
Недавно столкнулся с проблемным запросом, который делал отбор по столбцу с типом nvarchar(max). Про производительность отборов по nvarcar(max) я уже писал, а сейчас решил сделать пост о том, как можно решить проблему, если фильтр по nvarchar(max) нужен.
В первой части я покажу что можно сделать, если на самом деле nvarchar(max) не был нужен, а хватило бы "нормальной" длины, с которой столбец можно проиндексировать. А во второй - что делать, если строка на самом деле такая длинная, что проиндексировать столбец с ней не представляется возможным.
Я не могу показать проблемный запрос в том виде, как он был, но, упрощённо, его самая проблемная часть сводилась вот к такому:
SELECT id
FROM smth
WHERE
field1 = @v1
OR field2 = @v2
OR field3 = @v3Колонка field1 была проиндексирована, а field2 и field3 мало того, что не были, так ещё и имели тип nvarchar(max). Причём, не смотря на кажущееся очень неприятным условие, эта часть всегда возвращает очень небольшое количество записей - от нуля до нескольких десятков.
Для начала, создам таблицу, с помощью которой можно воспроизвести проблему:
CREATE TABLE smth (
id int IDENTITY PRIMARY KEY,
field1 nvarchar(200),
field2 nvarchar(max),
field3 nvarchar(max),
/* добавляю столбцы, чтобы сканировать кластерный индекс не всегда было выгодно */
field4 nvarchar(max),
field5 nvarchar(max),
field6 nvarchar(max),
field7 nvarchar(max),
field8 nvarchar(max),
field9 nvarchar(max),
field0 nvarchar(max),
/* а там ещё 40 столбцов с разными типами */
);
GOРеальная таблица достаточно широкая и содержит под сотню миллионов записей, мы сделаем поменьше:
--заполним случайными данными
;WITH
n AS (
SELECT 0 n UNION ALL SELECT 0
), n1 AS (
SELECT 0 n
FROM n, n n1, n n2
), n2 AS (
SELECT 0 n
FROM n1 n, n1 n1, n1 n2
), nums AS (
SELECT 0 n /* 262144 строк */
FROM n2 n, n2 n1
)
INSERT INTO smth (field1, field2, field3, field4, field5, field6, field7, field8, field9, field0)
SELECT
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field1,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field2,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field3,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field4,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field5,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field6,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field7,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field8,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field9,
CASE WHEN RAND(CHECKSUM(NEWID())) > 0.5 THEN CAST(NEWID() AS nvarchar(200)) ELSE NULL END AS field0
FROM nums;
GO
--добавляем дубли
INSERT INTO smth (field1, field2, field3)
SELECT field1, field2, field3
FROM smth;
GO 4 -- 4194304 строк
В результате получилась таблица с 4194304 записями.
Как я уже говорил, столбец field1 проиндексирован, поэтому тоже создаю индекс, выбираю произвольные значения и выполняю запрос:
CREATE INDEX ix_ST ON smth (field1);
GO
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR field2 = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR field3 = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'
SET STATISTICS TIME, IO, XML OFF;В результате, получаю 16 строк за примерно 4 секунды процессорного времени:
(16 rows affected) Table 'smth'. Scan count 9, logical reads 84083, physical reads 0, read-ahead reads 83155, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 3937 ms ...
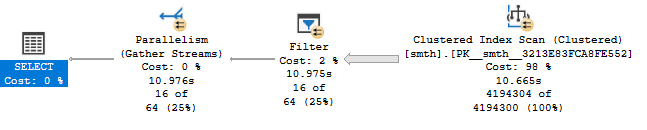
В плане запроса, как можно увидеть, просто сканирование кластерного индекса - это логично, т.к. поля field2 и field3 не входят в индекс по field1.
Первое, что приходит в голову - создать индексы по field2 и field3, но как я уже говорил, эти поля имеют типы nvarchar(max), поэтому индекс по ним создать нельзя. Но, можно включить их в существующий индекс, как include-поля. Давайте попробуем:
CREATE INDEX ix_ST ON smth (field1) INCLUDE (field2, field3) WITH (DROP_EXISTING = ON);Теперь у нас есть покрывающий индекс, в котором есть все поля, необходимые запросу. Но сильно ли он помогает? Выполнив тот же запрос, получаю:
(16 rows affected) Table 'smth'. Scan count 9, logical reads 65855, physical reads 0, read-ahead reads 64878, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 2874 ms ...

