
В первой части статьи было рассказано о бинарном и json форматах сериализации данных, о механизмах версионирования. В этой части речь пойдет о концепции команд, сообщениях, и механизмах их доставки.
Команда
В начале было Request/Response
Создавая что-то новое мы так или иначе опираемся на имеющиеся знания и опыт. В этом смысле "Команды" не стали исключением. Среди rpc-протоколов достаточно широко распространена концепция Request/Response (Запрос/Ответ). SOAP-протокол яркое тому подтверждение. Сначала я тоже шел по этому пути. Использование Request/Response выглядело простым и логичным: для того, чтобы получить что-либо, мы отправляем "Запрос", а в качестве результата получаем "Ответ" с нужными данными или описание ошибки, если что-то пошло не так. Однако по мере расширения сферы применения PProto протокола стали возникать ситуации, не укладывающиеся в рамки парадигмы "Запрос/Ответ". Например, когда "Запрос" используется не для получения данных, а для отправки управляющей команды или когда "Запрос" не нуждается в получении "Ответа". Возникало терминологическое несоответствие: что же это за "Запрос" такой, если на него ответ не нужен?! Поначалу я смотрел на подобные ситуации как на исключения из правил, но со временем их становилось все больше. В какой-то момент пришло понимание того, что относиться к ним как к исключениям уже нельзя, требовалось переосмысление используемой парадигмы. Исключения сами подсказали направление движения мысли: раз уж существенная часть "Запросов" используется для выполнения команд, то почему бы понятие "Команда" не сделать основополагающим? Терминологически "Команда" определяет требование (императив) совершения какого-либо действия. В этом контексте "Запрос (Request)" будет являться частным случаем "Команды (Command)", то есть командой для получения данных. Чтобы уйти от ассоциативности восприятия пары Request/Response, ответ на команду стал обозначаться словом "Answer".
Коллизии строковых имен
Отправляя "Запрос" (здесь пока используем старую терминологию) на удаленный узел, структуру запроса нужно как-то обозначить - присвоить ей имя. Обычно имя структуры запроса совпадает с наименованием вызываемой функции на удаленном узле. Вот простой пример для SOAP-протокола, взятый из интернета:
<soap:Body xmlns:m="http://www.example.org/stock">
<m:GetStockPrice>
<m:StockName>IBM</m:StockName>
</m:GetStockPrice>
</soap:Body>Здесь GetStockPrice - имя запроса. Наименование ответа часто содержит слово "Response":
<soap:Body xmlns:m="http://www.example.org/stock">
<m:GetStockPriceResponse>
<m:Price>34.5</m:Price>
</m:GetStockPriceResponse>
</soap:Body>Когда количество "Запросов" переваливает за две-три сотни и над проектом одновременно работают несколько разработчиков, возникает риск случайного повторения имен запросов (коллизий). Применительно к SOAP-протоколу контроль дубликатов может осуществляться на уровне генератора кода, но в самодельных rpc-протоколах подобная проверка не всегда присутствует. С такой реализацией мне довелось столкнуться в одном достаточно крупном проекте. Наличие коллизий разработчики должны были контролировать сами. Не могу сказать, что это было удобно. Поэтому при создании собственного протокола у меня был отдельный пункт по поводу уникальности наименований запросов (будущих "Команд").
Как известно, в C++ невозможно создать две переменных с одним и тем же именем в пределах одной области видимости. Это можно использовать. Если отказаться от строкового представления и определить "Команду" как языковую переменную, то за ее уникальность будет отвечать компилятор, а не программист. Осталось выбрать тип переменной. Первоначально мной рассматривались два варианта: int и string. Строковый тип - вполне рабочий вариант, но его использование отчасти означало бы возврат к тому, от чего только что ушли. Для бинарного протокола целочисленный тип выглядел более предпочтительным как с точки зрения объема, так и с точки зрения операций сравнения. Но у int-типа есть свои недостатки:
проблематично использовать монотонно нарастающие значения (наподобие
enum), так как сложность синхронизации таких значений будет прямо пропорциональна количеству разработчиков, участвующих в проекте;для псевдослучайных значений есть риск возникновения коллизий.
Проблема возникновения коллизий хорошо проработана для типа UUID. Вероятность появления дубликатов при генерации UUID настолько мала, что в большинстве случаев ей можно смело пренебречь. По большому счету UUID это тоже целочисленный тип только очень большой разрядности (128 бит). В протоколе PProto в операциях сравнения UUID интерпретируется как int128 при условии, что такой тип поддерживается операционной системой. Итак, с типом определились. Теперь можно сформулировать определение для "Команды":
Команда - это 128-битный числовой идентификатор (uuid), который обозначает выполняемое действие.
В C++ команда выглядит следующим образом:
//--- Хедер-файл ---
extern const QUuidEx Command1;
//--- Cpp-файл ---
const QUuidEx Command1 {"424efc1d-78c9-4e27-b70b-d12abd43f2a4"};Объявление и определение Command1 разделены сознательно. Для работы с командой потребуется ее адрес. Если определение выполнить в хедер-файле, то при сборке программы получим inline-подстановку, адрес у такой переменной будет отсутствовать.
К сожалению, радость от уникальности UUID-ов длилась недолго. Быстро выяснилось, что UUID-ы все-таки могут повторяться, и причина тому - человеческий фактор. При создании новой команды разработчик часто копирует/вставляет предыдущую, и если имя команды неизменным оставить невозможно, то числовой идентификатор можно спокойно дублировать, то есть разработчик может просто забыть его поменять. Как говорится, за что боролись, на то и напоролись! Для решения проблемы был выбран простой путь: при определении "Команды" происходит ее регистрация в пуле команд, далее при старте программы, обычно в функции main(), выполняется проверка на уникальность идентификаторов. Если обнаружено дублирование - работа программы прерывается, в лог выводится сообщение с указанием проблемных команд. Таким образом, коллизии стали отсекаться при первом же запуске. Регистрация команд в пуле выглядит так:
#define REGISTRY_COMMAND(COMMAND, UUID) \
const QUuidEx COMMAND = command::Pool::Registry{UUID, #COMMAND, false};
REGISTRY_COMMAND(SpeedTest, "b2e4557e-80eb-4b86-8bfa-7a12caade6d0")
REGISTRY_COMMAND(KeepWaitCommand, "edbd2b76-eee4-4ad5-80c0-b95dc0e2dfeb")
#undef REGISTRY_COMMANDПроверка уникальности команд при старте программы:
if (!pproto::command::checkUnique())
{
stopProgram();
return 1;
}Применение пула команд не ограничивается только проверкой уникальности, он используется для фильтрации неизвестных входящих команд, а так же в функциях-обработчиках сообщений.
Базовые команды
Протокол содержит следующие базовые команды:
QUuidEx Unknown {"4aef29d6-5b1a-4323-8655-ef0d4f1bb79d"}
Информирует противоположную сторону о том, что полученная команда неизвестна;QUuidEx Error {"b18b98cc-b026-4bfe-8e33-e7afebfbe78b"}
Команда используется для передачи информации об ошибке;QUuidEx ProtocolCompatible {"173cbbeb-1d81-4e01-bf3c-5d06f9c878c3"}
Запрос информации о совместимости. При подключении клиент и сервер отправляют друг другу информацию о совместимости. Это основополагающая команда: если она не будет отправлена/получена, то не произойдет запуск очереди обработки сообщений для установленного соединения;QUuidEx CloseConnection {"e71921fd-e5b3-4f9b-8be7-283e8bb2a531"}
Требование закрыть TCP соединение. Команда работает следующим образом: сторона, которая хочет закрыть соединение, отправляет это сообщение с информацией о причине закрытия соединения. Принимающая сторона записывает эту информацию в свой лог (или использует иным образом), затем отправляет обратное пустое сообщение. После того, как ответное сообщение получено, TCP соединение может быть разорвано. Такое поведение реализовано для того, чтобы сторона, с которой разрывают соединение, имела информацию о причине разрыва;QUuidEx EchoConnection {"db702b07-7f5a-403f-963a-ec50d41c7305"}
Команда для проверки актуальности TCP соединения. Иногда возникают ситуации, когда TCP соединение как бы "подвисает": данные через соединение не передаются, но разрыва TCP сессии при этом не происходит. Такое явление можно наблюдать при передаче TCP пакетов через несколько VPN туннелей. Команда EchoConnection позволяет отслеживать подобные ситуации и принудительно разрывать TCP соединение. После разрыва эмитируется внутреннее сообщение EchoConnection. Таким образом, приложение может корректно обработать потерю соединения.
В будущем этот список может быть расширен. Объявление базовых команд находится в файле commands/base.h
Сообщение
Для совершения действия одного идентификатора команды недостаточно. Большинству команд требуются исходные данные. У завершенного действия должна быть информация о статусе выполнения, также результат может содержать датасет. Чтобы совместно использовать команду, данные и статус выполнения, введена сущность "Сообщение".
Сообщение - это контейнер, который используется для пересылки команды совместно с данными, необходимыми для выполнения действия. Также при помощи сообщения возвращается результат и статус совершенного действия.
Наиболее значимые поля сообщения приведены в таблице.
Поле |
Описание |
|---|---|
id |
Идентификатор сообщения ( |
command |
Идентификатор команды ( |
type |
Тип сообщения |
execStatus |
Статус выполнения команды/обработки сообщения |
priority |
Приоритет сообщения |
tags |
Список 8-ми байтовых ( |
maxTimeLife |
Максимальное время жизни сообщения |
content |
Контент сообщения (полезная нагрузка, сериализованные данные) |
Структура сообщения определена в файле message.h. Ниже будут даны развернутые пояснения по некоторым параметрам.
Идентификатор сообщения: каждое сообщение имеет уникальный идентификатор, что позволяет отслеживать сообщение на каждом этапе его жизни. Идентификатор используется в механизмах синхронной обработки сообщений. В демонстрационном примере TDemo 05 приведен один из возможных вариантов синхронной обработки сообщения.
Тип сообщения: поле type определяет назначение сообщения в конкретный момент времени. Поле может принимать следующие значения:
Command - сообщение является командой на выполнение действия (или запрос данных), предполагается, что в ответ на данное сообщение придет сообщение с типом Answer;
Ansver - ответ (или результат) обработки сообщения с типом Command;
Event - этот тип похож на Command, но не предполагает получения ответа (Answer), он используется для рассылки широковещательных сообщений о событиях.
Статус выполнения команды: используется в сообщениях с типом Answer для того, чтобы уведомить другую сторону о результате выполнения команды с типом Command. Поле может принимать следующие значения:
Success - сообщение было обработано успешно и содержит корректные ответные данные;
Failed - сообщение не было обработано успешно, но результат не является ошибкой. Ответное сообщение будет содержать данные в формате
pproto::data::MessageFailedс описанием причины неудачи;Error - при обработке сообщения произошла ошибка. Ответное сообщение будет содержать данные в формате
pproto::data::MessageErrorс описанием причины ошибки.
Приоритет сообщения: позволяет установить приоритет для отправляемого сообщения. На принимающей стороне сообщение обрабатываются согласно порядку поступления, то есть приоритет не учитывается. При отправке ответного сообщения (тип Answer) приоритизация будет работать. Поле может принимать следующие значения: High, Normal, Low.
Поле tags: используется для передачи списка пользовательских данных размером 8 байт без сохранения их в поле content. Это позволяет сократить количество ресурсоемких операций по сериализации/десериализации данных, выполняемых для поля content. Максимальная длина списка составляет 255 элементов.
Максимальное время жизни сообщения: максимальное время жизни сообщения задается в секундах в формате UTC от начала эпохи. Параметр представляет абсолютное значение времени, по достижении которого сообщение перестает быть актуальным. Тайм-аут в 2 мин. можно задать так: setMaxTimeLife(std::time() + 2*60).
Контент сообщения: поле содержит произвольные сериализованные данные (механизмы сериализации описаны в первой части статьи).
