
Приветствую тебя, дорогой друг! Эта публикация была создана для тебя, если ты хотел бы разобраться с этими непонятными словами из заголовка раз и навсегда. Как с идейной, так и с математической стороны. Признаюсь сразу, в свое время в универе частенько прогуливал семинары по высшей математике где-нибудь в приятном заведение со вкусной едой и хорошей музыкой или вообще дома, занимаясь чем-то "уникальным" и "сверхполезным". Но жизнь оказалась более ироничной, чем я думал. Несколько лет как я работаю в аналитике и познаю мат. статистику заново. И теперь уже с горящими глазами. Дается местами она не просто, а особенную трудность испытываю, когда хочу найти в интернете простые и понятные материалы по необходимой теме. Собственно, это меня и побудило написать данную статью, включающую в себя всю математику, почему она так работает и как это вообще запрограммировать.

Начнем с примера
Заядлый рыбак Антон купил в магазине новую сверхтехнологичную наживку, так как друзья его убедили, что на данную снасть клюет более крупная рыба. Антон с нетерпением ожидал выходных, чтобы проверить его обновку в деле. И, естественно, в ближайшие даты он поехал на его любимый прудик, где клюет даже в самый нерыбный день. Всю дорогу наш рыбак вкушал как он будет вытаскивать трофейных сазанов и толстолобиков и с нетерпением ждал прибытия. По приезде Антон закинул две удочки. На первую он повесил старую, проверенную временем, наживку, а на вторую новую снасть. И теперь оставалось только ждать. Ждал Антон недолго, рыба клевала неприлично часто, только и успевай подсекать, взвешивать рыбу и отпускать обратно на волю. И вот, к концу выходных, сидя вечером около костра и поедая уху, Антон обратился к своему блокнотику, в который он записывал веса всех рыб. Там было отмечено около 300 взвешиваний по каждой из удочек. Но Антону до сих пор оставалось непонятно, какая же эффективнее. Он решил попросить помощи у своего друга математика. Предлагаю вам, вместе со мной, побыть на время этим самым другом математиком и помочь Антону ответить на его вопрос.
На обе удочки Антон поймал по 300 экземпляров рыб. В случае старой наживки средний вес рыбы был грамм, в случае новой наживки –
грамм. Можно сказать, что мы получили нормальное распределение весов, с мат. ожиданием
и стандартным отклонением
Мы можем говорить, что наше распределение является нормальным, так как распределения таких параметров как вес, рост, физическая сила, умственное развитие и т.д. являются нормальными.
Давайте попробуем сгенерировать теперь данные, которые нам передал Антон и посмотрим что получилось:
import numpy as np
fish_rod_1 = np.random.normal(loc=500, scale=150, size=300)
fish_rod_2 = np.random.normal(loc=530, scale=150, size=300)
fish_rod_1[:10]array([571.63344449, 496.64627972, 325.81534818, 474.13480467,
468.92529865, 471.77045815, 588.86876405, 493.60099443,
414.8360645 , 575.02554082])Посмотрим какое распределение получится:
Код python
import seaborn as sns
import matplotlib.ticker as ticker
fig, axes = plt.subplots(nrows=1, ncols=2, figsize = (15, 7))
sns.histplot(data=fish_rod_1, ax=axes[0])
axes[0].set(xlabel='Вес рыбы', ylabel='Кол-во')
axes[0].xaxis.set_major_locator(ticker.MultipleLocator(100))
axes[0].set_title('Старая наживка', size=15)
sns.histplot(data=fish_rod_2, ax=axes[1])
axes[1].set(xlabel='Вес рыбы', ylabel='Кол-во')
axes[1].xaxis.set_major_locator(ticker.MultipleLocator(100))
axes[1].set_title('Новая наживка', size=15)
Как мы видим, у нас действительно данные сосредоточены вокруг средних, и, на глаз, процентов 70 значений лежит в пределахграммов. Судя по всему новая наживка работает качественнее, чем старая, так как мы видим, что второй график смещен в правую сторону, относительно левого. Да и без графиков понятно, что среднее 530 больше, чем 500. Можем ли мы сделать вывод о том, что новая наживка лучше? Нет, нет и еще раз нет! Никто не отменял случайность. Возможно, нам так повезло, а в следующий раз будет наоборот. Так как же проверить правда это или нет, спросите вы? Давайте разбираться по порядку.
Нормальное распределение
Нормальное распределение - это распределение, которое задается функцией Гаусса и является само по себе функцией плотности, оно симметрично и унимодально. А самое важное для нас, что отклонения значений от среднего мало того, что равновероятны, так еще и подчиняются известному вероятностному закону. Давайте посмотрим на это распределение и поймем наглядно что это все значит:
Код python
fig, ax = plt.subplots(figsize = (12, 6))
norm_rv = stats.norm(loc=0, scale=1)
x = np.linspace(norm_rv.ppf(0.0001), norm_rv.ppf(0.9999), 1000)
ax.plot(x, norm_rv.pdf(x), lw = 2)
ax.vlines(0, 0, norm_rv.pdf(0), color='g', lw=2, linestyles="dashed")
ax.vlines([-1, 1], 0, norm_rv.pdf(1), color='g', lw=2, linestyles="dashed")
ax.fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > -1) & (x < 1))
ax.text(0.5, 0.15, '34.1%', size=15, ha='center')
ax.text(-0.5, 0.15, '34.1%', size=15, ha='center')
ax.vlines([-2, 2], 0, norm_rv.pdf(2), color='g', lw=2, linestyles="dashed")
ax.fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > -2) & (x < -1) | (x > 1) & (x < 2))
ax.text(1.5, 0.05, '13.6%', size=15, ha='center')
ax.text(-1.5, 0.05, '13.6%', size=15, ha='center')
ax.vlines([-3, 3], 0, norm_rv.pdf(3), color='g', lw=2, linestyles="dashed")
ax.fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > -3) & (x < -2) | (x > 2) & (x < 3))
ax.text(2.5, 0.035, '2.1%', size=15, ha='center')
ax.text(-2.5, 0.035, '2.1%', size=15, ha='center')
ax.text(3.5, 0.01, '0.1%', size=15, ha='center')
ax.text(-3.5, 0.01, '0.1%', size=15, ha='center')
ax.set_xticklabels(['- 5σ','- 4σ', '- 3σ', '- 2σ', '- 1σ', 'μ', '1σ','2σ', '3σ', '4σ', '5σ'], size=13)
ax.set_title('Нормальное распределение', size=15)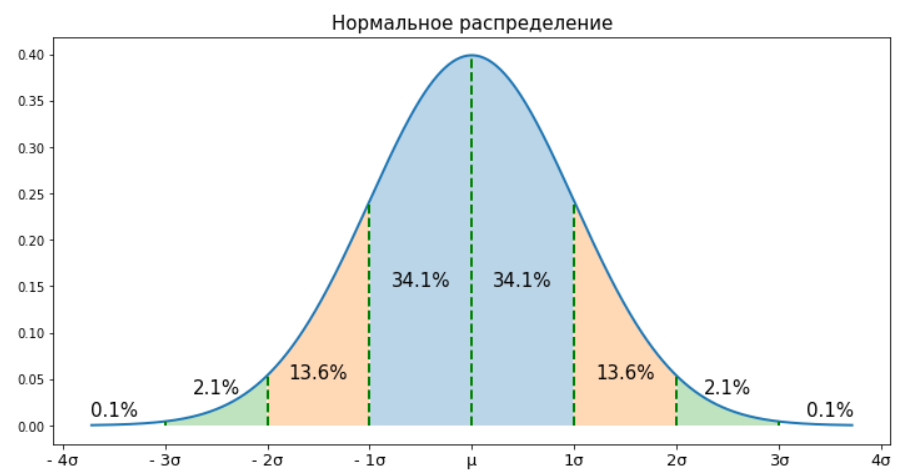
Разберемся с терминами:
Распределение симметрично относительно своего центра
Распределение унимодально. То есть имеет только одну моду (вершину). Собственно, вокруг этой вершины оно и симметрично.
Распределение является функцией плотности. То есть вероятность попасть в интервал
равняется площади под кривой нормального распределения в интервале
Важно, что вероятность попасть в интервал
равняется 100%, то есть площадь под кривой в данном интервале равняется единице.
Распределение подчиняется вероятностному закону. Взглянув на распределение, мы можем сказать, что в промежутке
находится приблизительно 34.1% + 34.1% = 68.2% наблюдений. Или, другими словами, вероятность случайным образом попасть в данный промежуток 68.2%. Или, с более формальной точки зрения, площадь под кривой нормального распределения в интервале
равняется 0.682.
Распределение задается функцией Гаусса:
Давайте посмотрим на эту страшную функцию. Не пугайтесь, она нам больше никогда не понадобится. Мы тут видим два неизвестных для нас параметра: и
Эти параметры отвечают за сдвиг и масштаб нашей функции. Давайте прибегнем опять к графикам и поиграемся в них с данными значениями.
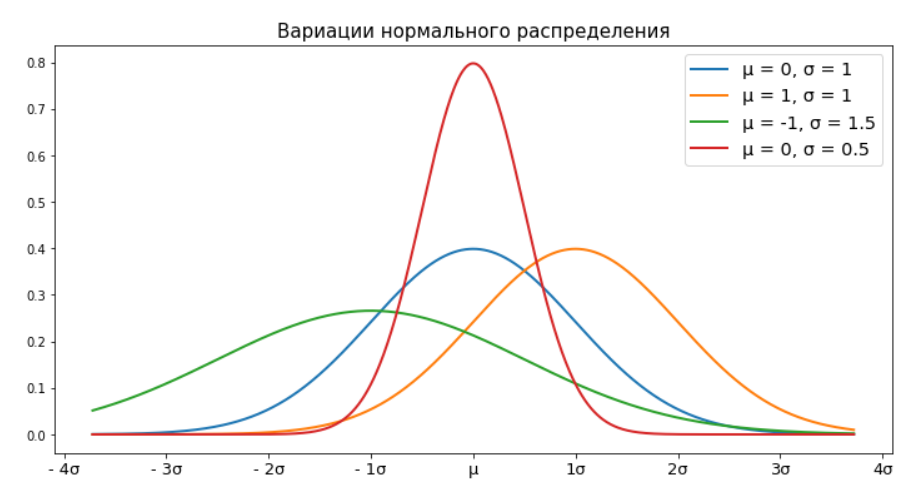
Все эти распределения являются нормальными. Различаются они лишь смещением центра относительно нуля и масштабом (некоторые из них шире, некоторые уже). Но, каждое из этих распределений, продолжает подчиняться вероятностному закону, о котором мы говорили выше. Так же, как мы расширили, сузили или сдвинули наше распределения от нормы и
так и обратным образом мы можем привести любое нормальное распределение к стандартному виду благодаря z-оценке.
Центральная предельная теорема
Центральная предельная теорема гласит, что сумма большого количества независимых случайных величин имеет распределение близкое к нормальному.
Давайте разбираться, у нас есть выборка размера рыб, пойманных на первую удочку. Проведем эксперимент.
Будем многократно выбирать 300 рыб случайным образом. Так, чтобы одна и та же рыба могла попасть в новую выборку несколько раз.
После этого считаем средний вес рыбы (независимая случайная величина).
Повторяем пункт 1 и 2 много-много-много раз и записываем каждый раз значения средних.
Распределение средних должно стремиться к нормальному с увеличением количества повторений.
Давайте построим как это выглядит на практике:
sample = np.random.normal(loc=500, scale=150, size=300)
print(sample.mean(), sample.std())
fig, axes = plt.subplots(figsize = (7, 4))
sns.histplot(data=sample, ax=axes)
axes.set_title('Изначальная выборка (n = 300)', size=12)
fig, axes = plt.subplots(nrows=2, ncols=2, figsize = (15, 8))
avg = [[0, 0], [0, 0]]
size = [[100, 1000], [10000, 100000]]
for i in range(2):
for j in range(2):
avg[i][j] = [np.mean(random.choices(sample, k=300)) for i in range(size[i][j])]
sns.histplot(data=avg[i][j], ax=axes[i][j])
axes[i][j].set_title('Распределение {:d} выборочных средних'.format(size[i][j]), size=12)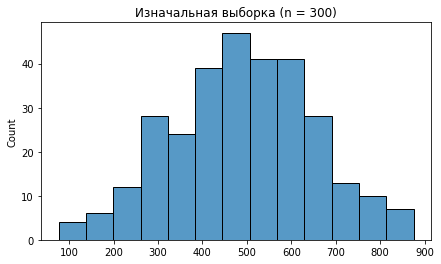

При 100 повторений график вообще не удался, по нему и не скажешь, что он куда-то стремится, тем более к нормальному распределению. А вот при 10.000 и 100.000 повторений графики очевидно похожи на то самое нормальное распределение.
Важно отметить, что чем больше (размер исходной выборки), тем ближе наше среднее к реальному среднему генеральной совокупности. То есть, чем больше рыб мы поймали, тем их средний вес ближе к реальному среднему весу всех рыб в данном пруду. Аналогично можно сказать и про стандартное отклонение. Поэтому, пока мы не знаем вес всех жителей пруда, мы не можем быть уверены, что в нашем улове среднее и стандартное отклонение совпадают с теми же значениями по всем рыбам пруда. Следовательно, нужно внести некую поправку, меру уверенности в наших данных. Эта мера уверенности есть. И она выглядит следующим образом.
Среднеквадратичное отклонение равняется стандартному отклонению выборки, деленному на корень из числа элементов выборки.
Z-score
Z-оценка представляет собой преобразование данных в стандартную Z-шкалу со средним и
по следующей формуле:
То есть, чтобы преобразовать наши данные в стандартную Z-шкалу, нам надо взять все веса рыб, отнять из них средний вес и поделить на cреднеквадратичное отклонение. Проделаем все это с данными по первой удочке:
mu_z = fish_rod_1.mean()
se_z = fish_rod_1.std() / sqrt(n)
z_fish_rod_1 = [(x - mu_z) / se_z for x in fish_rod_1]
z_fish_rod_1[:5][0.07787472513608741,
1.003823047141974,
0.36522112368440396,
1.1425856197000772,
-0.11237363891997496]А так будут выглядеть график.
Код python
fig, axes = plt.subplots(nrows=1, ncols=2, figsize = (15, 7))
sns.histplot(data=fish_rod_1, ax=axes[0])
axes[0].set(xlabel='Вес рыбы', ylabel='Кол-во')
axes[0].xaxis.set_major_locator(ticker.MultipleLocator(100))
axes[0].set_title('Наше распределение', size=15)
sns.histplot(data=z_fish_rod_1, discrete=True, ax=axes[1])
axes[1].set(xlabel='Вес рыбы', ylabel='Кол-во')
axes[1].xaxis.set_major_locator(ticker.MultipleLocator(1))
axes[1].set_title('Преобразованное в Z-шкалу', size=15)
Мы видим два абсолютно одинаковых графика с виду, но обратите внимание на ось абсцисс. Из-за того, что мы из вычли
правое распределение сместилось на
влево и среднее стало равняться нулю. А из-за того, что поделили на стандартное отклонение
, наше распределение сузилось. И теперь по оси абсцисс не единицы веса, а единицы стандартного отклонения. Таким образом любое нормальное распределение можно стандартизировать и привести к единому виду с
и
И как следствие из этого, мы можем сравнивать средние двух признаков, если они нормально распределены, потому что их можно привести к единому виду благодаря z-score. Данные после преобразования будут исчисляться уже не в рыбках, котиках и морковках, а в стандартных отклонениях от среднего.
Вернемся к нашим рыбам
Вспомним про наш вероятностный закон, которому подчиняется любое нормальное распределение. Мы можем сказать, что, к примеру, между у нас находится 68.2% наблюдений. То есть рыб. То есть из 300 рыб, у нас скорее всего 205 с весом
грамм. А в диапазоне
у нас 95.4% всех рыб. То есть 95.4% всех рыб находится в весовом диапазоне
грамм.
Код python
fig, ax = plt.subplots(figsize = (7, 4))
sns.histplot(data=z_fish_rod_1, bins=13)
ax.set(xlabel='Вес рыбы', ylabel='Кол-во')
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_title('Наши данные в z-шкале', size=15)
ax.set_xticklabels(['- 4σ', '- 3σ', '- 2σ', '- 1σ', 'μ', '1σ','2σ', '3σ', '4σ'], size=13)
plt.xlim([-3, 3])
ax.vlines([-1, 1], 0, 50, color='g', lw=2, linestyles="dashed")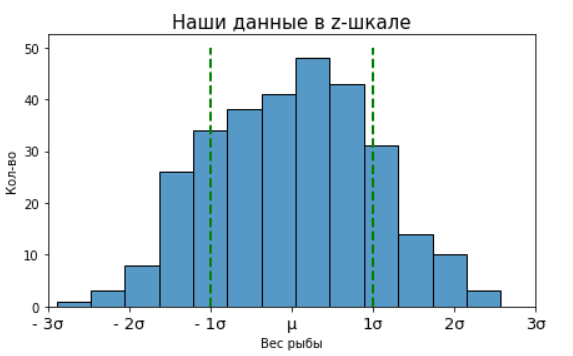
Генеральная совокупность и одна рыба.
Забудем пока про вторую удочку и представим, что Антон рыбачил только на одну. То есть мы можем для удобства сделать допущение, что параметры и
являются описанием генеральной совокупности. Запомните это. Поэтому нам не требуется делить наше стандартное отклонение на
Теперь вопрос, с какой вероятностью Антон поймает рыбу, которая будет тяжелее, чем 530 грамм? Чтобы узнать ответ, опять воспользуемся формулой z-score.
Подставим в формулу наши значения: Что мы сейчас получили? Мы посчитали, что значение 530 грамм отклоняется от среднего значения генеральной совокупности (500 грамм) на 0,2 стандартных отклонения. Да, как я уже и писал, мы теперь меряем все не в рыбках и граммах, а в стандартных отклонениях.
