
Одним из главных вызовов в сфере автоматической обработки естественного языка (Natural Language Processing, NLP) является построение таких разговорных ассистентов, которые могут понимать различные лингвистические явления, приcущие разговорной речи. Например, поскольку люди обычно не продумывают заранее, что они собираются сказать, устная речь часто прерывается, т.е. изобилует т.н. нарушениями беглости речи (disfluencies). Это могут быть как довольно простые нарушения, такие как вставка междометий, повторения, исправления или повторное начало, которые попросту нарушают непрерывность предложения, так и более сложные семантические нарушения беглости, меняющие значение всей фразы. Также для правильного понимания разговора часто необходимо знание темпоральных отношений, т.е. отношений временного следования или предшествования между действиями. Эти особенности естественной речи вызывают трудности у современных разговорных ассистентов, а успехи в улучшении их работы весьма скромны. Отчасти это объясняется отсутствием наборов данных, которые бы содержали столь интересные разговорные и речевые феномены.
Чтобы подогреть интерес научного сообщества к этой проблеме, авторы статьи представляют набор данных TimeDial, предназначенный для обучения темпоральным представлениям в диалоге, а также набор данных Disfl-QA, содержащий нарушения беглости речи в контексте диалога. TimeDial представляет новую задачу множественного выбора заполнения пропуска (multiple choice span filling task), нацеленную на усвоение темпоральных отношений, и имеет тестовый поднабор размером более 1.1 тысяч диалогов. Disfl-QA является первым набором данных, содержащим нарушения беглости речи в контексте информационно-поискового домена, а именно ответы на вопросы о статьях Википедии, и содержит около 12 тысяч вручную размеченных вопросов с нарушениями беглости. Эти первые в своем роде наборы данных выявили серьезную пропасть между качеством выполнения заданий человеком и современными NLP моделями.
TimeDial
В то время как люди могут без проблем оперировать такими понятиями времени, как продолжительность, частота или относительный порядок явлений в диалоге, для разговорных ассистентов такие задачи могут представлять значительную трудность. Так, современные NLP модели часто плохо справляются с задачей заполнения пропуска (см. рис.), которая предполагает наличие базовых знаний о мире или понимания явных и скрытых взаимозависимостей между темпоральными понятиями, разбросанными по репликам диалога.
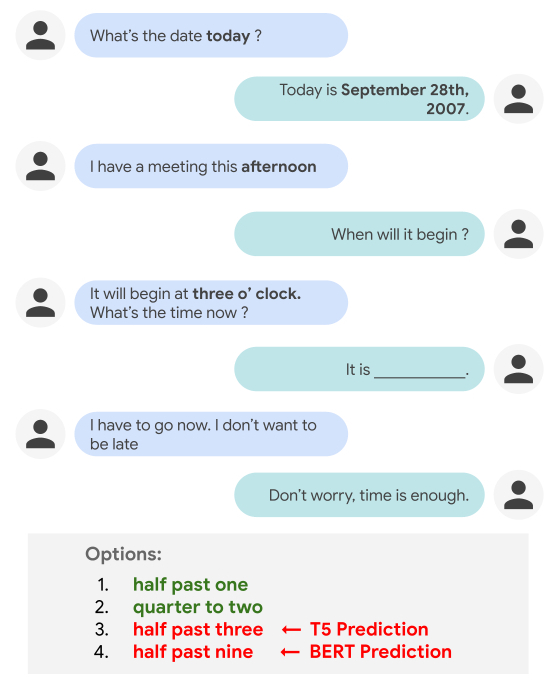
Для человека не составляет труда понять, что «половина второго» (half past one) или «без пятнадцати два» (quarter to two) будут более вероятными вариантами в данном контексте, чем «половина четвертого» (half past three) или «половина десятого» (half past nine). Однако подобные выводы относительно темпоральных отношений в контексте диалога являются достаточно нетривиальной задачей для NLP моделей, так как они подразумевают наличие общих знаний о мире (т.е. знание, что участники диалога еще не опоздали на встречу) и понимания темпоральных отношений между событиями («half past one» – это раньше, чем «three o’clock», в то время как «half past three» — позже). Так, современные модели вроде T5 и BERT в итоге выбрали неверные варианты ответа: «half past three» (T5) и «half past nine» (BERT).
Задача набора данных TimeDial (происходящего от корпуса многосторонних диалогов DailyDialog) позволяет оценить способность моделей понимать темпоральные отношения в контексте диалога. Каждый из около 1.5 тысяч диалогов в наборе данных имеет вид вопроса с множественным выбором, в котором одно из указаний времени маскировано. Модель должна найти правильный ответ из предложенных для того, чтобы заполнить пропуск в предложении.
В экспериментах, проведенных авторами, было обнаружено, что люди без труда справляются с этой задачей (достигая 97.8% точности (accuracy)), однако современные предобученные языковые модели справляются существенно хуже. Авторы провели эксперименты для трех разных парадигм моделирования: 1) классификация с помощью BERT 4-х предлагаемых опций; 2) заполнение маскированного пропуска в диалоге в помощью BERT-MLM; 3) генеративные методы с помощью T5. Все перечисленные модели показывают низкое качество, достигая лучшего результата в 73%.
| Модель | Точность |
|---|---|
| Человек | 97.8% |
| BERT — Классификация | 50.0% |
| BERT — Заполнение маски | 68.5% |
| T5 — Генерация | 73.0% |
Качественный анализ ошибок показал, что предобученные языковые модели часто основываются на поверхностных и даже ложных сходствах (в особенности текстовом совпадении), вместо реального извлечения смыслов в заданном контексте. Весьма вероятно, что для построения NLP моделей, которые были бы действительно способны усваивать темпоральные отношения в тексте, необходимо переосмыслить то, каким образом темпоральные объекты представлены в рамках общих текстовых представлений.
