

Как часто вы, в очередной раз матерясь и grep'ая простыню текста, говорили себе, что вот-вот перестанете хранить логи в файлах и переедете на ELK?
Я - часто, а виной тому кажущаяся сложность настройки всей системы в целом.
Наверное, так оно и есть, но для того, чтобы складывать логи и искать по ним, как оказалось, много ума не нужно.
Дисклеймер: я не знаю всех тонкостей ELK стека и возможно данный сетап не подойдет для огромной компании с сотней проектов и террабайтами логов, но там и без этой статьи все знают. Судите строго, давайте советы мне и другим в комментариях - я буду только рад.
В данной статье мы:
Разберем компоненты ELK стека
Напишем docker compose конфиг для того, чтобы развернуть систему одной командой
Законфижим Filebeat и научим его собирать и отправлять логи
Рассмотрим интерфейс Kibana и научимся искать по логам
Настроим Kibana, разберемся с правами доступа
Поговорим об индексах, шаблонах и об автоудалении индексов (неактуальных логов)
Все это мы будем делать на примере python приложения, которое пишет некоторые логи.
Что такое ELK?
ELK - это (вдруг вы не знали):
Elasticsearch (хранение и поиск данных)
Logstash (конвеер для обработки, фильтрации и нормализации логов)
Kibana (интерфейс для удобного поиска и администрирования)
Все эти три компонента располагаются на вашем сервере.
На клиент (сервер с приложением, допустим) устанавливается Beat. Именно Beat шуршит в ваших логах на клиенте. Beat'ы бывают разные (найдете), но в рамках данной статьи нас интересует только Filebeat.
Как это все работает вместе?
Достаточно просто для восприятия, на самом деле:
Beat следит за изменениями логов (Filebeat следит за файлами) и пушит логи в Logstsash
Logstash фильтрует эти логи, производит с ними некоторые манипуляции и кладет их в нужный индекс Elasticsearch (таблицу в терминах привычных баз данных)
Kibana визуализирует эти логи и позволяет вам удобно искать нужные события

