

Современное машинное обучение не только перенимает крутые математические методы, но и подстраивается под стремление человека автоматизировать управление процессами. Природа явления остаётся загадкой. То ли мы добиваемся лаконичности, то ли убиваемся собственной ленью — неважно, если результат оправдывает затраты.
Одним из таких результатов стала AutoML-платорма Brain2Logic стартапа Mavericka, которая недавно была пропилотирована в песочнице Ассоциации больших данных. Платформу помог протестировать Билайн, поставив задачу построить модели для рекомендаций фильмов. В этой статье представлен общий взгляд на современные AutoML-решения с акцентом на проект Brain2Logic (B2L).
Если вам интересно, что смогли придумать в Mavericka, посмотреть на тестирование и почитать наши рассуждения про AutoML — добро пожаловать под кат.
Что такое AutoML: доступное машинное обучение и рынок решений
Сегодня не каждый обязан быть как Галушкин или Хинтон — существуют сервисы AutoML, задача которых — сделать машинное обучение доступным. Но что такое AutoML?
На просторах интернета есть множество определений, которые звучат примерно так:
«AutoML — процесс создания динамической комбинации различных методов для формирования простой в использовании сквозной конвейерной системы машинного обучения».
(Источник — https://neerc.ifmo.ru/)
Определение можно упростить: AutoML — избавление от рутины. Под рутиной мы понимаем выбор оптимального алгоритма, точечную настройку и анализ данных — короче, создание эффективной модели.
Мы давно ушли от самостоятельного проектирования с нуля и пользуемся набором известных алгоритмов и архитектур. Программирование сетей отдалилось от математики. И это неплохо, поскольку даёт сократить производственные издержки научных исследований, где учёные вынуждены обучать модели.
Сегодня AutoML занимается примерно тем же, что и ClassicML: глубоким обучением (AutoDL), анализом естественного языка (AutoNLP), компьютерным зрением (AutoCV) и другими прикладными задачами. Уже сейчас AutoML — революция в машинном обучении.
Хочется процитировать строки из сборника Аркадия Аверченко «Дюжина ножей в спину революции», с которых стартует небезызвестная книга Николенко, Кадурина и Архангельской «Глубокое обучение. Погружение в мир нейронных сетей»:
Прежде всего, спросим себя, положив руку на сердце:
— Да есть ли у нас сейчас революция?
Разве та гниль, глупость, дрянь, копоть и мрак, что происходит сейчас, — разве это революция? Революция — сверкающая прекрасная молния, революция — божественно красивое лицо, озарённое гневом Рока, революция — ослепительно яркая ракета, взлетевшая радугой среди сырого мрака!.. Похоже на эти сверкающие образы то, что сейчас происходит?..
Поспешим ответить — да (скорее да, чем нет). AutoML воссоздаёт доступный подход к работе с данными, прогнозированию, что важно, когда спрос на digital-профессии постоянно растёт. Начиная с 2010 года количество опубликованных вакансий в сфере digital выросло на 1561 % (данные hh.ru на 1 ноября 2021 года). Поэтому автоматизированное машинное обучение — это классно.
Вместе с потребностью приходит и масса предложений от цифровых гигантов: Google, Сбербанка и др. И да, тот же Google AutoML — такой, каким представляется среднему DS-специалисту. И даже какой-то группе учёных, будь то хоть исследователи в области физики, такое решение зайдёт.
Например, автоматическое машинное обучение использовалось в исследовании Magnetic control of tokamak plasmas through deep reinforcement learning. Нейронная сеть автоматически настраивала размеры входного и выходного слоёв и контролировала управляющие обмотки на токамаке.
Однако глазами, например, простого бизнес-аналитика решение от гугла будет видеться идентичным ClassicML, и принцип «We need to go deeper» сохранится.
Сейчас на рынке нет продукта с полноценным френдли-интерфейсом, который не напоминал бы Jupyter Notebook или им же не являлся. Нам не известен доступный no-code-сервис, который смог бы предоставить гибкую настройку или дать пользователю выбрать модель. Над этим и работает команда B2L.
Brain2Logic — это бизнес-решение для машинного обучения и предиктивной аналитики, позволяющее управлять сложными алгоритмами, настраивать и адаптировать модели с открытым исходным кодом. Подразумевается, что подавляющая часть ЦА — это именно бизнес-аналитики.
