
Автор сообщества Фанерозой, биотехнолог, Людмила Хигерович.
Так или иначе, каждый человек, использующий масс-медиа, краем уха слышал о “биг дата”. Однако что это такое на самом деле, за границами ИТ мало кто представляет. И еще меньше людей знают о том, насколько сильно наш сегодняшний мир, каким мы его знаем, зависит от этого малопонятного термина. При этом речь идет не только об обработке больших потоков данных новостей или запросов браузера, или социальных сетей. Сегодня мы расскажем вам о том, как технологии Big Data помогают расширять границы науки.
Для понимания глубины процесса, нам придется ознакомиться с самим понятием “больших данных”, краем глаза поглядеть на историю этого явления, а также узнать, по каким принципам и правилам оно работает.

К сожалению или к счастью, в этом посте мы не будем рассматривать популярную тему с хранением и обработкой персональных данных пользователей и потребителей, хотя беглая пробежка по запросам поисковика показала, что это — наиболее частая сопутствующая тема в статьях о Big Data. Но не переживайте, краем глаза мы этого все же коснемся. Возможно…
Кроме того, мы попытаемся рассказать о данной сфере как можно более понятным языком. А это неминуемо ведет к упрощению некоторых понятий, равно как предмет в учебнике для школьников упрощает термины, использующиеся в Большой науке. Если вы сведущи в big data и заметили у нас неточность — милости просим дополнить нашу статью в комментариях. Если же нет — надеемся, что вы узнаете из нашей статьи что-то новое и интересное.

Рождение Колосса
Несмотря на то, что многие статьи в интернете в один голос твердят, что датой рождения термина big data является 3 сентября 2008 года, день выхода спецвыпуска британского научного и научно-популярного журнала Nature, посвященного целиком и полностью перспективам развития технологий работы с большими объемами данных, в том числе экспериментальных, реальное рождение термина произошло намного раньше.
В 1998 году главный ученый компании Silicon Graphics Джон Мэши сделал презентацию, в которой рассказывал о растущем потоке данных и необходимости разработки методов работы с ними. Там же он впервые употребил термин Big data в том смысле, в котором мы его применяем сейчас. Однако эта презентация была адресована узкому кругу коллег-информатиков, и потому широкой огласки не получила.
Однако фактически накопление и работа с данными, подходящими под этот термин, началась задолго до этого. В 40-х годах с развитием НТП и появлением новых вычислительных систем впервые в научных кругах стали обсуждаться проблемы накопления, хранения и извлечения данных. Тогда же вычислительные машины начали применяться в научных целях — сбор и обработка больших объемов статистической информации.
Для тех, кто скажет “какие, к черту, проблемы данных в 40-х годах?!”
Даже если не упоминать ранние механические приборы, в штучном формате создаваемые для автоматизации узких вычислений, включая трехсторонние счеты, “греческий компьютер” со встроенной астрономической картой, астролябией и шестереночным калькулятором, и программируемые с помощью веревок механические куклы и пылесосы эпохи Возрождения, вычислительные машины сопровождают человека уже больше столетия.


Первые же электронные ЭВМ разрабатывались еще в начале 20 века.
В 1930-х годах доктор Конрад Эрнст Отто Цузе, немецкий инженер, вел опытно-конструкторские работы по усовершенствованию громоздких и малофункциональных ЭВМ.
В 1941 он собрал первый компьютер, обладающий всеми свойствами современного компьютера: Z3, так называлось чудо техники, которое функционировало на базе телефонных реле и перфорированной пленки, а вычисления и программирование проводилось в формате двоичного кодирования. Во время Второй мировой войны он убедил военных дать ему возможность продолжать исследования, и даже открыл собственное производство ЭВМ. За три года он усовершенствовал свою машину, и на практике показал, что программируемые ЭВМ можно использовать в практических целях — с помощью Z3 проводились расчеты оптимальной формы крыльев для самолетов, а также обтекаемости ракет.

В 1946 году Цузе закончил работу над аппаратом Z4, а в 1948 опубликовал работу о созданном для него первом структурированном высокоуровневом языке программирования — Планкалкюль (нем. Plankalkül — «запланированные вычисления»).
С 1950 по 1960-е года Цузе и его фирма производили самые совершенные на тот момент компьютеры, постоянно улучшая производительность. К 1967 году его фирма поставила более 250 компьютеров, включая аппаратуру для оптической промышленности, авиа- и приборостроения, а также специальные измерительные и вычислительные устройства. Кроме того, Zuze KG создавали и специальные вычислительные машины, ставшие прообразом серверных вычислительных машин современных институтов прикладной математики и информатики, и первые компьютеры, использующие магнитные носители информации.

Позднее из-за финансовых трудностей компания Цузе была перекуплена компанией Siemens AG, а сам изобретатель стал ее консультантом в технических вопросах.
С распространением компьютеров, увеличились рост и объем обрабатываемой информации, как и объем хранимой информации, а вместе с тем — потребность в использовании компьютеров для извлечения и обработки еще большего объема информации. Замкнутый круг, с каждой итерацией (проходом), наращивающий собственный объем. В это же время, в 40 — 50-х годах прошлого века, впервые возникло такое понятие, как e-Science, на котором мы подробнее остановимся позже.
Таким образом появились большие вычислительные мощности, которые ставили на службу научно-технического прогресса. Однако с распространением и развитием ЭВМ их стали применять не только в целях промышленности и исследований, но и ради комфорта. Поначалу это выражалось в составлении прогнозов, проектировании зданий, эргономичной мебели и одежды, и, конечно же, интернета.

Big Data
Итак, что же сегодня представляет собой big data?
Big data или “большие данные” — общее название крупных пакетов данных разной природы, состава и характера. Они могут быть как структурированными (например, данные о температуре, давлении и влажности в определенном регионе за некий период времени), так и недифференцированным набором числовых и буквенных символов, чисел или даже файлов. Например, обычное содержимое вашего жесткого диска могло быть типичными big data, если бы подросло раз этак в тысячу)

В широком смысле — это в принципе все, что связано с производством, хранением и обработкой больших объемов данных. По объему биг дейтэ условно делят на данные определенной природы (данные пользователей, эмпирические данные определенного эксперимента, финансовые данные предприятия, данные Адронного коллайдера и т.п.), по региону (данные Европы, мировые данные), а также по другим критериям, необходимым для конкретной задачи.
Каков же объем данных, где граница больших данных и маленьких?
Проблема в том, что еще пару-тройку лет назад большим считался объем информации “весом” в терабайт (около 1000 гб), десять лет назад уже большинство компьютеров мира имело такой объем памяти как базовый (на отечественный рынок они пришли несколько позднее), пять лет назад появились игры, которые в принципе имели объем, сравнимый с одной десятой терабайта, а сами объемы жестких дисков и вычислительные мощности рядового ПК могли быть сравнимы с серверными шкафами институтов начала второго тысячелетия. Сегодня эти показатели выросли на порядки и еще продолжают расти.
Для наглядности приведем средние величины “мирового объема данных”, которые привели аналитики ISB (отечественной IT компании). Почему средние? Потому что никто точно не знает, и, вероятно, никогда не узнает реального объема всех данных нашей цивилизации.
- 2003 г. — 5 эксабайтов данных (1 ЭБ = 1 млрд гигабайтов)
- 2008 г. — 0,18 зеттабайта (1 ЗБ = 1024 эксабайта)
- 2015 г. — более 6,5 зеттабайтов
- 2020 г. — 40–44 зеттабайта (прогноз)
- 2025 г. — этот объем вырастет еще в 10 раз. (прогноз
При этом стоит помнить, что это не только данные в интернет-сети — значительную, если не превалирующую, часть этого объема занимают данные предприятий, финансовых рынков и бирж, законы и подзаконные акты государств, канцелярская и бюрократическая информация, а также научные данные.
В узком смысле, big data — это “железо”, физическое обеспечение работы с большими объемами информации, включающее разработку, создание, техническое обслуживание и программное обеспечение для оборудования, на котором осуществляется работа с big data.

Прикладная big data
В прикладном смысле, big data — это совокупность технологий (техники, алгоритмов, программного обеспечения, методов работы), которые так или иначе связаны с хранением, анализом, воспроизведением и изменением больших, чем обычно, объемов данных.
Больших, чем обычно — обычно в значении более крупных объемов по сравнению с необходимым для минимального функционирования человека, среднего предприятия или общества прошлых цивилизационных формаций.
Мы не уверены, насколько правомерно расшифровывать именно так, однако в СМИ часто прибегают к подобному определению на дилетантском уровне.
При этом информатики отмечают три необходимых аспекта, которые отличают технологии big data от всех прочих технологий:
- Обработка по-настоящему больших данных. Граница величины этого объема весьма плавающая, однако выборка в несколько сотен тысяч переменных в нее определенно входит.
- Быстрая обработка больших объемов поступающих данных. Быстрая — разумеется, по отношению к объему и текущей средней скорости вычислительных машин. Естественно, “быстро” сегодня — не такое же, как “быстро” десяток-другой лет, назад или вперед.
- Параллельная обработка больших объемов данных. При этом параллельность может быть как “горизонтальная” (разбиение обработки массива на разные узлы, одновременно выполняющие один и тот же алгоритм), так и “вертикальная” (обработка одних и тех же массивов разными алгоритмами одновременно).
Разумеется, эти три пункта — конвенциональны, и могут несколько различаться в зависимости от подхода и эксперта. Однако есть другая тройка, как принято считать, обязательная для определения технологии big data. Вероятно, как раз и выросшая на вышеназванных особенностях. Она получила название “Трех V”.
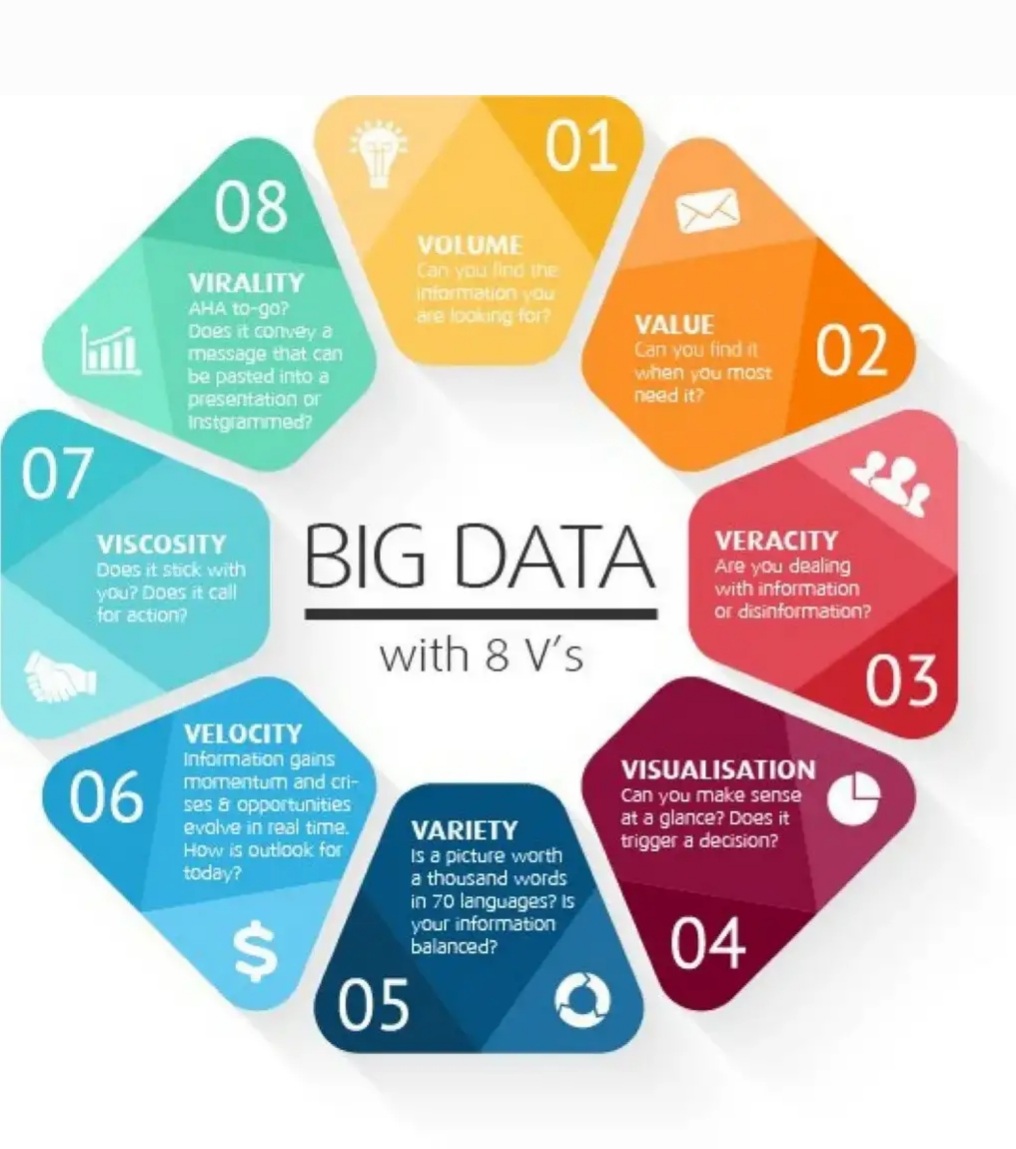
Три V или три основополагающих принципа работы с big data
Были впервые представлены в 2001 году компанией Meta Group, на тот момент одной из крупнейших фирм, специализирующихся на хранении и обработке информации. При этом, изначально VVV не соотносилось непосредственно с big data. Скорее, это было преподнесено в рамках технологических проблем накопления данных и как часть концепции “центрального хранилища данных” для предприятий, в силу своей работы оперирующих большими потоками информации.
Набор VVV состоит из следующих признаков.
- Volume — объем, в том числе физический объем хранимой информации.
- Velocity — скорость (вспоминаем велоцирапторов), в том числе скорость прироста объема данных, и скорость обработки данных.
-
Variety — различность (разнородность), в том числе разнородность данных в одном массиве или различная обработка в одном прохождении цикла обработки (итерации).
Со временем к трем основным V добавлялись и другие признаки, причем разнящиеся от эксперта к эксперту, от компании к компании. Такими “дополнительными V” стали:
-
Veracity — достоверность или проверяемость данных. Особенно актуально в эпоху фейков, а так же в рамках работы с научными данными.
-
Viability — “жизнеспособность” данных. Сложно сказать, жизнеспособность в плане возможности хранения данных или же их актуальность. Опять же, важно в эпоху быстротечной жизни и моментального устаревания.
-
Value — ценность, в первую очередь, коммерческая ценность. Кому интересно трекировать (отслеживать) Ваши перемещения на даче в сторону деревенского сортира? Другое дело — сводка по количеству купленных авиабилетов куда-нибудь в Египет.
-
Variability — изменчивость, в смысле переменчивость во времени и под воздействием обстоятельств. Очень важный признак при проведении пролонгированных (долговременных) исследований и предсказаний. Научных предсказаний, конечно же.
- Visualization — визуализация, то есть, наглядное представление. Не важно, в виде графика, диаграммы, наглядной плоскостной модели или математической формулы. Главное — показать структуру, динамику и алгоритм, если он есть.
Кроме множащихся V-шек, существуют и другие признаки big data:
-
Exhaustive — исчерпываемость. Этот параметр определяет, вся ли система захватывается или записывается или нет. Большие данные могут включать или не включать все доступные данные из источников.
-
Fine-grained and uniquely lexical — детальность и лексическая уникальность. Соответственно, доля конкретных данных каждого элемента в каждом собранном массиве или фрагменте, показывает, насколько элемент и его характеристики правильно проиндексированы или идентифицированы.
- Relational — относительность, соотносительность. Содержат ли собранные данные общие поля, пересекаются ли друг с другом или с ранее полученными данными, что позволит объединить их или сделать метаанализ различных наборов данных.
-
Extensional — расширяемость, экстенсивность. Показывает, насколько могут новые поля в каждом элементе собранных данных быть добавлены или изменены
-
Scalability — масштабируемость. Насколько быстро может увеличиться объем хранения данных в конкретной системе.
Особенности big data также формируют и принципы и подходы к работе с ними. Так же, как и признаков, основных принципов три:
Итак, мы кратенько пробежались по особенностям и принципам работы с big data, и даже затронули проблемы, с этим связанные (увеличение объема данных, опасность технического отказа, оптимизация доставки, обеспечение). Перейдем наконец к непосредственно научной стороне вопроса.

E-Science. Сухая наука
В естественных науках, особенно в биологии и смежных с ней, существует такое условное разделение, как “сухая наука” и “мокрая наука”. Особенно острым это разделение кажется в тех отраслях, где есть работа непосредственно с эмпирическими данными — т.е. данными, полученными непосредственно в ходе реального (не путать с виртуальным или мысленным) эксперимента или наблюдения in vivo (вживую, в природе).
Мокрая наука как раз и занимается сбором эмпирических данных и проведением опытов. “Мокрые ученые” выращивают плесень в пробирках и выводят бактерии, производящие лекарства, они же занимаются селекцией животных и растений и ездят в экспедиции в джунгли Амазонки. Другими словами, собирают материал в виде физических образцов и статистических данных.
Сухая наука — это та часть, которая занимается математической обработкой данных, полученных мокрой наукой. “Сухие ученые” сидят в теплых кабинетах, греясь от серверных шкафов и день за днем стирая глаза о монитор компьютера, систематизируя и обрабатывая “километры и килограммы” данных.
Конечно, на практике это далеко не всегда разные люди. Большая часть ученых успешно совмещает эти две роли, самостоятельно собирая материал и обрабатывая его, облекая в формат научного труда. Однако это не отменяет того факта, что существуют институты, специализирующиеся только на обработке научных данных.
Выше мы уже рассказывали, что машинная обработка научных сведений начала развиваться чуть ли не одновременно с появлением ЭВМ. Использование вычислительных машин в научных целях получило название e-Science.
E-Science или “электронная наука”
Это не информатика, как Вы могли бы подумать, а обработка больших пакетов электронных данных, полученных в ходе научных экспериментов и наблюдений. Впервые во всеуслышание термин был применен Джоном Тейлором, генеральным директором Управления науки и технологии Соединенного Королевства аж в 1999 году рамках презентации программы по финансированию научных исследований. Тогда же и было определено, что для обеспечения возможности использовать большие вычислительные мощности научными подразделениями требует и дополнительного финансирования, либо аренды институтами и исследовательскими группами чужих вычислительных мощностей. Так вплоть до сегодняшнего дня выстраиваются очереди к суперкомпьютерам крупнейших научно-технических институтов мира. Для справки, в мире сегодня всего 313 суперкомпьютеров, большая часть из которых расположена в Китае и США. При этом научно-исследовательских институтов по миру тысячи, в них сотни и тысячи кафедр и десятки тысяч подразделений и исследовательских групп. Теперь представьте длину очереди к каждому суперкомпьютеру!
Если вам кажется, что обработка научных данных не выглядит такой уж трудной задачей, то вот маленький пример.
Геном кишечной палочки состоит из одной кольцевидной хромосомы. Около 88% ее объема — кодирующие последовательности (“смысловые участки”, гены). Эти 88% содержат 4288 до 5500 цистронов (генов, т.е. участков, ответственных за синтез одного белка). Самый большой цистрон содержит 2383 кодона (триплета, ключевого для определенной аминокислоты), или 7149 пар нуклеотидов. При этом остальные 12 процентов генома не пусты — они не содержат генов, но выполняют регуляторные функции.

