
Мы в Smart Engines занимаемся системами распознавания документов, и мы решили проверить, сколько нужно времени, чтобы создать MVP инструмента, позволяющего предзаполнять типовые шаблоны в формате DOCX данными, извлекаемые из сканов и фотографий документов. В этой статье мы вам покажем как на базе нашей системы распознавания Smart Document Engine быстро сделать простой шаблонизатор, готовый к использованию и не требующий никакой предварительной подготовки пользователя. Кому интересно - добро пожаловать под кат!
Как же часто такое банальное действие, как заполнение какого-то договора, акта, или другого бизнес-документа, может доставлять море проблем и неудобств. Еще куда ни шло, если нужно заполнить ФИО из только что отсканированного паспорта в какой-нибудь банковский договор, и другое дело, если вам нужно заполнить несколько десятков однотипных документов, с источниками информации в других документах, и все это нужно сделать быстро, без ошибок, и в присутствии нетерпеливого клиента.
Конечно, все эти операции можно и нужно автоматизировать. На помощь могут прийти, например, RPA-системы, с помощью которых пользователь должен лишь выполнить правильную последовательность действий по загрузке-выгрузке данных. Но для того, чтобы в компании RPA была внедрена, как правило, нужно выполнить целый большой проект, собрать нужное количество компонент, настроить их, научить пользователей пользоваться, и так далее и тому подобное. Что если пользователю нужно всего лишь сканировать набор типовых документов и заполнять банальные Word-овые документы с правильными реквизитами?
Мы покажем, как просто собрать минимальный, но функциональный шаблонизатор, используя Smart Document Engine и python с несколькими общедоступными пакетами. Манипуляции все будут демонстрироваться на примере SDK для MacOS, однако все то же самое заработает также и для Windows и для систем на базе Linux.
Распознавание документов с помощью Smart Document Engine
В основе шаблонизатора лежит, само собой, распознавание документов с помощью Smart Document Engine. Библиотека обладает рядом интерфейсов интеграции (основной интерфейс C++ и набор оберток), но, для максимальной простоты, функцию распознавания мы реализуем в виде CLI-приложения, используя в качестве основы С++-пример, который находится прямо в SDK-пакете.
Чтобы скомпилировать поставляемый консольный пример docengine_sample, нужно вставить в код подпись клиента, которая берется из документации SDK-пакета:
// Creating a session object - a main handle for performing recognition.
std::unique_ptr<se::doc::DocSession> session(
engine->SpawnSession(*session_settings, “ABCDEFG….”));После этого его можно собирать (например, лежащим рядом скриптом build_cpp.sh).
Консольный пример docengine_sample принимает три параметра: путь к изображению документа, путь к конфигурационному архиву и маску типов документа. Проверяем распознавание в стандартном режиме, к примеру, платежного поручения:
$ DYLD_LIBRARY_PATH=../../bin ./docengine_sample ../../testdata/rus.payment_order_sample.png ../../data-zip/bundle_docengine_photo.se "rus.payment_order*"
Smart Document Engine version 1.11.0
image_path = ../../testdata/rus.payment_order_sample.png
config_path = ../../data-zip/bundle_docengine_photo.se
document_types = rus.payment_order*
(... Скрыто много дополнительной информации …)
Text fields (35 in total):
amount : 20 003 000-00
amount_words : ДВАДЦАТЬ МИЛЛИОНОВ ТРИ ТЫСЯЧИ РУБЛЕЙ 00 КОПЕЕК
beneficiary : ООО "МЕЧТА"
beneficiary_account : 11223344556677889900
beneficiary_bank : МЕЖДУНАРОДНЫЙ ЗАПАДНЫЙ БАНК
beneficiary_bank_invoice : 33344455566677788899
bik_beneficiary : 987654321
bik_payer : 012345678
(... и так далее …)
Для целей создания шаблонизатора слегка модифицируем код приложения:
1. В конфигурационном бандле bundle_docengine_photo.se по умолчанию используется режим, оптимизированный для распознавания фотографий (в нашем демо-приложении этот режим используется при распознавания документов с фотографий, полученных непосредственно на устройстве). Выставим сессиям распознавания режим “universal”, который более подходит в случае, когда заранее неизвестно, скан будет распознаваться или фотография (в демо-приложении этот режим используется при распознавании из галереи):
session_settings->SetCurrentMode("universal"); // переходим в режим universal
// For starting the session we need to set up the mask of document types
// which will be recognized.
