
Следить за обновлениями блога можно в моём канале: Эргономичный код
Эпиграф
a class is a necessary but insufficient vehicle for decomposition
Класс - это необходимое, но недостаточное средство декомпозиции
— Grady Booch, Object-Oriented Analysis and Design with Applications
Количество классов в реализации даже небольшой программы на один человеко-месяц исчисляется десятками. В средних программах на несколько человеко-лет счёт идёт уже на тысячи. А человек может одновременно оперировать 7-ю +/- 2 объектами. Поэтому все нетривиальные программы требуют декомпозиции своей реализации на более крупные блоки, чем классы - я буду называть такие блоки пакетами.
Сейчас наиболее распространены два основных подхода к декомпозиции систем:
пакетирование по слоям и техническим аспектам (далее просто "по слоям" для краткости)
-
пакетирование на основе предметной области, представленное группой вариантов:
пакетирование по фичам
пакетирование по компонентам
ограниченные контексты и пакетирование по агрегатам из предметно-ориентированного дизайна (DDD)
Однако ни один из этих подходов мне не подошёл в полной мере и я изобрёл… объектно-ориентированный подход к декомпозиции систем. Точнее, я изобрёл простую методику выполнения декомпозиции, а потом понял, что на выходе она даёт штуки обладающие свойствами объекта.
Но обо всём по порядку - сначала я рассмотрю критерии оценки подходов, распространённые подходы и почему они мне не подошли. А закончу пост представлением методики выполнения объектно-ориентированной декомпозиции.
В области группировки кода вообще и классов в частности есть ещё много разных идей и подходов - разделение Парнаса, структурный дизайн Константина, принципы дизайна пакетов Мартина, подходы на основе кластерного анализа.
Однако на основе того что я вижу в реальном коде и интернете - все они не получили распространения и, чтобы сократить и без того огромный пост, я не буду их рассматривать.
Отмечу лишь, что две из них (разделение Парнаса и структурный дизайн) дали нам универсальные критерии оценки дизайна программ: сокрытие информации и сцепленность/связанность соответственно. И я их возьму за основу для критериев оценки подходов.
Критерии
Подходы я буду сравнивать по двум аспектам - насколько хорошие декомпозиции они дают и насколько легко их применять.
Качество декомпозиции я буду оценивать по следующим критериям:
Сокрытие информации. Какую информацию подход скрывает
Сцепленность. Какое количество связей между пакетами порождает подход
Связанность. Какое количество связей внутри пакета порождает подход
Масштабируемость. Насколько большие системы могут быть эффективно декомпозированы с помощью подхода
Оценка сцепленности только по количеству связей внутри пакета, может быть легко "хакнута" - например, если в слоёной декомпозиции слой сервисов сделать высоко сцепленным. В этом случае формально слой сервисов будет обладать высокой связанностью, но фактически он будет обладать высокой сцепленностью внутренних элементов.
Для того чтобы это обойти, сцепленность я дополнительно буду оценивать по локальности изменений. Локальность изменений, в свою очередь, я буду оценивать по двум критериям:
Сколько в среднем пакетов затрагивает одно изменение. В идеальной декомпозиции это число должно быть равно 1.
-
Можно ли найти топологическую сортировку, определяющую такой порядок, что при удалении пакетов в соответствии с ним, система продолжает на каждом шаге:
Собираться
Быть полезной для конечного пользователя
Что касается лёгкости применения, то её я буду оценивать по таким критериям:
Простота обучения. Насколько просто обучить человека подходу.
Простота исполнения. Есть ли у подхода методика выполнения и насколько она проста
Пакетирование по слоям и техническим аспектам
Картинки кликабельны

В этом посте я буду рассматривать только декомпозицию выделенных бэкендов, которые предоставляют API для фронтэнда. В этом случае контроллеры выступают в роли тонких адаптеров обращений по протоколу сетевого взаимодействия (REST, SOAP, всевозможные протоколы RPC и т.д.) в вызовы методов сервисов.
Иллюстрировать декомпозиции я буду на примере вымышленной системы управления задачами.
Этот подход настолько прост и существует настолько давно, что, кажется, это уже коллективное бессознательное нашей индустрии. Судя по всему, своими корнями он уходит в статью Дейкстры The structure of the “THE”-multiprogramming system, датированную 67 годом, что делает его одним из самых ранних подходов.
Несмотря на свой возраст, этот подход является самым распространённым и по сей день и, думаю, он знаком всем разработчикам без исключения. Способ группировки заключается в том, что команда выбирает несколько аспектов реализации (самые частые примеры - контроллеры, сервисы, репозитории/дао, сущности, дто, фабрики, исключения, перечисления) и группирует классы по ним. Классы, которые не удаётся однозначно отнести к одному из этих аспектов, сваливают в специальную группу, которую обычно называют utils или common.
В слоёной архитектуре существует только одно ограничение - более "низкие" слои не могут зависеть от более "высоких". Это ограничение становится сложнее соблюдать, когда на одном уровне смешивают и архитектурную декомпозицию (контроллеры, сервисы, репозитории, сущности) и техническую (интерфейсы, исключения, перечисления). В этом случае для технических "слоёв" невозможно определить их порядок: что является более "высоким" слоем/уровнем - исключения или перечисления?
Такая декомпозиция теоретически должна скрывать способ реализации технических аспектов, например, способ работы с БД. Однако на практике, детали реализации слоёв очень часто "протекают" через границы, результатом чего становится отсутствие какого бы то ни было сокрытия информации вообще.
