

И снова всем привет!
На этот раз рассмотрим извлекающие методы, которым нужны эталонные рефераты для обучения. При этом эти методы всё ещё могут лишь выбирать предложения из оригинального текста. К методам этой группы и относятся описываемые ниже SummaRuNNer и BertSumExt.
Статьи цикла:
- Постановка задачи автоматического реферирования и методы без учителя
- Извлекающие методы автоматического реферирования ⬅️
Я не хочу объяснять вещи, которые не связаны непосредственно с реферированием. Поэтому под спойлером ссылки на другие источники, в которых необходимые для понимания вещи объясняются подробно.
Первое, что потребуется — понимание того, как обучать нейронные сети. То есть обратное распространение ошибки и различные модификации стохастического градиентного спуска.
???????????? Deep Learning, глава 6
???????????? Stanford CS231n, лекция 4
???????????? курс Воронцова, «Нейронные сети: градиентные методы оптимизации»
Дальше — рекуррентные сети.
???????????? «Understanding LSTM Networks»
???????????? «LSTM – сети долгой краткосрочной памяти»
???????????? Stanford CS224N, лекция 6
И наконец, механизм внимания и внимания-на-себя, Трансформеры и BERT.
???????????? курс Лены Войты, глава «Sequence to Sequence (seq2seq) and Attention»
???????????? курс Лены Войты, глава «(Introduction to) Transfer Learning»
???????????? «The Illustrated BERT, ELMo, and co.»
???????????? «BERT, ELMO и Ко в картинках»
???????????? Stanford CS224N, лекция 14
???????????? «Attention Is All You Need»
???????????? «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding»
Извлекающие методы реферирования
SummaRuNNer
SummaRuNNer — один из первых нейросетевых извлекающих методов автоматического реферирования с учителем.
Основная его идея — метод "оракула", сведение задачи автоматического реферирования к бинарной классификации предложений. Он заключается в том, чтобы набрать предложения из исходного документа так, чтобы квазиреферат из них был максимально похож на эталонный реферат по какой-либо метрике (например, по ROUGE). При этом мы делаем этот набор жадно: сначала выбираем такое первое предложение, которое максимально похоже на эталонный реферат по нашей метрике, потом подбираем второе предложение так, чтобы получившиеся два предложения оптимизировали метрику, и так далее. Останавливаемся тогда, когда добавление нового предложения не улучшает нашу целевую метрику. Вот пример кода для метода "оракула".
Архитектура модели представляет из себя двухуровневую двунаправленную рекуррентную нейронную сеть, первый уровень которой проходится по словам, а второй уровень — по предложениям. Схематично она представлена на рисунке ниже.
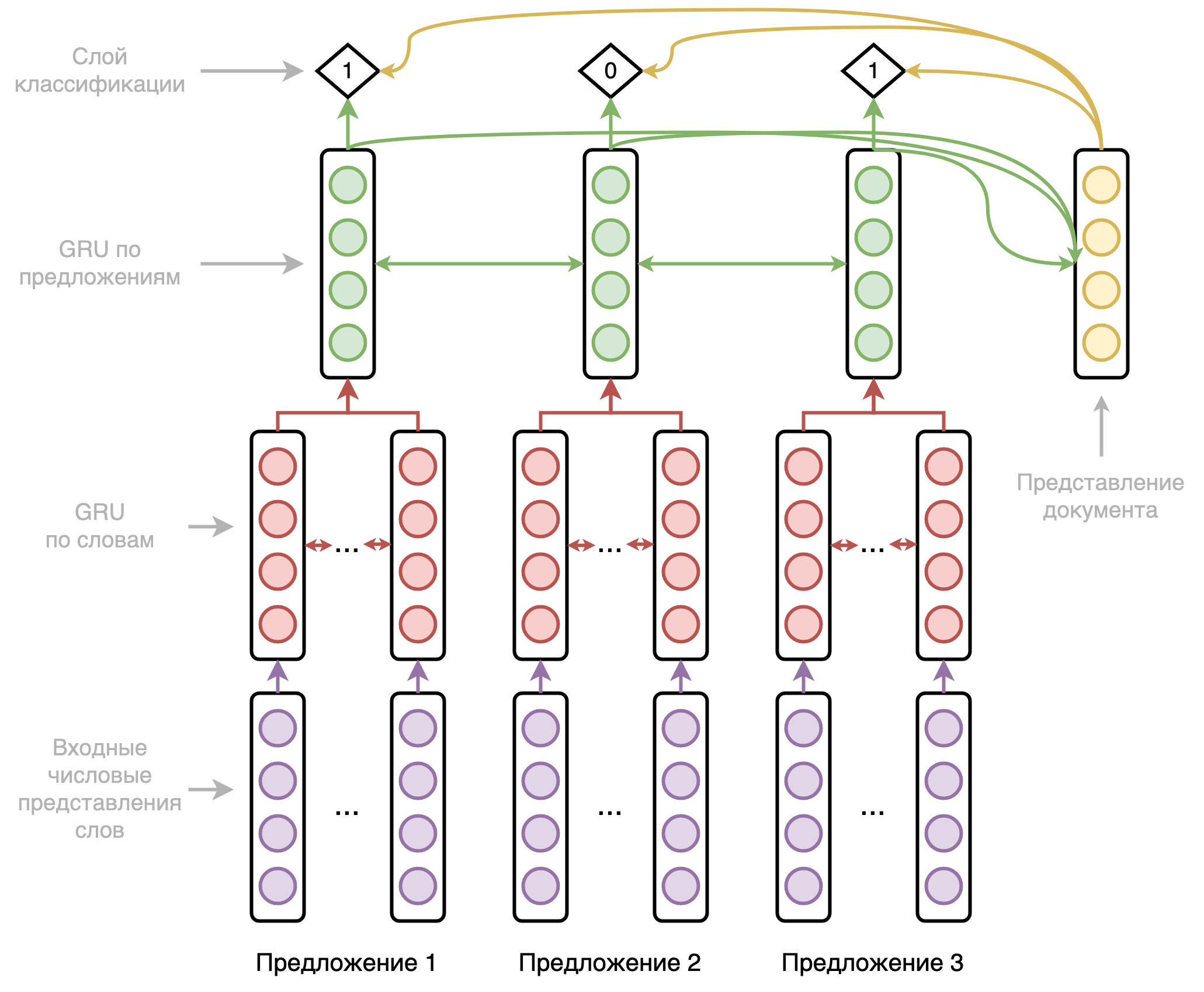
Подробнее на архитектуре я останавливаться не буду, рекуррентные сети уже не особо актуальны, как и большинство применяемых в этой модели хаков. Отмечу только, что модель по ходу своей работы собирает эмбеддинг документа и использует его в предсказаниях вместе с выходами сети и позиционными эмбеддингами. А также используется упомянутый в первой статье цикла штраф за однообразие.
В итоге модель получает для каждого предложения оригинального текста оценку вероятности быть включённым в итоговый квазиреферат. Всё, что нам остаётся сделать — отсортировать предложения по этой оценке и взять первые N в качестве квазиреферата.
SummaRuNNeR отлично показал себя на CNN/DailyMail, который долгое время был основным бенчмарком для реферирования, и до сих пор довольно важен. Модель работала лучше всех других моделей на этом наборе данных на момент написания оригинальной статьи (2016 год). Важное её преимущество — высокая по сравнению с абстрактивными методами скорость работы.
Мне довелось написать эту модель, код доступен тут. Можно запустить на своих текстах, в README есть пример применения. Работает она очень резво и выдаёт вполне приличные метрики.
BertSumExt
BertSumExt — метод извлекающего реферирования на основе BERT и сведения к задаче бинарной классификации тем же методом "оракула".
Модификации по сравнению с оригинальным BERT:
- [CLS] токены в начале каждого предложения. На выходе BERT мы ожидаем на позициях этих токенов эмбеддинги предложений, которые им соответствуют. По моему опыту можно использовать и [SEP] токены для тех же целей, это не принципиально. [CLS] теоретически может работать чуть лучше из-за предобучения на NSP (задача предсказания следующего предложения), но на практике я такого не наблюдал.
- Чередующиеся сегментные эмбеддинги. Напомню, что у стандартного BERT три типа эмбеддингов: эмбеддинги токенов, позиционные эмбеддинги, сегментные эмбеддинги. Сегментные эмбеддинги в оригинальной модели выделяли 2 фрагмента текста для NSP. А вот в этой модели мы для каждого предложения используем один из двух сегментных эмбеддингов с чередованием. То есть токены первого предложения получает первый эмбеддинг, токены второго — второй, токены третьего снова первый, и так далее.
- MMR-like фильтрация по триграммам, то есть по тройкам подряд идущих слов. При наборе предложений в квазиреферат мы пропускаем такие предложения, в которых встретилась хотя бы одна триграмма, которая уже была в ранее набранных предложениях.
- Дополнительный Трансформер-кодировщик над представлениями предложений со своими позиционными эмбеддингами.
Схематично это всё представлено на рисунке ниже.

А теперь немного субъективного: код у коллег так себе. Основная его часть взята из OpenNMT, но переделана в худшую сторону. Абстракции протекают, баги не исправляются, пулл-реквесты не принимаются. 120+ issues чего только стоят. У меня и моего студента, Лёши Бухтиярова, получалось запустить это всё, но никому такой опыт не советую.
И это не единственный неприятный момент. По ablation study модификации с сегментными эмбеддингами в оригинальной статье выходит, что она вообще-то не нужна, прирост там крайне незначительный. В оригинальной статье нет ablation study на последнюю модификацию, но оно есть в предыдущей статье автора. И знаете что? Дополнительный Трансформер тоже не нужен.
То есть выходит, что единственное, что нужно для работы модели — взять представления предложений из [CLS] или [SEP] и подать их в линейный слой с сигмоидой, то есть задача сводится к тегировнию токенов. И это правда работает, вот моя модель на основе RuBERT, обученная ровно таким способом (но чередующиеся сегментные эмбеддинги я всё-таки оставил).
Заключение
Бывают отдельные случаи, когда системам автоматического реферирования не позволено генерировать новые тексты. В конце концов, когда автоматика не генерирует отсебятину, доверие к ней выше. И в таких случаях извлекающие методы с учителем — прекрасный выбор. Классификаторы по построению проще и быстрее генераторов, поэтому эти модели могут пригодится ещё и в CPU-bound среде, типа мобильных устройств.
Как было отмечено, этим моделям нужна обучающая выборка. В отличие от абстрактивных методов, она не обязана быть большой — тысяч или даже сотен пар должно хватить. Есть ли такие выборки для русского? К счастью, да: Gazeta, MLSUM, XLSum, WikiLingua.
Осталось ещё две самых больших и самых главных темы: абстрактивные модели и метрики качества. Увидимся в следующих статьях!
Комментарии (11)

AH89
16.12.2021 18:31Про Форексис - у Вас одна из ссылок в статье была на публикацию:
курс Воронцова, «Нейронные сети: градиентные методы оптимизации»
в публикации на первом же слайде указан имейл адрес автора в домене этой компании

Takagi Автор
16.12.2021 19:23Не очень понятно, как из этого следует связь со мной, Яндексом или вообще чем-либо. Это слайды из курса, который я когда-то очень давно проходил и сейчас смог быстро найти.
AH89
16.12.2021 19:30Ок, я понял, что Ваши ссылки не имеют никакого отношения ни к Вам, ни к Яндекс ) У Форексис просто очень интересное направление деятельности, вот я и уточнил

OlegZH
16.12.2021 19:03Придётся довольно подробно разбираться с постановкой задачи. Далеко не всё понятно. Многое, даже, совсем не.
Если речь идёт о формировании поисковой выдачи, то лично мне совершенно не понятно, почему нельзя говорить о построении струкутрированного индекса страниц в интернете. То есть: сначала специальный механизм проводит анализ страниц, пытается восстановить их структуру (вот здесь нужны методы машинного обучения), привести структуру страниц к единому знаменателю и предоставить пользователю разнообразные семантические индексы.
Здесь надо понимать, что для различных запросов нужно строить и различные рефераты. Это означает, что в каждой конкртеной задачи будет свой критерий сходства.
Есть и ещё одна проблема. Почему-то никто ещё не догадался (кроме разработчиков старинных экспертных систем), сначала, хорошенько опросить пользователя на предмет того, а что тому нужно. Не гадать на кофейной гуще, а активно поинтересоваться. Для этого должден быть мастер-нидекс. Что-то вроде справочника номенклатуры и прписанных к нему регистров. Здесь снова нужны методы машинного обучения. И уже после того, как получен ответ что? где? когда?, можно будет корректным образом решать и остальные задачи.
И последнее. Обучение с подкреплением. Когда я получаю поисковую выдачу, я хочу, чтобы она была изначально структурирована по категориям. Я сам хочу выбирать категоризацию и разрез рассмотрения. Но! Если я вижу, что определённая ветка поисковой выдачи нерелеватная моему запросу, то у меня должна быть возможность поставить на этой ветке метку Это не то дроиды, которые мне нужны, и, тем самым сообщить системе, чтобы она больше никогда не показывала мне это в будущем. Аналогичные рассуждения касаются и фотографий, которые можно заранее отреферировать и группировать фотографии по действительно различным персонам, объектам и темам. Обратная связь позволит постепенно повышать точность и чувствительность распосзнаваия.
Takagi Автор
16.12.2021 19:40Эта статья к поисковой выдаче имеет крайне слабое отношение. Реферирование по запросу — отдельная задача, которая несомненно требует отдельных подходов. Но я всё равно постраюсь ответить.
Проблема всего, что описано в комментарии, банальна — с точки зрения поисковых корпораций это слишком сложно для типичного пользователя. По той же причине, например, медленно умирает язык поисковых запросов. Невыгодно поддерживать фичи, которыми пользуются доли процента пользователей.
Если же мы говорим не о потребительских поисковиках, то системы, спрашивающие пользователя, существуют. Мне это известно как интерактивное реферирование, вот пример статьи на эту тему. Это действительно выглядит круто, и у этого есть и будут свои пользователи, но это не массовый продукт.
OlegZH
16.12.2021 22:06это слишком сложно для типичного пользователя.
Здесь я с Вами не соглашусь. Думаю, что всё наоборот. Компании пытаются взрастить своего пользователя. Они думают, что, чем проще, тем удобнее. Я Вас уверяю, если сегодня предложить более продвинутую поисковую форму (типа расширенного поиска), то все будут с радостью пользоваться ею. А сейчас, когда пользователи привыкли к (не)замысловатости поисковой выдачи, то никто не будет искать что-нибудь нетривиальное. Компании упростили себе работу. В результате, то, что позавчера (где-то ещё в начале нулевых), во времена текстового интернета, можно было найти, терпеливо просмотрев несколько страниц поисковой выдачи, теперь совершенно невозможно найти, заранее зная, что этого не будет даже на сотой странице. (Впрочем, РКН и другие привходящие обстоятельства сейчас сильно подрезают любую выдачу.) А мне, как пользователю, совершенно не нужна вся это поисковая выдача. Мне нужен ответ на свой вопрос. Я хочу получить его в хорошо структурированном виде. Этот вид — реферат! И мы снова возвращаемся к началу разговора и теме статьи.
AH89
Весьма занимательно. +1.
А кроме Яндекс.Новостей это сейчас где ещё используется?
Форексис - это яндексовская дочка?
Takagi Автор
В целом поисковики очень активно исползует реферирование по поисковому запросу: если люди спрашивают что-то простое, лучше сразу показать им ответ на первом экране.
Разные маркетплейсы используют подобные технологии для сводного реферирования отзывов по товарам.
В середине прошлого десятилетия была куча проектов/стартапов по реферированию, они вот тут описаны. А так это в основном упомянутые выше новостные агрегаторы, новостные мониторинги, дайджесты научных статей, всякие сервисы для рерайта.
Про Форексис первый раз слышу, беглый поиск показывает, что он вроде как с Яндексом никак не связан.
AH89
Я почему про Яндекс спросил, потому что если попытаться в том же Google.Drive или Google Photos составить запрос посложнее (с boolean логикой) для поиска картинок с мета-тэгами, присвоенными вручную, то Гугл довольно плохо с такими запросами справляется.
Вы наверняка слышали про специальные решения (на базе того же exiftool.org), которые позволяют вручную присваивать мета-тэги для медиа-данных (картинок и тп)? Меня удивляет почему до сих пор не существует доступных облачных решений на базе OCR-технологий и Machine Learning с обучением, которые бы автоматизировали рутину присвоения тэгов? Сколько бы сразу нагрузки это сняло с плеч тех, кто каждый месяц по работе вынужден просматривать сотни публикаций и делать снэпшоты самого интересного для будущего использования. Ведь каждая публикаций - это порой 50-100 страниц, тогда как нужен порой лишь 1 график или табличка из всей публикации, причём нужда в этом может возникнуть спустя 3 года после прочтения публикации, когда сложно бывает вспомнить даже название издания, в котором она мелькнула. Я уж молчу о том, что у каждого издания нередко свой собственный архив, никак не связанный с архивами других изданий (в смысле возможностей сквозного поиска). Вам что-то о такой проблеме известно? :)
Takagi Автор
Про решения для автоматизации присвоения мета-тегов я до сих пор не слышал, да и в целом проблема мне не очень близка.
А вот задача генерации текста, который описывает картинку, мне известна. Задача в литературе называется image captioning. Аналогично с видео. Если есть обучающая выборка с тегами (а она есть), то все эти методы можно использовать и для тегирования.
Я не очень понял, как картинки плавно перетекли в публикации. Софт для их автотегирования мне тоже не знаком, но он, несомненно, технически возможен и даже несложен.
AH89
Очень удобно когда читаете публикации или статьи в pdf с планшета их скриншотить и потом присваивать картинкам тэги, чтоб потом быстро находить нужное