
Привет! Меня зовут Даир, я Data Scientist. Эту статью мы писали вместе с Санжаром, моим коллегой, который тоже занимался проектом. Мы расскажем, как научили понимать любые клиентские запросы уже разработанным ранее в Beeline чат-бота.
Фраза «понимание клиента» для нас значит следующее: клиент пишет текстовый запрос с описанием своей проблемы, если чат-бот может уловить суть проблемы, ее тематику и намерение, мы считаем, что мы справились со своей задачей. Намерение клиента в текстовом запросе мы называем «интент» (intent).

На конференции BeeTech Conf 2022 мы рассказывали про первую версию «ванильного» чат-бота, а в статье представляем описание его новой версии 2.0 с дополненными инсайтами и лайфхаками.
Первоначальный чат-бот: вводные данные
На схеме ниже можно увидеть весь наш путь: от постановки задачи до итоговой модели. Работа состояла их четырех условных итераций, после которых мы смогли выкатить в продуктив полноценную модель. Если вы захотите повторить наш путь и обучить своего бота, эта схема может быть полезной.

Перед тем как приступить к постановке задачи, было необходимо осознать, что из себя представляет текущий чат-бот и что мы можем в нем улучшить.
После изучения мы поняли, что Дана (так мы называем нашего чат-бота) — это кнопочный и сценарный чат-бот. Она содержада статичные сценарии и историю обращений клиента к боту, умела распознавать тематику текстового запроса с помощью ключевых слов и отвечала клиенту. Иногда это приводило к тому, что клиенту, уже описавшему свою проблему в тексте, приходилось блуждать по сценариям чат-бота и пытаться помочь себе самому.
Мы решили начать улучшение чат-бот с компоненты распознавания тематики обращения или интент-запроса (намерения). Поэтому нашей задачей стало обучить модель классификации. Для этого нужно определить список интентов и собрать текстовые запросы клиентов с разметкой на интенты.
Чтобы максимизировать эффект от модели, мы решили брать только 15 тематик, по которым чаще всего обращаются клиенты. Для этого собрали статистику по встречаемости сценариев в диалогах чат-бота, представили имеющиеся текстовые запросы в векторном виде и кластеризовали. После анализа сформировали доменно-интентную схему

Постановка и идея с кластеризацией
Конечно, для постороения бейзлайна нам никто не разметил данные, поэтому мы попробовали сделать это самостоятельно. Это стало нашей основной целью на первом этапе.
Источником данных послужили запросы клиентов на русском языке. Среднее количество слов в запросе — четыре, поэтому мы собрали n-grams (словосочетания из 3-5 слов) и решили кластеризовать их разными методами типа тематического моделирования – agglomerative clustering поверх sentence embedding. Агломеративная кластеризация оказалась удобнее, так как с ее помощью получилось задать необходимый трешхолд для расстояния между кластерами и выбрать меру расстояния.
В итоге мы использовали кластеризацию с такими переменными:
AgglomerativeClustering(affinity="cosine",
distance_threshold=distance_threshold,
n_clusters=None,
linkage="complete")Также в выставлении трешхолда расстояния нам помогла дендрограмма. На графике видно примерное расстояние между кластерами:

Инсайты по кластеризации, география кластеров
После того как мы завершили кластеризацию, решили посмотреть, как получившиеся кластеры расположены относительно друг друга. Возможно, группы кластеров можно объединить в интенты или домены. Для этого мы уменьшили размерность векторов до двух, агрегировали каждый получившейся кластер и отобразили это на карте кластеров.

Получились такие инсайты
На графике видно, что мы получили довольно заметное разделение: скучковались запросы по личному кабинету, интернету дома, смене тарифа и т.д. Так, мы получили авторазметку по определенным интентам с малым усилием. Плюс появились области точек (например, «интернет»), где «не пыльно» можно было разметить доменные интенты.
Метрики классификатора и чат-бота
Чтобы обучить модель классификации, нужно понять, как мы будем замерять качество модели. Решили использовать стандартные метрики: precision, recall, f1 score, accuracy.
На примерах покажем, как мы их использовали и какие из них были более показательны

На первом примере модель отработала хорошо. На всех классах accuracy = 0.65. Рассчитаем macro f1 score (0.72 + 0.28 + 0.66 + 0.66)/4 ~ 0.6, weighted f1 score (0.720.85+0.280.05+0.660.05+0.660.05) ~ 0.69.
На втором модель отработала отлично. Только на одном классе accuracy = 0.85. Рассчитаем macro f1 score (0.92 + 0 + 0 + 0)/4 ~ 0.23, weighted f1 score (0.920.85+00.05+00.05+00.05) ~ 0.78.
Для нас важен каждый класс независимо от количества наблюдений у него в выборке, поэтому мы использовали именно macro f1 score.
Конечно, одними метриками классификатора нельзя оценить эффективность работы чат-бота, поэтому мы ориентируемся на его основные метрики.
TCR (Task completed rate) — процент диалогов, в которых частично или полностью решили проблему абонента. Это ручная разметка выборки диалогов асессорами.
Мы делили диалоги на три типа:
зеленый цвет — бот правильно распознал запрос и дал правильный ответ;
желтый цвет — бот правильно распознал запрос и дал некорректный или неполный ответ;
красный цвет — бот неправильно распознал запрос.
Это информативная метрика, но важно правильно организовать процесс разметки.
CSI (Customer Satisfaction Index) — средняя оценка, которую поставили клиенты боту.
Основные моменты:
— онлайн-метрика – можно замерять уровень удовлетворенности клиента в реальном времени;
— нужно следить за репрезентативностью выборки респондентов. Для этого нужно по-максимуму облегчить доступ клиентов к анкете.
AR (Automation rate) — процент диалогов, в которых клиент не перешел на оператора.
Метрика показывает, насколько эффективно чат-бот удерживает клиента от перехода на оператора. Но некорректно использовать только ее, так как можно попасть в ловушку «хороших» показателей. У нас этот показатель учитывается, но не имеет большого веса в принятии решения.

Бейзлайн на саморазмеченных ngram-мах
После того, как мы определили метрики, возвращаемся к датасету с ngram-ми. Мы уже получили черновую бесплатную разметку путем кластеризации ngram. Для каждого интента собрали примерно по 60 примеров.Теперь, когда у нас есть данные, можно заняться обучением модели.
Начали с простых частотных методов векторизации текста tf-idf. Затем попробовали fast-text. Результат получился значительно хуже. Мы предположили, что это особенность нашего корпуса, состоящего из коротких запросов. После этого попробовали стандартно дообучить Bert model для русского языка.
Мы попробовали разные предобученные модели с ресурса Hugging Face. Лучший результат показала модель DeepPavlov/rubert-base-cased.

Вторая итерация по классификатору: пайплайн, аугментации, инструмент визуализации аттеншн-карт
После экспериментов с обучением модели у нас появился пайплайн, на котором можно достаточно быстро можно обучить любой текстовый классификатор.

Мы использовали в паплайне dvc, чтобы версионировать модели, пайплайны и данные. К тому же с его помощью можно легко воспроизвести любой эксперимент и получить модель ожидаемого качества. Нужно обязательно логировать все эксперименты в mlflow, чтобы было наглядно, какие данные и параметры влияют на качество.
Нами была проделана интересная работа по аугментациям. Более того, мы сделали много (очень много) экспериментов, и решили поделиться основными методами. Не могу сказать, что методы какие-то особенные, но именно они помогли нам решить задачу, поэтому мы рекомендуем начинать с них.
Методы, реализованные с помощью библиотеки nlpaug
Mask insert. Контекстная вставка слова в <MASK> символ.
Random injection. Достаточно консервативный, но результативный способ. Позволяет эмулировать опечатки и прочий шум.
def mask_word(text):
aug = naw.ContextualWordEmbsAug(
model_path="blinoff/roberta-base-russian-v0", aug_p=0.1
)
return re.sub("<unk>", " <unk>", aug.augment(text))Synonymizing. Строится синтаксическое дерево, потом оно усекается и, в зависимости от частей речи, идет синонимизация, например, через most_similar-метод моделей дистрибутивной семантики. Один из минусов — порой теряется связность текста.
def ft_synonimze_word(word):
threshold = 0.6
results = np.array(ft.get_nearest_neighbors(word))
if not len(results):
return word
scores, words = results[:, 0], results[:, 1]
floated_scores = list(map(lambda row: float(row), scores))
indices = np.array(floated_scores) > threshold
if any(indices):
word = random.choice(words[indices])
return word
def ft_synonimze_text(text):
processed_text = []
for tok in text.split():
pos = morph.parse(tok)[0].tag.POS
# NOUN имя существительное хомяк
# ADJF имя прилагательное (полное) хороший
# ADJS имя прилагательное (краткое) хорош
# COMP компаратив лучше, получше, выше
# VERB глагол (личная форма) говорю, говорит, говорил
# INFN глагол (инфинитив) говорить, сказать
# PRTF причастие (полное) прочитавший, прочитанная
# PRTS причастие (краткое) прочитана
# GRND деепричастие прочитав, рассказывая
# NUMR числительное три, пятьдесят
# ADVB наречие круто
# NPRO местоимение-существительное он
# PRED предикатив некогда
if pos in (
"VERB",
"INFN",
"PRTF",
"PRTS",
"GRND",
"ADVB"
# 'NOUN', 'ADJF', 'ADJS', 'COMP',
# 'INFN', 'PRTF', 'PRTS', 'GRND', 'ADVB', 'NPRO'
):
processed_text.append(ft_synonimze_word(tok))
else:
processed_text.append(tok)
return " ".join(processed_text)
Paraphrase. Можно попробовать с инференсом paraphrase-моделей, типа T5(cointegrated/rut5-base-paraphraser). Есть одно но: требуется мониторинг, как с обратным переводом, потому что нельзя терять важные бизнес-токены.
«Хочу подключить тариф Яркий» -> «Нужно включить расценку Светлый»
def paraphraser(text, beams=5, grams=4, do_sample=False):
model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME)
tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME)
x = tokenizer(text, return_tensors="pt", padding=True).to(model.device)
max_size = int(x.input_ids.shape[1] * 1.5 + 10)
out = model.generate(
**x,
encoder_no_repeat_ngram_size=grams,
num_beams=beams,
max_length=max_size,
do_sample=do_sample
)
return tokenizer.decode(out[0], skip_special_tokens=True)
Back translation. Популярный способ аугментации через NMT-модели. Текст переводится на иностранный язык и в обратную сторону. Не самый лучший способ аугментации, если вы боитесь за какие-то ключевые слова. Как пример можно использовать эту функцию:
aug_trans = naw.back_translation.BackTranslationAug(
from_model_name="Helsinki-NLP/opus-mt-ru-en",
to_model_name='Helsinki-NLP/opus-mt-en-ru',
device="cuda")К моменту, когда мы обработали данные и перепробовали аугментации, у нас появилась первая платная разметка. Мы подключили к процессу аннотаторов, то есть, размечали запросы вручную. Также мы смогли обучить модель на «живых» текстах с качественной разметкой: отошли от подхода с n-gram и размечали всё вручную. Результат, конечно, был лучше, чем в первой итерации:

Плюс мы впервые задались вопросом, как интерпретировать предсказания модели. Нам хотелось понять, в какую сторону «копать» дальше, чтобы найти узкие места. Мы решили изучить, как работает механизм внимания модели, какие слова для нее важны и какие слова ее триггерят, поэтому мы написали функцию по визуализации аттеншн карт с конкретных слоев и голов bert.
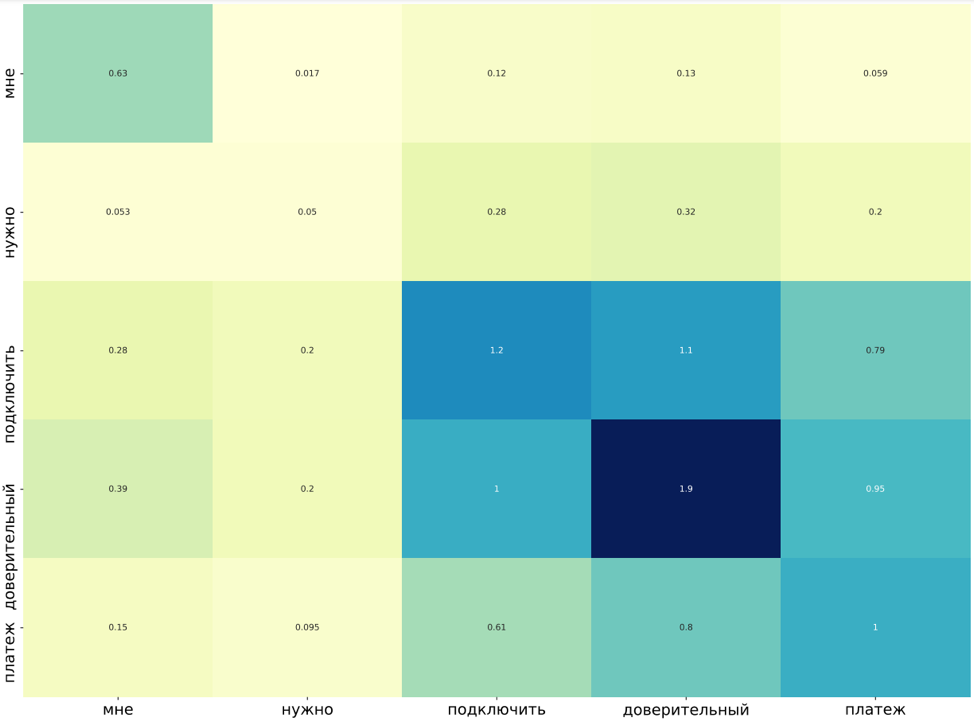
Эта визуализация оказалась очень полезной. Например, из нее мы можем понять, на какие ключевые слова смотрит модель, когда она явно ошибается. Благодаря этому можно точечно очистить обучающий датасет.
Третья итерация: анализ разметки, переразметка, инсайт по полноценным текстам, новые метрики
Модель, обученная на полноценных текстах на естественном языке, оказалась намного умнее, чем модель, обученная на n-gram. То есть, мы увидели проблему: оказалось, что модель, обученная на конкретных интентах, сильно ошибалась, и мы погрузились в анализ имеющийся разметок.
Оказалась, в разметках было много ошибок, которые тянуться еще с первой итерации и со времен разметки от аннотаторов. Поэтому мы решили опять переразметить датасет, с новыми знаниями и определившись с логикой самих интентов.
В дополнение к переразметке мы решили разделить модели: две модели определяют домен и интент запроса, третья модель – определяет наличие какого-либо интента в запросе (обычная бинарная классификация).
В результате переразметки и разделение моделей качество получилось следующее:

Chain-model, sentiment, spam
Так как в нашей задаче пространство всех интетов неопределенное (мы не знаем, сколько их), нужно было отделять имеющийся список интентов в чат-боте и остальную лексику, в которой могут содержаться и остальные интенты. Поэтому мы провели ряд экспериментов, в результате которых оказалось, что модель, обученная на определение наличия какого-либо интента, показывает хорошие метрики и разделяет общую лексику от запросов с интентами. Мы ее включили в общий пайплайн предсказания.
«Спам»-модель была встроена в наш движок для того, чтобы фильтровать неосмысленный текст. Мы даем клиенту попытку ответить на запрос бота, как бы вынуждая его писать запросы, которые наш чат-бот способен обработать.

На финальном пайплайне видно, что за определение интента отвечает бинарная модель. Она говорит, есть ли хоть какой-либо интент, и если он есть, запускается голосование доменной и интеной модели и финальный предикт. Если интента нет — проверяем запрос на спам и решаем, каким должен быть ответ бота.
Что в итоге
Сейчас мы отслеживаем наше влияние на чат-бот косвенными метриками:
— доля в распознавании пула запросов моделью увеличилась до 23 % в последнем месяце («синонимы» — это тоже инструмент распознавания тематики запроса, но на основе ключевых слов)

— процент перевода на оператора уменьшился с 7 % до 5 %;
— определяем в среднем 11 % спама, чем снижаем нагрузку на операторов путем фрода.
У нас есть планы на дальнейшее улучшение чат-бота:
— увеличение количества интетов в модели, что должно в теории увеличить охват запросов;
— увеличение порога распознавания «Синонима» для повышения точности, так как больше запросов будет обрабатываться моделью распознавания интента;
— внедрение классификатора на казахском языке для дальнейшего увеличения общего охвата запросов;
— улучшение качества распознавания путем налаживания процесса разметки запросов и построение автоматического процесса разметки данных с участием аннотаторов и валидаторов;
— упрощение chain model: есть гипотеза, что можно отказаться от бинарной классификации и оставить только две модели без потери качества. Это нам даст ускорение работы сервиса.
Дополнительно хотим провести пилот с внедрением инструментов распознавания и синтеза речи, чтобы позднее строить на базе нашего чат-бота платформу для управления голосовыми и текстовыми диалогами (Conversational platform).

Astroscope
Эффективные менеджеры наоборот наверняка заинтересуются одной только этой метрикой и тогда уже топ-менеджмент может попасть в ловушку идей и концептов от эффективных менеджеров, медленно и незаметно, но настойчиво и целенаправленно разрушающих коммуникации с клиентом. Ведь откуда известно, сколько из тех, кто не перешел на оператора, решили свой вопрос посредством чат-бота (плюс команде разработчиков чат-бота!), а сколько в ярости отключились, обещая себе никогда впредь не иметь дела с той конторой, где не пробиться к живому человеку по вопросу, который не может решить чат-бот? Прошу прощения за комментарий не вполне по сути статьи.