

Connections by GrahamSym.
YAML (YAML Ain't Markup Language) — язык сериализации данных, который обычно применяется в файлах конфигурации, используемых в Kubernetes, Docker, Ansible и многих продуктах. Сейчас этот инструмент незаслуженно недооценен, многие просто не понимают пользы YAML для Kubernetes.
Меня зовут Дмитрий Евдокимов, я основатель и технический директор компании Лантри. Мы разрабатываем Observability-решения, помогающие клиентам повышать прозрачность происходящего на всех уровнях Kubernetes. И в том числе видеть, как компоненты работают и взаимодействуют между собой.
Я расскажу, как YAML может упростить управление системами и автоматизацию большинства процессов, чтобы Kubernetes был удобной рабочей системой не только для DevOps и SRE, но и для всех ИТ-специалистов.
Статья написана на основе моего выступления на VK Kubernetes Conference — вы можете посмотреть его в записи.
Базовые модели Kubernetes: KRM и Everything-as-Code
По мнению соучредителя Kubernetes Брайана Гранта, Kubernetes во многом удобен именно благодаря модели ресурсов Kubernetes Resource Model (KRM). Это способ составления декларативного файла конфигурации в удобочитаемом формате, который позволяет определять нужные состояния системы с помощью кода. Ключевой аспект KRM — единообразные декларативные метаданные. Поэтому KRM часто выражается как YAML и декларирует основную идею, что все в Kubernetes — YAML.
Схожая идея лежит в основе парадигмы Everything-as-Code (EaC, все как код). Согласно ее принципам, вся ИТ-инфраструктура, от конфигурации до систем безопасности, может быть настроена с помощью кода. Это делает её декларативной, что позволяет сосредоточиться не на реализации отдельных функций, а на конечных целях и нужных состояниях. И в этом случае YAML имеет важное значение.
Kubernetes и YAML
Kubernetes называют ядром Linux XXI века. В основе этой идеи сравнение возможности поиска любой информации о системе через proc в Linux и через API в Kubernetes: в первом — все файлы (файловые стримы), во втором — все YAML. Об этом можно почитать в одной англоязычной статье 2021 года. Можно получать информацию о любых частях системы и приложений, реализованных в виде Kubernetes-операторов и кастомных ресурсов. Использование YAML существенно упрощает эти задачи.
Фактически тысячи проектов — от CNI и ServiceMeshs до Security и Infrastructure — выполнены нативно для Kubernetes в виде Kubernetes-операторов и кастомных Kubernetes-ресурсов. Cilium, Istio, Gloo, Knative, ClickHouse и другими сервисами можно управлять и наблюдать за ними нативно, просто меняя и отслеживая YAML-файлы. Это подтверждает, что Kubernetes и YAML тесно связаны и взаимозависимы.

Проекты Cloud Native Landscape
Почему важна однотипность, обеспеченная использованием YAML
Однотипность при реализации всех аспектов системы была важна всегда, и ее значимость только увеличивается с популяризацией DevSecOps-подхода. Сейчас с кластером могут работать много разных команд, и каждая из них должна иметь возможность не только видеть общую картину происходящего, но и четко понимать ее. Это важно для своевременного решения поставленных задач и слаженной работы всех департаментов.
Если же однотипность реализации не обеспечивается, легко возникает ситуация, при которой специалисты разных отделов будут видеть только разрозненные фрагменты информации о сервисах и инфраструктуре без какого-либо согласования. Это усложняет как повседневную работу, так и дебагинг. Подобные случаи недопустимы — все должны одинаково видеть происходящее в инфраструктуре.
Вот один пример. Команда разработчиков, operation, очень долго решала проблему: почему-то в одном окружении приложение нормально работало по сети, а в другом не работало. Один образ, одни настройки, все полностью идентично, но что-то не так. Потратив энное количество часов, они отчаялись и пошли к команде безопасности. Выяснилось, что те использовали стороннее коммерческое решение, которое для своей работы внедряет сторонние библиотеки в процессы, запущенные в контейнерах. И эти процессы и заблокировали неправильное, по их мнению, поведение сервиса. Блокировку можно было заметить только внутри памяти процесса и непосредственно в интерфейсе, который есть только у команды безопасности.