session_settings->AddEnabledDocumentTypes(document_types.c_str());2. Уберем весь отладочный/информационный вывод и упростим функцию OutputRecognitionResult так, чтобы она выписывала тип и текстовые поля распознаванного документа в JSON-формате:
void OutputRecognitionResult(
const se::doc::DocResult& recog_result) {
if (recog_result.GetDocumentsCount() == 0) {
printf("{}\n");
} else {
const se::doc::Document& doc = recog_result.DocumentsBegin().GetDocument();
printf("{\"DOCTYPE\": \"%s\"", doc.GetAttribute("type"));
for (auto f_it = doc.TextFieldsBegin();
f_it != doc.TextFieldsEnd();
++f_it) {
std::string escaped_value = std::regex_replace(
f_it.GetField().GetOcrString().GetFirstString().GetCStr(),
std::regex("\""), "\\\"");
printf(",\"%s\": \"%s\"",
f_it.GetKey(),
escaped_value.c_str());
}
printf("}\n");
}
}3. Переименуем получившийся исходник в docengine_cli.cpp и перенесем его в директорию рядом с динамической библиотекой libdocengine.dylib (в моем случае - в директорию /bin SDK-пакета), после чего скомпилируем с rpath-привязкой так, чтобы он искал библиотеку рядом в исполняемым файлом:
$ clang++ docengine_cli.cpp -O2 -I ../include -L. -l docengine -o docengine_cli -Wl,-rpath,"@executable_path"Проверяем (в вывод программы добавлены переводы строк для читабельности):
$ ./docengine_cli ../testdata/rus.payment_order_sample.png ../data-zip/bundle_docengine_photo.se "rus.payment_order*"
{"DOCTYPE": "rus.payment_order.type1","amount": "20 003 000-00",
"amount_words": "ДВАДЦАТЬ МИЛЛИОНОВ ТРИ ТЫСЯЧИ РУБЛЕЙ 00 КОПЕЕК",
"beneficiary": "ООО \"МЕЧТА\"","beneficiary_account": "11223344556677889900",
"beneficiary_bank": "МЕЖДУНАРОДНЫЙ ЗАПАДНЫЙ БАНК",
"beneficiary_bank_invoice": "33344455566677788899",
"bik_beneficiary": "987654321","bik_payer": "012345678",
"budget_classification_code": "","code1": "0401060","code_payment": "",
"date": "05.11.2020","date_document_payment_basis": "",
"debiting_date": "05.11.2020","inn_beneficiary": "1111111111",
"inn_payer": "1234567890","invoice_number": "98765432109876543210",
"kpp_beneficiary": "222222222","kpp_payer": "125125125",
"number_document_basis_payment": "","number_payment_order": "345",
"oktmo_code": "","payer": "ИП \"ДОБРОЕ УТРО\"",
"payer_bank": "ПУШКИНСКОЕ ОТДЕЛЕНИЕ БАНК \"ЗДОРОВЬЕ\"",
"payer_bank_invoice": "12345678901234567890","payment_code": "0",
"payment_reason_code": "","payment_type": "","place_payment": "8",
"purpose_payment": "ОПЛАТА ПО ДОГОВОРУ №23456 ЗА ВЫПОЛНЕНИЕ СТРОИТЕЛЬНЫХ И ФУНКЦИОНАЛЬНЫХ РАБОТ ПО ИССЛЕДОВАНИЮ ОРГАНИЗМА. НДС НЕ ОБЛАГАЕТСЯ",
"purpose_payment_1": "","receipt_date": "05.11.2020","tax_period": "",
"type_payment": "","wage_type": "01"}То, что надо! Теперь переходим к шаблонизатору.
Шаблонизатор
Что хотим? Хотим простое GUI-приложение, которое бы умело загружать шаблонные документы в формате DOCX, в стратегических местах которых проставлены теги вида ${very_important_info}, загружать изображения нужных документов, и сохранять документ с заполненными данными.
