
Ниже приведены преимущества каждого из вариантов.
Автоинкремент
- Занимает меньший объем
- Теоретически, более быстрая генерация нового значения
- Более быстрая десериализация
- Проще оперировать при отладке, поддержке, так как число гораздо легче запомнить
GUID
- При репликации между несколькими экземплярами базы, где добавление новых записей происходит более, чем в одну реплику, GUID гарантирует отсутствие коллизий
- Позволяет генерировать идентификатор записи на клиенте, до сохранения ее в базу
- Обобщение первого пункта — обеспечивает уникальность идентификаторов не только в пределах одной таблицы, что для некоторых решений может быть важно
- Делает практически невозможным «угадывание» ключа в случаях, когда запись можно получить, передав ее идентификатор в какой-нибудь публичный API
Фраза «теоретически, более быстрая генерация нового значения» звучит неубедительно. Подобные соображения всегда лучше подкреплять практическими примерами. Но прежде чем писать программу для тестирования, рассмотрим, какие варианты реализации первичного ключа есть с каждым из этих двух типов.
GUID можно генерировать как на клиенте, так и самой базой данных — уже два варианта. К тому же, в MS SQL есть две функции для получения уникального идентификатора — NEWID и NEWSEQUENTIALID. Давайте разберемся, в чем их отличие и может ли оно быть существенным на практике.
Привычная генерация уникальных идентификаторов в том же .NET через Guid.NewGuid() дает множество значений, не связанных друг с другом никакой закономерностью. Если ряд GUID-ов, полученных из этой функции, держать в отсортированном списке, то каждое новое добавляемое значение может «попадать» в любую его часть. Функция NEWID() в MS SQL работает аналогично — ряд ее значений весьма хаотичен. В свою очередь, NEWSEQUENTIALID() дает те же уникальные идентификаторы, только каждое новое значение этой функции больше предыдущего, при этом идентификатор остается «глобально уникальным».
Если использовать Entity Framework Code First, и объявить первичный ключ вот таким образом
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public Guid Id { get; set; }
в базе данных будет создана таблица с первичным кластерным ключом, который имеет значение по умолчанию NEWSEQUENTIALID(). Сделано это из соображений производительности. Опять же, в теории, вставлять новое значение в середину списка более накладно, чем добавление в конец. База данных, конечно же, не массив в памяти, и вставка новой записи в середину списка строк не приведет к физическому сдвигу всех последующих. Тем не менее, дополнительные накладные расходы будут — разделение страниц (page split). По итогу также будет сильная фрагментация индексов, которая может отразиться на производительности выборки данных. Неплохое объяснение того, как происходит вставка данных в кластеризованую таблицу, можно найти в ответах форума по этой ссылке.
Таким образом, для GUID мы имеем 4 варианта, которые стоит проанализировать в плане производительности: последовательный и непоследовательный GUID с генерацией на клиенте, и та же пара вариантов, но с генерацией на стороне базы. Остается вопрос, как получать последовательные GUID на клиенте? К сожалению, стандартной функции в .NET для этих целей нет, но ее можно сделать, воспользовавшись P/Invoke:
internal static class SequentialGuidUtils
{
public static Guid CreateGuid()
{
Guid guid;
int result = NativeMethods.UuidCreateSequential(out guid);
if (result == 0)
{
var bytes = guid.ToByteArray();
var indexes = new int[] { 3, 2, 1, 0, 5, 4, 7, 6, 8, 9, 10, 11, 12, 13, 14, 15 };
return new Guid(indexes.Select(i => bytes[i]).ToArray());
}
else
throw new Exception("Error generating sequential GUID");
}
}
internal static class NativeMethods
{
[DllImport("rpcrt4.dll", SetLastError = true)]
public static extern int UuidCreateSequential(out Guid guid);
}
Обратите внимание на то, что без специальной перестановки байт, GUID нельзя отдавать. Идентификаторы получатся корректные, но с точки зрения SQL сервера — непоследовательные, поэтому никакого выигрыша по сравнению с «обычным» GUID даже теоретически не получится. К сожалению, ошибочный код приведен во многих источниках.
К списку остается добавить пятый вариант — автоинкрементный первичный ключ. Других вариантов у него нет, так как на клиенте его генерировать нормально не получится.
С вариантами определились, но есть еще один параметр, который следует учесть при написании теста — физический размер строк таблицы. Размер страницы данных в MS SQL — 8 килобайт. Записи близкого или даже большего размера могут показать более сильный разброс производительности для каждого из вариантов ключа, чем на порядок меньшие записи. Чтобы обеспечить возможность варьировать размер записи, достаточно добавить в каждую из тестовых таблиц NVARCHAR поле, которое затем заполнять нужным количеством символов (один символ в NVARCHAR поле занимает 2 байта).
Тестирование
По этой ссылке находится проект с программой, которая была разработана с учетом указанных выше соображений.
Ниже приведены результаты тестов, которые выполнялись по такой схеме:
- Всего три серии тестов с длиной текстового поля в записи 80, 800 и 8000 байт соответственно (количество символов в тестовой программе будет в два раза меньше в каждом из случаев, так как один символ в NVARCHAR занимает два байта).
- В каждой из серий — по 5 запусков, каждый из которых добавляет по 10000 записей в каждую из таблиц. По результатам каждого из запусков можно будет проследить зависимость времени вставки от количества строк, уже находящихся в таблице.
- Перед началом каждой из серий таблицы полностью очищаются.
