
Вместо предисловия
Решал я как-то задачку по поиску сущностей в отсканированных документах. Чтобы работать с текстом, надо его сначала получить из картинки, поэтому приходилось использовать OCR. Выбор пал на одну из самых популярных и доступных библиотек Tesseract. С ее помощью задача решается очень неплохо и процент распознавания текста достаточно высокий, особенно на хороших сканах. Но нет предела совершенству, а так же ввиду наличия большого количества документов сомнительного качества, по-улучшав пайплайн разными методами, было принято решение попробовать улучшить и сам тессеракт.
Инструкция от разработчиков https://tesseract-ocr.github.io/tessdoc/Home.html не всегда сразу понятна и очевидна, поэтому и появилась мысль записать свой опыт в эту статью.
У меня на компьютере стоит Linux Mint 20.2 Cinnamon, поэтому все действия происходят в этой системе и я не могу гарантировать, что все получится точно так же в Windows или Mac.
Для начала необходимо установить библиотеку tesseract на компьютер. Делается это достаточно просто. Сначала проверю версию, которая уже установлена (как правило в комплекте с Linux уже есть пакет tesseract). В терминале набираем
$ tesseract -vУ меня изначально был такой ответ:
tesseract 4.1.1
leptonica-1.79.0
libgif 5.1.9 : libjpeg 6b (libjpeg-turbo 2.0.6) : libpng 1.6.37 : libtiff 4.2.0 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.4.0
Found AVX
Found SSE
Found libarchive 3.4.3 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3
libzstd/1.4.8Перед установкой новой версии, необходимо удалить текущую:
$ sudo apt-get remove tesseract-ocrТеперь для начала делаем клон из репозитория Git:
$ git clone https://github.com/tesseract-ocr/tesseract.gitА затем необходимо выполнить по порядку несколько команд:
$ cd tesseract
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
$ sudo ldconfig
$ make training
$ sudo make training-installПерезапускаем терминал и проверяем версию:
$ tesseract -v
> tesseract 5.1.0-32-gf36c0
> leptonica-1.79.0
> libgif 5.1.9 : libjpeg 6b (libjpeg-turbo 2.0.6) : libpng 1.6.37 : libtiff 4.2.0 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.4.0
> Found AVX
> Found SSE4.1
> Found OpenMP 201511Осталось скачать языковые пакеты. Все не нужны, поэтому переходим по ссылке https://github.com/tesseract-ocr/tessdata и скачать только необходимые. Я скачивал eng.traineddata и rus.traineddata. В дальнейшем, при запуске тессеракт указывается флаг с каким языком необходимо работать, например: -l rus или -l eng , а можно комбинировать -l rus+eng. Скаченные данные необходимо поместить в папку: /usr/local/share/tessdata/
Теперь можно использовать библиотеку тессеракт с помощью командной строки в терминале, например:
$ tesseract image outputfile -l rus+engА теперь начнем файн-тюнить полученную модель. Этот процесс состоит из нескольких этапов:
Разметка тренировочных данных
Слепок текущей модели для начала дообучения
Непосредственно дообучение модели
Фиксация результатов
Для демонстрации я выбрал случайный документ, немного закрасил фамилии, чтоб не было разглашения личных данных.

1. Разметка тренировочных данных
Для создания разметки в тессеракте используются файлы с расширением .box и создаются они специальной командой:
$ tesseract testfile.png testfile --psm 6 -l rus+eng lstmboxгде lstmbox - как раз указывает на необходимость создания файла разметки, а --psm 6 указывает на способ создания боксов. Это построчный вариант, как правило самый часто используемый при обработке обычных текстов, про другие варианты можно почитать здесь запустив команду: $ tesseract --help-psm
На выходе получается файл testfile.box. На моем документе он выглядит так:
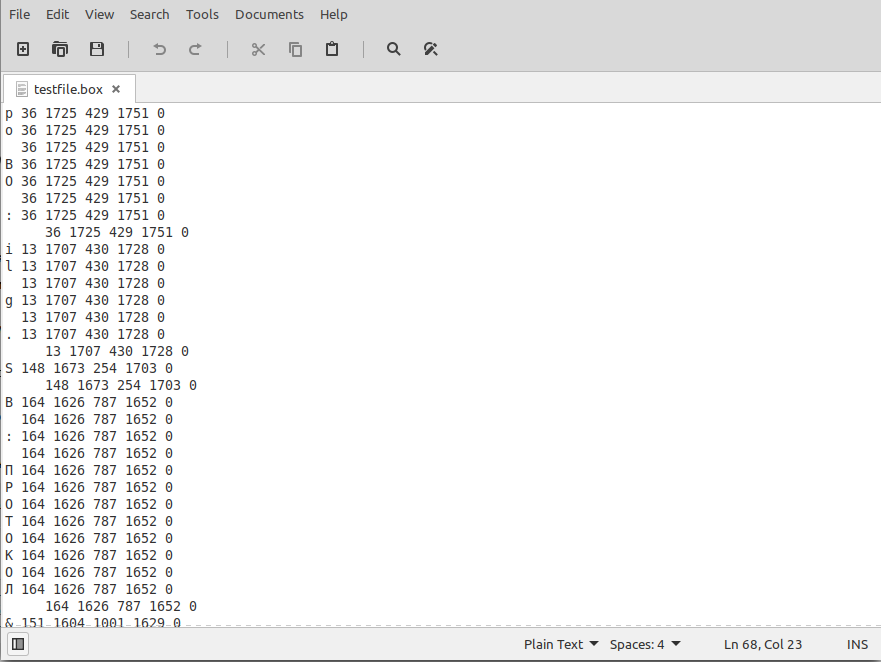
В файле с разметкой шесть столбцов. Разделитель пробел. Первый элемент - это непосредственно распознанный символ (или тоже пробел) затем через пробел указываются координаты бокса, в котором находится данный символ в виде x_min, y_min, x_max, y_max. Это если считать началом для ординаты левый нижний край картинки. Это немного отличается от привычных координат, когда ось ординат начинается с левого верхнего угла и опускается вниз, поэтому учитывайте этот момент. Что находится в шестом столбце я толком не нашел в документации, везде стоит 0, так и оставлял. Между боксами находится строка с теми же координатами, но у нее вместо символа и пробела в начале стоит символ табуляции /t
Самое сложное и долгое - это проверка файла разметки на правильность. Необходимо проверить все символы, правильно ли они распознались. А так же сверить верно ли модель определила боксы, не пропустила ли какие-то части текста. Я написал небольшой скрипт, который рисовал боксы из файла разметки на документе, чтобы увидеть "глазами" как это получается. Получилось вот так:

Видно, что тессеракт не совсем верно распознал где именно находится текст из-за плохого качества изображения. Так же отдельно собирается текст и проверяется правильность распознавания символов, удаляя мусорные знаки.
После того, как все файлы box будут готовы, необходимо сделать следующий шаг - преобразовать их в файлы lstmf. Именно их модель будет принимать на вход для обучения. Делается это с помощью следующей команды:
$ tesseract testfile.png testfile --psm 6 -l rus+eng lstm.trainгде testfile.png - это наш исходный документ и должен он быть именно в png или tiff формате, testfile - имя файла .box указывается без расширения, подготовленный ранее, затем --psm 6 - способ формирования боксов, -l rus - какую модель использовать и lstm.train - непосредственно метод преобразования данных. Это необходимо сделать с каждым документом и результат сложить в отдельную папку.
2. Слепок текущей модели для начала дообучения
Сначала извлекаем данные из текущей модели, которые будем использовать как предобученную модель. Запускаем:
$ combine_tessdata
-e /usr/local/share/tessdata/rus.traineddata
/home/andrey/Downloads/tesseract_train/rus.lstmЗдесь первым параметром я указывал полный путь к существующей модели, которую скачивал выше при установке тессеракта, а вторым параметром указан полный путь к слепку с расширением lstm, который будет использоваться в дальнейшем.
По тем инструкциям, что я нашел, данного шага должно быть достаточно, чтобы переходить к третьему этапу, но мне пришлось выполнить еще несколько команд, прежде, чем получилось идти дальше.
Итак, еще необходимо подготовить справочник символов, которые используются в файлах обучения. Команда собирает эти данные в файл, указанный флагом --output_unicharset из файлов указанных в конце, в моем случае это все *.box файлы из размеченных документов:
$ unicharset_extractor
--output_unicharset train/my.unicharset
--norm_mode 2 docs/*.boxТеперь генерируется начальная модель на основе всех имеющихся моих данных, символов, которые встречаются в моих документах, а так же дополнительных справочниках по словам и цифрам.
$ combine_lang_model
--input_unicharset train/my.unicharset
--script_dir /home/andrey/langdata_lstm/
--words /home/andrey/langdata_lstm/rus/rus.wordlist
--numbers /home/andrey/langdata_lstm/rus/rus.numbers
--puncs /home/andrey/langdata_lstm/rus/rus.punc
--output_dir train/ --lang rusФайлы, указанные в папке langdata_lstm я скачал с https://github.com/tesseract-ocr/langdata_lstm/tree/main/rus
3. Непосредственно дообучение модели
Осталось совсем немного и можно начинать тренировку. Команда для этого выглядит следующим образом:
$ lstmtraining
--model_output output/
--continue_from model/rus.lstm
--old_traineddata /usr/local/share/tessdata/rus.traineddata
--traineddata train/rus/rus.traineddata
--train_listfile train/rus.training_files.txt
--eval_listfile eval/rus.training_files.txt
--U train/my.unicharset
--max_iterations 140000--model_output output/ - папка куда сохраняется обученная модель (и чекпоинты)
--continue_from model/rus.lstm - подготовленная модель с помощью combine_tessdata
--old_traineddata /usr/local/share/tessdata/rus.traineddata - указание на родоначальную модель
--traineddata train/rus/rus.traineddata - здесь указывается модель, собранная командой combine_lang_model
--train_listfile train/rus.training_files.txt - файл со списком файлом lstm для тренировки модели
--eval_listfile eval/rus.training_files.txt - файл со списком файлов lstm для валидации модели
--U train/my.unicharset - указатель на приготовленный файл с используемыми символами
--max_iterations 500 - количество итераций
Я делал отдельный баш скрипт с перечнем всех указанных параметров и запускал его с сохранением логов в обычный текстовый файл, чтобы можно было затем посмотреть результаты. На самом деле там не очень все интересно и я сам не до конца разобрался во всех сообщениях в процессе обучения, кроме явных параметров, как здесь:
2 Percent improvement time=82, best error was 100 @ 0
At iteration 82/100/105, Mean rms=1.658%, delta=9.201%,
char train=27.571%, word train=35.266%, skip ratio=5%,
New best char error = 27.571 wrote best model:output/27.571_82.checkpoint wrote checkpoint.В папке output в результате обучения у меня появилось некоторое количество файлов:
4. Фиксация результатов
Каждый указанный выше чекпоинт - это по существу дообученная модель, показывающая указанную в наименовании ошибку. Теперь надо зафиксировать результат, чтобы эту модель можно было использовать. Делается это достаточно легко:
$ lstmtraining
--stop_training
--continue_from output/24.791_426.checkpoint
--traineddata train/rus/rus.traineddata
--model_output output/rus_ftuned.traineddata--stop_training - флаг указывает на завершение обучения
--continue_from output/24.791_426.checkpoint - указываю файл чекпоинта, который хочу использовать
--traineddata train/rus/rus.traineddata - ранее подготовленная модель
--model_output output/rus_ftuned.traineddata - куда сохранить результат
Я назвал свою дообученную модель rus_ftuned.traineddata. Теперь этот файл необходимо поместить к остальным языковым моделям тессеракта в папку /usr/local/share/tessdata/ , после чего ее можно использовать точно так же, как и любые другие, а так же в комбинации в другими языками. Например вот так:
$ tesseract image outputfile -l rus_ftuned+engЗаключение
Для обучения модели у меня было 40 размеченных страниц документов - картинок. Всего ставил 140 тыс. итераций тренировки. Ошибка при этом опустилась с 27.571 до 3.832. На тестовых документах стало меньше мусорных символов. Качество распознавания улучшилось, но незначительно. При подсчете расстояния Левинштейна между референсным текстом и распознанным тессерактом, значение уменьшилось в среднем на 3% относительно длины текста. Цифра вроде небольшая, но чем больше текст, тем больше правильно распознанных букв и цифр. Так, например, на тексте из 3363 символов, начальная модель ошибалась в 296, а дообученная всего в 203.
В заключении хочу сказать, что дообучение тессеракта под определенные типы документов имеет право на жизнь. Самое главное и в то же время самое сложное - это ответственно подходить к разметке. Я этим не занимался, я получил файлы уже размеченные, но при беглом осмотре я находил небольшие ошибки и в размерах боксов и в символах. Вероятно, если их исправить, то качество могло быть еще лучше.
Возможно, мой опыт кому-то пригодится. А если кто-то тоже уже занимался тренировкой тессеракта и заметил неточности, то буду благодарен если укажете.
Комментарии (5)


ShashkovS
02.06.2022 11:32Мне когда-то нужно было регулярно распознавать очень конкретные бумажки: каждый раз там был один и тот же шрифт и очень похожие по сути тексты (списки ФИО на самом деле).
Обучал тессеракт на этом шрифте долго и упорно, но результат был всё равно отстойный.
По сравнению с тем распознаванием, который выдавал API от ABBYY.
В общем задачу пришло по-другому решать, через распознавание русского текста не сработало (у ABBYY тоже хватало ошибок, поэтому подход пришлось отклонить)
ArXen42
Несколько лет назад пробовал дообучить тессеракт на распознание довольно специфичного текста, результаты не порадовали. У меня очень базовое понимание всей этой области, но возникло ощущение, что тессеракт остановился в своём развитии много лет назад и лучше использовать что-то более современное.
Непосредственно распознавание текстовых строк производится их самописной нейронной сетью, основанной на
LSTMячейках. Как я понимаю, это всё было очень круто для своего времени (они это реализовали еще до появленияTensorflow,согласно документации), но сильно устарело по сегодняшним меркам. Нет поддержки GPU, устаревшая архитектура (предполагаю, чтоGRUили вообще популярные сейчас трансформеры на современныхtensorflow/pytorchнамного обойдут самописнуюLSTMсеть в тессеракте и по точности и по скорости), сложности с обучением из-за привязки к их скриптам/форматам обучающих данных/C++ коду (т.е. даже напримерtensorboardдля более глубокого отслеживания процесса уже не привязать).Нахождение текста на фото делается классическими алгоритмами CV, которые не очень хорошо работают в сложных условиях. Насколько я помню, по-быстрому прикрученная к проекту модель Advanced EAST (примитивная по сегодняшним меркам) дала намного более качественный поиск текста без необходимости мучиться с бинаризацией и прочим препроцессингом, чем встроенная в сам тессеракт. Менее актуально для обычных сканов документов, чем для фотографий, наверное.
Насколько я вижу, сильно с тех пор в библиотеке ничего не поменялось, если бы понадобилось OCR сейчас - смотрел бы в сторону более современных инструментов, PaddleOCR например.
Modestovich Автор
Согласен, есть более интересные и гораздо современнее модели. По тестам они превосходят тессеракт в показателях. Хоть и не на много. Но тессеракт выигрывает своей простотой в использовании и быстрой настройкой. Буквально одна команда для установки и следующей командой можно пользоваться.
Хотя, если б стояла задача сделать полноценный пайплайн по OCR с нуля, то я выбрал бы для этого TrOCR или PaddleOCR.
PereslavlFoto
Только если надо распознать весь кадр. Если же надо распознать лишь два столбца из средней части кадра, тогда возникает вопрос, как же обозначить границы распознавания.