В первую очередь заведем конфигурационный файл, в котором будет указано, какое CLI-приложение нужно запускать, с каким конфигурационным бандлом, с какими масками типов документов для интересующих нас типов (пусть нас интересует Российские платежное поручение и справка о доходах физлица, и, скажем, социальная карта Армении), и как поля с разных документов должны транслироваться в теги шаблона.
Пусть из платежного поручения мы хотим извлекать название плательщика и его банка, реквизиты получателя, сумму прописью и назначение платежа. Из 2-НДФЛ извлекаем ФИО, дату рождения (справка о доходах физического лица, формально говоря, уже не называется 2-НДФЛ, но изжить такой прижившийся термин, думаю, будет непросто), и, наконец, из справки о социальном номере Армении извлекаем ФИО на армянском и, собственно, номер. Для целей демонстрации возможностей шаблонизатора вполне хватит. Конфигурационный файл (config.json) получился такой:
{
"executable": "docengine_cli",
"bundle": "bundle_docengine_photo.se",
"sessions": {
"rus_payment_order": {
"documents_mask": "rus.payment_order*",
"text": "payment order"
},
"arm_social_card": {
"documents_mask": "arm.ref_public*",
"text": "social card"
},
"rus_2ndfl": {
"documents_mask": "rus.2ndfl*",
"text": "income form"
}
},
"tags": {
"rus_payment_order:payer": "payer_name",
"rus_payment_order:payer_bank": "payer_bank_name",
"rus_payment_order:beneficiary": "beneficiary_name",
"rus_payment_order:beneficiary_account": "beneficiary_account",
"rus_payment_order:beneficiary_bank": "beneficiary_bank_name",
"rus_payment_order:bik_beneficiary": "beneficiary_bik",
"rus_payment_order:kpp_beneficiary": "beneficiary_kpp",
"rus_payment_order:amount_words": "payment_amount",
"rus_payment_order:purpose_payment": "payment_purpose",
"rus_2ndfl:surname": "surname",
"rus_2ndfl:name": "name",
"rus_2ndfl:patronymic": "patronymic",
"rus_2ndfl:birth_date": "birth_date",
"arm_social_card:name_patronymic_surname": "arm_fio",
"arm_social_card:public_service_number": "arm_number"
}
}Конфигурационный файл поместим в директорию resources, вместе со всем необходимым для запуска распознавания: конфигурационным бандлом bundle_docengine_photo.se, исполняемым файлом docengine_cli и библиотекой libdocengine.dylib.
В качестве самого шаблонизатора напишем простенькое GUI-приложение на wxPython. Не имеет смысла углубляться в детали, ограничусь лишь тем, что у меня ушло на все про все около двух часов (без опыта работы с wx) и 292 строчки кода. Разберем лишь процедуры распознавания изображения и заполнения шаблона.
В GUI-приложении распознавание изображения инициируется нажатием на кнопку, которая соответствует той или иной сессии распознавания, прописанной в config.json. Предлагаем пользователю выбрать файл с изображением документа, после чего запускаем docengine_cli при помощи модуля subprocess и парсим JSON, который получаем на выходе. После этого, согласно прописанным тегам в config.json обновляем словарь со значениями тегов:
def loadImage(self, event):
'''
Загружает изображение, распознает документ, обновляет словарь тегов
'''
button_name = event.GetEventObject().GetName() # соответствует ключу в словаре “sessions” конфигурационного файла config.json
self.tlog.AppendText('Loading image of %s...\n' % self.config['sessions'][button_name]['text'])
with wx.FileDialog(self, 'Open %s image file' % self.config['sessions'][button_name]['text'], \
wildcard="PNG, JPG or TIF image (*.png;*.jpg;*.jpeg;*.tif;*.tiff)|*.png;*.jpg;*.jpeg;*.tif;*.tiff", \
style=wx.FD_OPEN | wx.FD_FILE_MUST_EXIST) as fileDialog:
if fileDialog.ShowModal() == wx.ID_CANCEL:
return
pathname = fileDialog.GetPath()
try:
self.tlog.AppendText('Recognizing %s...\n' % pathname)
# запускаем docengine_cli
output = subprocess.run([
os.path.join(self.resources_path, self.config['executable']), # путь к исполняемому файлу docengine_cli
pathname, # путь к изображению
