

История машинного обучения (Machine learning, ML) началась в 1950-х, когда появились первые нейронные сети и алгоритмы ML. Однако чтобы стать известным обычному человеку, машинному обучению понадобилось ещё шестьдесят лет. Анализ более чем 16 тысяч статей по data science MIT technologies демонстрирует экспоненциальный рост машинного обучения на протяжении последних двадцати лет, стимулируемый big data и прогрессом в глубоком обучении.
На практике любой, имеющий доступ к данным и компьютеру, может сегодня обучить модель машинного обучения. Возможности автоматизации и создаваемые ML прогнозы имеют множество различных применений. Благодаря им работают современные системы распознавания мошенничества, приложения доставки товаров предсказывают время прибытия на лету, а программы помогают в медицинской диагностике.
Способы создания и применения моделей зависят от потребностей организации и прикладной области ML. Процесс создания моделей машинного обучения подробно описан, однако у ML существует и другая сторона — внедрение моделей в среде продакшена. Модели в продакшене управляются через специальный тип инфраструктуры — конвейеры машинного обучения. В статье мы расскажем о функциях сервисов ML в продакшене и рассмотрим готовые решения.
Что такое конвейер машинного обучения?
Машинное обучение — это подмножество data science, области знаний, изучающей способы извлечения ценности из данных. В свою очередь, ML предлагает методики и практики обучения алгоритмов на этих данных для решения таких задач, как классификация объектов на изображениях, без указания правил и паттернов программирования. По сути, мы обучаем программу принимать решения с минимальным вмешательством человека или с полным его отсутствием. С точки зрения бизнеса, после внедрения в продакшене модель может автоматизировать ручные или когнитивные процессы.
Конвейер (или система) машинного обучения — это техническая инфраструктура, используемая для управления процессами ML и их автоматизацией в организации. Логика конвейера и инструменты, из которого он состоит, сильно зависят от потребностей ML. Но в любом случае конвейер предоставляет дата-инженерам возможности управления данными для обучения, настройки моделей и управления ими в продакшене.
Между обучением и работой моделей машинного обучения в продакшене чёткого разделения нет. Поэтому прежде чем приступать к изучению работы машинного обучения в продакшене, давайте сначала разберём этапы подготовки модели, чтобы в общих чертах понять, как модели обучаются.
Процесс подготовки модели
Строго говоря, весь процесс подготовки модели машинного обучения разбит на 8 этапов. Эта структура описывает самый базовый процесс, при помощи которого дата-саентисты выполняют машинное обучение.
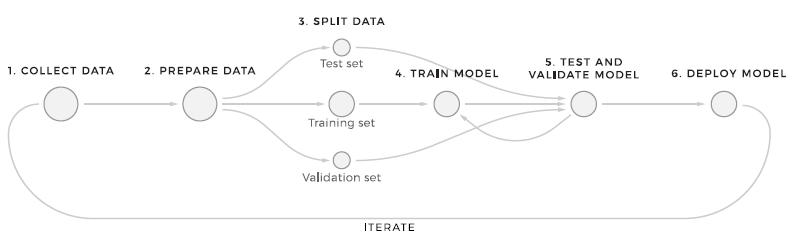
Процесс подготовки машинного обучения
Сбор данных: получение требуемых данных — это начало всего процесса. Специальная команда дата-саентистов или людей, имеющих знания в предметной области бизнеса, определяют данные, которые будут использоваться для обучения. По мнению Франсуа Шолле, этот процесс также можно назвать «формулированием задачи».
Подготовка данных и проектирование признаков: собранные данные подвергаются серии преобразований. Чтобы качество данных было приемлемым для будущих моделей, форматирование, очистка, разметка и обогащение данных часто выполняется вручную. После подготовки данных дата-саентисты приступают к проектированию признаков. Признаки — это значения данных, которые модель будет использовать и при обучении, и в продакшене. Дата-саентисты исследуют имеющиеся данные, определяют, какие атрибуты имеют бОльшую предсказательную силу, а затем создают список признаков.
Основы подготовки данных
Выбор алгоритма: зачастую этот этап выполняется параллельно с предыдущими, поскольку выбор алгоритма — одно из первоначальных решений в ML. В основе любой модели лежит математический алгоритм, определяющий, как модель будет находить паттерны в данных.
Обучение модели: обучение — основная часть всего процесса. Чтобы обучить модель делать прогнозы на основании новых данных, дата-саентисты подгоняют её под имеющиеся данные, на которых она учится.
Тестирование и валидация: затем обученные модели тестируются на данных тестирования и валидации, чтобы убедиться в высокой точности прогнозов. После сравнения результатов тестов модель могут настраивать/модифицировать/обучать на других данных. Обучение и оценка — это итеративные этапы, продолжающиеся, пока модель не достигнет приемлемого процента правильных прогнозов.
Развёртывание: последний этап — это применение модели ML в продакшене. То есть, по сути, это использование модели конечным пользователем для получения прогнозов, сгенерированных на реальных данных.
Конвейер машинного обучения в продакшене
Мы говорили о подготовке моделей ML в своей технической статье, так что подробности можно узнать в ней. Но в целом это всего лишь часть процесса. После завершения обучения модель применяют в продакшене.
Этап продакшена для ML — это среда, в которой модель можно использовать для генерирования прогнозов на реальных данных. На этом этапе нам нужно обратить внимание на несколько аспектов: развёртывание, мониторинг модели и обслуживание. Эти и другие малые операции можно полностью или частично автоматизировать с помощью конвейера ML в продакшене — набора различных сервисов, помогающих управлять всеми процессами продакшена.
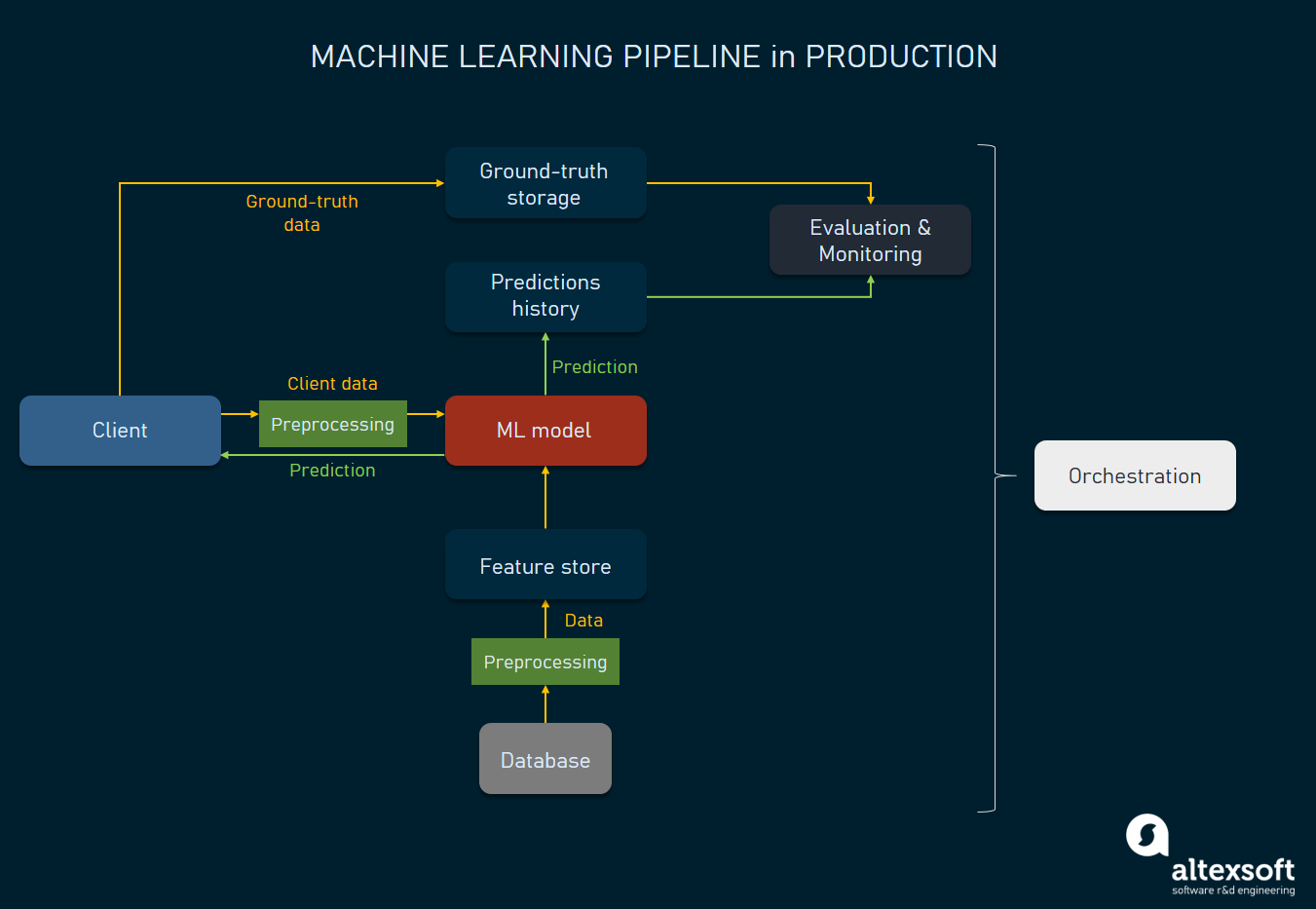
Архитектура конвейера машинного обучения в продакшене
Одно из ключевых требований к конвейеру ML — наличие контроля над моделями, их точностью и обновлениями. Ниже мы рассмотрим стандартную архитектуру и поток такой системы. Мы сегментируем процесс по действиям, расскажем об основных инструментах, применяемых для конкретных операций. Помните, что системы машинного обучения могут быть очень разными, поэтому описанное в статье может отличаться от вашего опыта. Тем не менее, это описание даст вам базовое понимание того, как работают сложившиеся системы машинного обучения.
Вызов модели из клиента приложения
Для описания потока продакшена мы воспользуемся в качестве начальной точки клиентом приложения. При наличии приложения, для которого модель генерирует прогнозы, конечный пользователь будет взаимодействовать с ним через клиент. Работа модели запускается, когда пользователь (или система пользователя) совершает определённое действие или предоставляет входящие данные. Например, если алгоритм машинного обучения занимается рекомендациями продуктов на веб-сайте онлайн-магазина, то клиент (веб-приложение или мобильное приложение) будет отправлять подробности текущей сессии, например, какие продукты или разделы продуктов сейчас изучает пользователь.
Клиент приложения: отправляет данные серверу модели.
Получение дополнительных данных из хранилища признаков
Хотя данные получаются со стороны клиента, некоторые дополнительные признаки могут также храниться в отдельной базе данных — хранилище признаков (feature store). Это хранилище признаков предоставляет модели быстрый доступ к данным, доступ к которым невозможен с клиента. Например, если онлайн-магазин рекомендует продукты, купленные другими пользователями со схожими вкусами и предпочтениями, хранилище признаков предоставит модели соответствующие признаки.
В свою очередь, хранилище признаков получает данные от других хранилищ (пакетно или в реальном времени) при помощи потоков данных. Пакетная обработка — обычный способ извлечения данных из баз данных, получение требуемой информации по частям.
Потоковая передача данных — это технология работы с актуальными данными, например, с информацией датчиков, передающих значения раз в минуту. Для этой цели необходимо использовать такие потоковые обработчики, как Apache Kafka и быстрые базы данных наподобие Apache Cassandra. Хотя в случае онлайн-магазинов обработка в реальном времени не требуется, она может понадобиться для прогнозов модели машинного обучения; допустим, при определении времени доставки требуются данные реального времени о местоположении доставляющей товар машины.
Хранилище признаков: предоставляет модели дополнительные признаки.
Предварительная обработка данных
Приходящие от клиента приложения данные поступают в сыром формате. Чтобы модель смогла прочитать эти данные, нам нужно обработать их и преобразовать в признаки, которые может потребить модель. Этот процесс базовых преобразований данных называется предварительной обработкой данных (data preprocessing).
У хранилища данных может быть специальный микросервис для автоматической предварительной обработки данных.
Препроцессор данных: данные, переданные от клиента приложения и хранилища признаков, форматируются, из них извлекаются признаки.
Генерация прогнозов
Наконец, когда модель получит все признаки от клиента и хранилища признаков, она генерирует прогноз и отправляет его клиенту, а также отдельной базе данных для дальнейшей оценки.
Модель: прогноз отправляется клиенту приложения.
Сохранение эталонных данных и данных прогнозов
Ещё один тип данных, которые мы хотим получить от клиента или от любого другого источника — это эталонные данные. Эти данные используются для оценки прогнозов, сделанных моделью, и для дальнейшего совершенствования модели. Эталонными данными можно назвать те данные, в которых мы уверены, например, реальный продукт, который когда-то купит посетитель. Для хранения этой информации используется база эталонных данных.
Однако сбор эталонных данных не всегда возможен, а иногда его нельзя автоматизировать. Например, продукт, купленный посетителем, будет эталонными данными, с которыми можно сравнить прогнозы модели. Но если посетитель увидел вашу рекомендацию и купил продукт в каком-то другом магазине, вы не сможете собрать подобные эталонные данные. Ещё одна ситуация — когда эталонные данные можно собрать только вручную. Если ваша модель компьютерного зрения сортирует гнилые и целые яблоки, вам нужно вручную размечать изображения с гнилыми и целыми яблоками.
Очевидно, что сами прогнозы и связанные с ними данные тоже сохраняются.
База эталонных данных: хранит эталонные данные.
Мониторинг и оценка модели
Модель, работающая на продакшен-сервере, будет иметь дело с реальными данными и предоставлять пользователям прогнозы. При мониторинге нам важно следующее:
- обеспечивать сохранение высокой точности прогнозов относительно эталонных данных.
- внимательно изучать точность и быстродействие модели.
- понимать, когда модели нужно повторное обучение.
Инструменты мониторинга часто создаются из библиотек визуализации данных, обеспечивающих наглядные визуальные метрики точности. Их интерфейс может походить на аналитический дэшборд:

Инструмент мониторинга для машинного обучения
Существуют научные работы и опенсорсные проекты, в которых можно увидеть такие инструменты. Например, MLWatcher — это опенсорсный инструмент мониторинга на основе Python, позволяющий выполнять мониторинг прогнозов, признаков и разметки у работающих моделей.
Инструменты мониторинга: предоставляют метрики о точности прогнозов и показатели моделей.
Оркестраторы
Оркестратор — это инструмент, выполняющий все процессы машинного обучения на всех этапах. То есть он обеспечивает полный контроль над развёртыванием моделей на сервере, управляет их работой, потоками данных и активацией процесса обучения/повторного обучения.
Оркестраторы — это инструменты, выполняющие по графику скрипты и запускающие все задачи, связанные с моделью машинного обучения в продакшене. Популярными оркестраторами моделей ML являются Apache Airflow, Apache Beam и Kubeflow Pipelines.
Оркестратор: отправляет команды для управления всем процессом.
Конвейер повторного обучения модели ML
Настало время рассмотреть конвейер повторного обучения: модели обучаются на предыдущих данных, которые со временем устаревают. Точность прогнозов начинает снижаться, это можно отследить при помощи инструментов мониторинга. Когда точность становится слишком низкой, нам нужно повторно обучить модель на новых массивах данных. Этот процесс можно выполнять по графику, чтобы повторное обучение проходило автоматически.

Как выполняется повторное обучение моделей
Повторное обучение моделей
Повторное обучение — это ещё одна итерация жизненного цикла модели, в которой, по сути, используются те же методики, что и при обучении. При снижении точности прогнозов можно обучить модель на обновлённых массивах данных, чтобы она могла обеспечивать более точные результаты. Иными словами, мы частично обновляем способности генерации прогнозов модели. Однако это не значит, что при повторном обучении можно добавлять новые признаки, избавляться от старых или полностью менять алгоритм. При повторном обучении обычно используется тот же алгоритм, но ему передаются новые данные. Впрочем, вполне возможно автоматизировать обновления модели целиком при помощи autoML и платформ MLaaS.
Все процессы, выполняемые на этапе повторного обучения до развёртывания модели на продакшен-сервере, управляются оркестратором. То есть мы можем управлять массивом данных, подготавливать алгоритм и начинать обучение. Для повторного обучения при помощи предоставления входящих данных используется сборщик модели. По сути, это автоматизирует процесс обучения, чтобы мы могли выбрать на этапе оценки наилучшую модель.
Оркестратор: отправляет модели на повторное обучение. Формирует новые массивы данных. Передаёт данные, собранные в базах эталонных данных/хранилищах признаков.
Сборщик модели: повторно обучает модели по заданным свойствам.
Оценка моделей-претендентов и отправка их в продакшен
Прежде чем повторно обученная модель сможет заменить старую, её нужно оценить, сравнив с базовыми метриками: точностью, скоростью работы и так далее.
Программа оценки (evaluator) — это ПО, проверяющее, готова ли модель к внедрению в продакшен. Оно может предоставлять метрики точности прогнозов или сравнивать новые обученные модели со старыми при помощи реальных и эталонных данных. Результаты модели-претендента могут отображаться при помощи инструментов мониторинга. Если модель-претендент превосходит параметры свой предшественницы, её можно развёртывать в продакшене. Цикл завершается.
Программа оценки: выполняет оценку обученных моделей, чтобы определить, лучше ли её прогнозы, чем у базовой модели.
Оркестратор: развёртывает модели в продакшене.
Инструменты для построения конвейеров машинного обучения
Конвейер машинного обучения обычно создаётся специализированным образом. Однако существуют платформы и инструменты, которые можно использовать в качестве фундамента. Давайте рассмотрим некоторые из них, чтобы понять принцип.
Google ML Kit. Развёртывает модели в мобильном приложении через API, есть возможность использования платформы Firebase для применения конвейеров ML и тесной интеграции с платформой Google AI.
Amazon SageMaker. Управляемая платформа MLaaS, позволяющая выполнять весь цикл обучения моделей. SageMaker также включает в себя множество инструментов для подготовки, обучения, развёртывания и мониторинга моделей ML. Одна из его ключевых функций — возможность автоматизации процесса обратной связи о прогнозах модели при помощи Amazon Augmented AI.
TensorFlow изначально разрабатывался Google как фреймворк машинного обучения. Теперь он развился до целой опенсорсной платформы ML, однако его базовую библиотеку можно использовать для реализации собственного конвейера. Огромное преимущество TensorFlow заключается в возможностях тесной интеграции при помощи Keras API.
Сложности с обновлением моделей машинного обучения
Хотя повторное обучение можно автоматизировать, процесс выбора новых моделей и обновления старых сложнее. В традиционной разработке ПО вопрос обновлений решается системами контроля версий. Они разделяют всё на ветки продакшена и ветки разработки. Если что-то пойдёт не так, можно откатиться к старой, стабильной версии ПО.
Для обновления моделей машинного обучения тоже требуется скрупулёзный и продуманный контроль версий, а также сложные конвейеры CI/CD. Однако обновление систем машинного обучения — более сложный процесс. Если дата-саентист выпускает новую версию модели, она с большой вероятностью будет потреблять новые признаки и иметь множество других дополнительных параметров.
Чтобы модель работала правильно, изменения нужно внести не только в неё саму, но и в хранилище признаков, способы предварительной обработки данных и многое другое. По сути, изменение небольшой части кода, отвечающего за модели ML, подразумевает существенные изменения в остальных системах, поддерживающих конвейер машинного обучения.
Более того, новую модель невозможно развернуть сразу же. Нужно провести множество экспериментов, иногда включающих в себя A/B-тестирование, если модель поддерживает какую-то функцию, с которой будет работать заказчик. Во время этих экспериментов её также нужно сравнивать с базовыми показателями, даже может потребоваться пересмотр метрик модели и KPI. Кроме того, если модель доберётся до продакшена, необходимо будет сконфигурировать и весь конвейер повторного обучения.
Поскольку эти сложности возникают в сложившихся системах ML, участники отрасли придумали ещё одно жаргонное слово — MLOps; это должность сотрудников, решающих задачи DevOps в системах машинного обучения. Их обязанности и всё с ними связанное достойны отдельного обсуждения в ещё одной статье.
FruTb
"На практике любой, имеющий доступ к данным и компьютеру, может сегодня обучить модель машинного обучения."
Ай. Больно стало. Дальше читать не смог.