Поле compression: возвращает информацию о том, в каком состоянии (сжатом или несжатом) находится контент сообщения. Поле может принимать следующие значения:
None - контент не сжат;
Zip - сжатие zip-алгоритмом, используются функции
qCompress()/qUncompress();Lzma - сжатие lzma-алгоритмом. По умолчанию алгоритм недоступен, для его активации в проект необходимо подключить библиотеку Compression ;
Ppmd - сжатие ppmd-алгоритмом. По умолчанию алгоритм недоступен, для его активации в проект необходимо подключить библиотеку Compression ;
Disable - при отправке сообщения в TCP сокет оно опционально (зависит от настроек соединения) может быть сжато zip-алгоритмом. Если контент сообщения предварительно уже сжат (JPG, PNG и пр. форматы), получим двойное сжатие и как следствие лишний расход процессорного ресурса. Чтобы этого избежать используется
Disable.
Данные для команды
В конструкции сообщения есть одна тонкость: команда связана с сообщением однозначно, а вот сериализованные данные могут быть совершенно произвольными. Предполагалось, что взаимодействующие стороны предварительно договариваются о формате данных для команды, и потом его придерживаются. Такой подход обладает большой вариативностью, но в этом кроется и серьезный недостаток. Проблема аналогична ситуации с дублированием команд - человеческий фактор. При копировании/вставке кода разработчик может забыть поменять тип структуры, что приведет к труднодиагностируемым ошибкам. Вдобавок к этому, с ростом количества команд в проекте, становится сложно отслеживать, какой команде принадлежит конкретная структура данных.
Пример записи произвольных данных в сообщение:
struct Data1
{
qint32 a;
DECLARE_B_SERIALIZE_FUNC
};
Data1 data1;
Message::Ptr message = createMessage(Command1);
message->writeContent(data1); // Command1 и Data1 никак не связаны между собойВ помощь программисту был разработан специальный декларативный механизм, позволяющий связать команду и структуру данных. Важно подчеркнуть, что механизм не ограничивает разработчика, а помогает ему не запутаться с командами и их структурами. Возможность записи произвольных данных в сообщение по прежнему остается.
Чтобы связать команду и структуру, необходимо последнюю унаследовать от базовой структуры Data. При этом шаблонные параметры базовой структуры будут определять критерии связи.
namespace pproto {
namespace command {
extern const QUuidEx Command1;
}; // namespace command
namespace data {
struct Command1Data : Data<&command::Command1, // Декларируем связь структуры и команды.
Message::Type::Command, // Декларируем, что структура будет использоваться
// в сообщении с типом Command.
Message::Type::Answer> // Декларируем, что структура будет использоваться
// в сообщении с типом Answer.
{
qint32 a;
DECLARE_B_SERIALIZE_FUNC
};
} // namespace data
data::Command1Data command1Data;
// Создаем сообщение с типом Message::Type::Command
Message::Ptr message = createMessage(command::Command1);
// Вызов writeToMessage будет корректным, так как тип Message::Type::Command
// декларирован для Command1Data
writeToMessage(command1Data, message);
// Создаем сообщение с типом Message::Type::Event
Message::Ptr message2 = createMessage(command::Command1, Message::Type::Event);
// Здесь при вызове writeToMessage прозойдет ошибка, так как тип Message::Type::Event
// не декларирован для Command1Data
writeToMessage(command1Data, message2);
} // namespace pprotoВ функции writeToMessage() выполняется проверка на соответствие между командой и структурой данных. Если команда и структура не соответствуют друг другу, в лог будет выведено сообщение об ошибке, затем программа завершит свою работу. Таким образом, расхождение будет выявлено уже при первом отладочном запуске.
Поскольку команда и структура теперь однозначно связаны, появляется возможность создавать сообщение сразу из структуры данных, без вызова writeToMessage().
data::Command1Data command1Data;
Message::Ptr message = createMessage(command1Data); У команды может быть несколько ассоциированных структур. Например, первая структура содержит данные для выполнения запроса, а вторая - для получения ответа.
namespace pproto {
namespace command {
extern const QUuidEx Command2;
}; // namespace command
struct Command2Data : Data<&command::Command2, // Декларируем связь структуры и команды.
Message::Type::Command> // Декларируем, что структура будет использоваться
// в сообщении с типом Command.
{
qint32 b;
DECLARE_B_SERIALIZE_FUNC
};
struct Command2DataA : Data<&command::Command2, // Декларируем связь структуры и команды.
Message::Type::Answer> // Декларируем, что структура будет использоваться
// в сообщении с типом Answer.
{
qint32 c;
qint32 d;
DECLARE_B_SERIALIZE_FUNC
};
data::Command2Data command2Data;
// Создаем сообщение с типом Message::Type::Command
Message::Ptr message = createMessage(command2Data);
// Отправляем сообщение в точку обработки
// ...
// Получаем ответное сообщение (answer). Тип сообщения Message::Type::Answer
data::Command2DataA command2DataA;
readFromMessage(answer, command2DataA);
} // namespace pprotoЕсли попробовать создать сообщение при помощи функции createMessage() на основе структуры Command2DataA, получим ошибку, так как Command2DataA предназначена только для ответных (Message::Type::Answer) сообщений. Также закончится ошибкой попытка прочитать данные из сообщения, созданного для команды Command1 в структуру Command2Data.
data::Command1Data command1Data;
Message::Ptr message = createMessage(command1Data);
data::Command2Data command2Data;
// Ошибка чтения данных: идентификатор команды (Command1) для message
// не соответствует идентификатору (Command2) для command2Data
readFromMessage(message, command2Data); Важно: при копировании/вставке кода программист по невнимательности может связать структуру данных с не той командой, например,
Command2Dataсвязать сCommand1, что с высокой долей вероятности приведет к неопределенному поведению программы. Диагностировать такие ошибки вряд ли возможно, поэтому программист должен быть внимателен при создании связи между структурой и командой.
В заключении раздела приведу пример создания ответного сообщения.