Для слоёной декомпозиции естественной является высокая сцепленность системы. Самый "толстый" слой сервисов содержит в себе только бизнес-логику, а все структуры данных (сущности, дто, исключения, перечисления) и вспомогательный код для работы с ними (репозитории, фабрики, билдеры) находятся в других пакетах. В итоге каждый класс в пакете сервисов начинает зависеть от множества классов в соседних пакетах, тем самым, по определению, повышая сцепленность.
Кроме того, даже единственное ограничение на зависимости между слоями чаще нарушают, чем соблюдают, ещё больше повышая сцепленность системы за счёт внесения циклов в зависимости.
В итоге декомпозиция по слоям представляет собой сочетание врождённой высокой сцепленности между пакетами и белого пятна в проектировании внутри пакетов. Эта гремучая смесь приводит к превращению системы в печально известный Big Ball of Mud (большой ком грязи) уже к концу первого года своей жизни.
Если связанность оценивать только по количеству связей внутри пакета, то откровенно плохо реализованная система с десятками зависимостей в каждом сервисе и связным графом сущностей может показаться высоко связанной. Однако истинная связанность таких систем легко демонстрируется с помощью дополнительных критериев, введённых специально для этого случая.
Большинство нетривиальных изменений таких систем будет затрагивать множество пакетов. А удаление единственного пакета (контроллеров), которое не сломает сборку, сразу же сделает всю систему бесполезной для пользователя.
С точки зрения масштабируемости слоёная декомпозиция также даёт не лучший результат. Постоянно развиваемая система довольно быстро доходит до 20-30 классов одного типа (то есть в одном пакете) и снова возникает проблема их группировки.
Хорошо, если команда осознанно выбрала слоёную декомпозицию, для сокращения времени разработки первой версии. В этом случае, достигнув пределов масштабирования слоёной архитектуры, команда может провести качественную декомпозицию.
Однако на практике слоёную декомпозицию не выбирают. Чаще всего это единственный известный и понятный разработчикам способ декомпозиции. И разработчиков сложно в этом винить, декомпозиции систем действительно нигде не учат - меня самого не учили в университете, и соответствующих курсов я ни разу не видел. С этим мнением согласен и Джон Оустерхаут, автор A Philosophy of Software Design:
I have not been able to identify a single class in any university where problem decomposition is a central topic. We teach for loops and object-oriented programming, but not software design.
У меня до сих пор не получилось найти хоть один курс в каком-либо университете, где бы декомпозиция задач была центральной темой. Мы учим циклам и объектно-ориентированному программированию, но не проектированию ПО.
— John Ousterhout, A Philosophy of Software Design, с. 9
Поэтому, как правило, дальнейшая декомпозиция внутри пакетов-слоёв выполняется методом "как бог на душу положит" первым разработчиком, который решил, что "пакет слишком разросся".
Если слоёная декомпозиция даёт столь плохие результаты, как она стала самой распространённой? Секрет кроется во второй группе критериев оценки методики - простоте обучения и исполнения.
Слоёная декомпозиция не требует никакой квалификации или интеллекта и может быть успешно автоматизирована даже без применения слабого ИИ - просто путём поиска нескольких ключевых подстрок в строке определения класса.
Этим же определяется и простота исполнения - опытный разработчик выполняет слоёную декомпозицию буквально спинным мозгом, не затрачивая на это ни секунды времени.
Хочу отметить, что я не являюсь противником разделения кода на слои как такового - в моих проектах есть и контроллеры, и сервисы, и репозитории. Более того, во всех моих системах последних семи лет за пользовательский интерфейс, бизнес-логику и хранение данных отвечают разные программы - веб- или мобильное приложение, бэкенд сервер и СУБД соответственно. А если бы я делал программу, реализующую все три аспекта, то я бы её в первую очередь разбил по слоям. Однако для программ, сфокусированных только на одном из этих аспектов, слои работают откровенно плохо.
Итоговая оценка пакетирования по слоям (по пятибалльной шкале):
Сокрытие информации - 2 (неуд.)
Сцепленность - 2 (неуд.)
Связанность - 2 (неуд.)
Масштабируемость - 2 (неуд.)
Простота объяснения - 5 (отл.)
Простота применения - 5 (отл.)
Пакетирование по фичам

Найти оригинальный источник идеи пакетирования по фичам у меня не получилось, но этой теме посвящено множество постов:
Хотя ни один из них я не могу назвать ни авторитетным, ни исчерпывающим.
В этом подходе, приложение декомпозируют на пакеты по фичам - для каждой фичи создаётся пакет, и весь код, реализующий фичу, попадает в него. Притом каждый пакет имеет явно выделенный публичный интерфейс, а всё остальное скрывается.
И тут мы сразу упираемся в главный недостаток этого подхода - его сложно объяснить, а исполнить ещё сложнее.
Декомпозиция по фичам только звучит просто (и то не для всех). Когда же вы сядете и попытаетесь декомпозировать систему по фичам, у вас тут же возникнет множество вопросов: "А фича - это вообще что такое?", "Как мне из требований получить набор фич?", "Судя по примерам, фича - это таблица. Мне что, заводить по пакету на каждую таблицу?", "А что делать с таблицами связками?", "Что делать с функциями, которые затрагивают две и более таблицы - в какой пакет их помещать?", "А что делать с функциями, которые работают не с таблицами, а с REST API?", "А с S3?", "А куда мне положить DSL создания Excel файлов для нескольких фич? В utils?". Ответы на все эти вопросы придётся искать самостоятельно, потому как все посты ограничиваются поверхностным описанием идеи.
Найти ответы, конечно же, можно - я нашёл и в итоге у меня получился объектно-ориентированный подход к пакетированию. Но мне для этого потребовалось пять лет вялотекущих размышлений, два года активной работы в этом направлении и эксперименты в пяти коммерческих проектах. Не у всех есть желание и возможность этим заниматься - когда давят сроки, лучше декомпозировать на въевшиеся в подкорку слои.
Но если преодолеть все сложности и не остановиться на полпути, то наградой будет декомпозиция высокого качества по нашим критериям - принципы низкой сцепленности/высокой связанности и сокрытия информации практически во всех постах из списка предлагаются как главенствующие.
С масштабируемостью дела обстоят хуже. При декомпозиции по фичам быстро расти будет не количество классов в пакетах, а количество самих пакетов. И если ничего не предпринять, то уже количество пакетов быстро дорастёт до 20-30 штук и проблема декомпозиции системы снова встанет в полный рост. В постах же эта проблема либо не упоминается вовсе, либо упоминается лишь вскользь. В результате разработчик снова остаётся с ней один на один. Но благодаря поискам ответов на изначальные вопросы, разработчик хорошо прокачает свой скилл проектирования. И в этом случае получившаяся декомпозиция вполне вероятно окажется высокого качества.
Итоговая оценка пакетирования фичам:
Сокрытие информации - 4 (хор.)
Сцепленность - 4 (хор.)
Связанность - 4 (хор.)
Масштабируемость - 3 (удв.)
Простота объяснения - 2 (неуд.)
Простота применения - 2 (неуд.)
Пакетирование по компонентам

Автором пакетирования по компонентам является Саймон Браун, описавший его в посте Mapping software architecture to code (также см. 1, 2, 3, и главу 34 "Missing Chapter" из Clean Architecture).
Пакетирование по компонентам очень похоже на пакетирование по фичам, поэтому я не буду на нём подробно останавливаться и лишь обозначу отличия.
Браун дистанцируется от пакетирования по фичам в первую очередь тем, что у него контроллеры вынесены в отдельный пакет. По его задумке это должно повысить сокрытие информации о реализации сервисов. Однако он это делал для классических контроллеров из MVC, которые собирают модель для представления из нескольких сервисов и для нашего примера с контроллерами API в этом смысла нет.
Зато есть другое отличие - модель данных выделена в собственный пакет. В тексте это явно не проговорено, но видно из иллюстрации и кода примера. И вот это уже, на мой взгляд, проблема, так как из-за этого за границы компонента начинает утекать структура его данных, и это создаёт предпосылки для сцепленности через общее окружение.
Уже в процессе редактуры этого поста я наткнулся на твит Брауна:
Each non-UI component isn’t a “feature”, it’s something else… like a domain concept or aggregate root (including DB access), integration point to the outside world, technical service, etc.
Каждый "non-UI" компонент не является "фичей", это что-то другое… как концепт предметной области или корень агрегата (включая доступ к БД), точка интеграции с внешним миром, технический сервис и т.д.
— Simon Brown, https://twitter.com/simonbrown/status/969112668132073473?s=20&t=w8c5RikLz3zFdS7X4APvNw
Основываясь на этом твите, можно предположить, что подход к декомпозиции Брауна по сути совпадает с пакетированием по объектам. Но это не точно.
И хотя с описанием пакетирования по компонентам дела обстоят лучше, чем с описанием пакетирования по фичам, чёткой методики выявления компонентов Браун также не предлагает. Поэтому итоговая оценка примерно такая же.
Итоговая оценка пакетирования компонентам:
Сокрытие информации - 3 (удв.)
Сцепленность - 3 (удв.)
Связанность - 4 (хор.)
Масштабируемость - 3 (удв.)
Простота объяснения - 2+ (неуд.)
Простота применения - 2 (неуд.)
Ограниченные контексты и пакетирование по агрегатам из предметно-ориентированного дизайна (DDD)

DDD - это полноценный подход к проектированию, описанный в одноимённой книге Эрика Эванса. Помимо этой книги, есть ещё ряд очень хороших книг - Domain Modeling Made Functional, PPP of DDD, Implementing Domain-Driven Design, суммарно на 2200 страниц. А ещё множество менее популярных книг и бессчётное количество постов в интернете.
Суть подхода можно охарактеризовать как то, что исходный код программы должен быть написан на языке предметной области.
Мне самому DDD импонирует и в Эргономичном подходе я позаимствовал из DDD все базовые блоки тактических паттернов. В частности, агрегаты играют одну из ключевых ролей в объектно-ориентированной декомпозиции. Однако вместо того, чтобы работать по DDD, я начал делать Эргономичный подход. Этому есть две основные причины - тяжеловесность и расплывчатость DDD.
Тяжеловесность DDD проявляется как в обучении, так и в применении.
DDD - это очень большая штука, на изучение которой требуется очень много времени. Как минимум надо будет прочитать 1000 страниц оригинальной книги и PPP of DDD или Implementing DDD. Мне для уверенного понимания стратегических паттернов не хватило даже прочтения всех 4 указанных выше книг по два раза (по разу от корки до корки, и ещё по разу разбираясь с отдельными концепциями).
Тут строгий читатель может спросить "Какого фига ты тогда пишешь о том, чего не знаешь?". Отвечаю.
Во-первых, DDD это такой слон в области проектирования, опусти я которого - другой (а возможно и тот же) строгий читатель спросит, почему я ничего не написал про DDD.
Во-вторых, я критикую DDD за сложность изучения и применения - а в этом, благодаря собственному опыту, я разбираюсь как раз очень хорошо.
Тяжеловесность изучения так же усложняет и исполнение - DDD требует включенности (а соответственно изучения) всей команды и экспертов предметной области. Мне в своей практике ни разу не удалось продать DDD даже команде, не говоря уж об экспертах предметной области.
Касательно декомпозиции DDD предусматривает два уровня - ограниченные контексты и агрегаты. Что это такое? А вот поди разбери.
A Bounded Context is an explicit boundary within which a domain model exists. Inside the boundary all terms and phrases of the Ubiquitous Language have specific meaning, and the model reflects the Language with exactness.
Ограниченный контекст - это явная граница, внутри которой существует модель предметной области. Внутри этой границы все термины и фразы Вездесущего языка имеют определённое значение и модель точно отражает Язык.
— Vaughn Vernon, Implementing DDD
Само определение ограниченного контекста является наглядной демонстрацией сложности и расплывчатости подхода.
Как декомпозировать задачу на ограниченные контексты тоже в двух словах не объяснить (мне, по крайней мере).
Как вариант - границы контекста определяются языковыми границами. Осталось выяснить самую малость - где проходят языковые границы.
Ещё вариант - выравнять контексты по организационной структуре компании. Но что делать, если я занимаюсь продуктовой разработкой или автоматизирую работу одного отдела?
Полноценного руководства по декомпозиции ограниченных контекстов на модули DDD также не предлагает. В оригинальной книге этому посвящён целый раздел, но я бы описал его как "вода-вода, не используйте слои, вода-вода". Если не слои, то что? Ответа нет. В первой книге.
Зато есть в Implementing DDD.
Typically you’ll have one Module for one or a few Aggregates (10) that are cohesive, if only by reference.
Обычно у вас будет по модулю для одного или нескольких агрегатов, которые связаны хотя бы по ссылке.
— Implementing DDD
В целом ответ хорош и в объектно-ориентированной декомпозиции, агрегаты действительно играют одну из ключевых ролей. Но он порождает три новых вопроса - что такое агрегат, как декомпозировать модель на агрегаты, как декомпозировать систему, в которой больше интеграций, чем собственного состояния? Мне чтобы найти и уложить в голове ответы на первые два вопроса пришлось проштудировать на несколько раз все книжки по DDD и потом написать пост об этом. А ответа на третий вопрос в самом DDD просто нет.
Тем не менее, я полагаю, если преодолеть все сложности - "продать" подход команде и экспертам, обучить всех, изучить язык экспертов и найти в нём границы - то результирующая декомпозиция на ограниченные контексты и пакеты будет обладать высоким качеством. В частности, в силу своего фокуса на предметной области и экспертах, DDD может дать декомпозицию с наибольшей связанностью среди всех подходов. А агрегаты и полнокровные сущности помогут существенно снизить сцепленность системы и повысить степень сокрытия информации.
Наконец, ограниченные контексты и возможность помещения нескольких агрегатов в один пакет дают хорошую масштабируемость декомпозиции "из коробки".
Итоговая оценка пакетирования по ограниченным контекстам и агрегатам:
Сокрытие информации - 4 (хор.)
Сцепленность - 4 (хор.)
Связанность - 5 (отл.)
Масштабируемость - 5 (отл.)
Простота объяснения - 2 (неуд.)
Простота применения - 1 (плох.)
Итак, мы пришли к выводу, что все распространённые подходы обладают существенными недостатками. Пакетирование по слоям даёт откровенно низкокачественную декомпозицию. Пакетирование по фичам и компонентам является скорее абстрактной идеей, которая требует значительных усилий по доработке для возможности эффективного применения на практике. DDD очень тяжеловесен и сложен в изучении и применении.
Существует ли серебряная пуля, которая позволит нам быстро и без больших усилий выполнять качественную декомпозицию систем? Я утверждаю, что да и что она всегда была у нас под носом. И имя ей - объектно-ориентированная декомпозиция
Пакетирование по объектам, ака объектно-ориентированная декомпозиция

"Объектно-ориентированная декомпозиция" - это рабочее название, и я не уверен, что сохраню его. Проблема этого названия в том, что сейчас термин "объектно-ориентированный" де-факто стал обозначать "использующий классы" (хотя это совсем не то, о чём думал Кей вводя его), а у меня речь идёт про более крупные структуры, которые в коде с тем же успехом можно реализовать и на чисто функциональном языке.
На рубеже 20 и 21 веков многие книги по ООП/Д/А (например, Object-Oriented Software Engineering, Designing object-oriented software, Applying UML and Patterns) в дополнение к методике проектирования классов, предлагали и рекомендации по их последующей группировке в более крупные структуры. Однако я ни разу не видел, чтобы кто-то применял эти методики в реальной жизни. Полагаю, потому что все эти методики очень тяжеловесные.
Поэтому я разработал "легковесную" методику выполнения объектно-ориентированной декомпозиции.
Как очевидно из названия, этот подход предполагает раскладку по пакетам разных объектов. В данном контексте под объектом я понимаю не экземпляр класса, а более крупную структуру, которая может быть реализована группой классов (группой экземпляров классов, если быть точнее). Эту структуру я называю объектом, потому что она обладает всеми присущими ему характеристиками - состоянием, которое она абстрагирует и инкапсулирует за высокоуровневым поведением. Идентичность тоже можно перенести на уровень пакетов, но на практике это требуется редко, поэтому я не стану на ней останавливаться.
