
За последнее десятилетие удалось добиться значительного прогресса в области автоматического аннотирования изображений — задачи, в которой компьютерный алгоритм создает письменные описания изображений. Значительный прогресс достигнут благодаря использованию современных методов глубокого обучения, разработанных как для задач компьютерного зрения, так и для обработки естественного языка, в сочетании с большими наборами данных, которые объединяют изображения и описания, созданные людьми. Помимо поддержания таких важных практических приложений, как предоставление описаний изображений для людей со слабым зрением, эти наборы данных также позволяют работать над интересными исследовательскими вопросами, касающимися интеграции языковых и визуальных средств в качестве входных данных модели. Например, изучение глубокого представления такого слова, как «автомобиль», означает использование как лингвистического, так и визуального контекстов.
Наборы данных аннотированных изображений, содержащие пары текстовых описаний и соответствующих им изображений, такие как MS-COCO и Flickr30k, широко используются для изучения совместных визуальных и текстовых представлений, а также для построения моделей создания описаний изображений. К сожалению, эти наборы данных имеют ограниченные кросс-модальные соответствия: изображения не сопоставляются с другими изображениями, описания сопоставляются только с другими описаниями того же изображения (также называемыми совместными описаниями), есть пары изображение-описание, которые совпадают, но не помечены как совпадение, и нет меток, указывающих, когда пара изображение-описание не совпадает. Это подрывает исследования того, как интермодальное обучение (например, соединение описаний и изображений) влияет на интрамодальные задачи (соединение описаний с описаниями или изображений с изображениями). Это особенно важно потому, что значительный объем работы по изучению изображений в сочетании с текстом мотивируется аргументами о том, что визуальные элементы должны привносить дополнительную информацию и улучшать языковое представление.
Чтобы восполнить этот пробел, авторы представили статью «Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO», опубликованную на EACL 2021. Набор данных с перекрестными описаниями (Crisscrossed Captions, CxC) расширяет тестовые и валидационные поднаборы MS-COCO, добавляя оценки семантического сходства для пар изображение-текст, текст-текст и изображение-изображение. Критерии оценок основаны на семантическом сходстве текстов (Semantic Textual Similarity), существующем и широко принятом показателе семантического родства между парами коротких текстов, который авторы применили также к изображениям. В целом, CxC содержит полученные человеком оценки семантического сходства для 267095 пар (полученных из 1335475 независимых оценок), что является значительным расширением по масштабу и детализации по сравнению с исходными 50 тысячами пар валидационного и тестового поднаборов MS-COCO. Авторы выложили CxC оценки сходства вместе с кодом для объединения CxC с существующими данными MS-COCO. Таким образом, любой, кто знаком с MS-COCO, может легко улучшить свои эксперименты с CxC.
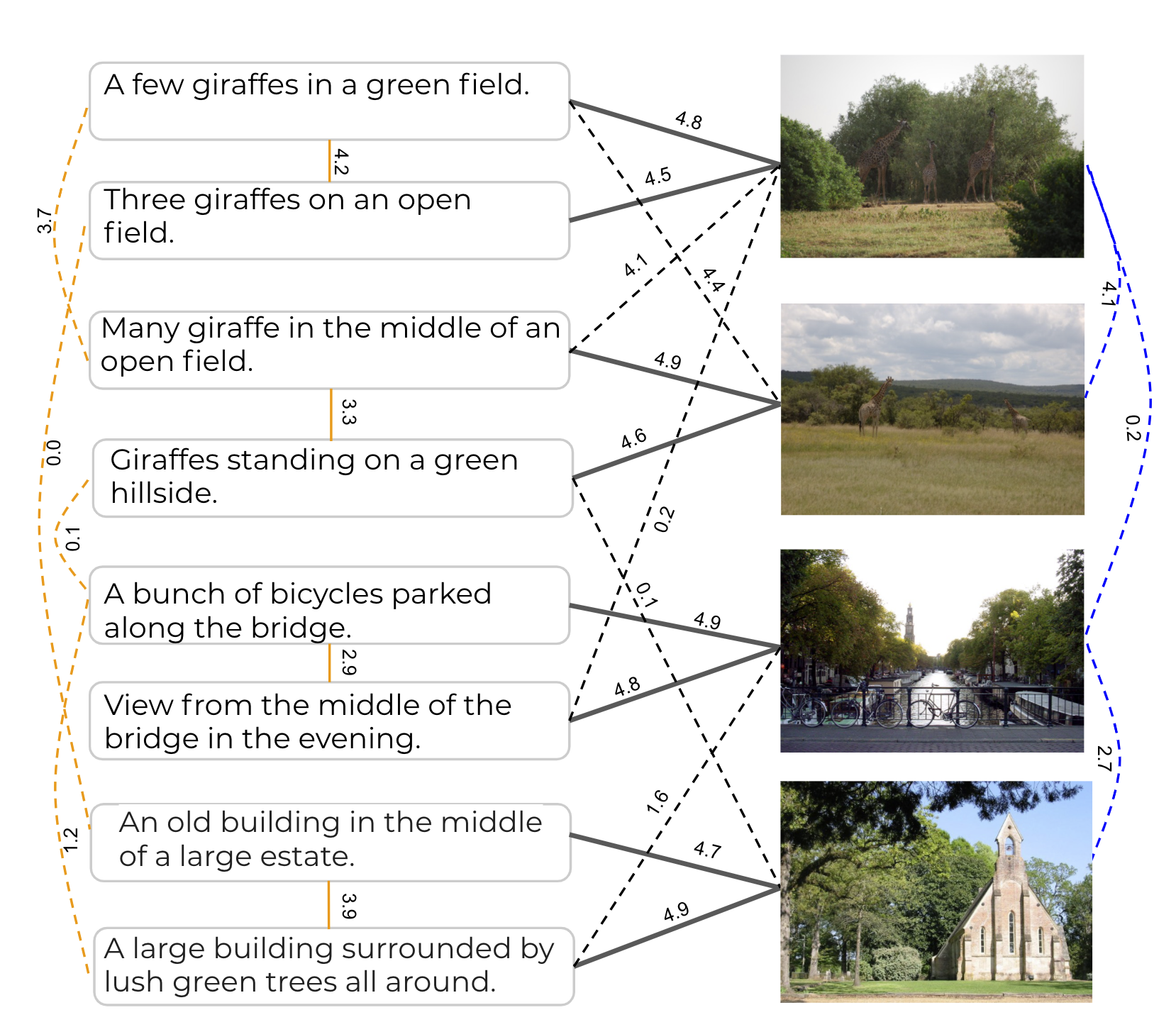
Набор данных CxC расширяет тестовые поднаборы из MS-COCO, добавляя полученные человеком оценки семантического сходства для существующих пар изображение-описание и совместных описаний (сплошные линии), а также увеличивает плотность оценок, добавляя человеческие оценки для новых пар изображение-описание, описание-описание и изображение-изображение (пунктирные линии).
Создание набора данных CxC
«Одна картинка стоит тысячу слов», — эта знаменитая фраза, вероятно, указывает на то множество деталей и их взаимосвязей, которые обычно можно найти на изображениях. Мы можем описать текстуру меха у собаки, назвать логотип на фрисби, за которым она гонится, подметить выражение лица человека, который только что бросил фрисби, или заметить лист ярко-красного цвета, висящий на дереве над головой человека, и так далее.
Набор данных CxC расширяет тестовые поднаборы MS-COCO с помощью дополнительной разметки оценок семантического сходства пар соответствий внутри и между модальностями. MS-COCO имеет пять описаний для каждого изображения, разделенных на поднаборы для обучения (размером 410 тыс. описаний — 82 тыс. изображений), для валидации (25 тыс. описаний – 5 тыс. изображений) и тестирования (25 тыс. описаний – 5 тыс. изображений). Идеальным расширением набора данных было бы оценить каждую пару в нем (описание-описание, изображение-изображение и изображение-описание), но это невозможно, так как для этого потребовалось бы получить ручную разметку для миллиардов пар.
Учитывая, что случайно выбранные пары изображений и описаний, вероятно, будут отличаться друг от друга, авторы придумали способ выбора элементов для человеческой разметки, чтобы она включала по крайней мере несколько новых пар с высоким ожидаемым сходством. С целью уменьшить зависимость выбранных пар от моделей, используемых для их поиска, авторы ввели схему косвенной выборки (изображенную ниже), в которой они кодируют изображения и текстовые описания, используя разные методы кодирования, и вычисляют сходство между парами одинаковых элементов модальности, составляя таким образом матрицы сходства. Изображения кодируются с использованием эмбеддингов Graph-RISE, а описания кодируются двумя методами: Universal Sentence Encoder (USE) и усреднением мешка слов (bag-of-words, BoW) на основе эмбеддингов GloVe. Поскольку каждый пример MS-COCO имеет пять совместных описаний, авторы усреднили их эмбеддинги для создания одного представления для каждого примера, что позволяет гарантировать, что все пары описаний могут быть сопоставлены с парами изображений (подробнее о том, как авторы выбирали интермодальные пары, ниже).

Сверху: матрица сходства текста (каждая ячейка соответствует оценке сходства)
построена с использованием усредненных эмбеддингов совместных описаний, поэтому каждая текстовая запись соответствует одному изображению, в результате чего получается матрица 5000x5000. Использовались два разных метода кодирования текста, но для простоты показана только одна матрица сходства текста. Снизу: матрица оценок сходства изображений для каждого изображения в наборе данных, в результате получается матрица 5000x5000.
Следующим шагом алгоритма косвенной выборки является использование вычисленных оценок сходства изображений для получения смещенной выборки пар описаний для ручной разметки (и наоборот). Например, выберем два описания с высоким сходством из матрицы оценок сходства текстов, затем возьмем каждое из их парных изображений, в результате чего получается новая пара изображений, которые отличаются по внешнему виду, но похожи по тому, что они изображают, на основе их описаний. Например, для описаний «Собака застенчиво смотрит в сторону» и «Черная собака поднимает голову в сторону, чтобы насладиться ветерком» модель покажет достаточно высокое сходство, поэтому соответствующие изображения двух собак на рисунке ниже могут быть выбраны для оценки схожести изображений. Этот этап также можно начать и с двух изображений с высоким вычисленным сходством, чтобы получить новую пару описаний. Таким образом, авторы опосредованно отобрали новые интрамодальные пары — и, по крайней мере, некоторые из них очень похожи — для которых они получили ручную разметку.
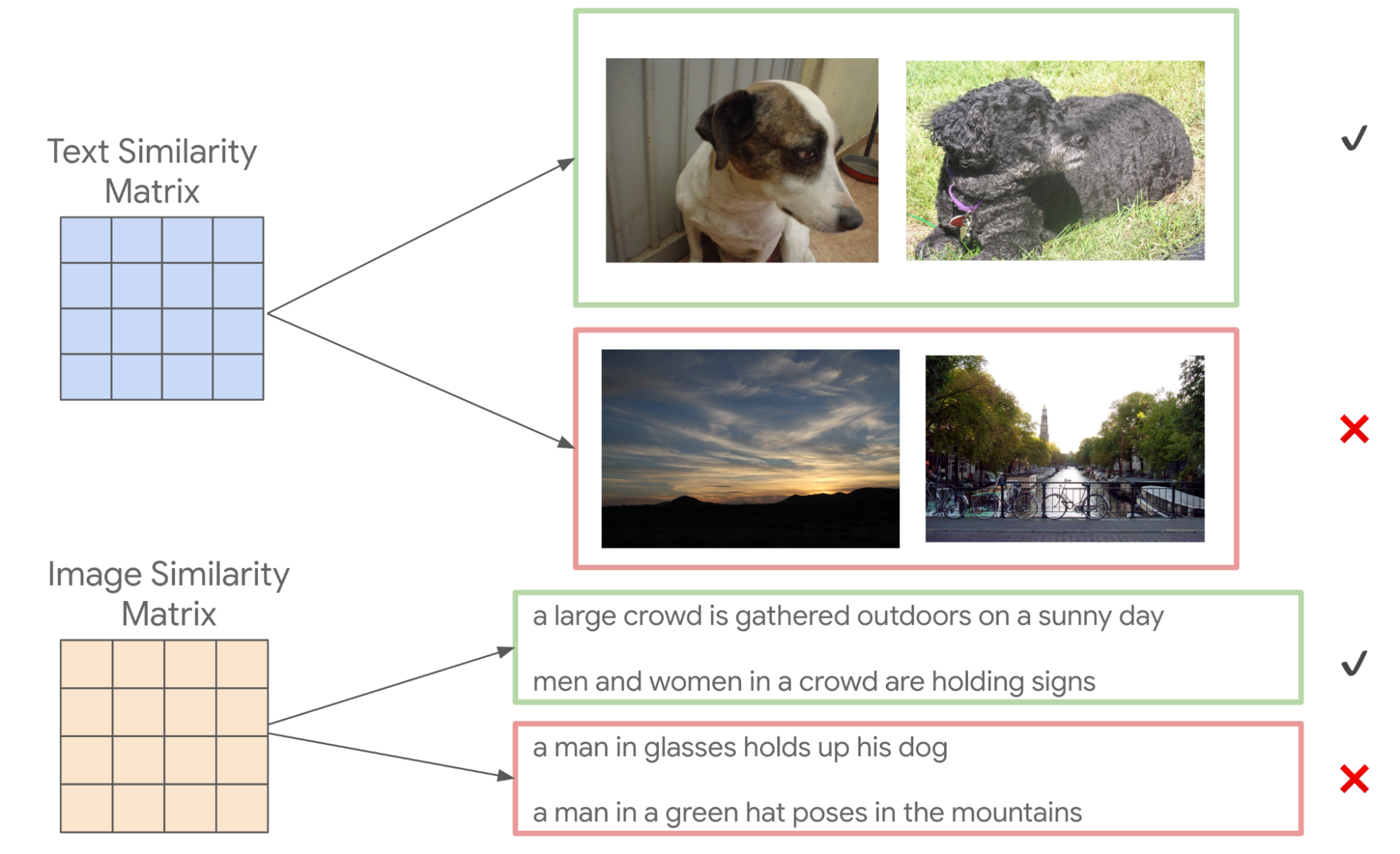
Сверху: пары изображений выбираются на основе вычисленного сходства описаний. Снизу: пары описаний выбираются на основе вычисленного сходства изображений, которые они описывают.
