
На платформе ODS.ai прошло соревнование по машинному обучению Data Fusion Contest 2022 от банка ВТБ.
Мы, команда Лаборатории ИИ Сбера и Института искусственного интеллекта AIRI, приняли решение поучаствовать в контесте, когда увидели, что тема соревнования сильно пересекалась с нашими исследованиями. Мы заняли первое место на private leaderboard в основной задаче Matching. Здесь я хотел бы описать решение, которое у нас получилось.
В рамках соревнования предлагались: датасет, содержащий транзакции, совершенные клиентами ВТБ по банковским картам, кликстрим (данные о посещении web-страниц) клиентов Ростелекома и разметка соответствия между клиентами из этих двух организаций. Соответствие устанавливается если два клиента – это один и тот же человек. Все данные были обезличены, а сами датасеты синтезированы на основе реальных данных таким образом, чтобы сохранить информацию о поведении пользователей.
В программу мероприятия входило пять задач разной сложности с разным призовым фондом. Мы решили сосредоточится на главной задаче Matching, как на самой сложной и самой интересной.
Про задачу
В задаче необходимо было сделать решение, которое бы устанавливало соответствие между клиентами ВТБ и Ростелекома. В качестве ответа необходимо было для каждого клиента банка предоставить 100 наиболее вероятных клиентов Ростелекома. Оценка велась как для ранжирования, то есть, чем ближе правильный ответ был к началу списка, тем выше была оценка. Также в данных были случаи, когда для клиента ВТБ пары не находилось. Для таких клиентов в ответе нужно было выставить нулевой идентификатор пары (rtk_id=0).
Это было контейнерное соревнование: нужно было отправить код, который бы вычислял ответ для новых входных данных из тестового датасета, не использовавшихся при подготовке модели. Вследствие этого, требования к качеству кода были такими, что код должен корректно работать не только "на моем компьютере", а везде. Ресурсы контейнера были ограничены: на вычисления отводилось не больше часа, что требовало достаточной производительности от решения.
У нас уже был довольно большой опыт работы с событийными данными. Мы одними из первых предложили метод для контрастного обучения на неразмеченных транзакциях. Мы выложили в открытый доступ библиотеку PyTorch-Lifestream для построения нейронных сетей для событийных данных. Но задача матчинга была для нас новой из-за необходимости одновременно работать с двумя разными доменами с событийными данными (транзакции и кликстрим).
Основной метрикой соревнования был R1, среднее гармоническое между Precision@100 и MRR@100. Precision равнялся 1 если правильный ответ попадал в top100 и 0, если не попадал. MRR (Mean Reciprocal Rank) равнялся "1 / position", где "position" – это позиция правильного ответа среди предложенных 100 кандидатов. То есть MRR = 1 если правильный ответ на первой позиции, 0.5 если на второй, 0.33 на третьей и 0.01 – если на последней. Если правильного ответа нет среди top100, то MRR = 0. Метрики усреднялись по всем клиентам. R1 считался по финальному среднему.
Локальная валидация
Поскольку метрика считалась на top100, выбранных среди 3000 клиентов, нам необходимо было выбрать аналогичное количество клиентов для нашей собственной валидации. Действительно, гораздо легче получить правильный ответ, выбирая 100 кандидатов из 200, чем 100 из 3000. В данных было 17581 размеченных пар. Мы решили разбить данные на 6 фолдов по 2930 пар в каждом, что примерно соответствовало размеру public-private датасетов. Мы делали стратифицированное разбиение на основе длин последовательностей. Интуитивно кажется, что это позволило получить более сбалансированные фолды. А еще, это позволило поровну поделить клиентов без данных о сайтах, поскольку у них длина кликстрима равна 0, а разбиение стремится равномерно разложить эту группу по всем фолдам.
Про данные
Всего в датасете было 15.4 млн транзакций для 17581 уникальных клиентов ВТБ и 94.8 млн событий кликстрима для 14671 уникальных клиентов Ростелекома. Итого, примерно 16.6% клиентов ВТБ были без матчинга. Еще были неразмеченные данные в виде 4952 клиентов ВТБ с 4.4 млн транзакций и столько же клиентов Ростелекома с 32.0 млн кликов. Неразмеченные данные хранились отдельно, мы их не включали ни в какой из фолдов.
Вот так выглядели сами данные.
Матчинг:

Здесь все просто, в строке прописано соответствие id банка и телекома. Там, где соответствия нет, указан 0.
Транзакции:

Здесь кроме id-клиента есть mcc код и два поля с его текстовым описанием, код валюты с расшифровкой, сумма транзакции (как с плюсом, так и с минусом) и дата-время транзакции.
Кликстрим:

Здесь кроме id клиента была указана категория страницы и три уровня иерархии с меньшей детализацией, дата-время клика и идентификатор устройства, с которого посещалась страница.
Базовое решение
Организаторами соревнования был предложен baseline, в котором в качестве фичей считались простые статистики (sum, mean, count) по сумме транзакции или количеству кликов в разрезе каждого mcc кода или категории. Фичи для транзакций и кликов объединялись и подавались в алгоритм бустинга. Алгоритм учился как задача бинарной классификации, где правильным ответом был 1, если транзакции и кликстрим соответствуют одному человеку (есть матч), и 0, если разным. На каждого клиента ВТБ был доступен один правильный клиент Ростелекома (соответствие из разметки) и несколько случайно выбранных из всей выборки неправильных примеров. На public leaderboard бейзлайн показывал R1 = 0.2217.
У нас получилось улучшить бейзлайн до R1 = 0.2757, но основные усилия хотелось приложить именно к решению задачи с помощью нейронных сетей. В качестве примера подхода основанного на генерации признаков для бустинга доступен код решения, занявшего второе место в задаче Matching, опубликованный автором.
Схема нашего решения
Мы решили использовать схему обучения похожую на сиамскую сеть, которая будет кодировать входную последовательность транзакций или кликстрим в вектор. Цель обучения нейросети – добиться, чтобы эти векторы, располагаясь в одном пространстве, были близкими по какой-либо метрике, если они принадлежат одному человеку, и далекими, если разным людям. То есть, вероятность матчинга объектов будет определяться расстоянием между их векторами. Такая схема часто применяется для установления соответствия между данными из разных доменов: например, картинок и подписей к ним. Была гипотеза, что этот подход сработает и для событийных данных разных типов. Тем более, что наши предыдущие исследования подтверждали, что методы, работающие для изображений, можно переложить на транзакционные данные. Вот схема обучения:

Между векторами клиентов ВТБ и Ростелекома считаются попарные расстояния и используется функция потерь, штрафующая за неправильные расстояния между парами. Во время применения обученной сети мы просто отбираем для каждого клиента ВТБ top 100 самых близких клиентов Ростелекома. Мы использовали контрастную функцию потерь (Contrastive Loss, он же NCELoss, QuerySoftMax, …). При ее применении, цель обучения – сделать расстояние между правильной парой меньшим, чем между случайно выбранной неправильной парой. Более подробно на схеме:

Выбирается Anchor - клиент ВТБ, для него выбирается позитивный пример – правильный клиент Ростелекома и некоторое количество негативных примеров, неправильные пары, случайно выбранные из батча. Все примеры собираются в один тензор размера (число клиентов X 1 + число негативных примеров). По нему мы можем рассчитать контрастную функцию потерь. Точная формула:
Здесь a - выходной вектор нейросети, sim - мера близости двух векторов. Мы использовали квадрат расстояния Евклида между векторами в качестве мера близости. Добавление температуры t позволяет нормализовать значения степеней экспоненты и избежать слишком больших значений.
Мы использовали батч по 128 клиентов, и, для каждого клиента генерировали два подмножества из его транзакций или кликстрима. В этом случае матрица попарных расстояний будет иметь размер 256x256. Чем больше негативных примеров мы используем, тем большую разрешающую способность имеет функция потерь. Чтобы попасть в top 100 из 3000, надо быть в top 1 из 30, top 2 из 60 или top 4 из 120. В рамках top 4 правильный клиент может двигаться к первой позиции более плавно, чем в рамках top 1. Можно было бы еще увеличить число негативов, но тогда необходимо было бы также увеличить размер батча, а на его размер есть два ограничения: в рамках датасета у нас становится мало батчей, а сами батчи растут так, что не помещаются в память GPU. С теоретической точки зрения не так важно, сколько негативных примеров используется при расчете функции потерь – если брать меньше негативных примеров, то увеличится время обучения сети для достижения такого же качества. На практике оказалось, что количество негативных примеров в этой задаче имеет значение для сходимости обучения к приемлемому качеству за разумное время.
В качестве Anchor мы сначала брали только клиентов ВТБ, то есть, шли по матрице слева направо. Потом добавили такую же процедуру для клиентов Ростелекома (сверху вниз по матрице). Это позволило немного поднять качество и получить более сбалансированную матрицу, в которой нет сильных перекосов по популярности отдельных клиентов Ростелекома.
Архитектура нейросети
Архитектура сети показана на схеме:

Основных компонентов два: кодировщик, который сжимает каждую отдельную транзакцию или событие кликстрима в вектор, и кодировщик, который сжимает последовательность полученных векторов в один – итоговый вектор, описывающий клиента целиком. В качестве последнего использовалась стандартная GRU RNN. Пробовали использовать здесь трансформер, но с ним качество получилось хуже. Поскольку финальные вектора находятся в одном векторном пространстве, возникла идея использовать общие веса для RNN слоя. Мы предполагали, что в этом случае общее векторное пространство будет также на входе в RNN, и что сеть сможет найти, например, похожие по смыслу mcc в транзакциях и категории в кликстриме. На практике оказалось, что вектора для транзакций и кликстрима получаются совсем разные, но это не мешает RNN с общими весами работать хорошо. В итоге использование общих весов позволило повысить качество, но немного не таким способом, как мы предполагали ранее.
В качестве кодировщика транзакций мы взяли готовый слой из нашей библиотеки TrxEncoder. Его работа показана на схеме:

Категориальные признаки подаются в embedding-слои. Числовые признаки нормируются и обрезаются выбросы. Результаты конкатенируются по всем признакам, и полученный вектор проходит через линейный слой, задача которого поменять размерность вектора. Это нужно для того, чтобы вектора для транзакций и кликстрима были одного размера, и можно было использовать RNN с общими весами.
Для того, чтобы подать данные в такой TrxEncoder, они специальным образом должны быть подготовлены. Нужно разбить транзакции на группы по клиентам, разделить колонки на отдельные вектора с признаками. Этот процесс показан на схеме:
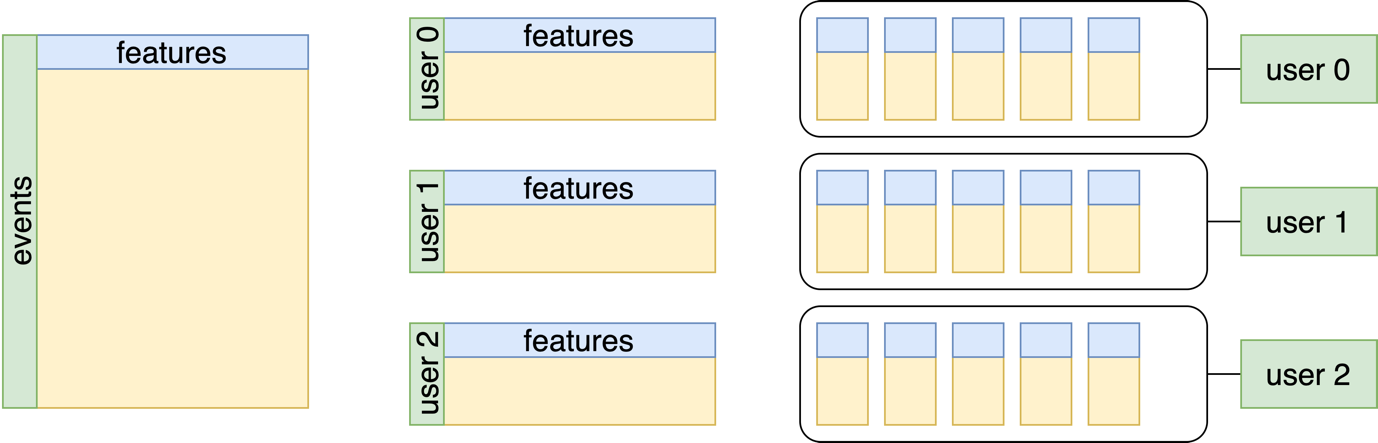
Еще надо перевести тип данных в torch.Tensor и закодировать категориальные переменные. Мы использовали частотное кодирование. Чем чаще встречается значение категории, тем меньше значение соответствующего ей кода. Это удобно тем, что можно быстро регулировать размер используемого словаря и выбрасывать редкие категории. Например, чтобы оставить только 100 самых частых категорий в словаре, можно сделать mcc_code.clamp(0, 100). Здесь все редкие категории, у которых код больше 100, будет объединены в одну.
Предобработка данных
Теперь немного о признаках, которые мы использовали. Важное достоинство нейросетевого подхода, в отличие от, например, бустинга, в том, что признаки можно подавать почти в сыром виде. Сеть сама может обучиться получать полезные для правильного ответа промежуточные представления данных. И все же подобная обработка помогает повысить качество, особенно, на небольшом датасете.
Вот какие признаки мы использовали для карточных транзакций:
Основной признак – это
mcc_code. Как и для остальных категориальных признаков, мы применили частотное кодирование. Мы использовали почти всеmccиз словаря, итого их получилось 350. Если брали меньше категорий, то итоговое качество падало.сurrency_rk– код валюты. Несмотря на то, что почти 99.8% значений приходятся на рубли, решили не выбрасывать остальные валюты (USD, EUR).transaction_amt– пробовали усложнить стандартный вариант, где поле просто нормируется. Разбили весь диапазон сумм на 100 бинов и закодировали сумму номером бина. Получился категориальный признак, для которого можно было обучить embedding-слой. Такой вариант позволяет более гибко строить признаки для суммы, сеть сможет выделить положительные, отрицательные, большие и маленькие диапазоны. Дополнительного прироста качества этот вариант разбиения не принес, но и хуже не стало. Этот признак мы оставили в финальном решении.transaction_dttm– во-первых, время использовалось для сортировки событий в хронологическом порядке. Во-вторых, из этого поля мы извлекли часы, минуты, секунды, день недели, номер дня в году, номер месяца. Больше всего пользы принесли часы: мы рассматривали номер часа как категориальный признак с обучаемым embedding-слоем для него, это дало большой прирост качества. Остальные признаки не помогли: минуты и секунды, вероятно, из-за слишком большой детализации; все, что относится к году, из-за того, что данных не так много, чтобы что-то выучить. Странно, но день недели тоже не дал прироста качества. Обычно какая-то недельная сезонность в данных присутствует.Пробовали использовать аналог позиционного эмбеддинга из трансформеров, переводили время в
timestampи считали от этого набор sin и cos с разной амплитудой и фазой. Получилось не лучше, чем было, и эти признаки не стали использовать.Наша RNN могла учитывать последовательность транзакций, но получала информации о расстоянии между ними по времени. Решили добавить признаки статистик вдоль временной оси: расстояние между соседними транзакциями в днях, количество транзакций в этот день, количество транзакций за последнюю неделю, считая от текущей транзакции. Из всего этого качество не падало только при использовании расстояния между транзакциями. Его мы оставили в финальном решении.
Для кликов использовали вот такие признаки:
Категории, их также, как и
mccвзяли почти все, в количестве 400 шт.Добавили все дополнительные иерархии
level_0–level_2. Если событие имеет одно значение level, но разные категории, то это будет учитываться. Будет видна и похожесть по level, и разница по категориям. Без этих уровней было чуть похуже, чем с ними.Для поля
timestampпосчитали те же временные признаки, что и для транзакций.Идентификатор устройства
new_uidтак и не смогли использовать. Считали количество уникальных id, в том числе и в разных временных окнах, пробовали делать отдельные последовательности для каждого устройства, пробовали закодировать устройство эмбеддингом по частоте его встречаемости у конкретного пользователя. Все это не сработало. Даже пробовали обучить отдельную сетку для кластеризации устройств. Сеть должна была посмотреть на всю последовательность кликов, и для каждого id выдать его класс. В итоге ответы сети схлопнулись, и для всех id предсказывался один и тот же класс.
Предобучение кодировщика транзакций с помощью Transfromer-модели
Можно заметить, что наряду с полезными признаками, мы добавили немного бесполезных, которые не повышали качество. Одна из причин, по которой это было сделано – предобучение кодировщика транзакций. Предполагалось, что во время предобучения сеть сформирует из мало полезных признаков какие-то их представления, которые потом сработают. Предобучение организовали по образу BERT. Использовалась промежуточная задача Masked Language Model. Отличие от NLP методов было в том, что мы маскировали и предсказывали не сам токен (транзакцию), а его вектор. Причина в том, что транзакция – сложный объект, и нет однозначного решения, как его маскировать и сравнивать потом с прогнозом. Вот схема предобучения:

Маскировались выходы TrxEncoder. Трансформер предсказывает значение вектора, которое было до маскирования. Используется уже упомянутый Contrastive Loss с негативными примерами. Негативные примеры нужны для того, чтобы сеть не смогла выучить тривиальное решение, например, все прогнозы делать нулями.
Предобучались TrxEncoder отдельно для транзакций и отдельно для кликов. Далее полученными весами инициировались соответствующие слои финальной модели и начиналось обучение под задачу матчинга. RNN слои при этом инициализировались случайными весами. Трансформер, который участвовал в предобучении, потом не использовался.
Аугментации
На всех этапах обучения сети мы использовали аугментации. Первая устраняла повторы в последовательностях. Повторяющиеся mcc или категории выбрасывались, а исходное количество транзакций записывалось в отдельное поля, как отдельный признак:

Это позволило сократить длины последовательностей, особенно для кликстрима, где встречались очень длинные цепочки повторяющихся категорий.
Вторая – вырезала часть из всей последовательности. Длина и место начала семпла выбиралось случайно.

Параметры семплирования были заданы так, что в обучение попадали и очень короткие последовательности (порядка 64 событий), и очень длинные (до 2000 событий, примерно половина всей последовательности). На коротких последовательностях сеть быстрее учится. На длинных получает больше информации.
Ансамблирование
В финальном варианте решения мы добавили использование ансамбля сетей. Несколько сетей учились с разными random seeds, каждая сеть выдавала матрицу попарных расстояний, а эти матрицы усреднялись по всем сетям ансамбля. В итоге это дало самый большой прирост качества, для ансамбля из пяти моделей R1 выросло с 0.2819 до 0.2949. Вот график зависимости качества от количества сетей в ансамбле:

В финальном решении мы смогли уместить 11 сетей, вычисление ответа для которых выполнялось почти за час. Можно было ускорить инференс и взять больше моделей в ансамбль, если бы мы вовремя заметили, что GPU в контейнер не подключилось. Позже мы делали точные замеры на локальной машине, и оказалось, что с GPU инференс с пятью моделями в ансамбле работает 2 минуты, из них полторы – это пребодработка данных.
Итоги
Полученное решение заняло второе место на public leaderboard и первое – на private. Полный код финального решения можно посмотреть по ссылке. Решение основано на нашей библиотеке для работы с событийными данными PyTorch-Lifestream.
Авторы текста: Иван Киреев и Дмитрий Бабаев