

В условиях бизнеса часто попадаются узкоспециализированные задачи, требующие особого подхода, поскольку они не вписываются в стандартный поток обработки данных и построения моделей. Одной из таких задач является классификация новых продуктов в рамках управления мастер-данными .
Первый жизненный пример задачи
Вы работаете в крупной компании (поставщике), занимающейся производством и/или реализацией продукции, в том числе через оптовых посредников (дистрибьюторов). Часто у ваших дистрибьюторов есть обязательство (перед компанией, в которой вы работаете) регулярно предоставлять отчетность о продажах вашей продукции — так называемый Sale Out. Не всегда дистрибьюторы могут отчитаться о проданных товарах в ваших кодах, чаще это свои собственные коды и собственные наименования товаров, которые отличаются от наименований в вашей системе. Соответственно, в вашей базе данных необходимо вести таблицу соответствия дистрибьюторов с товарными кодами вашего продукта. Чем больше дистрибьюторов, тем больше вариаций названия одного и того же товара. Если у вас большой ассортиментный портфель, это становится проблемой, которая решается ручной трудоемкой поддержкой таких таблиц соответствия при поступлении новых вариаций наименований товаров в вашу учетную систему.
Если относиться к наименованиям таких продуктов как к текстам документов, а коды вашей учетной системы (к которой эти варианты привязаны) считать классами, то получаем задачу множественной классификации текстов. Такую таблицу соответствий в вашей базе данных можно считать обучающей выборкой, и если на ней построить такую классификационную модель - она сможет снизить трудоемкость работы операторов по классификации потока новых имён существующих продуктов.
Второй жизненный пример задачи
В базу данных вашей компании поступают данные о продажах (или ценах) продукции от внешних аналитических (маркетинговых) агентств или из парсинга сторонних сайтов. Один и тот же продукт из каждого источника данных также будет содержать вариации в написании. В рамках данного примера задача может оказаться даже сложнее, чем в примере 1, потому что часто у бизнес-пользователей вашей компании возникает потребность в анализе не только вашей продукции, но и ассортимента ваших прямых конкурентов и, соответственно, количества классов ( эталонные товары), к которым привязаны вариации, резко возрастает.
В чем специфика такого класса задач?
Во-первых, очень много классов (на самом деле, сколько у вас продуктов, столько и классов). И если в этом процессе вам придется работать не только с продукцией компании, но и с конкурентами, рост таких новых классов может происходить каждый день - поэтому становится бессмысленным обучать одну модель чтобы многократно ее использовать для предсказания новых продуктов.
Во-вторых, количество документов (разных вариаций одного и того же продукта) в классах не очень сбалансировано: их может быть по одному на класс, а может и больше.
Почему классический подход множественной классификации текстов плохо работает?
Рассмотрим недостатки классического подхода к обработке текста пошагово.
Стоп-слова.
В таких задачах нет стоп-слов в общепринятых понятиях любого пакета обработки текста (но это не исключает создание своего списка в рамках специфики данной задачи)
Токенизация - в классических решениях разделение текста на слова основано на наличии знаков препинания и/или пробелов. В рамках этой задачи (где длина ввода текстового поля часто ограничена) нередко получают названия продуктов без пробелов, где слова разделены не четко, а визуально на основе регистра цифр или другого языка. Попробуйте запустить токенизацию из коробки в вашем любимом языке для вина "ВиноЗащНаимdom.CHRISTIANmoreau0,75LpeМ.EtFilChablis ". Без регулярок вряд ли получится разбить это на вменяемые токены.
Стемминг - вот описание из Википедии:
Сте́мминг (англ. stemming — находить происхождение) — это процесс нахождения основы слова для заданного исходного слова.
Основа слова не обязательно совпадает с морфологическим корнем слова.Задача нахождения основы слова представляет собой давнюю проблему в области компьютерных наук. Первая публикация по данному вопросу датируется 1968 годом.
Стемминг применяется в поисковых системах для расширения поискового запроса пользователя является частью процесса нормализации текста.
Но названия продуктов — это не текст в классическом понимании задачи, поддающийся выделению суффикса/окончания, которое можно отбросить. В названиях продуктов часто присутствуют аббревиатуры и сокращения слов, из которых непонятно, как выделить основу слова. А также есть названия торговых марок из другой языковой группы (например, включение торговых марок французского или итальянского языков в написании кириллицей), не поддающиеся нормальному стеммингу.
Сокращение матриц. - часто при построении матриц "document-term-matrix" пакет вашего языка предлагает уменьшить разреженность матриц для удаления слов (столбцов матрицы) с частотой ниже некоторого минимального порога. В классических задачах это действительно помогает повысить качество и снизить время на обучение модели. Но не в таких задачах. Выше я уже писал, что распределение по классам не сбалансировано - в обучающей выборке может быть всего один экземпляр названия продукта привязанный к эталонному (например, редкая и дорогая марка продукта или новый продукт который вышел на рынок недавно). Классический подход к уменьшению разреженности просто удалит такие токены из матрицы, что не оставит шансов модели классификации для второго такого продукта в predict'е.
Обучение модели.
Обычно на текстах обучается какая-то модель (LibSVM, наивный байесовский классификатор, нейронные сети или что-то еще), которая потом многократно используется. В этом случае новые классы могут появляться ежедневно, а количество документов в классе может в крайних случаях доходить до 1 экземпляра на класс . Поэтому нет смысла долго учить одну большую модель чтобы ее многократно переиспользовать — достаточно любого алгоритма с онлайн-обучением, например, классификатора KNN с одним ближайшим соседом.
Столкнувшись со всеми этими задачами мне пришлось изобретать столь же специфичные решения, которые в итоге я реализовал в пакете abbrevTexts и выложил в гитхаб.
Мы будем использовать tidytext в качестве вспомогательного пакета.
Пример
devtools::install_github(repo = 'https://github.com/edvardoss/abbrevTexts')
library(abbrevTexts)
library(tidytext) # text proccessing
library(dplyr) # data processing
library(stringr) # data processing
library(SnowballC) # traditional stemming
library(tm) В состав пакета я включил 2 набора данных по наименованиям вин: оригинальные наименования вин из внешних источников данных — «rawProducts» и унифицированные наименования вин, прописанные в стандартах ведения мастер-данных — «standardProducts». В таблице rawProducts есть много вариантов написания одного и того же продукта, эти варианты сводятся к одному продукту в StandardProducts через отношение «многие к одному» в ключевом столбце «standartId».
PS Вариации в таблице "rawProducts" генерировал программно , но максимально близко к реальности, с которой сталкиваюсь на работе.
data(rawProducts, package = 'abbrevTexts')
head(rawProducts)

data(standardProducts, package = 'abbrevTexts')
head(standardProducts)
Разделяем на тренировочную и тестовую выборки
set.seed(1234)
trainSample <- sample(x = seq(nrow(rawProducts)),size = .9*nrow(rawProducts))
testSample <- setdiff(seq(nrow(rawProducts)),trainSample)
testSampleСоздаем данные для режимов 'без стемминга' (df.noStem) и 'традиционный стемминг' (df.SnowballStem)
df <- rawProducts %>% mutate(prodId=row_number(),
rawName=str_replace_all(rawName,pattern = '\\.','. ')) %>%
unnest_tokens(output = word,input = rawName) %>% count(StandartId,prodId,word)
df.noStem <- df %>% bind_tf_idf(term = word,document = prodId,n = n)
df.SnowballStem <- df %>% mutate(wordStm=SnowballC::wordStem(word)) %>%
bind_tf_idf(term = wordStm,document = prodId,n = n)Создаем document-term-matrix:
document-term-matrix (Wiki)
Терм-документная матрица представляет собой математическую матрицу, описывающую частоту терминов, которые встречаются в коллекции документов. В терм-документной матрице строки соответствуют документам в коллекции, а столбцы соответствуют терминам. Существуют различные схемы для определения значения каждого элемента матрицы. Одной из таких является схема TF-IDF. Они полезны в области обработки естественного языка, особенно в методах латентно-семантического анализа.