Как видно, индекс используется, но, как и ожидалось, не очень эффективно - сначала проходит его полное сканирование и затем уже применяется заданный фильтр по трём полям. Запрос, в принципе, уже выполняется быстрее, но можно ли сделать его ещё лучше?
Поскольку мы говорим о не самом удачном дизайне таблицы, то да, можно В полях field2 и field3 фактическая максимальная длина (в реальном запросе) не превышает 200 символов, поэтому было бы здорово изменить у них тип данных на более подходящий. К сожалению, я не могу менять типы данных у существующих столбцов.
Попробуем добавить вычисляемые столбцы и проиндексировать их.
ALTER TABLE smth
ADD field2_calculated AS CAST(LEFT(field2, 400) AS nvarchar(400));
ALTER TABLE smth
ADD field3_calculated AS CAST(LEFT(field3, 400) AS nvarchar(400));
CREATE INDEX ix_ON ON smth (field2_calculated);
CREATE INDEX ix_ED ON smth (field3_calculated);Теперь выполним запрос в модифицированном виде:
SET STATISTICS TIME, IO, XML ON;
SELECT id
FROM smth
WHERE
field1 = N'0FCD0182-AF6E-47E9-94F9-456F2047992C'
OR CAST(LEFT(field2, 400) AS nvarchar(400)) = N'67D1B1C6-8E11-4E7F-BDAD-EF33D8D3AF87'
OR CAST(LEFT(field3, 400) AS nvarchar(400)) = N'D75B375A-E977-4EDD-A836-7AF4967B8BFD'Ура!
(16 rows affected) Table 'smth'. Scan count 3, logical reads 14, physical reads 0, read-ahead reads 2, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms ...
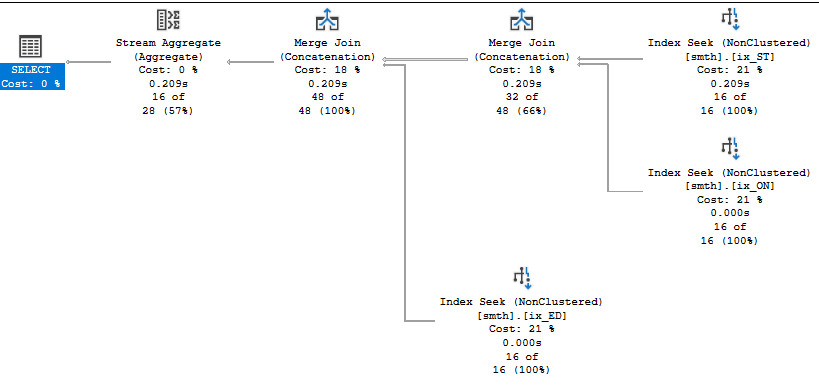
Примечание
Поскольку в field2 и field3 допустимы NULL'ы, а мы ищем по точному совпадению, имеет смысл делать фильтрованные индексы, с условием field2 IS NOT NULL и field3 IS NOT NULL (не забывая добавить их в запрос). Это вряд ли уменьшит количество чтений, но может очень сильно уменьшить размер индекса, если NULL-значений много.
А что делать, если nvarchar(max) реально нужен?
Для примера возьму таблицу dbo.Users из БД StackOverflow2013 (я использую Medium-вариант, содержащий данные с 2008 по 2013 год). В ней есть столбец AboutMe, по которому я и хочу искать.
SARGability
Напомню, что поиск всегда будет эффективным либо по полному равенству, либо по LIKE 'smth%', если использовать CHARINDEX или LIKE '%smth%', индексы вам сильно не помогут. Для эффективного использования индекса условия должны быть SARGable.
Итак, для примера посмотрим сколько будет выполняться такой запрос (я выбрал самое длинное значение поля AboutMe):
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;OPTION (RECOMPILE) я использую для того, чтобы оптимизатор лучше мог оценивать ожидаемое количество строк. Про то, как локальные переменные могут влиять на это можно прочитать здесь. А переменную использую, потому что ищу значение длиной больше 5000 символов.
Table 'Users'. Scan count 1, logical reads 44530, physical reads 0, read-ahead reads 25515, lob logical reads 106, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 828 ms
Чем в этом случае могут помочь вычисляемые столбцы? Одним из наиболее популярных решений является вычисление хэша, индексирование и сравнение хэшей:
ALTER TABLE dbo.Users
ADD AboutMeHash AS CHECKSUM(AboutMe);
CREATE INDEX ix_hash ON dbo.Users (AboutMeHash);Все мы знаем про возможные коллизии, поэтому дополнительно требуется проверка на полное совпадение:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CHECKSUM(AboutMe) = CHECKSUM(@var) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;Table 'Users'. Scan count 1, logical reads 6, physical reads 3, read-ahead reads 0, lob logical reads 8, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms
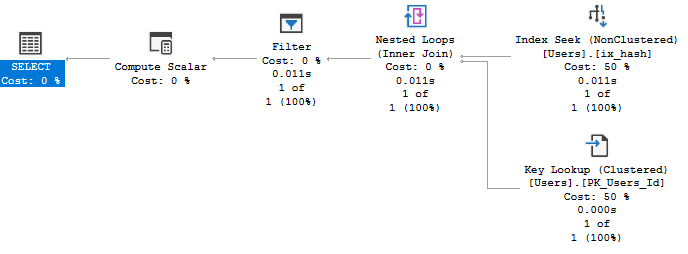
Находим полные совпадения по хэшу, дополняем полными значениями и фильтруем по ним. Успех? Успех!
Дополнительно, если мы всё-таки хотим иметь возможность поиска с помощью LIKE smth%, мы можем использовать такой способ (который может не всегда подойти, в зависимости от содержимого столбца):
ALTER TABLE dbo.Users
ADD AboutMeLeft AS CAST(LEFT(AboutMe, 800) AS nvarchar(800));
CREATE INDEX ix_lef ON dbo.Users (AboutMeLeft);Теперь первые 800 символов (у меня SQL Server 2017, где максимальная длина ключа некластерного индекса составляет 1600 байт, если у вас SQL Server старше 2016, вы ограничены 900 байтами) можно использовать как нам угодно. Либо так же, как в предыдущем случае, либо с помощью LIKE:
DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = AboutMe
FROM dbo.Users
WHERE LEN(AboutMe) = (SELECT MAX(LEN(AboutMe)) FROM dbo.Users);
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) = CAST(LEFT(@var, 800) AS nvarchar(800)) AND AboutMe = @var
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;Table 'Users'. Scan count 1, logical reads 9, physical reads 0, read-ahead reads 0, lob logical reads 12, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms

DECLARE @var AS nvarchar(max);
SELECT TOP 1 @var = LEFT(AboutMe, 10)
FROM dbo.Users
WHERE Id = 9; --случайный Id
SET STATISTICS TIME, IO, XML ON;
SELECT *
FROM dbo.Users
WHERE CAST(LEFT(AboutMe, 800) AS nvarchar(800)) LIKE @var + N'%'
OPTION (RECOMPILE);
SET STATISTICS TIME, IO, XML OFF;(317 rows affected)
Table 'Users'. Scan count 1, logical reads 1000, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times: CPU time = 0 ms

Если сама таблица достаточно "широкая" и Key Lookup'ы дороги, а доставать нужно, например, только идентификатор, то само значение может иметь смысл включать в индекс по вычисляемому полю в качестве INCLUDE-поля.
Про вычисляемые столбцы не очень часто вспоминают как о "технике оптимизации" (здесь, например, о них говорят скорее как о потенциальной "угрозе" производительности), однако, иногда они могут сильно помочь.
Комментарии (8)

gleb_l
14.09.2021 15:39Засовывать varchar(max) в included-колонки индекса - так себе практика. Индекс распухнет и перестанет быстро сканироваться (понадобится много чтений страниц даже для бинарного поиска в нем) - так как included-колонки хранятся в нем «по значению» ;). Туда хорошо ложатся компактные FK для дальнейших связок и всякие скалярные признаки, по которым может идти поиск.
Computed колонки лучше делать persisted (по ним, кстати, тогда можно тоже построить индекс и даже ПК). В Вашем случае можно сделать computed persisted-колонку LEFT(x, 200) и индекс по ней - если реально данные не длиннее 200 символов. Не забывайте ещё, что varchar(max) хранятся в куче, а в таблице - только ссылки на них - поэтому выборка для поиска может быть ещё дольше

unfilled Автор
14.09.2021 16:05+1Засовывать varchar(max) в included-колонки индекса - так себе практика.
Согласен, вроде и не утверждал обратного, хотя иногда и приходится.
Computed колонки лучше делать persisted
Можете пояснить - зачем persisted? Зачем хранить и в кластерном индексе, и в самом индексе, если они мне особо и не нужны, а только для оптимизации запроса?
computed persisted-колонку LEFT(x, 200) и индекс по ней - если реально данные не длиннее 200 символов.
Зависит от того, какая средняя длина. Я предпочитаю объявлять больше, чтобы не было спилов в tempdb, если в выборке будут слишком длинные varchar'ы.
DROP INDEX ix_ON ON smth (field2_calculated); GO ALTER TABLE smth DROP COLUMN field2_calculated; GO ALTER TABLE smth ADD field2_calculated AS LEFT(field2, 200) PERSISTED; GO CREATE INDEX ix_ON ON smth (field2_calculated); GOMsg 1919, Level 16, State 1, Line 18 Column 'field2_calculated' in table 'smth' is of a type that is invalid for use as a key column in an index.
Явно приводить тип всё равно нужно.
Не забывайте ещё, что varchar(max) хранятся в куче
зависит от реальной длины строки
gleb_l
14.09.2021 20:38+2Сорри, я прочитал статью на телефоне практически по диагонали - сейчас смотрю на компьютере и вижу, что вопросов у меня нет :)
Добавлю только, что я лично не уверен, что SQL Engine всегда будет понимать выражение с колонкой, и заменять его на computed, поэтому в своих конструкциях я полагаюсь на явное использование имени СС, при этом делаю ее PERSISTED, и если нужен индекс, включаю ее в селектор или в included. В примере с контрольной суммой CLOBа я бы сделал AboutMeHash AS BINARY_CHECKSUM(AboutMe) PERSISTED и построил бы индекс на AboutMeHash.
PS - Вы абсолютно правильно пишете про key lookup для широких таблиц - это очень затратная операция - этот факт нужно прописать болдом в мануале разработчиков - так как выборка по разреженным ключам при большой длине записи приводит к хаотичному чтению большого количества страниц, часто ради одного-двух ключей по которым таблицы связываются дальше - поэтому если в execution plan вы видите, что key lookup делается для вытаскивания компактного набора данных, и он относительно статичен (не апдейтится часто) - то добавление его в included индекса существенно ускоряет весь велосипед.

uaggster
18.09.2021 20:50Согласен, вроде и не утверждал обратного, хотя иногда и приходится.
А вот зачем приходится, не скажите? Ведь картинка будет та же - сначала будет найден ключ, а потом сервер полезет на LOB страницу. Что в лоб, что по лбу. Разве что для фильтрованных индексов имеет смысл.
Можете пояснить - зачем persisted? Зачем хранить и в кластерном индексе, и в самом индексе, если они мне особо и не нужны, а только для оптимизации запроса?
Чтобы не тратить время на пересоздание значения поля при каждом подъеме данных в память.
Впрочем, если вы построите по такому полю индекс (когда то давно это можно было делать только по persisted) - сервер всё равно материализует значение и сохранит в индексе.

jobgemws
19.09.2021 21:37+1Благодарю за интересный материал.
В своей практике часто использую вычисляемое сохраняемое поле как хэшсумма по большому полю или группы полей. На это поле навешивается индекс. В самом запросе сначала явно пишется фильтр по этому полю (равенство) и только потом фильтр уточняющий по исходным полям (равенство).
В принципе, такая идея лежит в .NET для тех ссылочных типов, когда сначала сравнивается их хэш двух объектов и если они одинаковые, то только потом сравнение идёт непосредственно по указанным полям. Так достигается лучшая производительность, чем тотально проверять сразу все поля типа на идентичность.
serber
Здесь какая то опечатка? Вы создаете вычисляемый столбец
AboutMeHashА в запросе его не используете
unfilled Автор
Я имена вычисляемых столбцов вообще нигде по тексту не использую - только их определения.
uaggster
MSSQLSERVER - умный, и в этом случае задействует индекс по вычисляемому полю.
Один из приемов ускорения запросов, в том случае, когда запрос изменить нельзя (например запрос летит из клиентского приложения, которое фиг поменяешь) - как раз и состоит в том, чтобы обнаружить подобные случаи, создать вычисляемые столбцы, аналогичные используемому выражению, и создание по ним индексов.