os.path.join(self.resources_path, self.config['bundle']), # путь к конфигурационному бандлу Smart Document Engine
Self.config['sessions'][button_name]['documents_mask'] # маска типа документа
], capture_output = True)
# парсим вывод docengine_cli
output_json = None
try:
output_json = json.loads(output.stdout)
except Exception:
pass
if output_json is None:
self.tlog.AppendText('Failed to retrieve any data.\n')
else:
# обновляем словарь тегов
any_fields_extracted = False
for tag in self.config['tags'].keys():
if tag.split(':')[0] != button_name:
continue
prop_name = tag.split(':')[-1]
if prop_name not in output_json.keys():
continue
prop_value = output_json[prop_name]
self.keyval[self.config['tags'][tag]] = prop_value
self.tlog.AppendText('Extracted %s: %s\n' % (self.config['tags'][tag], prop_value))
any_fields_extracted = True
if not any_fields_extracted:
self.tlog.AppendText('No fields extracted.\n')
except Exception as e:
self.tlog.AppendText('Cannot process file %s: %s\n' % (pathname, str(e)))Заполнение шаблона инициируется нажатием на другую кнопку, при котором подгруженный заранее DOCX-шаблон загружается при помощи пакета python-docx, после чего просматриваются все параграфы документа и все параграфы каждой ячейки каждой таблицы, с заменой найденных тегов на значения, извлеченные из распознанных документов. Скорее всего заполнение шаблона можно было сделать проще, но я уже в пижаме:
def applyTagsToParagraph(self, paragraph):
'''
Применяет словарь тегов self.keyval к одному параграфу DOCX-документа, сохраняя формат куска, содержащего символ “$”.
'''
for i in range(len(paragraph.runs)):
while '$' in paragraph.runs[i].text:
end_index = -1
found_key = None
composite_text = ''
for j in range(i, len(paragraph.runs)):
composite_text += paragraph.runs[j].text
for key in self.keyval.keys():
if '${%s}' % key in composite_text:
found_key = key
end_index = j
break
if found_key is not None:
break
if found_key is not None:
paragraph.runs[i].text = composite_text.replace('${%s}' % found_key, self.keyval[found_key])
for k in range(i + 1, end_index + 1):
paragraph.runs[k].clear()
else:
break
def saveDocument(self, event):
'''
Загружает шаблон документа из self.template_path, применяет словарь тегов self.keyval к документу и предлагает пользователю сохранить получившийся документ.
'''
if len(self.keyval) == 0:
self.tlog.AppendText('Nothing to apply.\n')
return
self.tlog.AppendText('Applying values to template file %s:\n' % self.template_path)
for k, v in self.keyval.items():
self.tlog.AppendText(' %s: %s\n' % (k, v))
document = docx.Document(self.template_path)
# применяем к параграфам документа
for paragraph in document.paragraphs:
self.applyTagsToParagraph(paragraph)
# применяем к таблицам документа
for table in document.tables:
for row in table.rows:
for cell in row.cells:
for paragraph in cell.paragraphs:
self.applyTagsToParagraph(paragraph)
with wx.FileDialog(self, "Save DOCX file", wildcard="DOCX files (*.docx)|*.docx", \
style=wx.FD_SAVE | wx.FD_OVERWRITE_PROMPT) as fileDialog:
if fileDialog.ShowModal() == wx.ID_CANCEL:
return
pathname = fileDialog.GetPath()
# на всякий случай добавляем расширение docx и безопасно сохраняем файл
if not pathname.lower().endswith('.docx'):
new_pathname = pathname + '.docx'
while os.path.exists(new_pathname):
new_pathname = new_pathname[:-5] + '-copy.docx'
pathname = new_pathname
try:
document.save(pathname)
self.tlog.AppendText('Saved to %s\n' % pathname)
except IOError:
self.tlog.AppendText('Cannot save to file %s\n' % pathname)Шаблонизатор готов! Для того, чтобы запускать его как любое другое приложение, можно применить удобный инструмент pyinstaller, он позволяет создавать готовое приложение для целевой операционки, упаковать внутрь директорию resources и подложить иконку:
$ pyinstaller -w docengine_templater.py --name="Docengine Templater" --add-data resources:resources -i docengine.icnsТестим!
