит от всех участников команды. Поэтому, чтобы точно понимать какой модуль был затронут, мы обратились к разработчикам с предложением информировать нас о том, какие изменения были внесены в выпускаемую версию.
Первое время нам приходилось напоминать, уточнять и указывать в задачах затрагиваемые блоки. С одной стороны, мы смогли облегчить регресс, выбирая только необходимые кейсы. Но с другой стороны, тратилось достаточно много времени на коммуникацию, и постоянные уточнения. Пропадала ясность, и не было полной уверенности в том, что проверяется всё необходимое.
Логически возникло следующее решение - сделать этот процесс автоматическим!
Был создан скрипт, который собирает информацию по коммитам. И далее, сформировав отчет о том, какие модули были затронуты, отправляет необходимую информацию в специальный канал Slack.
Скрипт работает просто:
После каждой сборки получает изменения между предыдущей версией приложения и коммитам, из которого собрался билд
Получает список файлов, которые отражают изменения в каком-то экране
Группирует эти изменения по фичам и командам, чтобы упростить жизнь тестировщикам
Посылаем сообщение в специальный Slack канал со всей информацией по изменениям
Результаты
Какие плюсы мы получили, подключив аналитику по сборкам:
Сократили время разработчиков на ручной анализ внесенных изменений
Снизили вероятность упустить из виду и недопроверить необходимый функционал
Упростили коммуникацию по данному вопросу
Естественно, было затрачено время на написание скрипта, и интеграцию его работы в Slack. Но, в дальнейшем, всем стало проще отслеживать вышеописанный процесс.
Коротко о главном
Использование тегов в тест кейсах и при формировании тест планов сократило объем тест плана, соответственно и время на тестирование.
Разработка и использование скрипта для оповещение об изменения дало возможность четко понимать какие модули были затронуты при разработке задач для релиза. Или при исправлении багов. Так же тестировщики перестали отвлекать разработчиков с такими вопросами.
Автоматизацией было покрыто около 46% тест кейсов, что сильно облегчило ручное тестирование. К тому же остается время на актуализацию кейсов и написание новых.
Разделение тестирования на backend и frontend помогло заранее определять локализацию проблем и своевременное исправление.



AlexNovikovAlex
Возможно в вашей ситуации это и работает, но в целом есть два замечания: 1. О том что автотесты не проходят и их надо править вы узнаете только после выпуска версии. 2. Проверять только исправленные места приведёт к тому что просто пропустите серьёзный релиз блокер из-за того, что разработчик что-то поменял в общем классе, который используется в разных частях приложения.
YuliaKolesnikova Автор
Доброго дня! :)
По замечаниям отвечу:
1. Мы запускаем лаунч для регресса релизной сборки в котором ручные тесты + автотесты. Пока проходим руками, прогоняется сборка с автотестами. После завершения прогона автотесты в статусе Failed мы просматриваем вручную. Так как мы постарались сделать их проще, то таких кейсов небольшое количество.
2. Для того чтобы не пропустить баг в важном функционале у нас есть обязательные кейсы, которые входят в каждый тест план. Мы их отметили тэгом Regress_everytime
AlexNovikovAlex
Это был не камень в ваш огород, а просто наболевшее. Что
1. чем больше автотестов, тем больше времени и сил уходит на их поддержку и нужно очень внимательно следить за их состоянием. Плюс есть гадкие изменения, когда автотесты работают неправильно после изменения, но не фейлятся. В любом случае автоматизация ускоряет процесс регрессионного тестирования, но увеличивает время на поддержку этой автоматизации.
2. Это наверное самое сложное и ответственное — решить тестирование какого функционала важное, а какое не очень. Но при этом все равно необходимо как минимум на мажорных версиях прогонять полную регрессию.
В любом случае достаточно полная и полезная статься, на мой взгляд.
YuliaKolesnikova Автор
Мне наоборот интересно читать замечания и комментарии, взгляд со стороны тоже очень полезен!
Проблемы зачастую одинаковые, а решения бывают разные.
Спасибо вам за отзыв :)