

Привет! Меня зовут Аркадий. Последние пару лет я занимаюсь развитием поиска по тексту в команде TQM (Tinkoff Quality Management) в банке Тинькофф. Наш продукт — это речевая аналитика по звонкам, чатам и другим активностям, контроль качества, анализ и прочее. Более подробно о продукте можно прочитать на странице бизнес-решений. Примерный объем нашего индекса в проде — 16 Тб, около 450 млрд сущностей.
Каждый раз, когда встает вопрос о полнотекстовом поиске, команда оказывается перед выбором: а надо ли? Уже есть полнотекстовый поиск в Postgres, а тут придется заказывать серверы, строить кластер. Но чем чаще пользователю требуется что-то найти, тем чаще приходится смотреть в сторону специализированных поисковых движков.
Как пишут сами разработчики Elasticsearch, он нужен именно «для поиска, вы же знаете» (you know, for search) и не сможет заменить полноценное хранилище данных. Зато достаточно быстрый, очень надежный и хорошо горизонтально масштабируется (при наших объемах).
Мы в TQM используем Elastic потому, что он гибкий, широко известный, имеет удобный и простой синтаксис, множество библиотек для работы как на Python, так и на C# (NEST). Хорошо скейлится под наши объемы (1—30 Тб).Kibana также очень удобна, мы используем ее для мониторинга, консоль Kibana применяем для запросов. А еще по сравнению с тем же Sphinx, Elastic удобно масштабировать (просто добавляем шарды, ноды, и он сам распределяет данные по ним). В случае с тем же Sphinx нам пришлось бы писать этот распределенный поиск самим, и не факт, что у нас получилось бы хорошо с первого раза.
Еще он и правда отказоустойчивый. Можно отрубить 2 ноды из трех, кучу шардов, и все равно Elastic будет пытаться отдавать результаты запросов, включать реплики и как-то выживать.
Потребление процессора будет уходить в 100%, запросы будут выполняться дольше, чем обычно, но система будет жить.
В этой статье я расскажу о том, как мы используем этот популярный движок у нас, со всей нашей спецификой.
Хранилище данных
Как правило, наши данные — это звонки и чаты, а также размеченные диалоги, по которым мы ищем, и куча метаданных, связанных с правами на операции с этими данными. Это вносит свои требования к проектированию всей системы.
По умолчанию Elastic предлагает схему из 3 шардов на индекс с одной репликой. У нас 3 ноды, и в этом случае итоговая схема выглядит примерно так:
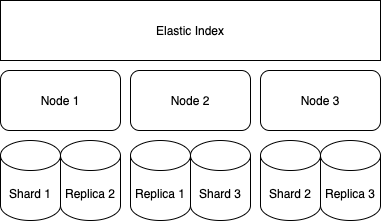
Создание анализатора
Тут все довольно просто. Документ попадает в индекс после нескольких операций: разбиения на токены, стемминга (нахождения основы слова),удаления стоп-слов, обогащения. Поэтому все эти вещи нужно добавить в раздел Settings.
Elastic по умолчанию использует для стемминга словарь Hunspell, поэтому предварительно нужно поставить файл словаря (просто закинуть в папку /usr/local/etc/elasticsearch/hunspell файл, взятый, например, отсюда: https://extensions.openoffice.org). При желании можно дополнять его своими словарями (для нас, например, очень актуален словарь мата).
Самый простой вариант, который точно заработает для русского языка:
{
"analysis": {
"analyzer": {
"rus_analyzer": {
"tokenizer": "standard",
"filter": [
"lowercase",
"rus_analyzer_filter"
]
},
"exact": {
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
},
"filter": {
"rus_analyzer_filter": {
"type": "hunspell",
"locale": "ru_RU",
"dedup": true
}
}
}
}Здесь есть блок analysis: описание фильтров и токенайзеров. Токенайзер разбивает пришедшую фразу на токены (по словам, символам и так далее), фильтр преобразует полученное, приводя к нужному регистру (вообще есть токенайзер lowercase, который тоже умеет менять регистр).
Попутно добавляя морфологию и используя как раз те самые фильтры, описанные ниже. Для того чтобы заработала морфология, включаем словарь Hunspell:
"rus_analyzer_filter": {
"locale": "ru_RU",
"type": "hunspell",
"dedup": "true"
}Если не нравится Hunspell (у него есть недостатки, он иногда довольно беден и не всегда может корректно нормализовать слова, которые не знает), то есть другой вариант для морфологии — плагин Jmorphy для Elastic, форк Pymorphy, который получше себя ведет при поиске по заковыристой матершине и разным странным словам. Мы попробовали и вместо этого иногда подливаем апдейты в словарь Hunspell.