Несмотря на прямое отношение к B2L, мы постараемся дать реальную оценку этому проекту в контексте развития AutoML.

Лучший вариант — посмотреть глазами пользователя, как всё работает. Перемещаемся в недра UI Brain2Logic!
Просто и наглядно. Тестируем платформу
Brain2Logic — это веб-платформа, т. е. вычислительные мощности клиентского компьютера не затрагиваются вовсе. История не нова, так как уже давно облачные сервисы захватили внимание пользователей.
Устроено всё просто: веб-клиент обращается через API-запросы к Nginx/HAProxy-серверу, на котором и происходит магия вычислений (напоминает Kaggle или Google Collab). Но Brain2Logiс выделяется интерфейсом, отличным от рабочего пространства типа Jupyter Notebook. Jupyter Notebook выглядит вот так (на скриншотах произвольный код):
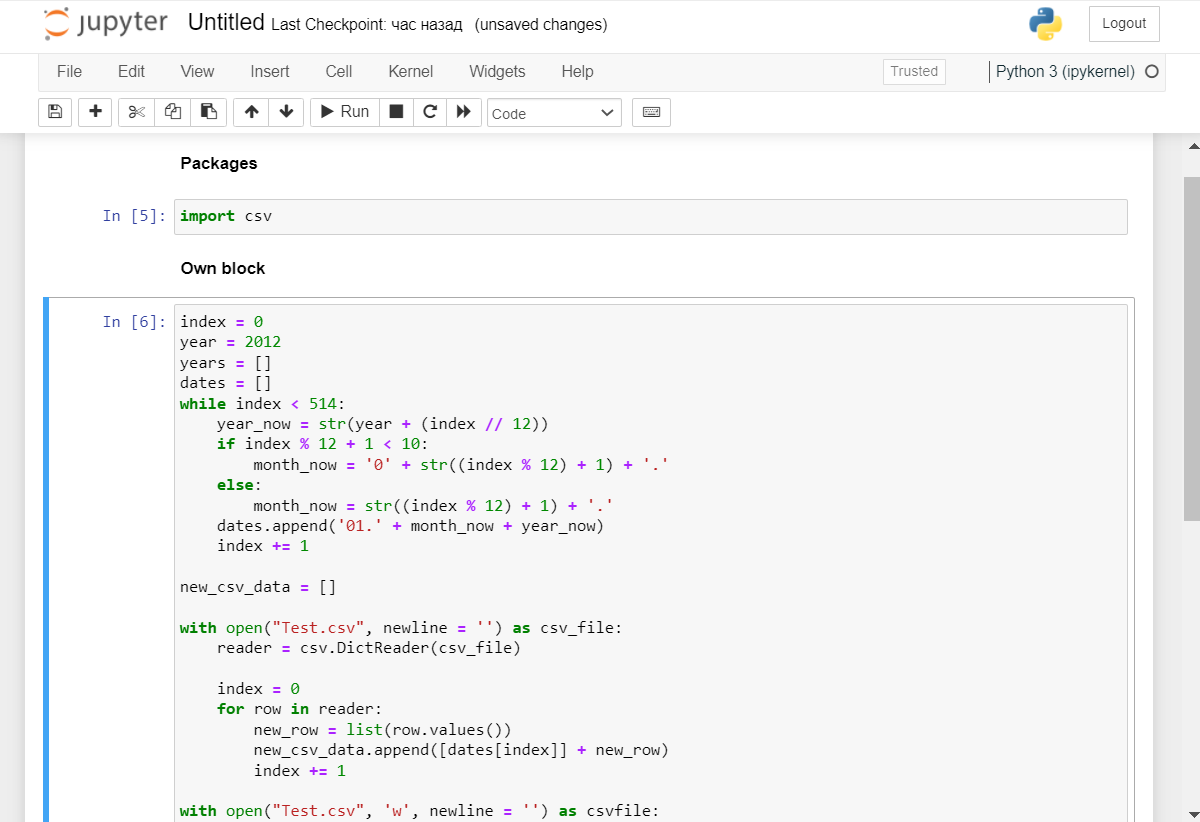
Сравните с Brain2Logiс:

Платформа умеет делать регрессию, прогнозирование временных рядов, классификацию и кластеризацию.