Disfl-QA
Поскольку нарушения беглости речи по сути являются феноменом разговорной речи, они чаще всего встречаются в текстовом выходе систем распознавания речи. Понимание такого бессвязного текста является ключом к созданию хороших разговорных ассистентов, способных понимать человеческую речь. К сожалению, исследования в области NLP и обработки речи затруднены из-за отсутствия выверенных наборов данных, содержащих такие нарушения беглости, а доступные наборы данных, такие как Switchboard, имеют ограниченный объем и сложность. В результате сложно провести стресс-тестирование NLP моделей при наличии подобных особенностей разговорной речи.
| Нарушение беглости речи | Пример |
|---|---|
| Междометие | «When is, uh Easter this year?» |
| Повтор | «When is Eas … Easter this year?» |
| Исправление | «When is Lent, I mean Easter, this year?» |
| Повторное начало | «How much, no wait when is Easter this year?» |
Различные виды нарушений беглости речи: репарандум (reparandum)(слова, предназначенные для исправления или игнорирования; выделены жирным), интеррегнум (interregnum)(необязательные реплики; выделены подчеркиванием) и исправления (выделены курсивом).
Disfl-QA — это первый набор данных, содержащий нарушения беглости речи в контексте информационно-поискового домена, а именно ответы на вопросы о статьях Википедии из SQuAD. Disfl-QA специально создан для выявления нарушений беглости речи и содержит около 12 тысяч вопросов с нарушением беглости, что превосходит все существовавшие до этого наборы данных для этой задачи. Более того, 90% нарушений беглости в Disfl-QA являются исправлениями или повторными началами предложений, что делает его гораздо более сложным набором тестов для исправления нарушений беглости. Кроме этого, Disfl-QA содержит более широкий спектр семантических дистракторов, то есть отвлекающих факторов, которые несут семантическое значение, в отличие от более простых речевых искажений.
Отрывок: …The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, …
| Индекс | Вопрос | Ответ |
|---|---|---|
| Q1 | In what country is Normandy located? | France |
| DQ1 | In what country is Norse found no wait Normandy not Norse? | |
| Q2 | When were the Normans in Normandy? | 10th and 11th centuries |
| DQ2 | From which countries no tell me when were the Normans in Normandy? |
Отрывок и вопросы (Q1, Q2) из набора данных SQuAD вместе с их версиями с нарушениями беглости речи (DQ1, DQ2), состоящими из семантических дистракторов (например, «норвежский» и «из каких стран») и предсказания модели T5.
Здесь первый вопрос (Q1) — это поиск ответа о местонахождении Нормандии. В версии с нарушениями беглости версии (DQ1) вместо Нормандии упоминается норвежский язык, а затем следует исправление. Присутствие этого исправления сбивает с толку QA модель, которая в своем предсказании склонна полагаться на поверхностные текстовые особенности вопроса.
Disfl-QA также включает и новые явления, такие как кореференция (выражение, относящееся к одному и тому же объекту) между репарандумом и исправлением.
| SQuAD | Disfl-QA |
|---|---|
| Who does BSkyB have an operating license from? | Who removed [BSkyB’s] operating license, no scratch that, who do [they] have [their] operating license from? |
Эксперименты показывают, что результаты систем ответов на вопросы, основанных на современных языковых моделях, значительно ухудшаются на Disfl-QA и эвристических нарушениях беглости (представленных в статье) на тестовых данных.
| Набор данных | F1 |
|---|---|
| SQuAD | 89.59 |
| Heuristics | 65.27 (-24.32) |
| Disfl-QA | 61.64 (-27.95) |
Авторы показывают, что методы аугментации частично помогают повысить качество, а также демонстрируют эффективность использования размеченных вручную обучающих данных для тонкой настройки. Авторы также отмечают, что исследователям нужны более масштабные наборы данных с нарушениями беглости речи, чтобы NLP-модели были устойчивыми к особенностям спонтанной речи.
Заключение
Понимание языковых феноменов, присущих человеческой речи, таких как, например, нарушения беглости речи, и темпоральных отношений является ключевым компонентом обеспечения более естественного общения человека и машины в ближайшем будущем. С помощью TimeDial и Disfl-QA авторы стремятся восполнить значительный пробел в исследованиях, предоставляя эти наборы данных в качестве тестовых площадок для моделей NLP, чтобы оценить их устойчивость к повсеместным явлениям в различных задачах. Авторы также надеются, что более широкое NLP-сообщество разработает обобщенные few-shot или zero-shot подходы для эффективной работы с этими явлениями, что избавит от необходимости наборов данных для обучения, размеченных вручную и созданных специально для этих задач.
Авторы
- Автор оригинала – Aditya Gupta, Shyam Upadhyay
- Перевод – Смирнова Екатерина
- Редактирование и вёрстка – Шкарин Сергей