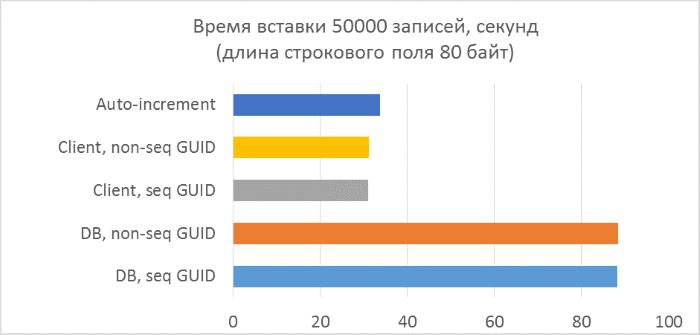
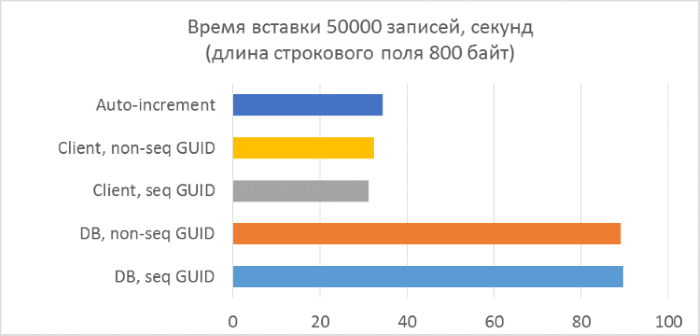
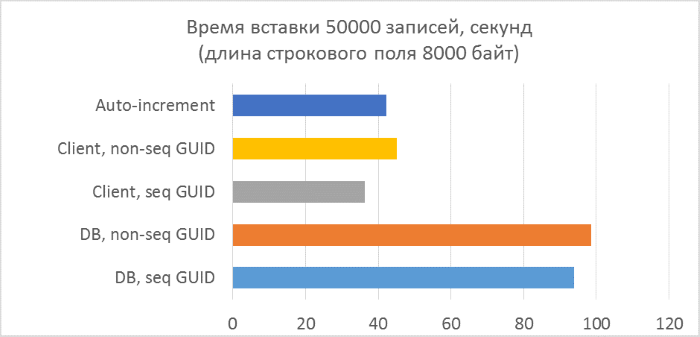
И результаты с разбивкой по каждому запуску:
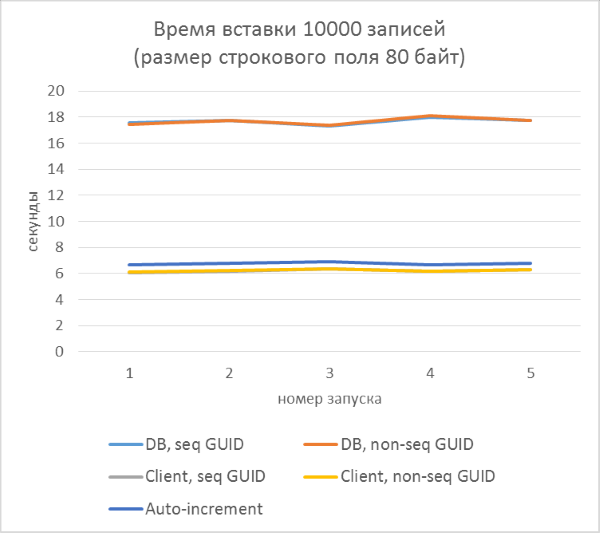
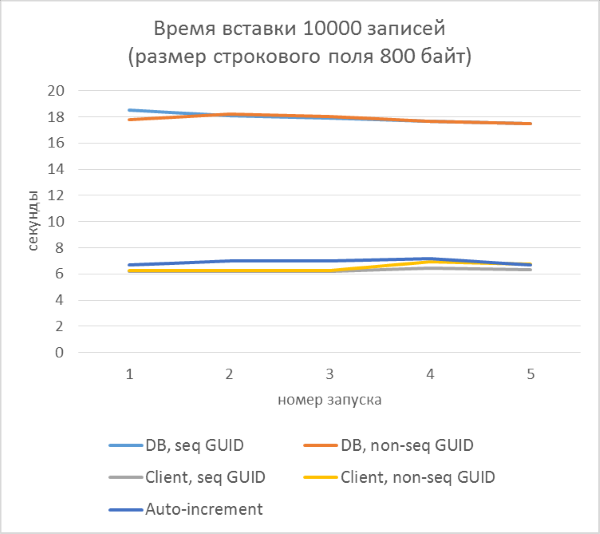
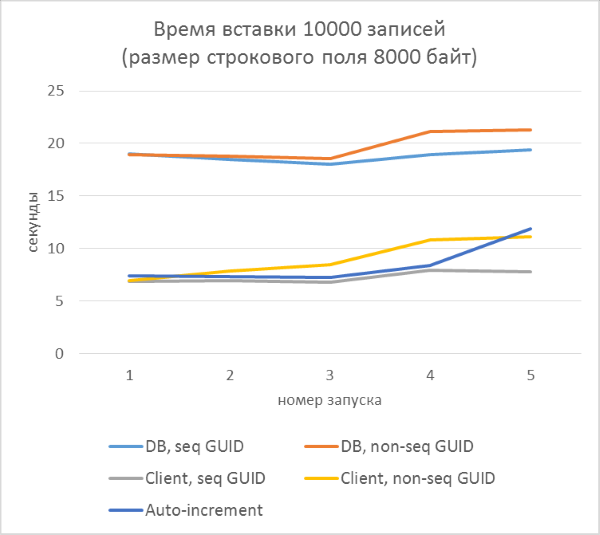
Из результатов сразу видно, что:
- Использование генерации GUID на стороне базы данных в разы медленнее, чем генерации на стороне клиента. Это связано с затратами на чтение только что добавленного идентификатора. Детали этой проблемы рассмотрены в конце статьи.
- Вставка записей с автоинкрементным ключом даже немного медленнее, чем с GUID-ом, присвоенным на клиенте.
- Разницы между последовательным и непоследовательным GUID практически не видно на небольших записях. На больших записях разница появляется с ростом количества строк в таблице, но она не выглядит существенной.
