
Привет, Хабр! На связи Юрий Кацер, эксперт по ML и анализу данных в промышленности, а также руководитель направления предиктивной аналитики в компании «Цифрум» Госкорпорации “Росатом”. В рамках рабочих обязанностей я решаю задачи в промышленности с помощью машинного обучения.
Большую часть работы по созданию моделей составляет работа с промышленными данными.В условиях стремительного роста объема информации, собираемой на производственных предприятиях в связи с развитием интернета вещей (сбор и хранение данных), важным аспектом становится качество таких данных. В то же время проблемы и ошибки в них становятся препятствием для применения методов машинного обучения и построения моделей на основе законов физики или предметной области. Такие проблемы, как выбросы, пропуски, изменение частоты дискретизации, шум, искажают результаты или делают невозможным практическое использование данных для машинного обучения.
В этой статье мы посмотрим на часто встречающиеся проблемы в промышленных данных типа временных рядов. О том, что такое временной ряд, и о других особенностях задач в промышленности я рассказываю в других статьях на хабре, рекомендую познакомиться, а мы пока перейдем к сути! На схеме ниже приведен большой список проблем в данных, о которых мы поговорим в статье.
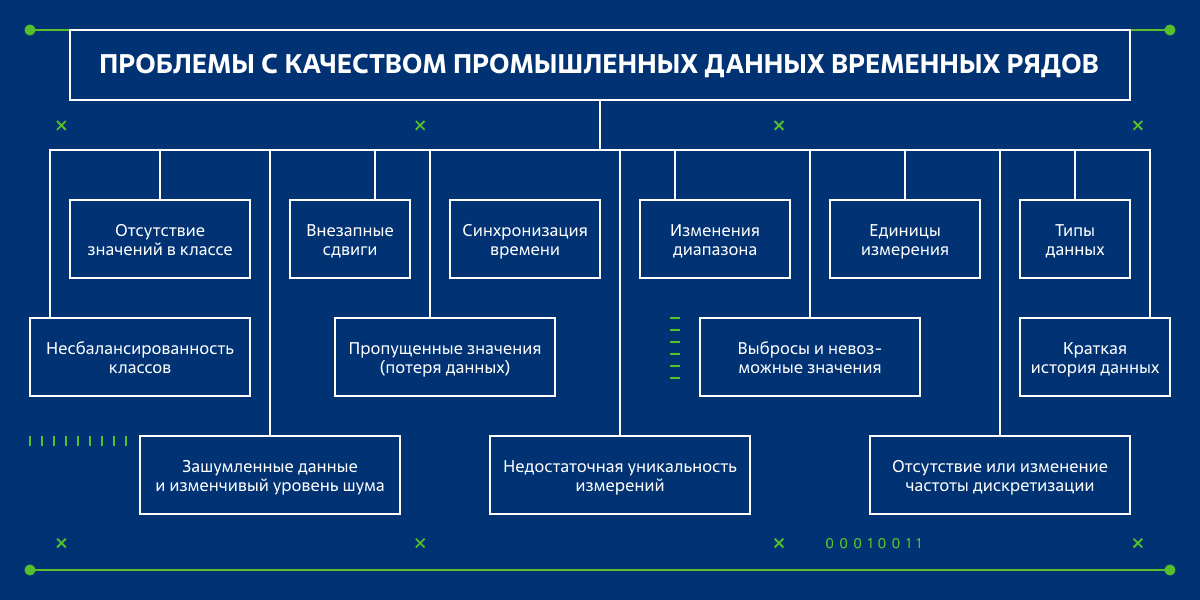
Обзор проблем
Пропущенные значения (потеря данных): пропуски в последовательности точек во временном ряду с регулярной частотой дискретизации.

Внезапные сдвиги: изменения в статистической модели, из которой генерируются данные (изменение технологического процесса, изменение режима эксплуатации, замена или перекалибровка датчика).

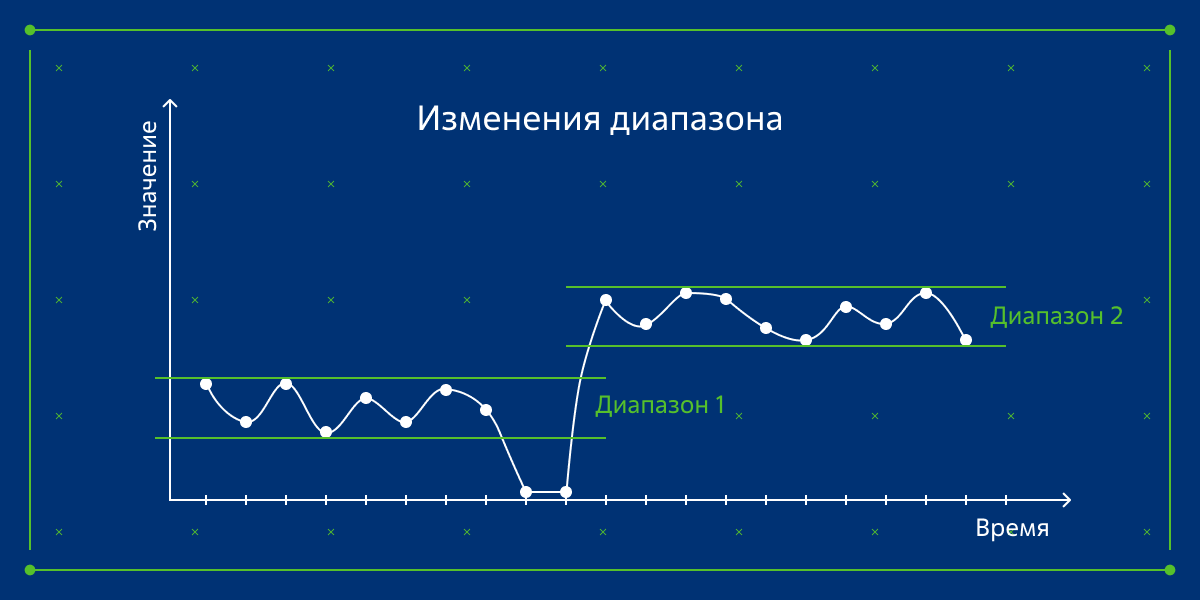
Изменения диапазона: аналогичны Внезапным сдвигам.
Чередование сигналов: сигналы «меняются местами».

Отсутствие или изменение частоты дискретизации: при отсутствии или изменении частоты дискретизации становится невозможным применить какой-либо способ анализа временных рядов, где требуется регулярность временной сетки.

Зашумленные данные и меняющийся уровень шума: слишком высокий или изменяющийся во времени уровень шума в данных.

Недостаточная уникальность измерений: значения становятся неточными из-за округления, высокой апертуры либо других факторов.

Выбросы и невозможные значения: единичные отклонения от ожидаемого поведения данных или значения вне допустимого диапазона доменной области.

Несбалансированность классов: Дисбаланс нормального и аномального классов данных ограничивает возможности применения моделей машинного обучения. Также важно помнить, что такая проблема также может возникать из-за смещения в выборке данных, а не всей генеральной совокупности.
Отсутствие значений в классе: Отсутствие значений, например, в аномальном классе, делает невозможным использование методов машинного обучения с учителем (supervised) или частичного обучения с учителем (semi-supervised).
Краткая история данных: История записи данных слишком коротка для их анализа и обучения моделей.
Единицы измерения: единицы измерения не одинаковы для всех сигналов или источников данных, например, сантиметры и дюймы.
Синхронизация времени: временные метки измерений, поступающих из разных источников, могут немного отличаться, например, UTC+0 и UTC+3.
Типы данных: различные типы данных, например, float и string.
Заключение
Таким образом, этап предварительной обработки данных в пайплайне решения или в процессе проекта становится одним из самых важных для обеспечения качественных результатов решения задач и даже применимости некоторых методов машинного обучения. Подробности, касающиеся части предварительной обработки, были представлены в этой статье и ссылках в ней.
Больше информации по теме можно почитать в этих статьях:
Могут быть полезны следующие научные статьи по теме проблем в данных:
Gitzel, Ralf. “Data Quality in Time Series Data: An Experience Report.” CBI (Industrial Track). 2016.
Pastorello, Gilberto, et al. “Observational data patterns for time series data quality assessment.” 2014 IEEE 10th International Conference on e-Science. Vol. 1. IEEE, 2014.
Hubauer, Thomas, et al. “Analysis of data quality issues in real-world industrial data.” Annual Conference of the PHM Society. Vol. 5. №1. 2013.
Комментарии (9)

adeshere
08.09.2022 18:36+2Я бы еще добавил сюда два довольно типичных дефекта, которые серьезно нарушают однородность сигнала:
1) псевдозапись и
2) изменение масштаба.
Псевдозапись - это когда в измерительной системе что-то "заклинивает" и она начинает писать одинаковые или почти одинаковые значения. По моему опыту, это совершенно типовой брак. Я почти не встречал сколько-нибудь длинных рядов относительно высокочастотного мониторинга (с дискретизацией 1 Гц или выше), где этот дефект отсутствовал бы. Мы для выбраковки таких серий включили в свой пакет специальную функцию, которая чистит временной ряд от этого брака. На вход она берет количество одинаковых значений данных (=минимальную длину бракуемой серии) и критерий "одинаковости" (чтобы функция считала одинаковыми слегка флуктуирующие значения, а не только в точности совпадающие). И еще: когда будете делать свой вариант, не забудьте, что такие повторяющиеся значения могут чередоваться с пропусками данных - брак от этого не перестает быть браком.
Псевдозапись надо обязательно выбраковывать, если при обработке считаются любые фрактальные статистики или оцениваются свойства высокочастотной составляющей. Иначе алгоритм будет безбожно врать, как только в скользящее окно попадет подобный фрагмент.Второй баг - это скачок коэффициента масштаба. Очень часто при замене датчиков или блоков в системе регистрации новый коэффициент усиления (умножения) не равен старому, хотя теоретически блоки/датчики идентичные. Но по данным разницу видно сразу же, если сигнал достаточно однородный.
Вообще, если в рядах есть сдвиги (скачки) уровня, то с очень большой вероятностью там и с масштабом не все гладко. Поэтому у нас оценка постоянства масштаба входит в базовый алгоритм "дефектоскопии данных". Для проверки наличия такого сдвига можно посчитать дисперсию высокочастотной составляющей ряда в скользящем окне и проверить ее постоянство. Мы для этого сперва жестко убираем из сигнала все, что хоть немного похоже на выброс, потом убираем низкие частоты ядерным сглаживанием, потом считается дисперсия сигнала в скользящем окне, затем полученный ряд скользящей дисперсии сглаживается медианой, и уже этот ряд скользящей медианы тестируется на скачки/сдвиги.
Впрочем, найти скачок масштаба - это только полдела, потом его еще устранить надо, чтобы сделать ряд однородным. И вот тут обычно оказывается, что скачок масштаба сопровождается еще и сдвигом уровня, т.е. нужно делать полноценное линейное преобразование по типу Ax+B с оцениваемыми коэффициентами А и B, а не просто умножить на что-то.А разве в технологических картах реактора не прописаны диапазоны значений? Или сборка данных не подразумевает их чистку на месте сбора?
Заведомо нереалистичные значения (типа отрицательной амплитуды), конечно, надо отсекать сразу. Но очень часто в данных есть менее очевидный брак, для выявления которого нужно проводить специальный анализ, иногда с участием эксперта. Мы у себя поэтому ведем не одну, а две базы данных: с первичными сигналами и с почищенными.
В первичную базу данных грузятся непосредственно те сигналы, которыепоступили с регистраторов
У нас это ana+anp-файлы, которые записываются где-то на пункте наблюдений, а затем по сети пересылаются в центр обработки с определенной регулярностью. Эти данные грузятся в "черновую" БД и сшиваются в непрерывный ряд в автоматическом режиме, сразу по мере поступления.
Затем полученные данные проходят через процедуру очистки (у нас это называется первичная обработка, и ее обычно контролирует оператор), и только после этого они загружаются в "чистовую" БД, которая используется для анализа наблюдений. При этом первичные (нечищеные) сигналы тоже хранятся, и к ним всегда можно вернуться - например, если захотелось что-то подкрутить в алгоритме первичной обработки.
Такая архитектура системы обусловлена спецификой научного мониторинга, основная цель которого - изучение наблюдаемых процессов, а не управление ими. Фактически у нас нет задач реального времени: анализ ведется преимущественно ретроспективно. В зависимости от вида наблюдений, запаздывание обработки может составлять от суток до месяца, а иногда бывает и больше. А оперативный контроль данных нужен прежде всего для того, чтобы убедиться, что измерительная система работает и с ней все в порядке.
И хотя проблемы качества рядов данных у нас практически те же самые, но отсутствие требования работы в реальном времени сильно расширяет арсенал инструментов, доступных для их решения. Напоследок приведу пару ссылок на публикации, где обсуждаются используемые у нас методы и подходы:
Развитие систем прецизионных наклономерных наблюдений в условиях подземной обсерватории
А полные тексты этих статей выложены вот здесь.

eteh
08.09.2022 22:20Частично в узкой сфере наблюдения за более-менее стабильным процессом нас на кафедре учили использовать метод главных компонент, который убирает множество недостатков, но это применение в промышленности. Его недостатки достаточно сложный мат. аппарат на матрицах, зато интерпретировать можно хоть нечеткой логикой, хоть экспертными таблицами.

Katser Автор
10.09.2022 20:54Интересно Ваше мнение, с какими из представленных проблем он борется (или какие недостатки убирает), потому что в первую очередь мне он знаком как метод снижения размерности
Katser Автор
10.09.2022 20:50+1Спасибо за дополнения и ответы на вопросы, а также за полезные материалы!

MonkeyKosta
10.09.2022 20:54У меня в основном глючит сеть. Ничего если это - температура с периудом опрса 10сек. Но скорсти и нагрузка приводов - это критично.
OBIEESupport
А разве в технологических картах реактора не прописаны диапазоны значений? Или сборка данных не подразумевает их чистку на месте сбора?
BONDiana
В ядерной энергетике никогда не работал, но с теми промышленными объектами, на которых работал ситуация следующая. На первом уровне сбора информации данные никогда не подвергаются изменению, показывается все как есть. Уже на следующих уровнях происходит верификация, нормализация, отбрасывание части значений, но при этом "сырец" всегда храниться.
Katser Автор
К сожалению, встречал кейсы, когда данные вообще не хранились, либо сохранялись только после каких-то преобразований. По опыту: чем выше уровень автоматизации и цифровизации, тем чаще хранятся сырые данные и вообще стратегия работы с данными становится осмысленнее и лучше с точки зрения машинного обучения и data science.
Katser Автор
Речь в статье идет скорее о промышленных производствах и других менее "опасных" и "закрытых" объектах промышленности, а не о реакторах или АЭС в целом.
Не могу ничего, к сожалению, сказать про данные на реакторах)