Код python
fig, ax = plt.subplots(figsize = (15, 8))
sns.histplot(data=z_fish_rod_1, bins=13)
ax.set(xlabel='Вес рыбы', ylabel='Кол-во')
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xticklabels(['- 4σ', '50 г.', '200 г.', '350 г.', '500 г.', '450 г.','600 г.', '750 г.', '4σ'], size=13)
plt.xlim([-3, 3])
ax.text(0.21, 50, '530 грамм', size=12, ha='left')
ax.vlines(0.2, 0, 52, color='r', lw=2, linestyles="dashed")
ax.vlines(0, 0, 52, color='g', lw=2, linestyles="dashed")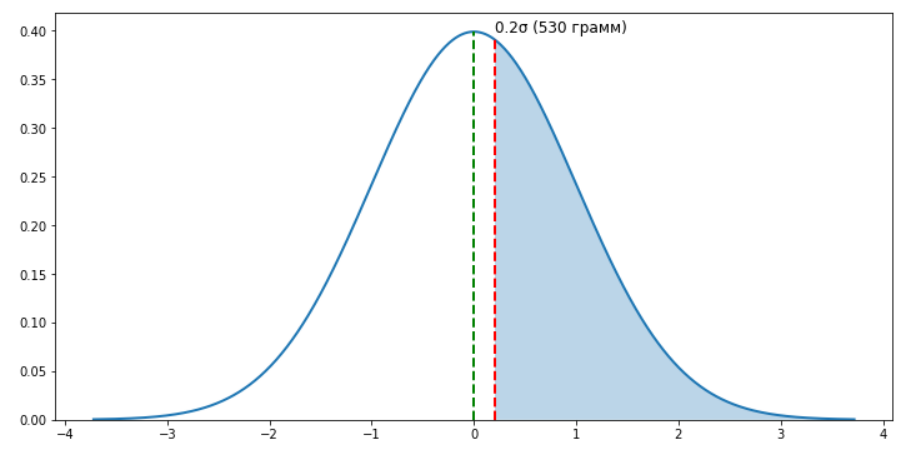
Зная отклонение от среднего генеральной совокупности (z-score), мы можем посчитать вероятность поймать рыбу тяжелее 530 грамм. Для этого воспользуемся подходящим инструментом в python, в который уже вшита функция плотности. Он за нас рассчитает площадь под кривой, правее (то, что закрашено синим на графике). Это и будет значением необходимой нам вероятности.
# Стандартизированное нормальное распределение
norm_rv = stats.norm(loc=0, scale=1)
print(1 - norm_rv.cdf(0.2))
# Или обычное нормальное распределение, как в нашем случае
norm_rv = stats.norm(loc=500, scale=150)
print(1 - norm_rv.cdf(530))Обе функции вернут одинаковый ответ: Это и есть p-value, вероятность случайным образом вытащить одну рыбу с весом более 530 грамм. Разница в них только в том, что в первом случае нормальное распределение стандартизировано, а во втором мы работаем с параметрами генеральной совокупности.
Генеральная совокупность и несколько рыб
С одной рыбой разобрались. А какова вероятность поймать 4, 100 и даже 300 рыб со средним весом 530 грамм? Воспользуемся формулой z-score, но немного ее модернизируем. Как раз сейчас нам и понадобится та самая поправка из центральной предельной теоремы.
Где, - среднее значение в выборке,
- среднее генеральной совокупности,
- стандартное отклонение в генеральной совокупности,
- кол-во элементов в выборке. Здесь мы вносим поправку в наше стандартное отклонение, так как работаем уже с несколькими элементами.
Практический смысл данной формулы говорит о том, что мы ввели две гипотезы, которые будут конкурировать между собой:
Нулевая гипотеза говорит о том, что выборка на самом деле принадлежит генеральной совокупности и средние значения выборки и генеральной совокупности равны
Альтернативная гипотеза говорит об обратном. Выборка не является частным случаем текущей генеральной совокупности и средние, на самом деле, отличаются
Чтобы подтвердить или опровергнуть мы и считаем z-score и p-value. То есть мы считаем вероятность того, что
отличается от
на
стандартных отклонений. И если эта вероятность нас устраивает, то мы принимаем нулевую гипотезу, а если нет - отвергаем. Теперь давайте подставим в формулу значения:
Теперь мы знаем, что среднее по выборке отклоняется от среднего генеральной совокупности
на
Давайте теперь посчитаем вероятность такого отклонения.
Код python
fig, ax = plt.subplots(figsize = (12, 6))
x = np.linspace(norm_rv.ppf(0.0001), norm_rv.ppf(0.9999), 1000)
norm_rv = stats.norm(loc=0, scale=1)
ax.plot(x, norm_rv.pdf(x), lw = 2)
ax.vlines(0, 0, norm_rv.pdf(0), color='g', lw=2, linestyles="dashed")
ax.vlines(0.4, 0, norm_rv.pdf(0.4), color='r', lw=2, linestyles="dashed")
ax.text(0.4, norm_rv.pdf(0), '0.4σ', size=12, ha='left')
ax.fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > 0.4))
ax.set_title('4 рыбы со средним весом 530 грамм\nz = {:.1f}, p = {:.4f}'.format(0.4, 1 - norm_rv.cdf(0.4)), size=15)
ax.set_ylim(0)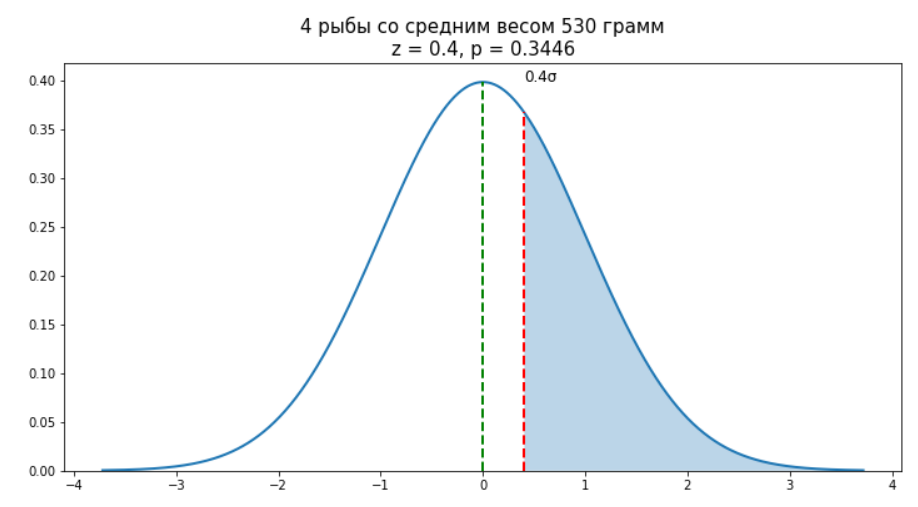
Вероятность поймать 4 рыбы со средним весом 530 грамм мы можем рассчитать все тем же способом, как и для единичного случая. P-value у нас получится равным 0.3446.
norm_rv = stats.norm(loc=0, scale=1)
print(1 - norm_rv.cdf(0.4))Как вы уже поняли, чем больше мы хотим поймать рыб со средним весом 530 грамм, тем больше у нас z-score и тем меньше p-value. Давайте посмотрим как это выглядит на практике:
Код python
fig, ax = plt.subplots(nrows=1, ncols=3, figsize = (15, 5))
x = np.linspace(norm_rv.ppf(0.0001), norm_rv.ppf(0.9999), 1000)
norm_rv = stats.norm(loc=0, scale=1)
fish = [4, 100, 300]
for i in range(3):
z = (530 - 500) / (150 / np.sqrt(fish[i]))
ax[i].plot(x, norm_rv.pdf(x), lw = 2)
ax[i].vlines(0, 0, norm_rv.pdf(0), color='g', lw=2, linestyles="dashed")
ax[i].vlines(z, 0, norm_rv.pdf(z), color='r', lw=2, linestyles="dashed")
ax[i].text(z, norm_rv.pdf(z - 0.3), '{:.1f}σ'.format(z), size=12, ha='left')
ax[i].fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > z))
ax[i].set_title('{:d} рыб(-ы) со средним весом 530 грамм\n z = {:.1f}, p = {:.4f}'.format(fish[i],
z, 1-norm_rv.cdf(z)), size=13)
ax[i].set_ylim(0)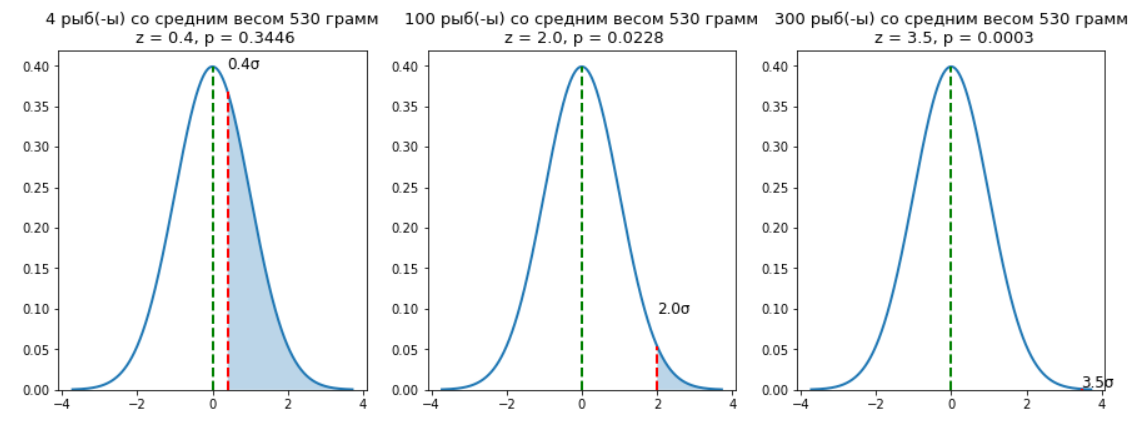
То есть вероятность поймать 100 рыб со средним весом 530 грамм равняется 2.28%, а вероятность поймать 300 рыб равняется 0.03%, что ничтожно мало. И мы можем сделать вывод, что вторая удочка, с новой наживкой отработала лучше. Так как только в 0,03% случаев мы могли ошибиться.
Но помните, что мы сделали допущение, что данные с первой удочки - это генеральная совокупность. А по факту это выборка из генеральной совокупности. Будет ли теперь наш вывод статистически правильным? Нет, мы не учли этот момент. Давайте теперь все учтем и наконец-таки сделаем финальный вывод с точными цифрами!
Две выборки со множеством рыб
Теперь у нас не генеральная совокупность и выборка, а две выборки из нескольких сотен рыб. То есть, если бы Антон продолжил бы ловить рыбу еще несколько дней, то средние значения и стандартные отклонения могли бы измениться.
Важно, что z-критерий требует знания стандартных отклонений. Поэтому давайте зафиксируемся на том, что мы поймали достаточно много рыб, чтобы утверждать, что и
являются такими же, как и в генеральной совокупности (во всем пруду). Иначе нам нужно будет воспользоваться t-критерием Стьюдента.
Старая наживка |
300 |
500 |
150 |
Новая наживка |
300 |
530 |
150 |
Как мы помним из ЦПТ, нам нужно ввести поправку. И у нас теперь две выборки и поправку необходимо будет учесть два раза.
Практический смысл данной формулы все тот же. Мы принимаем нулевую гипотезу о равенстве средних при условие высокой вероятности (p-value) данного события, в ином случае отвергаем.
Давайте теперь подставим наши значения и рассчитаем z-score.
Код python
fig, ax = plt.subplots(figsize = (12, 6))
x = np.linspace(norm_rv.ppf(0.0001), norm_rv.ppf(0.9999), 1000)
z = (530-500) / np.sqrt(150**2 / 300 + 150**2 / 300)
norm_rv = stats.norm(loc=0, scale=1)
ax.plot(x, norm_rv.pdf(x), lw = 2)
ax.vlines(0, 0, norm_rv.pdf(0), color='g', lw=2, linestyles="dashed")
ax.vlines(z, 0, norm_rv.pdf(z), color='r', lw=2, linestyles="dashed")
ax.text(z, norm_rv.pdf(z - 0.2), '{:.2f}σ'.format(z), size=12, ha='left')
ax.fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > z))
ax.set_title('Вероятность равенства средних в двух выборках\nz = {:.2f}, p = {:.4f}'.format(z, 1 - norm_rv.cdf(z)), size=15)
ax.set_ylim(0)
Как мы видим, вероятность того, что средние равны - 0.72%. Следовательно, мы можем с уверенностью в 99.3% отвергнуть нулевую гипотезу и сделать вывод, что новая наживка все же лучше, чем старая.
Когда можно использовать z-критерий?
Естественно, эти формулы можно использовать далеко не всегда. Иногда может потребоваться t-критерий Стьюдента, а иногда даже им не обойтись. Важно помнить, что для успешной реализации этого критерий необходимо соблюсти несколько условий:
Распределение должно быть нормальным.
Известна дисперсия генеральной совокупности для всех выборок.
Выборка имеет размерность более 30 элементов.
Если 2 и 3 условия не удовлетворяют требованиям, то лучше использовать t-критерием Стьюдента.
P-value
Давайте дополнительно чуть подробнее разберемся как определять p-value. Мы рассмотрели только один вариант, когда мы заранее знаем, что точно больше, чем
А если наоборот? Или вообще нет информации о том, как средние расположены относительно друг друга? Именно для таких случаев существует несколько видов гипотез.
Левосторонняя гипотеза.
Двусторонняя гипотеза.
Правосторонняя гипотеза.
Код python
fig, ax = plt.subplots(nrows=1, ncols=3, figsize = (15, 4))
x = np.linspace(norm_rv.ppf(0.0001), norm_rv.ppf(0.9999), 1000)
norm_rv = stats.norm(loc=0, scale=1)
fish = [4, 100, 300]
text = ['Левосторонняя гипотеза', 'Двусторонняя гипотеза', 'Правосторонняя гипотеза']
z = 1
coef = [1, 2, 1]
for i in range(3):
ax[i].plot(x, norm_rv.pdf(x), lw = 2)
ax[i].vlines(0, 0, norm_rv.pdf(0), color='g', lw=2, linestyles="dashed")
ax[i].vlines([-z, z], 0, norm_rv.pdf(z), color='r', lw=2, linestyles="dashed")
ax[i].text(z, norm_rv.pdf(z - 0.3), '{:.0f}σ'.format(z), size=12, ha='left')
ax[i].text(-z, norm_rv.pdf(z - 0.3), '-{:.0f}σ'.format(z), size=12, ha='right')
if (i == 0):
ax[i].fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x < -z))
elif (i == 1):
ax[i].fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x < -z) | (x > z))
else:
ax[i].fill_between(x, norm_rv.pdf(x), np.zeros(len(x)), alpha=0.3, where = (x > z))
ax[i].set_title('{:s}\n p-value: {:.4f}'.format(text[i], (1-norm_rv.cdf(z)) * coef[i]), size=15)
ax[i].set_ylim(0)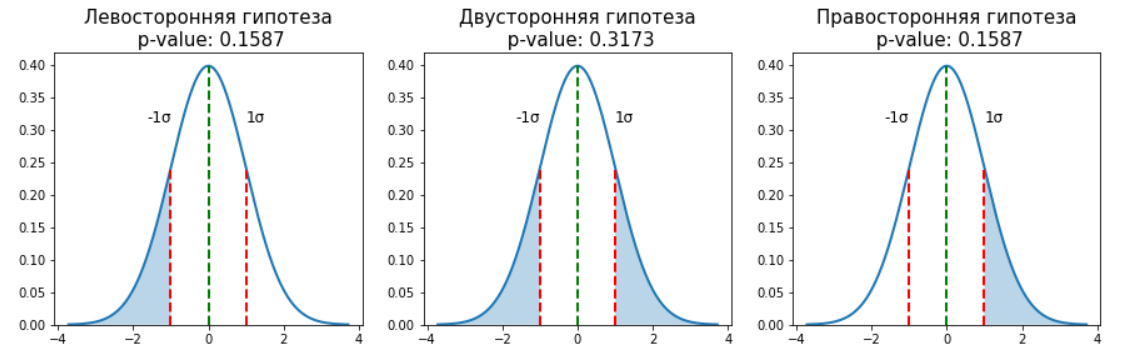
Отличия в них идеологические. Если мы заранее не знаем улучшится в тесте результат или ухудшится (не знаем знак z-score), то необходимо применять двустороннюю гипотезу и умножать полученный p-value на 2. А если мы тестируем улучшение или ухудшение, то тут достаточно односторонней гипотезы. Правда, уже после получения результатов теста, нельзя менять знак, который выбрали заранее.
Надеюсь, вам было все понятно, а читать было интересно. Буду безумно признателен, если поддержите мою первую публикацию лайком или комментарием.
Комментарии (3)

RomTec
27.02.2022 01:16+2Рассказывали бы так в наших институтах - "на рыбках", глядишь и подняли бы уровень образования. Спасибо за воспоминания!

mlyss
27.02.2022 21:03И если эта вероятность нас устраивает, то мы принимаем нулевую гипотезу, а если нет - отвергаем.
Если мы принимаем нулевую гипотезу, то это будет равносильно утверждению, что среднее выборки строго равно среднему генеральной совокупности. Но на основе p-value мы можем только сказать, есть ли значимые различия между средними. Если есть, (p-value достаточно мало), то H0 отвергается в пользу H1. В противном случае H0 отвергнуть нельзя, но это не означает, что средние равны, H0 ни в коем разе не принимаем. Либо отвергаем, либо не отвергаем и остаемся в рамках не подтвержденной, но и не отвергнутой H0.
ChePeter
Тут небольшое лукавство. Нужно чтобы эти почти независимые случайные величины имели почти одинаковое! ожидание. Тогда да, ЦПТ доказана и действует.
А если в пруду два сорта рыбы - караси и карпы, и караси едят не то, что едят карпы.
Если пруд дикий и там особи разных лет, то применение ЦПТ весьма сомнительно.
Даже если пруд культивируется и там особи одного года, то все равно их размер не всегда подчиняется ЦПТ. И классический пример это размеры плотвы.