

Занимательный факт. Исходный код программы бортового управляющего компьютера лунного модуля Аполлон 11 содержит 64830 строк. Исходные коды прошивок навигационного приемника, которые мы в МЭИ разрабатываем последние десять лет, содержат 217510 строчек на C++ и 181236 строчек на SystemVerilog. И я всё жду, когда это количество перейдет в качество.
Встраиваемый софт - это не только прошивки небольших контроллеров, он может быть объемным и сложным. Его разработка, например, для современных систем связи и навигации, может стоить дороже разработки схемотехники, корпуса или даже запуска в производство интегральных микросхем.
Если аппаратные решения определяют потенциал будущего изделия, то софт - длинная дорога для реализации этого потенциала. Выбор аппаратных решений осуществляется на первых этапах разработки устройства, а затем они слабо подвержены изменениям. Прошивки же эволюционируют пока устройством продолжают пользоваться.
Кодовая база переползает из проекта в проект, от изделия к изделию, многие из которых производятся и используются одновременно. Наработки и заплатки одного устройства нужны и в другом. Программное обеспечение - это технология. Технология развивается вместе с компанией и коллективом, применяется к нескольким продуктам одновременно. Требовать в каждом контракте разрабатывать прошивку с нуля, это как требовать от шеф-повара в каждом новом ресторане придумывать новые блюда. Он перепишет технологическую карту, но борщ останется борщом.
Мы оказываемся в ситуации, когда одни и те же программные модули влияют на несколько разных устройств. Да и в рамках одного устройства легко сломать одну фичу, добавляя другую. В процессе правок нужно контролировать выполнение требований, иначе говоря - тестировать.
Традиционные испытания радиоаппаратуры
Радиоаппаратура испытывалась, когда тестирование ПО ещё не было мейнстримом. Но типичные для России регламенты, например Система Разработки и Постановки Продукции на Производство, создавались давно и без должной оглядки на программную составляющую. Начертили блок-диаграммы на этапе разработки рабочей конструкторской документации, а затем проверили три раза: на приемо-сдаточных, предварительных и государственных испытаниях. Вот и все информационные технологии. Устройство на этих испытаниях проверяется досконально, но это немного не та частота, с который ты хочешь получать обратную связь при внесении изменений в код. Попробуйте исправить баг, которому семь месяцев к моменту его обнаружения!

Проводить испытания по полной программе значительно чаще - нереально. Типичная программа испытаний рассчитана на 1-2 недели ручного труда, нужно подключать/отключать разные приборы, использовать испытательные камеры и т.д. и т.п. Проверяется длинный список требований из следующих групп:

Даже если выделить специальных людей проверять эти требования в бесконечном цикле, то результат всё равно будет с запозданием, а исполнители очень скоро начнут сходить с ума. Нужно автоматизировать. А чтобы автоматизировать, нужно сократить программу испытаний.
Какие требования покрывать автотестами?
Так ли много требований могут сломаться при изменениях в прошивке? Пожалуй, в основном это требования назначения и, иногда, требования радиоэлектронной защиты. Их, а ещё ряд проверок выполнения требований к ПО, мы и автоматизировали:
требования назначения (правильное определение координат пользователя, быстрое решение, выдача наблюдений по спутникам, выдача навигационного сообщения, ...)
требования радиоэлектронной защиты (внеполосные излучения, устойчивость к помехам, ...)
требования к ПО (компилируемость, синтезируемость, соответствие заданным интерфейсам, запуск на целевой платформе, ...)
Может показаться, что это существенное сокращение программы испытаний, но на самом деле покрытие софтовых проблем всё ещё отличное:
самая частая ошибка при разработке ПО - код не компилируется или не синтезируется (забыли файл, не те ключи у разработчика, битстрим собирается с критическим ворнингом, прошивка перестала вмещаться в небольшую ПЛИС и т.д. и т.п.);
требования назначения доминируют в программе и методике испытаний радиоустройств (например, это 73% ПМИ в нашей последней разработке);
в навигации факт выдачи координат пользователя с точностью в 1 метр - это маленькое чудо, должны сойтись все-все звезды; если кто-то где-то что-то сломал, решения навигационной задачи скорее всего не будет, интеграционный/системный тест лучше и не пожелаешь.
Какие компоненты тестировать?
Как следует из списка проверяемых требований, объектом тестирования выступает устройство и компоненты его ПО. Но какое устройство и какие компоненты? Можно создать стенды под разные устройства и тестировать все подряд. Но автотесты не бесплатны в разработке и поддержке, поэтому нужно фокусироваться на главном.
В качестве устройства мы выделили изделие с максимумом функций и интерфейсов - навигационный приемопередатчик. Он не только принимает сигналы GPS, ГЛОНАСС и т.д., но может и формировать навигационные сигналы для разных нужд. Например, для испытания другой аппаратуры или построения локальных навигационных систем.

