
Привет, меня зовут Владимир Кустиков, я — архитектор решений в e-Legion. И сегодня я хотел бы рассказать вам про микросервисы.
Наверное, я где-то неправ. А возможно, что у меня просто подгорело. Но в какой-то момент после запроса рассказать о том, в каких проектах я успешно применял микросервисы, мое терпение лопнуло. Ни в каких, понятно?! И это мой персональный повод для гордости. Если вам вдруг стало интересно, что еще может рассказать этот странный безумец с пылающим взором, то у меня есть хорошая новость — ниже о микросервисах будет адаптированный под хаброформат рассказ с картинками. А если нет — смело закрывайте эту статью.
Для начала давайте синхронизируемся насчёт понятий, которые будут обсуждаться, а потом можно приступить и к самому обсуждению. Итак, микросервисы — что в имени тебе моем?
У меня есть две книги от Сэма Ньюмена: «Проектирование микросервисов» и «От монолита к микросервисам». Они слегка нелогичны, так как вторая книга является по сути предтечей первой, хотя и выпущена сильно позже. Но особый интерес во второй книге для меня вызвали комментарии переводчика. Он ВНЕЗАПНО взял и перевел наши родненькие «микросервисы» как «микрослужбы», и по всему тексту книги ни одного упоминания о микросервисах не оставил. И наверное, моему возмущению такой отсебятиной не было бы предела, если бы он там же не объяснил свою позицию. А она крайне логична — слово «служба» несет в себе мощный семантический посыл, который оказывается утраченным при другом переводе. Так что, поразмыслив, я пришел к выводу, что этот вариант мне даже нравится больше. Действительно, легко представить себе некого служивого, который умеет нести свою службу, от и до, и ни шага в сторону (привет, контракты!). И тогда микрослужбы — это мальчики-с-пальчики, которые вроде и ростом невелики, и помощи от них немного, но при необходимости могут и Гулливера нитками к земле привязать.

Казалось бы, после такого перевода необходимость в определении микросервиса отпадает сама собой. Но есть ещё один вариант от Avery Pennarun, которым невозможно не поделиться:
Микросервисы — это самая экстремально возможная реакция на монолиты.
Но так ли плох монолит, чтобы на него требовалось реагировать, да еще и экстремально? Давайте разбираться, что там у него с порохом и пороховницами.
Внимание, вопрос на засыпку. Знаете ли вы, чем отличается монолит от микросервисов?
А если вот так?
Правда, монолит красивее? ???? Хотя о вкусах не спорят, но как минимум, на этой картинке он выглядит проще. Да, собственно, так оно и есть. Монолит в разы проще, но при этом предоставляет массу возможностей, от которых приходится отказываться, переходя на микросервисную архитектуру. Ну вот, навскидку:
Просто разрабатывать.
Не нужно думать о куче взаимосвязей — весь проект полностью у тебя перед глазами в любимой IDE. И он либо соберется и запустится — либо нет.
Легко вносить сквозные изменения.
Разработчики могут протянуть любое сквозное изменение через всю систему (UI-Application-Database), так как владеют ей полностью.
Просто тестировать.
Есть множество методик тестирования монолита, отточенных в тысячах проектов.
Просто развертывать.
Часто развертывание заключается в переносе файлов на единственный сервер.
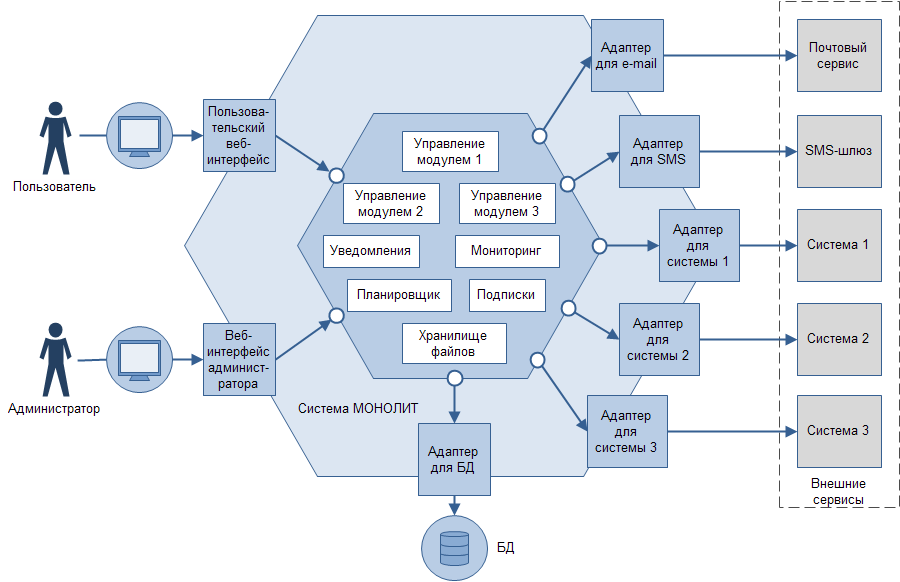
И даже нарисовать монолит бывает проще. Вот как симпатично он может выглядеть в гексагональной архитектуре.
Не подумайте, я не настолько люблю монолиты, чтобы эта любовь розовой пеленой застилала мне глаза. Вовсе нет, у монолитов есть свои недостатки, которые могут быть в определенных условиях настолько весомыми, что на них потребуется самая экстремально возможная реакция. ????
Вот эти «граждане»:
Сложно разрабатывать разнородную функциональность.
Сложно организовать работу разных команд.
Каждое изменение требует полного переразвёртывания.
Зависимость от постепенно устаревающего стека.
Зависимость от единственного физического узла.
Невозможно масштабировать функциональность отдельно.
Трудно поспорить, что это действительно критически важные недостатки. Однако большинство из них не требует радикальных реакций. Более того, на мой взгляд, большая часть проблем, возникающих на проектах, может (и должна) решаться в рамках теплых ламповых монолитов, но с небольшой щепоткой стероидов.
Посмотрите на рисунок ниже. Видите суслика? А его там и нет, так как не умеют суслики рыть норы в форме правильного куба, тем более, что это не простой куб, а самый настоящий куб масштабирования.
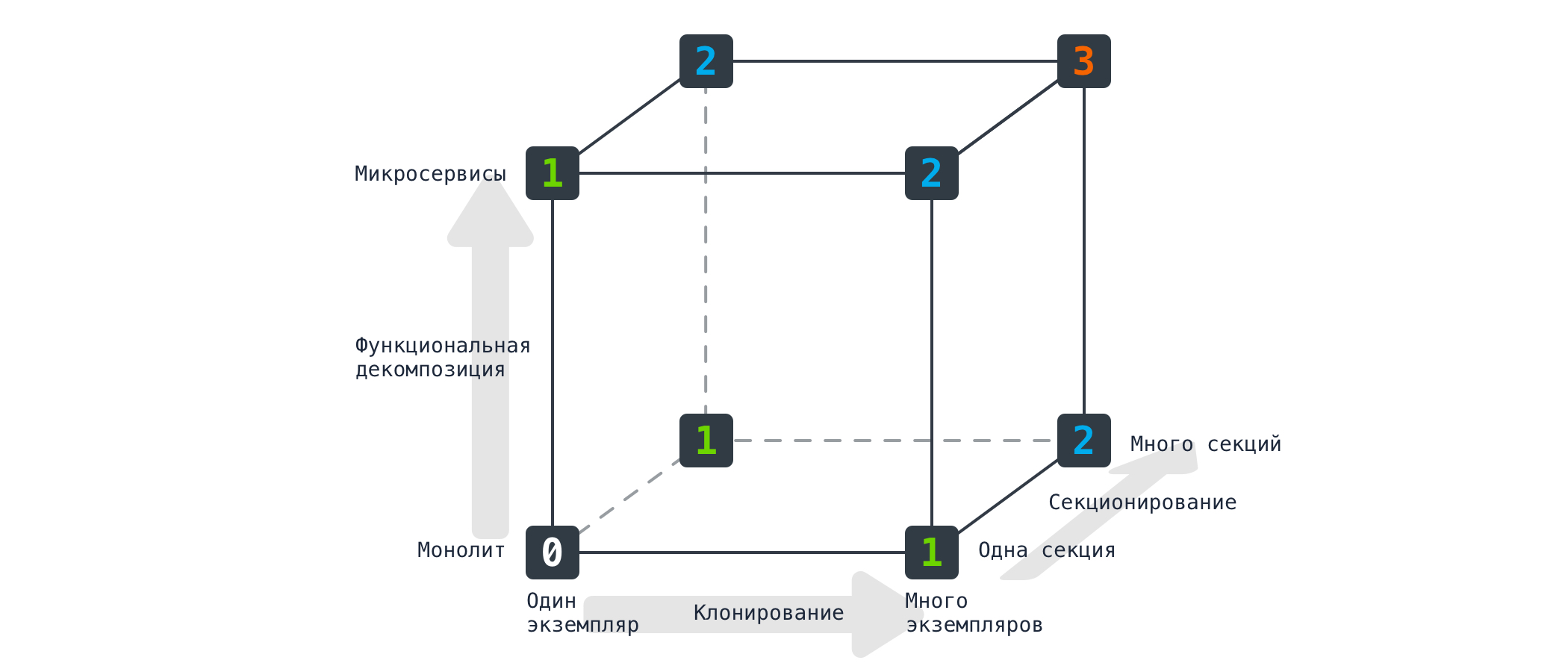
Чтобы разобраться во всем этом многобукофии и многоцифрии, предлагаю сразу обратить свое внимание на левый нижний угол куба с гордой цифрой «ноль». Этот угол — стандартное представление о монолитах — такие решения «сами в себе», запускаемые в единственном экземпляре и обрабатывающие весь поток поступающих данных. Но к счастью, жизнь монолита не обрывается в этом углу, у него есть еще целых три оси масштабирования:
Ось X — распределение нагрузки между несколькими идентичными экземплярами.
Ось Y — разделение приложения на функциональные сервисы.
Ось Z — выполнение запросов в зависимости от их атрибутов.
Нетрудно заметить, что монолит может масштабироваться по осям X и Z, не разваливаясь при этом на микросервисы, т.е. может сначала развернуться на несколько инстансов за балансировщиком нагрузки, а потом еще и распределить нагрузку по значениям атрибутов (другими словами, шардироваться). А вот если уже и это не помогает, тогда можно взглянуть и на микросервисы. Украдкой, с опаской, но взглянуть.
Прежде, чем все-таки перейти на микросервисы, ответьте на следующие вопросы:
Ваш монолит разбит на связные модули с минимальным количеством внешних взаимодействий?
Вы рассмотрели все потенциальные варианты масштабирования монолита?
Не подойдет ли для ваших задач компромиссное решение, например, модульный и/или распределенный монолит или цитадель?
Кстати, о цитаделях. На мой взгляд, это замечательный концепт с не менее замечательным названием. Если вкратце, то это монолит (сама цитадель) с вынесенной из него обособленной логикой (форпосты). При этом форпосты выполняют все те задачи, под которые обычно нанимают микросервисы. Думаю, одна картинка лучше тысячи слов.
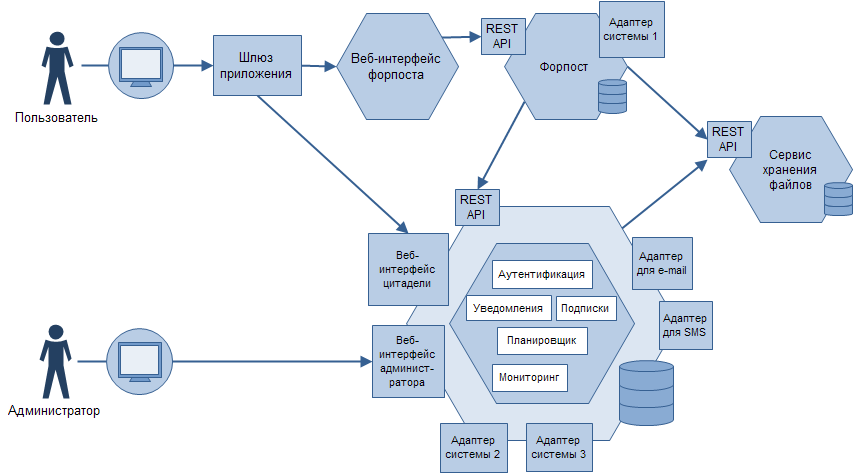
Что здесь интересного?
Смотрите, монолит практически полностью остался в первозданном виде. Но это только на первый взгляд. Предвидя новые вызовы или отвечая на уже существующие, монолит выделил из себя форпост — сервис, который должен решить те задачи, с которыми по объективным причинам цельному неповоротливому решению справиться значительно сложнее. Это могут быть проблемы неравномерности нагрузки, особенностей развертывания, особенностей технологического стека, организационных проблем — по сути тех проблем, ради решения которых и призывают «нас наш, нас новый мир построить», предварительно разрушив все до основанья.
При таком подходе в цитадели остается цельно и связно функционирующая предметная логика приложения, прикрытая от внешнего окружения форпостами, имеющими своё независимое внутреннее самоуправление. По собственному опыту могу сказать, что часто подобная архитектура решает все те проблемы, ради которых пытаются перейти на микросервисы, причем делает это наиболее естественным, простым и безопасным для разработки и бизнеса способом.
Но я подозреваю, что может возникнуть резонный вопрос — почему я всеми силами пытаюсь склонить читателей к неиспользованию микросервисов? Почему настолько категоричен в отношении виновников нашего торжества (читай, статьи)?
При всей простоте идеи микросервисы — крайне сложная вещь, которая несет с собой другие сложные вещи. Самое важное, что необходимо держать в голове следующее: микросервисные системы — это распределенные системы со всеми вытекающими последствиями. Если при прочтении предыдущего предложения ваши волосы не встали дыбом, то могу вас только поздравить. Либо с тем, что вы настолько умны (и я вам очень сильно завидую), либо с тем, что у вас впереди множество открытий чудных.
Вообще, существует несколько преимуществ перехода на микросервисы:
Делает возможными непрерывную доставку и развертывание крупных, сложных систем.
Код небольшой и простой в обслуживании.
Независимое развертывание.
Независимое масштабирование.
Автономность команд разработки.
Позволяет экспериментировать с технологиями.
Лучшая изоляция неполадок.
Но если внимательно присмотреться, то часть из них присутствует и в монолитах. Давайте уменьшим монолит в миллион раз, и что получим? Микромонолиты, раскиданные по сети, со всеми вытекающими преимуществами и проблемами.
Ну а теперь о болях:
Сложно подобрать подходящее разбиение на сервисы.
Сложность распределенных систем затрудняет разработку, тестирование и развертывание.
Развертывание функциональности, охватывающей несколько сервисов, требует тщательной координации.
Сложно определить момент, когда переход на микросервисы станет обоснованным.
Самая большая боль, как я уже сказал раньше — это то, что система переходит в класс распределенных, а там ох сколько проблем. Но как говорится, мыши плакали, кололись, но продолжали хайповать. И конечно же, неразрешимых проблем нет, при большом желании можно и JavaScript сделать серверным языком. Желание было, возможности тоже — вот и решения нашлись. Возможно, благодаря этим решениям и поддерживается технический прогресс. Так что не все то плохо, что кажется таким. И я для себя выделил некоторые проблемы и их решения, которые хоть как-то можно привязать к микросервисам, причем не всегда будут прослеживаться причинно-следственные и пространственно-временные связи, но определенная логика в этом есть. Вот, смотрите:
Автономное развертывание
o Контейнеры, Docker, Kubernetes (K8s)
Сетевые вызовы
o Сериализованные очереди, предохранители, дублирование соединений и сервисов
Координация множества сервисов
o Оркестрация, хореография, Service Mesh (istio, linkerd, envoy)
Пользовательский интерфейс
o API Gateway, фрагменты, микрофронтенды, BFF
Безопасность
o OpenID, Single Sign-On (SSO), JWT
Распределенные транзакции
o Саги, консенсус
Генерация отчетов
o Репликация, CQRS
Разные рабочие окружения
o Сервера конфигураций, решения для развертывания
o Канареечные и сине-зеленые выпуски
o DevOps-инженеры
Тестирование
o Тесты на основе запросов потребителей (CDC-тесты) вместо сквозных
Журналирование
o Сквозные идентификаторы
Ну ок, вы все-таки решились. Я сдаюсь. Микросервисы — ваше всё, и возражений не принимается. Как сделать хороший микросервис? Да практически так же, как и хороший модульный монолит. Но есть еще несколько пунктиков:
Его выделение обосновано (есть спец-команда, спец-требования, спец-ограничения, спец-циалисты).
У него сильное внутреннее сцепление и слабая внешняя связанность.
Он выполняет четко определенную функциональность.
Есть настроенное внешнее окружение и шаблон сервиса, который умеет в этом окружении жить и взаимодействовать.
Интеграции — обычно хороший вариант для микросервиса.
А у меня на этом всё, надеюсь, эта статья будет для вас полезной.
Комментарии (108)