Давайте попробуем сравнить B2L с нативным методом решения ML-задач.
За основу возьмём небезызвестный boston_dataset, понравившийся любителям книжек по ML. Например, тот же датасет рассматривается в книге «Занимательная манга. Машинное обучение» авторства Араки Масахиро и Ватари Макана. Датасет небольшой, всего 506 сэмплов и 14 параметров: уровень преступности, количество комнат, географическое положение — и все прочие данные, связанные с недвижимостью.
Нативное решение на Scikit-learn
Попробуем реализовать сначала на Python, с помощью библиотеки Scikit-learn.
Для этого нужно импортировать библиотеку и сам датасет:
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegressionПосле нужно загрузить параметры и таргеты из датасета:
boston = load_boston()
X = boston.data
y = boston.target Произведём обучение с набором признаковых описаний X и точной информацией y в качестве аргументов:
lr1 = LinearRegression()
lr1.fit(X, y) Теперь можно провести регуляризацию. Используем формулу суммы квадратов (последняя строка) и коэффициенты линейной регрессии (coef_):
print("Linear Regression")
for f, w in zip(boston.feature_names, lr1.coef_):
print("{0:7s}: {1:6.2f}".format(f, w))
print("coef = {0:4.2f}".format(sum(lr1.coef_**2)))И получаем результат:
Linear Regression
CRIM : -0.11
ZN : 0.05
INDUS : 0.02
CHAS : 2.69
…
B : 0.01
LSTAT : -0.53
coef = 341.86 Отлично! Теперь протестируем регрессию на основе того же датасета, но на платформе B2L.
Реализация на Brain2Logic
Для начала загрузим источник (под источником в B2L понимается датасет). Это можно сделать либо с помощью библиотеки встроенных источников (из базы данных или поставляемых по API), либо самостоятельно. В нашем случае используется свой источник — CSV-файл с 14 параметрами и 506 сэмплами, как и в предыдущем примере.

На основании этих данных нужно обучить модель (создать историю). Для начала следует определиться с параметрами, которые будут участвовать в регрессии. С этим проще, так как мы сразу, в несколько кликов, можем определить используемые параметры — притом не обязательно удалять определённые колонки.
Пусть в качестве выбранных параметров выступят crim, zn, indus, nox и, допустим, rm.
crim |
Уровень преступности на душу населения по городам |
zn |
Доля жилых земель, зонированных под участки площадью более 25 000 кв. футов |
indus |
Доля неторговых площадей в городе |
nox |
Концентрация оксида азота (parts per 10 million) |
rm |
Среднее количество комнат в жилом помещении |
Смысл каждого из параметров
В качестве таргета возьмём величину crim, тогда как остальные параметры обозначим просто числовыми величинами:
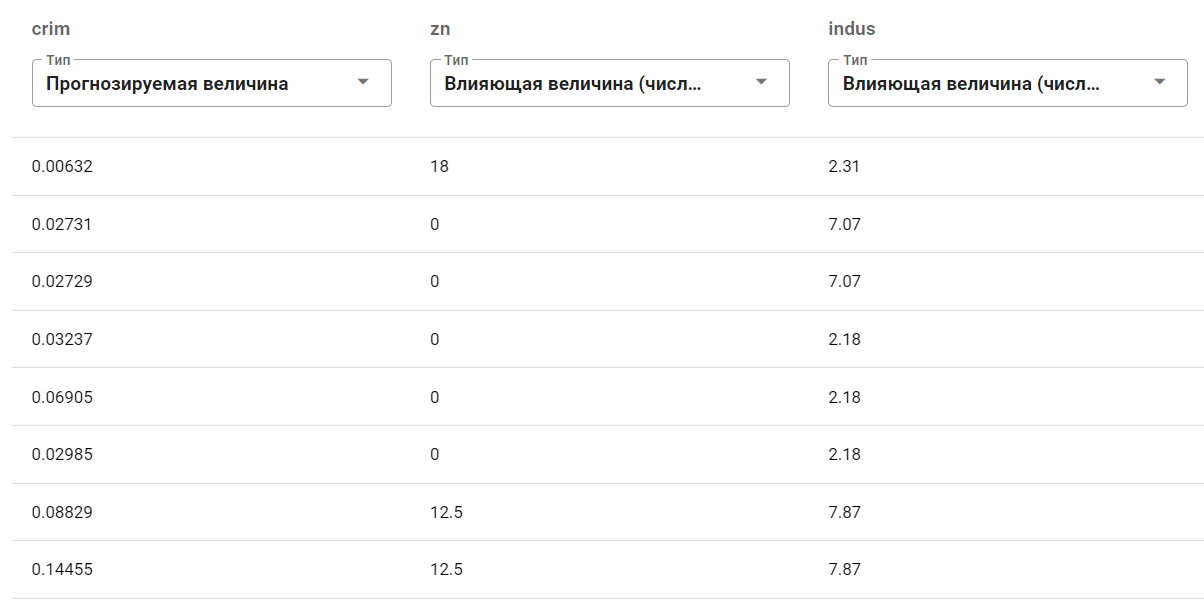
Теперь, пожалуй, самая сложная часть прогноза — скормить данные (тестовую выборку) для прогнозирования. Для этого возьмём, например, три записи со случайными значениями влияющих величин. Пусть будет что-то такое:
zn |
indus |
nox |
rm |
15 |
6.31 |
0.746 |
4.575 |
5 |
5.07 |
0.566 |
3.421 |
10 |
9.07 |
0.234 |
9.185 |
Итак, после загрузки данных для обучения и прогнозирования мы получаем forecast со следующим содержанием:

Итого вернулось три сэмпла со значениями прогнозируемой величины crim c помощью XGBoost и LightGBM — достаточно мощных алгоритмов, точечная работа с которыми заняла бы время, если бы мы это закодили на Python, пусть и с помощью библиотеки XGBoost. Обратим внимание, что в примере на Python использовалась только линейная регрессия. Хотя даже сейчас находятся уникумы, что пишут тот же XGBoost с нуля.
Глядя на результат, можно сделать выводы. Например, отрицательное значение crim в ячейке (5;3) может свидетельствовать о том, что мы задали «фейковые» значения параметров — т. е. такие значения, которые сильно разнятся с теми, что подавались во время обучения.
Вот немного жуткая, но отчасти забавная гипотеза, объясняющая такой вывод:
«Количество душ на приходящиеся площади велико (о чём свидетельствуют параметры zn, indus и rm), но недостаточен уровень концентрации оксида азота (nox), из-за чего люди страдают и не могут вести криминальную деятельность».
Конечно, к результатам стоит подходить с иронией, поскольку реальное исследование предполагает большее количество параметров. Однако такой регрессионный анализ провести гораздо сложнее — это одна из нерешённых проблем, к которой мы ещё вернёмся.
Наверное, можно выдвинуть какие-то другие предположения, но оставим эту задачу для вас — напишите в комментариях!
Итак, мы сравнили натив и B2L. И мы говорим даже не о количестве совершённых действий, а о визуальной доступности. Попробуйте догадаться, что окажется более заманчивым и дружелюбным для рядового пользователя или бизнес-аналитика.
Эксперимент с билайн
Недавно в песочнице Ассоциации больших данных был завершён второй пилот, в ходе которого на базе Brain2Logic команда Mavericka реализовала рекомендательный сервис для телеком-оператора билайн — активного участника нашей ассоциации. На базе того же билайн ТВ мы тестировали ранее CleverDATA (группа ЛАНИТ) — это был первый проект в песочнице АБД, про который мы тоже написали статью.
Задача B2L во время эксперимента — подбирать контент для каждого пользователя на базе истории потребления и подбора аналогичных сочетаний множества характеристик контента.
Пользователи |
750 |
Характеристики контента |
380 |
Модели ML |
4 |
Параметры управления |
50 |
Параметры эксперимента
Но для чего всё это? Ведь однозначно крупные стриминговые сервисы типа Netflix и YouTube используют под капотом строго задокументированные кодовые решения.
Дело в том, что именно на базе билайн была возможность в сжатые сроки проверить гипотезу. Сервис Brain2Logic позволяет бизнес-пользователям, не программируя, настраивать алгоритмы машинного обучения и управлять данными для прогнозирования, а также сокращает трудозатраты на рутинную работу с этими алгоритмами.
На старте — задача классификации с заранее подготовленным датасетом со стороны билайн, на котором обучались две модели, построенные DS-специалистом и платформой B2L соответственно. А после — сверялись время сборки модели и точность прогнозирования на тестовом датасете. Тут стоит упомянуть, что все данные поступали в обезличенном формате и не были открыты для Mavericka. Эксперимент проходил по всем канонам этики обращения с данными — этого удалось достичь благодаря нашей песочнице Ассоциации больших данных.
Подтвердилась ли гипотеза? Да, как и работоспособность платформы. Пока, конечно, нельзя сказать, что это полностью готовый продукт: Brain2Logic не в общем доступе, использовать можно лишь по согласованию с Mavericka. Работы над сервисом ещё ведутся. Однако он постоянно будет нуждаться в каких-то доработках в силу развития машинного обучения.
Вспоминается цитата из фильма Рауля Пека «Молодой Карл Маркс» / Le jeune Karl Marx:
«Изгнанный в Англию, благодаря поддержке Дженни и Фридриха, Маркс продолжал писать свою ключевую работу «Капитал» до самой смерти. Открытая, неизмеримая работа, и незавершённая. Потому что сам объект её критики находится в вечном движении».
Общая проблема, которую сейчас активно решает команда Mavericka, — вопрос осведомлённости пользователей о причинах недостаточной точности моделей. Команда прикладывает к увеличению точности много усилий: чтобы сами модели догадывались за пользователей, что не так, и лучше давали прогнозы, совершая при этом меньшее количество настроек (условно — чтобы модель сама улавливала определённые тренды). Последнего удалось достичь с помощью оптимизаторов модели: Hyperopt, Optuna, Ax, Dragonfly, BOHB и других — которые ускорили настройку моделей и сделали их точнее, тем самым затмив стандартный grid search, на который опирался B2L до эксперимента.
То есть стало возможным улучшать точность прогнозирования: оптимизаторы умеют буквально за несколько шагов сравнивать сэмплы и находить наиболее влиятельные параметры. Но это ещё не всё.
Первое, с чем столкнулись дата-сайентисты из билайн, — не хватало параметров регулировки модели. Чтобы исправить это, в платформу добавили тюнинг параметров. Это позволило устанавливать кросс-валидацию, вероятностные пороги для классов.
На выходе получился такой интерфейс, с помощью которого можно выборочно настроить модель:
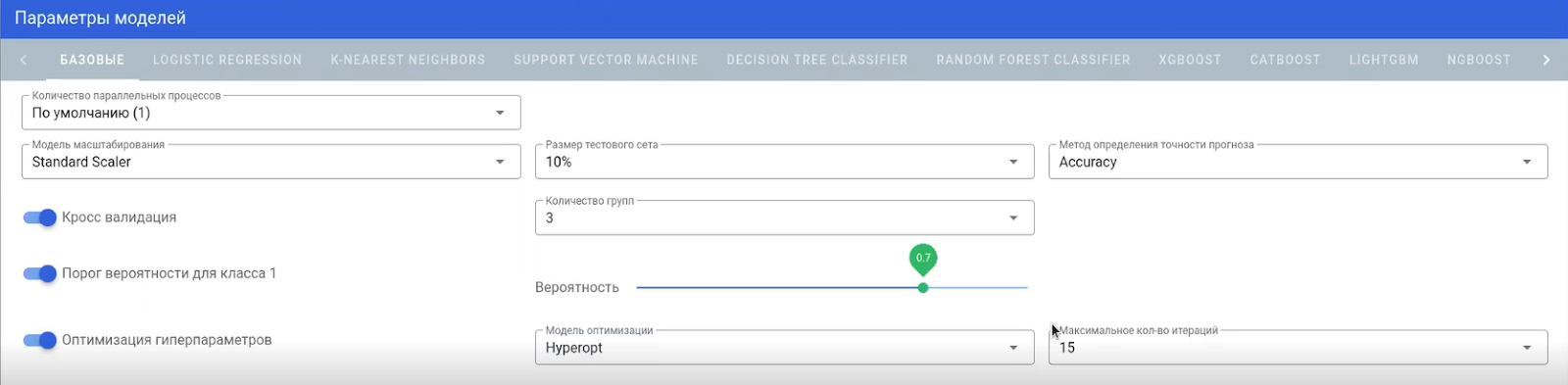
Есть также возможность установки максимального количества итераций. То же самое есть и в Jupyter’е, но вычисления происходят на одном ядре, тогда как в B2L их можно производить сразу на нескольких ядрах.
Со всеми нововведениями удалось ускорить настройку моделей в два раза и, самое главное, – довести точность прогнозирования B2L по показателю AUC ROC с 72 % до 86 %, что достаточно хорошо.
Какие выводы мы получили
Нельзя сказать, что Brain2Logic может полностью заменить работу опытного специалиста. Пока что это не так. Но у B2L есть важное преимущество — экономия денег. Поэтому малому бизнесу хорошо подходят AutoML-сервисы. Тот же Brain2Logic позволяет на коленке решать базовые задачи на прогнозирование и делать регрессию без затрат на содержание ML-специалистов в штате.
Над чем ещё можно поработать
Конечно, удобно, что не нужно копаться с каждым алгоритмом. Достаточно выбрать его и обозначить количество итераций. Тем не менее с ходу, без знаний, с этим не разобраться. И это одна из проблем всех AutoML-решений, будь то платформы Amazon, Google, Microsoft или Brain2Logic.
Некоторые AutoML-платформы кажутся пользователям чрезмерно простыми, но такой эффект присутствует лишь из-за урезанных возможностей, когда нельзя, например, настраивать модели и чистить данные, доступно только прогнозирование временных рядов и так далее.
В B2L ситуация обратная: есть возможность выбирать и настраивать модели (или позволить платформе самостоятельно выбрать лучшую модель), получать пространную отчётность по разным метрикам: MSE, RMSE, MAPE, MAE и др. — но всё это требует хоть какого-то контроля со стороны специалистов.
Если подноготная модели невесома и можно обойтись без дата-сайентиста, то в случаях, отличных от того примера — эксперимента с четырьмя параметрами Boston Housing, когда нужно сформулировать множество гипотез и выводов, построить и максимально точно настроить модель, — всё равно понадобятся аналитики и дата-сайентисты. Хотя последнее скорее не проблема AutoML, ведь машине безразлична семантика параметров в предиктивной аналитике.
Повторим, что в перспективе нужно работать именно над точностью формулировок и осведомлённостью клиентов о том, как работать. Ведь часто совсем не ясно, что требует от пользователя платформа, когда возвращает условный data_error. А причин за такой ошибкой может таиться множество. Самый яркий пример — когда пользователь пытается сделать предсказание на основании датасета из 20 параметров и 5 записей. Очевидно, что обучать модель на таких данных нерационально.
Не исключено, что такого рода проблемы можно решить с помощью грамотной и всеобъемлющей документации. Например, у гугла есть целый видеоряд на YouTube по Cloud AutoML, то же самое и с остальными платформами, и B2L не исключение.

Такие способы обучить пользователя являются необходимыми, но не достаточными. Вернее, сама идея документации не должна быть конечной точкой. Иначе всё может превратиться в эпизод «Кремниевой долины», когда команда стартапа «Пегий дудочник» собрала целый курс для простых обывателей, чтобы объяснить, как функционирует их пиринговая сеть.
В общем, пользовательский доступ к методам AutoML — тот ещё вызов и проблема, которую нужно решать. Зато исследователи в области данных могут спать спокойно, кадры никто сокращать не собирается.
Тем не менее уже сейчас сервисы, подобные B2L, могут избавить дата-сайентистов от мелкой работы и перенаправить их силы на решения более сложных задач, а это дорогого стоит.
Заключение
AutoML определённо позволяет решать пусть и не всегда большие, но задачи — это Brain2Logic доказал в эксперименте.
Нельзя сказать, что революция с целью вседоступности машинного обучения завершена. Скорее она только началась, ведь даже понятие ещё не прижилось, сложно обозначить границы автоматического машинного обучения.
Проблемно и сказать однозначно, каким должен быть AutoML. Должен ли он закрывать капот от пользователей и ограничивать их несколькими действиями? Или, может быть, AutoML полностью настраиваться вручную? Но тогда чем он отличается от визуального программирования?
Если у вас есть идеи, каким должен быть эталонный AutoML-сервис, — будем рады порассуждать в комментариях.