В комплекс его ПО входит множество компонентов:

Но наиболее критичными являются прошивка процессорной системы (Firmware в виде демона для запуска на ОС), прошивка программируемой логики (Logic Modules, из которых генерируется прошивка ПЛИС) и хостовые программы для взаимодействия с устройством.
Кроме того, у нас есть симуляция для PC, которая позволяет обернуть процессорную прошивку, и она будет считать, что запущена прямо на устройстве. Она не требует конечного устройства, не требует лабораторных приборов, выполняется во много раз быстрее реального времени. Звучит как отличный объект для быстрой проверки выполнения основных требований назначения. Почти бесплатно.
Как часто тестировать?
За один месяц разработки наша небольшая команда успевает накидать около 50 изменений (мердж реквестов), а количество промежуточных пушей далеко за тысячу.
Замечательно было бы реагировать на каждое изменение, вносимое разработчиками в код, в том числе в ветках. Тогда разработчики быстрее узнают о проблемах и быстрее их исправят. Но, к сожалению, пуши от разработчиков поступают чаще, чем длительность исполнения некоторых тестов. Так прошивка для ПЛИС может разводиться несколько часов, а тест на живом приемнике может потребовать сбора данных на нескольких десятках минут и т.д. Можно было бы размножать ресурсы для выполнения тестов, но вместо этого мы дополнительно сократили программу испытаний для отдельных пушей.
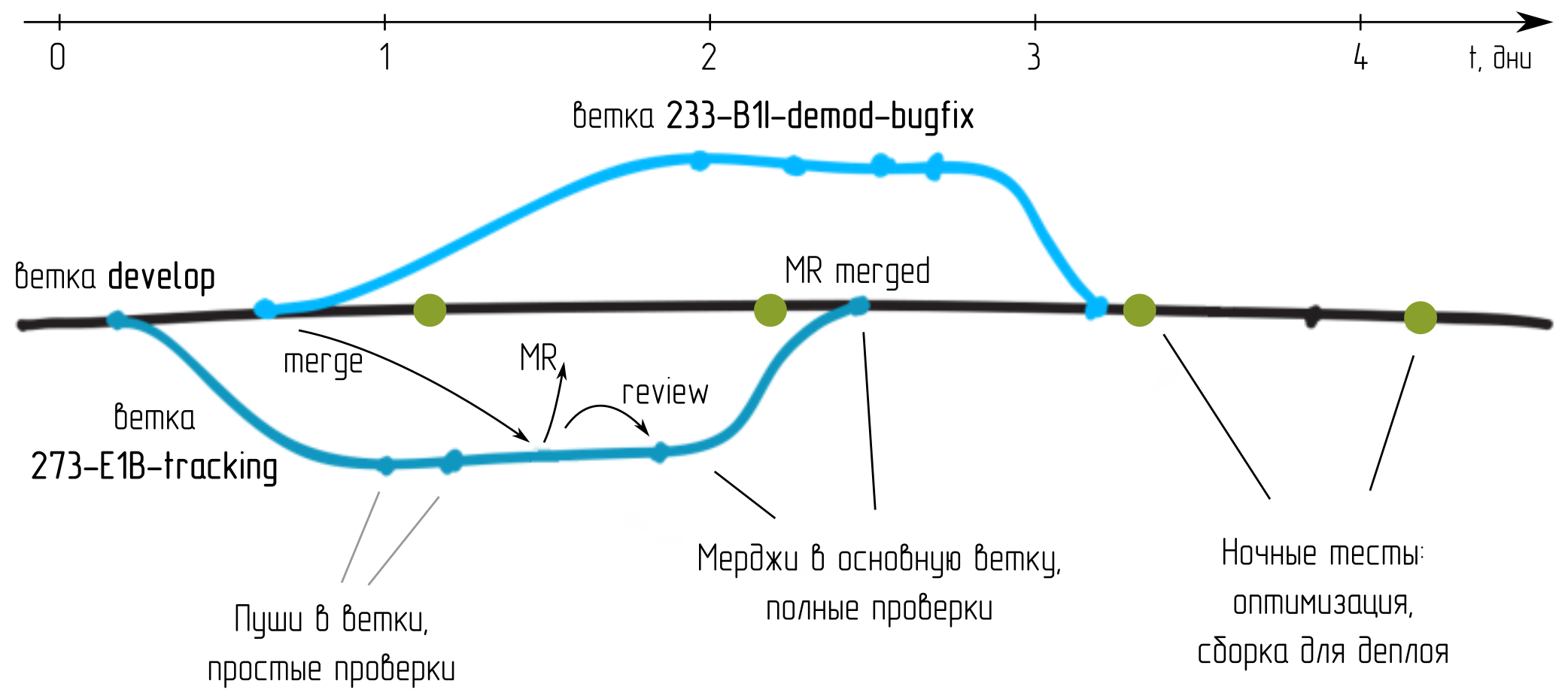
Второе по частоте событие - мердж реквест. Перед тем, как вносить изменения в основную ветку, их надо хорошо протестировать. Раньше это требовало час ручной работы проверяющего, теперь же эти тесты делает машина.
Третий тип событий - ночные тесты. Тут оборудование свободно. Можно занять несколько часов машинного времени, решить задачи оптимизации, подготовить прошивки ПЛИС с полным заполнением кристалла и т.д. и т.п. Подготовить прошивки для использования конечным пользователем.

Три разных типа событий, три разных программы, отличающиеся объемом и временем исполнения. Но все они - автоматические. Вместе они позволяют реализовать систему непрерывного применения изменений (Continuous Integration, CI) и непрерывной поставки изменений пользователю (Continuous Deploy, CD)
Использование Gitlab CI/CD для организации автотестов
Первые три попытки
Немного истории. Как опытные разработчики велосипедов, мы начали с собственного решения. Написали библиотечку для общения с лабораторными приборами в матлабе, скрипты тестирования под разные требования. Разложили по папочкам. Написали описание к каждому тесту в Word'е. И запускали эти скрипты по cron'у через Makefile. Отчет приходил ночью на почту.

Эта система ушла в забвение в 2014 после обновления сервера, проработав пару месяцев. Затем авторазложение повторилось в 2016 году, после того, как кто-то утащил имитатор сигналов для выполнения другой работы. Она не преодолела порог полезности - слишком много сил на поддержание, результат приходит с задержкой, не изящно и не красиво.

Третья версия была оформлена в виде тестов на Check, запускаемых при каждой компиляции на машине разработчика. Но в итоге в этой системе выжили только юнит-тесты, для которых Check изначально и разработан. Тесты на аппаратуре так не проведешь, а интеграционные и симуляция занимают слишком много времени, разработчики их отключали.
В четвертый раз инструмент соответствовал задаче. В качестве системы контроля версий - git, ведение проекта в Gitlab, а система автотестирования в Gitlab CI/CD. Ну и ряд организационных мер: ответственный человек и выделенные исключительно под тестирование лабораторные приборы и серверы.

Ядром системы выступает локальный Gitlab-сервер. На нем хранятся репозитории, с ним взаимодействуют разработчики и раннеры. Раннеры - специальные программы, запущенные на отдельных серверах. Они периодически обращаются на сервер с вопросом: а есть что потестировать? Если есть, они получают задачу и начинают её выполнять. Сейчас мы используем три раннера: один для сборки прошивок ПЛИС, один для взаимодействия с изделием и лабораторными приборами, и один для остальных нужд.
При необходимости, число раннеров может быть легко увеличено. Например, мы экспериментировали с покупкой серверных мощностей на несколько часов. Вы можете развернуть сотню-другую раннеров, набрать необходимую статистику или решить задачу оптимизации параметров прошивки ПЛИС, а затем отключить их.
Этапы испытаний
Сущности и понятия, используемые в Gitlab, хорошо ложатся на термины ГОСТ 15.211. Что ГОСТу этап, то Gitlab'у stage, что ГОСТу программа испытаний, то Gitlab'у pipeline (конвейер). Мы разбили программу испытаний на три этапа:
Build - Сборка - на этом этапе компилируются программы, генерируются прошивки ПЛИС, выполняются юнит-тесты
Sim - Симуляция - проверяется выполнение требований назначения в симуляционном окружении, когда мы прошивку процессорной системы оборачиваем кодом, имитирующим исполнение на целевом устройстве
Testbed - Стенд - собранные компоненты программного комплекса прошиваются в устройство, оно проверяется на выполнение требований назначения и требований радиоэлектронной защиты; активно применяются лабораторные приборы

Есть ещё чисто технический четвертый этап, Conclusion, на нем мы собираем итоговые документы о проведенном тестировании.
Проверки
По ГОСТ 15.211 этап содержит проверки или испытания, а в Gitlab'е этап содержит job'ы. Один job - одна проверка.
Каждая проверка - это скрипт, запускаемый на одном из раннеров в нужном docker-окружении. Ему могут быть предоставлены результаты выполнения других проверок (например, собранные прошивки). А ещё ему доступна локальная копия всего репозитория, все исходные коды проекта.

Правила запуска скрипта описываются в gitlab-ci.yaml файле, располагаемом в корне репозитория. Скрипты теста также лежат в репозитории. Таким образом, вы всегда можете вернуться к нужному коммиту и перезапустить проверки, если это потребуется.
Пример описания одной из проверок в gitlab-ci.yaml
Разделы с описанием проверок в gitlab-ci.yaml формируются отдельным генератором под составленную программу испытаний, выглядит они примерно так:
adicusSolveslnTTFFforGPS:
extends:
- .testbed
- .artifacts_settings
allow_failure: true
rules:
- if: '$CI_PIPELINE_SOURCE == "push"'
when: always
- if: '$CI_PIPELINE_SOURCE == "schedule"'
when: always
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
when: always
- when: never
variables:
PREFIX: '016'
needs:
- testBedlsPowered
- trcvdlsCompilableForPetaLinux
- simlsCompilableForHostLinux
script: >
python3 ./qa/tests/is_testbed_ttff_low.py --param '{"system": ["GPS"], "ttff": 300, "IP": ["192.168.0.117"], "DEV": ["CLONICUS"], "accumulation_time":150, "PLTYPEFINDBIT" : "CI" }' --obj "Прошивка процессорной системы" --prefix $PREFIX --stage $CI_JOB_STAGE --CI_JOB_NAME $CI_JOB_NAME --GITLAB_TOKEN $GITLAB_TOKEN
.artifacts_settings:
artifacts:
when: always
paths:
- qa/reports/$CI_JOB_NAME
- qa/reports/log
- built
- built/petalinux
- built/qnx
- qa/built
- qa/built/petalinux
- qa/built/qnx
- qa/log
expire_in: 2 week
.testbed:
image: navsyslab/sim:v3.3
stage: testbed
cache:
key: $CI_COMMIT_SHORT_SHA
paths:
- qa/cache
- qa/log
- built
- built/petalinux
- built/qnx
tags:
- testbed
resource_group: testbed
before_script:
- mkdir -p ./qa/cache
after_script:
- ls -l qa/cacheЗапуск в docker-окружении позволяет отвязаться от конкретного сервера, на котором будут выполняться проверки (за исключением тестов с аппаратурой). Но самое главное, это позволяет отвязаться от компьютера разработчика и его локальных настроек. Появляется общий знаменатель для настроек компиляторов, синтезаторов и т.д. для всей команды - контейнер.
Сердце каждого тестового скрипта - последовательность шагов, с помощью которых осуществляется проверка. Каждый шаг содержит три блока:
запись описания предстоящих на этом шаге действий в файл методики испытаний method.tex
непосредственно выполнение действия и получение результата
запись результата в файл протокола protocol.tex

Благодаря такой простой организации тестового скрипта описание методики, действия и протокол не расходятся и не содержат воду.
Приложения
При разработке традиционных методик испытаний по ГОСТ 15.211 инженеры не брезгуют выносить повторяющиеся куски испытаний в Приложения к документу. Обычно там скапливаются схемы установок, процедуры настройки лабораторных приборов, процедуры набора статистики и т.д.
В системе автоматического тестирования мы Приложения выделили в отдельные скрипты - apps. Они нужны для того, чтобы:
не дублировать код в скриптах проверок
не дублировать действие, если его результат известен из другой проверки
Половина проверок на требования назначения начинаются с одних и тех же действий: настроить имитатор сигналов на определенную систему, запустить приемник, набрать пять минут логов. А далее проверки отличаются только способом обработки этого лога. Скрипт-приложение позволяет не ждать эти пять минут во второй и последующих проверках, а сразу перейти к обработке лога.

Скрипт-приложение кэширует результат своей работы в отдельной директории для каждого набора входных параметров. Если какая-то проверка обращается к нему, он сначала проверяет, а нет ли у него готового ответа. Если есть, достает из кэша. Если нет, выполняет действия и отдает результат.
Стенд и взаимодействие с лабораторными приборами
В составе стенда мы собрали лабораторные приборы одного производителя - немецкого Rohde&Schwarz:
векторный генератор сигналов с функциями имитации навигационных сигналов SMBV100A,
осциллограф RTM1054,
анализатор спектра FSV3.
")
Векторный генератор используется для имитации выхода ГНСС антенны: навигационных сигналов различных спутников, теплового шума усилителя, помех.
Осциллограф позволяет контролировать точность выдачи приемником метки времени. Она сравнивается с секундной меткой от имитатора сигналов. Контролируется наличие метки и разница моментов прихода меток с субнаносекундной точностью.
Анализатор спектра позволяет оценить чистоту спектра формируемых сигналов, выполнение требований к внеполосным излучениям, уровень мощности и пик-фактор.
Все приборы управляются по локальной сети посредством SCPI команд. Для этого на пайтоне была написана библиотека функций для настройки приборов под сценарии проводимых испытаний, а также получения с них измерений.
Например, так генератор настраивается на имитацию шума ГНСС антенны
def setawgn(self):
self.sendcommand('SOUR:AWGN:STAT OFF')
self.sendcommand('SOUR:AWGN:MODE ADD')
self.sendcommand('SOUR:AWGN:BWID 75e6')
self.sendcommand('SOUR:AWGN:BWID:RAT 1.0')
self.sendcommand('SOUR:AWGN:DISP:MODE RF')
self.sendcommand('SOUR:AWGN:POW:MODE CN')
self.sendcommand('SOUR:AWGN:POW:RMOD NOISE')
self.sendcommand('SOUR:AWGN:CNR -26')
self.sendcommand('SOUR:AWGN:POW:NOISE -44')
self.sendcommand('SOUR:AWGN:BRAT 1023000')
self.opc()
self.sendcommand('SOUR:AWGN:STAT ON')
self.opc()
print(f'SMBV:AWGN set to ADD mode')Что-то даже есть в сети.
Функции библиотеки вызываются либо непосредственно из Проверок, либо из Приложений.
Оформление отчета по ЕСКД и ГОСТ 15.211
На этапе Conclusion отдельные методики и протоколы собираются в два документа:
Программа и методика испытаний
Книга протоколов испытаний

Благодаря LaTeX и нашему шаблону они выглядят на радость нормоконтролеру:

Для этого на этапе проверок и приложений готовятся уникальные tex-файлы и изображения. На последнем этапе они конвертируются в pdf.
Непрерывная интеграция изменений
Результаты испытаний хранятся на сервере и доступны участникам проекта. Мы храним их 120 дней, после чего они автоматически удаляются.

Если программа испытаний провалена, разработчику, сделавшему соответствующий коммит, сразу приходит письмо с сообщением о проблемах. Сокращается время между появлением проблемы в коде и её устранением. В свежей проблеме разобраться намного проще, чем в том, что ты делал несколько месяцев назад.

Когда разработчик выполнил поставленную задачу, он заводит Merge Request для передачи изменений в основную ветку проекта. Успешно выполненные тесты - это необходимое условие для принятия Merge Request'а. Если код и изделие не прошли испытания, изменения не попадут в основную ветку проекта.
Изменения, продержавшиеся в основной ветке до ночи и прошедшие ночные тесты, становятся рабочими для пользователей. На следующий день они получат их из артефактов соответствующего конвейера.
Заключение
Автотесты при разработке сложных радиоэлектронных устройств не только возможны, но и необходимы. Они существенно повышают качество продукта и снимают нагрузку с ключевых разработчиков, позволяют быть уверенным в результате и устранять проблемы сразу после их появления.
Комментарии (26)


lxsmkv
25.06.2022 14:43+2Класс! Больше ничего сказать не могу. Очень все изящно и красиво сделано.
Вы все десять лет шли к этому решению или сколько времени вы работали именно над этим вариантом? Немножко историю эволюции тестирования в этом проекте можете рассказать?
P.S. A и еще, это я так понимаю гос. учереждение. А финансируется проект частниками или из бюджета? Я к чему веду. Просто в коммерческой среде на создание нормальных решений как правило нет времени, нет времени чтобы спокойно все обдумать а потом спокойно все реализовать. В коммерческом секторе нередко все начинается с того что хотят быстро накидать тестовое покрытие, и только потом понимают, что тесты есть - толку нет.

Korogodin Автор
25.06.2022 15:11+2Там в статье есть кат с описанием первых трех вариантов. И даже ностальгические скриншоты. Желание автоматизировать проверки было всегда, т.к. железо/софт сложные и все время стремятся разложиться. Стоит что-то оставить без присмотра - оно обязательно протухнет.
Первые попытки не достигли устойчивого использования, но создали нужные наработки:
- покрытие юнит-тестами
- библиотеки для настройки приборов и получения с них данных
- симуляционное окружение для прошивки
- понимаю узких мест, того, что чаще ломается и что не дает системе прижиться
Пандемия резко обострила потребность в системе автотестирования. Мы стали часто работать удаленно, а надо как-то проверять Merge Request'ы перед вливанием в основную ветку.
Зимний сноубордический сезон 2020/2021 свел меня с синьор-помидор-qa-автоматизатором из Яндекса. Так новогодними вечерами под глинтвейн я подтянул знания о Jenkins, worker'ах и современных системах для решения подобных проблем.
В феврале 2021 мы взяли под разработку автотестов бойкую девушку, мою бывшую студентку. Я включал воображение и проектировал в голове будущую систему, она пыталась это натянуть на Gitlab CI/CD. Судя по git blame, 30 марта 2021 года у нас в основном репозитории программного комплекса появился первый gitlab-ci.yaml. Через некоторое время ей в подаваны взяли ещё 2 человек (ребята ещё студенты-третьекурсники, но толковые).
Новая система прижилась, без неё уже не представляю разработку. В новых проектах, даже если там нет задач по написанию прошивок, первым делом заводим CI.lxsmkv
25.06.2022 16:33+1Там в статье есть кат с описанием первых трех вариантов
Я прочитал этот отрывок но не заострил на нем внимания потому что не увидел взаимосвязи в прогрессии. (Кстати там материал по ссылке на srns закрыт для посторонних) Больше похоже на эксперименты без наличия четкого видения цели. А потом прям принципиальный скачок получился. А теперь я понимаю как это произошло. Это вы с правильными людми поговорили, и они вас "на нужную частоту настроили" :)
Еще такой вопрос, если можно: система подразумевает возможность полностью удаленной работы. Что вы делаете если прошивка запарывает устройство, есть какой-то способ экстренного восстановления работоспособности устройства, без личного присутствия? Или архитектурно сделано так, что прошивкой нельзя запороть устройство до такой степени, чтобы оно перестало принимать прошивки? И вы тогда, например, просто откатываете на базовый образ.Korogodin Автор
25.06.2022 17:21+1Если честно, чаще проблемы с сетью, чем запоротая прошивка. Но совсем на крайний случай, в лабе каждый день кто-нибудь есть, восстановит

