
В предыдущих статьях я рассказал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и перешел к способам соединения.
Прошлая статья была посвящена вложенному циклу, а сегодня поговорим про соединение хешированием. Заодно затронем группировку и поиск уникальных значений.
Однопроходное соединение хешированием
Идея соединения с помощью хеширования состоит в поиске подходящих строк с помощью заранее подготовленной хеш-таблицы. Вот пример плана, использующего такое соединение:
EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join
Hash Cond: (tf.ticket_no = t.ticket_no)
−> Seq Scan on ticket_flights tf
−> Hash
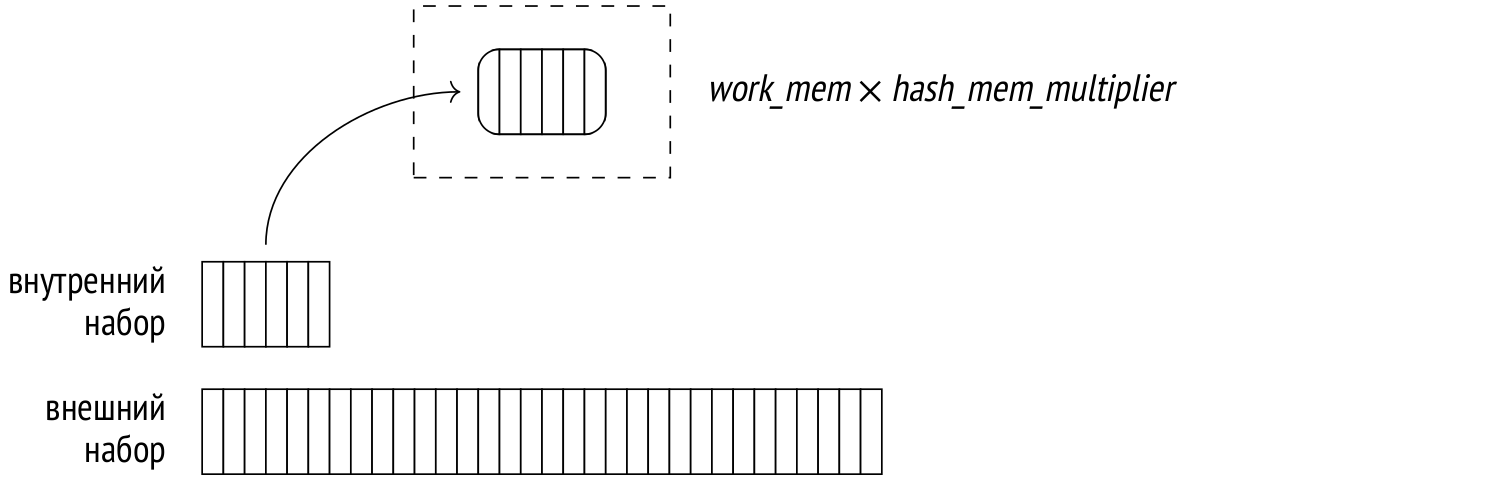
−> Seq Scan on tickets t (5 rows) На первом этапе узел Hash Join обращается к узлу Hash. Тот получает от своего дочернего узла весь внутренний набор строк и помещает его в хеш-таблицу.
Хеш-таблица позволяет сохранять пары, составленные из ключа хеширования и значения, а затем искать значения по ключу за фиксированное время, не зависящее от размера хеш-таблицы. Для этого с помощью хеш-функции ключи хеширования распределяются случайно, но равномерно по ограниченному количеству корзин (bucket) хеш-таблицы. Число корзин всегда является степенью двойки, поэтому номер корзины можно получить, взяв нужное количество двоичных разрядов значения хеш-функции.
Итак, на первом этапе последовательно читаются строки внутреннего набора, и для каждой из них вычисляется хеш-функция. Ключом хеширования в данном случае являются поля, участвующие в условии соединения (Hash Cond), а в самой хеш-таблице сохраняются все поля строки из внутреннего набора, необходимые для запроса.
Наиболее эффективно — за один проход по данным — соединение хешированием работает, если хеш-таблица целиком помещается в оперативную память. Отведенный ей размер ограничен значением work_mem × hash_mem_multiplier (значение последнего параметра по умолчанию равно 1.0).
Вот пример, в котором запрос выполнен с помощью команды EXPLAIN ANALYZE, чтобы получить информацию об использовании памяти:
SET work_mem = '256MB';
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM bookings b
JOIN tickets t ON b.book_ref = t.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (actual rows=2949857 loops=1)
Hash Cond: (t.book_ref = b.book_ref)
−> Seq Scan on tickets t (actual rows=2949857 loops=1)
−> Hash (actual rows=2111110 loops=1)
Buckets: 4194304 Batches: 1 Memory Usage: 145986kB
−> Seq Scan on bookings b (actual rows=2111110 loops=1)
(6 rows)В отличие от соединения вложенным циклом, для которого внутренний и внешний наборы существенно отличаются, соединение на основе хеширования позволяет переставлять наборы местами. Как правило, в качестве внутреннего используется меньший набор, поскольку это уменьшает размер памяти, необходимый для хеш-таблицы.
Здесь объема памяти хватило для размещения всей хеш-таблицы, которая заняла около 143 Mбайт (Memory Usage) на 4 М = 222 корзин (Buckets). Соединение поэтому выполняется в один проход (Batches).
Однако если бы в запросе использовался один столбец, для хеш-таблицы хватило бы 111 Мбайт:
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT b.book_ref
FROM bookings b
JOIN tickets t ON b.book_ref = t.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (actual rows=2949857 loops=1)
Hash Cond: (t.book_ref = b.book_ref)
−> Index Only Scan using tickets_book_ref_idx on tickets t
(actual rows=2949857 loops=1)
Heap Fetches: 0
−> Hash (actual rows=2111110 loops=1)
Buckets: 4194304 Batches: 1 Memory Usage: 113172kB
−> Seq Scan on bookings b (actual rows=2111110 loops=1)
(8 rows)RESET work_mem;Это еще одна причина не использовать в запросах лишние поля, в том числе «звездочку».
Количество корзин хеш-таблицы выбирается так, чтобы в полностью загруженной данными таблице каждая корзина содержала в среднем одну строку. Более плотное заполнение повысило бы вероятность хеш-коллизий и, следовательно, снизило бы эффективность поиска, а более разреженная хеш-таблица слишком неэкономно расходовала бы память. Рассчитанное количество корзин увеличивается до первой подходящей степени двойки.
(Если, исходя из оценки средней «ширины» одной строки, размер хеш-таблицы с расчетным количеством корзин превышает ограничение по памяти, используется двухпроходное хеширование.)
До того, как хеш-таблица полностью построена, соединение хешированием не может начать возвращать результаты.
На втором этапе (хеш-таблица к этому моменту уже готова) узел Hash Join обращается ко второму дочернему узлу за внешним набором строк. Для каждой прочитанной строки проверяется наличие соответствующих ей строк в хеш-таблице. Для этого хеш-функция вычисляется от значений полей внешнего набора, входящих в условие соединения.
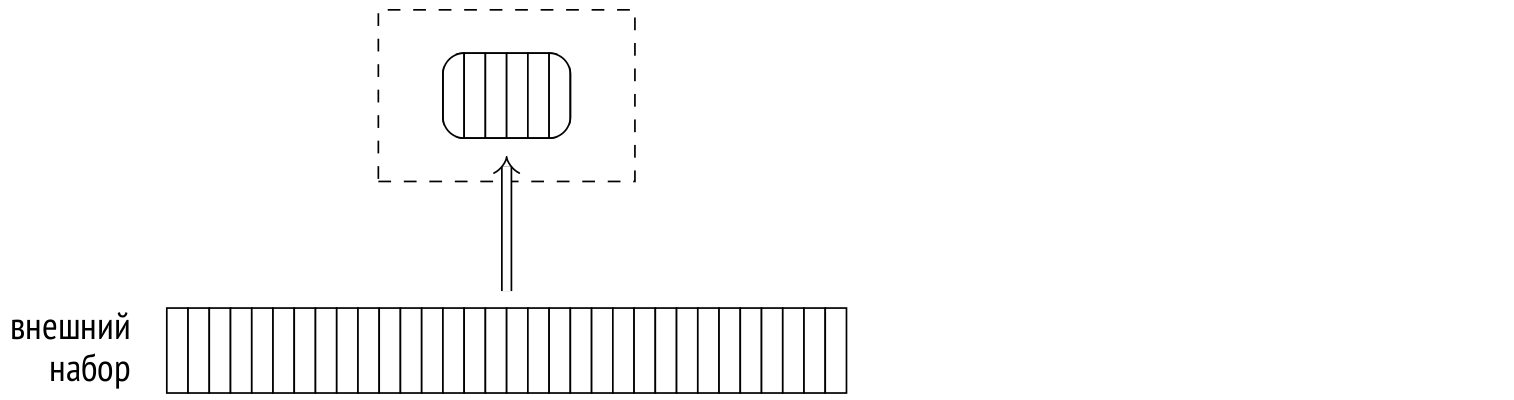
Найденные соответствия возвращаются вышестоящему узлу.
Для тренировки чтения «развесистых» планов можно посмотреть пример с двумя соединениями хешированием. Этот запрос выводит имена всех пассажиров и рейсы, которые они бронировали:
EXPLAIN (costs off)
SELECT t.passenger_name, f.flight_no
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
JOIN flights f ON f.flight_id = tf.flight_id; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join
Hash Cond: (tf.flight_id = f.flight_id)
−> Hash Join
Hash Cond: (tf.ticket_no = t.ticket_no)
−> Seq Scan on ticket_flights tf
−> Hash
−> Seq Scan on tickets t
−> Hash
−> Seq Scan on flights f
(9 rows)Сначала соединяются билеты (tickets) и перелеты (ticket_flights), причем хеш-таблица строится по таблице билетов. Затем получившийся набор строк соединяется с перелетами (flights), по которым строится другая хеш-таблица.
Оценка стоимости. Оценку кардинальности я уже рассматривал и она не зависит от способа соединения, поэтому дальше я буду говорить только об оценке стоимости.
Стоимость узла Hash выставляется равной полной стоимости его дочернего узла. Это фиктивная цифра, просто чтобы было что показать в плане запроса. Все реальные оценки включены в стоимость узла Hash Join.
Рассмотрим пример:
EXPLAIN (analyze, timing off, summary off)
SELECT *
FROM flights f
JOIN seats s ON s.aircraft_code = f.aircraft_code; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (cost=38.13..278507.28 rows=16518865 width=78)
(actual rows=16518865 loops=1)
Hash Cond: (f.aircraft_code = s.aircraft_code)
−> Seq Scan on flights f (cost=0.00..4772.67 rows=214867 widt...
(actual rows=214867 loops=1)
−> Hash (cost=21.39..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 79kB
−> Seq Scan on seats s (cost=0.00..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
(10 rows)Начальная стоимость соединения отражает в основном создание хеш-таблицы и складывается из:
полной стоимости получения внутреннего набора строк, который необходим для построения хеш-таблицы;
стоимости вычисления хеш-функции для каждого поля, входящего в ключ соединения, каждой строки внутреннего набора (одна операция оценивается значением параметра cpu_operator_cost);
стоимости вставки каждой строки внутреннего набора в хеш-таблицу (одна строка оценивается значением параметра cpu_tuple_cost);
начальной стоимости получения внешнего набора строк, без которого нельзя приступить к собственно соединению.
Полная стоимость соединения добавляет к начальной оценке стоимость собственно выполнения соединения:
стоимость вычисления хеш-функции для каждого поля, входящего в ключ соединения, каждой строки внешнего набора (cpu_operator_cost);
стоимость перепроверки условий соединения, которая необходима из-за возможных хеш-коллизий (вычисление каждого оператора оценивается значением параметра cpu_operator_cost);
стоимость обработки каждой результирующей строки (cpu_tuple_cost).
Наиболее сложной частью оценки здесь является определение количества перепроверок, которые потребуются в ходе соединения. Это количество оценивается произведением числа строк внешнего набора на некоторую долю числа строк внутреннего набора (находящегося в хеш-таблице). Оценка учитывает в том числе и возможное неравномерное распределение значений; я не буду вдаваться в подробности, а для данного примера оценка этой доли равна 0,150112.
Итак, для нашего примера оценка вычисляется следующим образом:
WITH cost(startup) AS (
SELECT round((
21.39 +
current_setting('cpu_operator_cost')::real * 1339 +
current_setting('cpu_tuple_cost')::real * 1339 +
0.00
)::numeric, 2)
)
SELECT startup,
startup + round((
4772.67 +
current_setting('cpu_operator_cost')::real * 214867 +
current_setting('cpu_operator_cost')::real * 214867 * 1339 *
0.150112 +
current_setting('cpu_tuple_cost')::real * 16518865
)::numeric, 2) AS total
FROM cost; startup | total
−−−−−−−−−+−−−−−−−−−−−
38.13 | 278507.26
(1 row)Двухпроходное соединение хешированием
Если на этапе планирования оценки показывают, что хеш-таблица не поместится в отведенные рамки, внутренний набор строк разбивается на отдельные пакеты (batch), каждый из которых обрабатывается отдельно. Количество пакетов (как и корзин) всегда является степенью двойки; номер пакета определяется соответствующим количеством битов хеш-значения.
Любые две строки, соответствующие друг другу при соединении, принадлежат одному и тому же пакету, поскольку у строк из разных пакетов не могут совпасть хеш-коды.
К каждому пакету относится одинаковое количество хеш-значений. Если данные распределены равномерно, то и размеры всех пакетов будут примерно одинаковыми. Потреблением памяти планировщик может управлять, выбирая подходящее количество пакетов так, чтобы каждый из них по отдельности поместился в память.
На первом этапе выполнения читается внутренний набор строк и строится хеш-таблица. Если очередная строка внутреннего набора относится в первому пакету, она добавляется к хеш-таблице и остается в оперативной памяти. Если же строка относится к какому-либо другому пакету, она записывается во временный файл — свой для каждого из пакетов.
Объем используемых сеансом временных файлов на диске можно ограничить, установив предельное значение в параметре temp_file_limit (временные таблицы в это ограничение не входят). Если сеанс исчерпает ограничение, запрос будет аварийно прерван.
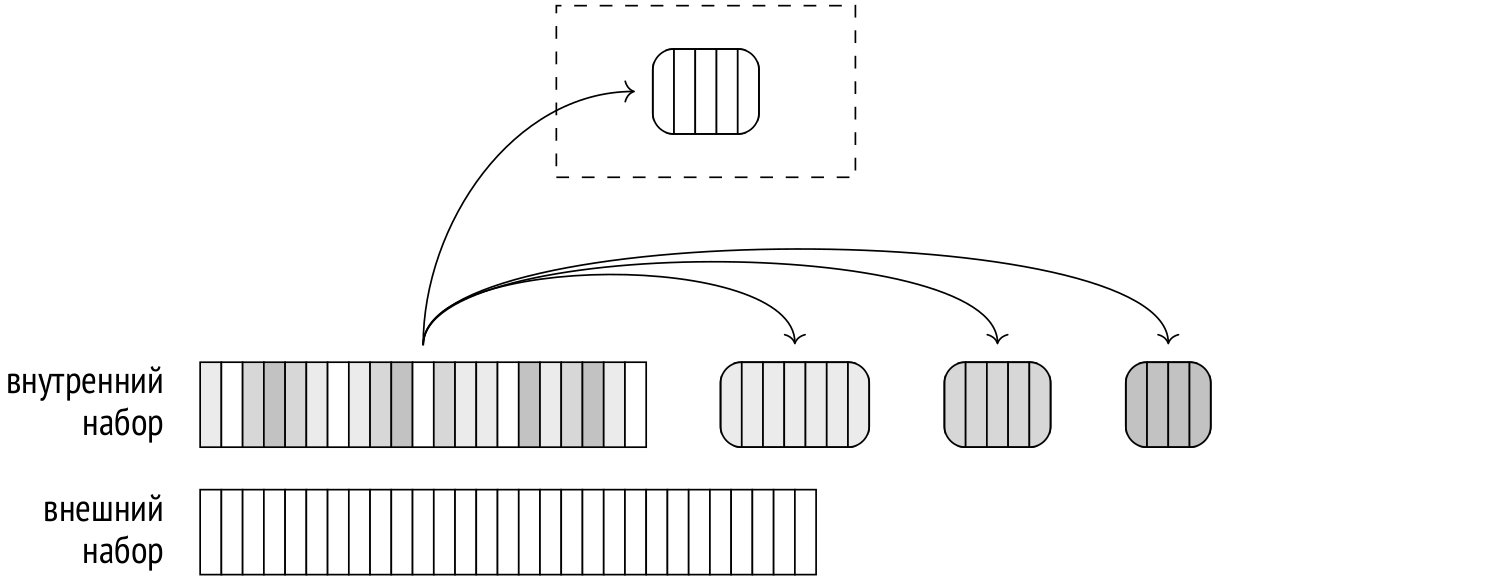
На втором этапе читается внешний набор строк. Если очередная строка принадлежит первому пакету, она сопоставляется с хеш-таблицей, которая как раз содержит строки первого пакета внутреннего набора (а в других пакетах соответствий быть не может).
Если же строка принадлежит другому пакету, она сбрасывается во временный файл — опять же, свой для каждого пакета. Таким образом, при N пакетах будет использоваться 2(N − 1) файлов (возможно меньше, если часть пакетов окажется пустыми).
После окончания второго этапа память, занимаемая хеш-таблицей, освобождается. На этот момент уже имеется частичный результат соединения по одному из имеющихся пакетов.
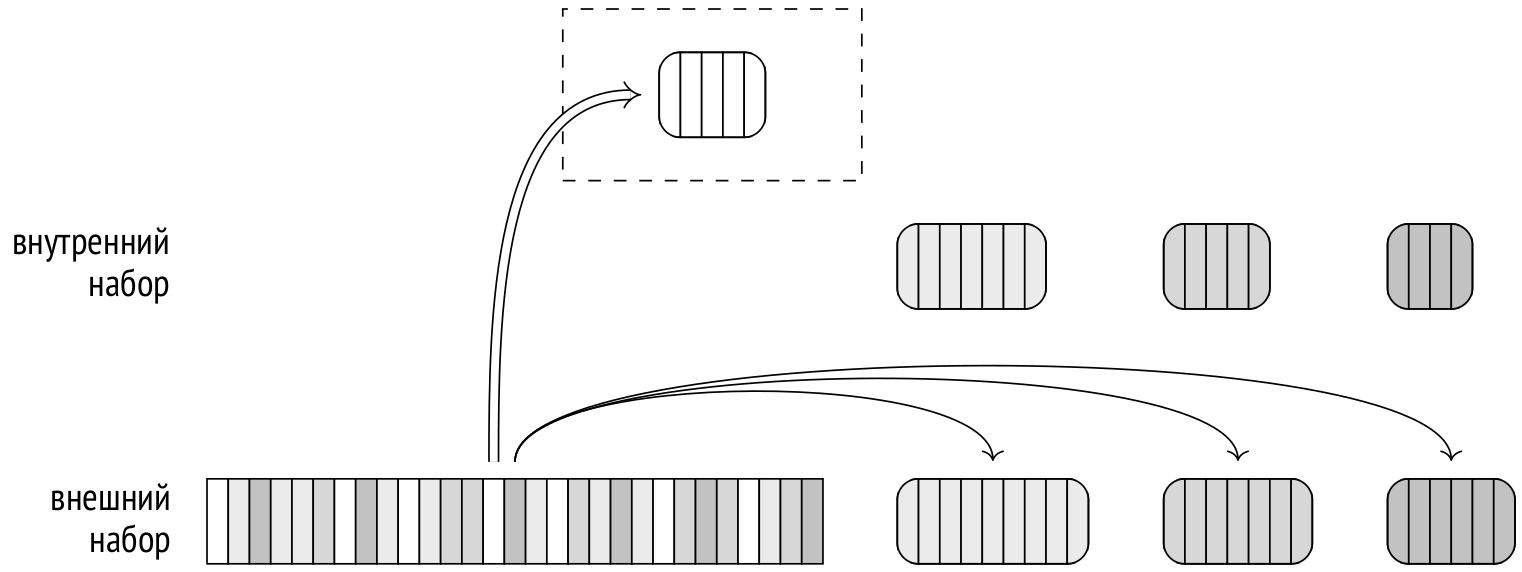
Далее оба этапа повторяются поочередно для каждого из сохраненных на диск пакетов. Из временного файла в хеш-таблицу добавляются строки внутреннего набора, затем из другого временного файла считываются и сопоставляются строки внешнего набора, соответствующие тому же пакету. Использованные временные файлы удаляются, и процедура повторяется для следующего пакета, пока соединение не будет полностью завершено.
Двухпроходное соединение в выводе команды EXPLAIN отличается количеством пакетов, большим единицы. Кроме того, с опцией buffers команда покажет статистику обмена с диском:
EXPLAIN (analyze, buffers, costs off, timing off, summary off)
SELECT *
FROM bookings b
JOIN tickets t ON b.book_ref = t.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (actual rows=2949857 loops=1)
Hash Cond: (t.book_ref = b.book_ref)
Buffers: shared hit=7205 read=55657, temp read=55126
written=55126
−> Seq Scan on tickets t (actual rows=2949857 loops=1)
Buffers: shared read=49415
−> Hash (actual rows=2111110 loops=1)
Buckets: 65536 Batches: 64 Memory Usage: 2277kB
Buffers: shared hit=7205 read=6242, temp written=10858
−> Seq Scan on bookings b (actual rows=2111110 loops=1)
Buffers: shared hit=7205 read=6242
(11 rows)Я уже приводил этот пример выше, но с увеличенным значением work_mem. В 4 Мбайта по умолчанию вся хеш-таблица не помещается; здесь задействовано 64 пакета, хеш-таблица использует 64 К корзин. На этапе построения хеш-таблицы (узел Hash) выполняется запись во временные файлы (temp written); на этапе соединения (узел Hash Join) файлы и записываются, и читаются (temp read, written).
Более детальную информацию о временных файлах можно получить, установив параметр log_temp_files в нулевое значение: в журнале сообщений сервера будет отмечен каждый файл и его размер (на момент удаления файла).
Динамическая корректировка плана
Запланированный ход событий могут нарушить две проблемы. Во-первых, неравномерное распределение.
При неравномерном распределении значений в столбцах, входящих в ключ соединения, разные пакеты будут иметь разное количество строк.
Если большим окажется любой пакет, кроме первого, все его строки придется сначала записать на диск, а затем прочитать с диска. Особенно это касается внешнего набора данных, потому что обычно он больше. Поэтому, если для внешнего набора строк доступна статистика по наиболее частым значениям (то есть внешний набор представлен таблицей, и соединение выполняется по одному столбцу — многовариантные списки не используются), то строки с хеш-кодами, соответствующими нескольким наиболее частым значениям, считаются принадлежащими первому пакету. Эта оптимизация (skew optimization) позволяет несколько уменьшить ввод-вывод при двухпроходном соединении.
Во-вторых, некорректная статистика.
Обе причины могут привести к тому, что размер некоторых (или всех) пакетов окажется больше расчетного, хеш-таблица для них не поместится в запланированный размер и выйдет за рамки ограничений.
Поэтому, если в процессе построения хеш-таблицы выясняется, что ее размер не укладывается в ограничения, количество пакетов увеличивается (удваивается) на лету. Фактически каждый пакет разделяется на два новых: примерно половина строк (если предполагать равномерное распределение) остается в хеш-таблице, а другая половина сбрасывается на диск в новый временный файл.
Это может произойти и в том случае, когда планировалось однопроходное соединение. По сути, одно- и двухпроходное соединение — один и тот же алгоритм, реализуемый одним и тем же кодом. Я разделяю их только для удобства изложения.
Количество пакетов может только увеличиваться. Если оказывается, что планировщик ошибся в бóльшую сторону, пакеты не объединяются.
Однако при неравномерном распределении увеличение числа пакетов может не помочь. Например, ключевой столбец может содержать одно и то же значение во всех строках: очевидно, что все они попадут в один пакет, поскольку хеш-функция будет возвращать одно и то же значение. Увы, в таком случае хеш-таблица будет просто расти, невзирая на значения ограничивающих параметров. (Теоретически для такой ситуации можно было бы применить многопроходное соединение, рассматривая за один раз только часть пакета, но это не реализовано.)
Для демонстрации динамического увеличения количества пакетов придется приложить некоторые усилия, чтобы обмануть планировщик:
CREATE TABLE bookings_copy (LIKE bookings INCLUDING INDEXES)
WITH (autovacuum_enabled = off);
INSERT INTO bookings_copy SELECT * FROM bookings;INSERT 0 2111110DELETE FROM bookings_copy WHERE random() < 0.9;DELETE 1899931ANALYZE bookings_copy;
INSERT INTO bookings_copy SELECT * FROM bookings
ON CONFLICT DO NOTHING;INSERT 0 1899931SELECT reltuples FROM pg_class WHERE relname = 'bookings_copy'; reltuples
−−−−−−−−−−−
211179
(1 row)В результате этих манипуляций у нас есть таблица bookings_copy — полная копия bookings, но планировщик полагает, что в ней в десять раза меньше строк, чем на самом деле. В реальности похожая ситуация может возникнуть, например, когда хеш-таблица строится по набору строк, полученному в результате другого соединения, о котором в таком случае нет достоверной статистики.
В результате планировщик полагал, что будет достаточно 8 пакетов, но в процессе выполнения соединения их число выросло до 32:
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM bookings_copy b
JOIN tickets t ON b.book_ref = t.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (actual rows=2949857 loops=1)
Hash Cond: (t.book_ref = b.book_ref)
−> Seq Scan on tickets t (actual rows=2949857 loops=1)
−> Hash (actual rows=2111110 loops=1)
Buckets: 65536 (originally 65536) Batches: 32 (originally 8)
Memory Usage: 4040kB
−> Seq Scan on bookings_copy b (actual rows=2111110 loops=1)
(7 rows)Оценка стоимости. Вот тот же пример, на котором я показывал расчет стоимости для однопроходного соединения, но теперь я предельно уменьшаю размер доступной памяти, и планировщик вынужден использовать два пакета. Стоимость соединения при этом увеличилась:
SET work_mem = '64kB';
EXPLAIN (analyze, timing off, summary off)
SELECT *
FROM flights f
JOIN seats s ON s.aircraft_code = f.aircraft_code; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Join (cost=45.13..283139.28 rows=16518865 width=78)
(actual rows=16518865 loops=1)
Hash Cond: (f.aircraft_code = s.aircraft_code)
−> Seq Scan on flights f (cost=0.00..4772.67 rows=214867 widt...
(actual rows=214867 loops=1)
−> Hash (cost=21.39..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
Buckets: 2048 Batches: 2 Memory Usage: 55kB
−> Seq Scan on seats s (cost=0.00..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
(10 rows)RESET work_mem;К стоимости однопроходного соединения добавляются расходы, связанные с записью строк во временные файлы и чтением их.
К начальной стоимости добавляется оценка записи такого количества страниц, которое будет достаточно для сохранения нужных полей всех строк внутреннего набора. Хотя первый пакет и не записывается на диск при построении хеш-таблицы, это не учитывается в оценке, поэтому она не зависит от количества пакетов.
К полной стоимости добавляется оценка чтения записанных ранее строк внутреннего набора и оценка сначала записи, а затем и чтения строк внешнего набора.
И запись, и чтение одной страницы оцениваются, исходя из последовательного характера ввода-вывода, значением параметра seq_page_cost.
