

Оказывается, в Кыргызстане, который в 11 веке стоял аккурат посередине Великого шёлкового пути, спустя тысячу лет появились проектировщики цифровых схем на уровне регистровых передач. Во время семинара «Модели бизнеса и основы технологий микроэлектроники для Центральной Азии» мы встретились с инженерами Азаматом Бексадаевым и Бахтияром Кукановым, которые принимали участие в разработке двух блоков на верилоге для международного проекта Parallella. Этот проект был инициирован американской компанией Adapteva, которая сейчас превратилась в Zero ASIC.
Основой технологии Adapteva была решетка из большого количества процессорных ядер внутри одной микросхемы. Ядра имели собственную архитектуру под названием Epiphany и были оптимизированы под энергоэффективные вычисления с плавающей точкой. По микроархитектуре каждое ядро было суперскаляром с двойной выборкой и последовательным выполнением (в википедии ошибка, она говорит, что Epiphany был суперскаляр с внеочередными выполнением инструкций (out-of-order – OoO). Последовательное выполнение для энергоэкономного CPU логично: in-order ядра примерно вдвое энергоэффективнее, чем out-of-order.
Архитектура не использовала когерентные кэши, вместо это в ней было разделённое глобальное адресное пространство, с локальными памятями при каждом ядре. При этом, всю конструкцию можно было программировать на Си, хотя программисту стоило понимать, что он делает. Инструкции и стек выполнения для каждого ядра должны были находиться в локальной памяти, но вот данные могли быть в разных местах: локально, в памяти других ядер, или вообще во внешней памяти вне чипа. Скорость доступа разумеется зависела от местанахождения данных.
Целью технологии было построить своего рода встроенный суперкомпьютер, в котором помимо решетки из 1024 ядер на чипе – можно было бы строить еще и решетку следущего уровня, из многих таких чипов, вплоть до миллиарда ядер. Adapteva выпустила несколько чипов на TSMC, в том числе чип на 16 нанометров в 2016 году. Деньги в проекте были от кикстартера, венчурных капиталистов и американских военных. Adapteva также вероятно пыталась продать компании Ericcson идею использовать Epiphany для распознавания речи и лиц в сотовых телефонах, судя по упоминанию Эриксона и раcпознавания в разных материалах (1, 2).
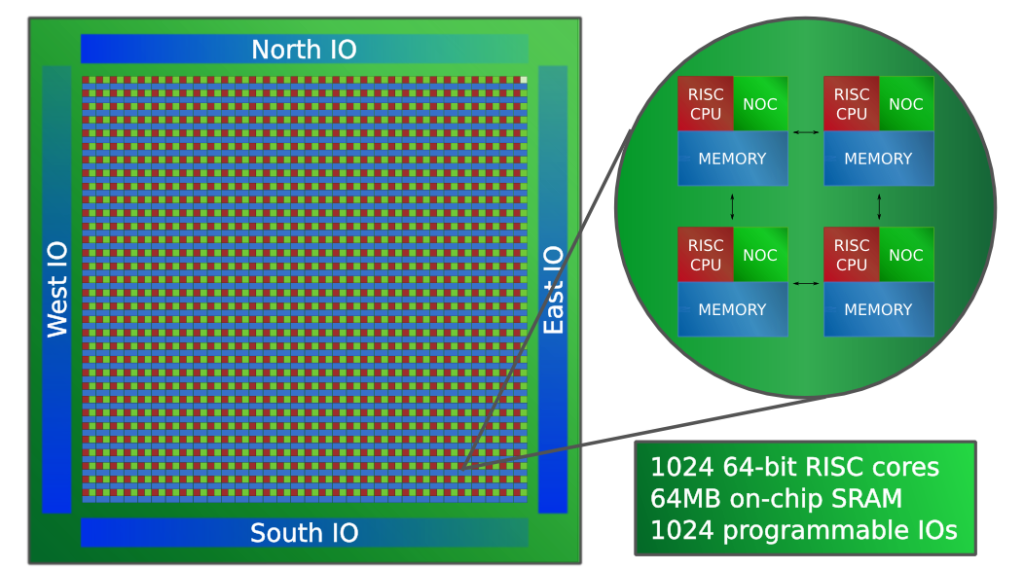
Плата Parallella, которую Adapteva пробовала раскрутить через Kickstarter для энтузиастов новых технологий вычислений, включала не только чип с ранней версией решетки процессоров Epiphany, но и более мейнстримный чип Xilinx Zynq, а также другие компоненты, в том числе порт Ethernet. Чип Zynq, с которым в основном работали Азамат Бексадаев и Бахтияр Куканов, представляет из себя комбинацию из двухядерного процессора ARM Cortex A9 – c матрицей из ячеек реконфигурируемой логики – Field-Programmable Gate Array – FPGA, которые по-русски принято называть Программируемые Логические Интегральные Схемы – ПЛИС.