Над последним пунктом стоит задуматься. Из-за чего может происходить замедление работы при использовании непоследовательных GUID-ов, кроме как частого разделения страниц? Скорее всего — из-за частого чтения «случайных» страниц с диска. При использовании последовательного GUID, нужная страница всегда будет в памяти, так как добавление идет только в конец индекса. С непоследовательным будет много вставок в произвольные места индекса, и не во всех случаях нужные страницы будут находиться в памяти. Чтобы проверить, насколько такое случайное чтение влияет на результаты тестов, искусственно ограничим объем памяти SQL Server так, чтобы ни одна таблица не могла полностью уместиться в памяти.
Грубый расчет показывает, что в тесте с длиной строки 4000 символов (8000 байт) при количестве записей 50000 тысяч, размер таблицы будет не менее 400Мб. Ограничим допустимый объем памяти SQL Server до 256Мб и повторим этот тест.
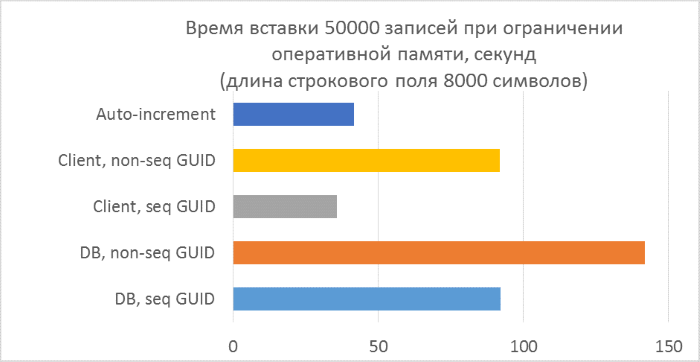
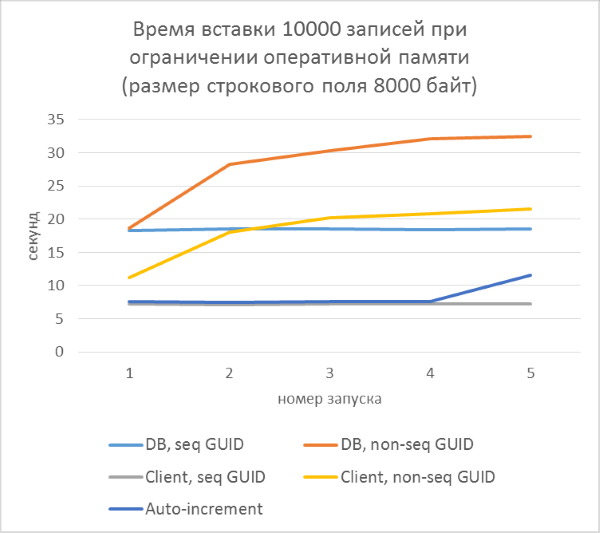
Как и следовало ожидать, вставка в таблицы с непоследовательными GUID-ами в ключах заметно замедлилась, и замедление увеличивается с ростом количества строк в таблице. В то же время, производительность вставки для последовательных GUID-ов и автоинкремента остается стабильной.
Выводы
- Если по каким-либо критериям, указанным в начале статьи, возникла надобность использовать GUID в качестве первичного ключа — наилучшим вариантом в плане производительности будет последовательный GUID, сгенерированный для каждой записи на клиенте.
- Если создание GUID на клиенте по каким-либо причинам неприемлемо — можно воспользоваться генерацией идентификатора на стороне базы через NEWSEQUENTIALID(). Entity Framework делает это по умолчанию для GUID ключей, генерируемых на стороне базы. Но следует учесть, что производительность вставки будет заметно меньше по сравнению с созданием идентификатора на стороне клиента. Для проектов, где количество вставок в таблицы невелико, эта разница не будет критична. Еще, скорее всего, этот оверхед можно избежать в сценариях, где не нужно сразу же получать идентификатор вставленной записи, но такое решение не будет универсальным.
- Если в вашем проекте уже используются непоследовательные GUID, то следует задуматься об исправлении, если количество вставок в таблицы велико и размер базы значительно больше, чем размер доступной оперативной памяти.
- У других СУБД разница в производительности может быть совершенно другой, поэтому полученные результаты можно рассматривать только применительно к Microsoft SQL Server. В то время как базовые критерии, указанные в начале статьи, справедливы независимо от конкретной СУБД.
UPD: Почему вариант с генерацией GUID ключа на стороне базы работает медленно
Когда Entity Framework выполняет вставку в таблицу с автоинкрементным ключем, SQL команды выглядит примерно следующим образом:
INSERT [dbo].[AutoIncrementIntKeyEntities]([Name], [Count]) VALUES (@0, @1)
SELECT [Id] FROM [dbo].[AutoIncrementIntKeyEntities] WHERE @@ROWCOUNT > 0 AND [Id] = scope_identity()
В случае с GUID, сгенерированным на стороне сервера, получаем более сложный вариант:
DECLARE @generated_keys table([Id] uniqueidentifier)
INSERT [dbo].[GuidKeyDbNonSequentialEntities]([Name], [Count]) OUTPUT inserted.[Id] INTO @generated_keys VALUES (@name, @count)
SELECT t.[Id] FROM @generated_keys AS g JOIN [dbo].[GuidKeyDbNonSequentialEntities] AS t ON g.[Id] = t.[Id] WHERE @@ROWCOUNT > 0
Таким образом, чтобы клиент мог получить ключ только что добавленной строки, создается табличная переменная, в которую заносится значение ключа при вставке, а потом из этой табличной переменной идет выборка для возврата полученного значения на клиент.
Краткий тест показывает, что такой набор команд выполняется в среднем почти в три раза медленнее, чем просто INSERT на той же таблице. В случае автоинкремента не используется никаких дополнительных табличных переменных, поэтому и оверхед меньше.