Если перевести весь геном кишечной палочки в вид буквенного кода по 4 основаниям-нуклеотидам, то получится примерно 4,6 Мб информации. По современным меркам сущий пустяк, однако какой полезный объем — для экономии места концы одних генов являются началом других!
Но кишечная палочка — модельный организм для исследования грамоотрицательных бактерий. Это значит, что она изучена настолько, насколько позволяет сегодняшний уровень науки. Именно с ней сравнивают геном всех исследуемых организмов. Поскольку каждый ее ген известен, а также известно большинство возможных модификаций (ведь даже в организмах разных людей кишечная палочка может значительно отличаться), ее геном используют как образец для секвенирования и анализа других геномов. Казалось бы, 4,6 мегабайт информации — не такой уж большой объем. Но 4,6 мегабайт в рамках генома — это от 4,5 до 5,6 миллиона пар нуклеотидов! Попробуй, сравни без машинной обработки! А ведь кишечная палочка — еще не самая “богатая” на гены бактерия…
Поэтому для сравнения участков ДНК были созданы специальные системы и библиотеки, о которых мы поговорим ниже.
E-Science выросла на необходимости обработки больших, подчас даже огромных объемов данных, хотя и не всегда big data в их прямом значении, подобных содержанию генома или данным о передвижении и распределении ареалов тысяч особей определенных групп птиц. Величина исходных данных и их однородность предъявляют определенные требования к своей обработке. Так, для вычислений и анализа используются сетевые среды с высоким горизонтальным распределением — то есть, увеличение производительности достигается за счет наращивания технических единиц обработки (“процессоров” или вовлеченных серверов). Этот метод также называют грид-вычислением.

E-Science однако не сводится к одной только обработке статистических данных. Большая часть исследовательской деятельности в области электронной науки сосредоточена на разработке новых вычислительных инструментов и инфраструктур для поддержки научных открытий. Из-за сложности программного обеспечения и требований к внутренней инфраструктуре в проектах электронной науки обычно участвуют большие группы, которые разрабатываются и управляются исследовательскими лабораториями, крупными университетами или правительствами.
Для удобства работы e-Science консолидировалась в инфраструктуры или консорциумы, разделенные по региону, специализации в методах обработки и преимущественному направлению науки. Крупнейшими консорциумами являются Worldwide LHC Computing Grid, федерация с различными партнерами, включая Европейскую грид-инфраструктуру, Open Science Grid и Nordic DataGrid Facility.
Open Science Grid — крупнейший открытый ресурс, объединяющий интерфейсы более чем 100 общенациональных научных кластеров, а также 50 интерфейсов с географически распределенными кэшами хранения и 8 сетей кампусов университетов и институтов мира. Области науки, пользующиеся преимуществами Open Science Grid, включают:
- астрофизику, гравитационную физику, физику высоких энергий, нейтринную физику, ядерную физику;
- молекулярную динамику, материаловедение, сопромат, информатику, компьютерную инженерию, нанотехнологии;
- структурную биологию, вычислительную и сравнительную биологию, геномику, протеомику, медицину;
- создание нейронных сетей и моделирование с помощью искусственного интеллекта, генерационные модели сложных систем.
Кроме того, есть отдельные специализированные сервера международного уровня, позволяющие быстро работать с определенными видами научных данных, сравнивая и проводя относительно “простые” статистические вычисления внутри системы. Так, например, существует система Blast, позволяющая быстро найти в библиотеке нужный участок ДНК, сравнить секвенированный в ходе опыта кусок генома с уже внесенными в библиотеку или даже найти последовательность, кодирующую определенный белок. Также не стоит забывать о ресурсах вроде Google genomics, которые не специализировались изначально на работе с научными базами данных, но при повышении спроса организовали открытые библиотеки. Есть и другие подобные ресурсы для биохимии белков и ферментов, а также открытые библиотеки химических веществ, и даже электронные каталоги небесных тел, во избежание переоткрывания планет и для облегчения наблюдений за космической динамикой.
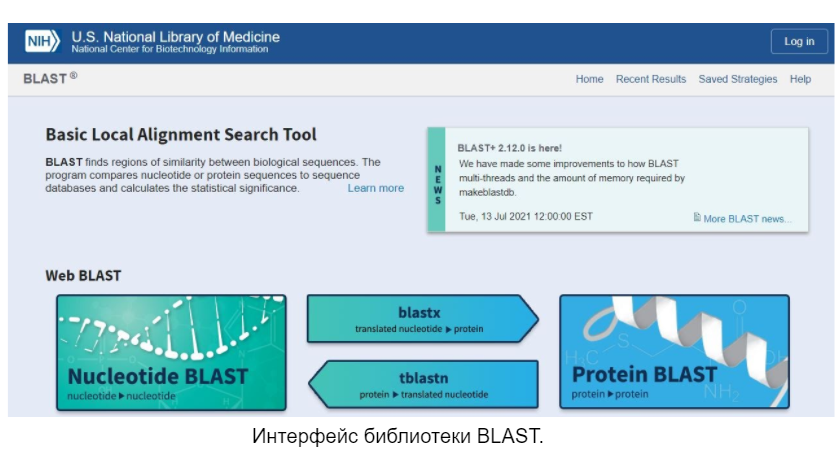
Вот такая она, электронная наука и большая дата. Надеемся, что вам было интересно.
Всего хорошего и не болейте!

«China: Big Data Fuels Crackdown in Minority Region: Predictive Policing Program Flags Individuals for Investigations, Detentions». hrw.org. Human Rights Watch. 26 February 2018. Retrieved 4 August 2018.
Min Chen, Shiwen Mao, Yin Zhang, Victor C.M. Leung. Big Data. Related Technologies, Challenges, and Future Prospects. — Spinger, 2014. — 100 p.
Bell, G.; Hey, T.; Szalay, A. (2009). «COMPUTER SCIENCE: Beyond the Data Deluge». Science. 323 (5919): 1297–1298
Bohle, S. «What is E-science and How Should it Be Managed?» Nature.com, Spektrum der Wissenschaft (Scientific American), www.scilogs.com/scientific_and_medical_libraries/what-is-e-science-and-how-should-it-be-managed
«DNAstack tackles massive, complex DNA datasets with Google Genomics». Google Cloud Platform. Retrieved 1 October 2016.
«The Government and big data: Use, problems and potential». Computerworld. 21 March 2012. Retrieved 12 September 2016.
Леонид Черняк. Свежий взгляд на Большие Данные // Открытые системы.СУБД. — 2013. — № 7. — С. 48–51.
С. Протасов. Что такое Big data? Постнаука [электронный ресурс] URL postnauka.ru/faq/46974
Большие данные. System engineering thinking Wiki [электронный ресурс] URL sewiki.ru/index.php?title=%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D0%B5_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5&oldid=3075
Комментарии (13)

webdi
12.11.2021 14:17+4О, Фанерозой пишет о bigdata на Хабре и почти ни слова о биологии.)
Интересно, много базовых сведений простым языком.

mattroskin
12.11.2021 15:13+3Обеденній перерыв потрачен не зря ) Тема, казалось бы, не новая, но изложена интересно. НО где же про биологию? Давайте продолжение, биология деиствительно сейчас активно математизируется и там происходит масса интересного.

phanerozoi_evidence Автор
12.11.2021 15:16У нас очень много тем по биологии. Но в данном случае, мы хотели показать, что можем писать и близко к теме it, а не только исключительно по биологическим дисциплинам.

VoronaDragon
14.11.2021 19:53+1Именно))
Биология сейчас математизируется, как никогда, особенно сфера генетики. Возможно, в следующий раз попытаемся также также рассказать о биоинформатике - математической и компьютерной части биологии.))

Holmogorov
12.11.2021 15:15+2Спасибо, интересная статья. Про Цузе я, кстати, писал еще в 2001 году: https://holmogorov.ru/pub/raichcomputers/



Dzziper
14.11.2021 19:20+2Выбрали интересную тему для разбора, а можно по-подробнее на тему биологии?
Ryppka
Правда что ли?!
phanerozoi_evidence Автор
Грамотрицательных. У меня в словаре были грамположительные, а отрицательных не было (автозамена). Произошла описка. Публиковал статью и с компьютера и с телефона. Спасибо, что заметили и сообщили.
phanerozoi_evidence Автор
Грамотрицательных. Описка. Спасибо.