Для теста шаблонизатора создадим простой DOCX-файл, использующий все теги, которые мы ранее добавляли в config.json:

Окно шаблонизатора после загрузки шаблона и распознавания трех изображений:

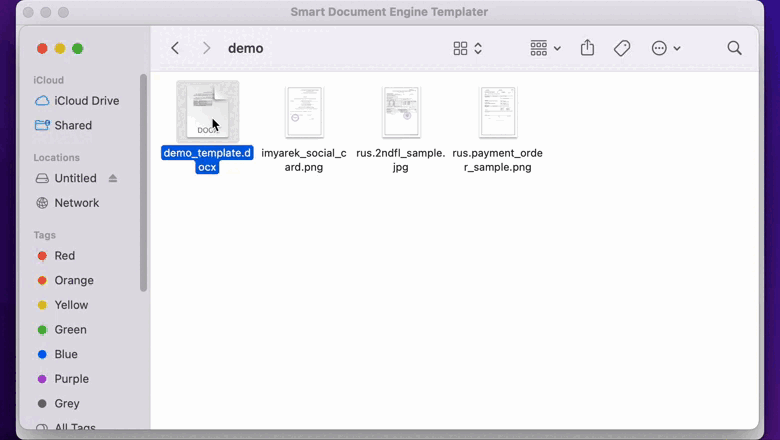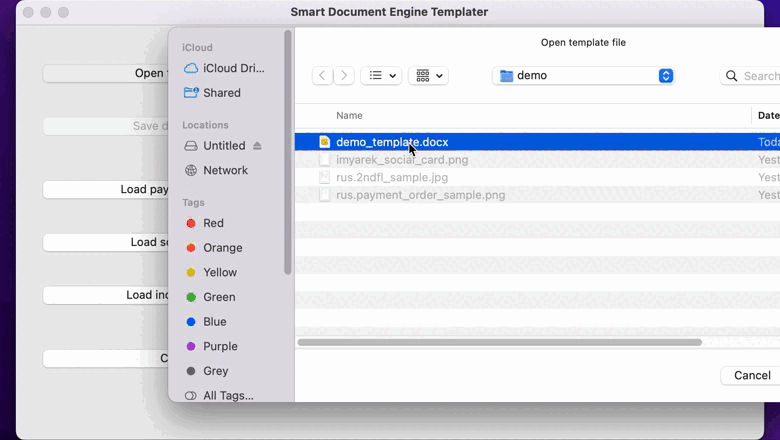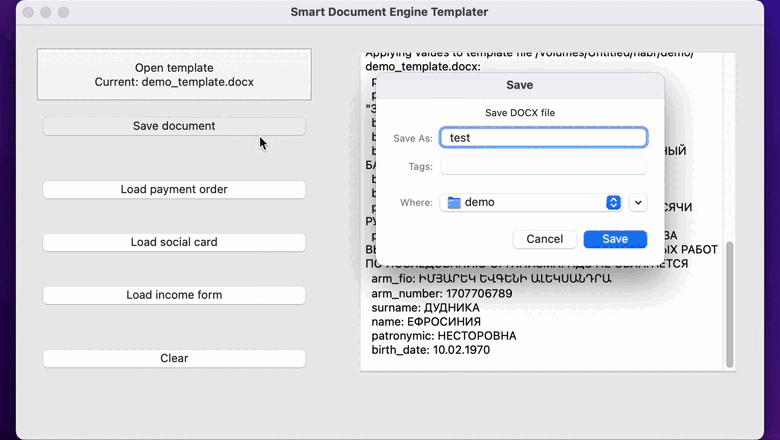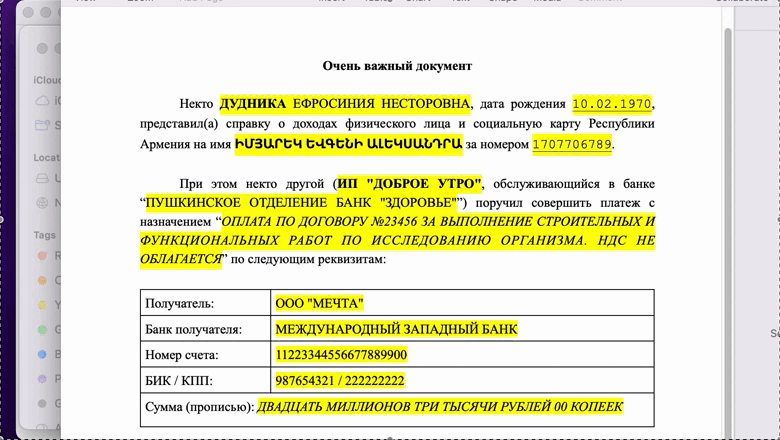
Сохраненный документ:

На этом, пожалуй все! Код шаблонизатора (и модифицированного семпл-приложения docengine_cli.cpp) вы можете посмотреть здесь.
Если вам интересен продукт Smart Document Engine, вы можете узнать про него больше на сайте нашей компании, или обратиться там же к нашим специалистам за подробностями.
Спасибо за внимание!
Комментарии (13)

NAI
23.06.2022 11:51Хотим простое GUI-приложение, которое бы умело загружать шаблонные документы в формате DOCX, в стратегических местах которых проставлены теги вида
${very_important_info}Чем вызван выбор такого не нативного тега?
Обычно используются свойства документа и "поля". ПО меняет свойство, поля обновляются уже самим движком текстового процессора. В крайнем случае, нативно поле имеет тег { DOCPROPERTY name }

Alexufo
23.06.2022 13:47Это еще ничего)) Вот тут переменные обернуты огонь))
github.com/guigrpa/docx-templates
Благо это можно менять в настройках.
Свойства типа нативных переменных ворда? Так они отвратительные, их же копипастой не задать, надо вставлять через интерфейс ворда разметку.NAI
23.06.2022 15:57В смысле нельзя?
Пишете условный DOCPROPERTY name, выделяете, ctrl+F9 и вуаля. Ну лан, справедливости ради надо еще нажать "обновить поле".
Или вы про создание перечня полей?
Alexufo
24.06.2022 15:23да про DOCPROPERTY, он переусложнен. Да, вот эти всякие поля кнопки горячие клавиши. Ничего не надо никому показывать. Вот слова в тексте такие же как текст. Онпен офис у тебя, или еше какой редактор, на мобилке, где угодно. Просто переменные в тексте очевидны для понимания.
NAI
24.06.2022 23:33Так включаете подсветку полей и они начинают подсвечиваться, так что в тексте становится сразу видно, что поле, а что нет. Причем, хочешь отображай имя поля, хочешь значение.
В этом кстати и есть сакральный смысл, потому что оформляя документ по ЕСКД, какая-нибудь длинная фамилия может поломать рамки и вы это увидите сразу, до, так сказать, рендера.
На счет переусложненности DOCPROPERTY, ну х.з. вон в yml один лишний пробел может весь конфиг поломать - сиди вычитывай. Ну и не стоит забывать что ворд это WYSIWYG - а много вы WYSIWYG-движков с переменными знаете? Бухгалтерам это не надо, программисты и на VBA\С#\python напишут ПО которое будет данные сразу из БД брать.
В общем ворд, нормальная, мощная штука, просто его надо изучать и строить процессы исходя из его возможностей, а не "мы привыкли по другому"
P.s. кстати, в ворде можно вообще сделать выпадающий список в поле с предустановленными значениями. Т.е. можно ограничить оператора сразу нормализованными значениями, чтобы не пихал всякую фигню. И править все это можно без заныривания в код.
Alexufo
24.06.2022 23:48DOCPROPERTY были полезны когда формат форда был бинарный doc. Еще полезно когда ты шлешь форму пользователю для заполнения, да это вы подметили верно. docx — xml и подменять в нем переменные стало по всем параметрам удобнее вне механизма ворда, без привязки к софту на любом яп. Улетело не так из-за длины строк? Так документ же перед глазами и после генерации тыкнул энтер где надо и на печать.

