
2021-й год закончился, уже почти прошел первый месяц 2022-го. Прошлый год стал знаменательным для JPA Buddy: первый публичный релиз, встреча с первым пользователем и рост до одного из самых высокорейтинговых плагинов на IntelliJ IDEA Marketplace. А еще завтра у Баддика первая годовщина — ровно год назад вышел первый публичный релиз! В этой статье мы решили поделиться историей, которая стоит за JPA Buddy, достижениями 2021-го года, некоторыми интересными фактами, которые получили от нашего комьюнити, и планами на 2022-й.

История
Для начала пара слов о том, как появился JPA Buddy. Идея плагина для IntelliJ IDEA появилась в 2019 году и она уходит корнями в другой продукт – Jmix (бывший CUBA Platform). Jmix – это фреймворк и прилагающийся к нему инструментарий для быстрой разработки бизнес-приложений. Как можно догадаться, слой доступа к данным в Jmix построен поверх JPA и инструмент разработки – Jmix Studio – позволяет построить модель данных (JPA сущности) при помощи визуального дизайнера практически без написания кода.
Этот визуальный дизайнер стал одной из самых любимых фич Jmix Studio, но его можно было использовать только для разработки приложений на фреймворке Jmix. И очевидно, что это сильно ограничивало круг разработчиков, которые бы хотели использовать визуальные инструменты IDE для работы с JPA в своих проектах. В итоге, мы решили выделить эту функциональность в отдельный плагин для IntelliJ IDEA, чтобы облегчить работу всем, кто использует JPA.
Разработка и преодоление трудностей
JPA – обширная и всеобъемлющая спецификация. Как уже было сказано, JPA Buddy основывался на функциональности Jmix Studio, в ней мы поддерживали довольно ограниченное подмножество фич из спецификации. Очевидно, что поддержка всех аспектов практически невозможна, особенно силами команды из двух разработчиков. Нам пришлось изучить спецификацию от корки до корки и сделать около сотни опросов, чтобы лучше понять, чем именно пользуется большинство разработчиков.
Для спецификации JPA есть несколько имплементаций. Не секрет, что Hibernate занимает доминирующее положение в этом семействе, но его доля далека от 100%. То же самое можно сказать о Spring с его проектом Spring Data JPA – доминирует, но не занимает весь рынок; у нас ещё есть Micronaut, Java EE/Jakarta EE, Eclipse Microprofile и основанные на нем фреймворки: Quarkus, Helidon и т.д. Проблема в том, что для этого многообразия фреймворков JPA Buddy должен генерировать код исключительно в контексте текущей имплементации JPA. Также генерируемый код определяется сопутствующими библиотеками приложения: Lombok, Hibernate Types, MapStruct... не говоря уже о выборе самого языка Java или Kotlin. Научить Баддика всем этим трюкам в условии суперпозиции всех условий было не очень просто, но вполне реально.

Изначально внешний вид дизайнера сущностей мы взяли из Jmix Studio. Он был разработан для тех, кто не был знаком с JPA (да и даже с Java не очень), но свою задачу выполнял хорошо. Но в процессе сбора обратной связи сразу стало ясно, что аудитория JPA Buddy будет отличаться от пользователей Jmix – это будут профессиональные Java разработчики. Поэтому, в отличие от Jmix, JPA Buddy никогда не скрывает исходный код под окном визуального дизайнера. Плагин аккуратно предлагает свою помощь в создании кода в соответствии с парадигмами JPA, а генерация кода сопровождается визуальными визардами. В итоге разработчики могут использовать практически все возможности плагина, без необходимости знать и помнить эти возможности наизусть.
В завершение нужно упомянуть, что работа с существующим исходным кодом – та ещё проблема. JPA Buddy – помощник, а не хозяин. Инструмент может давать совет, но не исправлять код без вашего ведома. Нам пришлось делать генерацию кода такой, чтобы не притащить ненужные или неожиданные изменения в существующие исходники. Чтобы это стало возможным, мы «тренировали» JPA Buddy «понимать» код, написанный разработчиком. Это заняло достаточно много времени, пока мы учились разбирать и обрабатывать исходники так, чтобы при этом не ломать плагин.
Миссия
Когда мы поняли, что подход Jmix c его визуальными дизайнерами не соответствует ожиданиям целевой аудитории, мы решили явно обозначить основные цели создания JPA Buddy:
Сделать порог входа для разработчиков как можно ниже
Ускорить разработку в части JPA и всего, что с этим связано
Форсировать применение лучших практик, при условии выбранных разработчиком библиотек, языка и имплементации JPA
Что касается генерации кода и инспекций, то мы тщательно изучили предмет, чтобы быть уверенными, что все соответствует спецификации, документации и лучшим практикам. Здесь нужно сказать спасибо Eugen Paraschiv, автору baeldung.com, а также Vlad Mihalcea и Thorben Janssen – их статьи и видео о JPA, Hibernate и Spring Data бесценным источником информации для всего Java сообщества.
Итоги 2021 года
2021-был отличным годом для всей команды JPA Buddy. Давайте пробежимся по некоторым итогам:
Выкатили больше 25 релизов, 6 мажорных версий
Закрыли больше 800 тикетов
Количество загрузок в JetBrains Marketplace: больше 500 тысяч уникальных и больше 1.6 миллиона в целом
Из 95 отзывов на странице плагина 91 был на пять звезд, средний рейтинг – 4.9
Заслужили статус «Recommended Plugin для IntelliJ IDEA»
Запустили собственный youtube канал
-
Сделали четыре выступления:
Вместе с Антоном Архиповым из JetBrains провели вебинар по лучшим практикам и частым ошибкам при использовании JPA в Kotlin
Совместно с RedGate (компанией, поддерживающей Flyway) сделали доклад о проблемах при миграции баз данных
В компании с JUGRu Group обсудили правила, которым мы следовали при разработке JPA Buddy
Написали больше 100 страниц документации
Получили больше 1500 сообщений в нашем канале Discord
Опубликовали восемь статей в нашем блоге
Количество подписчиков в Twitter превысило 2022, из 110 стран, количество просмотров твитов за год – более трех миллионов
А теперь давайте вспомним всю функциональность, разработанную в 2021-м:
-
Визуальные дизайнеры для:
JPA сущностей
Spring Data JPA репозиториев
Liquibase Changelog-ов
Файлов SQL и миграций Flyway
Генерации DTO и поддержка MapStruct
-
Помощь в написании кода:
Поддержка Kotlin
Инспекции для проверки правильности определения сущностей
Инспекции для безопасного использования Lombok
Контекстно-зависимая кодогенерация, доступная по комбинации клавиш
-
Версионирование баз данных:
Автоматическая генерация Liquibase скриптов
Автоматическая генерация Flyway миграций
Подсказки и возможность отключения небезопасных миграций
-
Импорт схемы базы данных:
Генерация сущностей из таблиц
Добавление атрибутов на основе столбцов таблиц в БД
Кэширование схемы БД для удаленных серверов

Даже сложно поверить, что все это было сделано такой небольшой командой всего за год!
Изучение мнений сообщества разработчиков
JPA Buddy – всего лишь инструмент. Именно поэтому мы стараемся фокусироваться на том, чего хотят разработчики и не влезать со своим собсвенным мнением в чужие монастыри. В 2021-м году мы делали несколько опросов, результатами которых хотелось бы поделиться.
Lombok
Похоже, нет такого Java разработчика, который был бы равнодушен к Lombok’у. Его или любят или ненавидят (ещё есть немного тех, которые про него не слышали :)). Такое радикальное отношение подтверждается и тем фактом, что твит про Lombok стал самым просматриваемым в аккаунте JPA Buddy. Но, к сожалению, Lombok – это ещё и причина самого большого количества типовых ошибок при использовании в определении сущностей JPA. При реализации поддержки Lombok в JPA Buddy, мы набили много шишек. В итоге, помимо новой функциональности в плагине, появилась статья в блоге, в которой мы собрали все советы по использованию Lombok в JPA. Этот пост стал самым читаемым в 2021-м году. Суммарно публикация на DZone и в блоге набрала около 20 тысяч просмотров за апрель.
Kotlin
Мы анонсировали поддержку Kotlin в конце апреля 2021. На тот момент мы и не думали, что JPA Buddy будет поддерживать тандем из Kotlin и JPA примерно в 15% проектов. А ещё одним сюрпризом стало то, что было невозможно нагуглить более-менее полное руководство по использованию JPA в приложениях, написанных на Kotlin. Когда мы собирали материалы и практики по использованию Kotlin, было немного страшновато видеть, что почти на каждом ресурсе по использованию Kotlin с JPA были примеры кода, которые могли привести к серьезным проблемам в приложении. В некоторых примерах использовались data-классы, а в некоторых – closed классы. Мы решили это исправить и собрать все практики использования Kotlin c JPA в одной статье. Почти 10 тысяч разработчиков прочли этот материал, в нашем хит-параде эта публикация уверенно занимает второе место.
Помимо всего этого, мы также сделали несколько опросов в Twitter, ниже – интересные факты и выводы из этих опросов.
Что первично в определении модели данных?
В этом посте мы спросили сообщество на предмет того, что является источником истины для построения модели данных. Вышло так: 56% разработчиков сначала меняют таблички в базе, а затем синхронизируют изменения с JPA сущностями, в то время как 44% делают наоборот: сначала меняют модель JPA, а затем обновляют БД.
На тот момент в JPA Buddy уже была возможность генерации скриптов обновления БД. Это делалось путем сравнения JPA модели и базы данных – большое подспорье тем, для кого JPA модель первична. Но получалось, что более половины разработчиков не могли полноценно пользоваться JPA Buddy для генерации обновлений из БД.

Это привело к решению назначить наивысший приоритет задаче импорта схемы данных в JPA модель, и мы даже пересмотрели свой взгляд на то, как это должно выглядеть в продукте. До опроса импорт представлялся как одноразовая операция: разработчик импортировал бы схему данных в JPA модель на начальном этапе разработки проекта, и работал бы дальше только с ней. Результаты опроса показали, что разработчики используют импорт постоянно, после каждого изменения таблиц в базе. Таким образом, было принято решение использовать подход, при котором таблицы (и даже поля) импортировались бы в JPA модель по одной, позволяя пользователю выбирать только необходимые изменения, без перегенерации всего кода JPA сущности.
Надеемся, что JPA Buddy теперь отвечает требованиям обоих лагерей разработчиков: и тем, у кого база – источник истины и тем, у кого это – JPA модель.
Flyway vs Liquibase
Сейчас JPA Buddy позволяет генерировать скрипты обновления БД и для Liquibase, и для Flyway, однако, в первых версиях мы предлагали поддержку только для Liquibase. Чтобы понять, насколько приоритетна задача поддержки Flyway, мы запустили следующий опрос:
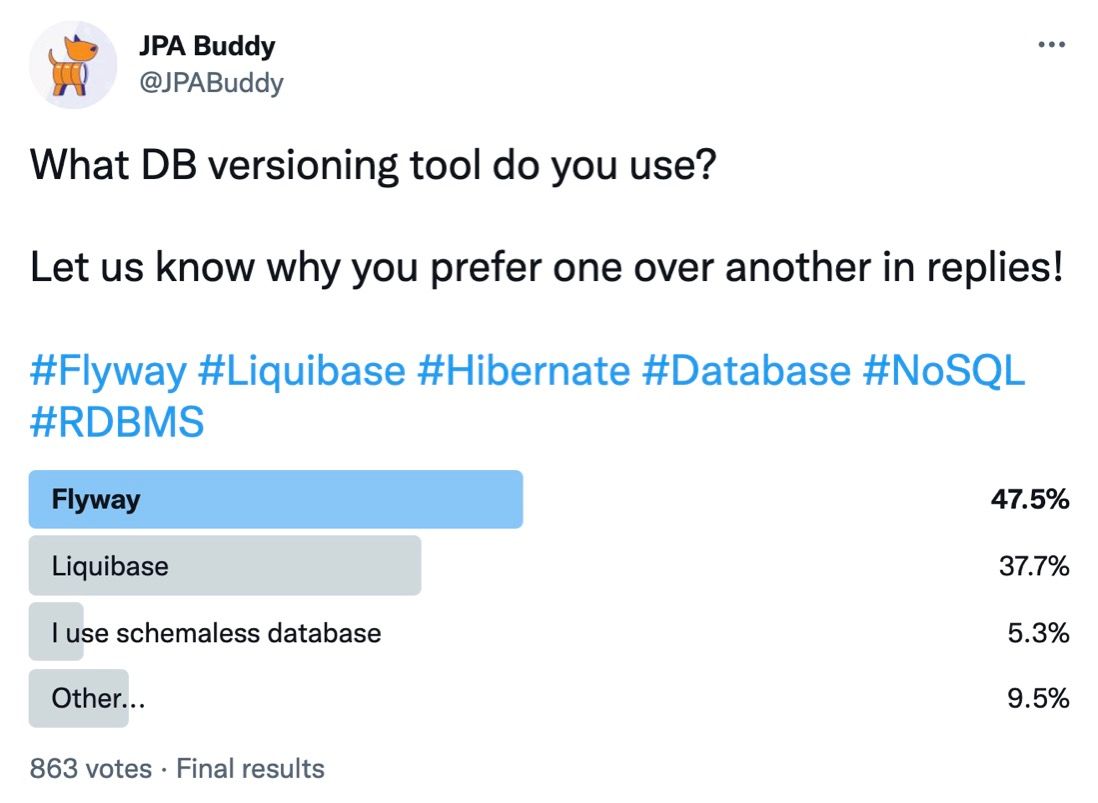
Как видно, в Java сообществе Flyway выигрывает. После анализа комментариев к опросу, были сделаны следующие выводы:
Люди выбирают Liquibase из-за возможности отката изменений, загрузки данных из CSV, preconditions, labels и contexts.
Основное преимущество Flyway – очень понятная концепция и простота использования.
Некоторые все ещё верят, что обновление БД – не задача разработчика, а этим должен заниматься администратор базы данных…
Правильный маппинг для типа данных SQL Timestamp/Datetime
Когда мы разрабатывали функциональность импорта таблиц БД в объекты JPA, то нужно было делать отображение типов данных столбцов таблиц в Java типы. И угадайте, про какой тип данных мы спорили больше всего? Конечно же Timestamp/Datetime! Так и не придя к общему знаменателю, мы решили попросить совета у сообщества и сделали ещё один опрос:
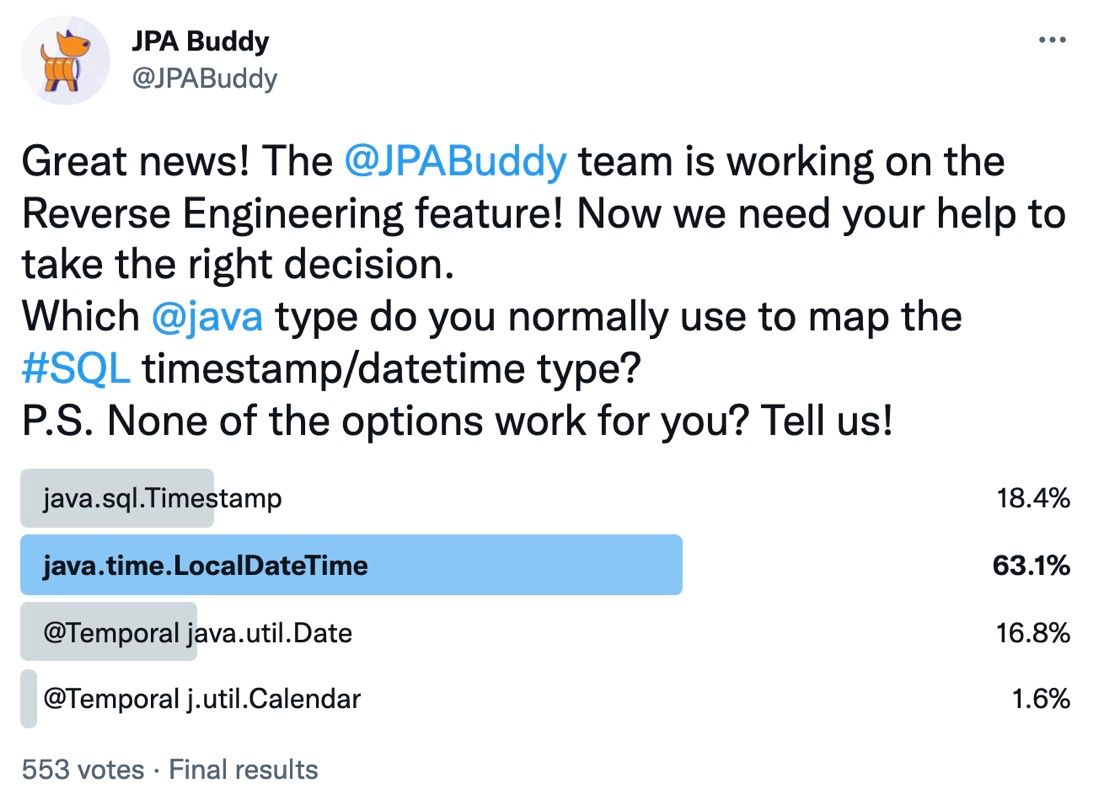
Как видите, 63% проголосовали за LocalDateTime. Ho! Спасибо Simon Martinelli и Corneil du Plessis, они первыми заметили, что правильного ответа здесь нет! Оказалось, что то, что нам было нужно – java.time.Instant!
Планы на 2022
Начнем с того, что с 2022-го некоторые фичи JPA Buddy будут доступны только по подписке. Весь год разработка плагина велась на энтузиазме и финансировалась изнутри компании. Спасибо Haulmont за то, что весь 2021 год мы смогли сохранять JPA Buddy полностью бесплатным. Однако, в 2022 мы всё же хотим получить канал стабильного финансирования, чтобы развивать плагин не по остаточному принципу, а более интенсивно. Ориентируемся на 1 апреля. Мы выбрали freemium модель: большая часть функциональности будет бесплатной, включая все визуальные редакторы для сущностей, Spring Data репозиториев, Flyway и Liquibase скриптов. Автоматическая генерация скриптов версионирования для Liquibase и Flyway, а также импорт схемы данных в JPA станут платными: 1,9$ в месяц для индивидуальных пользователей. JPA Buddy останется бесплатным для студентов и для академического использования, а также для обучающих курсов и школ программирования. Также мы предлагаем скидку 50% для учебных и некоммерческих организаций. Мы уверены, что наш инструмент экономит большое количество времени, и пара долларов в месяц окупится уже через несколько дней, если вы будете использовать JPA Buddy.
Во-вторых, мы планируем финализировать функциональность импорта таблиц БД в JPA, чтобы поддерживать не только импорт одиночных таблиц, но и пакетные операции. В идеале нам бы очень хотелось сделать так, чтобы можно было создавать приложение целиком на основе только лишь базы данных: вы указываете схему, а JPA Buddy генерирует все сущности, репозитории и даже REST контроллеры для CRUD операций.
В-третьих, мы планируем новую функциональность: «smart hints» - умные подсказки. Разработчики будут видеть различные советы, которые помогут сделать ваше приложение лучше, например, подсказки для более эффективного маппинга или рекомендации для оптимизации выборки данных.
А в багтрекере у нас ещё есть много того, над чем можно подумать. Мы будем приоритезировать всю эту функциональность в соответствии обратной связью и постепенно добавлять в наш плагин.
Мы видим следующий год ещё более продуктивным! Надеемся, COVID в конце концов покинет нас в 2022-м и мы сможем опять путешествовать по миру, видеться в офлайне, обмениваться идеями, как сделать софт лучше, а разработку – приятнее. Мы благодарим все пятьсот тысяч разработчиков, которые попробовали JPA Buddy в 2021-м году и дважды благодарим тех, кто сообщал нам об ошибках или делился своими соображениями и идеями.
Комментарии (15)

vasyakolobok77
28.01.2022 14:26+4Для начала, спасибо вам за отличный инструмент, пользуемся в команде им активно!
Но вот по поводу маппинга timestamp у меня для вас огорчение. Ответ в твиттере был верный! Заренее извиняюсь за портянку текста, просто не раз уже вижу такое заблуждение.
Простой timestamp – это метка времени "не привязанная" к временной зоне, это именно LocalDateTime. Timestamp with timezone – это метка "привязанная" к временной зоне, это метка в глобальном течении времени, и это Instant / OffsetDateTime.
Timestamp можно замаппить на Instant только если у нас бекенды приложения в одной временной зоне.
Давайте рассмотрим связку java и postgres, в котором работа с датой / временем сделана по канону. При отправке значения timestamp оно форматируется в строку с временной зоной бекенда. Сервер postgres принимает эту строку и разбирает ее в целое число. Внутреннее представление timestamp / timestamp with tz – это простое int64. Разница лишь в том, что при разборе timestamp переданная в строке TZ не учитывается, а при разборе timestamp with tz временная зона учитывается и значение приводится к UTC.
При вычитке значения из бд идет обратное преобразование: для timestamp временная зона не передается и бекенд "предполагает" свою, а для timestamp with tz временная зона клиента (бекенда) учитывается и время выравнивается сервером бд по ней.
В итоге, если есть бекенд А во временной зоне GMT+05 и бекенд Б в зоне GMT+10, то при передаче с бекенда А простого timestamp (без TZ) 10:00:00+05 на сервере БД сохранится 10:00:00 и при вычите на бекенд Б придет тоже 10:00:00, но только на Б "предполагается" уже GMT+10. А это никак не метка в глобальном течении времени. Это никак не Instant. Это просто LocalDateTime.

aleksey-stukalov Автор
28.01.2022 15:29+1Спасибо большое, что не поленились и все написали :)!
Да, я понимаю ваш кейс. Мы так изначально и думали. Но все же в общем случае это именно инстатнт. Давайте посмотрим на примеры.
Мы ставим отметку времени получения данных - это именно момент времени или
Instant. Мы фиксируем дату и время принятия документов в посольство и этоInstant. Фиксируем дату нарушения ПДД -Instant. Т.е. это характеристика некоторого события. И, как выяснилось, это и есть основные кейсы.Кейсы, подходящие под вашу логику такие: Студент должен подать документы на поступление в ВУЗ до 10:00 утра. И таквезде, т.к. это распоряжение МинОбраза. В Москве, Самаре, Воронеже,... Это и есть
LocalDateTime. И, количественно, по нашим изысканиям, такие кейсы уступают упомянутым выше.Однако, было понятно, что такой подход устроит не всех. Вот вас например не устроил :). Поэтому предусмотрена возможность переопределить дефолтный маппинг. Описано это это в доке: https://www.jpa-buddy.com/documentation/database-versioning/#custom-type-mappings. Просто добавьте туда маппинг, который считаете правильным и все.
Еще один способ, когда ваши колонки в базе типа timestamp интерпритируется "то так, то так", то можно вборочно обойтись добавлением columnDefinition.
vasyakolobok77
28.01.2022 17:40+1Мы ставим отметку времени получения данных - это именно момент времени или
Instant. Мы фиксируем дату и время принятия документов в посольство и этоInstant. Фиксируем дату нарушения ПДД -Instant. Т.е. это характеристика некоторого события. И, как выяснилось, это и есть основные кейсы.Все верно, это метки в глобальном течении времени. Для таких случаев надо хранить метку как timestamp with timezone. Если будем хранить метку как обычный timestamp, то в случае нескольких бекендов в разных временных зонах получим неразбериху.
Я понимаю ваш подход – покрыть более частые кейсы, а для особых мест иметь возможность переопределить. Но я считаю инструмент должен давать советы "как правильно делать", а не советы рода "как чаще используется в жизни".
Ведь вопрос с маппингом дат касается не только reverse-engineering, но и генерации migration на основе наших Entity. И правильно делать маппинг LocalDateTime -> timestamp, Instant -> timestamp with tz. Но сейчас насколько вижу для Instant генерится простой timestamp, что как я выше пояснил может породить неразбериху в случае бекендов в разных временных зонах.
aleksey-stukalov Автор
28.01.2022 23:07Честно, я не понимаю почему это может привести к неразберихе, даже если бэкеды будут в разных таймзонах. Время из инстанта не пересчитывается в локальную таймзону сервера. Вот прямо сейчас сделал тест. В обеих базах ровно одно и то же значение, как и при чтении. Попробовал Oracle, PostgreSQL 13, MS SQL.
Ведь вопрос с маппингом дат касается не только reverse-engineering, но и генерации migration на основе наших Entity.
Все так, поэтому настроить можно и там и там :).
vasyakolobok77
29.01.2022 17:22Время из инстанта не пересчитывается в локальную таймзону сервера.
Все верно, но сервер БД пересчитывает в таймзону клиента (бекенда).
Проверил на postgres и на, прости господь, h2database, работает как я и ожидал. https://github.com/vasyakolobok77/test_jpa
Извиняюсь за тесты с простым логированием, но суть они показывают. Давайте разберем, что происходит на примере postgres:
1. Допустим Бекенд А находится в зоне GMT+05 и по его часам сейчас 18:00, что по UTC будет 13:00.
2. Бекенд А сохраняет таймштамп в БД. В postgres, как я описывал ранее, timestamp передается простой строкой с таймзоной бекенда, т.е. с бекенда придет условно 18:00+05 (опустим дату и миллисекунды).
3. Сервер принимает строку и просто отбрасывает временную зону +05, к себе он сохранит 18:00.
4. Далее мы решаем прочитать сохраненное значение на бекенд А. Запрашиваем значение у БД и она отвечает нам строкой 18:00.
5. Бекенд принимает 18:00 и интерпретирует его в своей временной зоне +05, в итоге объект Instant будет указывать на 13:00Z (что равно 18:00+05).
6. Далее мы решаем прочитать сохраненное значение с другого бекенда Б, который допустим в зоне GMT+10. Бекенд запрашивает у БД и она отвечает все той же строкой 18:00.
7. Бекенд Б принимает 18:00 и интерпретирует это значение в своей временной зоне +10, что порождает объект Instant 08:00Z (что равно 18:00+10).
8. 13:00Z на бекенде А и 08:00Z на бекенде Б совсем не ссылаются на один момент времени. Они указывает на локальное время 18:00 :-)По описанному алгоритму работает postgres и h2db. С другими БД каюсь не проверял.
В тестах spring нужно учитывать, что контекст / коннекции к БД переиспользуется, потому простой setTimeZone в тест методах не прокатит, нужно делать полный перезапуск приложения в другой временной зоне.
aleksey-stukalov Автор
29.01.2022 21:41Ээээ. Так все же верно. Сохраняем с клиента инстант 29.01.2022 15:40 UTC. Ровно это значение получаем в базе. Ровно это знаение и зачитываем из базы. Таймзоны для работы в UTC вообще не причем. Их просто нет. Всегда +00.
Что значит "бэкенд интерпретирует это значение в своей временной зоне"?
vasyakolobok77
29.01.2022 22:28+1Пожалуйста, прочтите мои сообщения более внимательно и запустите тот пример кода, который я не поленился составить. Мы говорим об одном и том же, но видимо каждый видит свое.
Еще раз, если в зоне +05 мы сохраняем условную дату 18:00+05 (13:00+00) как таймштамп, то оно сохранится просто как 18:00. В spring+hibernate сохранение Instant вырождается в setTimestamp, в котором передается строковое представление даты в своей временной зоне. Никакого UTC там нет в помине. Postgres при обработке timestamp проигнорит таймзону +05 и сохранит просто 18:00. Посмотрите в отладчике.
При вычитке на бекенде этого значения идет обратное преобразование. Опять же postgres передаст просто 18:00, а spring+hibernate распарсят строку и применят текущую временную зону! В итоге в каждой временной зоне получим 18:00, но это будут свои метки: 18:00+05 и 18:00+10 , что соответствует меткам в глобальном времени 13:00+00 и 08:00+10 !!! Это разные метки.
Еще раз, timestamp в общем случае может хранить толкьо локальное время. Для хранение глобального времени (чем является Instant) нужен timestamp with tz.
Надеюсь я понятно теперь пояснил. Если у вас есть возражения, с удовольствием выслушаю.
Что значит "бэкенд интерпретирует это значение в своей временной зоне"?
Чтобы преобразовать строку даты / времени "2022-01-30T18:00:00.000" в Instant нужно знать временную зону. Для timestamp типа postgres не передает временную зону, потому бекенд использует текущую. В итоге для одного локального времени в каждой таймзоне получаем разный инстант. Об этом я говорю уже несколько комментариев.
Я тут распинаюсь в доказательствах, но хочу уточнить. Надеюсь вы не используете Instant как замену LocalDateTime? оО Поскольку если это так (что в корне неправильно), то дискуссия у нас ни о чем. :-)
aleksey-stukalov Автор
29.01.2022 23:08Надеюсь вы не используете Instant как замену LocalDateTime?
Очевидно что нет.
Для timestamp типа postgres не передает временную зону, потому бекенд использует текущую.
Чтобы не было проблем работы в разных таймзонах и не было преобразование времени из локали JVM в локаль DB и обратно есть такое замечательное свойство:
spring.jpa.properties.hibernate.jdbc.time_zone=UTC.vasyakolobok77
30.01.2022 09:12+1есть такое замечательное свойство:
spring.jpa.properties.hibernate.jdbc.time_zone=UTCСогласен, с таким workaround (по факту костылем!) Instant работает как надо, но перестает работать маппинг LocalDateTime в timestamp.
Если в одном проекте у нас и Instant для хранения глобальных меток, и LocalDateTime для хранения локальных меток, то не получится их одновременно замаппить на timestamp, что-то одно сломается.
aleksey-stukalov Автор
30.01.2022 12:37Честно, на костыль похоже подстановка локальной тамзоны, при явном отсутствии таковой. Есть даже статья Влада Михалчи, где про это явно говорится. Еще он упоминает, что далеко не все драйвера БД проставляют локальную тамзону. Вся история учит нас отказываться от дефолтов, причем плавающих (зависящих от подключенных зависимостий например).
Мне пришлось много поработать со временными полями и должен сказать, что практически всегда в итоге приходилось отказываться от локального времени вообще. Либо храним в UTC и переводим в нужную локаль на презентационном слое, либо храним полностью с часовым поясом. В противном случае мы завязываемся на внешние факторы. Например, непредсказуемые переводы времени. Да-да, бывает и такое. Когда все сервера думают, что надо переводить время с 2am на 1am, а локальные законы (это было с проектом в Ливане) делают это с 1am на 12pm (т.е. фактически переводят и день). И все заказы такси летят к чертям :). Также были случаи подения серверов, а при переподнятии невыставление правильной локали.
Спасибо вам большое за терпение, я проведу еще несколько консультаций со сторонними экспертами, чтобы окончательно решить как нам быть :). Так-то поменяем, в чем проблема :).
Sigest
Спасибо за инструмент. Он до сих пор вызывает некоторые проблемы у меня, IDEA при каждом своем перезапуске просит настроить его, но в любом случае вижу тенденцию к полезности вашего плагина.
aleksey-stukalov Автор
Спасибо! А можно поподробнее про настройку при каждом перезапуске? Напишите пожалуйста на info@jpa-buddy.com, будем очень благодарны!
Sigest
Когда я запускаю IDEA, то в правом нижнем углу она показывает разные информационные маленькие окошки, вот оно из окошек гласит "Вы используете hibernate, а не хотите ли настроить плагин под него" (сообщение на английском, но смысл вот такой). Я нажимаю настроить, выходит окно установки плагина, где показывается ваш плагин и мне нужно только нажать Ок. В принципе, не критично, но вот обратил внимание на такое поведение. На указанную почту скину версии всего используемого и скрины
aleksey-stukalov Автор
Понял-понял. "Мопед не наш" :). Это окно из IntelliJ, попробуем что-то с этим сделать! Спасибо!