
В предыдущей статье было показано как, используя несколько модулей Python, можно обрабатывать текстовые данные и переводить их в числовые векторы, чтобы получить матрицу векторных представлений коллекции документов. В данной статье будет рассказано об использовании матрицы векторных представлений текстов в сервисе автокластеризации первичных событий в платформе monq для зонтичного мониторинга ИТ-инфраструктуры и бизнес-процессов.

1. Кластерный анализ данных
Кластерный анализ, или кластеризация – статистическая процедура, разбивающая множество входных данных на сравнительно однородные группы (кластеры) по схожести каких-либо признаков. К основным задачам кластеризации относятся:
классификация и типология входных данных для упрощения их дальнейшей обработки и принятия решений (на каждый кластер своё действие или своя модель),
выделение нетипичных объектов из набора данных для детектирования потенциальных аномалий и обнаружения новизны,
таксономия входных данных для выявления их иерархической структуры (древообразное дробление кластеров на более мелкие по некой мере схожести или различия).
Применительно к системам мониторинга ИТ-инфраструктуры кластеризация может использоваться для выделения во входящих потоках первичных событий однородных групп, схожих по содержащейся в них текстовой информации. Кластерные метки, приписываемые событиям на основе обученной nlp-модели, можно использовать в конвейере обработки для агрегирования событий, для подавления шума, для визуализации, для запуска конкретных скриптов, как ответа системы на определённую проблему, и т.п.
Некоторые особенности кластерного анализа:
в машинном обучении задача кластеризации относится к классу задач обучения без учителя,
существует около десятка различных методов кластеризации – метод k-средних, метод c-средних, самоорганизующиеся карты Кохонена, алгоритмы FOREL, DBSCAN, BIRCH, t-SNE и др.,
решение задачи кластеризации принципиально неоднозначно в силу ряда причин:
число кластеров, как правило, неизвестно заранее и устанавливается либо в соответствии с некоторым субъективным критерием, либо "по построению",
результат кластеризации зависит (иногда существенно) от используемой метрики и алгоритма,
не существует какого-то общепринятого критерия качества кластеризации, только некоторые эвристические оценки.
2. Матрица векторных представлений первичных событий ИТ-мониторинга
Первичное событие в системе мониторинга ИТ-инфраструктуры это, как правило, либо лог-сообщение от какого-то сервиса, службы или приложения, либо сообщение-алерт о выходе какого-то параметра за пределы допуска от систем вроде Zabbix, Nagios и т.п.. Вот типичные примеры сообщений (в формате json) в системе одного из наших заказчиков из Zabbix:
|
|
а также из сборщика логов:
|
Из тел таких сообщений вычленяется текстовая информация, которая и образует “документ” соответствующий данному сообщению, а в совокупности они образуют “коллекцию документов” для построения nlp-моделей.
Как было сказано в начале, процедура получения матрицы векторных представлений коллекции документов с помощью модулей Python была подробно описана в предыдущей статье. Для наглядности, напомним основные этапы этой процедуры и используемые алгоритмы:
токенизация текстов,
нормализация текстов (стемминг или лемматизация),
удаление стоп-слов,
выделение n-грамм,
составление словаря токенов (включая n-граммы),
тематическое моделирование методом латентного размещения Дирихле,
получение семантических векторов с помощью алгоритма Doc2Vec,
объединение тематических и семантических векторов в матрицу полных векторных представлений.
Первым промежуточным результатом построения nlp-моделей, который можно и нужно контролировать, является словарь токенов (включая n-граммы). Вот, к примеру, как выглядит словарь токенов, точнее его начало и конец, в одной из nlp-моделей нашего заказчика, упомянутого выше (в стандартном формате - “token_id, token, token_occurrences” - “идентификатор токена, сам токен, сколько раз токен встречается в коллекции текстов”):
1929 action 3 |
213 центр_услуга 3 |
Видно, в словарь токенов входят как английские, так и русские слова и словосочетания (n-граммы), причём встречаются англо-русские n-граммы, а также 4-граммы (две биграммы, объединённые парсером триграмм). Характерно, что в данном примере большую часть словаря токенов составляют именно n-граммы, а не отдельные слова - в принципе, это можно регулировать выставляя соответствующие пороги в алгоритме выделения n-грамм.
Результаты тематического моделирования методом LDA можно визуализировать несколькими способами. Вот, например, картинка, полученная с помощью модуля wordcloud, которая показывает “облака слов”, образующие первые 20 тем, выделенные алгоритмом LDA в корпусе текстов первичных событий нашего вышеупомянутого заказчика (чем больше вес слова внутри темы, тем больше его визуальный размер):

Также можно построить (и проверить) гистограммы распределения весов выделенных тем во всех построенных тематических векторах первичных событий. В идеале такие гистограммы должны иметь два пика: в районе единицы (события, где данная тема определяющая) и около нуля (события, где данная тема несущественна). Для приведённых выше тематик гистограммы их весов выглядят следующим образом:

Из этой картинки видно, что большинство выделенных алгоритмом LDA тем имеют хорошие распределения весов, но три темы (12, 14 и 15) присутствуют в очень многих событиях – это из-за того, что в их состав входят токены “http”, ”mo” и “ru”. В принципе, эти токены можно включить в список стоп-слов, поскольку для данного корпуса текстов они попадают в категорию “общеупотребительные” и зашумляют данные.
Ещё одним вариантом визуализации результатов работы алгоритма LDA в Python является модуль pyLDAvis, который позволяет сохранять полученную тематическую модель в виде отдельного html файла для дальнейшей интерактивной работы с ней. Это можно сделать в несколько строк (продолжая примеры кода из нашей первой статьи):
Загрузив выходной html файл в веб-браузер, можно увидеть такую картинку:

Одним из достоинств модуля pyLDAvis является то, что он рассчитывает расстояние между темами (по метрике Йенсена-Шеннона) и проецирует его на плоскость так, что можно визуально оценить насколько выделенные LDA темы обособлены друг от друга или перекрываются (график слева на панели). Помимо этого площадь круга темы пропорциональна относительному преобладанию (общему весу) этой темы в корпусе текстов. Справа на панели отображаются токены, входящие в выбранную тему, и сколько раз конкретный токен встречается внутри выбранной темы по сравнению с общим числом его встречаний во всей коллекции текстов. Из приведённой картинки видно, что самыми частыми являются первичные события с темами 4, 7 и 14 (на предыдущих рисунках это темы 3-6-13, из-за того, что в pyLDAvis индексация тем начинается с 1), а также наличие значительного числа частично перекрывающихся тем.
Тематические вектора образуют первую часть матрицы векторных представлений первичных событий, вторую часть образуют семантические вектора, получаемые на выходе алгоритма Doc2Vec. Поскольку нейросетевая структура в Doc2Vec относится к типу систем обучаемых без учителя, очень трудно оценить результаты её работы - по существу, можно только посмотреть на гистограммы распределений числовых значений полученных семантических векторов первичных событий. Вот так выглядят эти гистограммы для nlp-модели из нашего примера:

Подавляющее большинство значений лежат в диапазоне от -1 до 1 (как и должно быть), а чем обусловлена разница в форме распределений и как её интерпретировать сказать сложно.
3. Кластеризация первичных событий ИТ-мониторинга
Полная матрица векторных представлений первичных событий размером N×L, где N - число первичных событий, L - размер векторного представления, полученная на предыдущем этапе, подаётся на вход алгоритма HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise - “Иерархическая основанная на плотности пространственная кластеризация для приложений с шумами”), который непосредственно осуществляет в L-мерном пространстве векторных представлений поиск кластеров и строит модель кластеризации. Механизм работы алгоритма HDBSCAN довольно подробно описан в его документации, мы лишь перечислим основные преимущества, которые имеет HDBSCAN по сравнению с другими алгоритмами кластеризации:
может работать с данными, в которых кластеры имеют произвольную форму, могут быть разного размера и плотности,
даёт достаточно устойчивые результаты на наборах данных со значительным количеством шума и выбросов,
не нуждается в задании входного параметра “Число кластеров” до начала работы,
может обрабатывать большие объемы данных и делает это быстрее большинства других алгоритмов.
Вот пример кода, в котором сначала обучается модель кластеризации, потом рассчитываются несколько оценочных параметров качества этой модели, а затем модель сохраняется на диск для дальнейшего использования:
import hdbscan
import pickle
from sklearn import metrics
inpMtx=np.concatenate( (textTopicsMtx, textD2vMtx), axis=1)
hdb = hdbscan.HDBSCAN(min_cluster_size=10, min_samples=5, prediction_data=True).fit(inpMtx) # training of the clusterization model
clusterLabels = hdb.labels_
nClusters = len(set(clusterLabels)) - (1 if -1 in clusterLabels else 0)
nNoise = list(clusterLabels).count(-1)
nEvents = inpMtx.shape[0]
noiseFraction=nNoise/nEvents
silhouetteCoef=metrics.silhouette_score(inpMtx, clusterLabels)
with open('clusterizationModel', 'wb') as fOut:
pickle.dump(hdb,fOut,protocol=4)где выходные значения noiseFraction - доля событий не попавших ни в один кластер, а silhouetteCoef (коэффициент силуэта) - мера усреднённой обособленности кластеров. Эти параметры можно использовать для оценки качества полученной модели кластеризации: каких-то четких общепринятых критериев нет, в своей практике мы используем модели с noiseFraction<0.05 и silhouetteCoef>0.45.
Для визуализации результатов обучения модели кластеризации можно использовать модули tsne или umap, которые преобразовывают распределения точек в многомерном пространстве в распределения точек в двух- или трехмерном пространстве с сохранением их совокупной структуры, т.е. в определённом роде делают 2D- и 3D-проекции кластеров многомерного пространства. Следующий код можно применить для визуализации кластеров, выделенных алгоритмом HDBSCAN на предыдущем этапе:
import matplotlib.pyplot as plt
from sklearn import manifold
import umap
pallet=plt.get_cmap('rainbow') # spectral, rainbow, terrain
nDim=3
for alg in ['UMAP','tSNE']:
if alg=='UMAP':
reducer = umap.UMAP(n_neighbors=5, min_dist=0.1, n_components=nDim, random_state=42)
mapOut = reducer.fit_transform(inpMtx)
elif alg=='tSNE':
tsne = manifold.TSNE(n_components=nDim, init='random', random_state=42, perplexity=30, verbose=0)
mapOut = tsne.fit_transform(inpMtx)
figHdb = plt.figure(figsize=(17,15))
axHdb = figHdb.add_subplot(111, projection='3d')
axHdb.set_title(r'$'+alg+'$ 3D-visualization',fontsize=16)
axHdb.set_xlabel(r'$'+alg+'_{out}^{1}$',fontsize=14)
axHdb.set_ylabel(r'$'+alg+'_{out}^{2}$',fontsize=14)
axHdb.set_zlabel(r'$'+alg+'_{out}^{3}$',fontsize=14)
im3 = axHdb.scatter(mapOut[:,0], mapOut[:,1], mapOut[:,2], s=2, cmap=pallet, c=clusterLabels)
figHdb.colorbar(im3, ax=axHdb)
figHdb.tight_layout()
figHdb.savefig(alg+'out_3D.png')Здесь следует понимать, что форма кластеров на 2D- и 3D-проекциях определяется спецификой работы алгоритмов UMAP и t-SNE, алгоритм HDBSCAN задаёт только расцветку точек (определяет им кластерные метки) в исходном L-мерном пространстве. В принципе, возможны ситуации, когда сначала применяется алгоритм UMAP или t-SNE для уменьшения размерности пространства данных (для этого они, собственно, изначально и придумывались, по крайней мере, UMAP), а потом проводится кластеризация алгоритмом HDBSCAN в этом редуцированном пространстве. Но на практике (если визуализация особо не нужна), кластеризация алгоритмом HDBSCAN в L-мерном пространстве отрабатывает значительно быстрее (в несколько раз), чем цепочка редуцирование пространства данных L→3 алгоритмом UMAP плюс кластеризация HDBSCAN в 3-х мерном пространстве, а для большого объема данных (N>106) это много часов на стандартном PC.
В нижеследующем примере модель кластеризации строилась на векторных представлениях около 200 тысяч первичных событий из системы мониторинга нашего вышеупомянутого заказчика. Алгоритм HDBSCAN (c параметром min_cluster_size=10 – минимальный размер кластера) выделил в этом наборе данных порядка 300 кластеров (с результатом noiseFraction=0.019 и silhouetteCoef=0.6). А вот так выглядят визуализации этих кластеров алгоритмом UMAP в 3D- и 2D-проекциях (разбросанные по объему фиолетовые точки – это события с clusterId=-1, т.е. не отнесённые ни к одному кластеру, “шум”):
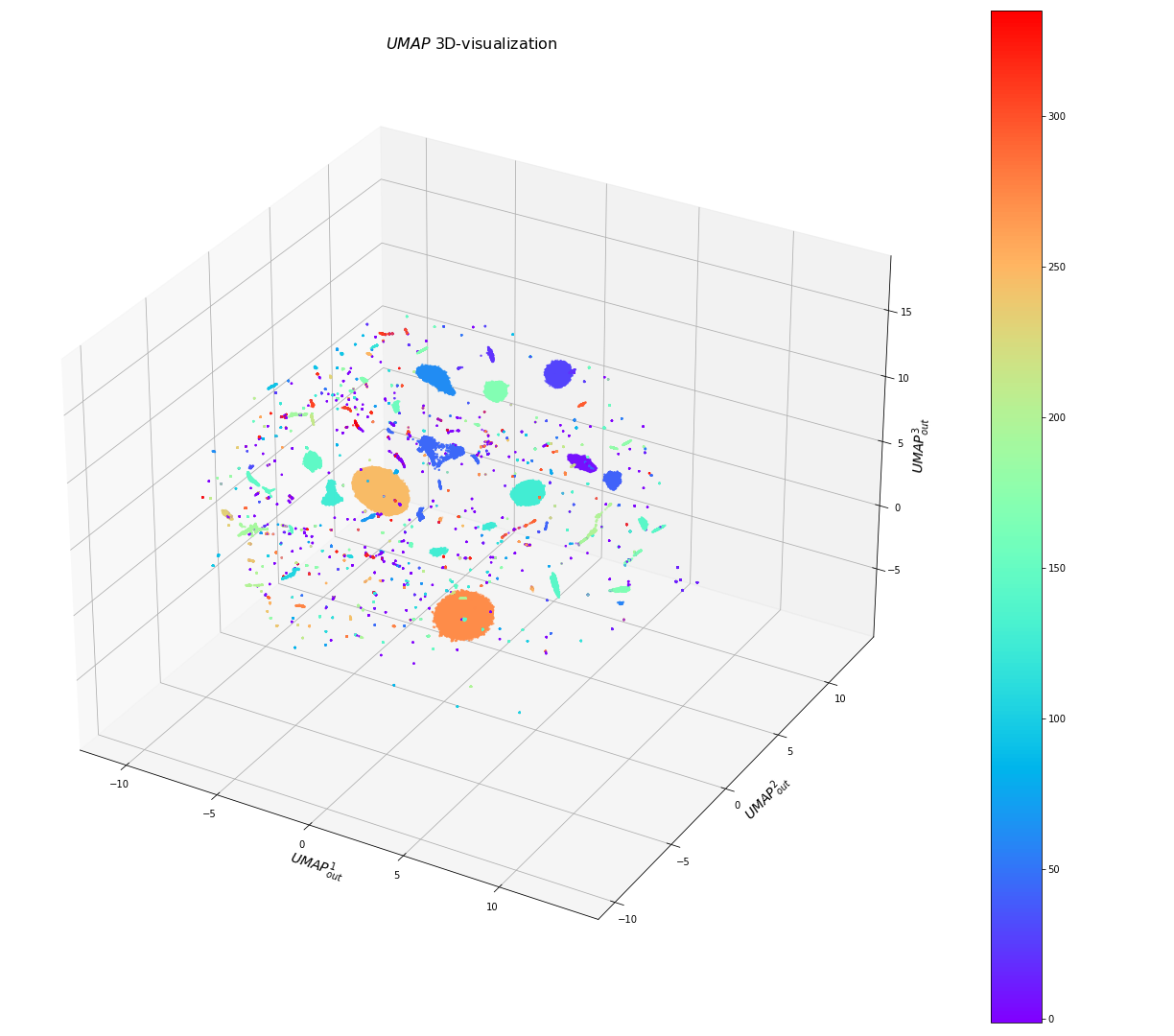

Результаты визуализации тех же кластеров алгоритмом t-SNE:


Из приведённых картинок видно, что алгоритм HDBSCAN выделил очень много мелких кластеров, которые почти не перекрываются с большими кластерами, но достаточно часто образуют агломераты друг с другом. Это говорит о том, что имеет смысл укрупнить кластеры путём увеличения значения параметра min_cluster_size при обучении модели. Например, при значении min_cluster_size=100 выделяется уже только 80 кластеров, при этом noiseFraction=0.037 и silhouetteCoef=0.64, а UMAP 2D-визуализация получается следующей (стало больше “шума”, некоторые мелкие кластеры слились):

Варьирование минимальным размером кластера является основным инструментом подстройки модели кластеризации под решение конкретной задачи или выполнение функциональных требований (но не всегда достаточным инструментом).
Сравнивая предыдущие картинки, также можно увидеть, что алгоритм UMAP стремится сделать кластеры более компактными и разделёнными в пространстве, в то время как t-SNE пытается сохранить при проецировании некоторую усреднённую плотность точек в кластерах исходного L-мерного пространства и занять большее фазовое пространство. Какой из алгоритмов использовать для визуализации и в какой проекции – вопрос больше эстетический (хотя 2D-проекции UMAP выглядят более информативными и он отрабатывает существенно быстрее t-SNE).
Сохранённая модель кластеризации используется, чтобы приписывать кластерные метки новым первичным событиям, которые приходят в систему мониторинга:
|
где hdb - модель кластеризации, vectorRepres - векторное представление нового события (полученное из ранее обученной nlp-модели), clusterId - метка кластера, в который попадает данное событие, а clusterPos - некоторая мера положения события относительно условного “центра” кластера (1 - в центре, 0 - на периферии).
Для полноты картины приведём несколько примеров кластеров, выделенных нашей моделью автокластеризации, с текстами сообщений, попавших в эти кластеры:



Видно, что в первом случае в кластере объединены проблемы с очередями rabbitmq, во втором случае – проблемы с базой данных, в третьем – проблемы с перегруженным CPU. Во всех случаях в кластеры объединяются проблемы с разных триггеров системы мониторинга.
4. Сервис автокластеризации
Сервис автокластеризации встроен в архитектуру платформы в модуль AIOps в виде трёх микросервисов:
ml-model, который строит и обучает nlp-модели и модели кластеризации,
ml-processor, который встроен в конвейер обработки первичных событий и использует обученные модели для приписывания кластерных меток новым событиям ИТ-мониторинга,
ml-scheduler, который запускает обучение новых моделей после накопления определённого количества новых данных.
Микросервис ml-model является самым требовательным по ресурсам CPU и оперативной памяти: для обучения средней по размеру модели (с числом событий около миллиона) потребуется 8-16 GB оперативки (в зависимости от среднего размера первичных событий) и 10-15 часов вычислений на стандартном PC (здесь следует отметить печальный факт, что алгоритм HDBSCAN в его Python имплементации не распараллелен и использует только одно ядро CPU). Следует также учитывать, что бинарный файл сохранённой модели кластеризации может занимать несколько GB дискового пространства.
Микросервис ml-processor менее требователен к ресурсам, но ему также нужно несколько GB оперативной памяти, чтобы в неё можно было загрузить модель кластеризации. При этом выставление кластерных меток происходит достаточно быстро – в среднем 6-7 миллисекунд на событие, т.е. один инстанс ml-processor может обрабатывать 150 событий в секунду.
Выставленные на событиях кластерные метки могут использоваться дальше в конвейере обработки стандартными способами:
для фильтрации событий,
для задания синтетических триггеров,
для агрегирования событий и подавления шума,
для визуализации событий,
для запуска скриптов.
5. Заключение
В данной статье мы привели подробный пример использования nlp-библиотек на Python для построения сервиса автокластеризации первичных событий в системе мониторинга ИТ-инфраструктуры и бизнес-процессов.