//--- Точка обработки сообщения ---
data::Command2Data command2Data;
// Читаем исходные данные для выполнения запроса из поступившего сообщения
readFromMessage(message, command2Data);
data::Command2DataA command2DataA;
// Получаем запрашиваемые данные, сохраняем их в command2DataA
// ...
// Содаем ответное сообщение с типом Message::Type::Answer
Message::Ptr answer = message->cloneForAnswer();
writeToMessage(command2DataA, answer);
// Отправляем answer в точку запроса данных
// ...Пояснение по использованию Message::cloneForAnswer(): в многопоточном приложении нельзя менять параметры исходного сообщения, поэтому ответное сообщение должно быть клоном исходного. Особенности работы функции клонирования описаны в модуле message.h.
Возврат информации об ошибках
Информирование об ошибочных ситуациях - важная часть любого программного механизма. В протоколе PProto предусмотрены несколько способов для работы с ошибками:
самостоятельная команда
Error;возврат информации об ошибке в ответном сообщении (тип сообщения
Message::Type::Answer);пользовательские структуры с информацией об ошибке.
Статистика использования указанных решений примерно следующая: команда Error - 0.5%; пользовательские структуры - 2-3%; оставшиеся 97% это возврат информации об ошибке в ответном сообщении. Рассмотри эти решения подробней.
Команда Error
Команда Error - это первый механизм, разработанный для протокола. Широкого распространения он не получил. Команда используется в тех случаях, когда по какой-либо причине невозможно передать информацию об ошибке в ответном сообщении. Для передачи данных используется одноименная структура.
struct Error : Data<&command::Error,
Message::Type::Command>
{
QUuidEx commandId; // Идентификатор команды, при выполнении которой произошла ошибка.
QUuidEx messageId; // Идентификатор сообщения.
qint32 group = {0}; // Код группы, используется для группировки сообщений.
QUuidEx code; // Глобальный код ошибки.
QString description; // Описание ошибки.
};Возврат информации об ошибке в ответном сообщении
Статус выполнения команды (Message::execStatus) определяет успешность совершенного действия. Предполагается, что в случае успешного выполнения команды ответное сообщение будет содержать запрашиваемые данные, а при неудаче - информацию об ошибке. Теоретически для каждой команды можно создать индивидуальную структуру с описанием ошибки, но практически это лишено смысла, так как большинство структур будут идентичными. В качестве общего решения по обработке ошибочных ситуаций протокол PProto предлагает две структуры, не привязанные к конкретной команде: MessageError и MessageFailed.
MessageErrorсодержит информацию об ошибке произошедшей в процессе обработки сообщения. Структура отправляется вызывающей стороне как Answer-сообщение, со статусом выполнения команды (Message::execStatus) равным Error.
struct MessageError
{
qint32 group = {0}; // Код группы, используется для группировки сообщений
QUuidEx code; // Глобальный код ошибки
QString description; // Описание ошибки
};Ремарка по поводу типа поля code: первоначально поле было целочисленным. С ростом количества программистов, вовлекаемых в разработку проектов, возросла сложность синхронизации целочисленных кодов ошибок. Переход на uuid-тип полностью устранил эту проблему.
MessageFailed отправляется вызывающей стороне как Answer-сообщение, со статусом выполнения команды (Message::execStatus) равным Failed. Это означает, что результат выполнения команды не является успешным, но и не является ошибкой. Такая ситуация может возникнуть, когда запрашиваемое действие невозможно выполнить корректно в силу разных причин. Например, неверные логин/пароль при аутентификации пользователя.
struct MessageFailed
{
qint32 group = {0}; // Код группы, используется для группировки сообщений
QUuidEx code; // Глобальный код неудачи
QString description; // Описание ошибки
};Возникает вопрос: "Зачем нужны две абсолютно идентичные структуры?" Можно назвать две причины:
В начале работы над протоколом не существовало четкого понимания о том, что в будущем структуры останутся идентичными, поэтому они были оставлены разделенными;
Статус выполнения команды зависит от типа сохраняемой в сообщение структуры, что дает более короткую запись в коде. Ниже приведено несколько примеров.
Создание ответного сообщения со статусом Message::ExecStatus::Error:
data::MessageError error;
// Создаем ответное сообщение с типом Message::Type::Answer
Message::Ptr answer = message->cloneForAnswer();
// В этой точке при записи информации об ошибке происходит установка статуса
// выполнения команды в Message::ExecStatus::Error
writeToMessage(error, answer);Создание ответного сообщения со статусом Message::ExecStatus::Failed:
data::MessageFailed failed;
// Создаем ответное сообщение с типом Message::Type::Answer
Message::Ptr answer = message->cloneForAnswer();
// В этой точке при записи информации о неудаче происходит установка статуса
// выполнения команды в Message::ExecStatus::Failed
writeToMessage(failed, answer);Явное задание статуса ответного сообщения:
data::MessageError error;
// Создаем ответное сообщение с типом Message::Type::Answer
Message::Ptr answer = message->cloneForAnswer();
writeToMessage(error, answer);
// Явно устанавливаем для структуры MessageError статус сообщения Message::ExecStatus::Failed.
// На принимающей стороне, если не предусмотрен индивидуальный обработчик для такой ситуации,
// десериализация будет выполняться в структуру MessageFailed
answer->setExecStatus(Message::ExecStatus::Failed);Обработка сообщения на принимающей стороне:
if (message->execStatus() == Message::ExecStatus::Success)
{
data::UserData userData;
readFromMessage(message, userData);
// Тут что делаем
}
else if (message->execStatus() == Message::ExecStatus::Error)
{
data::MessageError error;
readFromMessage(message, error);
// Обрабатываем ошибку
}
else if (message->execStatus() == Message::ExecStatus::Failed)
{
data::MessageFailed failed;
readFromMessage(message, failed);
// Обрабатываем неудачу
}Более короткий вариант, когда достаточно знать, что результат не успешен:
if (message->execStatus() == Message::ExecStatus::Success)
{
data::UserData userData;
readFromMessage(message, userData);
// Тут что делаем
}
else
{
QString err = errorDescription(message);
// ...
}Пользовательские структуры с информацией об ошибке
Может случиться так, что для конкретной команды трех полей MessageError окажется недостаточно. В этом случае разработчик может создать расширенную структуру с дополнительными полями для описания ошибки. Расширенная структура должна быть унаследована от MessageError/MessageFailed и "привязана" к команде.
namespace data {
struct Command1Error : MessageError, Data<&command::Command1,
Message::Type::Answer>
{
quint32 extCode = {0}; // Расширенная информация об ошибке
DECLARE_B_SERIALIZE_FUNC
J_SERIALIZE_BEGIN
J_SERIALIZE_BASE( MessageError )
J_SERIALIZE_OPT ( extCode )
J_SERIALIZE_END
};
void Command1Error::fromRaw(const bserial::RawVector& vect)
{
B_DESERIALIZE_V1(vect, stream)
// Структуры унаследованные от MessageError сериализуются в особом порядке,
// поэтому для них сериализация/десериализация базового класса не обязательна
// stream >> B_BASE_CLASS(MessageError);
stream >> extCode;
B_DESERIALIZE_END
}
bserial::RawVector Command1Error::toRaw() const
{
B_SERIALIZE_V1(stream)
stream << extCode;
B_SERIALIZE_RETURN
}
} // namespace dataИспользование расширенных структур с информацией об ошибке/неудаче приведено в примере TDemo 02 (см. команды TDemo02_05, TDemo02_06).
Если разработчик собирается использовать расширенную структуру в качестве глобальной (не привязанной к конкретной команде), наподобие MessageError/MessageFailed, то в этом случае ему придется самостоятельно реализовать специализированные функции чтения/записи: readFromMessage(), writeToMessage(). Код функций достаточно тривиален, посмотреть его можно здесь.
Еще один прием по возврату данных об ошибке заключается в использовании субструктуры с описанием ошибки внутри структуры с данными. Ниже приведен пример из реальной задачи: сервер посылает клиенту команду TaskStatus по мере прохождения задачей определенных стадий выполнения.
enum class TaskState : quint32
{
NotRun = 0, // Задача еще не запускалась
WaitRun = 1, // Состояние ожидания запуска
Running = 2, // В процессе выполнения
Complete = 3, // Завершено успешно
Failure = 4, // Завершено с ошибкой
WaitCancel = 5, // Прервано пользователем (ожидание остановки)
Cancelled = 6, // Прервано пользователем (остановлено)
Aborted = 7 // Прервано программой
};
struct TaskStatus : Data<&command::TaskStatus,
Message::Type::Command>
{
// Идентификатор задачи
QUuidEx id;
// Статус задачи
TaskState state = {TaskState::NotRun};
// Содержит информацию об ошибке для статуса Failure
ErrorInfo error;
...
DECLARE_B_SERIALIZE_FUNC
};Пояснение: сообщение TaskStatus фактически выполняет роль события, но маркировано как Message::Type::Command. Это сделано сознательно, чтобы обозначить, что сообщение-событие отправляется не всем подключенным клиентам, а только одному.
Декларативное описание ошибок
Декларативное описание позволяет в наглядной форме инициализировать переменные совместимые с MessageError. Вот несколько деклараций взятых из файла error.h
// Переменная-ошибка Группа, Id ошибки, Описание
DECL_ERROR_CODE(connect_to_database, 10, "2361b42b...", u8"Ошибка подключения к базе данных")
DECL_ERROR_CODE(begin_transaction, 10, "d521450f...", u8"Ошибка старта транзакции")
DECL_ERROR_CODE(commit_transaction, 10, "5bc8301e...", u8"Ошибка завершения транзакции")
DECL_ERROR_CODE(rollback_transaction, 10, "ee3f3100...", u8"Ошибка отмены транзакции")Декларативный способ описания ошибок имеет аналогичный с командами недостаток - идентификаторы могут ненамеренно повторяться. Поэтому, как и в случае с командами, идентификаторы ошибок проверяются при старте программы на уникальность:
if (!pproto::error::checkUnique())
{
stopProgram();
return 1;
}Пример использования:
db::firebird::Driver::Ptr dbcon = dbpool().connect();
Transaction::Ptr transact = dbcon->createTransact();
QSqlQuery q {db::firebird::createResult(transact)};
Message::Ptr answer = message->cloneForAnswer();
if (!transact->begin())
{
writeToJsonMessage(error::begin_transaction, answer);
webCon().send(answer); // Отправляем ответ клиенту с информацией об ошибке
return;
}Публичный интерфейс команд
Протокол PProto первоначально был ориентирован только на работу в рамках языка C++. Поэтому базовое представление команд и структур данных выполняется в C++ нотации. В демонстрационном проекте есть файл commands.h , он является простейшим примером командного интерфейса. С появлением json-сериализации стало возможно взаимодействие с другими языками, в частности это Java (библиотека pproto-java) и Python (библиотека pproto_py).
Описание команды в Java представлении:
// Класс описывающий запрос к серверу
class ExampleCommand {
public String name;
}
// Класс описывающий ответ от сервера
class ExampleAnswer {
public String greeting;
}
interface ExampleService {
@Command(id = "38fc19b9-b8af-4693-a7c1-12bd6e08186a")
ExampleAnswer hello(ExampleCommand command);
}Команда в Python:
from pproto_py import REGISTRY_COMMAND
ExampleCommand = "ExampleCommand"
EXAMPLECOMMAND = REGISTRY_COMMAND(ExampleCommand, "38fc19b9-b8af-4693-a7c1-12bd6e08186a")Эта же команда в C++ :
extern const QUuidEx ExampleCommand;
REGISTRY_COMMAND_SINGLPROC(ExampleCommand, "38fc19b9-b8af-4693-a7c1-12bd6e08186a")
struct ExampleCommand : Data<&command::ExampleCommand,
Message::Type::Command,
Message::Type::Answer>
{
QString name;
J_SERIALIZE_ONE( name )
};Механизмы доставки
Доставка сообщений может осуществляться через tcp, udp и локальные сокеты. Реализация выполнена с использованием QTcpSocket, QUdpSocket и QLocalSocket, это гарантирует функционирование механизма на любой ОС, поддерживаемой Qt. Сокеты работают в синхронном режиме, что подразумевает создание отдельного потока исполнения для каждого соединения. Tcp сокет применяется наиболее часто, поэтому в следующих разделах речь пойдет именно о нем. Udp сокет используется ограниченно, как правило, для исследования локальной и vpn сетей на предмет нахождения в них элементов (микросервисов) распределенного программного комплекса, чтобы в дальнейшем установить с этими элементами TCP соединение. Механизм передачи данных через локальный сокет задумывался как более быстрый вариант TCP сокета для локального хоста. Практика показала, что у локального сокета нет существенного преимущества перед TCP. Сейчас локальный сокет используется крайне редко, его поддержка осуществляется по остаточному принципу.
Порядок установки TCP соединения
После установки TCP соединения клиент отправляет на сокет сервера сигнатуру протокола. Сигнатура представляет собой uuid идентификатор в бинарном представлении (16 байт). Отправка сигнатуры преследует две цели:
Сигнализирует, что взаимодействие будет происходить в рамках протокола PProto;
Определяет формат сериализации сообщений.
Если сервер поддерживает сигнатуру - он отправляет клиенту тот же идентификатор сигнатуры в ответном сообщении. Если запрашиваемая сигнатура серверу неизвестна, клиенту будет отправлен нулевой uuid. Доступные форматы сериализации сообщений и их сигнатуры приведены в таблице:
Формат сериализации сообщений |
Сигнатура (строковое представление) |
|---|---|
QBinary |
"82c40273-4037-4f1b-a823-38123435b22f" |
Json |
"fea6b958-dafb-4f5c-b620-fe0aafbd47e2" |
QBinary (шифрование) |
"6ae8b2c0-4fac-4ac5-ac87-138e0bc33a39" |
Json (шифрование) |
"5980f24b-d518-4d38-b8dc-84e9f7aadaf3" |
Сервер ждет получения сигнатуры от клиента в течении 3-х секунд, клиент ожидает ответа от сервера 6 секунд. Если по истечении указанного времени сигнатуры не будут получены, TCP соединение будет разорвано. В случае создания шифрованного соединения клиент дополнительно к сигнатуре протокола отправляет сессионный публичный ключ шифрования. Сервер в ответном сообщении предоставляет свой публичный сессионный ключ.
После того как сигнатура протокола подтверждена сервером, клиент и сервер отправляют друг другу первое сообщение с командой ProtocolCompatible. Команда выполняет два действия: 1) проверяет совместимость версий протокола для клиента и сервера; 2) запускает очередь обработки сообщений. Если ProtocolCompatible не будет отправлена, механизм не сможет корректно работать, никакие другие команды, кроме CloseConnection, не будут обрабатываться.
Порядок передачи сообщений через TCP сокет
Любое сообщение, независимо от формата сериализации, передается в TCP сокет в бинарном виде. Чтобы сообщение можно было прочитать на принимающей стороне, нужно знать его длину. Поэтому сначала в сокет записывается длина сообщения, и только потом тело. Поле для записи длины занимает 4 байта (тип int32), порядок big-endian.
При отправке сообщения в TCP сокет оно опционально (зависит от настроек соединения) может быть сжато zip-алгоритмом. Признак сжатия передается в знаковом бите поля длины. Если принимающая сторона "видит", что длина сообщения отрицательна, это означает, что полученное сообщение нужно декомпрессировать. Данное правило не касается зашифрованных соединений. При шифровании необходимо минимизировать любые проявления, которые даже косвенно могли бы дать подсказки о передаваемых данных, поэтому признак сжатия находится внутри зашифрованного буфера данных.
Примечание: механизм сжатия на уровне TCP сокета по умолчанию отключен.
Версионирование протокола (концепт)
Технология версионировании структур данных (см. первую часть статьи) позволяет сохранять сквозную совместимость для элементов (микросервисов) распределенного программного комплекса. Предположим, что со временем наиболее старые элементы системы будут работать не так эффективно, как хотелось бы, в связи с чем возникает потребность исключать их из рабочего процесса. Задача решается введением диапазона (коридора) допустимых версий для каждого элемента программного комплекса. На рисунке ниже представлен Клиент с диапазоном версий 0-4 и Сервер с диапазоном 3-8. Пока диапазоны Клиента и Сервера пересекаются, они считаются совместимыми. Теперь представим, что выпущено обновление для Сервера и коридор его версий стал 5-8. Клиент с диапазоном 0-4 уже не сможет подключиться к обновленному Серверу. Проверка пересечения диапазонов выполняется командой ProtocolCompatible. Если диапазоны не пересекаются, Клиент или Сервер (зависит от того, кто из них раньше выполнит проверку) отправляет команду CloseConnection. Диапазон версий задается в процессе сборки проекта при помощи макросов PPROTO_VERSION_LOW, PPROTO_VERSION_HIGH.
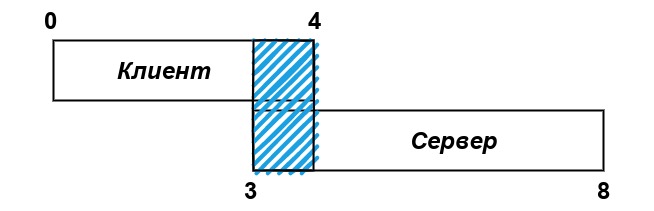
Версионирование протокола было реализовано на самых ранних стадиях разработки PProto, но в реальных проектах еще не применялось, по этой причине механизм все ещё находится в статусе концепта.
Обработка сообщений
После того как "сырое" сообщение вычитано из TCP сокета, оно десериализуется в C++ структуру Message. Далее сообщение рассылается в функции-обработчики при помощи Qt-механизма сигнал/слот. В примере TDemo 02 представлены два таких обработчика: clientMessage() для клиента и serverMessage() для сервера (см. файл tdemo02_appl.cpp). Код функций достаточно прост:
void Application::clientMessage(const pproto::Message::Ptr& message)
{
// Обрабатываем команду TDemo02_01
if (message->command() == command::TDemo02_01)
{
...
}
// Обрабатываем команду TDemo02_02
else if (message->command() == command::TDemo02_02)
{
...
}
// Обрабатываем команду TDemo02_03
else if (message->command() == command::TDemo02_03)
{
...
}
...
}Опытные разработчики, наверное, уже обратили внимание, что функции-обработчики достаточно объемные, при этом они охватывают всего шесть команд. Очевидно, что с ростом числа команд обработчики превратятся в плохо управляемых кодовых "монстров". В реальных проектах количество команд исчисляется десятками, иногда сотнями. Выходом из ситуации будет создание отдельной субфункции для каждой команды. Можно сделать еще один шаг: связать субфункцию и идентификатор команды, полученную пару поместить в список. В TDemo 03 представлена реализация описанной идеи. Связь субфункции с командой выполняется при помощи класса FunctionInvoker. Пример использования приведен ниже:
//--- TDemo 03 ---
class Application : public QCoreApplication
{
public:
Application(int& argc, char** argv);
public slots:
void message(const pproto::Message::Ptr&);
private:
//--- Обработчики команд ---
void command_TDemo03_01(const Message::Ptr&);
void command_TDemo03_02(const Message::Ptr&);
FunctionInvoker _funcInvoker;
};
Application::Application(int& argc, char** argv)
: QCoreApplication(argc, argv)
{
#define FUNC_REGISTRATION(COMMAND) \
_funcInvoker.registration(command:: COMMAND, &Application::command_##COMMAND, this);
FUNC_REGISTRATION(TDemo03_01)
FUNC_REGISTRATION(TDemo03_02)
#undef FUNC_REGISTRATION
}
void Application::message(const pproto::Message::Ptr& message)
{
// Не обрабатываем сообщение помеченное как "обработанное"
if (message->processed())
return;
if (lst::FindResult fr = _funcInvoker.findCommand(message->command()))
{
if (command::pool().commandIsSinglproc(message->command()))
message->markAsProcessed();
_funcInvoker.call(message, fr);
}
}
void Application::command_TDemo03_01(const Message::Ptr& message)
{
data::TDemo03_01 tdemo03_01;
readFromMessage(message, tdemo03_01);
log_debug_m << log_format("TDemo03_01 data: %?, %?",
tdemo03_01.value1, tdemo03_01.value2);
...
}
void Application::command_TDemo03_02(const Message::Ptr& message)
{
data::TDemo03_02 tdemo03_02;
readFromMessage(message, tdemo03_02);
log_debug_m << log_format("TDemo03_02 data: %?, %?",
tdemo03_02.value1, tdemo03_02.value2);
...
}В заключение рассмотрим условие из функции Application::message():
if (command::pool().commandIsSinglproc(message->command()))
message->markAsProcessed();Практика использования PProto показывает, что в 99% случаев команде требуется только один обработчик, но в программе могут присутствовать несколько Qt-слотов, принимающих сообщения. Функция Message::markAsProcessed() помечает сообщение как "обработанное". Таким образом, после того как сообщение попало в "свой" Qt-слот, остальные обработчики смогут его проигнорировать.
В ряде случаев необходимо доставить команду во все обработчики. Чтобы это стало возможным, у команды должен быть признак, определяющий то, как обрабатывать команду: в одном обработчике или во всех. Такой признак добавляется в пул команд в момент регистрации команды. Для удобства регистрации используются макросы REGISTRY_COMMAND_SINGLPROC, REGISTRY_COMMAND_MULTIPROC, см. файл commands.cpp в демонстрационном проекте.
#define REGISTRY_COMMAND_SINGLPROC(COMMAND, UUID) \
const QUuidEx COMMAND = command::Pool::Registry{UUID, #COMMAND, false};
#define REGISTRY_COMMAND_MULTIPROC(COMMAND, UUID) \
const QUuidEx COMMAND = command::Pool::Registry{UUID, #COMMAND, true};
REGISTRY_COMMAND_SINGLPROC(TDemo01, "76179ba9-c22d-4959-9c52-e853fbf52db0")
REGISTRY_COMMAND_SINGLPROC(TDemo02_01, "6eee6784-3472-4724-a2c0-6053a3010324")
REGISTRY_COMMAND_SINGLPROC(TDemo02_02, "6422f74e-73d1-43dc-b4aa-90312a850bc2")
...
#undef REGISTRY_COMMAND_SINGLPROC
#undef REGISTRY_COMMAND_MULTIPROCСинхронный/асинхронный режимы
Асинхронный режим обработки сообщений является основным для C++ версии протокола. Синхронный режим возможен, но программист должен реализовать его самостоятельно. На данный момент в PProto/C++ нет единого/унифицированного механизма для работы с синхронными сообщениями. Пример синхронной обработки команды TDemo05_SendChunk представлен в TDemo 05. В отличие от PProto/C++, библиотеки pproto-java и pproto_py функционируют только в синхронном режиме.
Приоритизация сообщений
О механизме приоритизации сообщений уже упоминалось в разделе Сообщение. Здесь хотелось бы сказать о том, где это может пригодиться. При передаче через TCP соединение большого объема данных некоторые команды могут приходить с ощутимыми задержками. Типичный пример - передача видеопотока на пользовательский терминал. Если все сообщения будут иметь одинаковый приоритет, управляющая команда на остановку видеопотока может выполняться с задержкой в несколько секунд. Понижение приоритета для сообщений, передающих видеоданные, решает эту проблему. Пример использования сообщения с низким приоритетом (команда TDemo05_SendChunk) можно посмотреть в TDemo 05.
Шифрование сообщений
Моя основная деятельность связана с созданием ПО под Linux. Как известно, в этой ОС нет проблем с организацией шифрованных сетевых соединений. По этой причине я избегал внедрения механизма шифрования в протокол PProto настолько, насколько это было возможно. Соображения были простые: зачем делать то, что уже хорошо сделано до тебя. Около года назад в разработку был взят пилотный проект с клиентской частью под Windows. Заказчик настаивал на полном шифровании передаваемых по сети данных. Предложение использовать известные средства защиты, например, VPN, было отклонено. Причина такого поведения оказалась банальна: нежелание разбираться с "непонятными" технологиями. Заказчику хотелось иметь все "из коробки". В итоге отказ сыграл положительную роль - в PProto появилось шифрование.
Ранее мне уже приходилось шифровать данные при помощи библиотеки libsodium, поэтому я решил пойти проторенной дорогой. Через две недели механизм был готов. Чтобы активировать шифрование в рабочем проекте, в него нужно добавить макроопределение SODIUM_ENCRYPTION и подключить libsodium-библиотеку. В демонстрационном проекте за активацию и подключение крипто-библиотеки отвечают переменные useSodium, useSystemSodium (см. файл pproto_demo_base.qbs). В примере TDemo 02 шифрование включится автоматически при наличии макроса SODIUM_ENCRYPTION.
void Application::clietnConnect()
{
_clientSocket->init({QHostAddress::LocalHost, 33021});
#ifdef SODIUM_ENCRYPTION
_clientSocket->setEncryption(true);
#endif
_clientSocket->connect();
}Конструктивный недостаток
В разделе "Механизмы доставки" говорилось о том, что TCP сокеты работаю в синхронном режиме и что каждое TCP соединение обрабатывается отдельным потоком исполнения. Собственно, это и есть конструктивный недостаток. С ростом числа соединений (речь идет о тысячах подключений) будет расти количество потоков выполнения, что может привести к чрезмерному потреблению ресурсов и к снижению производительности всей системы. Что можно сделать в этой ситуации? Были мысли перейти от схемы "один поток - одно подключение" к схеме "один поток - несколько подключений". Проблема заключается в том, что подобные изменения существенного усложнят механизм вычитки сообщений из Qt-сокетов, кроме того, придется отказаться от приоритизации сообщений. Механизм приоритизации может стать настолько сложным и неэффективным, что от него будет проще избавиться, чем поддерживать. Пойти на эту жертву я был не готов.
Вариант решения появился неожиданно: в одном из проектов потребовалось между Целевым сервисом и Клиентами разместить сервис-прослойку (Proxy сервис), см. рисунок ниже. Proxy выполняет переадресацию клиентских сообщений из одного VPN канала в другой в ситуации, когда использование механизма iptables затруднено. Положительный побочный эффект приведенной схемы состоит в том, что Proxy сервис берет на себя нагрузку, обусловленную большим количеством подключений/потоков, в то время как Целевой сервис, связанный с Proxy только одним TCP соединением, может беспрепятственно выполнять свои основные задачи. Сейчас аналогичный подход применяться в проектах с клиентским web-интерфейсом, только вместо Proxy используется Web-backend сервис.
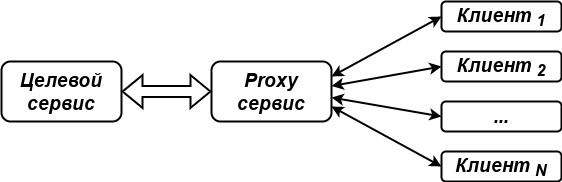
Готовя материал для статьи, я еще раз просмотрел информацию о допустимом количестве потоков в разных операционных системах. В моей текущей ОС (Ubuntu 20.04) теоретически можно создать более 200 тысяч потоков (см. cat /proc/sys/kernel/threads-max). В Windows число потоков регламентируется разрядностью системы и объемом оперативной памяти. Можно сказать, что запас есть, так что конструктивный недостаток еще поработает.
Где используется
На сегодняшний день PProto задействован практически во всех проектах компании "Точка зрения" (Tochka.AI). Среди сторонних разработок хотелось бы отметить систему АИС "Эксперт" (ссылка на новость). В ней протокол используется для взаимодействия целевого сервиса с web-интерфейсом пользователя, а также для получения данных из внешних источников. Еще один проект связан с обработкой изображений очень большого объема (десятки гигабайт) при помощи нейросетевых алгоритмов. В данном решении PProto используется для объединения мощных граф-станций в единую систему обработки информации. К сожалению, название проекта привести не могу, есть запрет на упоминание в публикациях.
Эксперименты с WEB
В последнее время у меня в разработке оказывается все больше проектов с web-составляющей. В основном это web-интерфейс, обеспечивающий дополнительный функционал, например, отображение справочно-отчетной информации. Как правило, такие проекты небольшие, поэтому возникает естественное желание минимизировать затраты на их разработку. Один из путей экономии заключается в упрощении и унификации Web-backend сервиса в цепочке:

В идеале хотелось бы получить механизм, передающий команды PProto напрямую в Web-клиент. Для экспериментов создан небольшой проект PProtoDemoWeb. Роль Web-backend выполняет простой Web-proxy сервис, транслирующий команды PProto в Web-клиент через WebSocket:

Сейчас эксперименты находятся в начальной стадии, тем не менее я с оптимизмом смотрю на будущее этого механизма.
Заключение
"От идеи до модели" путь бывает неблизкий, в моем случае он занял почти восемь лет. Долгое время это был безымянный механизм для внутреннего пользования. Имя протокол обрел пару лет назад, когда возникла необходимость в интеграции с внешними системами. Примерно в это же время стал актуален вопрос документации (подробные комментарии в исходном коде не в счет). Уже тогда у меня появилась мысль оформить описание протокола в виде статьи на Хабре с подкреплением примерами. Таким образом, можно изложить технические аспекты механизма и описать мотивы принятых решений и, конечно же, рассказать о протоколе большому кругу разработчиков. Возможность реализовать задуманное появилась только в конце прошлого года. Сейчас PProto является устоявшимся решением, проверенным не одним проектом, и в то же время протокол все еще развивается. Про proxy сервис и web эксперименты уже было сказано, также есть идеи по поддержке механизма разграничения прав пользователей. Как это будет реализовано, пока сказать сложно: поживем - увидим...