Если вы уже предвкушаете кучу конфигов в разных форматах и разбросанных по разным местам, то в следующей главе я постараюсь вас обрадовать - это так, но разобраться не сложно.
Как это все развернуть и не закопаться на каждом этапе?
Хоть ELK и выглядит достаточно монструозно, да только для наших нужд его можно быстренько приготовить за один вечер. Чем и займемся.
Для удобства разворачивания в одну команду напишем docker-compose файл со всеми сервисами, но для начала подготовим конфиги соответствующих сервисов:
configs/elasticsearch/config.yml
cluster.name: "elk"
network.host: 0.0.0.0 # Для корректной работы внутри контейнера
xpack.security.enabled: true # Для поддержки функционала, обеспечивающего безопасность кластера
xpack.license.self_generated.type: basic # Типа лицензии "basic" для наших нужд хватит с головойconfigs/logstash/config.yml
http.host: "0.0.0.0"configs/kibana/config.yml
server.name: kibana
server.host: 0.0.0.0
server.publicBaseUrl: "http://localhost:5601"
monitoring.ui.container.elasticsearch.enabled: true # Для корректного сбора метрик с elastic search, запущенного в контейнере
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
elasticsearch.username: elastic
elasticsearch.password: MyPw123docker-compose.yml
version: '3.7'
services:
elasticsearch:
image: elasticsearch:7.16.1
volumes:
- ./configs/elasticsearch/config.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro
- ./docker_volumes/elasticsearch/data:/usr/share/elasticsearch/data
environment:
ES_JAVA_OPTS: "-Xmx512m -Xms512m"
ELASTIC_USERNAME: "elastic"
ELASTIC_PASSWORD: "MyPw123"
discovery.type: single-node
networks:
- elk
ports:
- "9200:9200"
- "9300:9300"
logstash:
image: logstash:7.16.2
volumes:
- ./configs/logstash/config.yml:/usr/share/logstash/config/logstash.yml:ro
environment:
LS_JAVA_OPTS: "-Xmx512m -Xms512m"
ports:
- "5044:5044"
- "5000:5000"
- "9600:9600"
networks:
- elk
depends_on:
- elasticsearch
kibana:
image: kibana:7.16.1
depends_on:
- elasticsearch
volumes:
- ./configs/kibana/config.yml:/usr/share/kibana/config/kibana.yml:ro
networks:
- elk
ports:
- "5601:5601"
networks:
elk:
driver: bridgeПоднимаем все наше добро одной командой:
docker-compose upУбеждаемся, что мы можем попасть в kibana (в админку):
Переходим по адресу http://localhost:5601 и вводим логин/пароль из docker-compose.yml конфига (секция environment сервиса elasticsearch).
Сервисы стартуют долго. Kibana может смело стартовать 3-5 минут, так что не торопитесь лезть в конфиги и искать ошибки.
После того, как попали в админку - смело закрывайте ее. До нее мы еще доберемся.
Настройка Logstash для сохранения логов в Elasticsearch
Напомню, что схема сбора логов выглядит так: файл c логами приложения <- filebeat -> logstash -> kibana.
Подготовим конфиги:
configs/logstash/pipelines.yml
- pipeline.id: service_stamped_json_logs
pipeline.workers: 1
pipeline.batch.size: 1
path.config: "/usr/share/logstash/config/pipelines/service_stamped_json_logs.conf"Мы будем собирать логи в формате json с указанием сервиса - отсюда и такое название. Дальше станет яснее.
Если ваши логи не в json (а скорее всего так и есть), то можно привести их в json формат (имхо, так удобнее, но кто я такой, чтобы говорить "как надо") или изучить logstash немножечко глубже и погуглить "logstash logs parsing"- там тоже ничего сложного.
configs/logstash/pipelines/service_stamped_json_logs.conf
# Логи будут прилетать из beats'ов по порту 5044
input {
beats {
port => 5044
}
}
filter {
# Дропаем лог, если он пришел от неизвестного нам сервиса (по желанию)
# Ниже я два раза указал host_metrics_app в списке - это не опечатка. Какого-то лешего в условии, в массиве должно быть минимум 2 элемента.
# Так как приложение у нас одно - просто дублируем
# Поле service у нас появится благодаря конфигурированию Filebeat
if [fields][service] not in ["host_metrics_app", "host_metrics_app"] {
drop {}
}
# Оригинальный json-лог, который был сгенерирован вашим приложением, будет лежать по ключу message
# (из filebeat'а логи прилетают не в чистом виде)
json {
source => "message"
}
# Говорим logstash'у, чтобы в качестве timestamp'а лога он брал именно наш timestamp
# (в моем случае поле asctime в теле сообщения в формате "yyyy-MM-dd HH:mm:ss.SSS" и часовом поясе UTC)
# и затем подтирал поле asctime.
date {
match => ["asctime", "yyyy-MM-dd HH:mm:ss.SSS"]
timezone => "UTC"
target => "@timestamp"
remove_field => ["asctime"]
}
}
output {
# Отображаем лог в stdout (поиграйтесь и удалите данную строку)
stdout {}
# Пушим лог в elasticsearch, индекс будет создан автоматически по названию сервиса и текущей дате
elasticsearch {
hosts => "elasticsearch:9200"
index => "logs_%{[fields][service]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "MyPw123"
}
}Заранее подготовим конфиг для Filebeat. Его вы, скорее всего, захотите запускать вне докера, на хосте с приложением (но для экспериментов в рамках данной статьи запустим так же в докере):
configs/filebeat/config.yml
filebeat.inputs:
- type: log
enabled: true
# Я запущу filebeat в докере и проброшу логи приложения по данному пути
paths:
- /host_metrics_app/host_metrics_app.log
# В fields мы можем указать дополнительные поля, а затем в logstash вытаскивать их
# и делать какую-нибудь дополнительную работу с логами
fields:
# Название нашего сервиса
service: host_metrics_app
output.logstash:
# Будьте внимательны при запуске вне докера и вместо logstash укажите правильный адрес хоста с logstash.
hosts: ["logstash:5044"]Обновим наш docker-compose конфиг. Секцию volumes сервиса logstash заменим на:
volumes:
- ./configs/logstash/config.yml:/usr/share/logstash/config/logstash.yml:ro
- ./configs/logstash/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./configs/logstash/pipelines:/usr/share/logstash/config/pipelines:roДобавим сервис filebeat (еще раз: Filebeat скорее всего будет на ваших серверах с приложениями, а в данном конфиге он только для демонстрации):
beats:
image: elastic/filebeat:7.16.2
volumes:
- ./configs/filebeat/config.yml:/usr/share/filebeat/filebeat.yml:ro
- ./host_metrics_app/:/host_metrics_app/:ro
networks:
- elk
depends_on:
- elasticsearchСобираем логи и наблюдаем их в Kibana
Для демонстрации я напишу простое python приложение, которое лишь собирает некоторые метрики хоста и складывает в лог-файл в формате json.
host_mertics_app/main.py
import datetime
import json
import os
from time import sleep
import psutil
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
while True:
load1, load5, load15 = psutil.getloadavg()
ram_usage_percent = psutil.virtual_memory().percent
log = {
'load_avg': {
'load1': load1,
'load5': load5,
'load15': load15,
},
'ram_usage_percent': ram_usage_percent,
'asctime': datetime.datetime.utcnow().isoformat(timespec='milliseconds', sep=' ')
}
with open(os.path.join(BASE_DIR, 'host_metrics_app.log'), 'a') as f:
f.write(json.dumps(log) + '\n')
sleep(7)Запустим наше приложение и ELK стек (с Filebeat'ом):
python host_metrics_app/main.py
docker-compose.ymlРазбираемся с Kibana, видим логи и ищем по ним
Logstash мы сконфигурировали таким образом, чтобы каждый день он автоматически создавал новый индекс для логов нашего приложения. В дальнейшем мы будем использовать это для того, чтобы, например, удалять логи старше недели.
Сейчас же нам нужно настроить Kibana так, чтобы она думала, что все эти индексы - одна большая таблица с логами.
Ищем в меню: Management -> Stack Management -> Index patterns. Создаем новый index pattern "logs_host_metrics_app*" (похоже на регулярочку, да)?
Полезные скриншоты

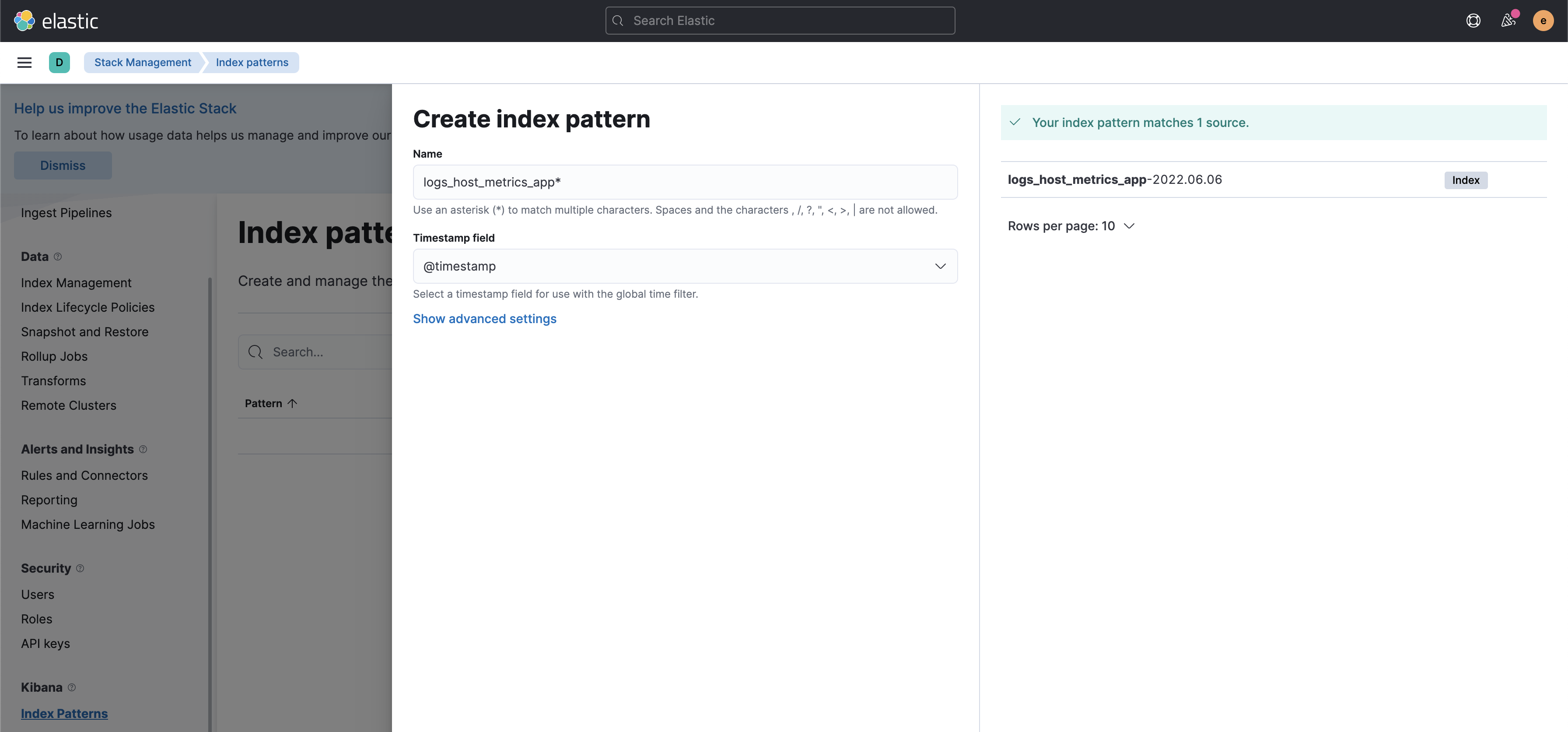
Ура, можем смотреть и искать по нашим логам. В меню ищем Analytics -> Discover. Тыкаемся во все, что попадется и радуемся! Ниже скрин с короткой справкой по интерфейсу.
Короткая справка по интерфейсу

На этом можно было бы закончить, ведь целью статьи было показать, как максимально быстро попробовать ELK, но давайте я все-таки попробую рассказать об интересных и полезных фишках.
Read Only пользователь
Рассказывать зачем нужен read only пользователь не буду - сами знаете. Делается так: идете в Management -> Stack Management -> Users и создаете нового пользователя с ролью viewer - данный пользователь будет видеть все индексы, все настройки, но не сможет ничего поменять/наломать.
Кстати, там же будут пользователи logstash_system, beats_system и т.п. Считается, что использовать пользователя elasticsearch в конфигах сервисов не совсем правильно. Можете задать им пароли и обновить конфиги. Я не буду.
Скорее всего, следом вам будет нужен пользователь с доступом только к определенному индекс-паттерну и максимально урезанный по функционалу. Делается так: идете в Management -> Stack Management -> Roles и создаете новую роль. В пункте "Elasticsearch" указываете только indices с privileges "read", а в пункте "Kibana" создаете новый набор привилегий для space default с кастомным набором доступным опций - для read only пользователя в большинстве случаев хватит только Analytics > Discover.
Скриншоты
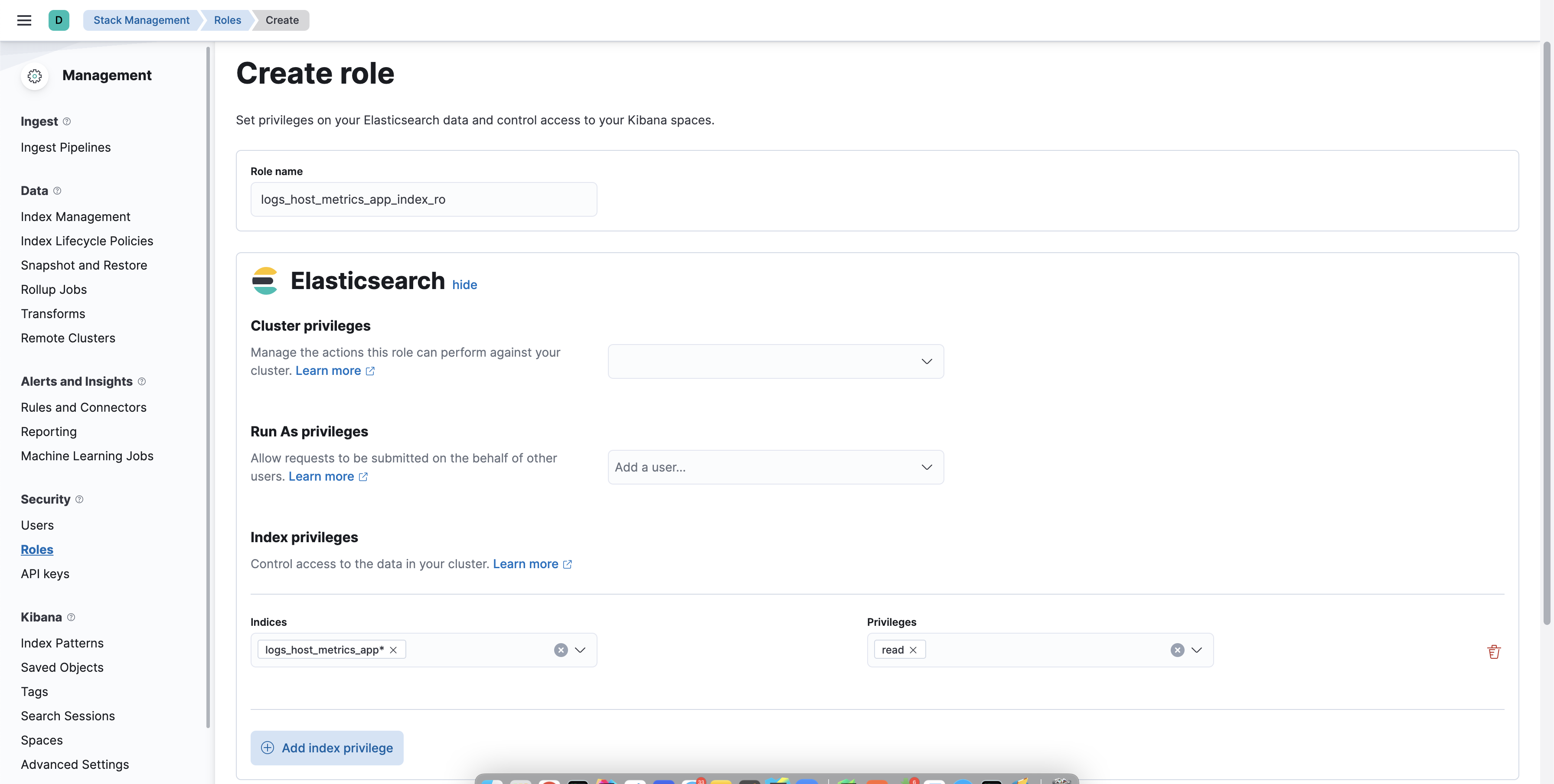


Дальше все просто - создаете нового пользователя с только что созданной ролью и получаете максимально урезанного по возможностям пользователя.
Выглядит так

Автоматически подтираем мусор и разбираемся с шаблонами индексов
Сейчас разберемся, как автоматически подтирать старые логи. Да, можно написать простенький скрипт или использовать curator, но зачем, если есть инструмент из коробки?
Для начала создаем политику жизненного цикла индекса (Index Lifecycle Policy): идем в Stack Management > Index Lifecycle Management и создаем политику. Ничего сложного - обзываем, например, 7-days, игнорируем стадии warm и cold и настраиваем автоматическое удаление через 7 дней.
Примечание: ELK требуется около 10 минут для проверки и запуска этапов жизненного цикла. Например, если вы настроили автоматическое удаление через 1 минуту (тестируете функционал, например), то проверка состояния и инициация удаления могут занять 10 минут (иногда чуть больше).
Скриншот

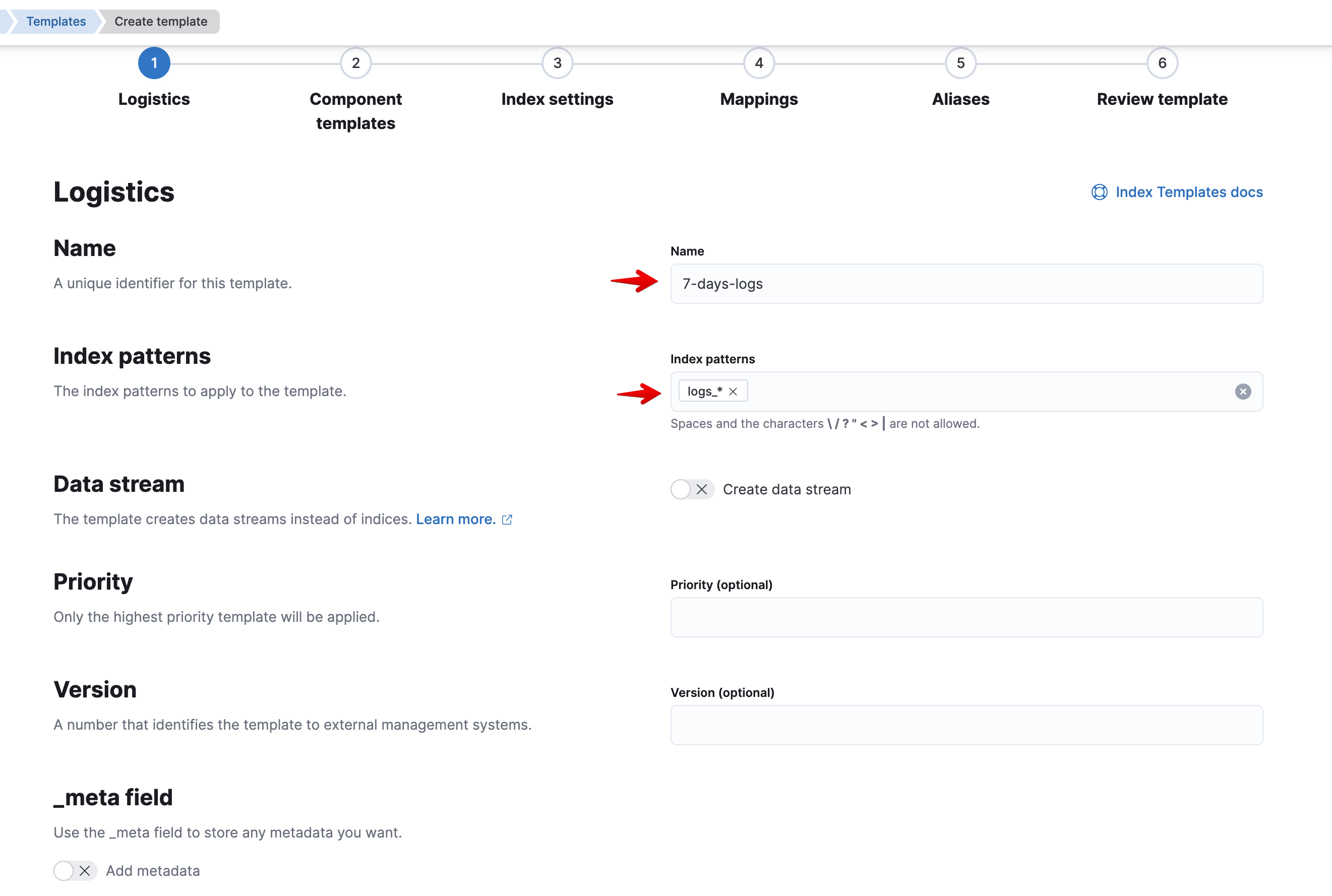
Теперь создадим шаблон для наших будущих индексов. По своей сути шаблон - это набор настроек, который будет автоматически применяться при создании индекса. Наверное, вы догадались, что применяться настройки будут к индексу, у которого название совпадает по маске, заданной в настройках шаблона (аналогично index-паттерну). Далее, все индексы соответствующие паттерну, указанному в шаблоне, будут создаваться с указанными в шаблоне настройками и политиками (повторение - мать учения).
Кстати, в шаблоне можно явно задать тип поля. Иногда это бывает полезно. Например, для IP адресов: указав явно, что поле - это IP можно будет дополнительно оперировать масками и сетями. Советую немного углубиться в эту тему, но сейчас не об этом.
Создаем шаблон: Stack Management > Index Management > Таб Index Templates. Кликаем на "Create Template", указываем название шаблона, index-паттерны, указываем настройку в Index Settings и при необходимости указываем типы полей явно. Если вдруг что-то не ясно - ниже скрины.
Настройка:
{
"index.lifecycle.name": "{название созданной политики}"
}Скриншоты


Теперь новые индексы logs_* будут создаваться на основе нашего шаблона. Убедиться в этом мы сможем в том же Stack Management > Index Management (см. скриншот).
Скриншот
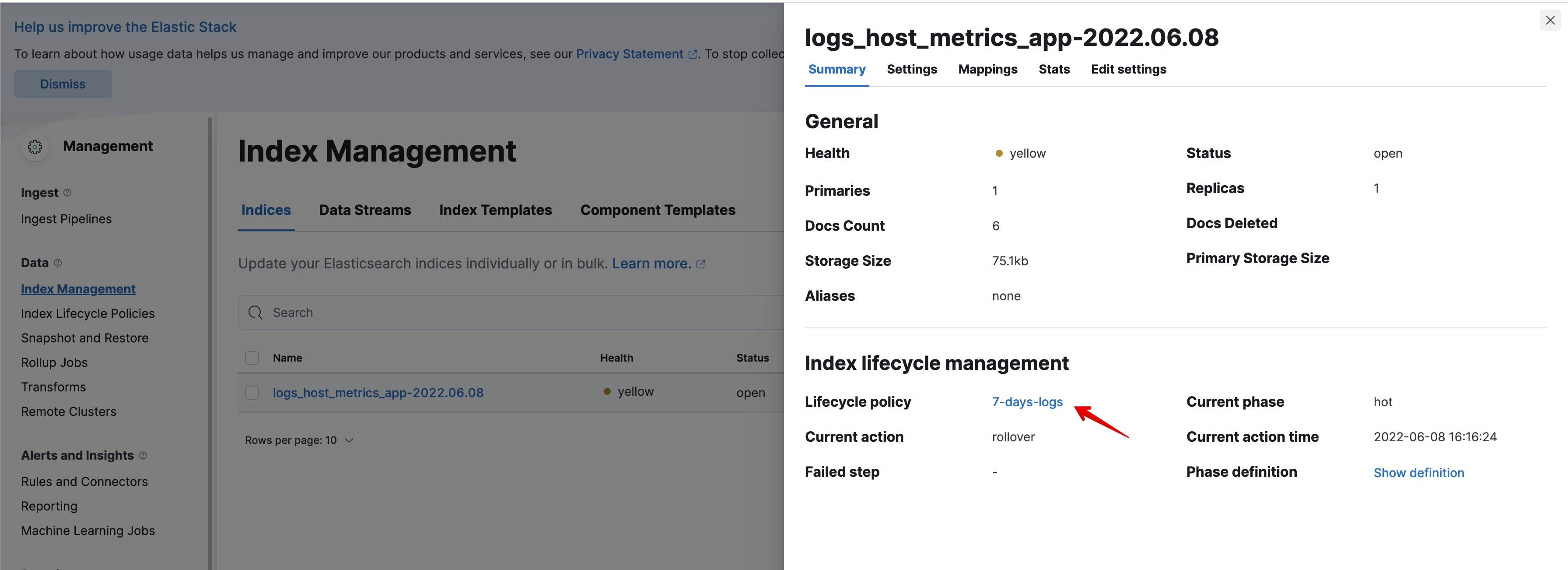
Все новые индексы logs_* будут автоматически удаляться через 7 дней.
Заключение
В заключении хотелось бы еще раз напомнить основную идею статьи: показать вам, как максимально быстро и, на мой взгляд, эффективно попробовать ELK не зная всех его особенностей и тонкостей.
Не забывайте прикрывать открытые порты, следите за индексами, по необходимости задавайте тип полей явно и все должно быть хорошо.
Репозиторий с кодом и конфигами: здесь
Комментарии (17)

sergeevik
15.06.2022 01:39+1При запуске в винды
ошибка:
Exiting: error loading config file: config file ("filebeat.yml") can only be writable by the owner but the permissions are "-rwxrwxrwx" (to fix the permissions use: 'chmod go-w /usr/share/filebeat/filebeat.yml')
лечится
https://discuss.elastic.co/t/volume-mapped-filebeat-yml-permissions-from-docker-on-windows-host/91893
добавлением строки
command: filebeat -e -strict.perms=false
в docker-compose.yml для компонента beats
beats:
image: elastic/filebeat:7.16.2
command: filebeat -e -strict.perms=false
volumes:
- ./configs/filebeat/config.yml:/usr/share/filebeat/filebeat.yml:ro
- ./host_metrics_app/:/host_metrics_app/:ro
networks:
- elk
depends_on:
- elasticsearch

gecube
15.06.2022 02:28+4Эм, очень странная статья. Непонятно зачем. Во-первых, сюрприз, но запросто может оказаться, что в пересчете на ресурсы поиск grep'ом, или ripgrep'ом быстрее и дешевле, чем хранить данные в эластике и искать там. Тем более, когда речь идет о сотнях гигов или терабайтах данных - просто подумайте сколько придется под сам эластик отдать ресурсов.
Во-вторых, компоуз. Ну, в 2022 это уже очень странно. Прикольно разворачивать в облаке, или брать kubernetes + eck оператор (там реально 3 манифеста для установки эластик стека)
В третьих, logstash не нужен. Filebeat прекрасно умеет слать в сам эластик и какие-то базовые преобразования он умеет. А если делать совсем надежно - то это помимо логстэша кафку еще притаскивать. В общем, космолет получается. Ну, или наоборот - биты завсегда можно логстэшом заменить. Здесь скорее вопрос ресурсов ))) потому что биты обычно кушают сильно меньше, чем полноценная установка logstash.
В четвертых, без того, чтобы само приложение написать так, чтобы оно писало структурированные логи - ценность в эластике в районе нуля. Тут главное не удариться в другую историю - когда вроде как мы логи в json завернули, но все равно все пишем в поле message.
В любом случае автору за попытку спасибо

blohinn Автор
15.06.2022 11:42+1Наверное, но иногда есть нужда красиво и удобно смотреть логи. Особенно, если есть необходимость давать доступ заказчику/аналитикам/тех.поду к некоторым логам.
Ну, тут на вкус и цвет. Не вижу ничего плохого в docker compose. За свой скромный опыт кубер был лишь на одном месте работы (но инфра была на аутсорсе), а где-то еще до сих пор rpm пакеты (прекрасно работало, кстати).
Согласен, но хотелось и самому разобраться и другим хоть как-то показать.
Этот пункт не совсем понял. JSON в поле message - костыль? Что вы подразумеваете под структурированными логами (я подумал про uuid пользователя, операции, контекста)?
Спасибо за комментарий)

MaximZalysin
16.06.2022 20:27Поддержу коллегу по п.3 — связка "*beat > logstash > elasticsearch" в 2022 свою актуальность совсем и полностью исчерпала. А именно Logstash — неудобный в эксплуатации, ресурсоемкий, ограниченный в отладке. Было бы круто и полезно новичкам, на кого очевидно и рассчитана статья, даже исходя из заголовка, увидеть примеры про актуальный и практичный Ingest Pipelines на удобной связке "*beat > elasticsearch" или перспективные Data Streams.
Ну и оставлю это тут как идею для дальнейшего углубления в изучение централизованной работы с лога и на базе продуктов Elastic Stack.

kt97679
15.06.2022 04:07+1У меня примерно 6 лет назад не получилось использовать elastic для хранения и обработки логов. Возможно с тех пор он стал лучше.

saduga
15.06.2022 13:56+1Можно ELK заменить на graylog (тоже на эластике) в настройке попроще чем кибана.
gecube
15.06.2022 14:19Хотел упомянуть, но потом подумал - а зачем ))) в принципе, полностью согласен - Грейлог для старта проще. Но каких-то откровений от него ждать странно, учитывая, что он на том же эластике

Caraul
16.06.2022 09:29Есть ощущение, что ELK и логи расходятся в разные стороны - слишком тяжелая конструкция выходит. И ресурсов требует много (в том числе административных), а открываешь Кибану - и как в кабине самолета. И это при том, что исходная задача поиска по логам в общем-то несложная, не зря многие решают ее простым grep'ом.
gecube
16.06.2022 11:39+1ELK хорош, например, в случае, когда у тебя 100500 серверов и нужно искать логи по каждому из них. А еще в взаимосвязи друг с другом. Но такую же задачу можно решить так - взять отдельный сервер, сделать на нем файлопомойку. Вгружать на него логи с серверов-источников rsyslog'ом. Профит. Да, при этом не будет красивой гуйни. Зато и оверхеда не будет...
Caraul
16.06.2022 14:06Именно - когда объемы логов и сложность поиска по ним превышают некий болевой порог админов. А для простых вещей недавно рекомендовали Loki через promtail. GUI минималистичный, но вот полнотекстового поиска уже нет, увы.
gecube
16.06.2022 14:08а полнотекст обычно и не нужен... полнотекст переоценен. Обычно ты ищешь что-то конкретное - потому что логи каждой программы выглядят как набор некий вполне определенных строк с некими плейсхолдерами. Кстати, ВНЕЗАПНО, для такой задачи опять же https://sentry.io лучше подходит, но в случае возможности инструментации программы.

vasilisc
16.06.2022 09:49Для удобства работы с grep в журнале должна быть в идеале 1 строка на 1 событие, которое вас интересует. Многие программы обладают параметрами по типу Nmap (-oG : Grepable format), чтобы их вывод легче было фильтровать. Сложности начинают возникать, когда событие "размазано" в журнале по разным строкам, которые могут быть "разбавлены" другими строками.
Благодаря мощности всего стека ELK можно красиво парсить даже multiline журналы, для примера Postfix. Лично я начал отказываться от grep текстовых журналов и вначале на базе ELK сделал единый remote syslog. Если вывод какой-то службы особо важен и интересен, то его выделяю в отдельный индекс и не ленюсь написать grok парсер для разбивки по полям: журнал bind9 запросов, postfix(SMTP), dovecot(POP3, IMAP), kaspersky linux mail server.
http://vasilisc.com/postfix-logs-2-elasticsearch
http://vasilisc.com/grok-pattern-kaspersky-linux-mail-server
gecube
16.06.2022 11:41Сложности начинают возникать, когда событие "размазано" в журнале по разным строкам, которые могут быть "разбавлены" другими строками.
мультилайн - это рак, я полностью согласен. И если в случае самописных программ это решается просто стандартом на логирование или, например, отправкой стектрейсов в sentry (!), то в случае старых легаси штук типа postfix, postgres, не знаю - подставьте свое название, то там придется выкручиваться. В идеале все-таки тоже переработать формат логов... Как хороший пример - nginx. Он умеет в нормальный json лог, а не в свой штатный...
можно красиво парсить даже multiline журналы, для примера Postfix
можно? да. Красиво? Нет! И более того - это лишняя нагрузка на процессор и память (потому что точно будете регекспами искать начало и конец мультилайна + кольцевой буфер нужен)...
vasilisc
16.06.2022 12:04Это делается в ELK не регулярными выражениями, а агрегирующим фильтром
https://www.elastic.co/guide/en/logstash/current/plugins-filters-aggregate.html
sunnybear
Есть ли сравнение ELK и Clickhouse (+clicktail) ?