SmartEngines Автор
23.06.2022 13:54Вы правы, что есть более каноничные способы заведения полей в DOCX-шаблонах, однако целью здесь было создание максимально простого инструмента, которым можно пользоваться как для заполнения полностью шаблонных документов, так и для "дозаполнения" подготовленных комплектов документов. Для разработки я не завязывался на возможности текстового процессора (кроме того, я не уверен, что python-docx умеет нативно работать с DOCPROPERTY). В крайнем случае, изменить текущий механизм тегов вида ${tag} на более нативный формат не составит труда.

tas
23.06.2022 12:27+1Делал когда-то такое - с таблицами, циклами и условиями вставки. Вот как это выглядело:

Красные - это управляющие коды по разделам, таблицам и др., которые при обработке из документа удалялись, а переменные были просто в квадратных скобках...

sshikov
23.06.2022 20:17>Делал когда-то такое
Да имя им легион. Их столько уже было, шаблонизаторов этих…


net_men
23.06.2022 13:17-2Поставил бы плюсик, но их нет у меня. Положу в закладки: возможно когда-нибудь пригодицца :)
idakseart
Хорошая статья, спасибо! Было интересно почитать!
Но в ходе прочтения возникло несколько вопросов по этой сфере.
Почему именно .docx? Понимаю, что исторически так сложилось, что это максимально простой инструмент для создания любого документа и т.д. и т.п., но почему для этой задачи не использовать условный latex? Ведь насколько я понимаю на выходе нет необходимости обрабатывать дополнительно этот файл? А у latex большие возможности для создания такого рода документов (ИМХО, естественно).
Объясню: представим, что документ у нас с шапкой и подписью внизу. Что будет если значение одного из полей будет больше, чем отведенное под него место (на заполнителе)? Скорее всего строка с подписью съедет на другой лист. Latex же позволит всегда размещать строку с подписью внизу страницу если это возможно, при этом если справка/заявление/иной документ будет более чем на страницу, то и подпись будет на последней странице внизу.
Да, резонно кто-то скажет, а как простой секретарь/менеджер/etc будет пользоваться latex? А по сути, ему и не надо это делать. Нужен один человек в компании кто заблаговременно создаст шаблоны заявлений в нем, а уже пользователь будет просто с помощью программы с GUI выбирать шаблон, заполнитель и т.д.
Alexufo
У вас в latex бухгалтер или юрист договора присылает?)) С расставленными переменными юрист или бух сам может сто раз на дню менять документ. Иначе это создание бутылочного горлышка.
>Что будет если значение одного из полей будет больше, чем отведенное под него место (на заполнителе)?
Ворд же рендерит, как вы зададите ему это поле так и будет. Можно проверить не отходя от кассы. Боитесь, что съедет — рисуйте фрейм с абсолютным позиционированием и в нем вставляете переменную. Подпись вставлять можно так же с абсолютным позиционированием.
Он всегда будет получать ворд от юриста и всегда будет до запятой искать отличия в новом и своем шаблоне, каждый раз, ведь юрист ему не принесет дельту. Это лишнее звено. Сам юристу отдаешь размеченный документ первый раз для примера и просишь его использовать для правок. А так ответственность размывается на двух людей, это куда сложнее контролировать.
Копипаста из ватсапа буху с описанием переменных вот и весь гуй.
SmartEngines Автор
Здесь дело не столько в том, что так исторически сложилось, сколько в том, чтобы создать максимально простой (для конечного пользователя) инструмент. Редактирование DOCX-документа после его заполнения вполне естественная операция для пользователя (к примеру, при заполнении комплекта документов при онбординге, какие-то поля документов вполне могут редактироваться вручную, боль доставляет "переписывание" данных из отсканированных документов). Тот инструмент, который получился здесь, можно отдавать сотруднику и начать им пользоваться он сможет уже через несколько минут.
В рамках более серьезного внедрения в информационную систему корпорации эту задачу можно решать совсем по-другому - с более глубоким интегрированием в существующую инфраструктуру, подгрузкой стандартных шаблонов (и уже, возможно, не в DOCX а в том формате или форматах, который принят в организации), и интеграцией распознавания не через вызов простейшего консольного приложения, а вызывая библиотечные функции.