Когда я приводил этот пример на своем тренинге по безопасности Kubernetes в одной компании, один из operation-инженеров с последней парты сказал: «Какие-то слабые айтишники. Первым делом, если что-то не работает в инфраструктуре, нужно сходить к безопасникам, а потом уже разбираться». В этот момент я не знал, то ли плакать, то ли смеяться. Не должно быть так, что с любой проблемой нужно идти к безопасникам. Все происходящее в инфраструктуре должно быть одинаково прозрачно для всех.
Kubernetes — это фреймворк. Он предназначен для того, чтобы максимально гибко создавать инфраструктуру для своих команд и процессов. При этом не только инфраструктуру, связанную с high availability, непосредственно с быстрой раскаткой сервисов, но и со всеми аспектами, связанными с базами данных, serviceless-нагрузками, безопасностью и прочим.
YAML — «дружественный» формат сериализации. Он не просто отличается простым синтаксисом и позволяет хранить данные в компактном и читаемом виде, но и подходит для всех языков программирования. Это позволяет применять его для обеспечения однотипного оформления, понятного и удобного для всех ИТ-специалистов.
Kubernetes-ресурсы сложнее, чем кажутся
В большинстве Source-code-менеджеров (SCM), используемых компаниями, проекты размещаются несколькими способами:
- YAML-ресурсы лежат по сервисам.
- YAML-ресурсы размещаются в соответствии с названием сервиса и его типом: Deployment, Service, Ingress и так далее.
- Ресурсы хранятся по категориям и подкатегориям.
К сожалению, по этой картине нельзя четко сказать, как действительно выглядит приложение и как оно работает.
На самом деле, все ресурсы в Kubernetes связаны. Если посмотреть на примере Ingress, Service и Pod, то можно увидеть, как Ingress ссылается на Service по полю
name, а Service ссылается на Pod по селектору app: MyApp: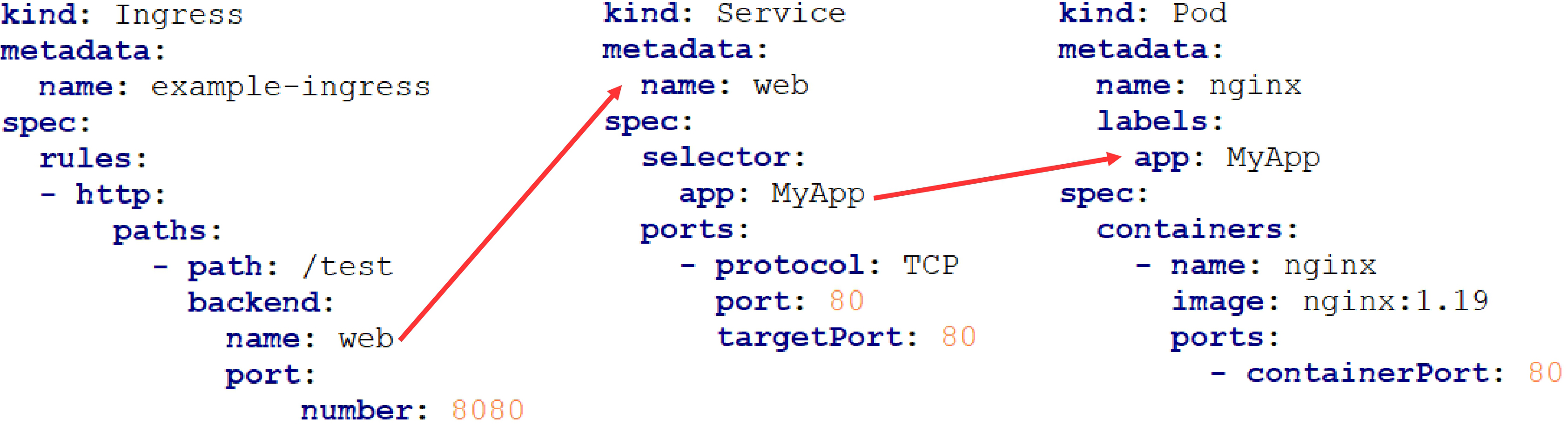
Пример связи между Ingress, Service и Pod.