XeaX
24.09.2021 18:18+7Пара вопросов:
Если не секрет, какого максимального масштаба продукты вы разрабатывали, сколько разработчиков/команд в них было, сколько было бизнес-доменов (см. Domain Driven Design), сколько длился самый длинный проект?
Чем "форпост" отличается от микросервиса?
oxidmod
24.09.2021 18:43Мне кажется, что «форпост» исключает асинхронное взаимодействие с монолитом.
Это просто способ один из модулей монолита написать на более подходящем языке, деплоить и масштабировать отдельно. Но за это вы заплатите сетевыми задержками и вместо вызова кода внутри процесса будете дергать его по http.

vkus
24.09.2021 18:56+5Думаю, вы все-таки спросили про проектирование, а не про разработку, поправьте, если я ошибаюсь. Тогда максимальной по объему и нагрузке была система для онлайн/оффлайн ритейлера федерального масштаба. Максимальное количество разработчиков - в районе 300, порядка 25 bounded context, говоря ubiquitous language-ом :) Этот проект ещё идет, так как пожелания ритейлеров неисчерпаемы. И модульный монолит прекрасно справляется.
Цитадель - это монолит, сумевший вовремя остановиться в процессе миграции на микросервисы :)

gecube
24.09.2021 23:57-2Думаю, вы все-таки спросили про проектирование, а не про разработку, поправьте, если я ошибаюсь. Тогда максимальной по объему и нагрузке была система для онлайн/оффлайн ритейлера федерального масштаба. Максимальное количество разработчиков - в районе 300, порядка 25 bounded context, говоря ubiquitous language-ом :) Этот проект ещё идет, так как пожелания ритейлеров неисчерпаемы. И модульный монолит прекрасно справляется.
надеюсь, не B2C? То-то я думаю, что все приложения Лента, Окей, Пятерочка так плохо работают )))))
XeaX
25.09.2021 16:26-2Интересный и масштабный опыт, моё уважение! А сколько у вас проходит от постановки задачи до появления фичи в продакшене? Как вы скейлите по нагрузке свой модульный монолит? Запускаете десяток инстансов?
Из всего выходит так, что форпост = микросервис, да еще и с микрофронтендом. И очень странно, что админ туда у вас не ходит. А то что вы решили отстрелить микросервису ногу (асинхронность) - ну такой себе "плюс".
XeaX
25.09.2021 17:46Поясню про асинхронность. У вас форпост стучиться в монолит с некоторой регулярностью и либо он должен туда стучаться, условно, очень часто, либо мы будем добавлять задержку в среднем в половину периода опроса.
vkus
25.09.2021 19:09Сейчас я уже активно не участвую в этом проекте, но тем не менее информацией поделиться могу. С момента постановки задачи до раскатки на сервера львиная доля времени уходит на все, что связано с разработкой и это время зависит много от чего. Думаю, вы не об этом хотели спросить. Насчёт масштабирования всё просто - хватило двух нижних осей, т.е. количества инстансов и количества шардов по географии.
Форпост не обязан иметь микрофронт. И следуя метафоре, которая кажется мне очень удачной, форпост нужен для сдерживания потока внешних врагов - врагов определенного вида. И ходить в цитадель он будет не часто, ввиду своей самодостаточности.
XeaX
26.09.2021 07:55Тут я ожидал ответ вида "в среднем N недель".
Можно тогда пример форпоста? Потому что если он самодостаточен и ходит к соседям не часто, то он прям совсем хороший микросервис. А в целом, откуда это название "форпост", сами придумали или это какой-то более менее сложившийся шаблон и где-то можно прочитать, чтобы вас не мучать вопросами?
vkus
26.09.2021 13:16Если в среднем, то полторы-две недели.
Корни цитадели идут отсюда https://blog.appsignal.com/2020/04/08/the-citadel-architecture-at-appsignal.html
К сожалению, название этого паттерна активно применяют только в сообществах архитекторов, так что можно считать это первой попыткой вынести его наружу в русскоязычном сообществе.
XeaX
26.09.2021 15:46Звучит волшебно, снимаю шляпу по поводу того, как у вас организован процесс, если 300 разработчиков не мешают друг другу с релизами, видимо, несколько раз в неделю.
Прочитал, спасибо. Кстати, в appsignal форпост постоянно стучится в цитадель, да еще и асинхронно через кафку. Так что вся эта история с цитаделью и форпостами - по сути про микросервисы, как бы не хотелось сделать вид, что это не они. И да, видимо вы тоже их применяете, надеюсь успешно :)
vkus
26.09.2021 17:19Здесь два момента. Первый - как я уже говорил, это из моего прошлого опыта. Второй - моей заслуги в этом мало, там была реально сильная команда тимлидов и проектных менеджеров и большое доверие от бизнеса. В общем, звезды сошлись так.
Применяем, но там, где они действительно нужны. Просто с какого-то времени это перестало быть опцией по умолчанию, продаваемой направо и налево. Ради этого пришлось сделать некоторые эмоциональные вбросы по тексту. Надеюсь, меня простят за это :)