В данном примере количество страниц для строк внутреннего набора оценено как 7, а для внешнего — как 2309. Добавив оценки к стоимости, которая была получена выше для однопроходного соединения, получаем цифры, совпадающие со стоимостью в плане запроса:
SELECT 38.13 + -- начальная стоимость однопроходного соед.
current_setting('seq_page_cost')::real * 7
AS startup,
279232.27 + -- полная стоимость однопроходного соед.
current_setting('seq_page_cost')::real * 2 * (7 + 2309)
AS total; startup | total
−−−−−−−−−+−−−−−−−−−−−
45.13 | 283864.27
(1 row)Таким образом, при нехватке оперативной памяти алгоритм соединения становится двухпроходным и эффективность его падает. Поэтому важно, чтобы:
в хеш-таблицу попадали только действительно нужные поля (обязанность автора запроса);
хеш-таблица строилась по меньшему набору строк (обязанность планировщика).
Соединение хешированием в параллельных планах
Соединение хешированием может участвовать в параллельных планах в том виде, в котором я описывал его выше. Это означает, что сначала несколько параллельных процессов независимо друг от друга строят собственные (совершенно одинаковые) хеш-таблицы по внутреннему набору данных, а затем используют параллельный доступ к внешнему набору строк. Выигрыш здесь достигается за счет того, что каждый из процессов просматривает только часть внешнего набора строк.
Вот пример плана с участием обычного (однопроходного в данном случае) соединения хешированием:
SET work_mem = '128MB';
SET enable_parallel_hash = off;
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT count(*)
FROM bookings b
JOIN tickets t ON t.book_ref = b.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (actual rows=1 loops=1)
−> Gather (actual rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
−> Partial Aggregate (actual rows=1 loops=3)
−> Hash Join (actual rows=983286 loops=3)
Hash Cond: (t.book_ref = b.book_ref)
−> Parallel Index Only Scan using tickets_book_ref...
Heap Fetches: 0
−> Hash (actual rows=2111110 loops=3)
Buckets: 4194304 Batches: 1 Memory Usage:
113172kB
−> Seq Scan on bookings b (actual rows=2111110...
(13 rows)RESET enable_parallel_hash;Здесь каждый процесс хеширует таблицу bookings, а затем сопоставляет с хеш-таблицей свою часть строк, полученную параллельным индексным доступом (Parallel Index Only Scan).
Ограничение на память под хеш-таблицу применяется к каждому параллельному процессу, так что суммарно будет выделено в три (в данном случае) раза больше памяти, чем это указано в плане (Memory Usage).
Параллельное однопроходное хеш-соединение
Несмотря на то, что и обычное соединение хешированием может давать определенную выгоду в параллельных планах (особенно в случае небольшого внутреннего набора, который нет смысла обрабатывать параллельно), для больших наборов данных лучше работает специальный параллельный алгоритм хеш-соединения, доступный с версии PostgreSQL 11.
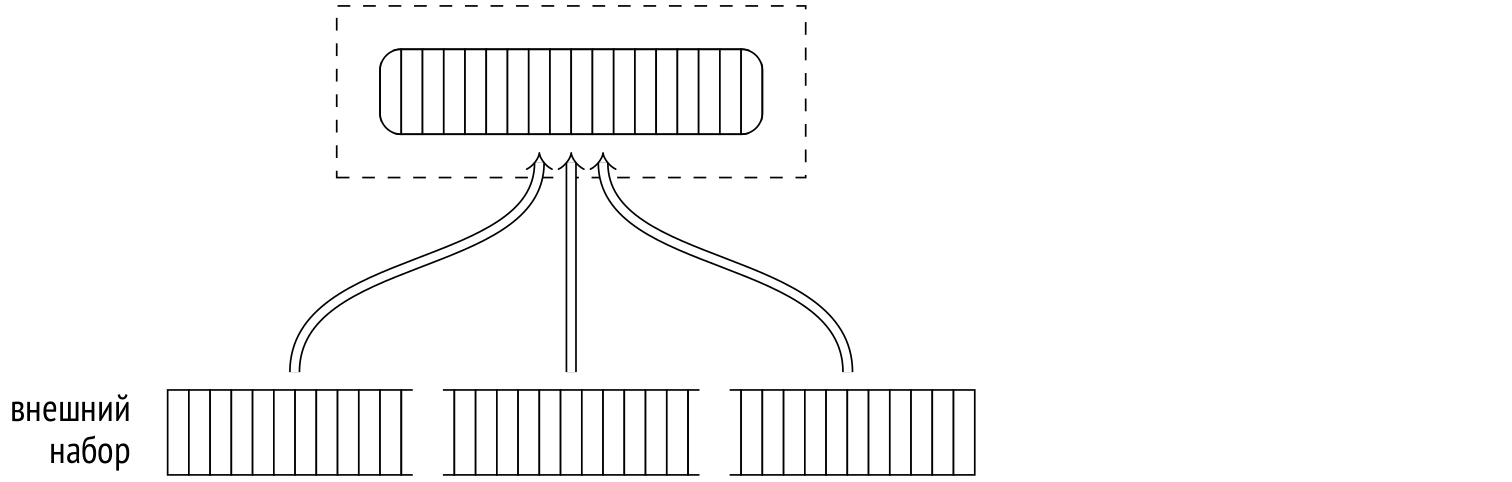
Важное отличие от непараллельной версии алгоритма состоит в том, что хеш-таблица создается не в локальной памяти процесса, а в общей динамически выделяемой памяти, и доступна каждому параллельному процессу, участвующему в соединении.
Это позволяет вместо нескольких отдельных хеш-таблиц создать одну общую, используя суммарный объем памяти, доступный всем процессам-участникам. Благодаря этому увеличивается вероятность того, что соединение сможет выполниться за один проход.
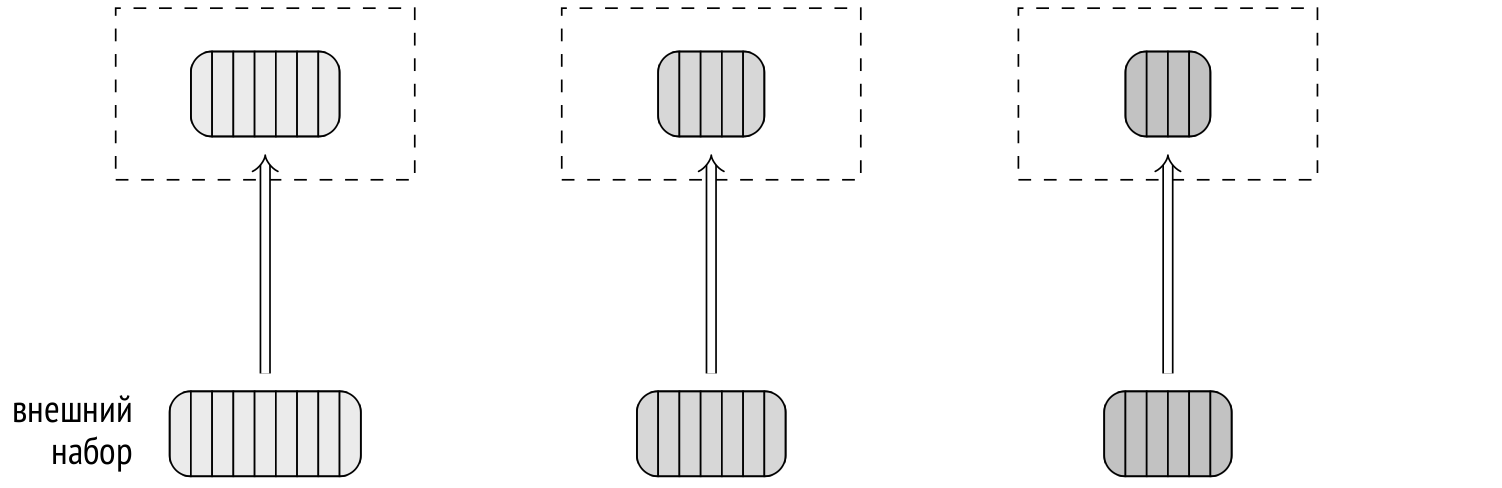
На первом этапе, представляемом в плане узлом Parallel Hash, все параллельные процессы строят общую хеш-таблицу, используя параллельный доступ к внутреннему набору строк.

Чтобы можно было двигаться дальше, каждый из параллельных процессов должен завершить свою часть первого этапа.
На втором этапе (узел Parallel Hash Join), когда хеш-таблица построена, каждый процесс сопоставляет с ней свою часть строк внешнего набора, используя параллельный доступ.
Вот пример такого плана:
SET work_mem = '64MB';
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT count(*)
FROM bookings b
JOIN tickets t ON t.book_ref = b.book_ref;QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate (actual rows=1 loops=1)
−> Gather (actual rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
−> Partial Aggregate (actual rows=1 loops=3)
−> Parallel Hash Join (actual rows=983286 loops=3)
Hash Cond: (t.book_ref = b.book_ref)
−> Parallel Index Only Scan using tickets_book_ref...
Heap Fetches: 0
−> Parallel Hash (actual rows=703703 loops=3)
Buckets: 4194304 Batches: 1 Memory Usage: 115424kB
−> Parallel Seq Scan on bookings b (actual row...
(13 rows)RESET work_mem;Это тот же запрос, что я показывал в предыдущем разделе, но там параллельная версия хеш-соединения была специально отключена параметром enable_parallel_hash.
Несмотря на то, что я уменьшил объем памяти под хеш-таблицу вдвое по сравнению с обычным хеш-соединением из предыдущего раздела, соединение осталось однопроходным за счет совместного использования памяти всех параллельных процессов (Memory Usage). Хеш-таблица занимает теперь немного больше памяти, однако она существует в единственном экземпляре, так что суммарное использование памяти уменьшилось.
Параллельное двухпроходное хеш-соединение
Даже совместной памяти всех параллельных процессов может не хватить для размещения всей хеш-таблицы. Это может стать понятно как на этапе планирования, так и позже, во время выполнения. В таком случае используется двухпроходный алгоритм, который существенно отличается от всех уже рассмотренных.
Важное отличие состоит в том, что используется не одна большая общая хеш-таблица, а каждый процесс работает со своей таблицей меньшего размера и обрабатывает пакеты независимо от других процессов. (Однако и отдельные хеш-таблицы располагаются в общей памяти, так что другие процессы могут получить к ним доступ.) Если уже на этапе планирования становится ясно, что одним пакетом не обойтись, для каждого процесса сразу создается своя хеш-таблица. Если решение принимается во время выполнения, таблица перестраивается.
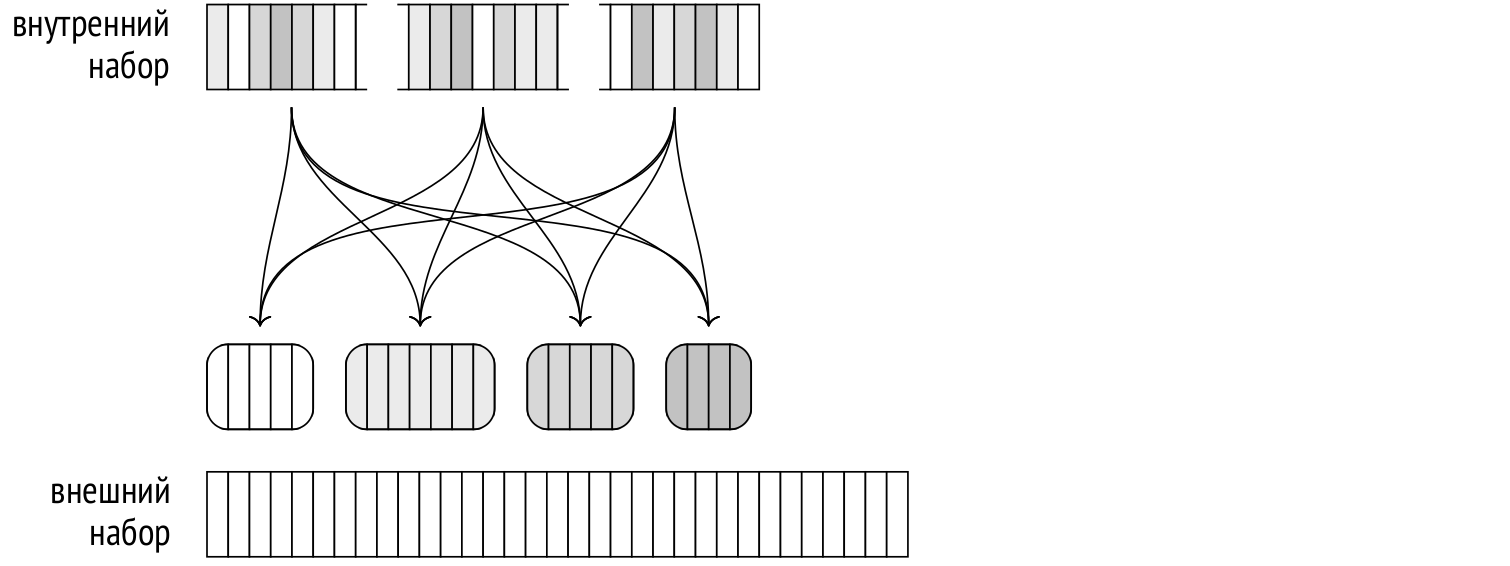
Итак, на первом этапе процессы параллельно читают внутренний набор строк, разделяя его на пакеты и записывая эти пакеты во временные файлы. Поскольку каждый процесс читает только свою часть строк внутреннего набора, ни один из них не построит полную хеш-таблицу ни для одного пакета (не исключая и первый). Полный набор строк любого пакета собирается только в файле, запись в который ведут все параллельные процессы, синхронизируясь друг с другом. Поэтому, в отличие от непараллельной версии алгоритма и от параллельной однопроходной версии, в данном случае на диск сбрасываются все пакеты, включая первый.
Когда все процессы закончили хеширование внутреннего набора, начинается второй этап. В случае непараллельной версии алгоритма строки внешнего набора, относящиеся к первому пакету, сразу же сопоставляются с хеш-таблицей. Но в параллельной версии в памяти еще нет готовой хеш-таблицы, а кроме того пакеты обрабатываются процессами независимо. Поэтому в начале второго этапа внешний набор строк читается параллельно, распределяется по пакетам и каждый пакет записывается в свой временный файл. В отличие от первого этапа, прочитанные строки не помещаются в хеш-таблицу и увеличение количества пакетов произойти не может.
Когда все процессы закончили чтение внешнего набора данных, на диске имеется 2N временных файлов, содержащих пакеты внутреннего и внешнего наборов.
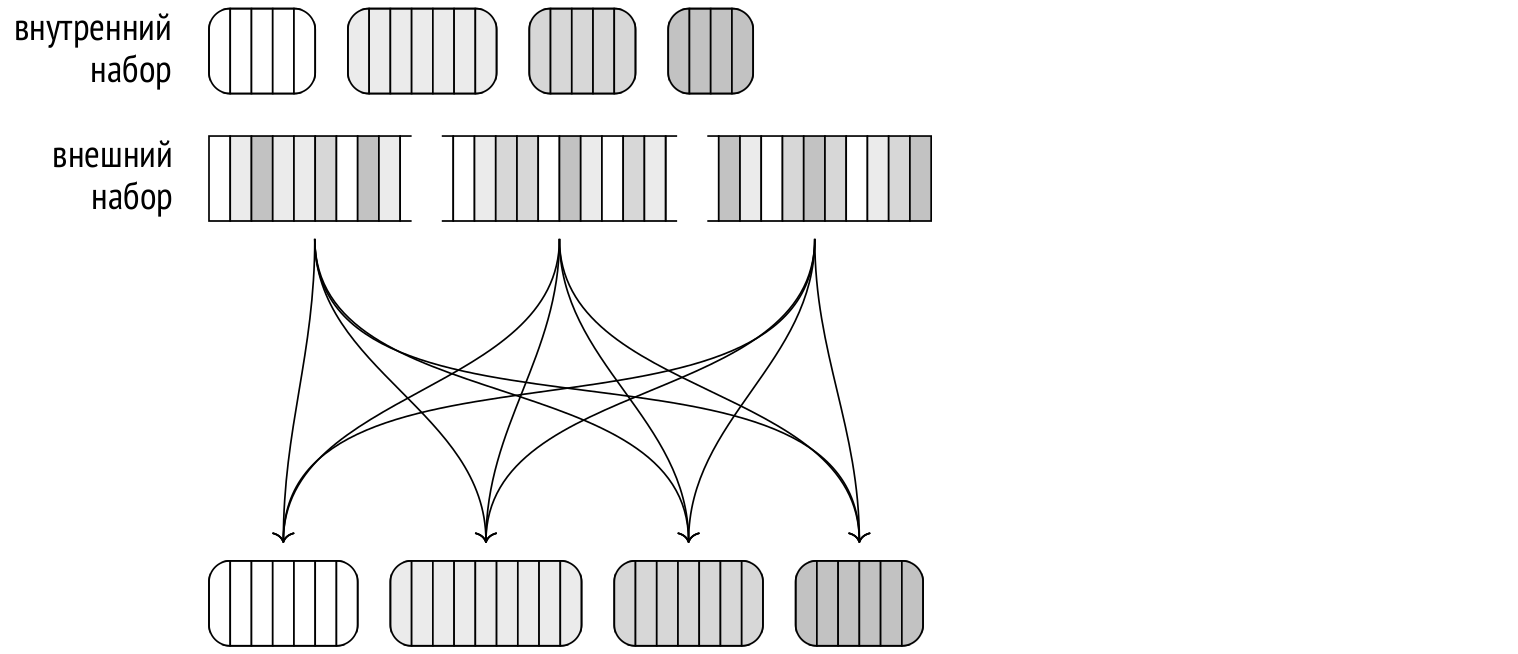
Затем каждый процесс выбирает один из пакетов и выполняет соединение: загружает внутренний набор строк в свою хеш-таблицу в памяти, читает строки внешнего набора и сопоставляет их со строками в хеш-таблице. Когда процесс завершает обработку одного пакета, он выбирает следующий еще не обработанный.
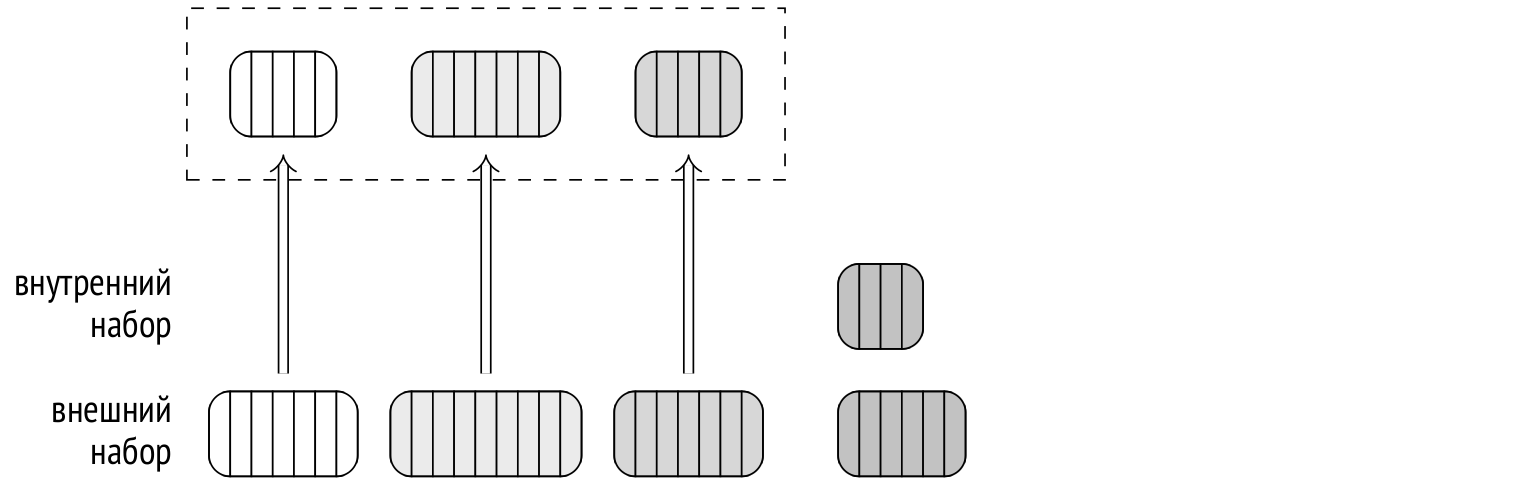
Когда необработанные пакеты заканчиваются, освободившийся процесс подключается к обработке одного из еще не завершенных пакетов, пользуясь тем, что все хеш-таблицы находятся в разделяемой памяти.
Такая схема работает лучше, чем одна большая общая хеш-таблица, которую совместно используют все процессы: проще организовать совместную работу, меньше ресурсов тратится на синхронизацию.

