
В интернете достаточно статей на тему «как обучить custom dataset на yolo».
Что скрывается за этими словами?
Ничего сверхестественного. Собираем или находим где-нибудь датасет, размечаем его, создаем файл аннотаций к картинкам. Далее берем одну из предобученных моделей yolo, обучаем эту модель на собственном датасете и далее наслаждаемся результатом.
Есть конечно, свои нюансы от yolo к yolo (которые уже определяются семействами в своих версиях, например, той же yolov5 порядка десяти вариантов моделей), но, в целом, порядок действий такой.
Все так. Однако модель, обученная на собственном датасете, будет определять только те классы, которые в нее заложили. Например, только дым и огонь.
При этом известно, что в датасете, на котором она обучалась, например Microsoft COCO в ситуации с YOLOX, «остались» еще 80 классов, которые также хотелось бы использовать в своих целях определения объектов на изображении.
Кроме того, попутно возникает вопрос: как убрать лишние классы из датасета Microsoft COCO? Потому как, определять на изображении автобусы и людей и одновременно тарелки и ножи, не каждому нужно.
Поэтому структура работы предлагается следующей:
- Возьмем какой-нибудь уже размеченный custom датасет. Для усложнения задачи, пусть он будет в другом формате (например Pascal VOC — формат данных, используемых в YOLOv5), конвертируем его в формат COCO (формат данных для целей модели yolox).
- Скачаем Microsoft COCO и «почистим» его от ненужных классов.
- «Склеим» свой датасет с Microsoft COCO.
- Обучим модель yolox на вновь созданном наборе данных и проверим как работает модель.
Свой собственный датасет.
Существует несколько вариантов:
- обрать свой собственный датасет;
- найти готовый.
Для первого варианта хотелось бы посоветовать opensource (почти) платформу roboflow.
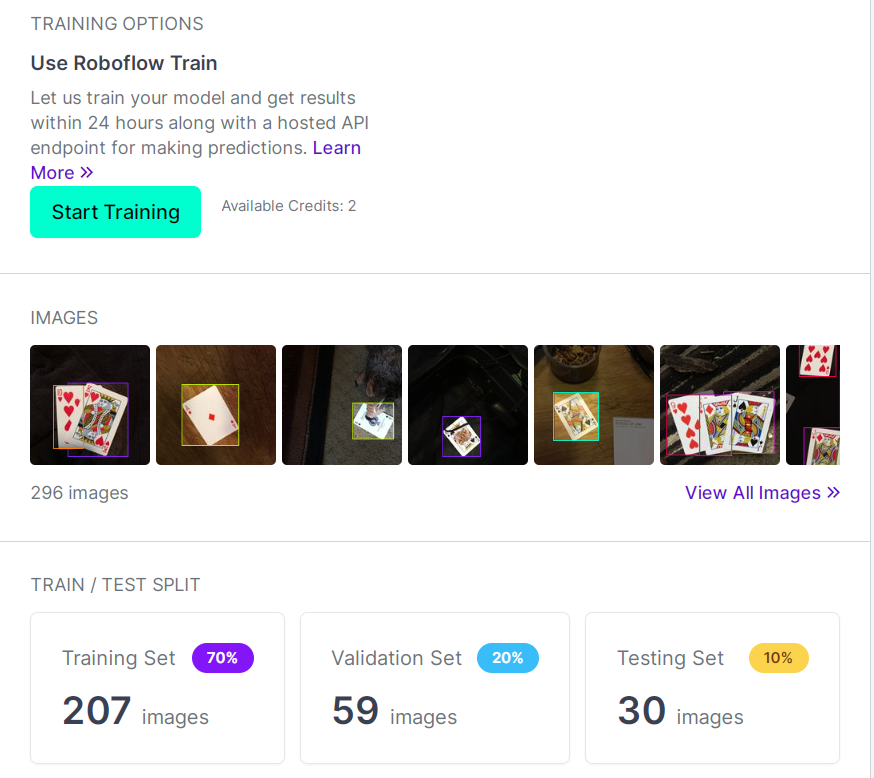
Автор не имеет к ее разработке никакого отношения, но хотелось бы поблагодарить ее создателей, так как работать с ней крайне удобно: загружаешь данные (картинки с аннотациями или просто картинки), система может сама наглядно показать где ошибки в аннотациях или пропуски, разбить данные на выборки (train, val, test), произвести аугментацию во всех ее ипостасях, обучить модель на месте, выгрузить данные в удобном формате coco,pascal и т.д.
Есть и минусы: если денежку за пользование не платите, то действует ограничение на размер датасета в 10тыс. картинок и то, что ваш датасет становится «народным» достоянием и любой может его скачать с roboflow.
*Автор набросал небольшой парсер и снял срез из 10тыс. наименований датасетов с roboflow. Но, к сожалению, доброкачественных из них десятки — скачать.
На этом данный пункт, можно было бы и закончить: загрузили датасет в roboflow, по желанию выполнили аугментацию, конвертировали в coco формат, выгрузили.
Однако, как показала практика, нельзя просто взять и выгрузить датасет в coco через roboflow.
Несмотря на внешнее сходство, аннотации после выгрузки «не дружат» с форматом, который принимает yolox. Поэтому, желательно выгружать в формате pascal voc и далее использовать ручной способ конвертации:

Мы воспользуемся ранее созданным и размеченным датасетом, в котором будут двери и лестницы как классы. Именно эти два класса мы добавим к существующим классам Microsoft COCO, при этом, для примера, выбросив оттуда «ненужные» классы.
Датасет с дверями и лестницами в формате Pascal VOC можно скачать отсюда — датасет.
Формат, котором представлен датасет «достался» от yolov5.
В общих чертах данный формат данных (Pascal VOC) представляет из себя следующее:
— к каждой картинке прилагается отдельный xml файл, который ее описывает;
— существует также единый файл с расширением, который просто перечисляет те классы, которые используются. В нашем случае выглядит так:
doors_and_stairs_map.pbtxt
item {
id: 1
name: 'door'
}
item {
id: 2
name: 'Stairs'
}
id: 1
name: 'door'
}
item {
id: 2
name: 'Stairs'
}
Данные разделены на train/val/test выборки, к train и val есть папки с аннотациями. Всего порядка 10тыс. файлов (картинок) этого вполне достаточно, чтобы классы не перекрывались классами из датасета Microsoft COCO, представители которых также исчисляются тысячами.
Если взять слишком маленький датасет, то его представители не будут определяться моделью, возникнет дисбаланс классов.
Конвертируем из Pascal VOC в coco формат.
Для обучения yolox нужен формат данных coco. Это, как правило, два json файла c аннотациями (один для папки с картинками из train, второй — validation папки). По сути, все то, что содержится в xml файлах (к каждой картинке), которые используют yolov5 модели должно перекочевать в 2 json файла, которые использует yolox.
Этапы конвертации
*Для датасета двери, лестницы все нижеперечисленные шаги уже выполнены.
1. После распаковки датасета с дверями и лестницами, в корне необходимо создать простой labels.txt c классами, которые используются в датасете. В нашем случае door и Stairs. При этом важно, чтобы сохранялся синтаксис названий классов и каждый класс — с новой строки.
2. Создать папки train2017, val2017,train_annotations, val_annotations. В которых будут аннотации и картинки отдельно друг от друга.
3. Создать два txt файла: train.txt и val.txt (для train и val папок), в которых в будут имена файлов в столбец без расширений:
cam_image1
cam_image1
cam_image1
cam_image10
Небольшой help-code для этого —
code
import os
directory = 'doors/images/train'
file_out='train.txt'
for file in os.listdir(directory):
if file.lower().endswith(".jpg"):
with open(file_out, 'a') as f:
f.write(f'{file.split(".")[0]}\n')4. Конвертировать в coco формат папки train и val:
python voc2coco.py --ann_dir doors-and-stairs-dataset/train_annotations --ann_ids doors-and-stairs-dataset/train.txt --labels doors-and-stairs-dataset/labels.txt --output doors-and-stairs-dataset/coco_instances_train.json --ext xmlpython voc2coco.py --ann_dir doors-and-stairs-dataset/val_annotations --ann_ids doors-and-stairs-dataset/val.txt --labels doors-and-stairs-dataset/labels.txt --output doors-and-stairs-dataset/coco_instances_val.json --ext xmlКонвертер — voc2coco.py
В результате получаются два файла json (coco_instances_train.json, coco_instances_train.json), которые вместе c папками train и val (в которых картинки) понадобятся для дальнейшего обучения в составе классов Microsoft COCO. Папки с xml файлами больше не нужны.
Скачать готовые json — здесь.
2. Скачаем Microsoft COCO и «почистим» его от ненужных классов
Датасет Microsoft COCO расположен по ссылке. Там же можно почитать о его структуре, ознакомиться с api. Нас интересует coco 2017, картинки с аннотациями.

Test выборку можно не скачивать, это просто картинки, на которых можно будет проверять уже готовую модель. Вместо картинок из test можно брать абсолютно любую картинку из интернета.
В аннотациях, которые являются json файлами нам понадобятся только instances_train2017.json и instances_val2017.json.
Заглянем в один из них, чтобы получить представление о структуре данных:
read_jsons.py
import json
from time import sleep
with open('instances_val2017.json') as json_file:
data = json.load(json_file)
for i in data['categories']:
print(i['name'])
#for i in data['annotations']:
#print(i)
#for i in data['images']:
#print(i)
Таким нехитрым способом можно посмотреть категории (классы), аннотации к ним, описания картинок. Эти сведения понадобятся в дальнейшем, когда будем объединять классы.
А пока отфильтруем Microsoft COCO, выбросив ненужные классы.
Фильтруем Microsoft COCO
Чтобы отфильтровать классы нужно выполнить файл filter.py со следующими аргументами:
python filter.py --input_json /annotations/instances_train2017.json --output_json /annotations/filtered_train2017.json --categories person dog catПри этом перечислить классы, которые оставить. Если класс состоит из двух слов, например wine glass, то его необходимо заключить в "". В примере выше мы оставляем только person, dog и cat классы. Но, чтобы не было путаницы, я исключу из coco меньше классов, сохранив следующие:
код
*Не будут найдены классы sofa tv monitor, но это не страшно.
python filter.py --input_json instances_train2017.json --output_json train2017_filtered.json --categories car orange banana "wine glass" sandwich bottle vase bicycle fork sofa umbrella toothbrush keyboard book mouse cat bed cup spoon microwave "cell phone" "tv monitor" carrot "teddy bear" "sports ball" knife scissors laptop oven remote sink backpack bench dog "dining table" chair handbag bowl toilet "hair drier" refrigerator "potted plant" clock person suitcase apple *Не будут найдены классы sofa tv monitor, но это не страшно.
Этот же код необходимо выполнить и для instances_val2017.json:
код
python filter.py --input_json instances_val2017.json --output_json val2017_filtered.json --categories car orange banana «wine glass» sandwich bottle vase bicycle fork sofa umbrella toothbrush keyboard book mouse cat bed cup spoon microwave «cell phone» «tv monitor» carrot «teddy bear» «sports ball» knife scissors laptop oven remote sink backpack bench dog «dining table» chair handbag bowl toilet «hair drier» refrigerator «potted plant» clock person suitcase apple
Готово!
Проверим ранее использовавшимся read_jsons.py вновь созданные файлы (любой из них). Должно остаться 44 класса coco из 80.
3. «Склеим» свой датасет с Microsoft COCO
Чтобы понять как происходит склейка, нужно заглянуть в файл аннотаций с помощью read_jsons.py
with open('filtered_val.json') as json_file:
data = json.load(json_file)
for i in data['categories']:
print(i) Код покажет, что категории идут по порядку:
{'supercategory': 'person', 'id': 1, 'name': 'person'}
{'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'}
{'supercategory': 'vehicle', 'id': 3, 'name': 'car'}
{'supercategory': 'outdoor', 'id': 4, 'name': 'bench'}
А вот как выглядят категории в созданном json для custom dataset «Двери и лестницы»:
{'supercategory': 'none', 'id': 1, 'name': 'door'}
{'supercategory': 'none', 'id': 2, 'name': 'Stairs'}
Следовательно, если просто склеить два json, то категории наложатся друг на друга, а с аннотациями и самими картинками будет путаница. Поэтому нужно сначала преобразовав json custom датасета «сдвинув» id классов.
Все было бы достаточно просто, если бы не одно «но», точно два «но».
Аннотации, id картинок в json файлах также подлежат изменению и вот краткая памятка:
##"categories":
#2 класса
##{'supercategory': 'none', 'id': 1, 'name': 'doors'} #заменить id 1 на id 45
##{'supercategory': 'none', 'id': 2, 'name': 'Stairs'} #заменить id 1 на id 46
##"annotations":
##{'area': 38280, 'iscrowd': 0, 'bbox': [311, 29, 174, 220], 'category_id': 2, 'ignore': 0, \
#'segmentation': [], 'image_id': 2, 'id': 1} #заменить category_id (см выше) и image_id (image_id*1000000)
#"images":
#{'file_name': 'cam_image2.jpg', 'height': 540, 'width': 960, 'id': 2} #заменить id (image_id*1000000)К счастью, удалось написать скрипт, который сам все меняет, но необходимо вручную указывать множитель в строке image_id*1000000. Далее на примере будет понятнее.
Преобразование json custom датасета перед склейкой с Microsoft COCO
Преобразуем файлы аннотаций custom датасета «Двери и лестницы»:
convert_jsons.py
import json,os
from time import sleep
#сдвиг по классам
n=44 # 44- указать последний номер класса в датасете coco сейчас
x1,x2,x3=100000,200000,1000000 #указать порядковые номера картинок
in_file='doors_stairs_train.json'
out_file='doors_stairs_train_out.json'
in_file2='doors_stairs_val.json'
out_file2='doors_stairs_val_out.json'
def transform(in_file,out_file):
with open(in_file) as json_file, open(out_file,'w') as out_file:
#with open('fromCOCO_cat_dog.json') as json_file:
data = json.load(json_file)
#меняем классы в "categories"
for i in data['categories']:
i['id']+=n
#print(i['id'])
#for i in data['categories']:
#print(i)
#меняем классы и id в "annotations"
for i in data['annotations']:
i['category_id']+=n
i['image_id']+=x1 #1000000 взято с потолка, просто, чтобы номера не пересекались с номерами из COCO, где ~700000 картинок
i['id']+=x2 ##100000 взято с потолка, просто, чтобы номера не пересекались с номерами из COCO
#for i in data['annotations']:
#print(i)
#меняем id в "images"
for i in data['images']:
i['id']+=x3 #1000000 взято с потолка, просто, чтобы номера не пересекались с номерами из COCO, где ~700000 картинок
#for i in data['images']:
#print(i)
json.dump(data, out_file)
transform(in_file,out_file)
transform(in_file2,out_file2)
os.remove(in_file)
os.remove(in_file2)
Здесь необходимо обратить внимание на вступительную часть:
n=44 # 44- указать последний номер класса в датасете coco сейчас
x1,x2,x3=100000,200000,1000000 #указать порядковые номера картинок
in_file='doors_stairs_train.json'
out_file='doors_stairs_train_out.json'
in_file2='doors_stairs_val.json'
out_file2='doors_stairs_val_out.json'
В дальнейшем добавляя новые классы, необходимо менять n и x1,x2,x3, увеличивая последние на 10 000 (по сути это количество картинок в датасете, чтобы они не перекрывали id других картинок). Если картинок в новом custom датасете больше, то x1,x2,x3 нужно также увеличить «с запасом».
После выполнения конвертации, опять же, можно проверить конвертированные jsons. Будет видно, что категории, аннотации, параметры картинок в аннотациях изменились:
{'supercategory': 'none', 'id': 45, 'name': 'door'}
{'supercategory': 'none', 'id': 46, 'name': 'Stairs'}
Склеиваем с Microsoft COCO
Осталось самое интересное. Приклеить к датасету coco свой custom датасет, тем самым расширив количество классов.
Здесь на помощь приходит еще один скрипт, который посчастливилось написать:
join_jsons.py
import json,os
from time import sleep
json_one='44_coco_train.json'
json_two='doors_stairs_train_out.json'
out_file='coco46_train.json'
json_one2='44_coco_val.json'
json_two2='doors_stairs_val_out.json'
out_file2='coco46_val.json'
def transform(json_one,json_two,out_file):
with open(json_one) as json_one, open(json_two) as json_t:
data1 = json.load(json_one)
data2 = json.load(json_t)
#объединили категории
data1['categories'].extend(data2['categories'])
data1['annotations'].extend(data2['annotations'])
data1['images'].extend(data2['images'])
with open(out_file, 'w') as out_file:
json.dump(data1, out_file)
transform(json_one,json_two,out_file)
transform(json_one2,json_two2,out_file2)
os.remove(json_two)
os.remove(json_two2)
Здесь надо быть внимательным, чтобы не склеить val с train:
json_one='44_coco_train.json'
json_two='doors_stairs_train_out.json'
out_file='coco46_train.json'
json_one2='44_coco_val.json'
json_two2='doors_stairs_val_out.json'
out_file2='coco46_val.json'
На выходе получаем готовые файлы аннотаций для дальнейшего обучения модели yolox уже на 46 классах, включая наши собственные.
Готовые файлы аннотаций — скачать.
И еще один важный момент.
Необходимо скопировать все картинки custom датасета в картинки coco датасета. Train custom датасета в train coco, val custom датасета в val coco.
А как же имена файлов?
С высокой долей вероятности имена файлов не будут пересекаться между собой. А привязка к картинкам по id указана в аннотациях, которые мы только что разобрали.
Продолжение следует.

pingvin1991
Уважаемый автор, а когда можно ожидать? --> 4. Обучим модель yolox на вновь созданном наборе данных и проверим как работает модель.
zoldaten Автор
Постараюсь в самое ближайшее время. Как работает модель можно на видео в посте посмотреть.
Спасибо, что читаете.