
Хабр, привет! Меня зовут Наталья Тоганова, я работаю бизнес-аналитиком в компании GlowByte Consulting. В этой статье хочу поговорить о деньгах и тестах. А точнее о том, как с помощью тестов определить, где больше денег.
Представим стандартную рабочую ситуацию аналитика. Дано две выборки с N наблюдениями. В каждой — данные о продажах лимонада молодыми хочу-стать-единорогами предпринимателями. В выборке А — предприниматели из Москвы, в выборке Б — из Санкт-Петербурга.
Каков стандартный порядок действий в этом случае? В первую очередь мы решаем, что будем сравнивать: выручку с покупателя или выручку с точки за день. Затем смотрим на распределение и, исходя из этого, выбираем тест: при нормальном — тест Стьюдента, а при распределении с длинным хвостом — тест Манна-Уитни. И с чувством выполненного статистического долга идем пить лимонад.
С этим подходом я и хочу поспорить в данной статье. Далее будет питч в пользу теста Стьюдента для подсчета денег (выручки, среднего чека, долга, дохода или любого другого схожего финансового показателя), когда у нас двусторонняя гипотеза, а распределение при этом может быть ненормальным или нормальным.
Дисклеймер: я не пытаюсь опровергнуть одно из базовых условий теста Стьюдента (нормальное распределение).
Что за тесты?
Перед тем как перейти к аргументам в пользу теста Стьюдента, коротко расскажу о нем, а затем рассмотрю тест Манна-Уитни (его используют как альтернативу тесту Стьюдента в случаях, когда у выборки нет нормального распределения).
Тест Стьюдента
В тесте Стьюдента мы сравниваем средние двух выборок с учетом стандартной ошибки и числа наблюдений. И на этой основе делаем вывод о схожести или различии двух выборок.
Тест Стьюдента рассчитывается по формуле:
где
где X1 — среднее первой выборки, X2 — среднее второй выборки, Sp — объединенное стандартное отклонение, размер выборки одинаковый, то есть n = n1= n2 и объединенное стандартное отклонение Sp , где дисперсия одной и второй выборки
В тесте Стьюдента можно проверять одно- или двухстороннюю гипотезу. В этой статье мы рассматриваем только двухстороннюю.
Тест Манн-Уитни
Тест Манн-Уитни ранговый. В его основе лежит принцип сравнения двух датасетов по рангам входящих в них величин. Чем датасет больше, тем сложнее рассчитывается тест (см. Statisticshowto).
А теперь несколько аргументов в пользу теста Стьюдента
Когда мы выбираем тест, то нередко это trade-off между несколькими возможными вариантами. Один может быть более интерпретируемым с точки зрения бизнес-задачи, другой — точнее или быстрее. Какому из тестов отдать предпочтение, аналитик решает, исходя из ситуации.
Ниже приведу четыре аргумента в пользу теста Стьюдента. Они находятся в привычном trade-off треугольнике:
интерпретируемость (аргумент 1),
точность (аргумент 2 и 3),
скорость (аргумент 4).
В случае теста Стьюдента trade-off нет. Его легко интерпретировать, поскольку он дает ответ именно на тот вопрос, который ставит бизнес (где среднее выше?). Он точен, то есть робастен, и быстро рассчитывается. Почему это так — расскажу дальше.
Интерпретируемость
Нам принципиально важно различие между средними значениями, а не формами распределения. Ведь нам необходимо быть уверенными в среднем доходе или выручке в месяц. При ненормальном, скажем, логнормальном распределении возможна ситуация, когда среднее и медиана у выборок одинаковые, но в одной хвост чуть длиннее. В этом случае тест Манна-Уитни покажет разницу, но для бизнеса ее нет.
(Подробнее об этом парадоксе можно почитать в работе М.В. Фагерлэнд [Fagerland, 2012].)
Точность
Точность, робастность и надежность теста Стьюдента при ненормальном распределении аргументируется двумя способами: через центральную предельную теорему и на основе экспериментов. Разберем каждый аргумент отдельно.
Выход центральной предельной теоремы
У нас обычно много данных. Конечно, понятие много данных относительное и весьма туманное, но когда работаешь с выборками, где собраны тысячи наблюдений, можно утверждать, что именно это и есть много. Тест Стьюдента сравнивает средние, поэтому при большом объеме данных начинает работать центральная предельная теорема. Кроме того, при большом объеме наблюдений разные тесты асимптотически эквивалентны. Признаю: последнее — аргумент в пользу Манн-Уитни, но питч же в пользу теста Стьюдента. Не забываем!
(Подробнее о том, почему работает центральная предельная теорема, можно почитать, например, в небольшой заметке Дж. Бартлетт [Bartlett, 2013], в монографии Э. Леманна [Lehmann, 1999] или в статье Т. Ламле и соавторов о значимости нормального распределения при тесте Стьюдента и регрессии [Lumley et.al., 2002]. В других работах это упоминается как аксиома.)
Кстати, именно факт большого числа наблюдений позволяет использовать стандартную формулу теста Стьюдента, в которой нет поправки на разницу между стандартными отклонениями в выборках [Lumley et.al., 2002].
Рассмотрим на примере, как благодаря центральной предельной теореме с ростом числа наблюдений тест Стьюдента становится эквивалентен тесту Манна-Уитни.
Как проверяют робастнес теста и что вообще значит «робастнес» в таком случае? Тест робастен, когда он стабильно показывает разницу между выборками при наличии этой разницы. Как проверяем: берем две выборки, между которыми точно есть разница, вытаскиваем из каждой подвыборку определенного размера и проводим тест. Если в достаточном числе случаев тест показывает разницу — признаем его подходящим для использования в рабочих задачах.
За отправную точку для такого упражнения возьмем логнормальное распределение со средним -0.7 и стандартным отклонением -0.5. Почему берем именно его? Потому что именно с ним или с чем-то на него похожим я чаще всего сталкиваюсь в работе: горб с большинством данных слева и довольно длинный хвост справа. К слову, в статьях, на которые я ссылаюсь, можно найти примеры и с другими распределениями.
Вот так будет выглядеть график со 100 тысячами наблюдений из логнормального распределения заданной формы.
Код
import pandas as pd
import numpy as np
from scipy.stats import lognorm, ttest_ind, mannwhitneyu
import matplotlib.pyplot as plt
import seaborn as sns
import time
mu = 0.7
std = 0.5
data = lognorm.rvs(s=std, scale=mu, loc=0, size=100000, random_state=42)
hx, hy, _ = plt.hist(data, bins=50, color="blue", alpha=0.5)
plt.ylim(0.0,max(hx)+0.05)
plt.grid()
plt.show()
plt.close()
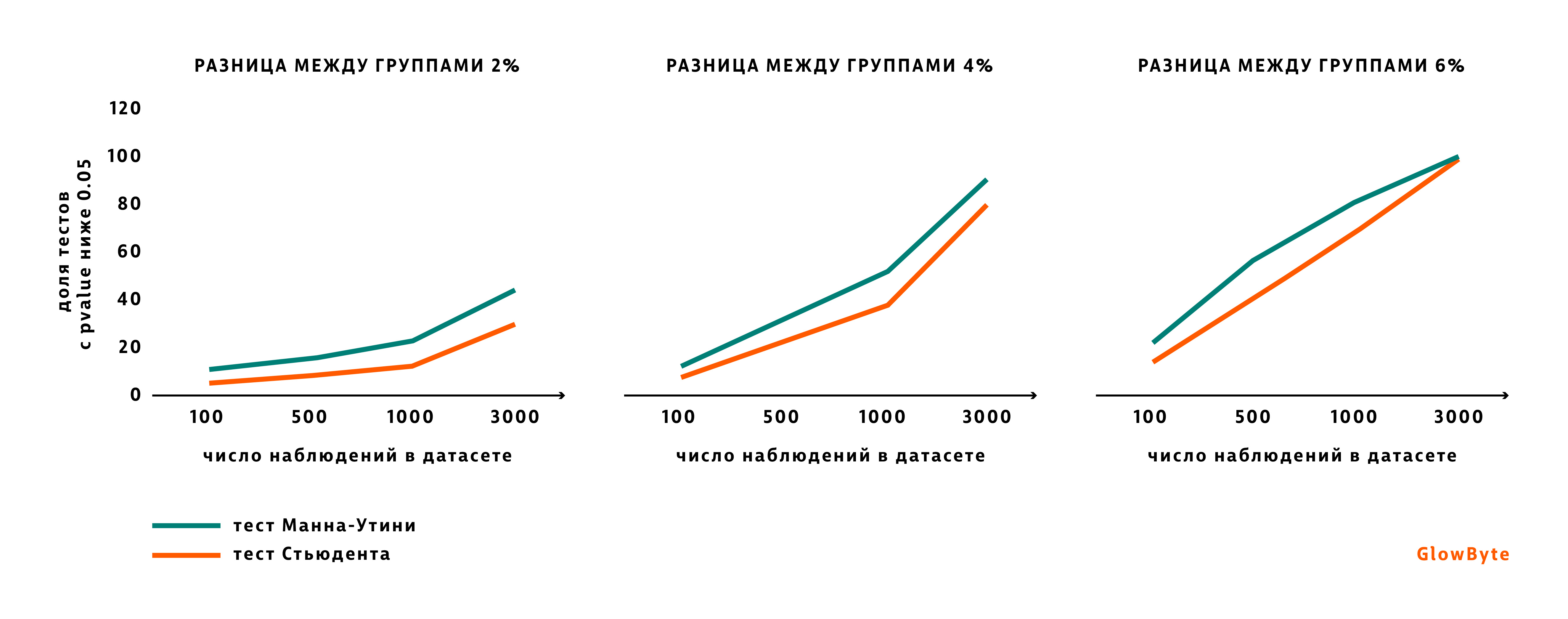
Далее мы создаем второй датасет со слегка отличным от первого средним. Среднее будем двигать на 2 проц.пункта несколько раз. Чтобы показать, что размер выборки также имеет значение, поменяем и этот параметр. Начнем с выборок с сотней наблюдений и закончим выборками, где наблюдений три тысячи. Выборки будем сравнивать между собой, используя тест Стьюдента и тест Манна-Уитни. При этом нас будет интересовать, какова доля тестов — будь то тест Стьюдента или тест Манна-Уитни, — которые стабильно показывают, что разница между группами есть. То есть pvalue ниже 0.05.
Код
# Нужны импорты, которые были в коде выше
counts = [100, 500, 1000, 3000] # Число наблюдений в каждой выборке
differnce = np.linspace(1.02,1.06,3) # Различия между средним выборок - от 2% до 6% с шагом в 2 проц.пункта
number_of_experiments = 10000 # Число экспериментов
rep = {'Размер групп': [], 'Разница между группами %': [], '% теста Стьюдента ниже 0.05': [],
'% теста Манна-Утини ниже 0.05': [], 'Среднее датасета 1' : [], 'Среднее датасета 2': []}
for dif in differnce:
for count in counts:
pvalue_ttest = []
pvalue_mw = []
data_first_mean = []
data_second_mean = []
for ex in range(number_of_experiments):
# Создаем два дата сета: один с средним 0,7 и стандартным отклонением - 0,5, а второй с большим среднем
mu = 0.7
std = 0.5
data_first = lognorm.rvs(s=std, scale=mu, loc=0, size=count)
data_second = lognorm.rvs(s=std, scale=mu*dif, loc=0, size=count)
# Смотрим, есть ли разница между датасетами согласно тестам
p_value_ttest = ttest_ind(data_first, data_second)[1]
pvalue_ttest.append(p_value_ttest)
p_value_mw = mannwhitneyu(data_first, data_second)[1]
pvalue_mw.append(p_value_mw)
data_first_mean.append(data_first.mean())
data_second_mean.append(data_second.mean())
rep['Размер групп'].append(count)
rep['Разница между группами %'].append((dif-1)*100)
rep['% теста Стьюдента ниже 0.05'].append(round(sum(np.array(pvalue_ttest) < 0.05) / number_of_experiments*100, 0))
rep['% теста Манна-Утини ниже 0.05'].append(round(sum(np.array(pvalue_mw) < 0.05) / number_of_experiments*100, 0))
rep['Среднее датасета 1'].append(round(sum(data_first_mean)/len(data_first_mean), 2))
rep['Среднее датасета 2'].append(round(sum(data_second_mean)/len(data_second_mean), 2))
report = pd.DataFrame(rep)Мы получим такую таблицу.

Проделав упражнение, мы видим, что с ростом наблюдений и/или значимости различий между группами тесты становятся взаимозаменяемыми.
А как быть, если данных немало, но мы все же не уверены, что их именно много? Бывают ли такие ситуации при меньших выборках, когда условие о нормальности распределения не так значимо? Короткий ответ: да, бывает. Даже при маленьких выборках с ненормальным распределением тест Стьюдента надежен. Об этом — ниже.
Небольшое лирическое отступление и ответ на вопрос: «Что такое реально мало данных?». Вдруг вам интересно, насколько маленькими могут быть выборки при тесте Стьюдента. Спойлер — очень маленькими: например, два или пять наблюдений [Winter de., 2013]. Но сложно себе представить ситуацию, когда это знание можно будет применить в работе, если вы, как и я, работаете с большими данными. Разве что блеснуть на собеседовании.
О чем говорят эксперименты
У сравниваемых выборок одинаковая форма распределения, почти неотличимое стандартное отклонение, и они одного размера. Это может показаться неожиданным. Скажу больше, для всех А/Б тестов, которые мы проводим и результаты которых оцениваем, это почти аксиома.
Почему именно аксиома? Продукты, для улучшения которых активно или даже непрерывно используют А/Б тестирование, чаще всего находятся на той фазе развития, когда менеджмент не ожидает прироста, скажем, выручки в полтора-два раза. От изменений ждут небольшого среднего прироста показателя, что в совокупности будет значимым для доходности. Этот средний прирост может быть как результатом роста на каждой отдельной сделке или операциях каждого клиента, так и оптимизацией, при которой есть просадка в одном сегменте и одновременно компенсирующий ее рост в другом.
Однако не это важно. Важно, что распределение интересующей нас переменной в группе А и группе Б практически неотличимо. А если оно и отличается (случай с просадкой в одном сегменте), то все равно не настолько, чтобы влиять на робастность теста. То есть, случаев, когда бы приходилось сравнивать выборку А с нормальным распределением и выборку Б с логнормальным длинным хвостом в работе почти не встречается.
«А что же с размером выборок? Почему и тут все идентично?» — спросите меня. Признаю, здесь все куда сложнее. Злой дух сравнения 1% клиентов с 99% оставшимися нет-нет да и промелькнет на горизонте аналитика. Однако давайте будем стремиться к идеалу. Далее коротко расскажу, почему с разным размером выборок можно примириться. Ну а если вам все же нужно делать сравнение 1 к 99, то посмотрите статью И.Мирмахмадова о том, как протестировать, будут ли такие сравнения работать именно в вашем случае [Mir, 2020].
Вернемся к ситуации, когда у нас выборки примерно одинакового размера и имеют схожую форму распределения. То, что тест Стьюдента может быть надежным в этом случае и при сравнительно маленьких выборках, доказывается экспериментами, которые проводили исследователи. И не раз. Как правило, в работах проверялось, как ведет себя тест Стьюдента при разнице размеров выборки, стандартных отклонений и форм распределения выборок. Приведу здесь выводы нескольких работ. Между ними есть небольшие разногласия, ведь наука не наука, если там нет разноголосицы или небольшой фальсифицируемости по К. Попперу. Но напомню, что за вами всегда остается право протестировать, работают ли описанные в научных статьях закономерности на ваших данных.
В работах, о которых пойдет речь, рассматривались маленькие выборки, хотя между самой ранней и самой поздней публикациями прошло почти полвека. В начале 1970-х годов исследователи делали расчеты без Python или R, практически на листочке [Havlicek, Peterson, 1974], а вот уже С. Гаррен и К. Осборн считали на R [Garren, Osborne, 2021].
Результат обеих работ схож: тест Стьюдента признан устойчивым. Но в более поздней работе были технические условия, которые давали возможность протестировать большее число вариантов, особенно что касается коэффициента эксцесса (kurtosis) и асимметрии распределения (skewness). Был сделан вывод, что низкий коэффициент эксцесса распределения ассоциируется с нестабильностью теста, тогда как при высоком коэффициенте эксцесса и асимметрии тест Стьюдента робастен [Garren, Osborne, 2021].
В более ранней работе мы находим почти такой же вывод, только иначе сформулированный: разница в стандартном отклонении между выборками и значительные отличия в форме распределения (разнонаправленные хвосты) приводят к тому, что тест ненадежен. В остальных случаях, даже при ненормальном распределении и различиях в числе наблюдений между выборками, когда форма распределения совпадает и стандартное отклонение идентично, — тесту Стьюдента вполне можно доверять [Havlicek, Peterson, 1974]. Следует отметить, что в других работах утверждается, что отклонения размера выборок более чем на 10% значительно снижают робастность [Posten, 1984].
Таким образом, при условии, когда выборки одного размера, распределение одной формы, а стандартное отклонение почти идентично, тесту Стьюдента вполне можно доверять.
Скорость
Тест Стьюдента быстрее считается. Этот аргумент я приберегла на конец, вдруг все предыдущие показались неубедительными. Если вам приходится регулярно и много считать — скорость может стать важным критерием. Длительность расчета теста Стьюдента не растет пропорционально росту числа наблюдений в сравниваемых выборках, поскольку расчет среднего выборки в целом довольно быстрая процедура. При тесте Манна-Уитни, напротив, с увеличением числа наблюдений сложность расчета растет быстрее, ведь определение ранга — более дорогая процедура, нежели подсчет среднего.
Проверим это утверждение. Возьмем две группы, размер которых будем постепенно увеличивать от 100 наблюдений до 10 тысяч. Проведем по одной тысяче тестов с каждым размером групп для теста Стьюдента и теста Манна-Уитни и посмотрим динамику по времени. График ниже показывает, что с ростом числа наблюдений времени на тест Манн-Уитни нужно больше, чем на тест Стьюдента.
Код
Для теста Стьюдента
# Нужны импорты, которые были в коде выше
counts = [100, 500, 1000, 3000] # Число наблюдений в каждой выборке
differnce = np.linspace(1.02,1.06,3) # Различия между средним выборок - от 2% до 6% с шагом в 2 проц.пункта
number_of_experiments = 10000 # Число экспериментов
rep = {'Размер групп': [], 'Разница между группами %': [], '% теста Стьюдента ниже 0.05': [],
'% теста Манна-Утини ниже 0.05': [], 'Среднее датасета 1' : [], 'Среднее датасета 2': []}
for dif in differnce:
for count in counts:
pvalue_ttest = []
pvalue_mw = []
data_first_mean = []
data_second_mean = []
for ex in range(number_of_experiments):
# Создаем два дата сета: один с средним 0,7 и стандартным отклонением - 0,5, а второй с большим среднем
mu = 0.7
std = 0.5
data_first = lognorm.rvs(s=std, scale=mu, loc=0, size=count)
data_second = lognorm.rvs(s=std, scale=mu*dif, loc=0, size=count)
# Смотрим, есть ли разница между датасетами согласно тестам
p_value_ttest = ttest_ind(data_first, data_second)[1]
pvalue_ttest.append(p_value_ttest)
p_value_mw = mannwhitneyu(data_first, data_second)[1]
pvalue_mw.append(p_value_mw)
data_first_mean.append(data_first.mean())
data_second_mean.append(data_second.mean())
rep['Размер групп'].append(count)
rep['Разница между группами %'].append((dif-1)*100)
rep['% теста Стьюдента ниже 0.05'].append(round(sum(np.array(pvalue_ttest) < 0.05) / number_of_experiments*100, 0))
rep['% теста Манна-Утини ниже 0.05'].append(round(sum(np.array(pvalue_mw) < 0.05) / number_of_experiments*100, 0))
rep['Среднее датасета 1'].append(round(sum(data_first_mean)/len(data_first_mean), 2))
rep['Среднее датасета 2'].append(round(sum(data_second_mean)/len(data_second_mean), 2))
report = pd.DataFrame(rep)Для теста Манна-Уитни
# Нужны импорты, которые были в коде выше
counts = np.linspace(100, 10000)
number_of_experiments = 1000
rep = {'Тест': [], 'Размер групп': [], 'Число тестов': [], 'Время' : []}
for count in counts:
start = time.time()
for ex in range(number_of_experiments):
mu = 0.7
std = 0.5
data_first = lognorm.rvs(s=std, scale=mu, loc=0, size=round(int(count),0))
data_second = lognorm.rvs(s=std, scale=mu, loc=0, size=round(int(count),0))
p_value_mw = mannwhitneyu(data_first, data_second)[1]
end = time.time()
rep['Тест'].append('Mannwhitneyu')
rep['Размер групп'].append(round(count, 0))
rep['Число тестов'].append(number_of_experiments)
rep['Время'].append(end - start)
report_mann = pd.DataFrame(rep)
#report_mann.to_csv()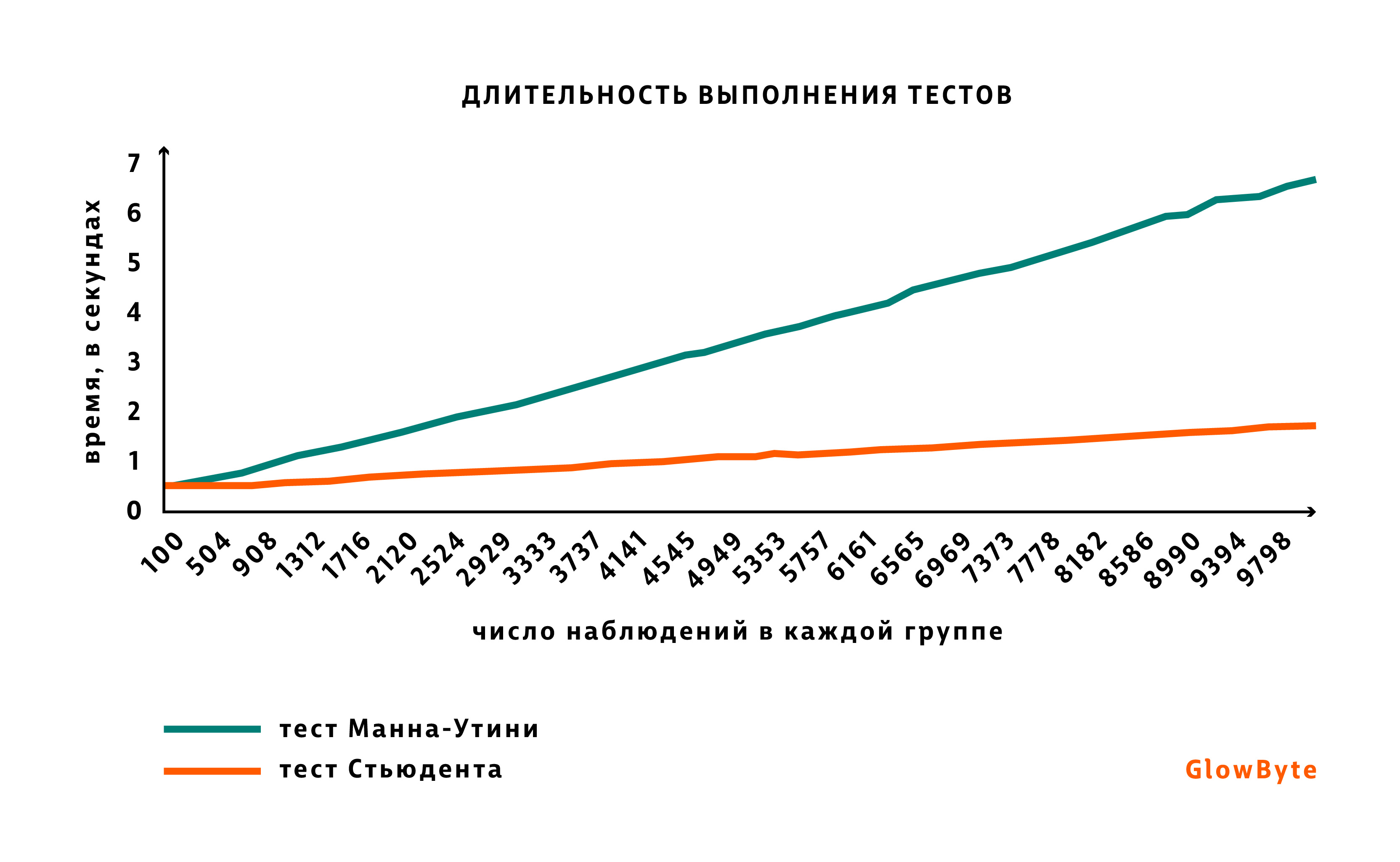
В заключение хочу сказать, что теория и научные изыскания прекрасны, но надежнее проверять подходы на данных, с которыми вы работаете. И лишь убедившись, что все именно так, как вы предполагали, делать выводы. В то же время бывают задачи, когда нужен именно тест Манна-Уитни или другой ранговый, а тест Стьюдента категорически не подходит. Ведь иногда нам важно различие именно формы распределения между группами. Не все же деньги считать.
Когда статья уже была написана, мне попались две работы, которые созвучны всему вышесказанному. Первая — статья Д. Лунина, Авито, «Как улучшить ваши А/Б тесты: лайфхаки аналитиков АВИТО. Часть 1» [Лунин, 2021]. Там подробно рассказано о том, как проверить робастность теста Стьюдента (или любого другого) на данных. Вторая — статья «История одного обмана или Требования к распределению в t-тесте» [Stats&Data ninja, 2021]. В последней Stats&Data ninja перечисляет источники, которые могут ввести в заблуждение по вопросу целесообразности теста Стьюдента.
Литература
Bartlett, J. (2013). The t-test and robustness to non-normality. The Stats Geek.
Stats&Data ninja (2021). «История одного обмана» или «Требования к распределению в t-тесте». Medium.com. 15.09.2021.
Garren, S. T., & Osborne, K. M. (2021). Robustness of T-test Based on Skewness and Kurtosis. Journal of Advances in Mathematics and Computer Science, 36(2), 102–110. https://doi.org/10.9734/jamcs/2021/v36i230342
Fagerland, M.W. (2012). t-tests, non-parametric tests, and large studies—a paradox of statistical practice? BMC Med Res Methodol 12, 78. https://doi.org/10.1186/1471-2288-12-78
Havlicek, L. L., & Peterson, N. L. (1974). Robustness of the T Test: A Guide for Researchers on Effect of Violations of Assumptions. Psychological Reports, 34(3_suppl), 1095–1114. https://doi.org/10.2466/pr0.1974.34.3c.1095
Lehmann, E.L. (1999). Elements of Large-Sample Theory. Springer.
Lumley, T., Diehr, P., Emerson, S., & Chen, L. (2002). The Importance of the Normality Assumption in Large Health Data Sets. Annu. Rev. Public Health, 23, 151–69. https://doi.org/10.1146/annurev.publheath.23.100901.140546
Mir, I. (2020). Дисбаланс в A/B-тестах. Есть ли разница между 99%/1% и 50%/50% в экспериментах? Medium.com. 06.10.2020.
Posten, H. O. (1984). Robustness of the Two-Sample T-Test. In D. Rasch & M. L. Tiku (Eds.), Robustness of Statistical Methods and Nonparametric Statistics (pp. 92–99). Springer Netherlands. https://doi.org/10.1007/978-94-009-6528-7_23
Winter de, J. C. F. (2013). Using the student’s t-test with extremely small sample sizes. Practical Assessment, Research and Evaluation, 18(10), 1–12. https://doi.org/10.7275/e4r6-dj05
Лунин, Д. (2021). Как улучшить ваши А/Б тесты: лайфхаки аналитиков АВИТО. Часть 1. Habr.com. 11.08.2021.
Про Feature Store, MLOps и другие вопросы вокруг применения ML и продвинутой аналитики в реальных бизнес-задачах мы регулярно общаемся в нашем сообществе NoML:
lea
Агитирую за использование перестановочных тестов.