Хотя ПЛИС работают как правило на более низкой частоте, чем ASIC (фиксированные микросхемы, Application-Specific Integrated Circuits), а также требуют больше ресурсов (площади на кристалле, электроэнергии), ПЛИС из-за их возможности меняться на лету широко применяют для обучения проектировщиков микросхем, для прототипорования ASIC-ов и для некоторых малосерийных изделий. Пара слов о сущности ПЛИС из другой моей заметки на Хабре:
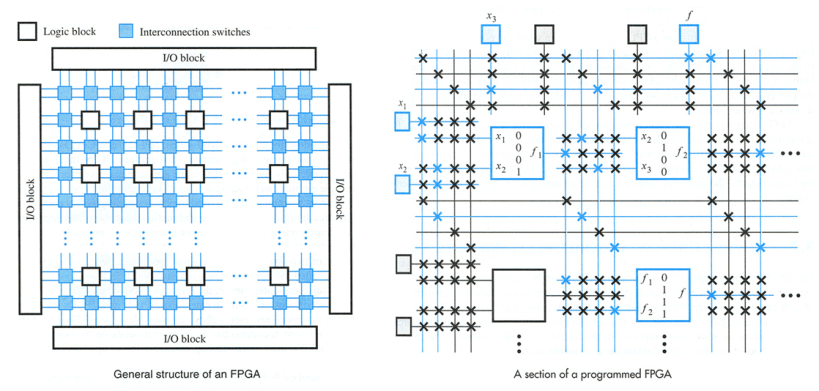
В самом простом варианте FPGA состоит из матрицы однородных ячеек, в функцию каждой из которых можно поменять с помощью мультиплексоров, подсоединенных к битам конфигурационной памяти. Одна ячейка может стать гейтом AND с четырьмя вводами и одним выводом, другая — однобитным регистром и т.д. Загружаем в конфигурационную память последовательность битов из памяти — и в FPGA образуется заданная электронная схема, которая может быть процессором, контроллером дисплея и т.д.
ПЛИС-ы / FPGA — не процессоры, «программируя» ПЛИС (заполняя конфигурационную память ПЛИС-а) вы создаете электронную схему (хардвер), в то время как при программировании процессора (фиксированного хардвера) вы подсовываете ему цепочку написанных в память последовательных инструкций программы (софтвер).
Внизу — схема простейшего блока FPGA, в который входит look-up table (LUT) и flip-flop. Правда в этой схеме не показаны мультиплексоры, которые меняют функцию ячейки, и соединения с конфигурационной памятью.

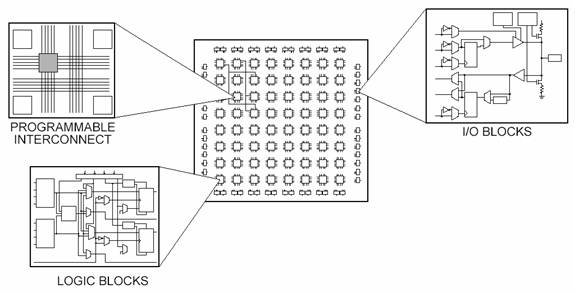
Диаграммы, иллюстрирующие структуру FPGA:
И еще одна:
Какую же именно схему реализовывал Азамат Бексадаев на Zynq FPGA а проекте Parallella? Два блока, которые Азамат описал в своем профайле на LinkedIn: контроллер флеш-карты памяти и аппаратный grep, обработка текста хардвером. Я тоже когда-то писал про обработку текста схемой без процессора в заметке “Как делать парсинг текста голым хардвером, без процессора и без софтвера”, но у Азамата задача горадо более сложная. Вот репозиторий проекта на GitHub и детали из линкдина Азамата:
-
Redesigned SD/eMMC Host Controller (HC) from “Wishbone” interface into the “AMBA AXI” interface and written key features for this Controller:
Extended data bus from 1 bit to 8 bit,
Written module Single Operation DMA (SDMA),
Upgraded SDMA to Advanced DMA (ADMA),
Written AutoCMD23 feature to optimise CMD exchange flow between Card and HC,
Controller was upgraded to work in High Speed mode. This mode allow read/write data in 50MHZ,
Implemented supporting of Dual Data Rate (DDR) mode, which is doubled the speed data transferring.
All these implemented upgrades and features speeded up the Host Controller from 14MB/s to 97MB/s. Some of features were carried out together with the changes of kernel SDHCI host driver.
-
Developed Pattern searching engine on FPGA with Regular Expression. Meta-characters compatible with POSIX standard. (Analogue of “grep”):
Participated in building and testing of subset construction algorithm that searches of patterns for some of the regexp meta characters.
Responsibility:
Develop RTL design on Xilinix ZYNQ 7020 SoC using Verilog HDL. Development kit – ZedBoard, Target board is Parallella.
Integrate Design with Linux driver.
Testing and debugging the each steps of the projects.
Measure electrical utilization. Comparing and analyzing metric results.
Writing documentation.
Competence in Agile Scrum methodology. Daily Scrum, Sprint planing, Backlog grooming, Sprint retrospectives.

Бахтияр Куканов работал вместе с Азаматом Бексадаевым (профиль Бахтиара на LinkedIn):

Какова же мораль всей этой истории? В Кыргизстане есть инженеры, которые умеют писать профессиональный код на языках описания аппаратуры, получают это умение в местных вузах (в кыргызском политехе есть курс по VHDL с лабами на FPGA) и развивают это умение с помощью участия в open-source проектах. Такое наблюдение поддерживает идею, ради которой собственно и был организован семинар в Бишкеке: в Средней Азии можно, с относительно низкого старта, развить экосистему проектирования микроэлектронных чипов, используя оставшиеся от советского периода традиции образования, в комбинации с поддержкой местных бизнесменов и международных технологических компаний.

Кстати, пока я смотрел на фрагмент кода Азамата, который я вынес в заголовок (фрагмент генерирует сигнал AWREADY протокола AXI), я осознал, что этот дизайн можно сделать более эффективным. Кто из читателей первым скажет как именно? Вот исходники. Подсказка: про это написано в свежей редакции стандарта AXI.
Материалы самого семинара (код, фото и видео) вы можете скачать и посмотреть на сайте Digital Design & Verification in Central Asia.
Комментарии (22)

byman
21.08.2022 13:37+2Ядра имели собственную архитектуру под названием Epiphany и были оптимизированы под энергоэффективные вычисления с плавающей точкой. По микроархитектуре каждое ядро было суперскаляром с внеочередными выполнением инструкций (out-of-order – OoO).
В статье (по ссылке) немножко другая информация: The Epiphany includes is an in-order dual-issue RISC processor...

YuriPanchul Автор
21.08.2022 17:06Ааааа, напутал, спасибо, перепроверю. В принципе in-order с такой архитектурой более логично, а суперскаляр он возможно несимметричный (типа целочисленные и floating point).
YuriPanchul Автор
21.08.2022 17:19Хм, а в википедии написано "out of order":
https://en.wikipedia.org/wiki/Adapteva
"The Epiphany architecture could accommodate chips with up to 4,096 RISC out-of-order microprocessors,"
byman
21.08.2022 17:51+1В Википедии все перепутано. Если почитать, то она сама себе противоречит :) Приведенная Вами ранее ссылка на статью автора изделия должна быть более достоверной.
YuriPanchul Автор
21.08.2022 17:39+1Поправил:
Основой технологии Adapteva была решетка из большого количества процессорных ядер внутри одной микросхемы. Ядра имели собственную архитектуру под названием Epiphany и были оптимизированы под энергоэффективные вычисления с плавающей точкой. По микроархитектуре каждое ядро было суперскаляром с двойной выборкой и последовательным выполнением (в википедии ошибка, она говорит, что Epiphany был суперскаляр с внеочередными выполнением инструкций (out-of-order – OoO). Это логично: in-order для энергоэкономного CPU примерно двое энергоэффективнее, чем out-of-order.
byman
21.08.2022 13:51+2Основатель Adapteva Andreas Olofsson может быть известен российскому читателю как автор DSP процессора TigerSharс ( https://habr.com/ru/post/314986/ )

BabundinAnton
21.08.2022 17:06Я заранее извиняюсь, я всего лишь верификатор а не дизайнер, у меня вопрос) А не должен ещё присутствовать BVALID и BREADY в условии ?
И тогда наверно можно через case описать
YuriPanchul Автор
21.08.2022 17:10Нет, не должен. Каналы AW и B в общем случае работают независимо - т.е. можно выдать 10 транзакций по каналу AW (адрес записи), друг за другом, потом выдать 10 транзакций по каналу W (данные для записи) , а получить 10 подтверждений по каналу B. Протокол AXI это не запрещает. Фишка тут в другом.
byman
21.08.2022 18:11На мой взгляд , все хорошо написано. По сути здесь АРВ интерфейс. Я бы добавил еще и буфер для записи данных, а не только для адреса. Сигналы axi_awready и axi_wready по сути одно и тоже. Хотя, синтезатор может это подчистить. Вот только с axi_bvalid у меня не все понятно. Если представить, что S_AXI_BREADY не отвечает сразу, то возможен пропуск ответа. Но скорее всего здесь одиночные циклы обмена и тип обмена предполагает отсутствие начала нового обмена до полного завершения предыдущего. Так в чем фишка ? :)
YuriPanchul Автор
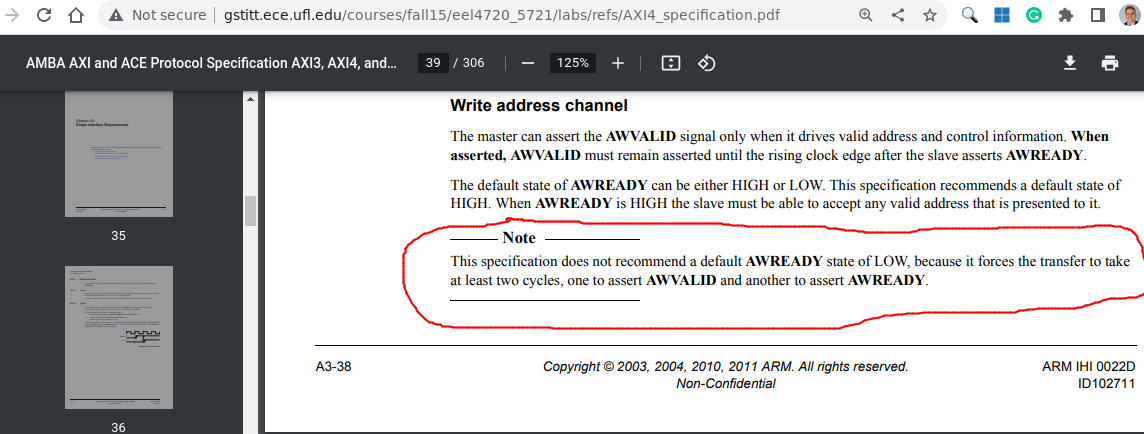
21.08.2022 18:59В коде две проблемы. Во-первых, он не позволяет back-to-back транзакции - перед приемом одной вставляется пропуск минимум в такт, что уполовинивает пропускную способность канала. Об этом непосредственно предупреждает спецификация (см. ниже). Чтобы этого избежать, ready должен восприниматься как "не busy" / "не занято", сбрасываться при reset в 1 и потом устанавливаться в 0 только если устройство не может принимать больше транзанзакций:
byman
21.08.2022 19:39+1Здесь тяжело судить , т.к. автор целенаправленно делает обмен в 2 такта. Возможно, у него такое ТЗ. Кто знает. Адрес буферизируется, данные нет. За такт в такой конструкции не запишешь. То, что готовность по умолчанию ноль, не есть хорошо, но нужно смотреть этот модуль в системе. Входящие достоверности адреса и данных очевидно разрешаются адресным декодером снаружи. Значит и выходная готовность будет разрешаться этим сигналом. А там уже итоговый уровень будет так, как Вы написали. Если подходить с точки зрения верификации, то нужны исходные требования. Тогда можно к чему-то придираться. А так вообще можно было готовности держать всегда в 1 и делать запись каждый такт, если мастер готов принимать ответы каждый такт. Но может есть какие-то ограничения в дизайне, не поддерживающие такой темп.
YuriPanchul Автор
21.08.2022 22:00+1С точки зрения верификации:
* пассивный монитор транзакций должен поддерживать оба режима - он должен просто считывать адрес когда valid & ready
модель axi slave (reference slave) должен иметь опцию как на ready default 0, так и на ready default 1, а также на случайную ready (так тоже должно работать)
активный bfm драйвер со стороны мастера должен быть написан так, чтобы ему было все равно. Он должен немедленно драйвить новую транзакцию после получения (ready & valid) на posedge clk , кроме случая, когда сценарий тестирования предполагает пропуски между транзакциями.

mpa4b
22.08.2022 20:01модель axi slave (reference slave) должен иметь опцию как на ready
default 0, так и на ready default 1, а также на случайную ready (так
тоже должно работать)По-моему, попахивает шизофренией случайно дёргать ready, когда valid=0. В скриншоте выше указано требование что valid если уж вскочил в 1, то и остаётся как минимум до соответствующего ready. Логично и на ready наложить такое же условие -- если уж вскочило в 1, то остаётся в 1 минимум до соответствующего valid.
YuriPanchul Автор
22.08.2022 22:03+1Это может казаться вам логичным, но:
Требование к valid ("если уж вскочил в 1, то и остаётся как минимум до соответствующего ready") в спецификации есть, а вот требование к ready - нет и
Я вполне могу представить дизайн с таким "шизофреничным" поведением ready - например если в дизайне есть несколько axi портов, и транзакции с них используют внутренний общий ресурс (например общую очередь, которую можно переполнить транзакциями, которые идут из второго порта, пока на первом ничего не происходит).
По поводу (2) вы можете сказать, что перед таким общим ресурсом стоит сделать дополнительный буфер для каждого порта, но на самом деле возражение (1) достаточно: если в спеке органичения нет, то модель не должна такое ограничение вводить.
mpa4b
23.08.2022 14:14+1п.2 с запаркованными на 1 редями всё равно потребует внутренних буферов на каждом порту, по крайней мере если каждый такой ready будет выходом с флопа, а не комбинаторной кашей. Ну и в целом -- я ни в коем случае не спорю с спекой, просто считаю, что такое дополнительное требование на реди -- рационально. Облегчает жизнь c обоих сторон подобного интерфейса (имею в виду valid-ready).
YuriPanchul Автор
22.08.2022 22:40Кроме этого в спецификации сказано в явной форме, что valid и ready несимметричны: valid не может ждать ready=1 перед переходом с valid=0 в valid=1. valid должен выставится (невзирая на ready) и стоять колом, пока на фронте клока не окажется valid=1 и ready=1 - а потом или продолжить стоять, уже для другого трансфера, или сняться в valid=0.
А вот ready может ждать valid=1, хотя это не рекомендуется (лучше если ready по умолчанию 1 и становится 0 только когда устройство занято / busy):
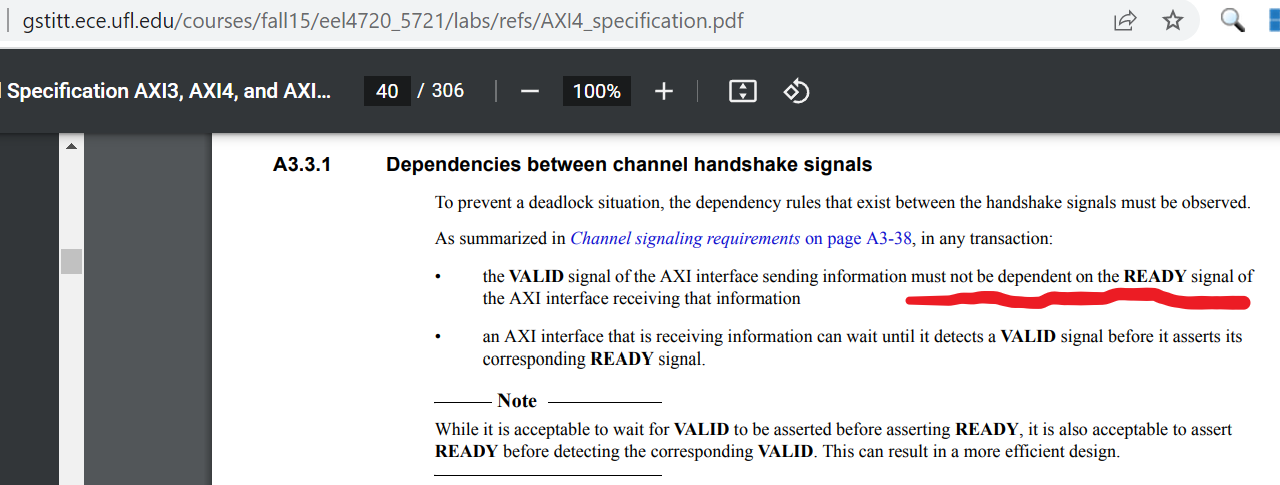
Никакого текста, запрещающего ready ходить ходуном пока valid=0 в спецификации нет.