Наконец, авторы используют эти новые интрамодальные пары и оценки их сходства, размеченные вручную, чтобы выбрать новые интермодальные пары для ручной разметки. Авторы используют существующие пары изображение-описание для связи между модальностями. Например, если пара описаний ij была оценена людьми как очень похожие, выбираем изображение из примера i и описание из примера j, чтобы получить новую интермодальную пару для ручной разметки. И снова используются интрамодальные пары с наивысшей оценкой сходства для выборки, потому что они включают, по крайней мере, некоторое количество новых очень похожих пар. Наконец, в набор данных добавляется ручная разметка оценок сходства для всех существующих интермодальных пар и большой выборки совместных описаний.
В следующей таблице приведены примеры пар семантического сходства изображения (semantic image similarity, SIS) и семантического сходства изображения-текста (semantic image-text similarity, SITS), соответствующих значению сходства, где 5 указывает на наиболее похожие пары, а 0 — полностью несхожие.






Примеры для каждой полученной человеком оценки сходства (слева: значение оценки сходства от 5 до 0, где 5 — очень похожи и 0 — совершенно не похожи) пар изображений на основе задач SIS (в центре) и SITS (справа). Стоит отметить, что эти примеры предназначены для иллюстративных целей и не входят в набор данных CxC.
Результаты
MS-COCO поддерживает три задачи извлечения:
- Для данного изображения найти соответствующие описания среди всех других описаний в тестовом наборе.
- Для данного описания найти соответствующее изображение среди всех других изображений в тестовом наборе.
- Для данного описания найти другие его совместные описания среди всех других описаний в тестовом наборе.
Пары MS-COCO неполные, потому что описания, созданные для одного изображения, иногда одинаково хорошо применимы и к другому, но эти соответствия не фиксируются в наборе данных. CxC расширяет эти существующие задачи извлечения новыми положительными парами, а также поддерживает новую задачу извлечения изображения-изображения. Благодаря своим оценкам сходства, CxC также позволяет измерять корреляции между значениями сходства, полученными моделью и вручную. Метрики для задачи извлечения в основном сосредоточены только на положительных парах, в то время как показатели корреляции CxC дополнительно учитывают относительный порядок схожих элементов, а также включают элементы с низкой оценкой (несоответствия). Поддержка таких оценок на общем наборе изображений и описаний делает их более ценными для понимания интермодального обучения по сравнению с несвязанными наборами соответствий описание-изображение, описание-описание и изображение-изображение.
Авторы провели серию экспериментов, чтобы показать полезность рейтингов CxC. Для этого они построили три модели двойного энкодера (dual encoder, DE), используя BERT-base в качестве текстового энкодера и EfficientNet-B4 в качестве энкодера изображений:
- Модель текст-текст (DE_T2T), в которой для обеих сторон используется общий текстовый энкодер.
- Модель изображение-текст (DE_I2T), которая использует вышеупомянутые энкодеры текста и изображения и включает в себя один слой поверх текстового энкодера текста, приводящий в соответствие выход последнего выходным данным энкодера изображения.
- Мультизадачная модель (DE_I2T+T2T), обученная на взвешенной комбинации задач текст-текст и изображение-текст.

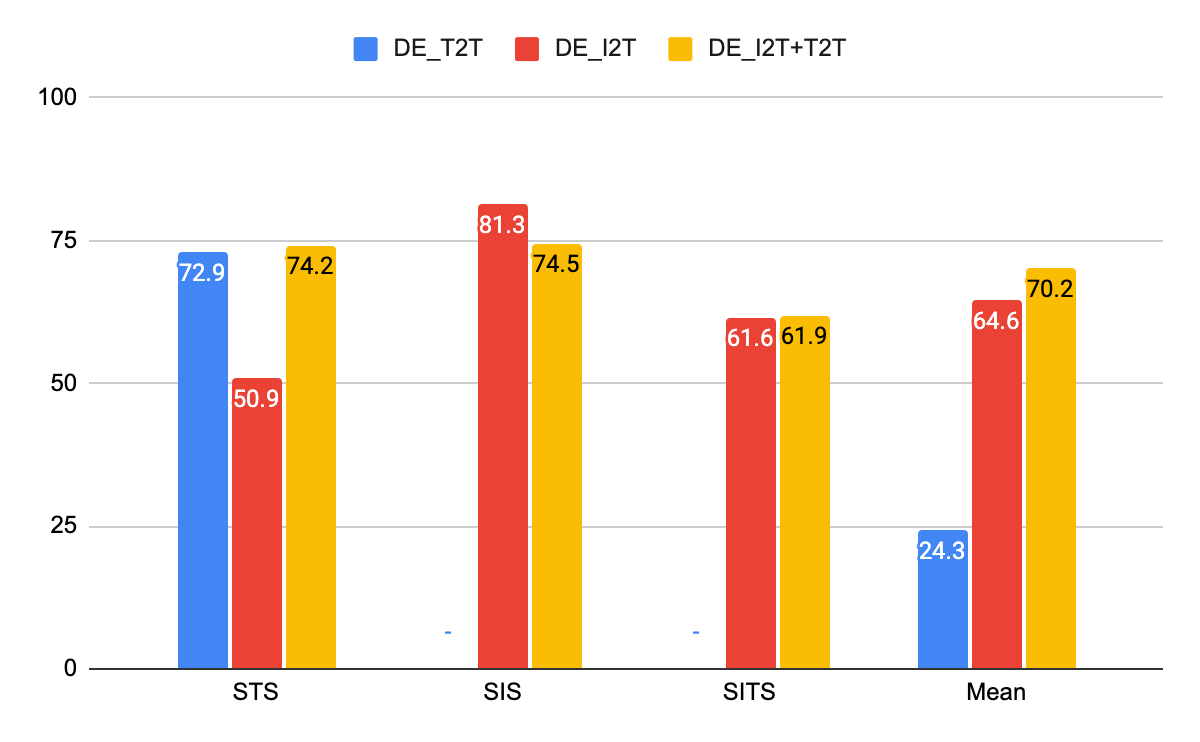
Результаты на задаче извлечений CxC — сравнение моделей двойного энкодера текст-текст (T2T), изображение-текст (I2T) и мультизадачной модели (I2T+T2T) для всех четырех задач извлечений.
Из полученных результатов видно, что DE_I2T+T2T (желтый столбец) работает лучше, чем DE_I2T (красный столбец) в задачах извлечения пар изображение-текст и текст-изображение. Таким образом, добавление интрамодальной (текст-текст) обучающей задачи помогло улучшить результаты для интермодальных задач (изображение-текст, текст-изображение). Что касается двух других интрамодальных задач (текст-текст и изображение-изображение), DE_I2T+T2T демонстрирует хорошие стабильные результаты на них обеих.
Результаты корреляции CxC для моделей, показанных выше.
Для задач корреляции DE_I2T показывает лучшие результаты на SIS, а DE_I2T+T2T лучше всех справилась в целом со всеми задачами. Оценки корреляции также показывают, что DE_I2T хорошо работает только с изображениями: у него самый высокий SIS, но гораздо худший STS. Добавление функции потери на парах текст-текст к обучению DE_I2T (DE_I2T+T2T) дает более стабильные общие результаты.
Набор данных CxC обеспечивает гораздо более полный набор взаимосвязей между изображениями и описаниями, чем необработанные пары изображение-описание MS-COCO. Опубликованы новые оценки сходства, подробности о которых можно найти в статье. Авторы надеются побудить исследовательское сообщество разрабатывать новые модели, превосходящие результаты, представленных CxC, на основе совместного обучения интер- и интрамодальным представлениям.
Авторы
- Автор оригинала – Zarana Parekh, Jason Baldridge
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей