

Платформа данных как услуга
Когда мы проектируем и создаем платформу данных, то работаем над обеспечением возможностей и инструментов, которые необходимы другим командам для развития их проектов.
Введение
Прошло несколько месяцев с тех пор, как я задумался о написании статьи "Что такое новая платформа данных предприятия?". В последние несколько лет я работал в качестве архитектора решений по данным и владельца продукта для новой платформы данных (Data Platform); я многому научился и хотел бы поделиться своим опытом с сообществом.
Я буду писать не о подходе к управлению, основанном на данных (Data-Driven), а о том, как построить платформу, которая позволит компании реализовать его. Когда мы проектируем и строим платформу данных (Data Platform), то работаем над предоставлением возможностей и инструментов, которые нужны другим командам для развития их проектов. Я не забываю о данных, но считаю, что они должны быть услугой, а не продуктом.
До этого челленджа я много читал о Data Platforms нового поколения. Обычно в блюпринте архитектуры упоминается, что она идеальная, и это нормально. Но реальный мир не совершенен. В большой компании существуют различные реалии, поэтому важно правильно определить приоритеты и в то же время сосредоточиться на "To-be (Как должно быть)" (это самое сложное). Также очень важно помнить, что не имеет значения, какая у нас самая лучшая архитектура, если никто ее не использует или мы опоздали на два года.
На мой взгляд, есть четыре основных составляющих, которые мы должны учитывать с самого начала:

Команда: Это самое важное и имеет наибольшее влияние на обеспечение вашего успеха.
Продукт: Это платформа, все функции и возможности, которые мы предложим пользователю.
Данные как услуга: Позволяет вам предоставлять клиентам пользу, способствуя достижению результатов, которых они хотят добиться, без значительных усилий и затрат.
Обучение пользователей: Это еще одна услуга, однако она достаточно важна, чтобы выделить ее отдельно.
В конце концов, продукт будет представлять собой объединение всего этого.
Ориентированность на продукт
Существует множество функций, которые должна предоставлять корпоративная Data Platform: демократизация данных, каталог данных, качество данных, CI/CD, мониторинг и т.д. Единственный способ обеспечить эти функции в корпоративной среде - это следовать подходу, ориентированному на продукт, что означает:
Выслушать потенциальных пользователей и попытаться понять, каковы их потребности или опыт.
Определить долгосрочную цель продукта (общая картина).
Варианты использования на высоком уровне.
Наиболее важные и общие функции.
Строительные блоки, из которых сформируется Data Platform, будет семейство продуктов.
Упростите услуги и облегчите нашим клиентам достижение их целей. Некоторые из них мы объясним далее.
Поделиться с пользователями и получить первоначальные отзывы.
Спланировать минимально жизнеспособный продукт.
Следовать agile-манифесту и модели непрерывного совершенствования.
Составить дорожную карту, регулярно получая обратную связь от пользователей.
Мы должны с самого начала предоставлять ценность нашим пользователям и в то же время регулярно получать обратную связь. Потребности пользователей не статичны и постоянно меняются, поэтому не беспокойтесь, если долгосрочная цель время от времени меняется, пусть даже и на начальном этапе. Data Platform должна постоянно развиваться, изменения - это часть жизненного цикла платформы.
Кроме того, я всегда придерживался трех основных принципов, которые применимы как к гибридной архитектуре, так и к облачной (Cloud-native):
Принимайте данные только один раз.
Все команды имеют доступ к одним и тем же данным.
Максимально разделяйте вычислительный уровень и уровень хранения данных.
Избегайте спагетти-архитектур.
Что происходит с данными как продуктом? Конечно, это очень важно, но не является частью Data Platform. Я думаю, что они находятся на вершине Data Platform.
Данные как услуга
Сегодня время важно как никогда (Speed-to-market (обеспечение скорейшего выхода продукта на рынок)). Необходимо избегать core-команд, которые централизованно управляют пайплайнами данных или обеспечением платформы. Централизованная команда не сработает; они окажутся в узком месте. Задач будет больше, чем они могут осилить. В итоге вся компания будет подавать запросы в одну централизованную команду.
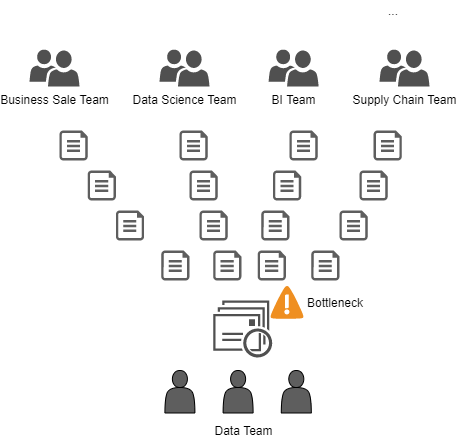
Такие ситуации порождают неудовлетворенность пользователя и разочарование команды:
Пользователь не может достичь своих целей.
Команда прилагает максимум усилий, но не может справиться со всеми запросами.
В этом случае, обеспечьте возможность самообслуживания, чтобы у пользователей было несколько вариантов:
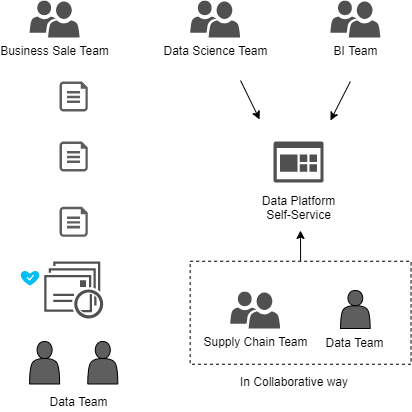
Делайте это сами.
Организуйте централизованную команду для бизнес-пользователей; здесь очень важна автоматизация. Не все могут работать автономно, есть бизнес-команды, которые используют функции отчетности и нуждаются в команде для предоставления им услуг.
В совместной работе поддерживайте смешанные команды, несмотря на то, что в начале потребуется много усилий, в долгосрочной перспективе это очень поможет. Это также стимулирует совместную работу команды и обмен знаниями.
Какие возможности для самообслуживания мы должны предоставить? Есть три основные потребности:
Пользователи должны знать, какие существуют данные и все связанные с ними метаданные. Например, позволить им искать таблицы, их историю и время обновления, схему, бизнес дефиницию и т.д.
Предоставить простой механизм ввода данных, который позволит пользователям технических средств автономно вводить данные.
Возможность наблюдения для предоставления всей информации, необходимой пользователям по мониторингу, организации процесса и т.д.
В конечном итоге, мы должны максимально автоматизировать процессы и предоставить простой способ сделать их доступными для пользователей. Это может быть git-ops, веб-сайт или какой-либо другой способ.
Команда
Люди - это самая ценная опора вашей Data Platform. Корпоративная Data Platform нуждается в различных подгруппах с разными навыками:

DataOps: Конечно, это не команда, а сочетание культур и практик. Важно иметь команду, которая понимает все эти концепции, а также владеет "мягкими" навыками. Для этого необходимы знания в области инжиниринга, интеграции и качества данных. Именно такая команда будет наиболее близка к пользователю.
Предоставление данных в Data Platform для их использования потребителями.
Обеспечение поддержки при возникновении проблем.
Поддержка интеграций.
Помощь в оптимизации обработки данных.
Помощь в понимании данных.
Дата-инженеры: Они отвечают за создание ядра Data Platform. Это техническая команда со знанием SQL, потоковой передачи данных, Spark и других технологий.
Создают и автоматизируют надежные пайплайны данных на основе пакетной или потоковой обработки.
Проектирование организации и слоев данных (необработанные, уточненные таблицы, функции...).
Разработка архитектуры хранилищ данных.
Преобразование данных в подходящий для анализа формат.
Исследование технологий для улучшения текущих и предстоящих функций.
Инженеры-программисты: Они важны благодаря возможностям самообслуживания сборки и другим функциям. Инженеры-программисты нужны для работы над бэкенд-порталами сайтов, сервисами данных на основе OpenApi, WebSocket и т.д.
Фронтенд-инженеры: В Data Platform работают различные типы пользователей. Важно обеспечить каждому из них хороший пользовательский опыт с помощью удобных инструментов, таких как веб-порталы самообслуживания. Фронтенд-инженеры работают над навигацией веб-процесса, проектируют пользовательский интерфейс и разрабатывают часть веб-приложения.
Инженеры платформ: Одним из ключевых моментов является автоматизация предоставления платформы и ее эксплуатации, иногда такую команду называют DevOps, хотя мы считаем, что DevOps - это культура, подобная DataOps. Инженеры платформы должны работать вместе с дата-инженерами и инженерами-программистами.
Осуществлять проектирование, разработку и развитие инфраструктуры как кода.
Проектировать, разрабатывать и развивать решения CI/CD.
Помогать в оптимизации процессов обработки данных, обеспечивая видение платформы.
Архитектор решений: Является лицом, ответственным за руководство общим техническим видением, согласованным с потребностями и требованиями, определенными владельцем продукта (Product Owner).
Product Owner: определяет цели, помогает команде в поддержании концепции и т.д.

В Data Platform задействовано несколько команд, и все они должны работать вместе, следуя культуре DataOps и DevOps. Время от времени все люди должны работать в составе каждой из команд. Качество и высокая доступность продукта - это сочетание платформы и процессов/приложений, так что вся команда должна работать вместе и быть согласованной.
Обучение пользователей
Когда мы разрабатываем очередную платформу, всегда появляются новые технологии, а также процессы и методологии. По этой причине обучение очень важно. Это позволит нашим пользователям легко освоить новую платформу.
Обычное обучение (4 часа утром под руководством тренера) - это неплохо, но в некоторых случаях этого недостаточно. Я верю в другой подход, например, позволить пользователю поработать некоторое время вместе с вашей командой. Такой подход позволяет им лучше разобраться в платформе и, более того, обеспечит вам более качественную обратную связь.
Вот обычный пример: мы запланировали тренинг на пять часов с десятью людьми из команды пользователей, и тут возникают некоторые проблемы:
У кого-то из них много работы, поэтому они не полностью сосредоточены на курсе.
На производстве возникли проблемы, поэтому двое пропускают по 2 часа.
Даже те, кто закончил курс, могут не воспользоваться полученными знаниями в течение нескольких недель.
Являются ли такие тренинги ненужными? Конечно, нет. Хотя на начальном этапе они требуют больше усилий, их необходимо дополнять другими видами обучения или контента:
Практические примеры, справочный код, упражнения и поддержка всего процесса.
Расширенная команда: Когда в работе одной из наших команд принимает участие кто-либо из другой группы. Участвовать - значит помогать в проектировании, разработке и эксплуатации Data Plarform.
Предположим, есть команда, которая хочет начать разработку в облаке и быть автономной, поэтому они хотели бы предоставить свои компоненты инфраструктуры. Они прошли обучение по программе Terraform, но не имеют опыта. Было бы интересно, чтобы они приняли частичное участие в команде, у которой он уже есть:
Обеспечение менторства.
Создает сообщество среди команд.
Решение повседневных ситуаций.
В конце процесса можно ненадолго применить такой метод, как парное программирование.
Такой подход позволяет командам консолидировать знания, создает сообщество и дает возможность самим быть генераторами идей. Команды Data Platform также оказываются в выигрыше, поскольку знают реалии наших пользователей и их потребности.
Data Platform
В самом начале и вместе с нашими пользователями мы должны определить сценарии использования и функции, которые мы хотим предоставить в нашей Data Platform.
Случаи использования
Первым шагом было определение вариантов использования с точки зрения высокого уровня.
Машинное и глубокое обучение
Обычно команды специалистов по даталогии имеют множество технических ограничений при работе на традиционной локальной платформе больших данных (On-Premise Big Data Platform):
Производительность: Системы хранения и вычислительные уровни связаны на одном физическом узле и не могут масштабироваться независимо друг от друга. Существует множество процессов с высокой рабочей нагрузкой. Масштабирование в такой Big Data Platform является сложным и требует много времени и усилий.
Технологическая отсталость: Специалисты по даталогии постоянно исследуют новые алгоритмы, методики и продукты, которые позволяют им обнаружить закономерность или оптимизировать процессы. В конечном счете, это обеспечивает ценность для компании благодаря осмыслению данных. Работа в условиях гибкой платформы и маневренности в этой меняющейся среде была очень важна для них.
Жизненный цикл машинного обучения: Им нужна операционная платформа для управления сквозным жизненным циклом машинного обучения.
Что касается данных, то они работали с большим количеством разнообразной информации:
Структурированные данные, такие как таблицы.
Изображения.
PDF-файлы.
И другие.
В настоящее время наличие аналитических "песочниц" является обязательным условием. Песочница данных - это масштабируемая и развивающаяся платформа, предназначенная для даталогии и аналитики. Предоставляет среду с инструментами и вычислительными ресурсами, необходимыми для поддержки экспериментальных или разрабатываемых аналитических возможностей без влияния на базы данных приложений или другие аналитические процессы.
Командам специалистов по даталогии необходимо анализировать большой объем данных, применять различные алгоритмы. Эти процессы требуют значительных затрат вычислительных ресурсов и памяти. Исследование не имеет определенных временных рамок. На традиционных платформах Bigdata, невзирая на наличие очередности в приоритетах работ, очень часто бывает, что одни процессы влияют на другие.
"Песочницы" могут стать решением этой проблемы, поскольку у каждой команды есть своя среда. Такие среды не имеют общих вычислительных ресурсов или ресурсов памяти, они изолированы друг от друга.
Аналитика
На фоне машинного обучения, которое является узкоспециализированной областью, существует множество команд, использующих возможности отчетности и аналитики:
Команды бизнес-аналитики.
Бизнес-аналитики.
Операционные команды используют этот информационный слой для предоставления оперативной отчетности без риска воздействия на их критически важную систему.
Любой пользователь, который хочет иметь быстрый и простой доступ к данным.
Когда все эти пользователи работают со структурированными данными в традиционном хранилище, у них возникают одни и те же проблемы:
Понимание данных: Обычно хранилища данных построены по "ETL спагетти топологии". Существуют тысячи ETL. Каждый из них может читать данные из разных источников и применять несколько преобразований для создания выходного результата. Это становится проблемой, когда несколько команд генерируют схожие данные, такие как перемещения запасов, и применяют различные ETL. Еще хуже, когда ETL вложены друг в друга, а их последовательность недоступна.
Задержка данных: Все пайплайны данных основаны на пакетной обработке, и пользователям требуется время для проведения анализа. Конечно, не во всех случаях требуются данные, близкие к реальному времени, и в некоторых случаях их применение невозможно, поскольку необходимо проанализировать большой набор накопленной информации.
Производительность: Существуют проблемы, связанные с вычислительными ресурсами и емкостью хранилища. Как и в традиционной Big Data Platform, масштабирование является сложной задачей и требует много времени и усилий. Обычно стандартные хранилища данных работают на девяносто процентов от своей мощности, и для того, чтобы изменить ситуацию, требуются годы усилий.
Дашборд и отчетность
Некоторое время назад отчетность была функцией, которая обычно разрабатывалась централизованной командой, как правило, командой бизнес-аналитики. Сегодня всем пользователям необходимо создавать свои операционные, деловые или информационные отчеты.
Проблемы с традиционными инструментами заключаются чаще всего в данных; они не готовы к работе в режиме реального времени, и зачастую не очень удобны для пользователя.
Службы данных
Не все команды пользуются данными из средств отчетности или путем прямого доступа к ним. Во многих случаях информация предоставляется через службы, такие как Restful-сервисы, и потребляется другими приложениями.
Фактически, в отличие от других типов систем, эти сервисы обычно предоставляют данные с той же структурой, что и таблица, или с применением функций проекции, агрегации и фильтрации.
В данном случае есть две общие области для улучшения:
Скорость выпуска: каждая команда разрабатывает свой пользовательский сервис, что требует больших усилий в разработке и решении задач управления. Кроме того, такой подход к проекту порождает дублирующийся код.
Владелец: Неясно, кто отвечает за предоставление этих услуг. В зависимости от проекта это может быть владелец данных, команда, которой необходимо потреблять данные, или даже команда платформы.
Наблюдаемость
Data Platform - это сложная система, состоящая из множества компонентов и процессов. В ней задействованы многие команды с очень разными моделями использования.
На разных уровнях существуют свои потребности:
Инфраструктура.
ETL.
Потоковый процесс.
Качество данных.
Наблюдаемость может оказаться хорошим подходом. Цель состоит в том, чтобы опубликовать как можно больше событий из различных уровней Data Platform. Такой подход позволяет пользователям коррелировать события и принимать решения на основе различных их разновидностей: инфраструктура, процессы ETL или журналы. Каждая команда решает, какие именно события она хочет наблюдать.
Например, представьте, что мы публикуем события с состоянием всех процессов ETL, и в определенный момент времени у нас возникает глобальная проблема в механизме ETL:
Команды, которые следят только за своей нагрузкой, знают, что их процесс дал сбой, возможно, всего один раз.
Команды, наблюдающие за всеми событиями, причем не только за состоянием, а также за другими типами метрик, могут знать, что их процессы дали сбой; но также понимают, что существует глобальная проблема, и в будущем они смогут опередить ее. Это позволяет им принимать более эффективные решения.
Конечно, помимо возможности наблюдать, необходимо обеспечить стандартный мониторинг и инструменты для облегчения работы команд.
Каталог данных и самообслуживание
Каталог данных управляет перечнем всех данных организации. Он включает метаданные, помогающие пользователям:
Обнаружить данные.
Понять данные.
Предоставить информацию о происхождении данных, чтобы знать, что является их источником.
Это ключевой компонент для того, чтобы избежать изолированности и демократизировать данные. Не имеет значения наличие Data Platform для предоставления всех данных организации, если пользователи не знают, какие из них доступны.
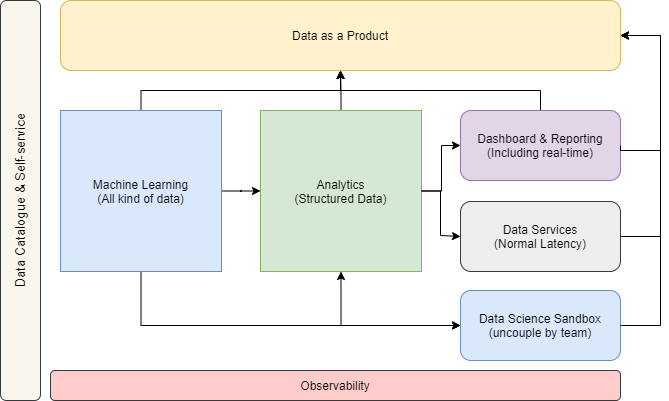
Функции
На следующей диаграмме показаны наиболее важные функции Data Platform.

В следующей статье я подробно расскажу об архитектуре Data Platform и ее возможностях.
Материал подготовлен в рамках курса «DataOps Engineer».
Всех желающих приглашаем на бесплатное demo-занятие «Облака и on-premise решения в обработке данных». На этом занятии мы рассмотрим основные технологические платформы для построения систем обработки данных. Какие варианты есть для развертывания on-premise? Какие инструменты предлагают облачные провайдеры? Какие тенденции появились в платформах в последние годы? Если интересно обсудить эти вопросы, записывайтесь.