Paskin
26.09.2021 13:37Я не автор, но на второй вопрос ответ - практически ничем. По сути, такая архитектура мало отличается от принятой у "грандов" вроде SAP - когда ядро системы, оно же "монолит" - прячется за "стенами" из CAP (client access point) и кастомных модулей, имплементирующих большую часть специфики заказчика.
В недавнем проекте - мы шли похожим путем, введя мораторий на изменения монолита - кроме добавления событий в нужные точки и выделения клиенто-независимых API. Вся клиенто-зависимая логика ушла в сравнительно легковесные микросервисы-CAP, расширения - в микросервисы-обработчики событий. Все работало, пока сменившееся руководство не решило переписать и ядро на микросервисы, убрать события/асинхронность и т.п.

Regis
24.09.2021 18:41+6Сетевые вызовы
Тут ещё такой момент, что некоторые вещи, которые относительно вполне себе нормально делаются в монолите очень трудно или почти невозможно делать в микросервисах.
Например, сделать торговый сервер (биржу) обрабатывающий в одиночку поток в 10 Gbit FIX сообщений с латентностью в пределах, скажем, 20 микросекунд — задача непростая, но осуществимая. А сделать сервер с такой же логикой на микросервисах уже просто не выйдет, так как каждый сервис в цепочке обработки будет кратно увеличивать и трафик, и латентность.
oxidmod
24.09.2021 18:51+13Тут проблема не столько в микросервисах и сетевых задержках, как в выделении границ для разбиения на микросервисы. Если для выполнения задачи ваш микросервис должен синхронно дергать другой сервис, а тот в свою очередь третий и так далее, то у вас не микросервисы, а распределенный монолит. Микросервисы должны быть самодостаточными. Для каждого конкретного микросервиса, все остальные микросервисы являются 3rd-party системами. Вы же вот не ожидаете при интеграции с 3rd-party, что они будут ходить на вашу апиху и доставать необходимую информацию, когда вы посылаете им запрос на какое-то действие? Вы всю эту информацию сами собираете и вместе с запросом отправляете. Максимум, что у вас есть — нотификация через вебхуки (аналог ивент баса по сути)
Regis
24.09.2021 19:38+6Тут проблема не столько в микросервисах и сетевых задержках, как в выделении границ для разбиения на микросервисы.
Почему же? Проблема именно в появлении сетевого слоя там, где не нужно. У меня внутри монолита вполне могут быть высокоизолированные компоненты, которые асинхронно общаются между собой через высокопроизовдительную общую шину. Каждый компонент — самодостаточен. И всё прекрасно работает в монолите за счёт того, что передача сообщения между компонентами — в пределах десятков (ли хотя бы сотен) наносекунд. А если те же компоненты превратить в микросервисы (концептуально-то они хорошо соответствуют) — вы просто не пройдёте по техническим требованиям из-за сетевых издержек.
Максимум, что у вас есть — нотификация через вебхуки (аналог ивент баса по сути)
Давайте предположу: вы из протоколов коммуникации между системами используете только JSON/Rest, а поток данных обычно ограничен парой тысяч запросов в секунду?
oxidmod
24.09.2021 20:13+2Проблема именно в появлении сетевого слоя там, где не нужно.
Это не сетевой слой где не нужно, это граница неверно проложенаДавайте предположу: вы из протоколов коммуникации между системами используете только JSON/Rest, а поток данных обычно ограничен парой тысяч запросов в секунду?
Откуда такие выводы?phtaran
24.09.2021 20:26+1Это не сетевой слой где не нужно, это граница неверно проложена
я тоже не понял вас. Если для обработки запроса нужно уложиться в 100 мс, а у вас обработка запроса проходит через 5 микросервисов, каждый из которых даёт latency пусть 30-60 мс, то как тут поможет установка границ? Лейтенси между микросервисами ненулевое же, так? И оно меньше чем лейтенси внутри одной ноды, так?
Или вы имеете в виду что переход на асинхронность решает эту проблему? Т.е. message bus или просто реактивные сервисы.
Politura
24.09.2021 20:43+7Если для обработки запроса нужно уложиться в 100 мс, а у вас обработка запроса проходит через 5 микросервисов
Скорее всего это означает, что там, где должен был быть один микросервис, у вас их 5 штук.
codefun
27.09.2021 13:55Скорее всего это означает, что там, где должен был быть один микросервис, у вас их 5 штук.
почему? Как вы это определили, не видя систему?
oxidmod
27.09.2021 15:05+2Из понятия «самодостаточность»
Микросервис должен быть самодостаточным и делать свою работу опираясь только на свои данные и данные из запросаphtaran
28.09.2021 11:48Из понятия «самодостаточность»Микросервис должен быть самодостаточным и делать свою работу опираясь только на свои данные и данные из запроса
то есть никакой микросервис не может вызывать другой микросервис?
oxidmod
28.09.2021 13:19+2В идеале. Конечно у вас есть микросервис под названием API Gateway, обязанность которого дернуть другие сервисы и собрать ответ из их ответов. Но между самими микросервисами не должно быть прямого взаимодействия.
Но это идеальная теория, а на практике у все выходят распределенные монолитыoxidmod
28.09.2021 15:11Это попытка подумать своей головой
В реальности конечно сервисы общаются друг с другом через API
Но каждый раз, когда вы хотите добавить синхронный вызов другого сервиса нужно подумать зачем вы это делаете. Каждый такой вызов увеличивает связность системы. С каждый таким вызовом вы теряете часть преимуществ микросервисов — их независимость и простоту разработки и деплоймента. Добавляете дополнительные зависимости.
oxidmod
28.09.2021 15:31Мне еще зашла вот эта статейка
dataart.com.ua/news/microservices-kak-pravil-no-delat-i-kogda-primenyat
Процитирую маленький кусочек из описания микросервисовЧто значит «сфокусированный» сервис? Это значит, что сервис решает только одну бизнес-задачу, и решает ее хорошо. Такой сервис имеет смысл в отрыве от остальных сервисов. Другими словами, вы его можете выложить в интернет, дописав security-обертку, и он будет приносить людям пользу.
Тобишь каждый сервис сам по себе маленький продукт, который может обслуживать не только вашу систему, а и внешних пользователей в отрыве от всех остальных микро-сервисов.

LynXzp
25.09.2021 18:35проходит через 5 микросервисов, каждый из которых даёт latency пусть 30-60 мс
Это Вы про сетевую задержку? Если да, то она решается переходом с сети на shared memory, и с json, на sbe. При этом задержка передачи данных становится ровно такой же как в монолите. Ну а время обработки не зависит монолит это или микросервис.
Regis
25.09.2021 00:10Откуда такие выводы?
Ну, вы почему-то сразу про "вебхуки", хотя я про веб ни слова не говорил.
oxidmod
27.09.2021 10:31+2Я говорил об интеграции с 3rd-party системами. О том, что вы передаете всю инфу вместе со своим запросом и не ожидаете, что этот 3rd-party будет опрашивать ваше API для сбора недостающей инфы. Максимум, что делает 3rd-party — нотифицирует вас о каких-то изменениях посредством вебхуков. Так вот, микросервисы друг для друга должны быть как 3rd-party. Не должно быть синхронных запросов на другие сервисы за какой-то инфой или запуском каких-то задач с синхронным же ожиданием результата. Микросервис должен быть независимым и самодостаточным. Тогда не будет этих цепочек вызовов между микросервисами, которые наращивают задержки
Regis
25.09.2021 00:12+1Это не сетевой слой где не нужно, это граница неверно проложена
Эм. А как она должна быть проложена? Вот логические сервисы, вот в монолите они общуются напрямую, а в микросервисах будет какой-то RPC. При чём тут граница? Как поможет "перенос границы" в другое место, если проблема изначально с тем, что поток данных очень "толстых", а требования по latency - очень жёсткие?

nsinreal
25.09.2021 12:25+3Чтобы выделить микросервис недостаточно логической целесообразности. Нужна ещё реальная независимость сервисов. В частности, есть правило, что микросервисы должны делиться так, чтобы не пересекать transaction boundary.
В идеале никакой сервис не должен дергать другой сервис. Если у вас после проектирования получилось так, что пайплайн запроса состоит из пяти микросервисов, то это серьёзная ошибка, имхо.
(т.е практически любая имплементация микросервисной архитектуры - неправильная, потому что мало у кого есть вообще необходимость в микросервисах, но все с ними хотят работать даже ценой боли)
phtaran
25.09.2021 12:41+2В частности, есть правило, что микросервисы должны делиться так, чтобы не пересекать transaction boundary.
В идеале никакой сервис не должен дергать другой сервис. Если у вас после проектирования получилось так, что пайплайн запроса состоит из пяти микросервисов, то это серьёзная ошибка, имхо.
занятная мысль)
но я видел немало таких длинных цепочек обработки запроса. И это не считая еще гейтвэя и может 1-2 доп. прокси. Понимаете, ваша мысль звучит вполне здраво, но те системы что я видел повсеместно нарушают это. Разве есть хоть какое-то доказательство (назовём это "закон длины цепочки для микросервисов") что любая распределенная система из микросервисов может быть спроектирована таким образом что длина цепочки обработки запроса не превышает заданного N ? Причем независимо от бизнес-логики и прочих факторов. Т.к. то что вы говорите, неявно опирается на веру в подобного рода закон.
Netflix делал всё что мог чтоб сократить задержки, например client service discavery. А взять хотя бы distributed tracing? Вряд ли он возник из необходимости трасировать цепочки из 2 запросов. А значит такая ситуация длинных цепочек возникает нередко. То что такие штуки возникли, говорит о том что ваша идея расходится с реальностью.nsinreal
25.09.2021 16:35+2Понимаете, ваша мысль звучит вполне здраво, но те системы что я видел повсеместно нарушают это
Почему так происходит:
Микросервисы пишут люди средние по рынку, а не гении. И солюшены тоже средние по рынку, а не с какими-то дикими нефункциональными ограничениями. Если солюшен с цепочкой в 5 микросервисов работает и фирма не банкротится — все будет крутиться так и дальше. Если в монолите лапша, но он тоже работает — все будет крутиться так и дальше.
Опять же, есть много хайповодов, конечно, которые не соображают, что делают. Я, когда в первые познакомился с микросервисами в их исполнении - долго ненавидел концепцию. Голову на место мне вставила книжечка по DDD+микросервисам - показала, где именно есть место микросервисам
Изначально микросервисы идут из мира огроменных солюшенов. Даже если разработчики гении, то огроменный солюшен нельзя выдержать качественным со всех точек зрения. Он обязательно будет ошибочно спроектированным, даже если на его проектирование затратили тысячи человеколет.
Разве есть хоть какое-то доказательство (назовём это "закон длины цепочки для микросервисов") что любая распределенная система из микросервисов может быть спроектирована таким образом что длина цепочки обработки запроса не превышает заданного N ? Причем независимо от бизнес-логики и прочих факторов. Т.к. то что вы говорите, неявно опирается на веру в подобного рода закон.
Нет такого доказательства. И нет, на ничего подобного я не опираюсь. Если я говорю о том, что нельзя выделять микросервис просто так, то это не значит, что его всегда можно выделить.
Вот смотрите. Есть такое правило. Надо писать код без goto. Нарушается? Нарушается! Раньше — больше. Сейчас — куда меньше, но все равно goto есть и нужен. Разве правило дурацкое? Да ни в коем случае, замечательное правило.
Пишите код без goto, делите микросервисы с учетом transaction boundary.
Netflix делал всё что мог чтоб сократить задержки, например client service discavery. А взять хотя бы distributed tracing? Вряд ли он возник из необходимости трасировать цепочки из 2 запросов. А значит такая ситуация длинных цепочек возникает нередко. То что такие штуки возникли, говорит о том что ваша идея расходится с реальностью.
Вдумайтесь только, у netflix >1000 микросервисов! Это же очень-очень-очень прилично. Distributed tracing в такой системе является необходимостью, даже если большинство цепочек из всего 1-2 микросервисов. И более того, в системе таких размеров написание distributed tracing - это просто капля в море затрат. Тем более, продукт такого уровня обязан иметь хороший годный тулинг для дебага.
Просто представьте. Вот у вас в системе один клиентский запрос, увы, обрабатывается 2-мя микросервисами последовательно (т.е. один дергает другой). Вот что-то упало во втором микросервисе. Не имея матчинга хотя-бы уровня correlation-id вы просто задолбетесь понимать из логов, что именно стало причиной падения. Даже 3-го уровня не нужно, чтобы появилась нужда в нормальном тулинге.
Так что я не думаю, что моя идея расходится с реальностью.
---
И раз уж мы говорим о солюшене типа netflix, то давайте говорить честно. Нужно сравнивать монолит размера netflix и сравнивать солюшен из микросервисов тоже размера netflix.
Если netflix внезапно переедет из микросервисов в монолит, то они не смогут выдерживать ни темпы разработки, ни требования к downtime; да и скейлится им будет тяжелее. Им будет тяжелее мерджиться, им будет тяжелее гонять тесты, им будет тяжелее деплоиться. Да и архитектура после такой миграции вообще поедет нафиг. Сэкономили на сетевых затратах, но зато получили пачку других проблем.
Netflix является и типичным, и атипичным примером. Типичным — потому что именно для таких компаний как netflix микросервисы дают огроменную выгоду. Атипичным — потому что в большинстве систем будет 10-100 микросервисов, а не 1000.

vstreltsov
27.09.2021 13:55Голову на место мне вставила книжечка по DDD+микросервисам - показала, где именно есть место микросервисам
А не подскажете, как называлась эта книжечка?
codefun
28.09.2021 12:01Голову на место мне вставила книжечка по DDD+микросервисам - показала, где именно есть место микросервисам
присоединяюсь к просьбе, что за книжечка?Вот смотрите. Есть такое правило. Надо писать код без goto. Нарушается? Нарушается! Раньше — больше. Сейчас — куда меньше, но все равно goto есть и нужен. Разве правило дурацкое? Да ни в коем случае, замечательное правило.
Так что я не думаю, что моя идея расходится с реальностью.
Netflix является и типичным, и атипичным примером. Типичным — потому что именно для таких компаний как netflix микросервисы дают огроменную выгоду. Атипичным — потому что в большинстве систем будет 10-100 микросервисов
Изначально микросервисы идут из мира огроменных солюшенов. Даже если разработчики гении, то огроменный солюшен нельзя выдержать качественным со всех точек зрения. Он обязательно будет ошибочно спроектированным, даже если на его проектирование затратили тысячи человеколет.
(цитирую разные участки чтоб собрать в кучу цепочку мыслей)
идея понятна - надо стараться делать как лучше, несмотря на плохие примеры в отрасли. Т.е. вы считаете что обычно у компаний 10-100 микросервисов, и такие ситуации когда обрабатывают запрос 5 микросервисов по цепочке - скорее всего в 99% случаев результата плохого проектирования, верно?
просто вы сами отметили, что спроектировать правильно почти никому не удаётся, потому-то и интересно - не становятся ли бест-практики для микросервисов своего рода недостижимым идеалом. У вас не было в личной практике случаев перепроектирования и скажем упрощения архитектуры с урезанием числа микросервисов?
nsinreal
28.09.2021 15:09Это была книжечка Patterns, Principles, and Practices of Domain-Driven Design
В ней вам будут интересны следующие главы:
"Chapter 6 Maintaining the Integrity of Domain Models with Bounded Contexts"
"Chapter 7 Context Mapping"
"Chapter 8 Application architecture"
"Chapter 11 Introduction to Bounded Context Integration"
"Chapter 12 Integrating via Messaging"
"Chapter 13 Integrating via HTTP with RPC and REST"
---
Ща, дальше дисклеймер и поотвечаю на вопросы. У меня не то, чтобы прям так много опыта с микросервисами. Есть кое-какая рабочая практика с хорошими и плохими примерами. Но я далеко не знаток.
идея понятна - надо стараться делать как лучше, несмотря на плохие примеры в отрасли
Тут в общем какая хрень мною была обнаружена. Если внезапно микросервисы сделаны так, что ты начинаешь их ненавидеть, то это потому что тот, кто их делал - неопытен в этом деле или даже в программировании вообще.
Это довольно частая беда для разработки ПО. Практически с каждой технологией так. Просто микросервисная архитектура больше остального требует квалификации от архитектора (или команды, если архитектора нет).
Т.е. вы считаете что обычно у компаний 10-100 микросервисов
Да. Можно считать, что микросервис - это какая-то отдельная фича. Возьмите свой проект и посчитайте, сколько там фич.
Если так трудно, то можно от обратного. Возьмите пару средних фич. Посчитайте, сколько они занимает таблиц в бд (например, три или пять таблиц на одну фичу). И поделите общее количество таблиц на количество таблиц для фичи.
и такие ситуации когда обрабатывают запрос 5 микросервисов по цепочке - скорее всего в 99% случаев результата плохого проектирования
Да, у меня такие мысли.
Такое решение (5 в цепочке) не имеет много пользы от микросервисов (а именно: независимые беклоги, устойчивость остальной системы при временном выпадении одного микросервиса etc).
Зато имеет от микросервисов кучу проблем (а именно: проблемы с транзакционностью, необходимость синкать данные, сетевые задержки, тяжелый дебаг, размазанность кода etc).
И в принципе, если у вас 5 микросервисов в цепочке, то получается, что вы поделили систему по "слоям", а не по "фичам"; да еще и с чертовски сильной связностью.
просто вы сами отметили, что спроектировать правильно почти никому не удаётся, потому-то и интересно - не становятся ли бест-практики для микросервисов своего рода недостижимым идеалом
Насколько я понял, бест-практики являются недостижимым идеалом, потому что никто о них не знает.
У вас не было в личной практике случаев перепроектирования и скажем упрощения архитектуры с урезанием числа микросервисов?
Немного было. В основном из-за очень дебильных ошибок. Было например такое, что команда почему-то решила одну сущность раскладывать в два микросервиса. Причем взаимозависимость была максимальная, все данные тупо редактировались вместе и не могли быть разъединены. Причин для этого серьезных не было, а проблем было очень много.