aiveng0
22.08.2022 11:46+2Юрий, спасибо за заметку.
Фрагмент кода, который вы вынесли в заголовок, генерируется софтом от Xilinx автоматически при создании нового IP c AXI. Непосредственно код Азамата начинается примерно с 677-й строки в том исходнике.
nerudo
Юрий, а как там с перспективами занятия микроэлектроникой в Российской Федерации?
YuriPanchul Автор
В смысле "как там"? Микроэлектроника в Российской Федерации переживает бум у молодежи. Регистрации на семинары в 2022 году бьют рекорды 2021 года. Конечно есть проблема, что из России ушли Synopsys, Cadence и Mentor Graphics, но для обучения ASIC design вместо их софта можно использовать открытые тулы - Open Lane. Если еще и российcкое государство и корпорации реализуют аналог партнерства Google + Skywater, при котором Google отбирает лучшие проекты сделанные с open source EDA tools и бесплатно изготавливает из на фабе Skywater - было бы вообще зашибись. Типа если бы скооперировался Yandex и зеленоградский Микрон.
Открытые тулы:
Программа Google + Skywater. Caravel - это template для SoC с служебным RISC-V процессором:
Публичные проекты, предложенные Гугло молодежью:
amartology
ЕСЛИ
YuriPanchul Автор
Ну у них сейчас для такого проекта может возникнуть мотивация :-) Как без чего-то такого прогресс делать?