Комментарии (69)

APXEOLOG
26.08.2015 10:36+2Я конечно понимаю, что шанс сгенерировать два одинаковых GUID'a очень мал, но что будет если это все-таки произойдет? Отловить ошибку и попытаться вставить с новым GUID'ом? А если и тогда сгенерирует существующий?

YuriyIvon
26.08.2015 11:03В общем случае — повторить попытку. Для пользовательской транзакции это может выражаться в попытке сохранить изменения еще раз, для обработчика сообщений из очереди — сделать автоматический retry несколько раз, прежде чем поместить сообщение в очередь «проблемных» и т.д. Вероятность того, что GUID генератор подряд даст два одинаковых значения практически равна 0. Мне на практике не встречалось ни одного случая коллизий у GUID
APXEOLOG
26.08.2015 11:07+3Ну тут следует учесть что шанс этот напрямую зависит от кол-ва записей в базе. Если у вас в базе уже есть несколько сотен миллионов GUID'ов, то шанс нарваться на коллизию значительно выше чем в случае «сгенерировать два идентичных ключа». Интересно кстати было бы посчитать вероятности
YuriyIvon
26.08.2015 11:13Все давно посчитано ;)
en.wikipedia.org/wiki/Globally_unique_identifier
the total number of unique such GUIDs is 2122 (approximately 5.3?1036). This number is so large that the probability of the same number being generated randomly twice is negligible

toxicdream
26.08.2015 13:54+1Если очень быстро генерить GUID, то можно получить один и тот же два раза подряд.
В моей практике был очень неприятный случай.
Диск был SSD-шный, а данных на запись мало.
Вылетело необработанное исключение, не предусмотренное логикой программы.
Так как приложение было «почти enterprise» уровня, на орехи досталось всем.
Поставили костыль, обработку исключения и попытку получить новый GUID, после трех не успешных попыток добавлять интервал Sleep(100) между следующими тремя попытками. И если и это не помогло, то корректно откатывать транзакцию и показывать пользователю фигу.
Кроме всего прочего noname-сетевые платы могут содержать один и тот же MAC-адрес на всю партию, а он используется при генерации GUID.
В общем, ни в коем случае не стоит расслабляться.
lair
26.08.2015 15:28+5Если очень быстро генерить GUID, то можно получить один и тот же два раза подряд.
Что такое «очень быстро»? Как скорость генерации влияет на псевдослучайный генератор, используемый в гуидах?
Кроме всего прочего noname-сетевые платы могут содержать один и тот же MAC-адрес на всю партию, а он используется при генерации GUID.
У вас генератор первой версии, что ли, был? MAC-и (и время) использовались только в первой версии.toxicdream
26.08.2015 15:56Да скорее всего первый.
В то время про версии GUID-а мало кто что слышал, около 2003-2004 годов.
Сейчас то конечно с уникальностью уже получше и от сетевых карт отказались.lair
26.08.2015 15:57Так может не стоит это переносить на существующие реалии?
toxicdream
26.08.2015 16:02Переносить наверно не стоит, но обжегшийся на молоке на воду дует.
Я же на всякий случай try… catch… буду ставить. Так спокойней спится.
А да диск был не ссд-шный, там рам-диск был, чего это с памятью то моей…lair
26.08.2015 16:04Проблема, понимаете ли, в том, что в ситуации, когда вам действительно нужен сгенеренный на клиенте GUID, try/catch вам не поможет, потому что данные уже давно улетели. Вам надо либо всю архитектуру строить исходя из того, что уникальные идентификаторы генерятся рядом с базой (что в определенных случаях просто существенно дороже), либо… доверять гуидам.

BalinTomsk
26.08.2015 17:31+2Далее с символьного сервера Microsoft при
помощи WinDBG вытянул rpcrt4.dbg и rpcrt4.pdb. Скормив их IDA Pro, получил картину, поразившую меня.
Ниже схематично представлен алгоритм, как я его понял — от вершины и до функций нижнего уровня.
Заголовок спойлераRPC_STATUS __stdcall UuidCreate(UUID *Uuid){
rc4_safe_select(x,x,x);
NewGenRandom(x,x,x,x);
rc4_safe_key(x,x,x,x);
}
__stdcall NewGenRandom(x,x,x,x)
{
NewGenRandomEx(x,x,x);
}
__stdcall NewGenRandomEx(x,x,x){
InitRand(x,x);
InitializeRNG(x);
GenRandom(x,x,x);
}
__stdcall InitRand(x,x){
InitCircularHash(x,x,x,x);
ReadSeed(x,x);
}
int __stdcall ReadSeed(LPBYTE lpData,DWORD cbData){
AccessSeed(x,x);
RegQueryValueEx(«SOFTWARE\Microsoft\Cryptography\RNG\Seed»);
}
int __stdcall AccessSeed(REGSAM samDesired,DWORD dwDisposition){
RegCreateKeyEx(«SOFTWARE\Microsoft\Cryptography\RNG\Seed»);
}
__stdcall InitializeRNG(x){
rc4_safe_startup(x);
InterlockedCompareExchangePointerWin95(x,x,x);
}
__stdcall InterlockedCompareExchangePointerWin95(x,x,x){
InterlockedCompareExchange();
}
__stdcall GenRandom(x,x,x){
RandomFillBuffer(x,x);
}
__stdcall RandomFillBuffer(x,x){
UpdateCircularHash(x,x,x);
rc4_safe_select(x,x,x);
GetCircularHashValue(x,x,x);
GatherRandomKey(x,x,x,x);
rc4_safe_key(x,x,x,x);
rc4_safe(x,x,x,x);
}
__stdcall UpdateCircularHash(x,x,x){
MD4Init(x);
MD4Update(x,x,x);
MD4Final(x);
}
int __stdcall GatherRandomKey(LPVOID lpInBuffer,DWORD nInBufferSize,LPVOID lpOutBuffer,LPDWORD lpBytesReturned){
GatherRandomKeyFastUserMode(x,x,x,x);
}
int __stdcall GatherRandomKeyFastUserMode(LPVOID lpInBuffer,DWORD nInBufferSize,LPVOID lpOutBuffer,LPDWORD lpBytesReturned){
IsRNGWinNT();
NtOpenFile("\\Device\\KsecDD");
InterlockedCompareExchangePointerWin95(x,x,x);
}

Frag
26.08.2015 15:32Я на работе у коллег слышал о случае совпадения гуидов в .NET-приложении лет шесть назад.