OlegAxenow
25.09.2021 13:20+1В целом — скорее согласен с комментарием, но есть встречные комментарии.
В частности, есть правило, что микросервисы должны делиться так, чтобы не пересекать transaction boundary.
Это стараются обходить сагами и прочими ухищрениями, то есть правило не железобетонное. Но хорошее, да — всё-таки саги — это дополнительная сложность, дополнительная сложность заставляет меня грустить (поэтому обхожусь пока без саг).
В идеале никакой сервис не должен дергать другой сервис.
Ну, это слишком уж строгое ограничение. А лучший код — тот, который не написан? И то и другое звучит красиво, но работает редко.
Скажем так, если один микросервис изредка вызывает другой — не вижу проблемы. А вот если один микросервис постоянно вызывает другой — тут уже возникают вопросы, правильно ли выбрали границы.Если у вас после проектирования получилось так, что пайплайн запроса состоит из пяти микросервисов, то это серьёзная ошибка, имхо.
Здесь согласен. Разве что, в качестве исключения могут быть инфраструктурные вызовы (положить в интеграционную шину, просигналить о необходимости отправки оповещения и т.п.). Но у всех по-разному это происходит — где-то для инфраструктуры библиотеки подключены, где-то — отдельные микросервисы.

andreyverbin
25.09.2021 01:30+1И всё прекрасно работает в монолите за счёт того, что передача сообщения между компонентами — в пределах десятков (ли хотя бы сотен) наносекунд.
Это нужно ещё постараться, чтобы внутри процесса, через шину, данные прошли за сотни наносекунд. Я бы ждал микросекунды. Ваш аргумент понятен, но что делать бирже, если регулятор требует high availability? Все известные мне биржи только от этого уже становятся распределенными, нужно хотя бы дождаться ответа от реплики.
Насколько мне известно, 20 мкс бирже не особо нужно, скорее это маркет мейкер, который за это время должен пару десятков байт в запросе поменять и отправить его назад.

fzn7
25.09.2021 08:48В прошлом году сделали, 99 перцентиль был 1.2 микросекунды 14 сервисов в цепочке, один хост, ipc шина. Считаю что можно было сделать гораздо лучше

chupasaurus
25.09.2021 14:50+2И масштабироваться такое будет исключительно вертикально.
fzn7
26.09.2021 11:58Потому-что горизонтальное масштабирование предусмотрено через логический инстансинг по символам. Хотя бы здесь не стали переусложнять
Politura
24.09.2021 19:51+11Да собственно даже тот-же Сэм Ньюмен говорит, что монолит должен быть вариантом по-умолчанию и делать микросерсисы, или переделывать монолит на них стоит только имея веские причины для этого, не знаю, упоминал он это в книге, или нет.
Кстати, на картинке со стрелочками от каждой буквы к следующей буковке не микросервисы, а распределенный монолит. :) Суть микросервисов в т.ч. и в независимости, если они сильно зависят друг от друга - что-то спроектированно не так.
И еще, с чем я не согласен, так это с тем, что монолит просто разрабатывать. Поначалу да, очень просто, красивая, логичная архитекрура и тд. Но когда он становится огромным, проблемы начинают лезть все сильнее и сильнее. Чем он огромнее, тем больше команд работают над ним, все больше надо межкомандного взаимодействия и надо либо все держать в одном монорепозитории, имея растущие проблемы связанные с этим (типа сделал пул-реквест, его проверили и отпричили, но замержить нельзя, ибо сонаркуб не закончил свою проверку, а как закончил, оказалось кто-то другой успел замержиться перед тобой, надо заново подмерживаться в свою ветку, просить опять отптичить пул-реквест, ибо он поменялся, и заново ждать, так могут целые дни проходить), либо разбиваться на разные репозитории и иметь свои проблемы связанные с этим. И вот в какой-то момент начинаешь мечтать о наборе полностью независимых сервисов, каждая команда работает над своим сервисом, или набором сервисов и с кем-то еще пересекается крайне редко.
vkus
24.09.2021 20:48+8Да по сути основной посыл статьи как раз об этом. Микросервисы не должны быть вариантом по умолчанию только потому, что это модно. Это инструмент решения определенного класса задач, причём достаточно ограниченного.
Если на картинке стрелочки расставить так, как оно обычно бывает в микросервисах, можно было бы сложить по связям много интересных слов :) поэтому я не рискнул.
Проблемы монолитов часто идут от того, что они растут из решений, которые не предполагали увеличения нагрузок. И часто такие решения разрабатывались людьми, которые не имели на тот момент нужных знаний или опыта. А как известно, исправление ошибок проектирования намного дороже исправлений кода. Вот и откладывается это на лучшие времена, а потом ищутся серебряные микросервисные пули.
gecube
25.09.2021 00:00+2А все почему?
Потому что, во-первых, надо правильно описывать архитектурно значимые требования. Например, для кейса с торговым ботом действительно очень важна низкая латентность. А вот для какого-нибудь сайта магазина - важна эластичность в зависимости от кол-ва пришедших клиентов.
Потому что нужно управлять сложностью и техдолгом. Толку от фичи, запиленной прямо сейчас, если завтра из-за нее мы сможем вносить изменения в 10 раз медленнее?
vkus
25.09.2021 01:00-2К сожалению, в нашем неидеальном для ИТ мире позиция архитектора закрывается по низшему приоритету. И это понятно - зачем бизнесу вкладываться в завтра, если непонятно, выживет ли он сегодня.
Бывают, конечно, случаи, когда разработчик внезапно проявил незаурядные таланты в проектировании - но это близкая к погрешности удача.

BugM
25.09.2021 03:32+4Подавляющая часть софта в мире спроектирована и сделана обычными разработчиками. Хорошими, но именно разработчиками.
Зря вы так превозносите архитекторов. Они в среднем бесполезны.
Бывают всякие особенности наименований. Я под разработчиком имею в виду человека который пишет код в продакшен хотя бы 3 дня в неделю.
vkus
25.09.2021 09:55Зря вы так превозносите архитекторов. Они в среднем бесполезны.
Вот не хотел я, чтобы мой комментарий так воспринимали. Видимо, не удалось правильно сформулировать.
Архитектор - по должности/лычкам и архитектор по складу ума/призванию - разные понятия. Я имею в виду именно вторых.
Ещё я хотел бы сделать акцент на том, что проектирование и разработка приложений с одной стороны, и программных систем с другой - это все-таки отличающиеся вещи, в которых полезны разные навыки. Кроме того, условные 20+ лет боевого многопроектного опыта против курсов переподготовки "вайти" могут сыграть свою роль.

Tellamonid
25.09.2021 10:11+1Присоединяюсь. Мы начали отрезать куски от монолита, когда в большой распределенной команде у этого монолита тесты проходили час. И после первых N итераций у нас стало несколько сервисов, у каждого время пробегания тестов не больше 10 минут, а чаще около пары минут.
vkus
25.09.2021 14:29+1Поделитесь своим опытом:
Как изменился у вас объём тестирования при этом? Сколько тестов вы выкинули, сколько переписали? Как вы сейчас тестируете решение целиком? Если речь о тестировании функционала в рамках своего контекста/микросервиса, что мешало запускать тесты в параллель помодульно? Если перешли на CDC подход, что мешало применять его в модульном монолите?
Tellamonid
25.09.2021 21:11Объем тестирования остался прежним. Тесты переписали, конечно. У нас был такой монолит, в котором не было dependency injection, и поднять для тестов можно было только все целиком. А в микросервисах мы всё сделали по уму, да ещё в части сервисов перешли с мавена на грейдл, что тоже дало ускорение билдов с тестами.
Помодульно запускать было можно, наверное, просто никто такое разделение не сделал.
Для решения целиком у нас есть отдельные end to end тесты, но они и с монолитом были. Ускорили мы юнит- и интеграционные тесты путем выделения его частей в микросервисы.
CDC у нас буквально несколько тестов, в основном потому что очень мало вызовов через REST, почти всё идет через мессаджинг.
Надеюсь, ответил
john_soft
04.10.2021 08:59+1Чем он огромнее, тем больше команд работают над ним, все больше надо межкомандного взаимодействия и надо либо все держать в одном монорепозитории, имея растущие проблемы связанные с этим, либо разбиваться на разные репозитории и иметь свои проблемы связанные с этим.
Думаю, это основная причина по которой следует рассмотреть переход на микросервисы. Микросервисы это скорее не про архитектуру приложения, а про управление процессом разработки разработки в больших командах разработчиков.
Но к сожалению, зачастую в компаниях выбор в сторону микросервисов, принимается, на хайпе, менеджерами высшего звена. При этом команда проекта состоит из десятка разработчиков.

akhmelev
25.09.2021 01:21+7Давайте я вам свое расскажу за монолиты. За то как я на них погорел. Люблю их до боли. А все почему?
Писал всегда только монолиты. Что пишу - то и люблю. Иначе вот не получается как-то.
Всегда практически все полностью сам от начала до конца, от кода до развертывания. Типа самоделкин. Ну или фуллстек, как нынче принято. Приятно. В этом есть смак. Костыли, не костыли - нет проблем. Пока помню свою же архитектуру - вопросов ноль. Паттерны - по желанию. Есть страшные magic-куски и phd-code, да не беда, замечательно же. Приятно даже иногда.
Жаба мое все уже лет 8-10. Но вот недолюбливаю спринги с хибером и вообще любые фреймворки. Почти всегда можно самому сделать все, что они предлагают, и обычно это легко и просто. Обычно легче. Обычно производительнее. Обычно понятнее. Обычно удобнее. Свои DI и IOС, свой пул препередстейтметов без вымывания кеша, причем не ручками а рефлесией наделанный - ну вот что может быть проще.
Ненавижу всякие улучшайзеры и облегчаторы. Ломбок - как пример. Предурацкая же вещица. Типа - скажем нет бойлерплейту, а на самом деле втихую он же именно его и генерит. Ну вот какой в том смысл - загадка. Макрос в IDE - влегкую такое умеет.
и т.д. и т.п. Могу долго ныть == выпендриваться.
-
Почему все это плохо? Да потому, в основном, что мне полсотни лет в обед погожего августовского дня было.
Я как бы не самый бестолковый, и кандидат технических, и доктор экономических, и что, я полагаю, что весьма крут и хорош? А вот ни разу. Я буду совершенно точно не у дел, и вы тоже будете точно не у дел, потому что сейчас рынку нужно другое.
Что? А вот что: круд за утро накатать, к обеду затестить, а вечером надо закрыть таску и ждать CI+CD, которые желательно, чтобы не ругнулись даже. Те кто будут этот ваш круд дергать в него никогда не заглянут. Некогда. Все в гонке.За углом на питоне модель предсказания рынка вашего стека парни в кластере катают, а за другим углом из айфонового и флаттерного миров к вам постучали мобильные разрабы, за третьим на котлине хотят стильно-модно-молодежно, за четвертым на сях переписали узкий кусок или jvm на нейтив решили заменить. Плюс если бизнес взлетает, то надо за вечер его отмасштабировать в ширину и глубину. И? Вот и все. Вот вам они - микросервисы. Вот 12-ти факторные приложения, с очередями и реактивщиной. Вот он - 21 век, прошу любить и жаловать.
А еще, вот вам и вывод: монолиты - лепота, но увы, пока-пока. К ламповым приемникам и винилу плиз.
vkus
25.09.2021 02:26+5Знаете, я где-то понимаю и даже разделяю вашу грусть. И если рынок будет диктовать своё намерение переводить свои системы на микросервисную архитектуру, у меня есть аргументы за то, чтобы хотя бы подумали об альтернативах.
Но если решение уже принято окончательно и бесповоротно - ок, этот инструмент тоже есть в моём арсенале и мой священный долг как архитектора - минимизировать возможный вред от этого решения.
BugM
25.09.2021 03:40Если рынок хочет мы ему что угодно напишем. Пока деньги платят, проблем вообще нет.
Но хочется хотя бы иногда сделать хорошо. И не городить 100500 сервисов ради типовой задачи где в обозримом будущем от них точно не будет пользы. А распределенный монолит отработает идеально. И если бизнесу интересно, то всегда с радостью. И пошардируем хорошо и балансировщиками обвесим и отказоустойчивость на высшем уровне сделаем и маштабирование горизонтальное будет и скорость работы отличную сделаем и монолит красивый напишем.
Бизнесу этого на обозримый срок хватит. А если он сможет начать в Амазон превращаться, то все переписать заново это в любом случае самый разумный подход.

saboteur_kiev
25.09.2021 13:06+1Городите 5 сервисов, а не 100500.
Распределенный монолит - это как?
BugM
25.09.2021 13:57-1Городите 5 сервисов, а не 100500.
5 это и будет нормальное разделение по функциональности. И это будет 5 монолитов по размерам.
Распределенный монолит - это как?
Шардированный, горизонтально маштабируемый, за балансером стоящий монолит. Это часто называют распределенным монолитом.

michael_v89
25.09.2021 06:46+3круд за утро накатать, к обеду затестить, а вечером надо закрыть таску и ждать CI+CD
Не знаю, что вам тут кажется необычным, но например на PHP это вполне реально, и не только для круд. Разделение на монолиты и микросервисы с этим никак не связано.

vvbob
25.09.2021 09:07+2Такое ощущение что текущий проект, на котором я работаю делали по такому-же принципу.
Чертова куча велосипедов с квадратными колесами. Может оно поначалу и было легче, понятнее и производительнее, но сейчас это адЪ разработчика, в котором до конца не разбирается уже никто, даже те кто работает давно. Какие-то простые вещи в распространенных фреймворках, вроде - добавить новую табличку, написать для нее CRUD, пробросить денные через слои к внешнему API, то что обычно делается быстро и легко, потому что тривиально, у нас приходится исполнять с кучей танцев вокруг самописных фреймворков, глючных, кривых, неудобных и с массой загадочной магии под капотом.
Как-то понадобилось кое-что набросать на нормальном современном стеке, так я просто отдыхал, все просто, быстро и легко, при этом работает ну вот совсем не хуже этой груды велосипедов (лучше так-то, причем ощутимо).
А насчет ломбока - а не пофигу что он там генерит под капотом? Главное что он реально избавляет от бойлеркода. Вместо многословной простыни с массой геттеров, сеттеров, "private final" и прочей воды, имеем небольшой, аккуратный класс в котором нет ничего лишнего, код, который приятно изучать и сопровождать.

Groramar
25.09.2021 09:47Писать под каждый ларек микросервисами исходя из того что он через какое-то время смаштабируется до пятерочки как-то мне кажется слишком. Крупные масштабирования - это уникальные, единичные случаи. Которые в обязательном порядке потребуют переписывания всего, и микросервисов тоже, даже если изначально с применением их было всё написано.

vsb
25.09.2021 16:53Я чем-то похож на вас. Тоже всё всегда писал сам. Тоже писал монолиты, т.к. не было проектов, где был бы смысл в микросервисах. Хотя по факту получались сервисы. Не микро, но сервисы. Но это уже так исторически получается. Выскажусь тоже, раз уж вас прочитал.
Мой любимый стак, к которому я в итоге пришёл:
Приложение, работающее под tomcat, т.е. не самостоятельный jar, как нынче любят.
Для простых приложений (до 10 000 строк) - никаких или минимум зависимостей (вроде guava). Логика обработки на сервлетах, работа с БД через JDBC, view на JSP.
Для не простых приложений - Spring MVC. Никакой асинхронщины. Никакого Boot. Работа с базой через MyBatis.
Миграции базы через Flyway.
Никаких докеров, тупо запускаем Tomcat на хостовой ОС.
Чем он хорош:
Он прост как два рубля. По крайней мере для того, кто в жаве давно варится. Никакой магии в нём никогда не происходит.
Он выдаёт достойную производительность.
В Tomcat есть много интересных фишек, про которые знают те, кто читал его документацию. К примеру не нужно использовать никаких пулов соединений, в Tomcat уже есть пул. Есть средства конфигурации через Context. Есть zero downtime deployment.
Чем он плох:
Если в Tomcat много приложений, по неопытности можно получить утечку памяти при редеплое. Возможно в Java 11+ уже исправили.
Не модно.
Простые вещи занимают ненулевое время. Там, где гипотетический товарищ на Spring Boot за 10 секунд парой команд добавит поле в бин и у него всё само сгенерируется и выставится в REST-интерфейсы (это я предполагаю, я точно не знаю), мне придётся писать самому миграцию, мне придётся самому дописывать поля в запросы, бины, тесты. В общем условный час.
Поначалу тоже писал свои велосипеды, потом перестал, просто пишу больше бойлерплейта на стандартых API, ну и ладно, не так уж это и страшно.
Сейчас я работаю на другой работе. Тут изначально использовалась Java через Spring Boot в докере. Также много ребят пишут на node.js. И сложилась такая ситуация, что с одной стороны их устраивает контейнерная архитектура и уходить с неё они не хотят, с другой стороны Java-разработчики поувольнялись, Java-приложения жрут довольно большие объёмы оперативной памяти, node-разработчики переписывают некоторые Java-приложения на node, получая серьёзное уменьшение потребления оперативной памяти. В общем ситуация для Java не совсем хорошая. Но мне переходить на node совсем не хочется, не люблю я её, хоть и в целом знаю (ну как знаю, я тот, кого нынче модно называть fullstack, знаю всё понемногу и знаю Java хорошо).
На монолит переходить смысла нет. Тем более, что у руководства есть желание уходить с dedicated-серверов в облако (Jelastic), т.к. это потенциально может сэкономить расходы на инфраструктуру. Т.е. стоит задача с одной стороны использовать Java, с другой стороны поумерить её аппетиты, чтобы она особо не проигрывала той же node.
Я выбрал фреймворк Helidon SE. Долго мучал Quarkus, ничего особо плохого сказать не могу, но вот не нравится он мне и всё тут, слишком эдакий, хипстерский, уж простите. А Helidon SE с одной стороны даёт мне нужные объёмы реализованного функционала, с другой стороны достаточно низкоуровневый, прям то, что мне нужно, и SQL ручками дёргать нужно, и бины маппить ручками, но всё как-то приемлемо, с современными API, с третьей стороны он вполне современный, например текущее приложение я написал на Java 16 и сейчас "мигрирую" на Java 17. Оно небольшое, но полноценное. Стартует моментально (ну по-джавовски моментально, условно говоря секунду, уж точно быстрей спринга), памяти ест приемлемо, с -Xmx6m запускается простой сервер. Ну и сам по себе он мне понравился, написан адекватно, работает как обычная библиотека, не хочет под себя подминать мой pom.xml.
Есть теоретическая возможность компилировать в native, на текущем проекте не получилось из-за одной старинной библиотеки-криптопровайдера, хотя может ещё и получится, но несколько часов я потыкался и решил отложить это дело. Но на следующих сервисах обязательно постараюсь скомпилировать в native, там точно будет не хуже node/go.
Один минус - реактивщина. Прям воротит меня от неё. И не потому, что не осилил, а просто не люблю. Очень жду Project Loom в продакшне и фреймворков на его основе. Но пока приходится с реактивщиной жить.
А вообще порой грущу - Java в теории может быть такой классной, но её так тормозят всё, что вокруг неё. maven/gradle - неповоротливые монстры, а ведь не обязательно сборка должна быть такой, можно собирать небольшие проекты за долю секунды. Только в последнее время входят легковесные фреймворки в моду (хотя и спринг когда-то считался легковесным, всё познаётся в сравнении). Хочется иногда взять отпуск года на 3, да сваять полный стек с нуля вокруг Java - и build tool, и http server без всякой асинхронщины, и data layer, без всяких ORM, чтобы компилировалось моментально, перезагружалось моментально и само, в общем как люди на PHP пишут, только со всеми плюсами Java.
andreyverbin
25.09.2021 01:37Мне не понятно отчего две копии монолита, запущенные на разных машинах, лучше, чем два микросервиса? И так и так распределённая система получается, со всеми вытекающими.
vkus
25.09.2021 02:01+1Самая большая разница в направлениях и объёмах потоков данных. Функциональная декомпозиция предполагает намного большую интенсивность взаимодействий между нодами, так как доменную логику реализуют сервисы запущенные на них. Даже с учетом выделения ограниченных контекстов.
В случае горизонтального масштабирования или шардирования монолитов ноды могут вообще не взаимодействовать явно, т.е. в вырожденном случае это будет не классическая распределенная система, а многоуровневая с некоторыми нюансами в виде балансировщика, аналитического хранилища и иже с ними.
gecube
25.09.2021 10:49В случае горизонтального масштабирования или шардирования монолитов ноды могут вообще не взаимодействовать явно, т.е. в вырожденном случае это будет не классическая распределенная система, а многоуровневая с некоторыми нюансами в виде балансировщика, аналитического хранилища и иже с ними.
и неявными требования. Потому что если этот монолит хранит внутри себя стейт - вы обрекаете себя на настройку чего-нибудь типа стики сессий на балансировщике. И количество костылей вокруг монолита при его масштабировании начинает расти в геометрической прогрессии. Мне кажется, что все через это проходили...
vkus
25.09.2021 11:59Липкие сессии - это решение для горизонтального масштабирования и применимо оно как для монолитов, так и для микросервисов. В статье картинка про куб масштабирования есть, там это отдельное измерение.
Я для себя вывел эмпирические правила - 1) масштабировать сначала по измерениям, наименее ограниченным окружением или внутренностями предметной области, и 2) не вводить новые измерения без крайней необходимости.

rdo
27.09.2021 13:54Стики сессии на балансировщике это самое простое и понятное решение, еще десять лет назад никого не удивляли кластеры на каком-нибудь Glassfish из сорока серверов, в полным server state на каком-нибудь jsf. Почему это сейчас должно стать какой-то магией?
nsinreal
25.09.2021 20:23+2
Где-то так.
andreyverbin
30.09.2021 01:58+1Топологий распределенных систем можно много придумать, от этого они не перестают быть распределенными. Все приведенные варианты отличаются в деталях, но движущая сила одна и та же - надо как-то решать проблемы синхронизации разных нод между собой.
BugM
30.09.2021 03:08+1Есть идеальный случай. Синхронизация не нужна вообще или хватает типичного общего кеша. Тот же Редис из коробки. Это покрывает процентов 95 всех апишек ко всему.
Вот когда вам перестает хватать такой синхронизации стоит крепко подумать перед тем как дробить или распределять дальше. Монолит может оказаться лучше и надежнее.
Красный флаг это общий стейт или общие транзакции между сервисами. Написать-то можно. Но это прям очень сложно и очень долго. Вероятность что получится написать правильно и это окупится для бизнеса минимальна.
nsinreal
30.09.2021 16:15Я не соглашусь. Конечно, надо как-то решать проблему. Но есть разница между использованием существующего решения и написанием своего кастомного.
Вы же не пишите свою собственную бд.


vsh797
25.09.2021 10:40+1Автономность команд разработки.
А так ли они автономны? Взаимодействие между микросервисами все равно ведь надо налаживать. Кажется, что проблема высокой связанности команд с разбиением на микросервисы не решается, а переводится в другую плоскость.
vvbob
25.09.2021 14:08+2Думаю тут скорее изолированность. Все что происходит в
Лас-Вегасемикросервисе, остается в микросервисе. С другой стороны в монолите тоже так легко можно изолировать модуль, только что там так-же легко можно эту изолированность и поломать, просто заюзав функционал в обход API модуля, что с микросервисом не получится.OlegAxenow
25.09.2021 14:15+1Плюсану. Вы очень ёмко выразили основную мысль, которую я сам хотел донести в комментарии ниже. Но у меня огромный комментарий получился из нескольких частей, прям, монолит какой-то...
vsh797
25.09.2021 15:14Мысль понятна. Но в модулях, думаю, статическим анализом можно добиться того же. Так что тут преимущество микросервисов разве что в дефолтности такого поведения.

SpiderEkb
25.09.2021 12:38А объясните мне, старому дураку, чем новомодные микросервисы отличаются от старых добрых акторов, которые еще в 70-х придумали?
Paskin
26.09.2021 13:42Да ничем. Все инструменты для реализации такого подхода были и в CORBA и в DCOM и в EJB - только называлось это по-другому и не паковалось в Docker, как заметили в параллельном комментарии.
SpiderEkb
26.09.2021 16:10Вот и у меня ощущение, что старую сову в очередной раз натягивают на новый глобус...
OlegAxenow
25.09.2021 14:11+2Если основной посыл статьи — "думайте, прежде чем использовать микросервисы" — на 100% согласен.
Disclaimer: я не сторонник "пихать микросервисы везде", я за их умеренное использование там, где они уместны. На контрасте со статьёй дальнейшие слова могут показаться "фанатскими", однако, это не так.
Лично для меня основное удобство микросервисов в том, что в статье упомянуто как "Код небольшой и простой в обслуживании". Только в нашем случае (имею в виду часть проектов моей компании) я бы добавил "относительно" к "небольшой" и "простой"...
Когда кода реально много — появляются проблемы с тем, что, как ни старайся соблюдать границы внутри монолита, появляются "клубочки". Например, когда программисту проще смешать всё в одну кучу, потому что так удобнее решить конкретную задачу. А потом, с большой вероятностью, получить неожиданные сюрпризы из-за большой связанности кода.
Мы боремся с такими проблемами тем, что делаем явные границы, вынося их в API, которое уже контролируется и версионируется. Это создаёт дополнительные накладные расходы в разработке, спору нет. Зато дисциплинирует и позволяет надеяться на то, что, если поменяли только внутренности модуля, а мажорных изменений API нет, то поведение для вызывающего кода будет тем же.
А ещё, у каждого модуля свой жизненный цикл и вносить изменения в один модуль проще (в т.ч. с точки зрения тестирования). Конечно, до тех пор, пока не приходится делать мажорные изменения — тут уже надо решать, поддерживаем ли старую версию (и сколько старых версий) или всё настолько серьёзно, что лучше обновить все зависимости сразу.
Зато внутри модулей, особенно новых и не "устоявшихся", частично может быть подход "фигак-фигак и в продакшн", но он не распространяется как раковая опухоль на всё, а решение целиком работает приемлемо.Почему я говорю про "модули" а не "микросервисы"? Потому что, строго говоря, те же самые преимущества можно получить и в рамках монолита (никто же не мешает сделать отдельные проекты и даже отдельные репозитории под модули). Но, на мой взгляд, сделать это сложнее, в основном — из-за возможности прямых вызовов.
Да, про прямые вызовы. У нас есть возможность сделать так, чтобы оба модуля были в одном процессе, но вызовы выглядят всё равно как внешние, через "прокси". И сериализацию параметров полезно оставить (чтобы, опять же, не прокрались лишние зависимости). Такой вот ".NET Remoting наоборот".
Возможно, мы какие-то нетипичные разработчики микросервисов и вообще (ужас!) — мы Docker не используем, хотя сервисы обычно распределены либо на несколько виртуалок, либо на несколько физических серверов.
В общем, из моего опыта (не буду называть что-то явно плюсом или минусом, не всё так просто):
- микросервисы заставляют тратить больше усилий на этапе проектирования;
- продуманный API — наше всё (мелкие исправления вносить несложно, а вот сильно переделывать — больно);
- некоторые "минусы" микросервисов можно обойти, когда есть возможность править (или написать свой) код, отвечающий за инфраструктуру (внешние вызовы и т.п.);
- не стоит ставить целью делать "мельчайшие" микросервисы, выше был правильный комментарий про Transaction Boundary и т.п.
P.S. "спец-циалисты" — прям хорошо!

sved
25.09.2021 15:36Мне кажется, микросервисы это такой шаг назад в те времена, когда ещё были популярны EJB.
EJB тоже же задумывались как изолированные модули, которые можно было бы развёртывать по-отдельности. Кроме того, EJB из коробки предоставляли весьма полезные фичи: проброска секьюрного и транзакционного контекстов, сериализация из коробки.
Но в итоге они ушли в небытие. Почему? Потому что поддержка зоопарка EJB, написание ненужных интерфейсов, усложнение развёртывания, проблемы с несериализуемыми объектами, обратными вызовами и повышенное потребление ресурсов сильно усложняют и удорожают разработку и тестирование.
Зачем же мы делаем этот шаг назад? Неужели история нас ничему не научила?
Я ещё не видел инженеров, которые бы ратовали за микросервисы.
Создаётся впечатление, что единственным драйвером в поддержку микросервисов является стремление занять работой "архитекторов".

Throwable
26.09.2021 21:35Затем, что концепт коммерческого сервера приложений сильно устарел, а на замену пришли коммерческие клауд платформы. С конспирологической точки зрения весь хайп вокруг микросервисов был создан исключительно, чтобы увеличить потребление бизнес приложениеми ресурсов клауда, а соответственно и стоимость. Реально микросервисная архитектура нужна лишь единицам, однако в АйТи как нигде силен культ карго...
Создаётся впечатление, что единственным драйвером в поддержку микросервисов является стремление занять работой "архитекторов".
Концепт сильно не поменялся -- так было и раньше. Стоимость разработки и поддержки растет, все заняты работой: менеджеры раздают таски, архитекторы рисуют интерфейсы, девелоперы клепают микросервисы, а
девопсерыспециалисты CI/CD поднимают стопицот тулзов и контейнеров, чтобы создать "пайплайн" -- без него никак. Все это деплоится в клауд, потребляя тонны ресурсов, и там потихоньку ворочается.
Politura
27.09.2021 07:39Не работал с EJB, но судя по пробросу транзакционного контекста из коробки они весьма связанные между собой штуки.
Мне кажется микросервисы не слишком удачно названны. Микро - как будто это что-то прям очень маленькое, вот и старается народ нарезать все на мелкие кусочки и отхватывает головную боль. На самом деле хотя-бы то, что у каждого микросервиса должна быть своя база данных и он не должен лазить в чужие говорит о том, что имеет смысл делать их довольно крупными, иначе начинает разваливаться согласованнось данных и приходится прилагать дофига усилий для ее обеспечения. Идеальная микросервисная архитектура это такая, при которой микросервисы никак не общаются друг с другом вообще (хотя на практике такое удается весьма редко). Что-то мне подсказывает, что EJB вообще не про это.

marataziat
26.09.2021 11:43Зависимость от единственного физического узла.
Архитектура не влияет на физическое расположение. Монолит точно так же можно засунуть в оркестратор как и микросервисы.
gecube
26.09.2021 18:03Монолит точно так же можно засунуть в оркестратор как и микросервисы.
можно, но придется на уровне оркестратора сделать кучу настроек, чтобы что-то не пошло не так. Простой пример - монолит не умеет в две реплики, ну, так его написали. Засунешь в оркестратор наивно - в какой-то момент времени данные могут превратиться в труху, потому что две реплики таки запустилось. Приходится донастраивать, писать всякие костыли, чтобы это хоть как-то хромало
marataziat
26.09.2021 20:43Обычно все состояние хранят в СУБД и кол-во инстансов ничего не ломает.
gecube
26.09.2021 21:14+1не совсем достоверная инфа - потому что, например, производительности не хватает, начинают обмазываться локальными кэшами и пошло-поехало. Это не то, чтобы проблема монолита как такового, но в целом - переход от одной реплики монолита к нескольким может быть больным (и я такое на практике видел).
vkus
26.09.2021 13:29+1Сегодня в Telegram-канале ИТ Архитекторов я получил разгоромный комментарий от одного из участников и с его разрешения делюсь им. На мой взгляд, это хорошо оформленная точка зрения, показывающая неоднозначность темы, и я должен ей поделиться. Далее по тексту:
Про плюсы монолита:
Простота разработки в IDE зависит от того, монорепа или нет. Сколько сервисов - пофиг, IDE все стерпит )
Аналогично, нет проблем рефакторить и множество сервисов.
А почему монолит проще тестировать? Скорее сложнее, связей внутренних обычно больше.
Если развертывание идет через копирование файлов - то у вас большие проблемы с процессами, увы. Выкладка монолита - тоже сложный процесс, с миграциями, плановым остановом (если не поддерживается выкладка без простоя) и так далее.
Минусы тоже не совсем про монолиты:
Что значит "сложно разрабатывать разнородную функциональность"? Как это выражается? Почему в монолите это сложнее?
Можно и монолит частично выкладывать, делов-то. Ну, если это нужно. Технологий для этого куча.
Можно и монолит сделать кластеризуемым, это не сложно. И масштабируемым.
Нарисованные картинки с архитектурой цитадели вызывают много вопросов (особенно про отдельный интерфейс форпостов, это обычно не очень хороший подход, особенно в данном случае, лучше уж многослойную архитектуру рисовать). Впрочем, термин цитадали неплохо вносить в массы, это плюс.
Из плюсов микросервисов
непрерывную доставку можно делать и на монолите, микросервисы тут не при чем.
автономность команд не очень зависит от микросервисов или монолитов, а скорее от процессов.
Среди минусов не названы самые главные:
Версионирование взаимодействия и вытекающие проблемы с выкладкой
Поддержка кучи разных БД
Гарантии для бизнес-транзакций между разными БД
Throwable
26.09.2021 22:31Из плюсов микросервисов
Я бы добавил:
3) API-first дизайн дает более чистую модель взаимодействия между бизнес компонентами и исключает "спагетти из вызовов", которые зачастую встречаются в монолитах. Ну по крайней мере теоретически.
Среди минусов не названы самые главные:
3) Гарантии для бизнес-транзакций между разными БД
А если учесть, что большинство коннектит свои микросервисы к одной и той же БД, напрочь теряя всякую возможность для ACID, то на мой взгляд это один из основных недостатков. Кто-то не заморачивается и тупо забивает на ACID, провоцируя неконсистентность в данных при отказе. А кто-то пытается городить велосипеды типа "сага", на смену того, что раньше решалось в две строчки, и которые к тому же не дают гарантий уровня ACID.
4) В разы более высокий расход ресурсов как для разработки, так и для продакшна. В миллионы раз более медленная скорость межкомпонентного взаимодействия.
5) Близорукость. Расхайпованный крупными техкомпаниями, продающими облачные мощности и сервисы, концепт микросервисов для многих стал своего рода культом карго и серебряной пулей для принятия решений об архитектуре системы, даже в самых явных случаях, когда микросервисная архитектура заведомо неоправданна.
DHdev
27.09.2021 13:54А можно ссылку на этот телеграм чат/канал (интересно читать обсуждения там) или это закрытое сообщество?
VKus78 Автор
27.09.2021 14:09Ничего секретного, в телеграме по поиску "Архитектура ИТ" легко находится: https://t.me/itarchitect
sved
27.09.2021 10:56+3Если абстрагироваться от микросервисы vs монолит, то я вижу только такие частые причины выделять модуль в отдельный сервис:
1) модуль написан на другом языке или использует конфликтующие библиотеки,
2) модуль используется из разных клиентов, при этом, кеширует данные из своей собственной, принадлежащей ему, базы данных,
3) модуль имеет простой чёткий API и обновляется значительно чаще чем остальное приложение
Какие проблемы микросервисы не решают:
1) упрощение тестирования. Тестирование микросервисов сложнее. Необходимость тестировать систему в сборе никто не отменял.
2) упрощение развёртывания, масштабирование и надёжность: в этом смысле монолиты ничем не отличаются от микросервисов
Кроме очевидных технических сложностей, которые нет смысла перечислять, микросервисы выявляют организационные проблемы:
1) Нет чёткого понимания, какую именно проблему решает выделение модуля как отдельный сервис
2) проектирование сервисов заранее, хотя во всех книгах пишут что всегда начинайте с монолита и только потом выделяйте сервисы, если в этом есть необходимость
catz_a
27.09.2021 13:54Хотя всё разумно и логично, но не мешало бы какую либо практическую привязку - "был монолит, перешли на микросервисы ... вернулись на монолит и живем счастливо". Либо - "начали с микросервисов - не пошло вернулись на монолит". Пускай даже случай не автора, а знакомых и пр.
VKus78 Автор
27.09.2021 15:09Таким опытом не принято делиться, потому что:
такие шатания из стороны в сторону - расходование проектного бюджета с нулевым выхлопом (если только списать что-то на обучение команды, очень дорогое обучение);
вернуться обратно к монолитному решению для многих - это как расписаться в том, что "не шмогла я", поэтому будут идти до конца. Хотя бы, чтоб потом можно выступить на какой-то конференции с горячим докладом;
это не модно
... и много чего ещё.
Из своего опыта: я видел систему, спроектированную по всем канонам микросервисного искусства. С сагами, контейнерами и хранилищем в облаках.
Но не взлетевшую.
Сейчас эта система, собранная в монолит, обрабатывает запросы пользователей на ресурсах, на порядок меньших изначальных, и командой, в разы меньшей.
Чья в этом вина? Бизнеса, неверно рассчитавшего рыночную потребность, или архитектора, сделавшего хорошее (подчеркну еще раз, хорошее) но, увы, не в этих условиях решение?
gecube
28.09.2021 10:39Чья в этом вина? Бизнеса, неверно рассчитавшего рыночную потребность, или архитектора, сделавшего хорошее (подчеркну еще раз, хорошее) но, увы, не в этих условиях решение?
обоих. Мы же прекрасно знаем, что garbage in - garbage out
mathslove
27.09.2021 13:54Я бы ещё отзывы самих разработчиков послушал, а не теоретику
VKus78 Автор
27.09.2021 14:25Тогда получилась бы другая статья. Мне уже здесь прилетело за "неструктурированность, непонятный посыл и отсутствие практических выводов". Добавьте сюда проектную практику с примерами, отзывы сейлзов, мнения стейкхолдеров и тестировщиков - и получится такая каша, которая как бы для всех, но в реальности для никого. Хотя все вроде бы и по теме.
Так что пусть это будет в другой статье: моей, вашей или чьей-нибудь еще.
no_future
27.09.2021 13:54Разбиение монолита на микросервисы это то же самое, что и разбиение кода на функции. Или функций на классы. Или классов на модули. Суть одна и та же — разбить сложное на более простые части, чтобы их можно было изучать, понимать и разрабатывать независимо.
Остальное детали — как разбивать, какие при этом появляются проблемы и как их решать.

aanovik42
27.09.2021 13:54Оставлю комментарий на правах новичка, изучающего Java и сопутствующие фреймворки.
Перед началом обучения я переговорил с несколькими знакомыми разработчиками - причём, они работают с разными стеками. И все как один говорили, что стоит получить хотя бы базовое понимание микросервисной архитектуры, потому что мне наверняка придётся иметь с ней дело.
И чем больше я погружаюсь в эту тему, тем хуже я понимаю, почему на хабре регулярно выходят вот такие статьи. Для новичка микросервисы выглядят настоящей магией, которая серьёзно упрощает понимание происходящего. Даже простейшие учебные приложения гораздо приятнее писать на микросервисах, а не в виде монолита.
Пока что мне удалось придумать только одну ситуацию, в которой микросервисы могут быть вредны - брутальное создание MVP на коленке. Нет времени планировать архитектуру, нужно дёшево и быстро выкатить в прод хоть что-то работоспособное.
В остальных случаях - ну не понимаю я, чем так плохи микросервисы. И данная статья в очередной раз отвечает на вопрос "почему я использую монолит (резюме: потому что привык)". При этом тема "когда и почему есть смысл отказаться от микросервисов" раскрыта очень слабо и неубедительно. Если у кого-то есть более конкретное видение и примеры, буду признателен за комментарий.
oxidmod
27.09.2021 15:08+4В том то и дело, что на простых учебных проектах все выглядит очень сладко. Но вот распределенные транзакции, саги, трудноуловимые баги, вызванные асинхроном и eventual consistency в реальном мире приносят много боли
nsinreal
28.09.2021 15:17Потому что приходишь ты на проект, а там дяди гоняют файл в сто мегабайт между двумя микросервисами раз пять за запрос.
В целом потому что тема очень сложная, а практика применения не очень хорошо наработанная.
Можно рассматривать сейчас топик "микросервисы vs монолит" как "c++ vs java". Примерно такая же байда. Или есть риск ногу отсрелить, или некоторые задачи будут решаться хуже.

AlexunKo
22.11.2021 03:30Если коротко - проблема в том что между вызовами методов появляется сеть. Это добавляет сложность разработки и поддержки, которые неоправданно растут (не окупаются со временем).
codefun
28.09.2021 12:05вопрос к знатокам, может кто в теме: вроде как классическим стэком для микросервисов длительное время был стэк Netflix (по большей части это java и Spring). Но в последние годы всё больше двигаются в сторону Kubernetes. Как считаете, лучше ли Kubernetes? Что насчет service mesh?
oxidmod
28.09.2021 13:20Какая связь между java + Spring и Kubernetes?
codefun
28.09.2021 13:35Какая связь между java + Spring и Kubernetes?
речь не о Spring+java, а о стэке Netflix для микросервисов, который (так уж совпало) базируется в основном на Spring.
Я читал вот тут, https://en.wikipedia.org/wiki/Microservices (см раздел A comparison of platforms) в связи с чем и возник вопрос
teemour
для большого мира монолит это микросервис