Идея объектов-пакетов принадлежит не мне - я её подглядел в Object-Oriented Software Engineering Ивара Якобсона (одного из соавторов UML). В этой книге Якобсон оперирует тремя видами объектов - объекты анализа, объекты дизайна и объекты (модули) языка программирования.
И здесь я говорю об объектах дизайна, которые Якобсон описывает следующим образом:
The design model will be composed of blocks which are the design objects. These will make up the actual structure of the design model and show how the system is designed. These blocks will later be implemented in the source code.
The blocks will abstract the actual implementation. The implementation of the blocks may be one specific class in code, that is, one block is implemented by one class. However, often, a block is implemented by several different classes. The blocks are therefore a way of abstracting the source code.
Проектная модель будет состоять из блоков, которые являются объектами дизайна. Они будут составлять фактическую структуру проектной модели и покажут как спроектирована система. Позже эти блоки будут реализованы в исходном коде.
Эти блоки абстрагируют фактическую реализацию. Реализацией блоков может быть один определённый класс в коде, то есть один блок реализуется одним классом. Однако зачастую блоки реализуются несколькими разными классами. Таким образом, блоки являются способом абстракции исходного кода.
— Ivar Jacobson, Object-Oriented Software Engineering
Общая концепция ОО-подхода очень проста. Есть операции - атомарные единицы поведения, которые могут быть вызваны извне (пользователем через UI или внешней системой через [REST] API). Есть ресурсы, которые обеспечивают операции (в первую очередь коллекции в хранилищах данных, но это могут быть и файлы, и внешние системы, и внешние устройства). Операции и обеспечивающие их ресурсы надо так поделить на объекты дизайна, чтобы каждый ресурс обеспечивал операции только одного объекта. Наконец, ресурсы надо инкапсулировать в объектах дизайна - исключить возможность обращения к ресурсу напрямую снаружи объекта.
Интерфейс объекта дизайна может быть дополнен операциями, необходимым другим объектам. Но в общем случае для взаимодействия объектов лучше использовать асинхронный обмен сообщениями и событиями через посредника (очередь).
Кратко методика проектирования объектов дизайна (ака декомпозиции на пакеты) состоит из трёх основных шагов:
Определить операции системы и ресурсы необходимые для их выполнения
-
Сгруппировать их таким образом, чтобы с ресурсами каждой группы взаимодействовали только операции этой группы. Эти группы фактически определяют поведение и состояние объектов дизайна.
Для защиты ресурсов, у каждого объекта дизайна выделяется набор классов, определяющих его интерфейс (обычно это класс сервиса и DTO). Всё остальное (сущности, репозитории, клиенты внешних систем, другие вспомогательные классы) делаются закрытыми (package private в Java, internal + ArchUnit правило в Kotlin).
Часто оказывается так, что не получается однозначно отнести ресурс к определённой группе. В этом случае ресурс помещается в ту группу (А), с операциями которой он более тесно связан. А доступ к ресурсу для операций из других групп предоставляется посредством дополнительных операций в группе А.
-
Нормализовать количество и размер объектов:
Если количество объектов получилось слишком большим на ваш взгляд (на мой слишком много - ~10 и более) - сгруппировать связанные между собой объекты (объекты, которые используют операции друг друга). Если таких объектов нет, то стоит рассмотреть декомпозицию уже самой системы на несколько независимых на основании "здравого смысла" или более технических аспектов (по разработчикам, эксплуатационным требованиям, частоте релизов и т.п.).
Если в одном объекте количество операций или ресурсов получилось слишком большим (~10 и ~4 и более соответственно), то надо рассмотреть возможность разбить этот объект на несколько более мелких, взаимодействующих через обмен сообщениями. Если такой возможности нет, то хотя бы выделить ресурсы во внутренние объекты (подпакеты)
Первый шаг этой методики - определение операций и ресурсов - я описал в "посте с описанием построения диаграммы Эффектов проекта True Story Project".
Пример, рассмотренный в этом посте, хорошо демонстрирует работу с внешними системами, но, в силу специфики исходного проекта, практически не касается вопроса декомпозиции на ресурсы собственного состояния системы. В общих чертах этот вопрос у меня раскрыт в посте про агрегаты, а пост с конкретным примером проектирования системы с развесистым собственным состоянием - в планах.
Второй и третий же шаги я опишу в следующем посте, для которого данный является прелюдией с обоснованием необходимости создания собственной методики.
Эта методика относительно простая и механистическая, но даёт на удивление хорошие результаты.
Очевидно, что полученная декомпозиция обладает высокой степенью сокрытия информации - детали реализации (ресурсы) операций системы скрываются внутри объектов дизайна. Такая степень сокрытия информации является прочным фундаментом и для сведения сцепленности к минимуму.
Вместе с низкой сцепленностью, рука об руку идёт и высокая связанность (количество зависимостей внутри пакета), которая подтверждается локальностью изменений в проектах, декомпозированных таким образом.
Наконец, масштабирование также учтено и встроено в саму методику.
С критериями оценки самой методики тоже всё хорошо. Объяснить её, конечно, сложнее, чем слоёную декомпозицию, но намного проще, чем остальные методики из группы декомпозиций на основе предметной области.
То же касается и применения - проектирование объектов находится посередине между предельно простым проектированием слоёв и очень сложным проектированием фич, компонентов и ограниченных контекстов.
Итоговая оценка пакетирования по объектам:
Сокрытие информации - 5 (отл.)
Сцепленность - 4 (хор.)
Связанность - 4 (хор.)
Масштабируемость - 5 (отл.)
Простота объяснения - 3 (удв.)
Простота применения - 3 (удв.)
Заключение
Все распространённые методики группировки классов по пакетам обладают существенными недостатками. Группировка по слоям даёт откровенно плохие результаты. Группировку по фичам и компонентам непонятно, как выполнять и где научиться. Группировку по ограниченным контекстам и агрегатам сложно изучить, а потом выполнить.
Для того чтобы решить эти проблемы, я разработал методику объектно-ориентированной декомпозиции системы на пакеты. Она проще в изучении и применении группировок по фичам, компонентам и ограниченным контекстам/агрегатам, но даёт результаты такого же качества.
В следующем посте я вернусь к серии о диаграмме эффектов и подробно рассмотрю процесс выполнения объектно-ориентированной декомпозиции на конкретном примере.
Приложение А. Сводные данные
Картинка кликабельна

Подход |
Сокр. инфы |
Сцепл-ть |
Связ-ть |
Масш-ть |
Обучение |
Применение |
|---|---|---|---|---|---|---|
Пакетирование по слоям |
2 |
2 |
2 |
2 |
5 |
5 |
Пакетирование по фичам |
4 |
4 |
4 |
3 |
2 |
2 |
Пакетирование по компонентам |
3 |
3 |
4 |
3 |
2+ |
2 |
Пакетирование по ограниченным контекстам и агрегатам |
4 |
4 |
5 |
5 |
2 |
1 |
Пакетирование по объектам |
5 |
4 |
4 |
5 |
3 |
3 |
Комментарии (14)

inkelyad
22.08.2022 15:19Проблема же в том, что в разных случаях использования и с разных точек зрения (сравним "тот, кто пишет библиотеку" vs "тот, кто использует библиотеку") будет удобен разный принцип сбора понятий и операций в контейнеры.
Сравним
class Отчет { Записать отчет в базу данных(...); Вывести отчет на принтер(...); } class Заказ { Записать заказ в базу данных(...); Вывести заказ на принтер(...); }и
class База данных { Записать отчет в базу данных(...); Записать заказ в базу данных(); } class Принтер { Вывести отчет на принтер(...); Вывести заказ на принтер(...); }С точки зрения одних удобней и понятней первый способ. А с точки зрения других - второй.

Ares_ekb
22.08.2022 17:27Есть очень интересная книга как-раз на эту тему Chris Partridge "Business Objects: Re-Engineering for Re-Use", там в деталях описывается эта проблема. Если в нескольких словах, то идея следующая. Есть реальность (хотя фиг знает есть ли, а если есть, то фиг знает что это), в которой есть некие объекты реального мира: отчет, заказ, база данных, принтер. Есть языки концептуального моделирования (RDF/OWL, Object-role model, ...), которые эти объекты ровно так и моделируют, максимально приближенно к реальности.
Ещё в этой модели могут описываться действия или события: запись отчета в базу данных, вывод отчета на принтер, ... Причем в концептуальной модели они описываются не просто как метод какого-то класса, а как полноценные сущности, у которых может быть атрибут "дата события", "место события", ... Может быть достаточно сложная иерархия, например, выделяем базовую сущность событие (дата, место и другие атрибуты), более специфическую сущность действие (тут добавляется ссылка на субъекта действия, ссылка на объект действия, ...), на их основе определяем более специфические типы действий "запись", "вывод", на их основе определяем ещё более специфические действия "вывод отчета на принтер". Читаем тонны статей типа такой или такой, смотрим разные онтологии верхнего уровня, пытаясь максимально полно и точно описать предметную область.
Короче, идея в том, что если мы строим нашу концептуальную или онтологическую модель правильно, то в ней все эти вещи (заказы, принтеры и т.д.) описываются каким-то одним "правильным" способом. Там не будет такой ситуации, что сменилась точка зрения и нужно перефигачивать всю модель, превращать классы в методы, атрибуты в классы и т.д.
С другой стороны, в информационных системах обрабатываются не сами эти объекты реального мира, а какие-то наборы сведений о них. Там используется какой-то небольшой срез этой концептуальной модели. Например, если нам не важна дата вывода отчета на принтер, то она не будет храниться в базе данных или логах, не будет нигде передаваться. Или, например, нам важно место заказа (географическое расположение покупателя), от этого зависят скидки и т.п.
Иными словами концептуальная модель достаточно универсальная, она на сколько это возможно описывает реальность как есть и не особо зависит от точки зрения. А при проектировании конкретной информационной системы, да, все эти концептуальные сущности превращаются в таблицы, классы, методы, атрибуты, ... И как именно это будет сделано в значительно степени зависит от требований к информационной системе, от точки зрения архитектора или разработчика. Да, таблицы, классы и методы и не предназначены для концептуального моделирования, они описывают конкретную реализацию. На сколько она окажется удачной зависит от опыта разработчика, но вполне возможно, что придётся всё перефигачить, если требования изменятся или что-то не было учтено. В концептуальных моделях такого обычно не бывает, они преимущественно только дополняются.

jdev Автор
23.08.2022 03:10+1За книжку - спасибо, добавил себе в список прочтения.
Может быть после неё я уже наконец всё пойму и соглашусь с тем, что ООП хорошее средство для моделирования реальности :trollface:
Я собственно и пошёл изобретать велосипед, т.к. я не понимаю, как проектировать системы через моделирование реальности. А вот как проектировать системы через операции и ресурсы - я понимаю
michael_v89
22.08.2022 19:03+1Правильнее все-таки делать так.
class ОтчетСервис { конструктор(БазаДанных базаДанных, Принтер принтер) { ... } Записать отчет в базу данных(Отчет отчет) { ... } Вывести отчет на принтер(Отчет отчет) { ... } } class ЗаказСервис { конструктор(БазаДанных базаДанных, Принтер принтер) { ... } Записать заказ в базу данных(Заказ заказ) { ... } Вывести заказ на принтер(Заказ заказ) { ... } }Технические компоненты не должны зависеть от бизнес-логики, так как они должны быть универсальны, а в сущностях не должно быть бизнес-логики, так как она требует зависимости для своей реализации.
inkelyad
22.08.2022 19:11Тут дело в том, что с точки зрения того, кто библиотеку для печати (или записи в базу данных) пишет - то его "бизнес логика" - это все, что про принтер. А как устроены отчет или заказ и что они умеют или что еще с ними делать можно - это для него "техническая компонента". Ибо точка зрения другая.
Поэтому у него будет "ПринтерСервис". Ну и так далее.
michael_v89
22.08.2022 20:27его "бизнес логика" — это все, что про принтер
Верно, только в этой бизнес-логике нет заказов и отчетов, поэтому и методов для их печати в ПринтерСервис не будет. Проблема, которую вы описали, есть, но идет она из неправильной архитектуры, а не из точки зрения. Логику пытаются запихнуть куда-то в существующие классы, обычно ради следования принципу "Бизнес-логика должна быть в сущностях", и возникает вопрос "а куда", хотя правильный ответ никуда, надо сделать отдельный класс.
ПринтерСервис может быть вообще в сторонней библиотеке, взятой с Гитхаба. Он принимает на вход некие ДанныеДляПечати, которые могут содержать список команд для управления печатью или какой-то язык разметки, и вот эти ДанныеДляПечати как раз и должны подготавливаться в методе "Вывести заказ на принтер" какого-то другого сервиса.
inkelyad
22.08.2022 21:11Это просто переносит выбор на другой уровень/слои.
У нас получится четыре куска логики:
Подготовить ДанныеДляПечати из Отчета
Подготовить ДанныеДляПечати из Заказа
Подготовить ДанныеДляЗаписиВБазуДанных из Отчета
Подготовить ДанныеДляЗаписиВБазуДанных из Заказа
Которые так же можно сгруппировать в модули/пакеты/классы двумя способами.
michael_v89
22.08.2022 21:43"Подготовить ДанныеДляПечати из Отчета" и "Подготовить ДанныеДляЗаписиВБазуДанных из Отчета" будут находиться в ОтчетСервис, и скорее всего будут private, так как это деталь реализации соответствующей бизнес-логики. Иногда они могут быть вынесены в соответствующие отдельные классы фабрики или билдеры, но точно не в общий класс "Подготовитель данных для записи в базу", который зависит от 20 сущностей проекта. Делать классы с таким количеством зависимостей просто архитектурно неправильно.
Отчеты и заказы это разные модули, они могут быть вообще оформлены как пакеты, устанавливаемые через пакетный менеджер, и разрабатываться разными командами, или вынесены в отдельные микросервисы. Или просто один появился раньше, второй позже, и при создании классов для первого нельзя было сгруппировать с ними методы для второго, потому что их еще не было. Появился второй модуль, делаем для него отдельную папку в папке modules, и пишем туда все новые классы для этой бизнес-логики, не меняя существующие. В общем, тут нет выбора между равнозначными вариантами, есть конкретные критерии, почему один вариант лучше другого, поэтому это архитектурный вопрос.
jdev Автор
23.08.2022 03:03Я не могу понять "требования" за этим кодом. Все 4 операции доступны для конечного пользователя? Операции записи и печати как-то связанны между собой? Например печать берёт отчёт, ранее записанный в базу? Откуда берётся отчёт для записи в базу?
А вообще ваша задача очень похожа на проблему выражения у которой нет хорошего решения. А как из возможных решений выбирать, зависит опять же от требований и кофейной гущи - что чаще у вас будет появляться, новые данные или новые операции?
inkelyad
23.08.2022 08:58Да нет, есть вот просто четыре куска логики, которые условно функциями обозначены и их нужно раскидать по контейнерам - namespace-ам. Я тут явно зря написал пример в виде классов - надо было более абстрактно.
На самом деле оно вообще для программирования не специфично, а просто проблема построения плоской классификации. Вот пример:

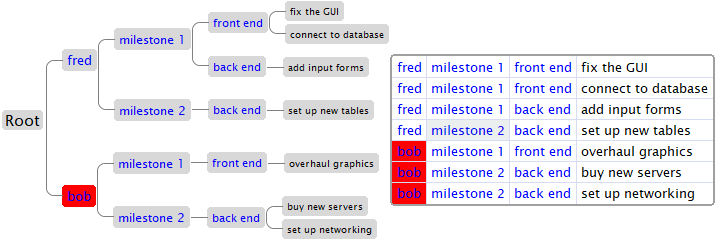
Информация на обоих деревьях одна и та же, просто классификация и контейнеры по разному построены.
jdev Автор
23.08.2022 09:36Для программирования не специфично, но в программировании есть свои ограничения, которые исходят из требований и планов/перспектив развития, и без приземления на них выбрать решение невозможно.