Модификации
Алгоритм соединения хешированием может использоваться не только для внутренних соединений, но и для любых других типов: левых, правых и полных внешних соединений, для полу- и антисоединений. Однако, как я уже говорил, в качестве условия соединения допускается только равенство.
Часть операций я уже показывал на примере соединения вложенным циклом. Вот пример правого внешнего соединения:
EXPLAIN (costs off) SELECT *
FROM bookings b
LEFT OUTER JOIN tickets t ON t.book_ref = b.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Right Join
Hash Cond: (t.book_ref = b.book_ref)
−> Seq Scan on tickets t
−> Hash
−> Seq Scan on bookings b
(5 rows)Обратите внимание, как логическая операция левого соединения в SQL-запросе превратилась в физическую операцию правого соединения в плане выполнения.
На логическом уровне внешней таблицей (стоящей слева от операции соединения) являются бронирования (bookings), а внутренней — таблица билетов (tickets). В результат соединения поэтому должны попасть в том числе и бронирования, не имеющие билетов.
На физическом уровне внешний и внутренний наборы данных определяются не по положению в тексте запроса, а исходя из стоимости соединения. Обычно это означает, что внутренним набором будет тот, чья хеш-таблица меньше. Так происходит и здесь: в качестве внутреннего набора выступает таблица бронирований. Поэтому в плане выполнения тип соединения меняется с левого на правый.
И наоборот, если в запросе указать правое внешнее соединение (желая вывести билеты, не связанные с бронированиями), то в плане выполнения тип соединения поменяется на правое:
EXPLAIN (costs off) SELECT *
FROM bookings b
RIGHT OUTER JOIN tickets t ON t.book_ref = b.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Left Join
Hash Cond: (t.book_ref = b.book_ref)
−> Seq Scan on tickets t
−> Hash
−> Seq Scan on bookings b
(5 rows)И для полноты картины пример плана запроса с полным соединением:
EXPLAIN (costs off) SELECT *
FROM bookings b
FULL OUTER JOIN tickets t ON t.book_ref = b.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Hash Full Join
Hash Cond: (t.book_ref = b.book_ref)
−> Seq Scan on tickets t
−> Hash
−> Seq Scan on bookings b
(5 rows)В настоящее время параллельное соединение хешированием не поддерживается для правых и полных соединений (но работа над этим ведется). Обратите внимание, что в следующем примере таблица бронирований использована в качестве внешнего набора данных, хотя, если бы правое соединение поддерживалось, планировщик предпочел бы его:
EXPLAIN (costs off) SELECT sum(b.total_amount)
FROM bookings b
LEFT OUTER JOIN tickets t ON t.book_ref = b.book_ref; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate
−> Gather
Workers Planned: 2
−> Partial Aggregate
−> Parallel Hash Left Join
Hash Cond: (b.book_ref = t.book_ref)
−> Parallel Seq Scan on bookings b
−> Parallel Hash
−> Parallel Index Only Scan using tickets_book...
(9 rows)Группировка и уникальные значения
Группировка значений для агрегации и устранение дубликатов могут выполняться алгоритмами, схожими с алгоритмами соединения. Один из способов состоит в том, чтобы построить хеш-таблицу по нужным полям. Каждое значение помещается в хеш-таблицу, только если его там еще нет. Таким образом в конечном итоге в хеш-таблице остаются только уникальные значения.
В плане выполнения узел, отвечающий за агрегацию методом хеширования, обозначается как HashAggregate.
Вот несколько примеров ситуаций, в которых может использоваться такой узел. Количество мест для каждого класса обслуживания (GROUP BY):
EXPLAIN (costs off) SELECT fare_conditions, count(*)
FROM seats
GROUP BY fare_conditions; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
HashAggregate
Group Key: fare_conditions
−> Seq Scan on seats
(3 rows)Список классов обслуживания (DISTINCT):
EXPLAIN (costs off) SELECT DISTINCT fare_conditions
FROM seats; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
HashAggregate
Group Key: fare_conditions
−> Seq Scan on seats
(3 rows)Классы обслуживания и еще одно значение (UNION):
EXPLAIN (costs off) SELECT fare_conditions
FROM seats
UNION
SELECT NULL; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
HashAggregate
Group Key: seats.fare_conditions
−> Append
−> Seq Scan on seats
−> Result
(5 rows)Узел Append соответствует объединению двух наборов строк, но не удаляет дубликаты, как этого требует операция UNION. Удаление выполняется отдельно узлом HashAggregate.
Память, выделяемая под хеш-таблицу, ограничена значением work_mem × hash_mem_multiplier, как и в случае хеш-соединения.
Если хеш-таблица помещается в отведенную память, агрегация выполняется за один проход (Batches) по набору строк, как в этом примере:
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT DISTINCT amount
FROM ticket_flights; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
HashAggregate (actual rows=338 loops=1)
Group Key: amount
Batches: 1 Memory Usage: 61kB
−> Seq Scan on ticket_flights (actual rows=8391852 loops=1)
(4 rows)Уникальных значений стоимости не так много, поэтому хеш-таблица заняла всего 61 Кбайт (Memory Usage).
Как только во время построения хеш-таблицы новые значения перестают помещаться в отведенный объем, они сбрасываются во временные файлы, распределяясь по разделам (partition) на основе нескольких битов хеш-значения. Количество разделов является степенью двойки и выбирается так, чтобы хеш-таблица для каждого из них поместилась целиком в оперативную память. Конечно, оценка зависит от качества статистики, поэтому расчетное значение умножается на полтора, чтобы еще уменьшить размер разделов и увеличить вероятность того, что каждый из них можно будет обработать за один раз.
После того как весь набор данных прочитан, узел возвращает результаты агрегации по тем значениям, которые попали в хеш-таблицу.
Затем хеш-таблица очищается и каждый из разделов, записанных на предыдущем шаге во временные файлы, читается и обрабатывается точно так же, как обычный набор строк. При неудачном стечении обстоятельств хеш-таблица раздела может снова не поместиться в память; тогда «лишние» строки снова будут разбиты на разделы и записаны на диск для последующей обработки.
В двухпроходном алгоритме соединения хешированием наиболее частые значения специальным образом переносятся в первый пакет, чтобы избежать ненужного ввода-вывода. Для агрегации такая оптимизация не нужна, поскольку на разделы разбиваются не все строки, а только те, которым не хватило отведенной памяти. Частые значения сами по себе с большой вероятностью встретятся в наборе строк достаточно рано, чтобы успеть занять место.
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT DISTINCT flight_id
FROM ticket_flights; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
HashAggregate (actual rows=150588 loops=1)
Group Key: flight_id
Batches: 5 Memory Usage: 4145kB Disk Usage: 98184kB
−> Seq Scan on ticket_flights (actual rows=8391852 loops=1)
(4 rows)В этом примере количество уникальных идентификаторов относительно велико, поэтому хеш-таблица не помещается в память целиком. Для выполнения запроса потребовалось пять итераций (Batches): одна по начальному набору данных и еще четыре по каждому из записанных на диск разделов.