victor_1212
Привет Илья, полезная статья, обычно merge является критичной операцией, были бы интересны детали - именно кто отвечает за разрешение возможных конфликтов в коде, и в этой связи взаимодействие разработчиков и project leader
> Когда разработчик выполнил поставленную задачу, он заводит Merge Request для передачи изменений в основную ветку проекта
ps
Apollo 11 Code Review
All the source code has 64.992 lines. There are 40.202 lines of code. There are no files without comments, 31.443 of the lines contain a comment and there are 5900 blank lines used. The software was submitted by 1 person and approved by 6 other people.
https://tecknoworks.com/apollo-11-code-review/
Korogodin Автор
Добрый вечер, Виктор
Перед тем, как заводить MR, разработчик вливает в свою ветку develop и разрешает все конфликты. Получающийся после этого коммит и отправляется на ревью. В этот момент код компилируется, проходит тесты. Если вдруг не проходит, то это задача разработчика поправить все ошибки.
Ревьювер проверяет код на логические ошибки и выполнена ли вообще задача, ради которой заводилась эта ветка. Если есть претензии к конкретным строчкам кода, то можно к ним оставить комментарии и обсудить в ветке Merge Request'а:
Чаще всего их правит разработчик. Но если там какая-нибудь мелочь, то и ревьювер может поправить.
Если ошибки логические или касаются задачи в целом, то их лучше обсуждать в соответствующей issue. У нас там собирается база знаний, схем, и т.п., к которым удобно возвращаться время от времени:
victor_1212
понятно, какой у вас порядок количества разработчиков зависящих от merge, и как часто merge происходит?
ps
типичный размер команды с которым приходилось иметь дело 30-60 человек, merge на основную рабочую ветку проекта каждые 3-4 дня, конфликты кода обычное дело из-за параллельной работы, все спорные вопросы - ответственность несет project leader (один или несколько), примерно так
pps
"wc -l" =newline (\n) countKorogodin Автор
Мержи каждый день по мере завершения работы над issue.
Редко бывает, что разные люди работают над одними и теми же участками кода. Поэтому разработчик, завершив работу над задачей, заводит MR и переходит к следующей задаче, ответвившись от своей же ветки. На схеме выше это 273-E1B-tracking -> 274-E1B-modulation. Либо же к началу работы над новой задачей MR успевают принять, тогда он ветвится от develop
victor_1212
> Редко бывает, что разные люди работают над одними и теми же участками кода
это понятно, причин для конфликта может быть много, просто пытаюсь представить ваш рабочий порядок, наелся всего этого более чем достаточно за долгое время работы
Korogodin Автор
Если конфликт уровня git merge, то кто мерджит, тот и разбирается.
А если конфликт уровня "моё решение лучше твоего", то такого и не бывает. Коллектив небольшой, код пишет дюжина человек. Очень редко пересекаются правки. А если пересекаются, то есть внутренняя субординация и взаимоуважение, разный опыт работы и уровень погружения в проект. До драки ни разу не доходило :)
victor_1212
> код пишет дюжина человек ... есть внутренняя субординация и взаимоуважение, разный опыт работы и уровень погружения в проект.
так примерно и думал, отличается от того к чему привык, т.е. большие довольно опытные команды, примерно 50/50 senior/principal, много нового кода каждый день, QA 24/7 занимается тестированием -> кроме прочего 2-3 bug fixing каждый день на человека, примерно так embedded systems делаются в us
Korogodin Автор
А как PM успевает расписать задачи на 30-60 человек? Или они, разработчики, настолько универсальные бойцы, что могут брать любую задачу из бэклога и начинать работать? Мне последнее тяжело представить в радиотехнике. Когда я пишу issue, я представляю 1-3 человек, кто за неё может взяться. Исходя из прошлого опыта, уровня навыков и текущей загруженности.
Почему бы их не разбить на группы человек по 8-12 и развести по разным подпроектам?
victor_1212
> как PM успевает расписать задачи на 30-60 человек?
отличный вопрос, если PM имеется в виду manager, то его функции несколько другие, больше координация процесса, бюджет, через него идет общение с QA, проведение status meeting, вообще планирование, с технической стороны есть project leader (один или несколько) и consulting engineer (также может быть несколько, часто для нескольких проектов одновременно), собственно они определяют основные спецификации и контролируют качество кода, в начале нового проекта первое, что делает project leader это выясняет кто из инженеров хочет и может в нем участвовать, как правило добровольно, или возможно привлекает со стороны контракторов или новых сотрудников, это обсуждается с sw manager и sw director, когда основные части нового проекта прикрыты людьми или чуть раньше consulting engineer делает архитектурные спецификации и пошло-поехало, в процессе обсуждения спецификации участники проекта делят задачи между собой, в этой фазе конфликты редки, люди как правило знают друг друга долгое время по другим совместным проектам, не уверен ответил ли на Ваш вопрос, так как тема большая
ps
какие именно проекты делать зависит от многих факторов, но это уже уровень sw director и результат обсуждения с другими людьми его уровня
victor_1212
pps
> Почему бы их не разбить на группы человек по 8-12 и развести по разным подпроектам?
структура проектов функциональна, может быть 8-12, а может быть 30 и больше, спецификаций хватает, но обычно никто не расписывает задачи для других в явном виде, как-то без этого обходится, типа с опытом приходит
Korogodin Автор
Дивный новый мир. В российских реалиях для встраиваемого ПО наша команда средняя или даже выше среднего по численности. При этом почти всегда идут несколько проектов параллельно, поэтому эффективная численность снижается. И я говорю не только про госкорпорации, но и про местные r&d центры иностранных компаний. Описываемая вами картина с трудом натягивается у нас даже на Яндекс или Сбер в части веба и корпоративных сервисов, не то что эмбэд. Могу предположить, что ваш опыт касается больших корпораций вроде Broadcom, Qualcomm, Intel, Infineon, Apple и т.д. Там мне пока не приходилось работать.
А вот эти senior/principal, составляющие основную массу разработчиков встаиваемого ПО, какой у них бэкграунд? Это MSc/PhD из EE или MSc CS? Они в курсе предметной области или их дело перевести спецификацию в код? Как именно работает система знает только consulting engineer? Насколько глубоко тогда consulting engineer и лиды расписывают спецификации? В духе "нам нужно дополнить систему таким-то режимом, вон описание от IEEE, действуй" или "нужно разработать функцию с именем x, входные и выходные интерфейсы y, тестовые сценарии такие-то, ограничения на память такие-то и т.д."?
В описываемую группу входят разработчики логических модулей (кремния или плис)? Или вы готовите ПО уже под готовый кристалл?
victor_1212
приходилось работать в разных компаниях, но хорошего уровня начиная с digital, все время embedded, в основном для сетей, практически с самого начала, вопросы заданы интересные, попробую ответить (в меру сил) -
> senior/principal, составляющие основную массу
образование уровня физтеха или mit, средний опыт 10-15 лет, как правило MS computer science, последнее время все чаще одновременно MS типа electrical engineering (жизнь заставляет), в общем серьезные люди способные работать самостоятельно, предметную область все знают по-разному, но на достаточно детальном уровне, людей уровня "перевести спецификацию в код" обычно не держат, если требуется что-то в этом роде - это дело контрактников, типа какой-нибудь редкий porting сделать, ничего ответственного им не поручают,
> Как именно работает система знает только consulting engineer?
consulting engineer это типа свободный художник, mentor, например заслуженный project leader, иногда держатель оригинальных патентов на что-нибудь, его роль передача опыта, часто присматривает за несколькими проектами одновременно, отвечает в том числе за выбор перспективной технологии на будущее, всключая hw архитектуру, asic и пр.,
в части понимания работы системы - обычно понимают все (возможно на разном уровне детализации), для крайних случаев больших систем - пытаются понять все, но не у всех получается, примерно так :)
> Насколько глубоко тогда consulting engineer и лиды расписывают спецификации
как требуется для понимания работы, но все интерфейсы довольно детально, сильно зависит от конкретного проекта, но информация никогда не дублируется, типа ссылка на соответствующие rfc, этого достаточно, если предлагается что-то новое, тогда все детали,
> "нужно разработать функцию с именем x, входные и выходные интерфейсы y, тестовые сценарии такие-то, ограничения на память такие-то и т.д."
обычно нет, но бывают исключения если ресурсы ограничены, типа для основного рабочего цикла, могут быть детальные временные оценки требуемой производительности, времени реакции и тп. , если к примеру закрытые прерывания влияют, это рассматривается детально, включая измерения,
> В описываемую группу входят разработчики логических модулей
нет, это отдельно, обмен спецификациями и взаимодействие есть как требуется, но в общем случае на уровне project leader
Korogodin Автор
А теперь главный вопрос: как собрать 30-60 выпускников MIT с опытом 10-15 лет, способных работать самостоятельно, в одну компанию на линейные должности? Почему они при таком бэкграунде всё ещё не лиды, CTO, consulting engineer'ы? Не могут же таких людей мотивировать только деньги, должно быть что-то ещё.
Они выращиваются в компаниях второго эшелона и рассматривают возможность поработать в таком коллективе как промежуточный шаг? Или это MIT и привлекательность США так фильтрует кандидатов? Может это нежелание заниматься менеджерской рутиной и любовь к своему делу? Или возможность прикоснуться к большому проекту и увидеть результат своего труда во всех магазинах?
Если проецировать на мою индустрию, спутниковую навигацию, то на всю Россию людей подобных качеств примерно столько, сколько у вас в одной описываемой команде. Обычно это лиды отдельных коллективов, на которых держатся целые компании или отделы. В коллективы очень редко кто-то приходит с улицы на полноценные рабочие позиции, чаще это выращивание людей со студенчества с постепенным расширением зоны ответственности.
victor_1212
> главный вопрос: как собрать 30-60 выпускников MIT с опытом 10-15 лет
"образование уровня физтеха или mit" необязательно получено в mit, в us порядка 20 университетов и колледжей примерно такого уровня (включая stanford и пр.), но вопрос правильный, imho комбинация интересной работы и относительно высокой компенсации включая stock options, заметим vesting которых зависит от стажа работы, бонусы работают также, конечно сильно амбициозные люди уходят и приходят, но в разумных пределах
Korogodin Автор
Я использовал следующую методику: