
Предлагаем детальный гайд по подготовке к интервью по проектированию системы ML
Что означает дизайн системы ML?
Такие навыки как машинное обучение, презентации, кодирование, статистика, вероятность, тематические исследования и прочие необходимы для успешного проведения интервью по машинному обучению. И одном из главных интервью по ML является интервью по проектированию системы.
Оно необходимо для оценки кандидата на его понимание общей картины разработки полной системы ML с учетом всех деталей. В основном кандидаты ML хорошо разбираются в технических тонкостях, но когда дело доходит до их компиляции, они не могут увидеть сложности и взаимозависимости проектирования всей системы от сбора данных до оценки и развёртывания модели и поэтому плохо справляются с интервью.
Важно в таком интервью – структурированный мыслительный процесс. Однако он требует подготовки. Заранее подготовленный гайд может очень пригодиться при ограниченном времени интервью. Гарантируем, что вы сконцентрируетесь на важном, не будете долго обсуждать одно или упускать важные темы.
Итак, гайд выглядит так:
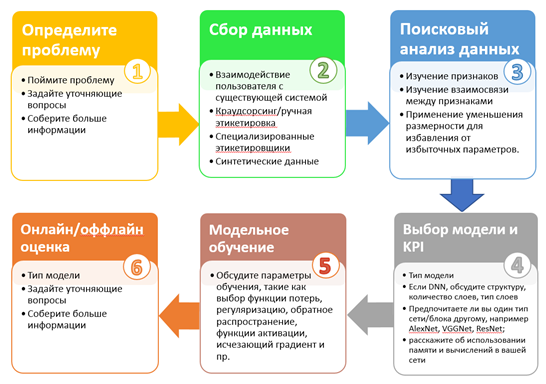
Далее мы рассмотрим организованное интервью ML в соответствии с шаблоном, состоящим из 6 этапов, изображенным на схеме, с описанием ключевых ресурсов для каждого модуля.
1. Задайте уточняющие вопросы и разберитесь в проблеме.
Ключевым моментом в разработке эффективной модели является сбор как можно большего количества информации. Столкнувшись с проблемой, необходимо убедиться, что поняли ее правильно, задать уточняющие вопросы, например, размер данных, ограничения энергии, памяти, данных, требования к задержке и пр.
2. Сбор данных, генерация.
ML модели учатся непосредственно на данных, поэтому источник и стратегия сбора имеют большое значение. Есть несколько путей сбора данных для вашей ML системы:
Взаимодействие пользователя с существующей системой;
Краудсорсинг/ручная этикетировка;
Специализированные этикетировщики;
Синтетические данные.
Полезно обсудить с заказчиком/интервьюером какие данные вам доступны и их универсальность. Вы должны быть осведомлены о последствиях несбалансированного набора данных в ML и устранить дисбаланс при необходимости. Убедитесь, что положительные и отрицательные образцы сбалансированы, чтобы избежать переобучения к одному классу. Также в процессе сбора данных не должно быть никакой предвзятости. Спросите себя, взяты ли данные из достаточно большого массива, чтобы они хорошо обобщались.
3. Поисковый анализ данных.
Итак, у вас есть необработанные данные, но использовать их для подачи в систему ML пока нельзя. Вы должны анализировать и возможно сократить их. Предварительная обработка включает в себя очистку данных, фильтрацию и избавление от избыточных параметров. Приведем несколько способов сделать это:
Изучение признаков (среднее, медиана, гистограмма и т.д.);
Изучение взаимосвязи между признаками (корреляция, ковариация и т.д.);
Применение уменьшения размерности (например, РСА) для избавления от избыточных параметров.
Цель – изучить, какие функции важны, и избавиться от лишних, чтобы избежать проблем в обучении модели.
4. Выбор модели и KPI.
Не выбирайте сложные модели, начинайте с более простых. Проанализируйте модель для данной проблемы и данных, а затем продолжайте ее совершенствовать. Интервьюер поинтересуется вашей логикой, можете ли вы осознать свои ошибки и улучшить их. Дискутируя о модели, вы должны быть уверены, что обсуждаете:
Тип модели (ANN, регрессия, деревья, случайны лес и т.д.);
Если вы выбрали DNN, обсудите структуру, количество слоев, тип слоев и т.д.;
Предпочитаете ли вы один тип сети/блока другому, например AlexNet, VGGNet, ResNet;
Обязательно расскажите об использовании памяти и вычислений в вашей сети.