Но это так, к слову… Руководствоваться следует фактами, а не рассказами людей из интернетов :)
gandjustas
26.08.2015 16:22Стандартный механизм генерации GUID какой-то уникальный номер или MAC (детали не знаю) от сетевой карты. Поэтому в природных условиях сгенерировать одинаковые гуиды можно только путем целенаправленного шаманства.

m08pvv
26.08.2015 15:12Вроде MS SQL Server гарантирует, что на стороне сервера генерируются именно что уникальные, а вот на клиенте можно нагенерировать чего угодно.

RouR
26.08.2015 10:45+1Остается вопрос, как получать последовательные GUID на клиенте? К сожалению, стандартной функции в .NET для этих целей нет, но ее можно сделать, воспользовавшись P/Invoke:
Я видел другой вариант — GUID генерировался из двух частей, первая — текущая дата, вторая — рандом.YuriyIvon
26.08.2015 10:58Ключ должен быть строго возрастающим. Если вторая часть — рандом, то он уже не дает строгого возрастания, если это не какой-то специальный рандом.
RouR
26.08.2015 11:05+1Cтрогого возрастания нет, а так ли это нужно? Нужен гарантированно уникальный ключ, а возрастание даёт бонус в производительности, который теряем на P/Invoke www.codeproject.com/Articles/253444/PInvoke-Performance
YuriyIvon
26.08.2015 11:10Внимательно прочитайте статью, там как раз сравнивается перформанс разных вариантов, и затраты на P/Invoke там не видны. Как раз время вставки записей, в которых последовательный GUID ключ генерится через P/Invoke оказывается самым быстрым, потому что затраты на «обработку» непоследовательного ключа на порядки больше. Цитата приведеная выше из моей статьи говорит именно про последовательные гуиды, поэтому я не совсем понял, как предложенный способ генерации ключа соотносится с «последовательным».
RouR
26.08.2015 11:24Я считаю возможным три варианта: GUID строго последователен, GUID не строго последователен, GUID рандомен. В статье увидел только два варианта: seq и non-seq. Я может чего не понимаю, но для не строго последовательной генерации в большинстве случаев последовательность будет соблюдаться. Вижу только две ситуации когда этот вариант будет хуже — хайлоад и логи.
Вообще будет здорово добавить тест в сравнение, и учесть не только время вставки, но и время генерации самого GUIDаYuriyIvon
27.08.2015 10:38Вообще будет здорово добавить тест в сравнение, и учесть не только время вставки, но и время генерации самого GUIDа
Время генерации включено во всех случаях (можно посмотреть в коде, который я на гитхабе выложил).
lair
26.08.2015 11:15NEWSEQUENTIALID()не дает строго возрастания, он дает возрастание в рамках некой группы, группы периодически ротируются, поэтому в некий момент вы можете получить идентификатор, который меньше ранее созданного.YuriyIvon
26.08.2015 11:21Согласен. Строго говоря он работает так:
Creates a GUID that is greater than any GUID previously generated by this function on a specified computer since Windows was started. After restarting Windows, the GUID can start again from a lower range, but is still globally unique.
Взято вот отсюда
khaale
26.08.2015 11:08+2Реализация comb guid из NHibernate — старшие байты берем из даты-времени (что обеспечивает возрастание), младшие байты из Guid.NewGuid() обеспечивают уникальность.
yorick_kiev_ua
26.08.2015 11:54Только нужно помнить, что «меньший объем» и «быстрее генерируется» — вещи относительные. Относительные относительно, в этих примерах, размера таблицы и скорости вставки, т.е. в подавляющем большинстве реальных сценариев это ничто, это даже не экономия на спичках.
michael_vostrikov
26.08.2015 12:32Возможно, вопрос немного глупый, но что если бы можно было генерировать автоинкремент на клиенте? К примеру, при подключении к БД программа резервирует себе некоторый набор id-шников — [1001-1100] — и расходует при создании новых записей. По окончании запрашивает снова — [1601-1700]. Какие недостатки будут у такой системы?
lair
26.08.2015 12:39Как вы предлагаете «резервировать»?
michael_vostrikov
26.08.2015 16:44Одна общая последовательность на всю базу. Хотя, как сказали ниже, это будет узким местом.
yul
26.08.2015 13:29Можно, только зачем? Плюс нужно отслеживать коллизии, когда два параллельных процесса смогли зарезервировать одинаковый набор.
YuriyIvon
26.08.2015 13:40Или жестко лочить доступ к генератору последовательности на этапе получения «резервного» отрезка, что создает bottleneck. Потом, если приложение за время рабочей сессии ничего не добавило, что делать с резервированным отрезком? Если просто игнорировать и всегда получать по возрастанию, то можно быстро дойти до конца 32-битного integer. Можно взять больший тип, но в любом случае решение получается очень хрупкое и плохо масштабируемое.
В реальной жизни в сценариях с репликацией и автоинкрементными ключами на разных репликах вручную прописывают разные диапазоны ключа. Например, на реплике А он стартует с 1, на реплике Б — с 1000000. Но это, опять же, требует ручного вмешательства, плохо масштабируется, и существует вероятность коллизии, когда одна реплика вставит по какой-то причине неожиданно большое количество записей.michael_vostrikov
26.08.2015 16:46Насколько я понимаю, последовательные GUID-ы тоже не на единицу отличаются, если рассматривать его как 128-битное число? Как вы сказали, 32 бита брать необязательно, можно те же 128. Если даже раздавать всем клиентам по 1000 каждый раз, то получится примерно 2^118 вариантов. Если база большая, к примеру расположена на 4 машинах, то можно реализовать такую же схему, как с клиентами — генератор последовательности на каждой машине получает свой большой диапазон у мастер-генератора (назовем его так): [1 — 1000000], [1000001 — 2000000],… Как вы считаете, такая схема реальна, или не стоит заморачиваться? В общем-то, основная причина, по которой я спрашиваю — поиск по целочисленному ключу теоретически должен быть быстрее поиска по GUID (что имеет значение при отказе от join-ов).
YuriyIvon
27.08.2015 10:41Если те же 128, то строго говоря разницы не будет. Что ГУИД, что 128-битовое число — набор байт одинаковой длины. Разница может быть только в порядке сравнения этих байт.
Насчет скорости поиска — я планирую либо сделать вторую часть статьи, либо проапдейтить эту сравнениями производительности выборки. Действительно, это очень нужный в данном случае тест.

nekt
29.08.2015 22:40автоинкримент всегда можно увеличивать с определенным шагом, зависящем от количества реплик + какой-нибудь запас.
vlivyur
30.08.2015 22:33Главное в этом случае не пользоваться identity(1, 10) и identity(2, 10) ибо если во втором данные обгонят по величине первые и перелить из второго в первое, то в первом новые ключи будут нумероваться с двойкой на конце. Ну или не переливать друг в друга.
khaale
26.08.2015 16:12Примерно так и работае HiLo Identity Generator в NHibernate.
Hi (номер cледующего свободного блока) хранится в отдельной таблице в БД, при старте приложение атомарно считывает и инкрементирует текущее значение.
Lo часть генерируется на клиентском приложении.
Id вычисляется как Hi * 32767 + Lo.
Из минусов могу назвать:
1. Int32 действительно быстро кончаются.
2. Неудобно вставлять данные из скриптов — приходится повторять логику по инкрементированию Hi и вычислению Id.
3. Последовательности Id получаются с пропусками.gandjustas
26.08.2015 16:19Такой подход требует, чтобы клиент поддерживал сеанс. Поэтому в случае REST\Web работать не будет.

Dim0FF
26.08.2015 21:26В Entity Framework 7 появилась возможность получать последовательные айдишники блоками по 10 штук (по умолчанию). Гарантируется, что все блоки не пересекаются, получение потокобезопасно и коллизий возникнуть не может.
С полученными блоками можно работать напрямую, явно указывая id при сохранении объекта.
Проблемы те же, что и в NHibernate — пропуски в id, быстрое увеличение значений ключа. По умолчанию по-прежнему ключ генерируется в БД.
Подробнее рассмотрено в видео блоге.

AlexLeonov
26.08.2015 12:45Простите чайниковский вопрос, конечно, но разве в столь продвинутой БД как MS SQL нет сущностей SEQUENCE? Мне отчего-то кажется, что использование последовательностей снимает все вопросы, поднятые в статье, нет?
lair
26.08.2015 12:52+3Есть. Но — никак не снимает. Фактически, использование последовательностей для идентификаторов ничем особо не отличается от Identity.

BearMef
26.08.2015 16:03+2Хосподи, ну что за статья-обрубок??
«так как для некоторых ситуаций более предпочтительным может оказаться GUID» — ну хотя бы ма-аленько так про ситуации. Ну хоть парочку для каждого случая, чтобы сориентировать про какие ситуации вообще вам известно.
«Приведены преимущества каждого из вариантов...» — вот это вообще не имеет смысла при отсутствии анализа недостатков (что там у нас с джойнами по GUIDу на серьезной базе?).
«На практике возможны и другие, более редкие, типы ключа» — действительно, нафиг всю эту тягомотину с денормализацией и подходами к выбору оптимальных ключей! GUID и автоинкремент — наше все! А все остальное — редкая фигня.
Теперь о тестах (и в продолжение об обрубках). Судя по ним, автор в базу исключительно пишет. Кстати, давайте поиграем со вставкой, когда таблица не пустая, а содержит миллион записей. С индексом, конечно. А с несколькими индексами? А с кластерным по ключу?
А где, кстати, чтение, обновление, удаление? Джойны опять же?
Слова про «ограничение оперативной памяти» есть только на диаграммах. Что сие означает и как (зачем) это было реализовано?
Ну и раз уж речь идет о тестах, было бы любезно указать версию MSSQL и описать железо.
Какая-то абстракция ни о чем. Вот на кой такое писать?lair
26.08.2015 16:05вот это вообще не имеет смысла при отсутствии анализа недостатков (что там у нас с джойнами по GUIDу на серьезной базе?).
Что вы считаете серьезной базой? Десять на десять миллионов записей — все нормально.
BearMef
26.08.2015 16:57Мы же с вами инженеры, правильно? ;)
Если основные задачи на базе — это запросы для построения отчетов и конечный пользователь радуется результату через 5 минут после запроса отчета за годовой период — это нормально. В общем случае при равных условиях джойн по GUIDу (16 байт) будет медленнее джойна по целочисленному (4 байта, например) ключу.
Если у нас онлайн торговая площадка/агрегатор — то здесь речь о нормально может идти при разговоре о сотнях миллисекунд.
Для абстрактного же (и поучающего) теста я ожидаю более четкой постановки задачи и всестороннего рассмотрения вариантов решения зачачи при этих ограничениях, иначе все это похоже на плохую лабу.lair
26.08.2015 16:59+1В общем случае при равных условиях джойн по GUIDу (16 байт) будет медленнее джойна по целочисленному (4 байта, например) ключу.
Да, медленнее. Но вопрос в том, критично ли это замедление для решаемой задачи.
Если у нас онлайн торговая площадка/агрегатор — то здесь речь о нормально может идти при разговоре о сотнях миллисекунд.
Там вообще не факт, что надо РСУБД использовать, так что обсуждение, что в качестве первичного ключа, теряет смысл.
YuriyIvon
26.08.2015 16:43Прежде чем писать в таком тоне, очень рекомендую самому попытаться написать хотя бы одну статью. И прочитать внимательно критикуемую статью, кстати, тоже.
А теперь по пунктам:
«так как для некоторых ситуаций более предпочтительным может оказаться GUID» — ну хотя бы ма-аленько так про ситуации. Ну хоть парочку для каждого случая, чтобы сориентировать про какие ситуации вообще вам известно.
Ниже вообще-то расписываются критерии, по которым предпочтительнее GUID, и даже выводы насчет его производительности в плане вставки есть в конце статьи? Или я должен был написать в стиле «Если у вас каталог для интенет магазина — используйте автоинкремент», если у вас база данных пользователей — используйте ГУИД"?
«Приведены преимущества каждого из вариантов...» — вот это вообще не имеет смысла при отсутствии анализа недостатков (что там у нас с джойнами по GUIDу на серьезной базе?).
Да, это указать можно, и в тексте статьи упоминается, как на скорость вычитки могут повлиять непоследовательные ГУИДы
«На практике возможны и другие, более редкие, типы ключа» — действительно, нафиг всю эту тягомотину с денормализацией и подходами к выбору оптимальных ключей! GUID и автоинкремент — наше все! А все остальное — редкая фигня.
Составные ключи (например, версия + номер записи), строковые ключи, иерархические ключи и т.д. Всех их рассмотреть в статье? В каком проценте решений они используются? Статья не претендует на полный гайдлайн по выбору ключей. Заголовок даже на это не намекает. Что за юношеский максимализм?
Теперь о тестах (и в продолжение об обрубках). Судя по ним, автор в базу исключительно пишет. Кстати, давайте поиграем со вставкой, когда таблица не пустая, а содержит миллион записей. С индексом, конечно. А с несколькими индексами? А с кластерным по ключу?
Про миллион записей — это когда вся таблица не умещается в памяти. И этот кейс рассмотрен.
А где, кстати, чтение, обновление, удаление? Джойны опять же?
Про чтение и джойны я плнаирую, как будет время, написать в part 2.
Слова про «ограничение оперативной памяти» есть только на диаграммах. Что сие означает и как (зачем) это было реализовано?
Если прочитать внимательно, то все можно увидеть.
Ну и раз уж речь идет о тестах, было бы любезно указать версию MSSQL и описать железо.
Цель этого тестирования — сравнительные цифры, а не абсолютные. Сравнение дает понять как в одних и тех же условиях ведут себя разные варианты. Знание конкретного железа чем-то поможет?
gandjustas
26.08.2015 16:17+1Недавно видел пост, о том как чуваки умудрились сделать коллизию, используя sequential id. Так что для распределенных случаев его категорически нельзя использовать. В итоге остается один достойный вариант — autoincrement.
Кроме того первичный ключ (вернее кластерный ключ) хранится во всех листах не кластерных индексов, поэтому выбор guid в качестве кластерного ключа увеличивает объем индексов и замедляет их обработку. Это я уже не говорю о том, что внешние ключи в вид guid увеличивают размеры таблиц.
Поэтому всегда имеет смысл делать кластерный ключ auto increment. Но если вы хорошо знаете SQL Server, то догадаетесь, что кластерный ключ и первичный ключ таблицы — разные вещи. Можно иметь кластерный ключ — auto increment для оптимизации хранения и первичный ключ guid, если у вас планируется распределенная БД.YuriyIvon
26.08.2015 16:52И все-таки насчет одного достойного варианта — спорное утверждение. Настройка и поддержка репликации при использовании автоинкрементов — очень неприятное занятие.
Насчет кластерного и первичного — конечно же знаю разницу. И на практике были разные случаи. Например, когда таблица кластеризована по дате изменения объекта, а первичный ключ, естественно, не кластерный.gandjustas
26.08.2015 17:03Встроенный механизм репликации в SQL Server как раз добавляет колонку с GUID (если не было объявлено колонки ROWGUID) и Timestamp. Вообще для репликации гуиду вовсе не надо быть ключом.
Например, когда таблица кластеризована по дате изменения объекта
При каждом обновлении меняется кластерный ключ? Это же гениально!YuriyIvon
26.08.2015 17:05+1А если эти изменения редки, а вычитка записей за последние 30 дней идет крайне часто? Все зависит от бизнес кейса ;)

blind_oracle
26.08.2015 22:23В мульти-мастер кластере MySQL Galera интересно решается проблема с коллизиями автоинкрементов при записи с разных нод: Auto increments in Galera
Каждая нода генерирует свои уникальные непересекающиеся с другими нодами ID используя оффсет и размер инкремента.
gandjustas
26.08.2015 16:34+1Тесты в статье некорректны.
При длине строкового поля размером более 4000 байт, то при вставке строки в страницы IN_ROW_DATA не попадает ничего и данные пишутся в страницы ROW_OVERFLOW_DATA. Это значит, что в тесте GUID произошло по факту гораздо меньше page splits, чем случилось бы в реальной системе.YuriyIvon
26.08.2015 16:49Скорее всего вы говорите о количестве символов. Т.к. в NVarchar длина символа — 2 байта, то при 8000 байт там как раз 4000 символов. Или я как-то не так трактую technet.microsoft.com/en-us/library/ms186981%28v=sql.105%29.aspx
gandjustas
26.08.2015 17:06Да, 8000 байт или 4000 символов в nvarchar.
YuriyIvon
27.08.2015 10:43Т.е. в моих тестах все корретно. Единственное — опечатка на предпоследнем графике (там написано «символов» вместо «байт»), поправлю ее вечером.
BalinTomsk
26.08.2015 20:08Мое REPO на TSQL
Запускал по 3 раза
Microsoft SQL Server 2014 — 12.0.2269.0 (X64)
Jun 10 2015 03:35:45
Copyright © Microsoft Corporation
Developer Edition (64-bit) on Windows NT 6.3 (Build 9600: )
SSD drive
Заголовок спойлера— IDENTITY
create table TestTable ( id int identity(1,1) not null primary key clustered, sequence int not null, data char(250) not null default ''); go
— NEWID
create table TestTable ( id uniqueidentifier default newid() not null primary key clustered, sequence int not null, data char(250) not null default ''); go
— NEWSEQUENTIALID
create table TestTable ( id uniqueidentifier default newsequentialid() not null primary key clustered, sequence int not null, data char(250) not null default ''); go
тестируем вставкой 50.000 записей
declare @count int; set @count = 0; while @count < 50000 begin insert TestTable (sequence) values (@count); set @count = @count + 1; end; go
смотрим что получилось:
— Get the number of read / writes for this session…
select reads, writes from sys.dm_exec_sessions where session_id = @@spid;
— Get the page fragmentation and density at the leaf level.
select index_type_desc, index_depth, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent, record_count from sys.dm_db_index_physical_stats(db_id(), object_id('TestTable'), null, null, 'detailed') where index_level = 0; go
toxicdream
27.08.2015 06:33А с джойнами как?
BalinTomsk
27.08.2015 20:48с joina-ми тока удвоенная нагрузка на CPU — оно и понятно — сравнение за 2 операции делается, вместо одной int-а.
SQL RepoIF EXISTS( SELECT * FROM sysobjects WHERE name='ParentTable' AND (xtype='U') )
DROP TABLE dbo.ParentTable
GO
IF EXISTS( SELECT * FROM sysobjects WHERE name='TestTable' AND (xtype='U') )
DROP TABLE dbo.TestTable
GO
create table TestTable ( id int identity(1,1) not null primary key clustered, sequence int not null );
go
create table ParentTable (
id int identity(1,-1) not null primary key clustered,
ParentTableId int not null INDEX idx_ParentTableId
);
go
alter TABLE dbo.ParentTable with nocheck add CONSTRAINT FK_ParentTable FOREIGN KEY (ParentTableId) REFERENCES dbo.TestTable(id);
GO
--— NEWID
create table TestTable ( id uniqueidentifier default newid() not null primary key clustered, sequence int not null );
create table ParentTable (
id uniqueidentifier default newid() not null primary key clustered,
ParentTableId uniqueidentifier not null,
);
go
alter TABLE dbo.ParentTable with nocheck add CONSTRAINT FK_ParentTable FOREIGN KEY (ParentTableId) REFERENCES dbo.TestTable(id);
GO
--— NEWSEQUENTIALID
create table TestTable ( id uniqueidentifier default newsequentialid() not null primary key clustered, sequence int not null );
go
create table ParentTable (
id uniqueidentifier default newsequentialid() not null primary key clustered,
ParentTableId uniqueidentifier not null
);
go
alter TABLE dbo.ParentTable with nocheck add CONSTRAINT FK_ParentTable FOREIGN KEY (ParentTableId) REFERENCES dbo.TestTable(id);
GO
— тестируем вставкой 2,000,000 записей
declare count int = 0;
while count < 2000000 begin
INSERT INTO TestTable (sequence) VALUES ( count);
set count = count + 1;
end;
INSERT INTO ParentTable (ParentTableId) SELECT id FROM TestTable
go
select max(sequence) from ParentTable p join TestTable t on p.ParentTableId = t.id
where exists (select * from TestTable s where p.ParentTableId = s.id)
--смотрим что получилось:
--— Get the number of read / writes for this session…
select reads, writes
from sys.dm_exec_sessions
where session_id = @@spid;
--— Get the page fragmentation and density at the leaf level.
select index_type_desc, index_depth, page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent, record_count
from sys.dm_db_index_physical_stats(db_id(), object_id('TestTable'), null, null, 'detailed')
where index_level = 0;
go

pcmaniac
22.09.2015 14:38У меня была ситуация, когда клиент вставлял пачками по 10-15М очень маленьких записей. Чтобы ускорить вставку, я пришёл к составному ключу: два поля Int32. Первое — автоинкремент с сервера, сеансовый ключ, который каждый клиент получает при каждом коннекте к серверу. Второе — внутренний инкремент на клиенте. Так у нас будет и последовательность и непротиворечивость, при чём обе гарантированные. Последовательность обеспечивается ещё и тем, что клиент перед заливкой данных, даже если и висел на связи несколько часов, всё равно делает реконнект, чтобы получить свежий сеансовый ключ и его заливка шла в конец базы. Клиентов много, но одновременная заливка двух крайне маловероятна, в основном они читают. Но даже если лить будут два, будем просто иметь перерасход кэша (нужно будет в памяти держать одновременно две страницы, по одной на каждого клиента).

4knowledge
Не очень ясно почему, неужели именно указанная причина будет оказывать такое влияние?
YuriyIvon
Планирую разобраться с этим более детально и добавить результаты исследования в статью.
NYBR
прочел статью, и нигде не нашел упоминания негативного эффекта использования случайной строки (GUID) в качестве primary key на индексацию таблицы. Primary key это же clustered index, те добавляя такую запись мы вынуждаем сиквел сервер копаться в таблице, чтобы разместить новую запись в правильное место. Для табличек размером в тысячи записей — плевать, а для милионов?
lair
Во-первых, primary key — не обязательно кластерный. А во-вторых, именно для решения этой проблемы и берут псевдопоследовательные гуиды.
YuriyIvon
Странно, статья как раз в том числе и об этом. Вот эти абзацы например:
и далее по тексту. Потом:
и далее
YuriyIvon
Добавил информацию в конце статьи о том, почему получается такая разница