

Привет, Хабр! Меня зовут Белков Евгений, я тимлид одной из команд разработки Siebel CRM в Московском кредитном банке.
Все мы регулярно сталкиваемся в работе с агрегацией данных, формированием отчетов и ведением статистики. И еще мы часто используем всем удобный и известный инструмент для визуализации собранных данных – Excel! Но в этой статье я расскажу об альтернативном варианте, менее функциональном, но довольно простом и понятном тому, кто привык пользоваться Confluence.
Что мы хотим вообще сделать
У нас есть матрица, которая имеет определенный шаблон. По массиву заполненных шаблонов нужно сделать автоматизацию расчета оценок в разных разрезах, например, команда или должность. Потом по сводным данным сделать простые диаграммы – они воспринимаются лучше, чем просто таблица.
Для начала сразу определим, чем плох Excel. Ничем! Почти. Это крутой инструмент, у него много возможностей, много различных вариантов для построения графиков и диаграмм. Но в определенный момент становится не очень удобно актуализировать файл, да еще и так, чтобы в реальном времени, без пересчета макросов, получать актуальную информацию и визуализацию. Это было основной причиной, почему я стал в присматриваться к Confluence.
Самый первый этап подразумевает построение схемы объектов. На нем сразу определяем , что у нас есть шаблон, на основе которого будет сформировано множество страниц, сводная таблица, и массив отчетов, которые будут ссылаться на готовый свод.

Со схемой использования данных определились, приступим.
Что мы уже имеем
Отлично, мы уже поставили себе цель и сделали выбор в пользу Confluence. Нарисовали схему, а теперь давайте поймем, что у нас есть на входе.
У нас есть порядка 10 команд (количество меняется в связи с расширением).
В каждой команде от 1 до 6 человек (так же свойственно менять).
Есть некоторый скелет шаблона с навыками (выглядит примерно так). Синим выделил часть, которая не должна меняться, так как это влияет на формируемый свод.
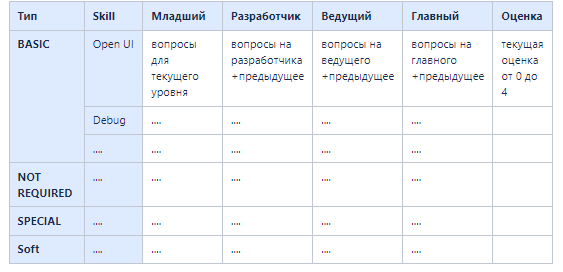
Часть 1. Адаптируем шаблон
7 раз проверь - один раз в прод
Чем раньше мы сделаем полноценную постановку требований к шаблону, тем меньше нас ждет рефакторинга в дальнейшем. Простыми словами, если мы сначала сделаем сбор данных, например по 30 сотрудникам, а потом поймем, что нам нужно его доработать, то нужно будет по 30 страницам пробежаться и поменять шаблон, а это драгоценное время.
Так как мы хотим получать данные в определенных разрезах и фильтровать по команде и должности, сверять с эталонной оценкой, надо добавить следующие колонки в шаблон, где:
Команда – это бизнес-команда, к которой он привязан;
Должность – здесь все очевидно;
ФИО – имя разработчика;
-
Эталонная оценка – это по сути верхняя планка по оценке для текущей должности (0 – нет необходимости в знаниях, 1 – соответствует младшему разработчику , 2 – разработчику, 3 – ведущему разработчику, 4 – главному разработчику).

Часть 2. Сбор данных
Проходим долгий и мучительный этап собеседований, заполняем матрицу навыков со всеми сотрудниками и для каждого создаем отдельную страницу из шаблона в Confluence. Сразу отмечу, что в Confluence есть возможность создавать свой шаблон, но это требует права администратора. Дальше при создании новой страницы содержимое можно заполнять из готового шаблона. Можно, конечно, пойти и по старому протоптанному пути, Ctrl+C Ctrl+V, но мы же с вами хотим все оптимизировать сразу, оставив Monkey Job кому-нибудь другому.
В итоге получаем примерно 50 страниц. Желательно их сразу создавать в одном пространстве и под одной страницей, чтобы потом было проще их искать. Как вариант воспользоваться функцией создания "Шаблона".
Часть 3. Собираем сводную таблицу
Итак, мы наконец-то имеем всю информацию по каждому отдельному человеку. Так выглядит иерархия страниц:

На родительской странице «Результаты Assessment» добавляем макрос «Сводная таблица», пока без всяких настроек.
Получаем пустой макрос, который может сделать свод по таблице внутри. Но теперь самое интересное: как нам положить в нее 50 гигантских таблиц с результатами матриц?

Все просто, нам не нужно их копировать из источника, так как в таком случае пришлось бы постоянно менять значения в двух местах, а нам нужна автоматизация пересчета в реальном времени.
Внутрь сводной таблицы добавляем макрос «Включить страницу», в которой указываем название страницы из списка выше. Допустим, что это макрос «...Алексей Юрьевич», и повторяем это действие со всеми страницами компетенций сотрудников.

В итоге получаем такую красоту и сохраняем.

Сразу оговорюсь, что чем больше страниц, тем больше будет «глючить» система. Такой вариант подходит либо для расчета небольших команд, либо максимум для 50-70 человек. Больше данных – больше лагов Confluence.
Теперь надо настроить сводную таблицу, чтобы можно было по ней строить графики. Для этого определяем типы фильтрации статистики. Я выбрал такие.

Не забываем сохранить, чтобы в следующий раз страница не потерла изменения при обновлении.
Как итог у нас вполне симпатичный свод в разрезе навыков и команд по типам навыков с суммой оценок и средним коэффициентом.

Часть 4. Визуализация (построим диаграмму из свода)
Создаем новую страницу или редактируем верхнеуровневую. В моем случае это новая страница FINS.
Добавляем макрос «Диаграмма из таблицы» и внутрь него «Фильтр таблиц».

Затем внутрь последнего помещаем еще один макрос «Включить страницу», в котором выбираем страницу, созданную в части 3 «Результаты Assessment».
В диаграмме важно на первых порах оставить настройку «Скрыть исходную таблицу» в таком положении.
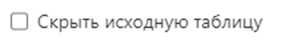
У фильтра выбираем настройку столбцов для фильтрации.

Также советую сразу выбрать панель для фильтрации, но учтите, что в некоторых сводных таблицах фильтрация на колонках не работает, поэтому иногда придётся жертвовать красотой ради функциональности.

Результат будет выглядеть примерно так
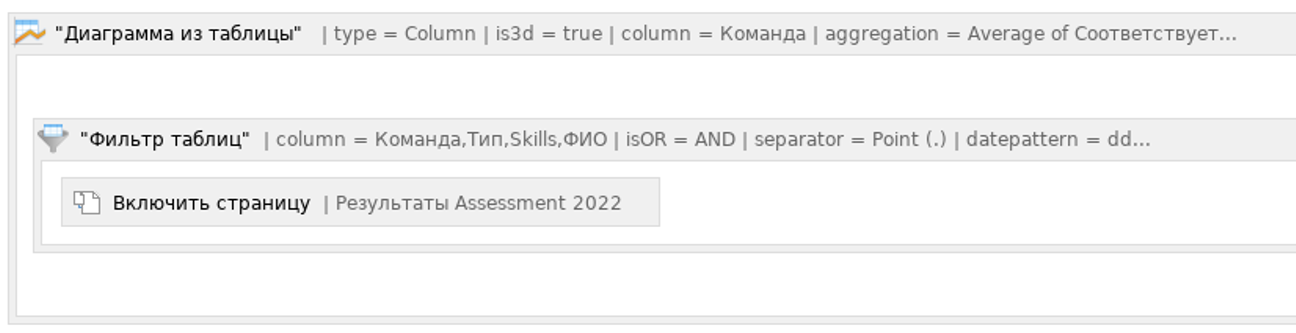
Сохраняем все остальное без настройки. Диаграмма отображается пустой, фильтр тоже пустой, при этом значения подгружаются с уже созданной ранее страницы.
Добавляем на диаграмме
Тип диаграммы (вариантов там немного, но стандартных вполне хватает, хотя и графика не хватает).
Столбцы подписей (по сути это разрез, в котором данные будут отфильтрованы).
Столбцы для расчета (тут просто по каким полям считаем).
Не забываем сохранить!

Если нам нужно ограничить данные, то ниже есть таблица, при фильтрации по которой график будет перестраиваться.
К примеру, сейчас расчет сформирован по всем типам навыков, а я хочу посчитать только по одному «Оценке поставленной задачи».
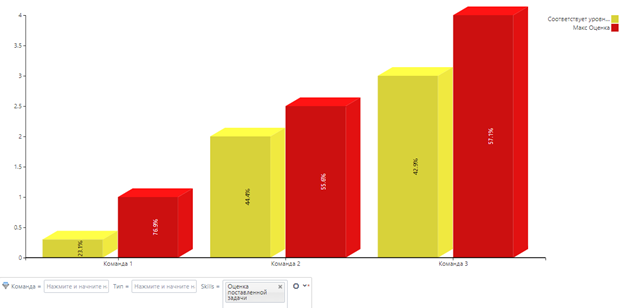
Часть 5. Индивидуальные оценки
В предыдущих частях мы рассмотрели командный сбор оценок. Но вы спросите, а зачем мы добавляли тогда колонку ФИО, но не посчитали ничего по ней.
Давайте рассмотрим, как посчитать автоматически личные оценки.
По сути, мы так же добавляем сводную таблицу и включаем в нее все те же страницы с результатами.

Но теперь мы делаем фильтрацию по команде и ФИО. При сохранении получаем готовую матрицу с оценками.

То же самое и с другими разрезами, например, по должности.
Заключение
При наличии готового шаблона можно легко и быстро сделать свод из данных внутри этих страниц.
При этом важно учитывать и минусы, и плюсы.
Минусы
Возникают «глюки» Confluence при больших объемах данных и количестве обрабатываемых страниц (больше 50).
Нужно соблюдать типизацию шаблонов. Если название в одной странице поменять у какого-то Skills, то на выходе будем иметь кривую сводную. Именно поэтому не стоит отходить от шаблона, либо нужно менять название на всех страницах.
При включении содержимого важно учитывать, что включаются все переносы строк, заголовки и прочий текст. В итоге страница может стать очень длинной, так что рекомендую хранить на страницах только одну таблицу без всего лишнего, либо пользоваться макросами "Выборка" и "Включить выборку", чтобы ограничить только нужный контент страниц.
Функционал Confluence в качестве построения диаграмм и графиков не сильно впечатляет, так что этот вариант подходит лишь для простых агрегаций или для сбора сводных таблиц.
Для покрытия расчета матрицы компетенций подходит, но при увеличении численности команд придется либо упрощать шаблон, либо разбивать на команды.
При визуализации диаграммы иногда съезжают из-за автоматического расчета «Итого», и получается не очень читабельная картинка. До Excel, далеко.
В Confluence нет возможности встроить формулы в расчет.
Плюсы
Наличие 2-х таблиц на заполненных страницах – это не проблема. Можно собирать данные по любой из них, если каждую из таблиц поместить в свой макрос «Свойства страницы», и присвоить ему ID. В этом случае таблиц на странице может быть сколько угодно, а собирать данные необходимо с учетом присвоенного ID макроса «Свойства страницы», содержащего нужную таблицу.
При появлении новых страниц по сотрудникам достаточно добавить включения содержимого этих страниц в расчет, и Confluence применит их на своде.
Вся информация находится в общем пространстве, любой может поменять данные, посмотреть актуальные и сформировать необходимый сводный отчет на основе этих данных.