

Для ML-моделей не нужны (и даже вредны) персональные данные. Но пригодятся данные, которые описывают не отдельных людей, а их группы, то есть обезличенные. Как их получить и как с ними работать? Как убедиться, что права того, чьи данные были взяты за основу, не нарушены? И где граница между персональными и анонимными данными?
Меня зовут Алексей Нейман, я исполнительный директор Ассоциации больших данных. В этой статье попробуем разобраться в этих вопросах.
Проводим грань между анонимными и персональными данными
Что такое персональные данные? Согласно 152-ФЗ, персональные данные — это «любая информация, относящаяся к прямо или косвенно определённому или определяемому физическому лицу (субъекту персональных данных)». Значит, анонимные данные — информация, которую нельзя отнести к какому-либо физическому лицу. В законе такого понятия нет, но оно вытекает из него естественным образом.
По идее, восстановить связь анонимных с субъектом персональных данных невозможно. Но бывает ли такое в реальной жизни?
Методов анонимизации данных много. Они обобщают данные и подавляют персональные признаки. На выходе получаем сухую статистику, которая бесполезна для разработки моделей. Всему виной уничтоженные скрытые закономерности: ведь у нас теперь усреднённые данные, которые применимы ко всем.
Между персональными и анонимными есть данные, в которых нет идентифицирующих признаков, но которые ещё не полностью анонимны. Давайте назовём такие данные обезличенными. Они отлично подойдут для обучения моделей ML.
Обезличенные данные сочетают особенности и персональных, и анонимных данных:
Обезличенные данные можно получить из персональных методами анонимизации (существует несколько самых распространённых подходов).
Обезличенные данные не содержат прямых идентификаторов, но могут содержать много косвенных. Например, населённый пункт или место работы. Комбинация косвенных идентификаторов может раскрыть личность.
Данные содержат специфическое знание о группе людей. Например, возраст или музыкальные предпочтения.
Связь данных с персоналиями не полностью разорвана и для каких-то персоналий может быть восстановима. Допустим, нам известны место работы и должность. Некоторые массовые специальности типа «руководитель отдела» или «специалист» не дают восстановить связь, а «генеральный директор» или «главный бухгалтер» — легко восстанавливают связь.
Обезличенные данные содержат всю информацию о людях, необходимую для работы модели. Например, мы знаем окончания имён и что в русском языке большинство женских оканчивается на гласную. Теперь мы легко обучим модель предсказывать: кто захочет пойти в картинг, а кто — в магазин косметики.
Итак, если вычищать из персональных данных идентифицирующие признаки, то спустя какое-то время мы получим остаточный датасет. Однако он будет бесполезен для многих операций. Например, если обучить модель предсказывать покупку автомобиля марки Toyota в сентябре, удаление сведений о доходах человека станет для модели фатальным. Но если удалить не всё, мы не достигнем полной обезличенности. Чем нам это грозит?
Сталкиваемся с трудностями в работе с персональными данными
Обработка персональных данных жёстко регулируется законом. Обрабатывать их можно только с согласия человека. Технические требования к средствам обработки весьма суровы:
В помещение с оборудованием могут попасть люди из утверждённого списка.
Регистрируются и анализируются все подозрительные события.
Обязательны антивирус и криптография.
Законодательно понятие «анонимные данные» не установлено. На практике анонимными считаются данные, полученные из персональных путём подавления ряда признаков, последующей агрегации и с заключением внутренних служб комплаенса или информбезопасности. Если мы считаем датасет анонимным, закон не ограничивает работу с ним. Иными словами, мы оперируем информацией и статистикой свободно. Технические требования к обработке также не регламентируются.
Как мы видим, подход к устранению рисков совершенно разный. Для персональных данных риски уменьшаются за счёт введения юридических, организационных и технических ограничений их обработки без изменения самих данных. Для анонимных — за счёт изъятия из персональных данных всех чувствительных связей, без ограничений по их дальнейшей обработке.
Подходы к анонимизации данных не гарантируют, что все риски для физических лиц устранены. Будь это не так, никто не слышал бы об утечках персональных данных (риски, связанные с обработкой персональных данных) или скандалах с публичными личностями (риски, связанные с публикацией анонимных данных). Выходит, в обоих случаях есть лишь приемлемый порог риска обработки данных, при котором можно и хорошо защитить персоналии, и эффективно работать с данными. Как же нам подобраться к оптимальному датасету, максимально избегая рисков?
Оцениваем риски при работе с персональными данными

Риски работы с данными можно поделить на две группы. Во-первых, это риски, связанные с данными. Вдруг мы не убрали из датасета идентифицирующую информацию о человеке, и злоумышленник сможет получить персональные данные. Риски данных измеряются специальными показателями (о которых можно прочитать подробнее):
K-anonymity — свойство обезличенных данных, при котором в наборе данных должно быть не менее k лиц, обладающих общим набором атрибутов, которые могут стать идентифицирующими для каждого человека. Например, если k = 3, а потенциально идентифицирующими переменными являются имя и возраст, то набор данных с k-anonymity имеет не менее трёх записей для каждой комбинации значений имени и возраста. В наиболее распространённых вариантах для k-anonymity используются такие методы преобразования, как обобщение, глобальное перекодирование и подавление.
L-diversity и t-closeness расширяют понимания рисков для уже сгруппированных данных с k-anonymity при атаках на приватное знание о группе субъектов, а не на реидентификацию отдельных субъектов.
Чем больше будут значения этих трёх параметров, тем более обезличенными получатся данные, а значит, бесполезными для ML. Помимо этого, данные могут защищаться при помощи шифрования и кодирования (о разнице в подходах можно почитать у @RuslanYamilov), а также других методов криптозащиты.
Во-вторых, контекстные риски: насколько защищён контур, в котором обрабатываются датасет. Опасность заключается в том, что злоумышленник доберётся до самого датасета и украдёт данные. Как организовать защиту контура — описано в требованиях ФСТЭК и Европейского агентства по кибербезопасности ENISA. Сейчас применяются методы AutoML для обучения моделей и защищённые machine-only среды: работа с обезличенными данными происходит без оператора-человека. Таким образом, скомпрометировать данные некому. Но бывает, что искать связь данных с конкретными лицами — это прямое назначение модели, то есть если сама модель предназначена для идентификации (например, модели антифрода и борьбы с мошенниками). Чтобы всё же скомпрометировать данные, придётся поработать и восстановить связи с персоналиями по оставшимся косвенным признакам.
Защищают/ограничивают контур обработки информации для того, чтобы кто-то чужой не смог до этой информации добраться и использовать её не по тому назначению, по которому она в этом контуре обрабатывается. Для общедоступной информации этот риск равен 1, так как никто не может запретить читателю использовать общедоступную информацию как угодно. Например, «Яндекс» публикует статистику заболеваемости ковидом в Москве. Это анонимный датасет, который может скачать любой из нас и использовать с любой целью: хоть Минздрав критиковать, хоть сравнивать со статистикой Лондона. Словом, контекст обработки не задан. Организация обработки обезличенных данных не вызывает трудностей, при этом её риски оказываются не выше приемлемых на сегодняшний день для обработки ПД и анонимных данных.
Совокупный риск обезличивания — это произведение риска данных на контекстный риск. Совокупность двух рисков показывает, в каких условиях и какой датасет мы можем обрабатывать. Защита контура обработки обезличенных данных при разработке и работе моделей воздействует на контекстный риск. А вот при работе с анонимными данными незачем ограничивать контур обработки. При этом операция обезличивания при построении моделей, в свою очередь, уже влияет на риск данных по сравнению с рисками данных при обработке ПД.
Выходит, нивелировать риски можно двумя основными способами: первый — убирать из данных как можно больше персональной информации. При таком подходе всегда можно «споткнуться» о предел, когда наш датасет станет бесполезным для ML. Модель перестанет работать, её предсказательная способность упадёт почти до нуля. Если для модели, цель которой — предсказать вероятность покупки памперсов в этом месяце, убрать данные о возрасте и поле детей, датасет может стать бесполезным. Значит, надо вовремя остановиться, перестать агрегировать данные из датасета и начать нивелировать риски вторым способом — защитой контура.
Подобрать алгоритм действий для получения обезличенного датасета с сохранением его полезности для ML не так-то легко. Для разработки моделей мы отбираем полезные показатели с большой степенью значимости, то есть показатели, которые влияют на предсказательную способность ML. Поэтому вряд ли удастся существенно изменять эти показатели при применении методов обезличивания.
Значит, надо найти компромисс для разработки каждой модели, который позволит подавлять связь с персоналией по несущественным для работы модели параметрам и при этом позволит оставить, выявить и синтезировать значимые для моделирования параметры. Они могут служить косвенными идентификаторами. Фактически решается классическая задача максимизации функции полезности модели при минимизации рисков данных.
Поэтому мы в АБД отошли от поиска универсальной методики обезличивания. Мы решили поработать с пограничными условиями с точки зрения остаточного риска — и уже на базе этого признавать датасет анонимным или неанонимным. Мы тестируем простейшую модель расчёта риска: у неё индекс 1/k (k — класс эквивалентности) данных для персоналий. Напомним: класс эквивалентности — это количество персоналий, к которым можно отнести информацию в строке датасета. Например, строка «профессия — музыкант, место работы — группа The Beatles, доход — выше среднего» имеет класс эквивалентности “4”. Строка «профессия — премьер-министр, место работы — правительство РФ, доход — выше среднего» имеет класс эквивалентности “1”. Для малых классов эквивалентности риски могут быть уменьшены за счёт шифрования косвенных идентификаторов.
А есть ли способ оцифровать такой порог риска? И можно ли обезличенные данные обрабатывать для обучения и работы ML-моделей с таким же уровнем риска, сочетая известные подходы к оценке рисков?
Тестируем новый подход к оценке рисков

Предположим, что нам удастся придумать методику оценки рисков, связанных с выходом на персональные данные. В этом случае минимальный (допустим, меньше 0,1) порог риска будет означать, что наш датасет содержит обезличенные данные для работы.
Мы разработали методику, которая считает оба риска. Она представляет собой произведение риска данных на контекстный риск. Представим координатную плоскость, где по оси Х отложена степень обезличивания данных, по оси Y — относительная полезность данных и их защищённость (из единицы вычитаем риск данных). Наша задача — найти оптимальную кривую, когда работа с риском данных и работа с контекстным риском уменьшают совокупный риск до минимума. Идеальным результатом станут два крайних состояния по работе с персональными данными и с открытой информацией.
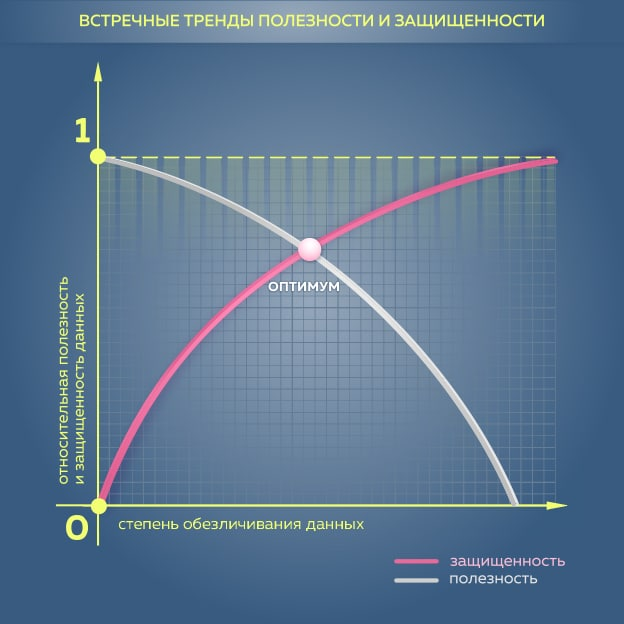
Мы считаем, что хорошим датасетом может стать тот, где данные ещё не анонимны, но хорошо защищены. Мы хотим найти подход, при котором обрабатываем датасет с такой степенью защиты, и насколько такая обработка рискованна или допустима. Допустимость — собственный аппетит рисков и законодательный аппетит к риску. Для этого задействуем индекс 1/k, который планируем усложнять. Ещё мы использовали классическую весовую матрицу ENISA, из которой сделали пополняемую весовую матрицу.
Подробнее о методологии ENISA можно узнать в справочнике, который есть на сайте организации. ENISA также предлагает онлайн-инструменты для оценки рисков в работе с ПД онлайн. При работе с анкетой ENISA мы получаем остаточный контекстный риск, перемножая эти два риска — финальный риск.
Сейчас сотрудники АБД тестируют методику оценки рисков, что позволит считать её в реальных кейсах. Задействованные в тестировании кейсы включают рекомендательный сервис для малого бизнеса, точки касания в маркетинге и бюро кредитных историй. Мы делаем это для сравнения обработки минимизированных данных (ещё не анонимных) с персональными данными. Последние защищены только средствами уменьшения контекстного риска. При этом риск данных практически равен 1.
Тестирование позволит нам решить оставшиеся вопросы, улучшить методику и преобразовать первую версию подхода к оценке рисков в продукт для широкого использования. Планируем рассказать конкретику в следующих статьях.
Если есть вопросы, готов ответить на них в комментариях.