Ну и мне всё больше кажется, что вы говорите о "проблеме выражения". Плюс вспомнил ООПный способ её решения


{kind=link}
Ares_ekb
Спасибо за статью. Лично я больше всего склоняюсь к варианту, когда схема данных вынесена в отдельный проект. Причём и сущности, и репозитории, потому что это достаточно связанные вещи. Структура проекта например такая:
com.example.users.entities
com.example.users.repositories
com.example.issues.entities
com.example.issues.repositories
Это делается по двум причинам. Во-первых, это технически проще. Ссылочная целостность данных обеспечивается на уровне СУБД. Проще писать миграции. Проще потом работать с этими данными, строить аналитику и т.п. Да, и распиливание на отдельные проекты или тем более микросервисы особо ничего не даёт. А, во-вторых, и это наверное даже более важная причина, за схему данных должен отвечать один человек. Он гарантирует, что одинаковые атрибуты у разных сущностей одинаково называются, гарантирует, что нет дублирующих сущностей, что сущности правильно выделены и декомпозированы. Если распределять эту ответственность между разными людьми или командами, то начинается полный хаос. Изначально разрабатывать свои кусочки схемы данных могут и разные люди, но в итоге всё равно всё это должен посмотреть один человек.
Это похоже на проектирование по компонентам из вашей статьи. Но только репозитории лежат рядом с сущностями, там практически нет кода, нет смысла их куда-то выносить. А сервисы, контроллеры, DTO, мапперы и т.п. просто нафиг не нужны в большинстве случаев. Достаточно Spring Data REST.
Хотя наверное в большинстве примеров в сети описывается именно стандартная архитектура с сервисами, контроллерами. А в идеале ещё и распиленными на отдельные микросервисы. Обычно это доходит до полного абсурда, когда, например, 3 отдельных микросервиса: пользователи, товары, заказы. При этом каждый микросервис имеет свою небольшую помоечку для сваливания данных, хочешь PostgreSQL, хочешь MongoDB, хочешь Kafka, хочешь просто в файлах храни данные или в реестре Windows - где угодно. Ссылочная целостность? Дублирование данных? Последующее использование этих данных за пределами микросервиса? Не, зачем нам всё это? Главная задача выполнена, монолит распилен, всё остальное по барабану.
Я долго думал почему эта "стандартная" архитектура так популярна:
Данные теоретически в будущем могут храниться не только в базе данных, но и в какой-нибудь внешней системе, файле или ещё где-то. Поэтому нужны сервисы, которые позволяют абстрагироваться от способа хранения. Но вероятность такой ситуации обычно равна примерно нулю. Подобные изменения в любом случае приведут к существенному изменению кода. Какой смысл писать сервисы и контроллеры, интерфейс которых практически один в один дублирует интерфейс репозиториев?
Другая причина зачем это может делаться: чтобы уменьшить связность между слоем хранения данных и API. Если база данных рассматривается просто как свалка чего-то непонятного поверх чего делается красивое и правильное API, то такой подход имеет место быть. Но если схема данных - это фундамент приложения, а API - это просто производная от схемы данных, то они не должны сильно расходиться. Возможна ситуация, когда какие-то данные (например, пароль пользователя) не должны быть доступны через API или сущности должны агрегироваться, но обычно таких расхождений не так много и есть более простые решения, чем создание отдельного слоя DTO.
Третья причина зачем может понадобиться весь этот код - это упрощение тестирования, чтобы можно было всё замокать, сделать какой-нибудь сервис, который сохраняет пользователей не в реальной базе, а просто в списке. Но тут всё просто: нет лишнего кода - нечего тестировать. А для моканья базы данных есть инструменты типа TestContainers, OpenTable, Zonky Embedded Database и других. К тому же лучше тестировать на реальной СУБД, которая будет использоваться в продакшене, а не на списках объектов в памяти.
jdev Автор
Вам спасибо за комментарий:)
Пока что, на уровне СУБД я тоже до последнего стараюсь сохранить общую схему с внешними ключами - я изолирую только код, если у меня нет чёткого понимания когда и почему я буду пилить систему на отдельные сервисы.
А вот тут не согласен. Возможно, дело в личном опыте, но мой говорит, что нарезка даёт очень многое. Если для каждого бита информации нет одного явного места, откуда с ним можно работать и это ограничение не реализовано технически, то очень быстро весь код начинает работать со всей схемой. А в след за этим идёт экспоненциальный рост стоимости разработки, из-за кучи регрессий в неожиданных местах, "волновых эффектах", когда изменение в одной таблице требует изменений во всей кодовой базе.
Тут я в целом с вами согласен, но зависит от масштабов. У меня нет отсечки в таблицах, но в есть в людях - имхо, при появлении пятого бакэндера в команде надо начинать всё пилить пополам - команду, схему, систему. И там за схему снова будет отвечать один человек.
Угу, мне прямо щяс такой легась прилетел, последний баг отлаживал запустив 6 (шесть) микросервисов. Надеюсь продать идею тотального реинженеринга:) Так вот я даже на уровне модулей не это предлагаю, боже упаси - моя идея в том, чтобы провести "транзакционный анализ" и в идеале так нарезать систему, чтобы в выполнении любой транзакции задействовался код только одного модуля.