
Тестировать будем следующие сценарии:
- Поиск отдельной записи по первичному ключу с вычиткой одной дочерней коллекции
- Поиск отдельной записи по первичному ключу с вычиткой нескольких дочерних коллекций
- Выборка нескольких записей с вычиткой одной дочерней коллекции для каждой записи
- Выборка нескольких записей с вычиткой нескольких дочерних коллекций для каждой записи
- Выборка всех записей из таблицы с вычиткой одной дочерней коллекции для каждой записи
- Выборки всех записей из таблицы с вычиткой всех дочерних коллекций
Разделение на сценарий с одной дочерней коллекцией и несколькими нужен для понимания, насколько влияет количество соединений (JOIN) по ключу в одном запросе на конечный результат. И насколько уменьшение производительности зависит от типа ключа.
С помощью этих сценариев сравним три варианта ключей:
- Автоинкремент
- Последовательный GUID
- Непоследовательный GUID
Для этого понадобится три набора таблиц, каждый из которых состоит из главной таблицы и 5 таблиц для дочерних записей.
Тестирование будем проводить, как и в предыдущей статье, с использованием Entity Framework 6.1.3. База данных — Microsoft SQL Server 2014 Developer Edition (64 bit). В каждую из главных таблиц добавим по 10000 записей, где у каждой записи будет 5 дочерних коллекций, содержащих по 10 элементов. Таким образом, в таблицах дочерних коллекций будет содержаться по 100000 строк.
Исходный код тестовой программы можно найти здесь.
Ниже приведены диаграммы полученных результатов. Для удобства сравнения на них указаны проценты, где за 100% берется минимальный результат из всех вариантов.
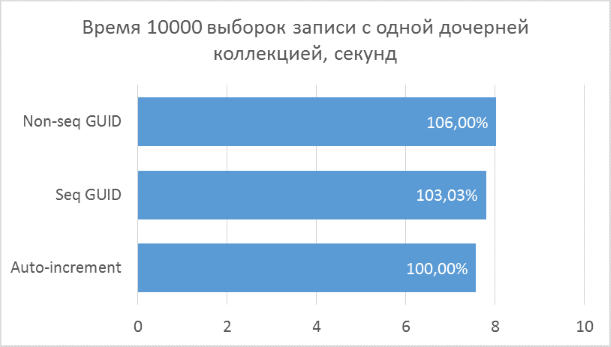

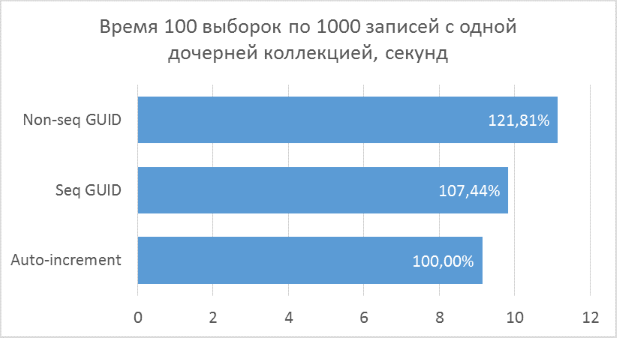
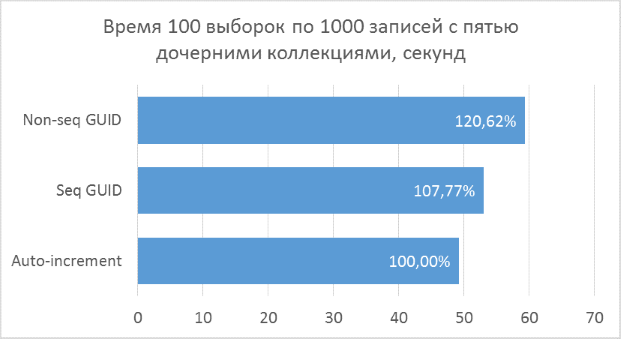
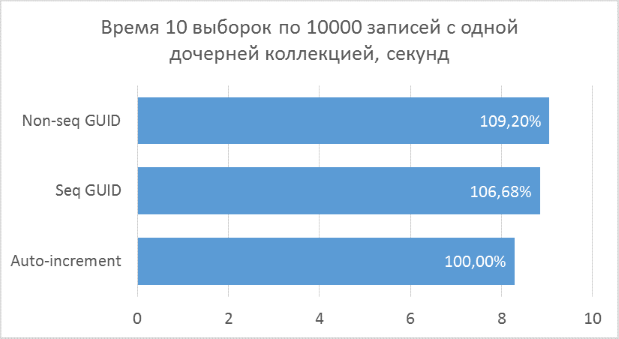
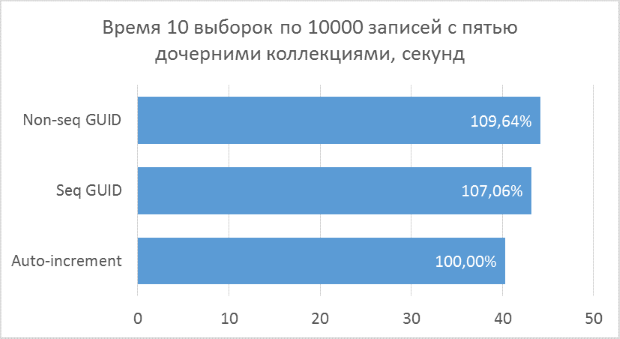
Полученные результаты показывают, что операции выборки, оперирующие целочисленными ключами, конечно же, быстрее, чем в случае с GUID. Но разница в производительности между последовательным GUID и автоинкрементом не настолько велика, чтобы говорить у существенном проигрыше при выборе GUID.
Также следует отметить, что процентная разница времени выполнения сохраняется при увеличении количества соединений в одном запросе. Чего, на самом деле, и стоило ожидать, но убедиться нужно было.
Непоследовательный GUID показал в некоторых случаях заметно худшие результаты, что, опять же, закономерно. На практике разница между ним и остальными двумя вариантами может оказаться еще больше — в тех случаях, когда база данных не может быть полностью закеширована в оперативной памяти и понадобится большой объем чтений с диска для получения всех соседних дочерних записей (подобный тест был описан в предыдущей статье для вставки записей). Соответственно, использовать такой вариант первичного ключа на практике не имеет смысла.
Несмотря на то, что этот тест показал небольшую разницу между автоинкрементом и последовательным GUID, я бы не стал рассматривать последний, как вариант, который можно бездумно использовать во всех ситуациях. GUID занимает больше места, особенно в текстовом представлении. Если в системе есть преобразование объектов в текстовый формат (JSON, XML), и порция объектов, преобразуемая за один раз, содержит большое количество идентификаторов — разница в объеме по сравнению с целочисленными ключами может оказаться существенной. Обратное преобразование (десериализация) для GUID намного медленнее, чем для числа, но, на мой взгляд, этой разницей можно пренебречь. Это время все равно очень мало — на моей машине на парсинг ста тысяч GUID-ов уходит 60 миллисекунд, против 12 миллисекунд для целых чисел. Более ощутимой проблемой при использовании уникальных идентификаторов может оказаться то, что ими гораздо сложнее оперировать при поддержке и отладке, чем целыми числами.
Общий вывод по итогам обеих статей я бы сформулировал так: если по каким-либо причинам, не связанным с производительностью, есть надобность использовать GUID в качестве первичного ключа, то из возможных реализаций следует выбрать последовательный, генерируемый на клиенте. При этом, в большинстве случаев, насчет потери производительности операций чтения можно не переживать. Основная проблема GUID в плане производительности выборки не в том, что процессору нужно больше действий делать для сравнения (это, скорее всего, оптимизировано, да и сравнений при поиске по ключу происходит немного, если это не скан), а в том, что он занимает в 4 раза больше обычного int, соответственно меньшее количество страниц индексов и данных может быть закешировано в том же объеме оперативной памяти. Если в вашей базе индексы первичных и внешних ключей занимают десятки процентов от общего объема базы и объем активно используемых данных не может быть полностью закеширован, причем нет возможности увеличивать объем оперативной памяти — имеет смысл подумать о более «легких» ключах. Но такая ситуация мне кажется достаточно редкой. Также следует обратить внимание на потенциальные проблемы при сериализации/десериализации, упомянутые выше. Однако, соответствующий случай, который я видел на практике, был не столько проблемой самого GUID, сколько проблемой неправильного дизайна API — вычитывалась вся коллекция за один раз без ограничений, пейджинга и т.д.
Комментарии (26)

kuber
11.10.2015 13:21+5У Guid есть еще несколько преимуществ:
1. Повышенная устойчивость к перебору, что очень хорошо сказывается на безопасности приложения;
2. Уникальность в пределах планеты очень сильно облегчает объединение данных из различных источников.
У огромного количества проектов нет необходимости в безумной оптимизации скорости выполнения запросов к БД и в этом случае предпочтение отдается удобству взаимодействия с БД. В реальности какая разница получите вы ответ через 200 мс или через 220 мс? Если же ваш проект действительно высоконагруженный и критичен к минимальным задержкам, то вам не то, что от Guid придется отказаться, но и от Entity Framework.
YuriyIvon
11.10.2015 20:33Про преимущества GUID я писал в первой статье, в том числе и про эти. В тех случаях, когда этих преимуществ не требуется, можно обойтись целочисленным ключом.
А что касается безумной оптимизации — то я тут полностью согласен, чаще всего она не нужна )

m08pvv
12.10.2015 10:05Уникальность в пределах планеты очень сильно облегчает объединение данных из различных источников.
Не то чтобы уникальность, просто очень маленькая (даже мизерная) вероятность коллизии.
mird
12.10.2015 11:46+1Нет у гуид повышенной устойчивости к перебору. Особенно у Sequential. Если вам нужна криптографическая стойкость, нужно использовать другие алгоритмы. А следующий гуид вполне можно предсказать.

realbtr
11.10.2015 13:27+1Есть способ генерации ключевого поля без гуида, но при этом полностью получая преимущества гуида.
Этот способ заключается в том, что каждый источник генерации автоинкремента имеет собственный идентификатор, который известен всегда и статичен для данного клиента (статичность — непринципиальна, в общем-то, одно и то же устройство/экземпляр клиента может получать разовые идентификаторы сессии для каждого соединения)
Проще говоря, мы имеем набор методов генерации автоинкремента на основе ключа клиента или ключа разовой сессии клиента из множества конкурентных.
Что нам необходимо? Чтобы сгенерированный клиентом ключ гарантированно не пересекался со сгенерированным в это же время ключом на другом клиенте. То есть мы не хотим коллизии.
Решение проблемы в том, что ключ имеет форму комбинации/смеси (ключ клиента/сессии, известное последнее значение ключа, которое уже занято)
GUID это один из способов генерации гарантированно уникальных ключей, с огромным запасом избыточности.
В практических целях оптимизации, достаточно использовать либо постоянный ключ клиента (который неким образом связан с авторизацией этого клиента) и простой автоинкремент значений ключа в рамках этого клиента, либо использовать номер одновременной сессии, который выдается сервером каждому клиенту для его работы.
Почему процесс генерации бывает медленным? Потому что необходимо произвести определенный протокол обмена данными между клиентом и сервером для того, чтобы и клиент и сервер знали необходимый ключ
Когда клиент генерирует большое количество данных, очевидно, что проще выдать частичный ключ клиенту, а клиент сможет спокойно инкрементировать этот ключ в определенном (заранее известном) диапазоне, не создавая даже шанса для коллизий.
Когда клиент генерирует ограниченное количество записей за короткое время, нет никакой проблемы генерировать необходимые ключи на сервере и возвращать их клиенту в ответ на операцию записи (для того, чтобы клиент знал, какие данные он только что записал).
На практике мы использовали GUID в своих системах, но я к ним отношусь крайне скептически и считаю довольно расточительным механизмом.
Я бы доработал GUID как универсальный механизм как минимум до генерации серии GUID необходимой емкости, в которой легко догенерировать клиентскую часть.
Впрочем, может быть, кто-то знает, как подобное сделать в существующих библиотеках?
osmirnov
11.10.2015 16:19+1Странно, что никто не упомянул алгоритм генерации ObjectId из MongoDB:
ObjectId is a 12-byte BSON type, constructed using:
a 4-byte value representing the seconds since the Unix epoch,
a 3-byte machine identifier,
a 2-byte process id, and
a 3-byte counter, starting with a random value.YuriyIvon
11.10.2015 20:41+1Упомянуть-то можно — просто еще один алгоритм генерации последовательного GUID. Принципиально нового он ничего не вносит. Реализовывать аналог с тем же алгоритмом и размером для того же MS SQL или Oracle может оказаться не оправдывающей себя задачей.

pred8or
11.10.2015 16:38-6Строго говоря, в статье обсуждаются суррогатные ключи. И, по хорошему, использовать их в качестве первичных нехорошо, потому что ведёт к нарушению семантики данных. И конечно же, это повсеместно игнорируется
michael_vostrikov
11.10.2015 17:00+9На форуме пользователь по имени Вася Пупкин отправил другому пользователю по имени Вася Пупкин сообщение «Привет, тезка», причем умудрился нажать кнопку «Отправить» 2 раза подряд за одну секунду. Какие семантически значимые свойства сущностей «Пользователь» и «Сообщение» вы бы выбрали в качестве их естественных ключей?

Komzpa
11.10.2015 22:35-4Например, никнейм (для «несерьёзных» проектов) / номер телефона (для «серьёзных» проектов) и timestamp.
В нормальных базах у timestamp разрешение в 1 микросекунду, www.postgresql.org/docs/9.4/static/datatype-datetime.html
lair
12.10.2015 00:31+1Номер телефона не является натуральным идентификатором сущности «человек». Собственно, ничто не является. Никнейм пользователя является таким идентификатором только в том случае, если система не позволяет их менять.

VolCh
12.10.2015 08:59+2Папиллярные узоры, код ДНК — вроде как являются. Насчёт никнейма — в принципе, если система гарантирует уникальность, то тоже является идентификатором, правда не сущности «человек», а сущности «пользователь», даже если можно их менять, при условии, что нам не нужно поддерживать внешнюю ссылочную целостность. Но в целом, да — как только дело касается физических лиц, очевидное решение — суррогатный ключ, по крайней мере пока каждому при рождении не будет присваиваться уникальный код. Но это тоже суррогатный ключ, просто внешней системы :)
kuber
12.10.2015 06:54+2>> В нормальных базах у timestamp разрешение в 1 микросекунду
И что это меняет? Мне неизвестна ни одна СУБД, которая бы гарантировала, что в один момент времени в БД не вставят несколько записей.Komzpa
12.10.2015 08:47-2Во-первых, unique constraint на поле с таймстампом это вполне гарантирует.
Во-вторых, это автоматически реализует антифлуд.VolCh
12.10.2015 09:15+2Во-первых, unique constraint на поле с таймстампом это вполне гарантирует.
Они гарантируют, что в базе не будет двух записей с одинаковым первичным ключом (что и так гарантируется по определению первичного ключа), но не гарантирует отсутствие коллизий при сохранении, а значит пользователи могут получать ошибки типа «извините, Вася Пупкин, но ваша запись не может быть сохранена, поскольку другой Вася Пупкин в эту микросекунду уже сохранил другую». Вообще у сообщений нет естественного первичного ключа. Даже полное сообщения (все заголовки и тело) с таймстампом с точностью до наносекунды таким ключом не является — в общем случае они могут дублироваться.
А с точки зрения «автоматического антифлуда» особой разницы нет может пользователь генерировать в микросекунду одно сообщение или десять. Ну и далеко не во всех системах требуется антифлуд, а где требуется лучше его реализовывать отдельным явным конфигуриремым фильтром.
lair
12.10.2015 00:32+3И, по хорошему, использовать их в качестве первичных нехорошо, потому что ведёт к нарушению семантики данных.
Какой-то авторитетный источник для подкрепления этого заявления найдется?
Scratch
Можно половину гуида делать инкрементной, а половину случайной. Так и сортируемость будет и гарантия непересекаемости
YuriyIvon
Алгоритм, который использует UuidCreateSequential() гарантирует непересекаемость (в предыдущей статье описано). Эта же функция используется SQL сервером для получения результата NEWSEQUENTIALID()
kuber
>> Так и сортируемость будет…
Сортировка по первичному ключу? Не учите людей плохому.
Scratch
И что тут плохого?
kuber
Отвертку можно использовать, чтобы забивать гвозди? В принципе можно, но люди предпочитают для этого использовать молоток. Роль первичного ключа не сортировку обеспечивать, а однозначную идентификацию запись в БД. Если вам нужна сортировка, то для этого надо использовать другие поля.
TimsTims
Вы так и не ответили на вопрос, что плохого в кластеризации по первичному ключу, но сообщили о полезном свойстве первичного ключа — «однозначная идентификация».
Мне, например, тоже непонятно, чем плох первичный ключ с кластеризацией. Статья, по моему, как-раз про это — сравнение двух скоростных методов — GUID и инкремент по кластерному ключу.
kuber
Ох, ты. Из-за какой-то мелочи еще и в карму минусов поднакидали. Молодцы!
TimsTims
Похоже, ответа на любопытный вопрос не будет…
kuber
Понимание приходит с опытом.
vlivyur
Ничем. Но это самый последний вариант для кластерного ключа, когда остальные уже были отброшены (вместе с вариантом «не использовать его в принципе»).