dtm.noStem <- df.noStem %>%
cast_dtm(document = prodId,term = word,value = tf_idf) %>% data.matrix()
dtm.SnowballStem <- df.SnowballStem %>%
cast_dtm(document = prodId,term = wordStm,value = tf_idf) %>% data.matrix()Создаем knn-модель для данных без стемминга и считаем аккуратность классификации:
knn.noStem <- class::knn1(train = dtm.noStem[trainSample,],
test = dtm.noStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.noStem==rawProducts$StandartId[testSample])Accuracy : 0.4761905 (47%)
Создаем knn-модель для данных традиционного стемминга и считаем аккуратность классификации
knn.SnowballStem <- class::knn1(train = dtm.SnowballStem[trainSample,],
test = dtm.SnowballStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.SnowballStem==rawProducts$StandartId[testSample])Accuracy : 0.5 (50%)
Пакет abbrevTexts
Ниже приведен пример с теми же данными, но с использованием функций из пакета abbrevTexts.
Разделяем слова используя функцию makeSeparatedWords пакета abbrevTexts
df <- rawProducts %>% mutate(prodId=row_number(),
rawNameSplitted= makeSeparatedWords(rawName)) %>%
unnest_tokens(output = word,input = rawNameSplitted)
print(df)
Как видите, токенизация текста проведена правильно: учитываются не только переходы из верхнего/нижнего регистра при слитном написании, но и учитываются знаки препинания между словами, написанными слитно без пробелов.
Создание Tidy словаря стемминга на основе обучающей выборки слов
После поисков среди разных реализаций стемминга я пришел к выводу, что традиционные методы, основанные на правилах языка, не подходят для таких специфических задач, поэтому пришлось искать свой подход. В итоге пришел к наиболее оптимальному решению, которое сводилось к обучению без учителя, не чувствительному ни к языку текста, ни к степени сокращения имеющихся слов в обучающей выборке.
Эта функция принимает на вход вектор слов, минимальную длину слова для обучающей выборки и минимальную степень сокращения для рассмотрения "дочернего" слова как сокращения от "родительского" слова (min.share), а затем делает следующее:
Отбрасывает слова с длиной меньше установленного порога.
Отбрасывает слова, которые являются цифрами.
Сортирует слова в порядке убывания их длины.
-
Для каждого слова в списке:
4.1 Фильтрует слова, которые меньше длины текущего слова и больше или равны длине текущего слова, умноженной на min.share;
4.2 Отбирает из полученного списка отфильтрованных слов те, которые являются началом текущего слова.
Допустим, мы фиксируем min.share = 0,7. На этом промежуточном этапе (4.2) мы получаем родительско-дочернюю таблицу, где можно найти такие примеры:
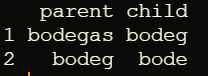
Обратите внимание, что каждая строка удовлетворяет условию, что длина дочернего слова не короче 70% от длины родительского слова.
Однако могут встречаться пары, которые нельзя считать сокращениями слов, поскольку в них разные родительские слова сводятся к одному дочернему, например:

Моя функция для таких "рассогласованных" неявных случаев оставляет только одну пару.
Вернемся к примеру с однозначными сокращениями слов

Но если посмотреть чуть внимательнее, то мы увидим, что для этих 2-х пар есть общее слово "bodeg" (child в первой строке и parent-во второй) и это слово позволяет соединить эти пары в одну цепочку сокращений, не нарушая наших начальных условий на длину слова (70%) так что можно рекурсивно собрать ее в общую цепочку не нарушая входящий параметров в аргументах функции
bodegas->bodeg->bode
Итак, мы приходим к таблице вида:

Такие цепочки могут быть произвольной длины и рекурсивно собираться из найденных пар . Соответственно мы подходим к 5му этапу определения конечного потомка для каждого участника построенной цепочки сокращений слов.
5. Рекурсивный перебор найденных пар для определения конечного (терминального) дочернего элемента для всех членов цепочек.
Возвращает итоговый словарь сокращений
Функция makeAbbrStemDict автоматически распараллеливается несколькими потоками, загружающими все ядра процессора, поэтому при больших объемах текстов целесообразно учитывать этот момент (пакет создавал на Windows, на Unix системах параллелизацию не тестил).
abrDict <- makeAbbrStemDict(term.vec = df$word,min.len = 3,min.share = .6)
head(abrDict) Ниже tidy-словарь стемминга полученный из этой функции на наших данных

Вывод словаря стемминга в виде tidy-таблицы также удобен тем, что в парадигме «dplyr» можно выборочно и простым способом удалить часть ненужных строк стемминга.
Предположим, что мы хотим исключить родительское слово «abruzz» и терминальную дочернюю группу «absolu» из словаря стемминга, делается это легко и быстро:
abrDict.reduced <- abrDict %>% filter(parent!='abruzz',terminal.child!='absolu')
print(abrDict.reduced)
Сравните простоту этого решения с тем, что предлагается в stackoverflow.
Делаем стемминг с учетом словаря
df.AbbrStem <- df %>% left_join(abrDict %>% select(parent,terminal.child),by = c('word'='parent')) %>%
mutate(wordAbbrStem=coalesce(terminal.child,word)) %>% select(-terminal.child)
print(df.AbbrStem)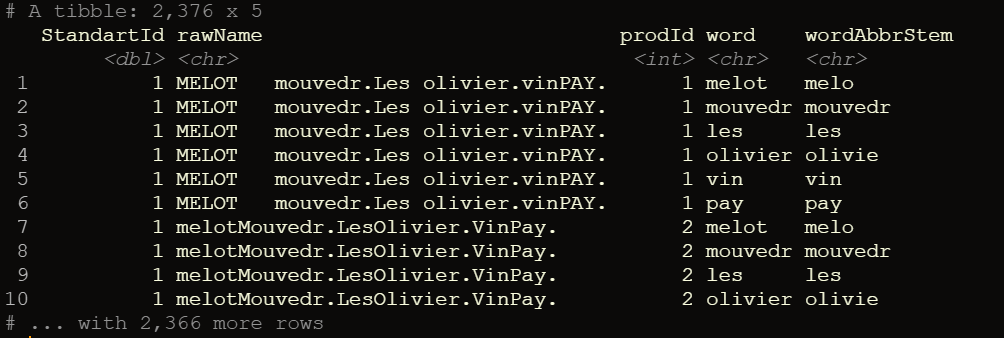
TF-IDF для результата стемминга
df.AbbrStem <- df.AbbrStem %>% count(StandartId,prodId,wordAbbrStem) %>%
bind_tf_idf(term = wordAbbrStem,document = prodId,n = n)
print(df.AbbrStem)
Создаем document terms matrix
dtm.AbbrStem <- df.AbbrStem %>%
cast_dtm(document = prodId,term = wordAbbrStem,value = tf_idf) %>% data.matrix()Создаем knn модель
knn.AbbrStem <- class::knn1(train = dtm.AbbrStem[trainSample,],
test = dtm.AbbrStem[testSample,],
cl = rawProducts$StandartId[trainSample])
mean(knn.AbbrStem==rawProducts$StandartId[testSample]) Accuracy для "abbrevTexts": 0.8333333 (83%)
Как видите, мы получили значительные улучшения качества классификации в тестовой выборке. Tidytext — удобный пакет для небольшого корпуса текстов, но в случае большого корпуса текстов пакет «AbbrevTexts» также отлично подходит для предобработки и нормализации и обычно дает более высокую точность в таких специфических задачах по сравнению с традиционным подходом.
Единственная ремарка - здесь в рамках встроенного датасета я использовал модель классификации из базового пакета R class::knn1 потому что данных у нас не много, но в реальных боевых задачах я использую более мощные алгоритмы, например реализованные в пакете FNN
Надеюсь кому-нибудь статья и пакет помогут.
i_shutov
Генрих, отличная практическая задача с полей. Частая задача во всех ритейлах.
Странно, что никто ничего не прокомментировал, все вручную проглядывают?
Хорошо бы тег python добавить, чтобы охват увеличить.
Ananiev_Genrih Автор
Илья, спасибо за коммент. К сожалению тег #пихтон только разъярит адептов секты отсутствием в коде