
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Использование мьютекса зачастую намного проще, чем использование атомарных операций. Он позволяет создать критическую секцию, которая может быть выполнена не более чем одним потоком в любой данный момент времени. Кроме того, продвинутые мьютексы, такие как shared_lock, в некоторых случаях могут повысить эффективность, позволяя группе потоков исполнять критическую секцию, если мьютекс не захвачен в эксклюзивное использование.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector<int>& vec) {
int sum = 0;
for (int i = 0; i < vec.size(); ++i) {
sum += vec[i];
}
return sum;
}
Выполнение алгоритма в однопоточной программе:
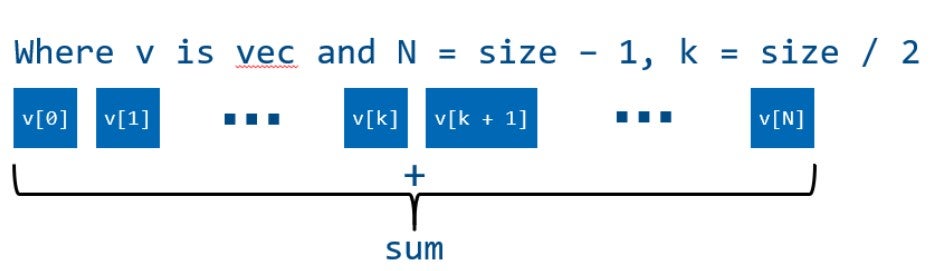
Для того чтобы исполнить алгоритм параллельно, нам нужно разделить его на независимые части, которые могут обрабатываться независимо друг от друга. Самый простой подход состоит в том, чтобы разделить обрабатываемые элементы на несколько частей и обработать каждую часть в своем собственном потоке.
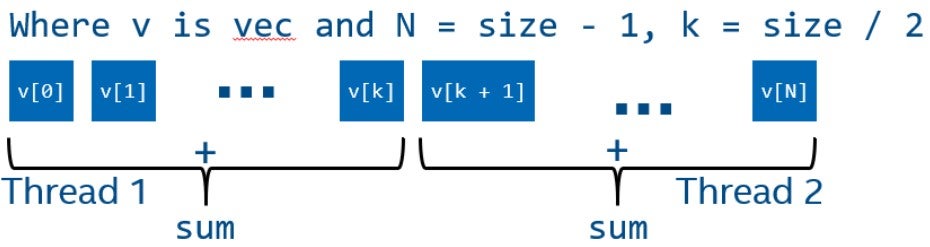
Однако в этом коде есть сложность, которая не позволяет нам просто разделить массив на две равные части и обрабатывать его параллельно. Все элементы суммируются в одну переменную, доступ к которой приведёт к data race, потому что один из потоков может записывать эту переменную одновременно с другим потоком, считывающим или записывающим в данную переменную.
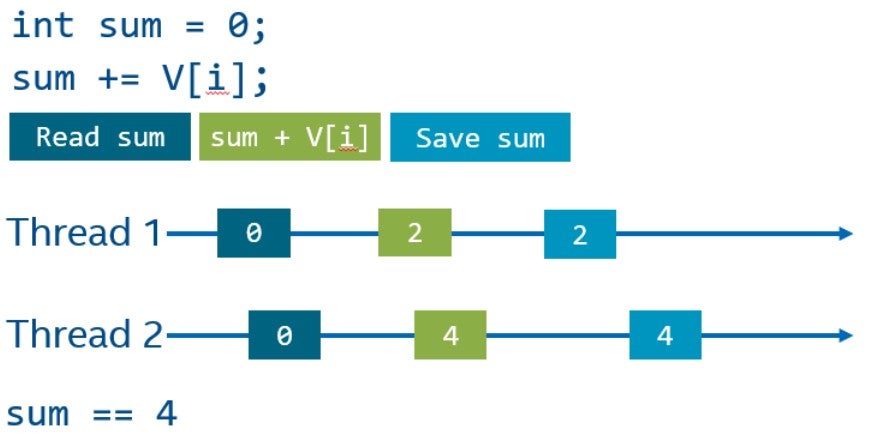
Составной оператор (оператор +=), по сути, состоит из трех операций: чтение из памяти, операция сложения и сохранение результата в памяти. Эти операции могут выполняться параллельно разными потоками, что может привести к неожиданным результатам. На следующем рисунке показан возможный порядок операций на временной шкале двух потоков. Основная сложность заключается в том, что оба потока могут не получить результат операций другого потока и перезаписать данные. C++ трактует такие ситуации как data race, и поведение программы, в таких случаях, не определено. Например, в результате мы можем получить четыре, ожидая шесть (как показано на рисунке). В худшем случае данные могут быть в непредсказуемом состоянии.
Существует много способов борьбы с data race, давайте рассмотрим самый простой из них - мьютекс.
Мьютекс имеет два основных интерфейса: блокировка (lock) и разблокировка (unclock). Блокировка переводит мьютекс в эксклюзивное владение, а разблокировка освобождает его, делая доступным для других потоков. Поток, который не может заблокировать мьютекс, будет остановлен, ожидая, пока другой поток освободит данный мьютекс.
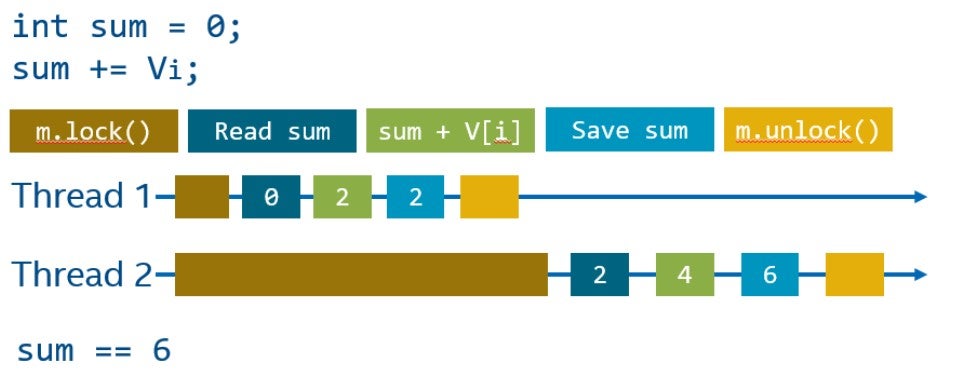
Код, защищенный мьютексом, также называется критической секцией. Важное наблюдение состоит в том, что второй поток, который не смог заблокировать мьютекс, не будет делать ничего полезного, во время того, пока первый поток находится в критической секции. Таким образом, размер критической секции может значительно повлиять на общую производительность системы.
Давайте попробуем сделать наш последовательный пример параллельным. Для создания потоков используем библиотеку <thread> из стандартной библиотеки C++.
int summarize(const std::vector<int>& vec) {
int num_threads = 2;
std::vector<std::thread> threads(num_threads);
int sum = 0;
std::mutex m;
auto thread_func = [&sum, &vec, &m] (int thread_id) {
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i) {
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе (т.е. вызван mutex.unlock())
std::lock_guard<std::mutex> lock(m);
sum += vec[i];
}
};
for (int thread_id = 0; thread_id < num_threads; ++ thread_id) {
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
}
std::cout << sum << std::endl;
for (int thread_id = 0; thread_id < num_threads; ++ thread_id) {
// Нам нужно дождаться всех потоков
// до разрушения std::vector<std::thread>
threads[thread_id].join();
}
return sum;
}
Запустив нашу программу, мы, вероятно, увидим неверный результат. Причина в том, что с помощью мьютекса мы защитили себя от data race при вычислении суммы, но основной поток может считывать переменную sum, в то время как другие потоки изменяют ее. Даже если мы защитим чтение с помощью мьютекса, это приведет к другой неочевидной сложности, называемой race condition: чтение, защищённое с помощью мьютекса, не гарантирует логическую корректность алгоритма. В нашем случае мы не дожидаемся полного завершения вычислений. Чтобы решить эту проблему, мы должны дождаться завершения потоков, прежде чем считывать результат. Однако, в данном случае мьютекс не требуется для чтения общей суммы , потому что синхронизация вычислений выполняется во время ожидания потоков (с помощью функции join).
int summarize(const std::vector<int>& vec) {
int num_threads = 2;
std::vector<std::thread> threads(num_threads);
int sum = 0;
std::mutex m;
auto thread_func = [&sum, &vec, &m] (int thread_id) {
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i) {
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
std::lock_guard<std::mutex> lock(m);
sum += vec[i];
}
};
for (int thread_id = 0; thread_id < num_threads; ++ thread_id) {
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
}
for (int thread_id = 0; thread_id < num_threads; ++ thread_id) {
// Нам нужно дождатьсявсех потоков до
// разрушения std::vector<std::thread>
threads[thread_id].join();
}
std::cout << sum << std::endl;
return sum;
}
Этот подход к распараллеливанию, очевидно, будет работать медленнее, чем последовательная версия, потому что для каждого sum += vec[i] мы берем мьютекс std:: lock_guard<std::mutex> lock (m). Таким образом, мы полностью упорядочиваем вычисления, т. е. разрешаем работать только одному потоку в любой момент времени. Чтобы избежать этого, мы можем сначала выполнить локальное суммирование в каждом потоке, а в конце вычислений добавить результат к глобальной сумме.
int sum = 0;
std::mutex m;
auto thread_func = [&sum, &vec, &m] (int thread_id) {
// Делим origin rangeитерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
int local_sum = 0;
for (int i = start_index; i < end_index; ++i) {
local_sum += vec[i];
}
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
std::lock_guard<std::mutex> lock(m);
sum += local_sum;
};
Этот простой пример демонстрирует, что параллельное программирование приводит к ряду проблем, которые невозможно наблюдать в последовательной программе. Более того, эти проблемы не всегда легко обнаружить, и они не всегда очевидны. Библиотеки, такие как oneTBB, упрощают параллельное программирование во многих аспектах. Для наглядности наш пример можно переписать с помощью parallel_reduce, который не требует каких-либо специальных синхронизаций и механизмов, чтобы избежать race conditions:
int summarize(const std::vector<int>& vec) {
int sum = tbb::parallel_reduce(tbb::blocked_range<std::size_t>{0, vec.size()}, 0,
[&vec] (const auto& r, int init) {
for (auto i = r.begin(); i != r.end(); ++i) {
init += vec[i];
}
return init;
}, std::plus<int>{});
return sum;
}
Хотя этот пример относительно небольшой, он показывает набор значительных упрощений, которые предоставляет oneTBB. Например, oneTBB автоматически создаст набор потоков, которые будут повторно использоваться между несколькими вызовами параллельных алгоритмов. Кроме того, parallel_reduce реализует все необходимые синхронизации, а пользователю достаточно описать требуемую операцию свертки, например, std::plus<int>.
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
Комментарии (13)


schulzr
22.10.2021 00:36Добрый день, спасибо за статью.
А какие существенные преимущества (или недостатки) tbb дает в сравнении с openmp? Для такого простого примера openmp выигрывает и в кол-ве строк кода и наглядности.
Спасибо

lamerok
22.10.2021 06:29+2Спасибо, можно код отформатировать в статье, чтобы он выглядел как код С++, а не просто текст, а то ну очень трудно воспринимается.

motoroller95
22.10.2021 10:12+2Блог компании Intel и такой текст это зашквар. Я ожидал большего. Но, как говорится, мои ожидания это мои проблемы. Минус

DistortNeo
23.10.2021 01:43+3Ладно текст. Но я впервые увидел, чтоб ещё и комментарии от "ботов" оставляли.

beskaravaev
22.10.2021 10:46+1Не хочу обидеть, но это не уровень блога компании. Я понимаю, что для Вас это первый пост, но тогда вам должны были помочь внутри компании. Если хотя бы код отформатировать как код, а не текст, то смотреться будет уже в разы лучше. Ещё можете давать статью на просмотр коллеге или нескольким, чтобы дал фидбэк, что добавить, убрать, изменить. Успехов Вам в следующих работах.

duke_alba
22.10.2021 19:40Формально мы не имеем права использовать один вектор в нескольких тредах, так как std:::vector не thread-ssfe.
В реальной жизни скорее всего параллельное чтение из вектора через разные итераторы - Ок, но тем не менее...

the_guy
09.11.2021 12:51Вообще говоря, в этом примере можно читать элементы вектора из разных потоков. Гонка данных возникает при: запись + запись или запись + чтение, в данном примере, потоки только читают данные из вектора.
duke_alba
09.11.2021 13:35Зная реализацию вектора в плюсаз, можно утверждать, что при чтении из вектора разными потоками гонки не будет. Но. В документации по С++ об этом не говорится. По этому формально воспринимая класс vector как чёрный ящик, читать разными тредами не защищаясь тоже нельзя.
korsetlr473
22.10.2021 20:13зачем нужна скрытая настройка в windows электропитания , гласящая "не переключать ядра последовательно" ?
derKodt1
09.11.2021 12:51А не проще ли просто определиться в каком месте код параллельный, а в каком последовательный - для данного примера просто из каждого потока получить промежуточные суммы, а потом их просто сложить?
hab_rr
Как раз то что искал, спасибо!