Выбор модели зависит как от имеющихся данных, так и от показателей производительности. Обязательно расскажите о различных ключевых показателях эффективности и о том, как они сравниваются друг с другом. Такие ключевые показатели эффективности включают, но не ограничиваются ими:
Задача классификации: accuracy[1], precision (точность)[2], recall (полнота)[3], F1-мера, площадь под кривой ошибок ROC (AUROC);
Регрессия: MSE, MAE, R-квадрат/скорректированный R-квадрат;
Обнаружение объекта/локализация: IoU[4], средняя точность (average precision – AP);
Усиленное обучение: кумулятивное вознаграждение, доходность, Q-оценка;
Система/оборудование: задержка (latency), энергия, мощность;
KPI бизнеса: удержание пользователей, ежедневные/ежемесячные активные пользователи (DAU, MAU), новые пользователи.
5. Модельное обучение.
Будьте готовы проявить технические знания. Вы должны быть знакомы с различными аспектами обучения ML и вы способны поговорить о них. Вас могут спросить как вы будете бороться с переобучением или, например, почему не использовали регуляризацию и т.д. Темы выключают например:
Выбор функции потерь: кроссэнтропия, MSE (среднеквадратическая ошибка), MAE (средняя абсолютная ошибка), потеря Хубера (Huber loss), потеря шарнира (hinge loss);
Регуляризация: L1-регуляризация (или лассо-регрессия – используется для разрежения), L2 (регрессия Риджа), энтропийная регуляризация, кросс-валидация k-fold, dropout (метод прореживания или метод исключения);
Обратное распространение: ADAGrad, SGD, Momentum, RMSProp;
Функции активации[5]: линейная, ELU, RELU, Tanh (гиперболический тангенс), сигмоид-функция;
Исчезающий градиент и как с ним бороться;
Другие проблемы: несбалансированные данные, переоснащение, нормализация и т.д.
6. Оценка.
Итак, ваша цель – чтобы обученная модель хорошо работала в реальных сценариях рассматриваемой проблемы. Чтобы проанализировать это нужно провести как онлайн, так и оффлайн оценки.
Оффлайн оценка: производительность модели на независимых наборах данных, например, тренировочном, тестовом и валидационном. Идея состоит в том, чтобы проанализировать, насколько хорошо модель обобщает независимые наборы данных. Вы также можете выполнить кросс-валидацию K-fold, чтобы найти производительность для разных наборов данных. Модель, которая хорошо работает для выбранного KPI, выбирается для реализации и развертывания.
Онлайн оценка: Первым шагом развертывания обученной модели в реальных сценариях (после того, как она была оценена в оффлайн режиме) является проведение А/В-тестирования. Обученная модель не может быстро справиться с реальными данными вцелом, т.к. есть риски. Вместо этого модель развертывается на небольшом подмножестве сценариев. Например, модель должна сравнить водителя Убер и гонщика. При А/В-тестировании модель будет развернута только в меньшем географическом регионе, а не по всему земному шару. Затем бета-версия модели будет сравниваться с существующей моделью в течение более длительного периода времени. И если это приведем к увеличению производительности KPI, связанных с бизнесом (например, больше DAU/MAU для приложения Убер, лучшее удержание пользователей и, в конченом счете, увеличение дохода) тогда она будет реализована в более широком масштабе.
Подводим итог
Если на каком-то этапе вы движетесь в неправильном направлении, интервьюер вмешается и попытается направить вас в нужном направлении. Убедитесь, что вы прислушались к советам интервьюера.
Предполагается, что проектирование системы ML-это дискуссия, поэтому всякий раз, когда вы что-то заявляете, спросите интервьюера, что он думает по этому поводу или считает ли он это приемлемым шагом проектирования. Как только закончите говорить об этих 6 шагах (с улучшениями в процессе), обязательно кратко опишите окончательные параметры проектирования системы в нескольких предложениях, упоминая ключевые выводы на этом пути.
Итак, в этой рассмотрен гайд по интервью о проектировании системы ML. Здесь нет ни правильных, ни неправильных ответов, цель интервью-анализ мыслительного процесса кандидата для проектирования системы. Тем не менее, для успеха в этом интервью необходимо глубокое понимание различных тем ML.
[1] Доля правильных ответов алгоритма. Метрика, характеризующая качество модели, агрегированное по всем классам.
[2] Точность - Доля правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом.
[3] Доля правильно найденных положительных объектов среди всех объектов положительного класса.
[4] Отношение площадей ограничивающих рамок.
[5] Определяет выходное значение нейрона в зависимости от результата взвешенной суммы входов и порогового значения.