Я не первым заметил эту особенность. Уже есть достаточно много проектов, которые стараются графически в связанном виде представить, как ресурсы влияют друг на друга, например, kublect-graph или Kubesurveyor. Но если вы начнете их использовать, то увидите, что инструменты знают только определенный набор ресурсов, поэтому не всегда дают точную картину происходящего в системе.

Они видят и знают не все, так что перед использованием рекомендую предварительно посмотреть, а какие вообще ресурсы этот инструмент видит
Как правило, если вы используете кастомные ресурсы, ни одно средство их не увидит. Например, если у вас в инфраструктуре есть та же Service Mesh Istio, ни один проект не отрисует вам взаимосвязь стандартных ресурсов Kubernetes с Istio.
Итак, мы поняли, что ресурсы связаны. И что связи важны для поддержки и понимания устройства сервисов и других сущностей кластера, как и отсутствие связей — оно может указывать на опечатки и ошибки. Но это для этого требуется поддерживать и понимать огромный набор различных проектов со своей логикой использования связей.
Для примера: в Kubernetes есть команда для
kubectl -n namespace get all. Из ее описания кажется, что она вернет все ресурсы в этом namespace. Но это не так: команда видит только определенный набор ресурсов. Поэтому, если вы ей пользуетесь, то получите неполное представление о конкретном namespace. Способы организации связей между ресурсами
Я выделил шесть способов связи ресурсов между собой — они пригодятся, если вы будете разбираться в чужом проекте либо писать свой Kubernetes-оператор со своими кастомными ресурсами:
-
ownerReference (UID),
-
Selector,
-
targetRef,
-
name,
-
annotations,
- неочевидные связи.
ownerReference
Позволяет одному ресурсу сослаться на его «родителя». При таком способе связи изменение или удаление «родителя» влияет на всех потомков. Такой вариант применяется, например, когда
Deployment — «родитель» ReplicaSet, а ReplicaSet — «родитель» pod.ownerReferences:
- uid: "ae748794-14b3-41le-84aa-e8lab7763be0"
kind: "Deployment"
name: "productpage-vl"
apiVersion: "apps/vl"
controller: true
blockOwnerDeletion: trueownerReference активно использует GarbageCollector: если родитель удаляется, то все ресурсы, связанные с ним по ownerReference, будут удалены. Например, если в описательной модели удалить образ для контейнера, вместе с ним будет удален и ресурс, в котором хранятся связанные с ним результаты сканирования и отчеты.Selector
Самый распространенный способ связи ресурсов между собой — по селекторам и лейблам.
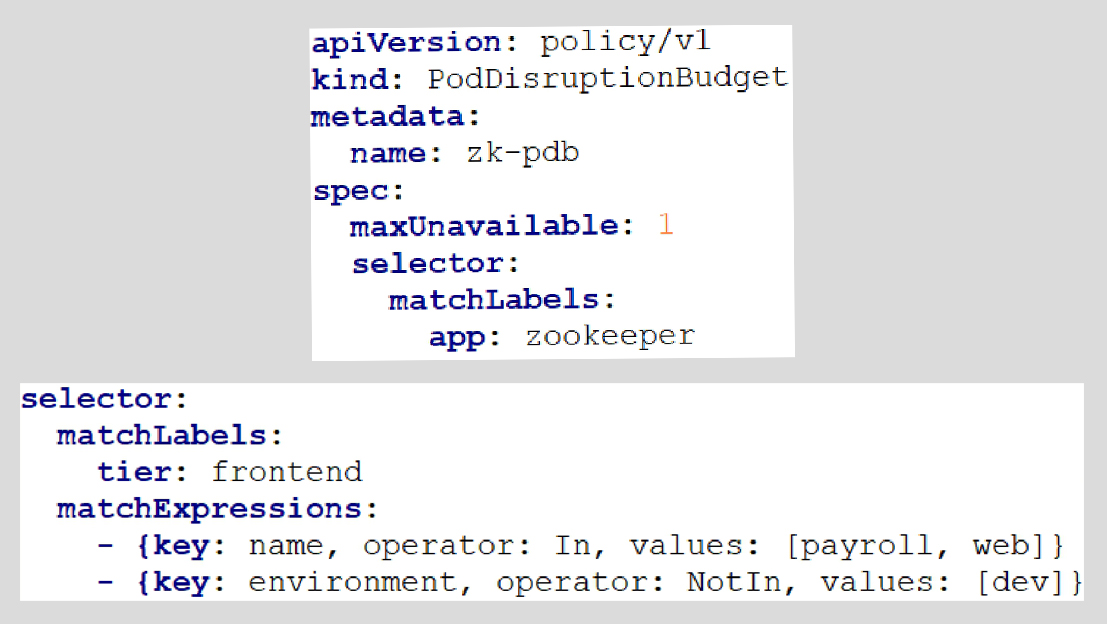
Пример классического синтаксиса с селектором и matchLabels
Но в разных проектах
Selector может использоваться по-разному, что нивелирует удобство и универсальность метода. Например, в кастомных ресурсах может использоваться неклассический синтаксис. apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: allow-tcp-6379
namespace: production
spec:
selector: color == 'red'
ingress:
- action: Allow
protocol: TCP
source:
selector: color == 'blue'
destination:
ports:
- 6379targetRef
Один из способов организации связи —
targetRef. Он подразумевает указание API-версии ресурса, его названия и типа ресурса.
Пример связывания ресурсов с помощью targetRef
Такой способ дает четкое понимание всех взаимосвязей, поэтому
targetRef (название может меняться в зависимости от реализации, но идея остается прежней) считается лучшим для связывания ресурсов между собой. name
В некоторых случаях для организации связи между ресурсами может использоваться название какого-либо ресурса.
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- http:
paths:
- path: /test
backend:
name: web
port:
number: 8080Такой способ не самый очевидный и часто сложен для понимания: не всегда понятно, что именно нужно указать в поле name и какая версия и тип ресурса упоминаются. Без изучения документации часто с этим способом не разобраться, поэтому на практике он практически не применяется.
annotations
В отдельных Kubernetes-операторах ресурсы связывают с помощью аннотаций.
apiVersion: vl
kind: Pod
metadata:
name: hello-apparmor
annotations:
container.apparmor.security.beta.kubernetes.io/hello: localhost/k8s-apparmor-example-deny-writeНапример, такой способ используется в проектах Kubernetes security profile operator и Kubarmor: профили генерируются в виде отдельных ресурсов и связываются с помощью внутренних аннотаций.
Неочевидные связи
Иногда встречаются неочевидные способы связи, в которых невозможно разобраться без детального изучения документации.

Использование неочевидных, запутанных способов связывания ресурсов на примере Istio
Ресурс, созданный в корневом namespace Istio, при использовании применится абсолютно ко всем ресурсам с определенным лейблом. Обычно это cluster-wide-ресурсы, но этот ресурс находится в конкретном namespace, а влияет на все ресурсы в других namespace в Service Mesh сети.
Обеспечение прозрачности процессов с помощью Лантри
Очевидно, что отображение ресурсов в виде списков недостаточно для понимания всех процессов и связей в системе. Для этого лучше применять решения, позволяющие графически отображать текущие состояния, например Лантри. Этот инструмент может отображать кастомные и нативные ресурсы, позволяя отслеживать инфраструктуру, связи и события.
Лантри разработан, чтобы увеличить observability происходящего в Kubernetes. С его помощью можно увидеть практически все: от происходящего внутри контейнеров до коммуникации микросервисов между собой, какие экземпляры Kubernetes влияют и не влияют на работу сервиса.
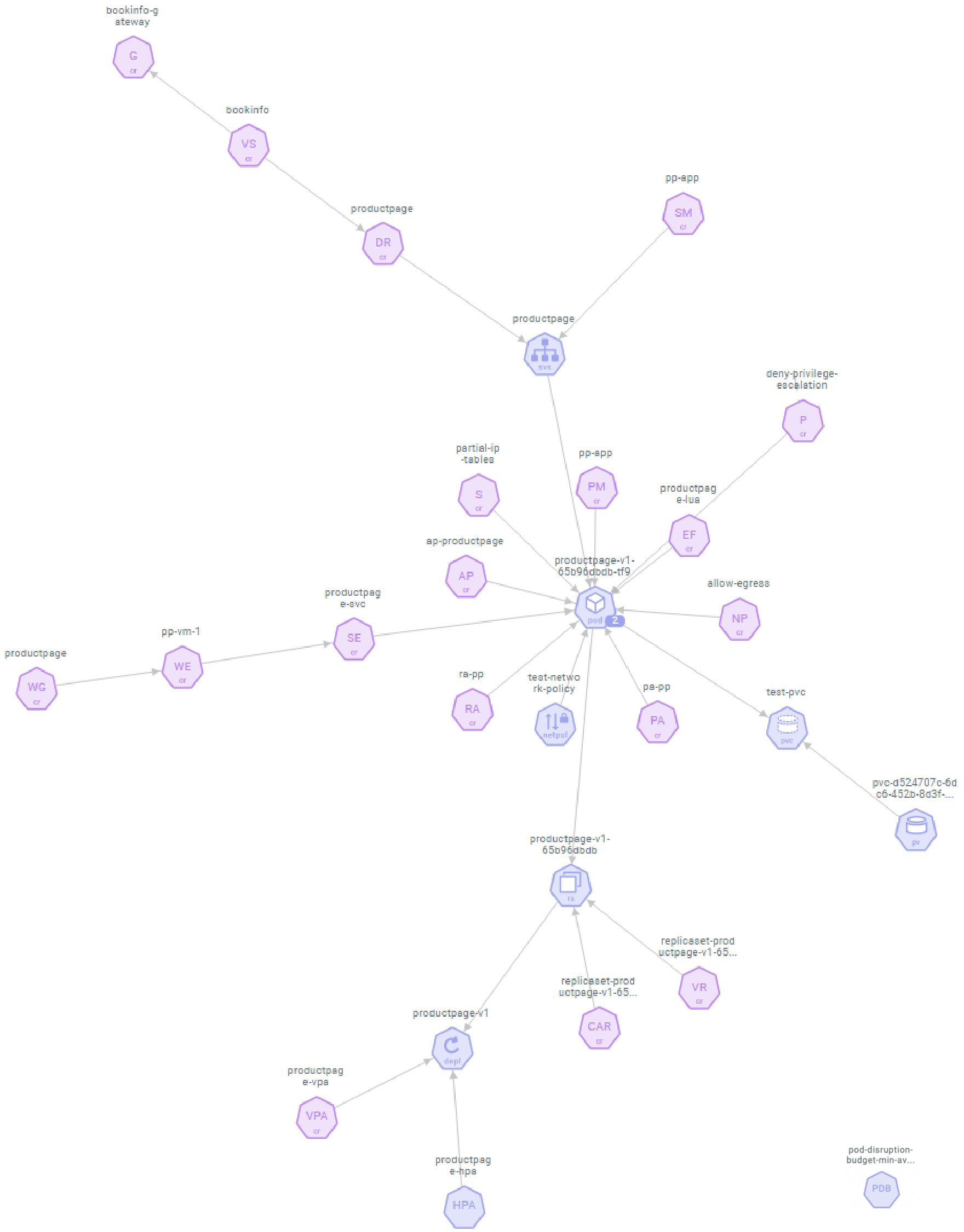
Пример отображения ресурсов проекта в интерфейсе Лантри. Синие — нативные ресурсы, фиолетовые — кастомные ресурсы
В этом случае Лантри отображает пример условного проекта, в котором используются:
- Deployment,
- storage,
- сервисы,
- NetworkPolicy,
- PV/PVC,
- HPA/VPA/PDB,
- Service Mesh (Istio),
- Policy Engine (Kyverno),
- Prometheus operator,
- Starboard operator.
Подобная визуализация позволяет четко отслеживать взаимосвязанность сервисов, текущие связи или их отсутствие (что тоже может быть), а также видеть все аспекты инфраструктуры.
Лантри позволяет специалистам всех команд (Dev, Sec, Ops) видеть единую, глобальную картину происходящего, а использование YAML-файлов помогает разным департаментам не просто разговаривать друг с другом на одном языке, а определять, наблюдать, контролировать и управлять всеми аспектами.
При реализации практики совместного использования Лантри и YAML Kubernetes становится одинаково понятным, удобным и управляемым для всех: от разработчиков и SRE-инженеров до специалистов, отвечающих за мониторинг и безопасность. Это упрощает много операционных процессов и помогает быстро исправлять любые ошибки, не обращаясь за помощью в другие департаменты и не используя сторонние интерфейсы с ограниченным доступом.
Почему важна визуализация аспектов инфраструктуры
Многие специалисты, работающие с Kubernetes, так или иначе работают с ресурсами в виде списков. С увеличением числа используемых компонентов такую конфигурацию становится сложнее контролировать, отлаживать и поддерживать в работоспособном состоянии, особенно в условиях постоянных и частых изменений.
Кроме того, графическое отображение важно, потому что:
-
Ресурс может указывать на несуществующие сущности. Например, если селектор ссылается на устаревшую версию лейбла или разработчик просто делает опечатку. В таком случае визуализация отображает, где именно разорвана связь. При использовании ресурсов в виде списков и каталогов увидеть это невозможно.
-
Ресурс может указывать на сущность за пределами кластера. Многие Kubernetes-операторы могут быть связаны с внешними базами данных, например, для передачи телеметрии разработчикам опенсорсных решений. Графический контроль помогает понимать, с кем и как взаимодействует ресурс.
-
NameSpaced-ресурсы могут ссылаться на Cluster-wide-ресурсы, и наоборот. При этом сетевые политики Cluster-wide-ресурсов могут влиять на сетевую работу pod во всех namespace. Если у специалиста есть доступ только к ресурсам конкретного namespace и нет возможности увидеть происходящее в конфигурации, он может просто не знать, что вызывает ошибки в той или иной ситуации.
-
Данные в Git могут быть неактуальными. Kubernetes-операторы (Admission controllers) могут автоматизированно обрабатывать ситуации без участия человека. Из-за этого содержимое в Git в конкретный момент времени может сильно отличаться от того, что находится в продакшене. Дополнительно изменения в ресурсы могут вносить подключенные инструменты и механизмы. В такой ситуации увидеть реальное состояние инфраструктуры можно только через Kubernetes API.
-
Бывают связи, которые ни на что не влияют. Иногда могут создаваться связи между объектами, которые по разным причинам ни на что не влияют. Часто это может быть из-за ошибок или несовместимости с Network Policy. Такие ситуации нужно оперативно выявлять, а без дополнительных инструментов это сделать сложно.
Главное о YAML и KRM
Изначально Kubernetes разрабатывали в качестве фреймворка и модель Kubernetes Resource Model использовали как основной метод интеграции разных аспектов приложений инфраструктуры в платформу. В контексте этого YAML не только удобный язык сериализации данных. Он позволяет специалистам всех департаментов понимать, что происходит с инфраструктурой и как взаимодействуют сервисы.
Из этого можно сделать несколько выводов:
- Kubernetes Resource Model может помочь получить максимум пользы от Kubernetes. Он позволяет не просто автоматизировать процессы и работать с pod, а повысить скорость разработки и вывода продуктов на рынок за счет слаженной работы всех департаментов.
- YAML-ресурсы нельзя рассматривать в качестве списка обособленных компонентов — это не дает полного представления о текущем состоянии инфраструктуры.
- Инструменты визуализации проектов, такие как Лантри, значительно упрощают отслеживание связей и повышают прозрачность происходящего в Kubernetes. С их помощью можно контролировать инфраструктуру, выявлять аномалии на ранних стадиях и минимизировать риски.
- При использовании модели KRM переход на концепцию Everything-as-Code делает инфраструктуру и происходящие в ней процессы максимально понятными и управляемыми для каждого, как для разработчика, так и для специалиста по безопасности. Особенно концепция Everything-as-Code важна при масштабировании, когда контроль усложнен количеством компонентов.
Мы развиваем наш собственный Kubernetes aaS, о нем рассказывали в этой статье. Будем признательны, если вы его протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Что еще почитать: