
Statoscope — это инструмент для анализа webpack-бандлов, а я его автор и мейнтейнер. Он зародился в далеком 2016 году как эксперимент, а теперь это полноценный тулкит для просмотра, анализа и валидации сборки.

В ноябре на конференции HolyJS я выступил с докладом о Statoscope и провёл воркшоп по его использованию. Зрителям понравилось, так что мы с организаторами HolyJS решили, что доклад может пригодиться и читателям Хабра — поэтому сделали текстовую версию. Видеозапись тоже прилагаем.
Оглавление
- Немного истории
- Анализ содержимого
- Собственные отчёты
- Валидация
- Запросы в статы
- CI — собираем все вместе
- Планы
- Call to action
Немного истории
В 2016 году я выпустил первую версию инструмента, который тогда назывался ещё не Statoscope, а Webpack Runtime Analyzer. Это была техническая демка другого инструмента rempl от Романа Дворнова (lahmatiy).
Мы хотели предоставить визуальный интерфейс для анализа сборки в режиме реального времени. То есть вы запускаете специальный инструмент в браузере, и он показывает, что происходит внутри вашей сборки: из чего она состоит, собирается ли она сейчас, какие ошибки возникли. Тогда для подобного существовали консольные утилиты, но не браузерные.
После года работы над проектом у меня закончились идеи, и я заморозил его. Но примерно тогда же начал больше работать с webpack, контрибьютил в его ядро (об этом уже рассказывал на одной из предыдущих HolyJS). Поэтому в 2018-м захотел возродить Webpack Runtime Analyzer с учётом накопленного опыта.
В октябре 2020 года я выпустил первую версию Statoscope. По сути, это Webpack Runtime Analyzer, но в другой обёртке с более прокачанными фичами — более продуманный, глубокий инструмент для анализа вашего бандла.
В 2021-м Statoscope стали использовать у нас в Яндексе, причем абсолютно разные команды: Яндекс.Маркет, Яндекс.Карты, Яндекс.Метрика, Кинопоиск. Судя по фидбеку, все довольны.
Анализ содержимого
Это одна из основных фич Statoscope. Но сначала поймём, как вообще работает сборка и из чего она состоит.
Перед нами довольно типичный конфиг с двумя точками входа:
module.exports = {
entry: {
main: './main.js',
admin: './admin.js',
},
}Это главная страница и админка. Вроде ничего особенного.
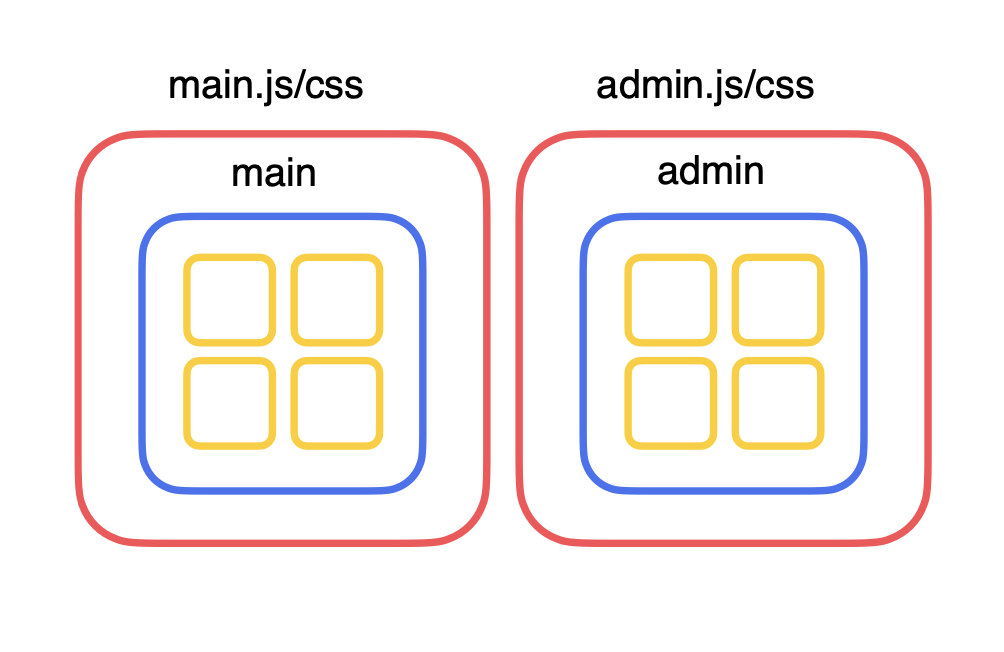
Когда мы запускаем сборку, webpack определяет каждый JS- или TS-файл как модуль. Сборка состоит из множества JS-модулей (на иллюстрации выше — жёлтые квадраты).
Модули собираются в группы — так называемые чанки (синие квадраты). Есть группа модулей, которые входят в главную страницу, модулей админки и так далее (синие квадраты).
И всё это оборачивается в ассеты (красные квадраты). Это выходные файлы, которые вы видите в директории dist (или build, смотря как у вас настроено). Это то, чем оперирует webpack.
Быстро пройдемся по стадиям сборки. Это нужно для дальнейшего понимания того, что вообще происходит.

- Webpack принимает на вход JS-, TS- или CSS-модули, парсит их в абстрактное синтаксическое дерево.
- Определяет связи между этими модулями. Например, модуль А импортирует модуль B. А модуль B что-то экспортирует. В общем, он строит граф зависимостей между модулями.
- Пытается оптимизировать этот граф: если мы используем модули в сыром виде, в котором они есть в файловой системе, это может быть не очень эффективно. Например, там могут быть дубли или какие-то из этих модулей вообще можно объединить, какие-то мы используем не полностью, а частично. Например, модуль предоставляет два экспорта, а мы используем только один. Второй экспорт нам не нужен, поэтому мы можем безболезненно выпилить его — никому от этого плохо не станет, и ничего мы в сборке не поломаем. Это часть оптимизации — то, что делает webpack, чтобы уменьшить размер выходных ассетов.
- Генерирует содержимое файлов, которые в итоге получатся в директории dist — это рендеринг ассетов.
- Сливает эти файлы в директорию.
Если не углубляться, это основные стадии того, как работает webpack и что он вообще делает с этими модулями.
С чем работает Statoscope?
Webpack предоставляет Statoscope информацию обо всех модулях, чанках, ассетах, которые встретились ему на пути сборки. Он предоставляет это в виде так называемых «статов» — это большой файл stats.json, который webpack генерирует вместе со сборкой, передает его в Statoscope (точнее, чаще всего Statoscope забирает его сам), а Statoscope анализирует его и генерирует отчёт, который мы можем посмотреть в браузере, что-то поанализировать и так далее.
Вот такой процесс: webpack генерирует статы, передаёт их в Statoscope, а Statoscope на основе этих статов генерирует HTML-отчёт.
Как получить статы?
Есть два способа. Первый — вы можете запустить вашу сборку, написать webpack, передать флажок JSON, и указать, в какой файл сохранить статы. После этого вы можете загрузить статы на специальный сайт statoscope.tech — это песочница, которую я специально поднял для того, чтобы можно было просто дропнуть туда статы и поанализировать. Это самый простой способ получить статы, никуда не интегрируя Statoscope.
$ webpack –json stats.json
Второй способ, который я рекомендую использовать, потому что он собирает гораздо больше информации о вашей сборке — добавить в вашу сборку Statoscope-плагин.
config.plugins.push(new StatoscopeWebpackPlugin())Вы просто идёте в конфигурацию вашей сборки и говорите: добавь мне в мою сборку плагин Statoscope. С этого момента начинается интересное.
Что представляют собой статы?
{
"modules": [/*...*/],
"chunks": [/*...*/],
"assets": [/*...*/],
"entrypoints": {/*...*/},
/*...*/
}Статы — это внутренняя информация из webpack: на какие модули, JS-, TS-, CSS-файлы он наткнулся, в какие чанки он объединил эти файлы, какие ассеты после этого получились. Всё это сливается в один большой .json-файл, а потом Statoscope анализирует этот файл.
Детали
Можно более детально посмотреть информацию о модуле:
{
"identifier": "babel-loader!./src/index.js",
"name": "./src/index.js",
"reasons": [/*...*/],
/*...*/
}Например, мы говорим: наш главный файл приложения index.js имеет вот такой идентификатор, такое имя файла, вот по такому пути он располагается. А в свойстве reasons можно посмотреть, где этот файл импортируется, где он используется. Вот такую подобную информацию webpack предоставляет в статах.
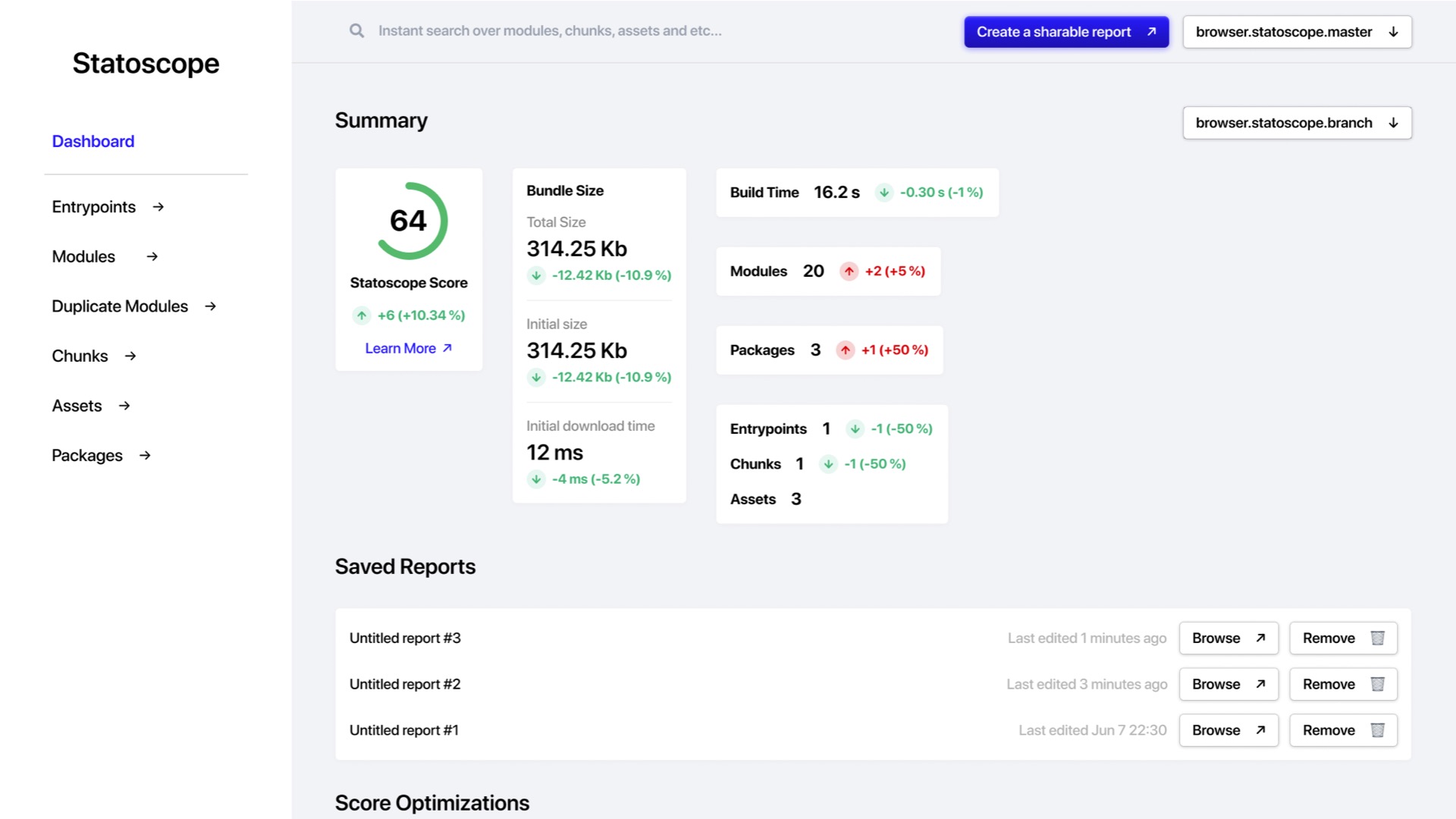
Statoscope это анализирует, компонует, что-то дополнительно делает с этим и предоставляет в удобном виде. Примерно в таком:
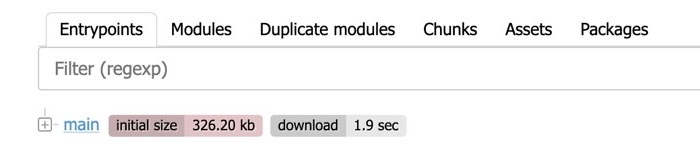
Он показывает entrypoints, модули, чанки, ассеты — всё, о чём я рассказал.
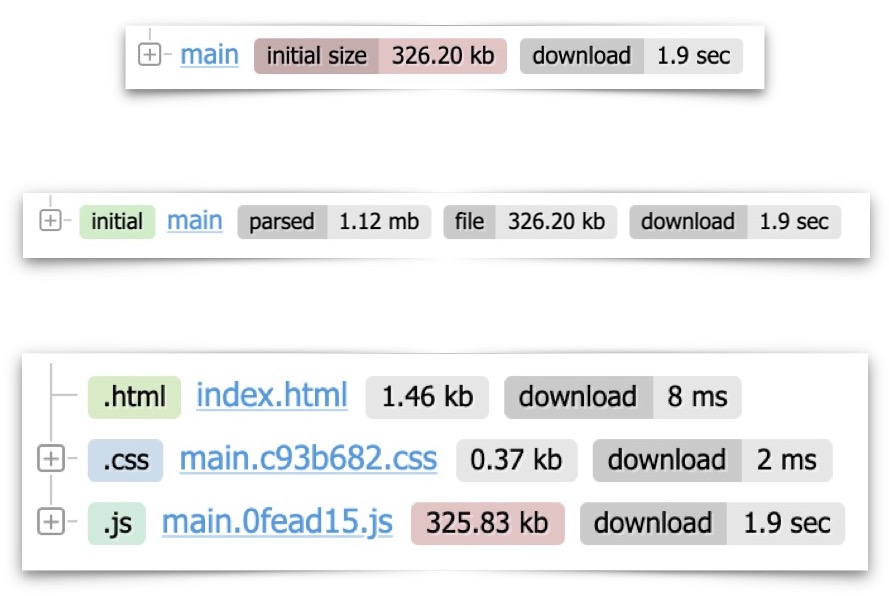
На изображении выше, в середине, чанк main. Мы видим, что это initial чанк.
Вообще чанки бывают двух видов:
- initial — тот, который обязательно должен быть загружен при загрузке страницы;
- async — тот, который получается в результате, например, динамического импорта и может быть отложенно загружен на страницу, то есть асинхронный. Если вы делите приложение на динамические части, например, у вас есть тяжёлая библиотека для анимации, которую нужно загружать, только если анимация понадобилась, — это асинхронный чанк.
Копии пакетов и их версии
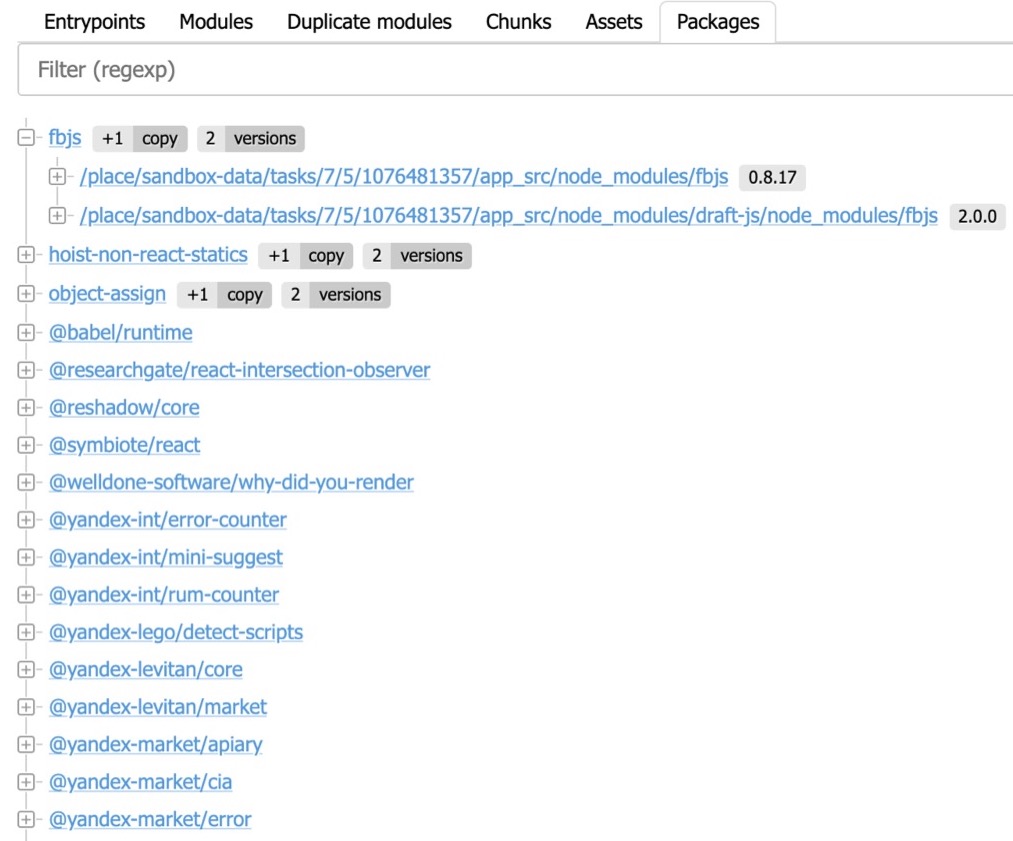
На основе этой же информации Statoscope ещё вычисляет дерево пакетов — по сути npm-пакеты, которые используются в вашей сборке: какие пакеты, сколько копий у этих пакетов.
Может возникнуть ситуация, когда вы устанавливаете пакет А и пакет B. Эти два пакета используют один пакет С, но разных версий. И получается, что вдруг в вашей сборке появляются два пакета С — дубль. Statoscope говорит: вот у тебя fbjs двух версий. В корне используется версия 0.8.17, а где-нибудь в draft-js используется версия 2.0.0. Пожалуйста, разберись. Обнови свои зависимости, и дубль пакета уйдёт.
Как видите, Statoscope дополнительно обогащает статы какой-то другой информацией, например, информацией о версиях пакетов. Изначально статы webpack не обладают информацией о версии пакетов. Чуть позже расскажу, как это происходит.
Карта модулей
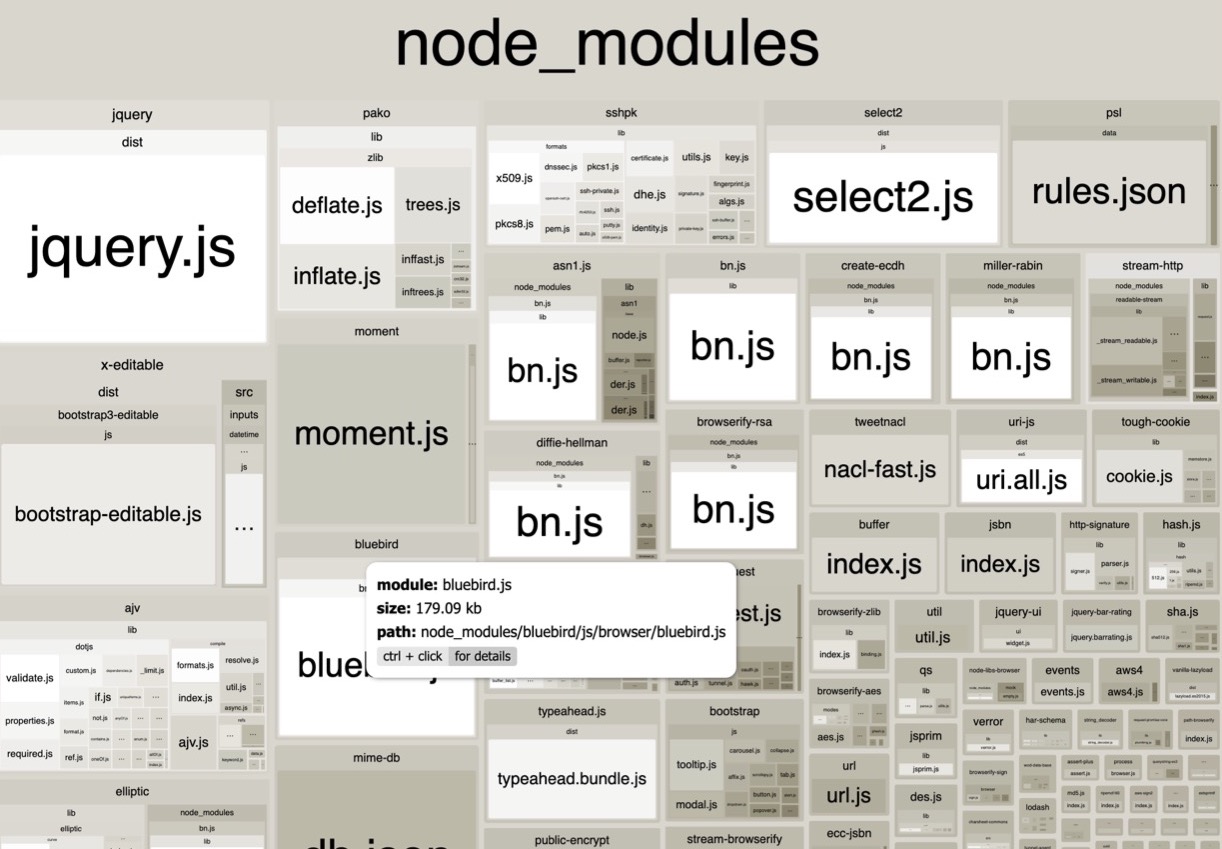
Карта модулей должна быть вам знакома, если вы использовали другие инструменты для анализа статов, например, Webpack Bundle Analyzer.
Карта модулей — одна из частей Statoscope. Разница в том, что Webpack Bundle Analyzer анализирует не статы, а внутренности webpack. А Statoscope анализирует статы. Смысл почти один и тот же, но принцип работы разный. В Statoscope вы можете поанализировать и модули, и карту модулей, и чанки, и ассеты — и всё это в одном месте.

Также мы можем перейти в пакет, например, asn1. Мы можем посмотреть, из чего состоит каждый отдельный пакет. Хотите понять, почему пакет так много весит? Заходим в информацию о пакете и смотрим.
Сравнение сборок
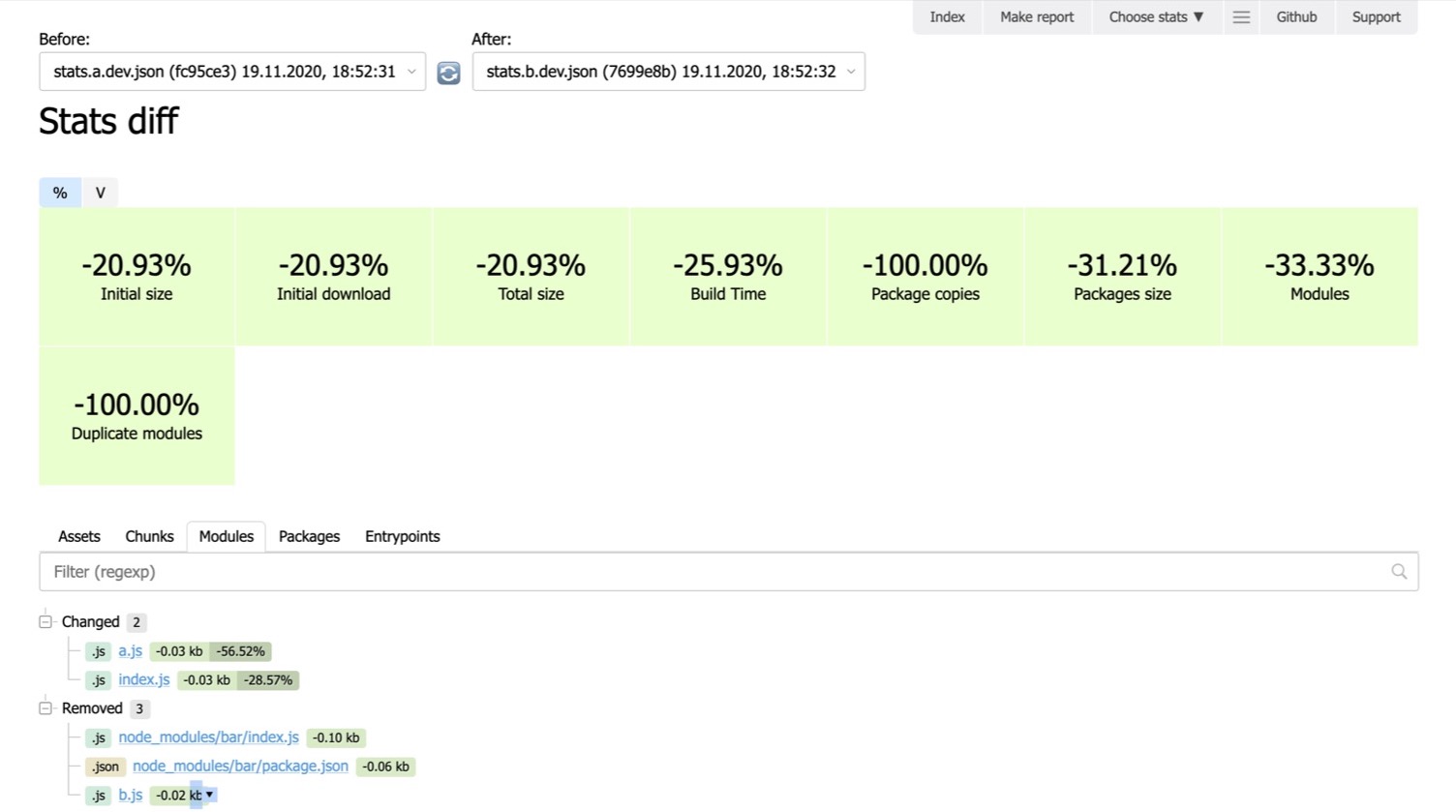
Мы можем выбрать предыдущие статы, текущие статы, нажать на кнопку — и Statoscope покажет, а что вообще поменялось: какие модули были, какие стали, какие удалились, какие добавились, какие просто изменились (например, поменялся размер), какие чанки добавились, изменились, удалились и так далее.
Например, текущими статами могут быть статы из вашей текущей feature-ветки. К примеру, вы делаете суперклассную фичу, а статами «до» могут быть статы из мастер-ветки. Вам хочется понять: а вот то, что я сейчас сделал, не утяжелило сборку? Я не ухудшил то, что сейчас в мастере? Вы можете всё это скормить Statoscope, и он вам скажет, ухудшили ли вы (а может, и улучшили), и чем.
Собственные отчёты
Если вам не хватает отчётов, которые предоставляет вам Statoscope, и вы хотите сделать что-то своё, то вы можете сгенерировать собственный отчёт.
Но есть несколько проблем, которые Statoscope тоже решает.
Статы — это большой .json-файл, и его размер может достигать нескольких гигабайтов. У этого файла есть свой формат, часто нужно написать много кода, чтобы вынуть данные из этого .json-файла. Наверное, никому не нравится писать этот код, особенно если его много. Хочется, чтобы всё это было проще.
Jora
Одно из решений этой проблемы — язык запросов, который называется Jora. Не спрашивайте, откуда такое имя.
Вот JS-код, который мы написали бы, чтобы вынуть из статов, например, список модулей и отсортировать их, например, по имени:
const modules = [];
for (const compilation of compilations) {
for (const module of compilation.modules) {
modules.push(module);
}
}
modules.sort((a, b) => a.name.localeCompare(b.name))А вот кусочек кода на языке Jora, и этот кусочек делает то же самое:
compilations.modules.sort(name)
Мы говорим ему: возьми все компиляции, из этих компиляций возьми все модули и отсортируй их по имени. Всё — этого достаточно.
Как видите, Jora позволяет уменьшить количество JS-кода, который мы пишем. Это лёгкий, семантичный, понятный язык для запросов в JSON.
Если вы работали с библиотеками типа jq, это будет вам знакомо.
Вот три примера из Jora.
Filter
modules.[size > 1000]
Мы можем сказать: дай-ка мне все модули, размер которых больше тысячи байтов.
Map
modules.({module: $, size})
Мы хотим преобразовать модули в другой объект. Говорим: дай нам, пожалуйста, модули и добавь к ним размеры. У нас будет объект с двумя полями: модуль и размер. Просто и лаконично.
Map call
modules.(getModuleSize(hash)).size
Мы делаем map, и чтобы получить результирующий объект, мы ещё и вызываем функцию, которая возвращает нам этот объект. Вернемся к этому в воркшопе, где я покажу, что можно технически делать со Statoscope.
UI
Итак, мы разобрались с тем, что Statoscope позволяет делать запросы в статы, формировать свои отчёты при помощи языка запросов Jora. А как выводить? Нам же нужен какой-то UI, мы не можем тупо выводить структуру JS-объекта. Нам хочется вывести список, заголовок, кнопки, бейджи.
Кажется, что можно сделать UI на React. Но тогда начнутся дополнительные проблемы: интерфейс надо где-то хостить, его нужно собирать, куда-то складывать. Statoscope предоставляет способ, как решить эту проблему.
Discovery.js
Discovery.js — это платформа декларативного описания UI.
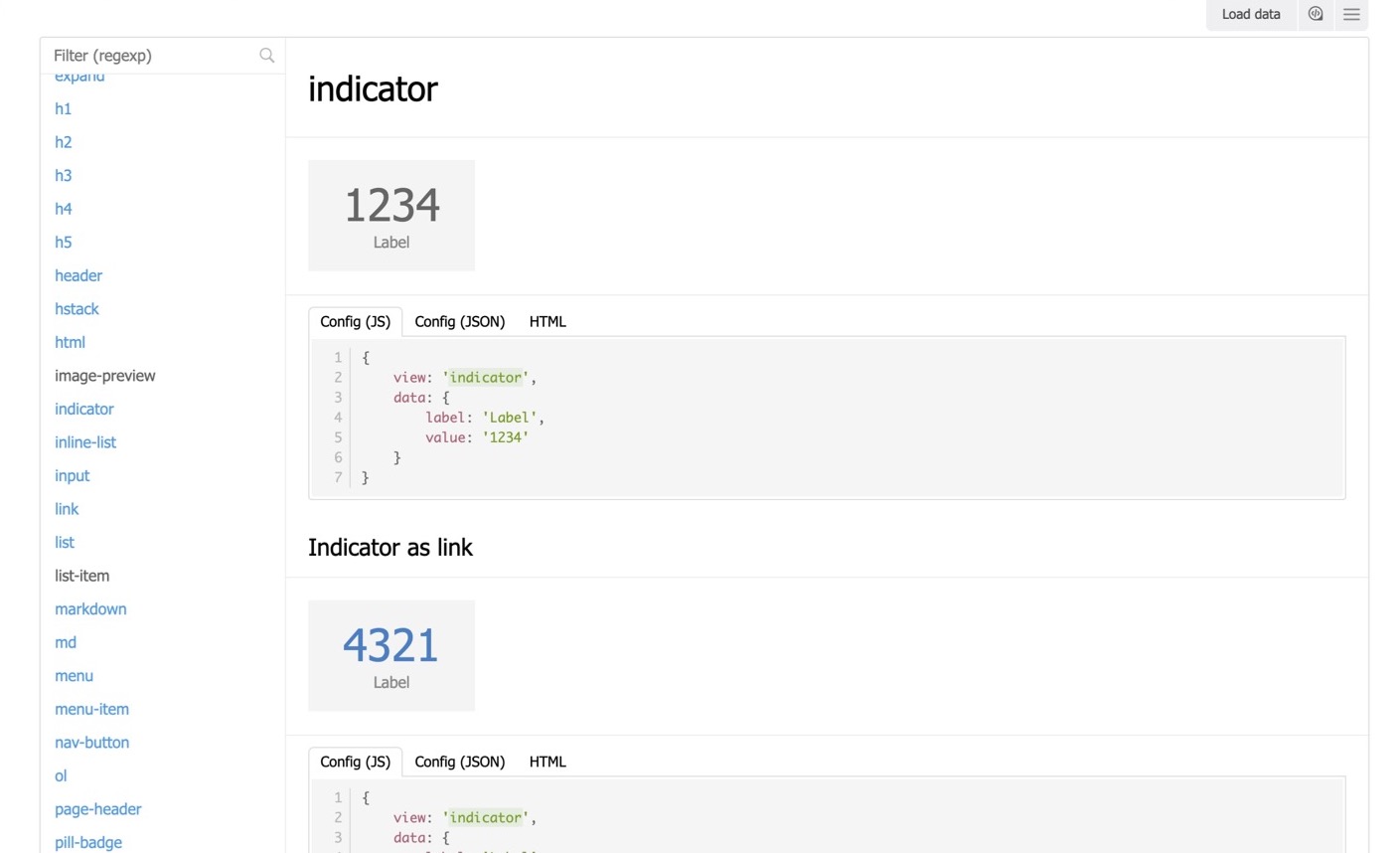
Мы видим пример. Слева вы можете видеть уже готовые UI-элементы. В Discovery.js входит готовый UI-кит: кнопки, заголовки, бейджи, индикаторы и так далее. Всё это есть готовое, и этим можно пользоваться.
Но основная фича этой истории состоит в том, что layout, сами компоненты, вьюшечки вы можете использовать при помощи JSON.

То есть мы говорим: мне нужен индикатор, надпись у индикатора будет такая-то, значение будет такое-то.
И вместо этого JSON Discovery.js сформирует вам HTML-вьюшечку. Делая композицию из таких JSON-объектов, вы можете составлять собственные отчёты.
При помощи Jora вы получаете данные, при помощи layout на Discovery.js вы получаете view, соединяете — и получаете отчёт.
Собираем всё вместе
Вот как это выглядит:

Если в Statoscope нажать кнопку Make report, то вверху можно ввести запрос любой сложности на Jora, в поле ниже вы можете ввести UI, то есть описать layout в виде JSON, и ниже у вас получится готовый отчёт.
В данном случае мы берём все модули всех компиляций и сортируем их по размеру. Получаем простейший отчёт. Вверху у нас будут самые тяжёлые модули.
Плюшечка в том, что мы можем делиться ссылкой на этот отчёт с коллегой. Например, вы на CI запустили отчёт, поанализировали, поняли, что что-то происходит не то. Дай-ка напишу свой кастомный отчёт. Написали этот отчёт и поняли, где собака порылась. Составляете отчёт, копируете ссылку на него, прямо на CI, и отправляете коллеге. Коллега открывает его и видит тот же отчёт, что и вы. Это суперудобно.
Это один из вариантов того, как можно генерировать свои кастомные отчёты прямо на ходу. Нажали Make report, написали Jora-запрос, Discovery.js layout, получили отчёт на ходу, на лету.
Зашиваем в UI
Но такие кастомные отчёты можно встраивать ещё и в ваш отчёт на CI. Делается это при помощи Statoscope-плагина для webpack. У него есть свойство reports, когда вы добавляете в webpack-сборку Statoscope-плагин, вы говорите: а зашей-ка мне в мой HTML-отчёт вот такой мой кастомный отчёт. Это практически то же самое, что и в предыдущем варианте, только здесь топ-20 самых тяжёлых модулей. Тут мы отсекаем нижнюю границу.
new StatoscopeWebpackPlugin({
reports: [
{
id: 'top-20-biggest-modules',
name: 'Top 20 biggest modules',
data: { some: { custom: 'data' } }, // or () => fetchAsyncData()
view: {
{
data: `#.stats.compilations.(
$compilation: $;
modules.({
modules: $,
hash: $compilation.hash,
size: getModuleSize($compilation.hash)
})
).sort(size.size desc)[:20]`,
view: 'list',
item: 'module-item',
},
},
},
],
})На пятой строке — имя отчёта, на шестой строке — данные, если они нам нужны. Они могут нам понадобиться, например, если мы хотим составить кастомный отчёт с метриками, как менялась наша сборка. Мы можем в data положить данные из хранилища наших метрик. Например, мы можем каждый день записывать среднее время сборки, отправлять в хранилище с метриками и потом вшивать в этот кастомный отчёт. Говорить: возьми метрики отсюда и составь UI-отчёт, где на графике будут располагаться опорные точки, и по этим точкам будет нарисована линия, по сути chart того, как менялась наша сборка с течением времени. График тоже можно описывать средствами Discovery.js, там тоже есть такая вьюшечка. Как мне кажется, это суперудобно.
Те отчёты, которые вы вшиваете в UI-отчёт, появляются в выпадающем меню. Вот как это выглядит.

Можете делиться этим отчётом с коллегами. Напомню, разница в том, что в первом случае вы составляете свои отчёты на ходу и делитесь с коллегами, а в этом варианте вы вшиваете свои отчёты в HTML, который получается у вас на CI. Это не будет ссылка, в GET-параметры которой зашиты запрос, view и так далее. Это будет самый настоящий вшитый в HTML отчёт.
Валидация
Это суперважная и суперклассная история. Почему она для меня важна: я подступался к ней не одну неделю, пытаясь придумать, как валидировать статы. Что это значит: хочется сделать так, чтобы наши pull requests не попали в мастер, если ухудшают нашу сборку (например, увеличивают объём бандла или время сборки). Такие в мастере не нужны.
Как валидировать, чтобы было удобно? Подсмотреть было негде, я нигде не натыкался на подобные решения.
Поэтому пытался что-то изобретать, делал, понимал, что не работает, переделывал, понимал, что неудобно, снова переделывал… Это очень кропотливая история, но как мне кажется, в итоге я справился. В результате появился Statoscope CLI. Это консольная утилита, позволяющая валидировать статы.
Установить CLI
npm install -g @statoscope/cli
Установить плагин для валидации webpack-сборки
npm install -D @statoscope/stats-validator-plugin-webpack
Как это работает? Мне не хотелось изобретать что-то кардинально новое. Ну, вот есть всем знакомый ESLint. Он позволяет линтить JS/TS-файлы. Если что-то идёт не так, наш код не соответствует правилам в конфиге ESLint, пожалуйста, мы получим в консоли ошибку. Если на CI проверки не пройдут — ничего не поделаешь, иди и исправляй эти ошибки.
Я хотел сделать что-то похожее, чтобы не приходилось изучать какую-то суперновую концепцию. Новых вещей вроде Jora и Discovery.js, мне кажется, предостаточно. Поэтому мы устанавливаем консольную утилиту Statoscope CLI. Устанавливаем плагин для webpack, потому что будем валидировать webpack-статы.
Пока что Statoscope работает только с webpack-статами, но в моём идеальном мире он является платформой для любого сборщика, поэтому я архитектурно стремился распиливать каждый кусочек тулкита (не зря я сказал, что это именно тулкит), стремился делать так, чтобы он поставлялся как плагин, а не как что-то захардкоженное. И понемногу я к этому прихожу.
Поэтому устанавливаем Statoscope CLI и webpack-плагин для валидации именно webpack-статов. Если у вас будет Rollup, то в будущем у вас будет плагин именно для его статов, или esbuild-статов. Это как в ESLint: хочется линтить TypeScript — устанавливаете соответствующий плагин, хочется линтить что-то ещё — устанавливаете отдельный плагин и описываете правила.
Вот так выглядит конфиг Statoscope для валидации (на самом деле, не только для нее):
module.exports = {
validate: {
// использовать плагин с правилами для webpack-сборок
plugins: ['@statoscope/webpack'},
reporters: [
// репортер для вывода результатов в консоль
'@statoscope/console',
// репортер для генерирование UI-отчета
['@statoscope/stats-report', {open: true}],
].
rules: {
// время сборки ухудшилось не более чем на 10 сек
'@statoscope/webpack/build-time-limits': ['error', {global: 10000}],
// любые другие правила
}
}
}Здесь все похоже на тот же ESLint — опять же, чтобы не выбиваться из привычных концепций. У нас есть плагины, мы говорим, что будем валидировать при помощи вот такого плагина.
Говорим, что будут вот такие репортеры. Пока в Statoscope два встроенных репортера: консольный (выводит все в консоль) и stats-report (генерирует отчет). Генерация отчета — это киллер-фича валидации, потому что в консоли искать и анализировать по большому числу ошибок трудно.
А потом я хочу эти ошибки, например, привязывать к конкретным модулям. Я хочу открыть модуль и видеть, какие ошибки этому модулю соответствуют. В консоли это делать, мне кажется, невозможно — там текстовый формат без интерактива, делать суперсложные консольные UI-штуки мне не хотелось.
В свойстве rules мы говорим, какие правила хотим применить к валидации. Правил сейчас порядка 12. Например, есть правила, которые бюджетируют размер бандла, initial size бандла, время загрузки бандла на клиент.
Например, вы хотите, чтобы pull requests, которые увеличивают время скачивания вашего бандла на медленном 3G, не попадали в master. Пожалуйста, вот такое правило, в Statoscope оно есть.
Документация по каждому правилу есть, можете зайти в репозиторий Statoscope, там есть ссылка на эти правила, и по каждому правилу есть подробная документация. Они на разные случаи жизни вплоть до «запретить использовать дубли пакетов». Если вдруг сделаете pull request, добавляющий дубль, то такой запрос не пройдет проверку, вас отправят его переделывать — это история про CI.
Запускаем валидацию
Всё довольно просто. Запускаем в консоли:
$ statoscope validate --input ./stats.json
Все довольно просто: вводим команду statoscope validate, которая позволяет валидировать, и указываем, над чем вообще нужно произвести проверки. Получаем отчёт (в консоли и в браузере), тоже похоже на ESLint.
Это мы провалидировали одни статы. Но могут быть как правила, анализирующие единственные статы (вроде «нет ли дублей»), так и правила, которые сравнивают, например, насколько вы увеличили размер сборок? Например, вы хотите увеличить не более чем на 2%. Для этого нужно скармливать статы и из текущей ветки, и из master.
Поэтому немного терминологии:
--input — это текущие статы,
--reference — «эталонные», предыдущие, с которыми происходит сравнение.
Изучаем отчёт
Посмотрите, то же, что мы видели в консоли, но в удобоваримом формате:
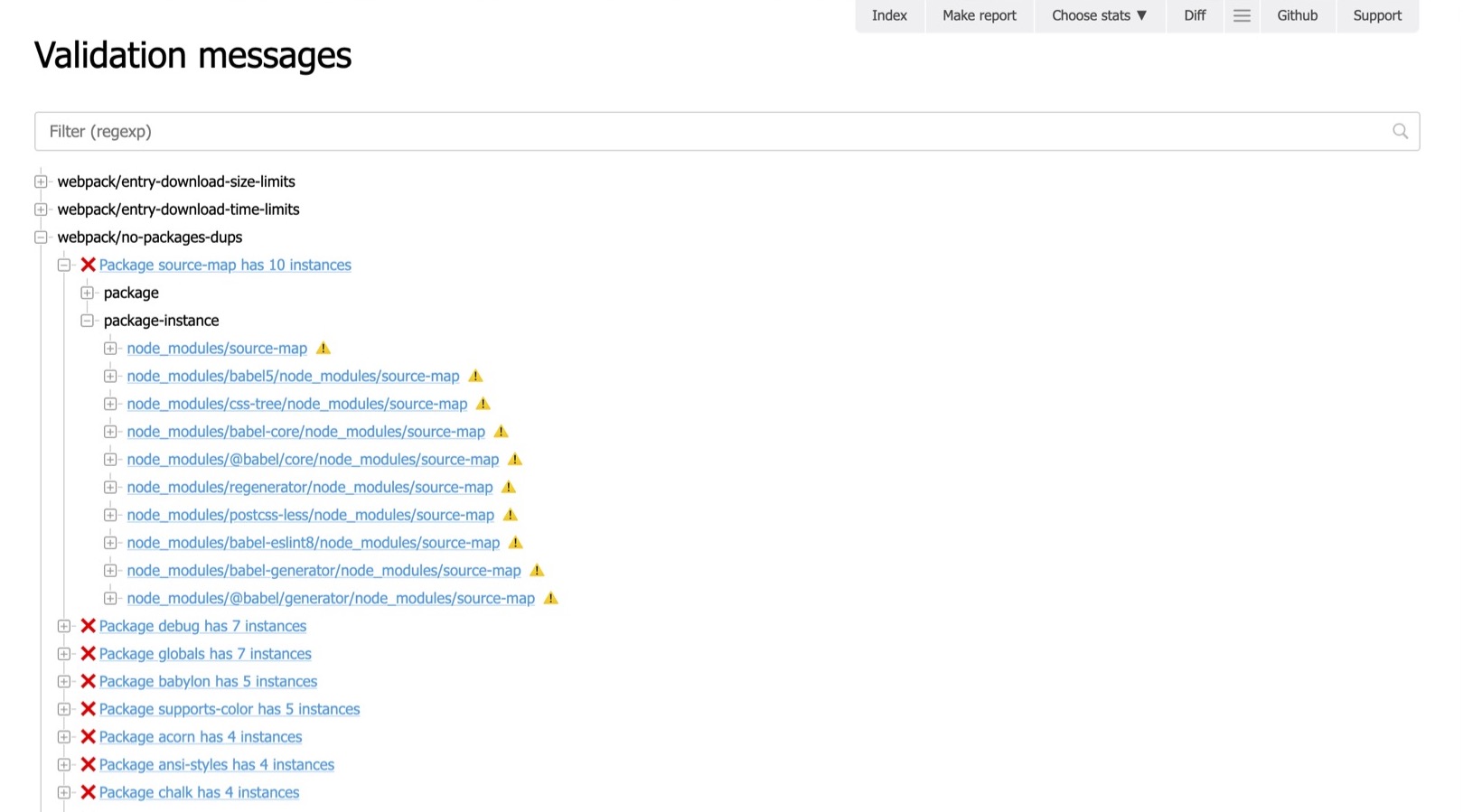
Это такое дерево, где все подсвечено, элементы могут скрываться или раскрываться, могут являться ссылками (можно посмотреть сообщение об ошибке или с какими модулями она связана). Тут же можем пофильтровать, сверху поле для этого. Это гораздо удобнее, чем грепать и анализировать консольный вывод.
Запросы в статы
Следующая часть, касающаяся CLI. Зачем могут пригодиться запросы в статы?
Вот у нас есть stats.json — информация о модулях, чанках, ассетах. Мы хотим получать из статов размер вашей сборки или ее длительность. Это может понадобиться, например, для формирования кастомных комментариев к вашему pull request или для отправки метрик.
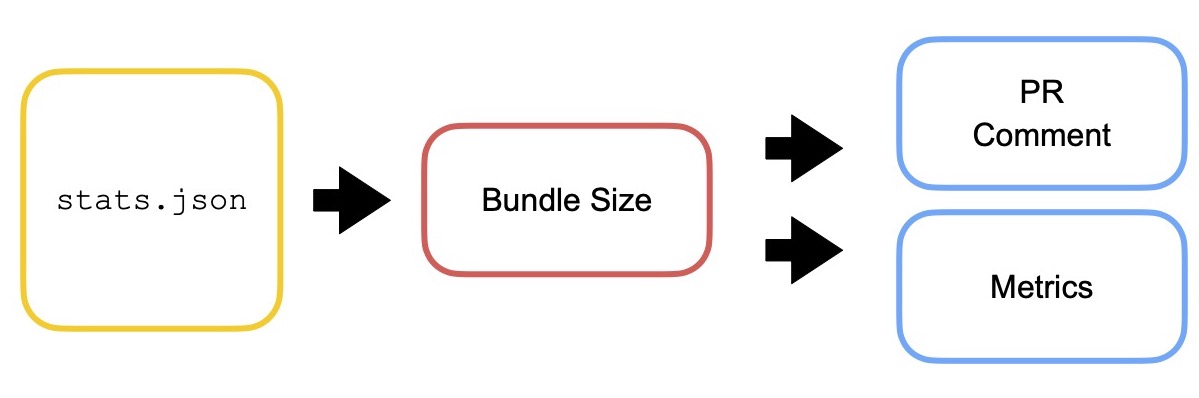
Если у нас есть доступ только к визуальной части, это становится проблемой — непонятно, как оттуда вытащить данные. Но у нас есть консольная утилита statoscope query, при помощи которой мы всё это проворачиваем. Она позволяет делать Jora-запрос.

Вот над зеленой линией указано, какой запрос хотим сделать, над синей — в каких статах делаем запрос. Например, мы говорим: а дай-ка нам количество модулей. И эта утилита вернет его.
Мы можем делать любой Jora-запрос и хранить его в отдельном файле. Вот так можно сказать «дай мне запрос из файла query.jora, "спайпни" (передай) его в statoscope query, примени к таким-то статам, а потом сохрани результат в файл result.json»:

Например, хотим количество ошибок валидации прикреплять в комментарии к pull request — пожалуйста!
CI — собираем все вместе
Посмотрим, что будет, если собрать вместе валидацию и statoscope query. Я покажу это на основе Github Actions.
Коммиты в master
Как я уже говорил, у нас есть input-статы (в текущей ветке) и reference-статы (из master). Как мы их получаем и храним? На каждый коммит в master мы делаем билд (если мы что-то закоммитили в master, значит, там всё хорошо), получаем из него статы, называем файл reference.json и отправляем в наше хранилище артефактов — им может быть всё что угодно.
Если речь идет о GitHub, там уже есть встроенное хранилище артефактов, вам не нужно ничего специально делать, просто говорите «upload artifact». С этого момента у нас есть статы из master, и они где-то хранятся.
Коммиты в pull requests
Но у нас еще есть комменты в pull requests, самое интересное. На каждом коммите в pull request мы точно так же билдим сборку, получаем из нее webpack-статы, называем этот файл input.json, скачиваем артефакт reference.json из предыдущего шага, и вот у нас получаются два файла. Скармливаем два этих стата в statoscope validate (получаем report.html) и statoscope query (получаем result.json).
Всё, у нас есть и UI-отчет, и кастомные данные из query. И теперь мы можем сформировать, например, какой-то кастомный комментарий от лица нашего бота.

Как это можно сделать? Давайте подумаем. Текст комментария — это данные из query плюс какой-то шаблон. В качестве примера приведу Jora-запрос — не такой длинный, как может показаться:

Он получает время сборки из двух статов (reference и input), отнимает одно от другого и получает разницу: ухудшили или улучшили. Делает то же самое с initial size: насколько похудела или поправилась наша сборка. А ещё смотрит на количество ошибок валидации и это тоже дампит в JSON.
А вот наш наш шаблон для комментария. Я выбрал движок шаблонизации mustache, но вообще он может быть любым.

Мы говорим: время сборки изменилось так-то, initial size — так-то, ошибок валидации столько-то. А полный отчёт можешь найти здесь — и видишь ссылку на полный отчёт.
И вот что у нас получается в результате — к pull request прикрепляется такой комментарий от лица бота:

Всё это мы делаем не в воздухе, а как часть нашего процесса, часть нашего CI. У нас есть ряд проверок вроде линтинга нашего кода, и отдельным шагом у нас есть проверка Statoscope: валидация, скачивание артефакта, собственно запрос и формирование комментария. Это делается отдельным шагом. Вот в данном случае проверка Statoscope отмечена крестиком, то есть на валидации что-то упало:
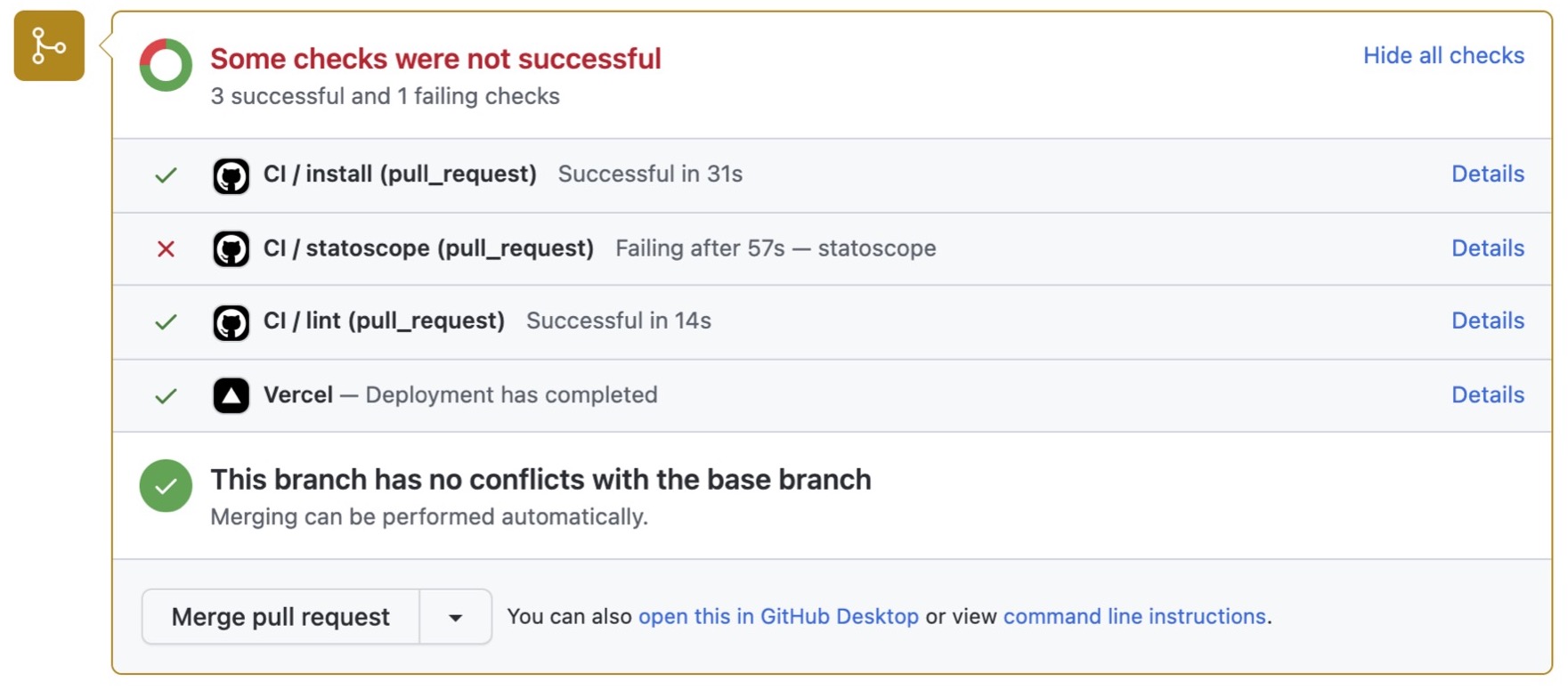
Хочешь посмотреть, что — иди в UI-отчёт из комментария и наслаждайся.
Полный исходный код GitHub Action, делающего всё, что я показал (с шаблоном, Jora-запросом), можно посмотреть в репозитории statoscope.tech. То есть это не эфемерная штука, которую я просто показал — пожалуйста, всё уже работает, на каждом pull request в этом репозитории будет генерироваться такой отчет. Можете завести тестовый pull request и посмотреть, что будет. Ну, и в папке workflows хранится исходный код всех GitHub Actions, можно посмотреть, как это вообще работает.
Планы
Подходя к завершению доклада, давайте я расскажу про планы, потому что их громадьё.
-
Свой формат статов. Напомню, что я веду Statoscope в сторону независимости от конкретного сборщика. Но чтобы не городить огород из разных форматов статов, хочу трансформировать их все в единый формат.
-
Очень хочется добить UI до расширяемого состояния. Вообще расширяемость — это ключевая особенность проекта, к этому очень стремлюсь. Очень хочется, чтобы Statoscope расширялся плагинами.
-
Упомянутая поддержка других сборщиков: я хочу отвязать Statoscope от webpack, чтобы в самом Statoscope даже не упоминался webpack, только в плагинах.
-
Процесс по интеграции в CI хочется объединить в единый Github Action и опубликовать пакетом, чтобы вы не копипастили себе исходный код, а установили Github Action и его использовали.
-
Сейчас вся документация распихана по readme в репозитории. Если зайдете в репозиторий, там есть папка packages, и практически по каждому пакету есть какая-то документация. Очень хочется единый портал с документацией — что-то вроде того, как сделано у Jest (мне безумно нравится, как у них сделано).
-
Хочется поддержать rempl (это технология, демкой которой являлся Webpack Bundle Analyzer в 2016 году). Какая здесь идея: если вы используете сборку в watch-режиме вроде HMR (Hot Module Replacement), вы открываете свой браузер, и у вас доступ к Statoscope есть прямо из средств разработчика в браузере. Вы что-то меняете в исходном коде (например, верстаете какой-то React-компонент), сохраняете, у вас отрабатывает HMR, в инструментах разработчиках вашего браузера точно так же висит Statoscope, и вам не нужно на каждый чих перегенерировать отчёты.
-
Анализ конфига сборщика. Конфигурация, в частности, webpack — это, конечно, отдельная история и отдельный навык. И очень сильно хочется предоставлять коллегам какие-то советы, модифицировать конфиг в режиме реального времени, чтобы он был эффективнее. Когда у Statoscope будет такая функциональность, станет проще делать эффективные сборки.
-
Рекомендации по оптимизации сборки. Хочется, чтобы можно было открыть Statoscope, а он сказал: «Слушай, коллега, у тебя вот тут неправильно, вот тут можно оптимизировать, сделай — и ты сократишь размер своего бандла вот на столько-то мегабайт».
-
Редизайн. Хочу сказать отдельное спасибо моему коллеге Даниле Авдошину, который нашел свободное время для редизайна. Пока это хранится только в прототипах Figma, но я уверен, что руки дойдут и до этого.
-
И моя личная мечта: рейтинг сборок. Я хочу, чтобы сборками можно было меряться. Пока продумываю, как это сделать, но хочется, чтобы был топ сборок по эффективности настройки, по эффективности использования возможностей webpack и так далее.
Зачем я рассказываю о планах? Statoscope — полностью опенсорсный проект, так что issues и pull requests приветствуются. Я быстро отвечаю на запросы, мне это интересно. Если есть желание поучаствовать в серьезном проекте — по любому из перечисленных пунктов можете помочь.
А вот что нарисовал Данила, как это может выглядеть:
Смысл тут в гибком UI: можно настраивать, какие блоки нужны на странице, решать, что я вообще хочу показывать. Например, мне не нужен список модулей, но место этого блока может занимать график.
Данила нарисовал прототип в этом направлении, есть в Figma, тут тоже можно поконтрибьютить. У меня в любом случае руки до этого когда-то дойдут, но можно помочь.
Call to action
Ну и, наконец, к чему я призываю этим докладом:
-
Попробуйте statoscope.tech. Это песочница, там есть демоданные, и можно загрузить свои.
-
Попробуйте @statoscope/webpack-plugin. Напомню, этот плагин собирает гораздо больше информации, чем предоставляет сам webpack.
-
Попробуйте @statoscope/cli для валидации, запросов, формирования комментариев. Кстати, Statoscope сейчас используется в пакете Андрея Ситника size-limit. Недавно мы совместно интегрировали его туда, заменив Webpack Bundle Analyzer. Теперь при запуске size-limit с флажком --why («почему увеличился размер») открывается Statoscope.
-
Делитесь фидбеком, задавайте вопросы.
-
Познакомьтесь с Jora. Это простой лаконичный язык, конструкций не так много. И у вас появится возможность писать как минимум отчеты, а затем правила.
-
Посмотрите в сторону Discovery.js.
-
Напишите свой отчёт.
-
Напишите своё правило валидации.
-
Напишите своё расширение.
-
Приносите свои PR/Issue.
-
Поставьте звездочку на GitHub. Мне будет приятно :)
-
А если доклада оказалось недостаточно, можете посмотреть ещё и видеозапись воркшопа.
Это расшифровка доклада с прошедшей недавно конференции HolyJS. Если он оказался интересен вам, то вас может заинтересовать и следующая HolyJS, которая состоится 18-21 апреля 2022. Подробности о ней — на сайте.