Шардинг и реплики
"number_of_replicas": 1 — количество реплик на случай утраты части шардов. Это приводит к тому, что там, где был 1 шард, будет 2.
Примерно так:

Очень важная для производительности настройка — number_of_shards: xxx тут. Это зависимость от размера данных в индексе. К сожалению, нельзя заранее создать шарды с запасом. Это приводит к такой деградации по скорости выполнения запросов, что пользоваться полнотекстовым поиском становится невозможно. Сама зависимость от размера описана тут.
Правила:
размер шарда — от 10 до 65 Гб;
не более 20 шардов на Гб памяти.
Им мы следуем всегда, кроме временных индексов: они создаются каждый месяц и иногда не дотягивают до минимальной границы. Чтобы размеры шардов не выходили за эти пределы, есть политики ILM, о которых расскажем в следующих сериях.
Все эти настройки используются при создании индекса — обновить текущий индекс с ними не получится. Чтобы получилось, мы создаем алиасы для всех наших индексов и индексы с номерами версий.
Чтобы создать алиас для индекса call_v1, нужно выполнить:
POST _aliases
{
"actions": [
{
"add": {
"index": "call_v1",
"alias": "call"
}
}
]
}Хорошая идея для внешних систем — всегда обращаться к индексу через алиас. Внешне запрос не будет отличаться, и внешний клиент не будет знать, что используется алиас, но это позволяет незаметно для пользователя производить длительные операции с отключенным индексом.
Например, вам потребовалось поменять тип поля с Long на Keyword. Вы не сможете просто взять и поменять такой маппинг в существующем индексе — потребуется создать новый индекс и реиндекс. А после — прописать в конфигах новое название. Неудобно!
В случае если у вас есть алиас и везде зашит он, то потребуется просто изменить алиас в Elastic. Подробнее про алиасы можно почитать тут.
Хранение индекса
Индекс иммутабельный — это значит, что сегменты используются только для чтения. При изменении создается новый сегмент и удаляется старый. Но так как сегмент Readonly, то для удаленных документов существует другой индекс, содержащий удаленные документы.
При поиске мы находим в Elastic документ, а потом проверяем, нет ли такого в удаленных. И так по каждому шарду. Напомню, что каждый шард — это отдельный Lucene Index. В принципе, рано или поздно Lucene мержит это и оптимизирует, но в моменте множество изменений текущего индекса в разы замедляют поиск и увеличивают требуемое место на диске. Еще больший эффект увеличения занятого места на диске мы можем получить при удалении записей по одной.
При индексации пропускаем документ через фильтры (убираем все, кроме текста), токенайзер. После этого то, что получилось, складываем в обратный индекс.

Для проверки работы выполним запрос:
GET index/_analyze
{
"text": "Мама? 2 конгрегации раму.",
"analyzer": "rus_analyzer"
}И получим что-то вроде:
{
"tokens": [
{
"token": "мама",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "2",
"start_offset": 6,
"end_offset": 7,
"type": "<NUM>",
"position": 1
},
{
"token": "конгрегация",
"start_offset": 8,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "рама",
"start_offset": 20,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 3
}
]
}Видим, что корректно отработала русская морфология, а фильтры и разделение на токены нас устраивают. Если возникают вопросы, почему мы не нашли ту или иную фразу, то таким образом можно сравнить то, что возвращает анализатор, и то, что лежит в индексе. После наполнения индекса тоже иногда полезно посмотреть, что возвращает анализатор и почему по какому-либо запросу не находится нужный документ.
Inverted Index
Для поиска Elastic использует обратный (инвертированный) индекс, который выглядит примерно так:
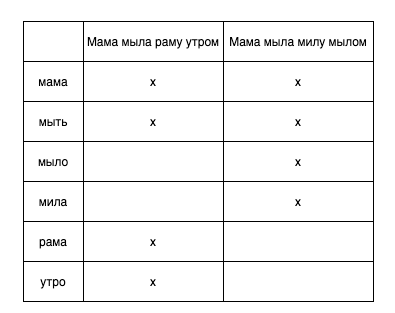
Соответственно, при запросе в обратный индекс мы получаем список документов, которые содержат крестики по каждому слову (если все слова обязательны в поиске).
Стоит помнить, что обратный индекс создается под каждое поле документа. Больше полей — больше обратных индексов. В случае с Muti-field (когда у вас на одно поле есть несколько вариантов, например Text и Keyword) будет построено несколько обратных индексов. При поиске можно искать по этим полям по отдельности.
Поиск по обратному индексу — это стандартный Binary Search.
В Lucene есть понятие сегмента — по сути, это отсортированный список по одному или нескольким документам.
При вставке документа в памяти сервера формируется новая сущность — сегмент. Сегменты складываются в буфер, по таймеру вызывается Refresh. Сегменты объединяются в один, мержатся термы и прочее. После этого по этому сегменту можно искать записи независимо от того, успели ли мы записать документ на диск (операция Flush (lucene commit)).
Каждая вставка или апдейт записи — это создание сегмента. Поэтому если мы много раз вставляем/меняем записи по одной, это плохо для производительности. Bulk — хорошо.
При удалении мы добавляем записи в отдельный индекс, и это позволяет игнорировать их при поиске до того, как Elastic запустит мерж и физически удалит записи.
Есть одна не очень приятная особенность операции Refresh. Refresh пишет сегменты из буфера в памяти на диск, при этом происходит мерж данных. Это само по себе создает лишнюю фоновую нагрузку. Elastic по умолчанию запускает Refresh для индекса раз в 1 секунду (если индекс находится в активном использовании). Для некоторых проектов это возможно и оправданно, а наши пользователи могут подождать новых обновленных данных чуть дольше. Мы сделали у себя index.refresh_interval=30 (секунд), это позволило на 3—5% снизить фоновую нагрузку на сервер. При реиндексы мы отключаем refresh_interval и удаляем реплики на время операции.
Организация данных
Инфраструктура готова — можно заняться данными. Основные сущности — поля (Field). Это кусочки данных для хранения в Elastic. Например, фраза, ID записи, ФИО оператора и так далее. Могут включать в себя другие поля (например, Keyword) для поиска по ключам.
Везде написано, что при поиске по точному совпадению нужно использовать Keywords, но в нашем случае это обязательно. Когда сущностей под 300 млрд, на поиск по Numeric-полям не остается времени.
Один и тот же запрос по числовому полю, скорее всего, будет сконвертирован в такое:
{
"type": "PointRangeQuery",
"description": "phrases.channel:1 TO 1",
"timeinnanos": 414870
}А запрос по keyword:
{
"type": "TermQuery",
"description": "phrases.channel.keyword:1",
"timeinnanos": 61593
}Видим, что разница по времени очень существенна.
Кстати, для того чтобы посмотреть план запроса и время выполнения каждого кусочка, есть свойство _profile:
GET call/_search
{
"profile": "true",
"query": {
"term": {
"phrases.channel": {
"value": "1"
}
}
}
}А чтобы посмотреть, что за кусочки и почему релевантность именно такая: _explain
GET call/_search
{
"explain": "true",
"query": {
"term": {
"phrases.channel": {
"value": "1"
}
}
}
}Иногда так не получается — бизнес хочет, например, искать все звонки длиной более 40 секунд. Тогда мы создаем поле с типом Keyword, где храним интервал по длительности — 0—30, 31—60, — и ищем по нему за те же миллисекунды.
Для поиска по тексту у нас есть несколько вариантов (поиск по семантике и прочий NLP в этой статье не трогаем).
Fuzzy Query используем, когда хотим найти слова с опечатками. Elastic под капотом использует расстояние Левенштейна. Если количество необходимых операций меньше или равно указанному в параметре Fuzziness, то нам вернется данное слово (фраза).
Поиск по одному слову — это легко, а вот когда мы хотим найти фразу, где опечатка разрешена в каждом слове и менять порядок слов нельзя, то запрос будет сложнее.
Мы делаем это так:
{
"span_near": {
"clauses": [
{
"span_multi": {
"match": {
"fuzzy": {
"messages.message.exact": {
"fuzziness": 1,
"value": "марс"
}
}
}
}
},
{
"span_multi": {
"match": {
"fuzzy": {
"messages.message.exact": {
"fuzziness": 1,
"value": "атакует"
}
}
}
}
}
],
"in_order": true,
// - важен порядок
"slop": 0
// - нельзя менять местами
}
}Тут мы найдем фразы «марс атакует», «морс атакуед» и прочее. Fuzziness может быть Auto (зависеть от длины слова), но внутренние клиенты наших продуктов говорят, что точное значение (у нас — 1) работает более предсказуемо.
Поиск с морфологией. Мы специально разделили два анализатора в самом начале: один ищет с морфологией, другой нет. Это позволяет в коде обращаться к полю с использованием префикса, если необходим поиск по точному совпадению или началу фразы. Например, такой запрос найдет все фразы, слова в которых начинаются с «при»:
GET call/_search
{
"query": {
"match_phrase_prefix": {
"phrases.phrase.exact": "при"
}
}
}Диалоги и Nested Fields
Мы часто ищем диалоги. Когда оператор сказал одно, а клиент ответил другое, и надо найти диалог, где во фразе оператора ML-модель обнаружила недопустимый уровень негатива. Тут нам на помощь приходят Nested Fields, когда мы в массиве Phrases храним не просто текст, а набор:
phrase: text,
channel: keyword (канал клиент / оператор / бот …)
и немного мета-информации.
Пример запроса:
GET call/_search
{
"query": {
"nested": {
"path": "phrases",
"query": {
"bool": {
"filter": [
{
"term": {
"phrases.channel": {
"value": "1"
}
}
},
{
"match_phrase": {
"phrases.phrase": "привет"
}
}
]
}
}
}
}
}Этот запрос вернет из первого канала фразы, где встречается слово «привет».
Такие запросы выполняются дольше, но это плата за их сложность. Еще одна проблема заключается в том, что если использованы Nested Fields, вы не сможете сортировать индекс по дате. Это сильно ударяет по скорости на большом индексе. Решение этого — в Data Streams, которые сейчас активно развивает команда Elastic.
Словари
Иногда не все можно найти.
Например, как найти документы, в которых есть совпадения с одним из 1000 ключевых слов? Поисковый запрос упадет с таймаутом, или сервер выжрет весь процессор. В этом случае предварительно размечаем каждый документ в соответствии с наборами ключевых слов. Такой запрос называется Percolator.
GET dictionaries/_search
{
"highlight": {
"fields": {
"phrase": {
"phrase_limit": 256,
"fragmenter": "simple",
"fragment_size": 1000,
"number_of_fragments": 10
}
}
},
"_source": "name",
"query": {
"bool": {
"filter": [
{
"percolate": {
"field": "query",
"documents": [
{
"phrase": "Перевожу вас на профильный отдел",
"channel": 2
},
{
"phrase": "как же так!",
"channel": 1
}
]
}
},
{
"term": {
"tags.keyword": "Reports"
}
}
]
}
}
}
Этот запрос за 7 мс вернет такой результат:
{
"_index": "dictionaries_v1",
"_type": "_doc",
"_id": "wow_dict",
"_score": 0.0,
"_source": {
"name": "Словарь восклицаний клиента"
},
"fields": {
"_percolator_document_slot": [
1
]
},
"highlight": {
"1_phrase": [
"<em>Как</em> <em>же</em> <em>так</em>"
]
}
}В итоге мы находим, что в этом звонке были восклицания, и впоследствии можем искать звонки по этому словарю. Добавляем в соответствующий массив нашего документа id словаря _wow_dict и при последующем поиске ищем по наличию "_wow_dict" в этом массиве.
Помимо скорости (мы в общем-то ищем по очень ограниченному числу документов) такую разметку всегда можно вынести на отдельный маломощный сервер и убрать еще одну фоновую нагрузку с основного сервера.
Это основные фичи и проблемы полнотекстового поиска на нашем проекте. Elastic нам очень хорошо зашел и пока решает все наши вопросы. Недавно запустили поиск похожих по смыслу фраз, готов прототип поиска последовательностей в диалоге, автооценка — все это можно делать практически мгновенно, путем поисковых запросов.
Невозможно рассмотреть в одной статье все. За скобками осталось, например, то, как мы решаем проблемы сложного, очень многокритериального поиска, оптимизируем поиск по векторному пространству, ищем смайлики и опечатки, пишем свои процессоры. Об этом — в следующих статьях.
В Тинькофф еще очень много интересного. Если вам хочется посмотреть, как все это работает на поиске 450+ млрд документов, покопаться в NLP, релевантности, TF*IDF и прочем, то есть простой способ это сделать — откликнуться на вакансию с пометкой «для TQM».
Комментарии (8)

OkunevPY
14.12.2021 09:10Я думал крупные компании могут себе позволить разработать нормальный движок под свои задачи
korsetlr473
Подскажите elastic такое научился делать в 2021 ?
Делаю автокомплит, ищу по массиву тэгов в одном документе. Как находится подходящие в массиве под запрос выводятся только они, остальные пропускаются , например:
Giardo911 Автор
Не понятно, completion поле вполне может быть массивом.
Главное чтобы в маппинг его тип был именно completion.
Типа такого:
Документ должен быть
И ищем:
Находим:
Но лучше для автокомплита завести отдельное поле, даже если оно будет дублироваться с полем tags.
korsetlr473
в том и дело что вы ищите do, но возвращается окромя do неподходящие тэги "boom", bom".
Giardo911 Автор
Да, а в таком случае проще всего завести отдельный индекс для тегов.
korsetlr473
прошло 5 лет, и всё никак не сделают эту фичу ...
orangeShadow
А зачем так делать ? Можно суть проблемы