

В первой статье из серии об использовании Apache Cassandra в машинном обучении мы обсудили цели и задачи машинного обучения, и поговорили почему Cassandra — превосходный инструмент для обработки больших наборов данных. Также рассмотрели технологический стек, используемый Uber, Facebook и Netflix. Обе статьи основаны на воркшопе Machine Learning with Apache Cassandra and Apache Spark (Машинное обучение с помощью Apache Cassandra и Apache Spark).
В этой статье мы рассмотрим интеграцию Apache Spark с Cassandra и построение эффективных алгоритмов и решений. Мы также обсудим обучение с учителем, без учителя и метрики машинного обучения. Примеры и упражнения доступны на GitHub.
Cassandra для машинного обучения
У Cassandra есть ряд возможностей, особенно полезных для приложений машинного обучения:
Отличная масштабируемость. Для обработки петабайт данных вам потребуется масштабируемая база данных.
Работа в облаках (cloud-native) и отсутствие мастер-сервера (masterless). Облака имеют важное значение для глобальных компаний таких как Uber, Apple и Netflix с пользователями по всему миру. Cassandra изначально спроектирована для создания единого кластера из географически распределенных узлов, что позволяет читать и записывать данные в любом месте.
Исключительная отказоустойчивость. Данные не только распределены по кластеру, но и реплицированы. Благодаря автоматической репликации по нескольким узлам (обычно по трем) база данных всегда будет доступна, даже если вам нужно заменить узлы.
Децентрализованное распределение данных. Чтобы машинное обучение работало правильно, необходимо продолжать наполнять данными базу, что влечет за собой использование децентрализованной и отказоустойчивой базы данных, такой как Cassandra.
Производительность для обеспечения точности данных. Cassandra предлагает высокодоступную и высокопроизводительную базу данных с masterless архитектурой, способную поддерживать высокоскоростные алгоритмы машинного обучения с отсутствием единой точки отказа.
Однако в использовании Cassandra как единой универсальной базы данных есть некоторые недостатки. Из-за децентрализованной распределенной модели данных некоторые типы запросов выполняются не очень эффективно, особенно операции агрегирования, анализа данных и т.п. Но здесь поможет Apache Spark.
В нашем туториале мы показываем, как использование Spark с Cassandra помогает решить эти проблемы. DataStax предлагает корпоративное решение с интегрированными Cassandra и Spark. Хотя фактически внутри используются библиотеки с открытым исходным кодом. В этой статье мы сделаем обзор их совместной работы.
Как Cassandra работает с Apache Spark
Cassandra отвечает за хранение и распространение данных, Spark — за вычисления. Cassandra и Spark очень хорошо дополняют друг друга при обработке больших данных, поскольку Cassandra хорошо справляется с хранением и получением неограниченного объема данных, а Spark — с обработкой сложных запросов и аналитикой. Итак, Cassandra хранит данные, а рабочие узлы Spark (worker) выполняют обработку данных.
Давайте немного поговорим об аналитике данных. Аналитика данных — это наука об анализе сырых данных с целью получения из них информации, в том числе для поддержки принятия решений. Аналитика данных может решать такие задачи как:
Выдача рекомендаций
Обнаружение фрода (мошенничества)
Анализ социальных сетей и веб-ссылок
Решения в сфере маркетинга и рекламы
Профиль клиента 360
Аналитика продаж и фондового рынка
Анализ данных IoT
Spark — это движок распределенных вычислений, предназначенный для анализа больших объемов данных с обработкой в оперативной памяти. Spark доступен на Python, SQL, Scala, Java и R с возможностью работы как на отдельных узлах, так и на кластерах. С помощью Spark можно выполнять интерактивный или пакетный анализ данных до 100 раз быстрее и с меньшим количеством кода, чем при использовании Apache Hadoop — другой платформы распределенной обработки больших наборов данных.
Наше решение DataStax Enterprise (DSE) включает в себя интеграцию Spark и Cassandra с унифицированной базой данных, поиском и аналитикой. Решение не привязано к какому-либо облачному провайдеру и полностью переносимо. DataStax Enterprise также можно развернуть в локальном, гибридном или мультиоблачном окружении.
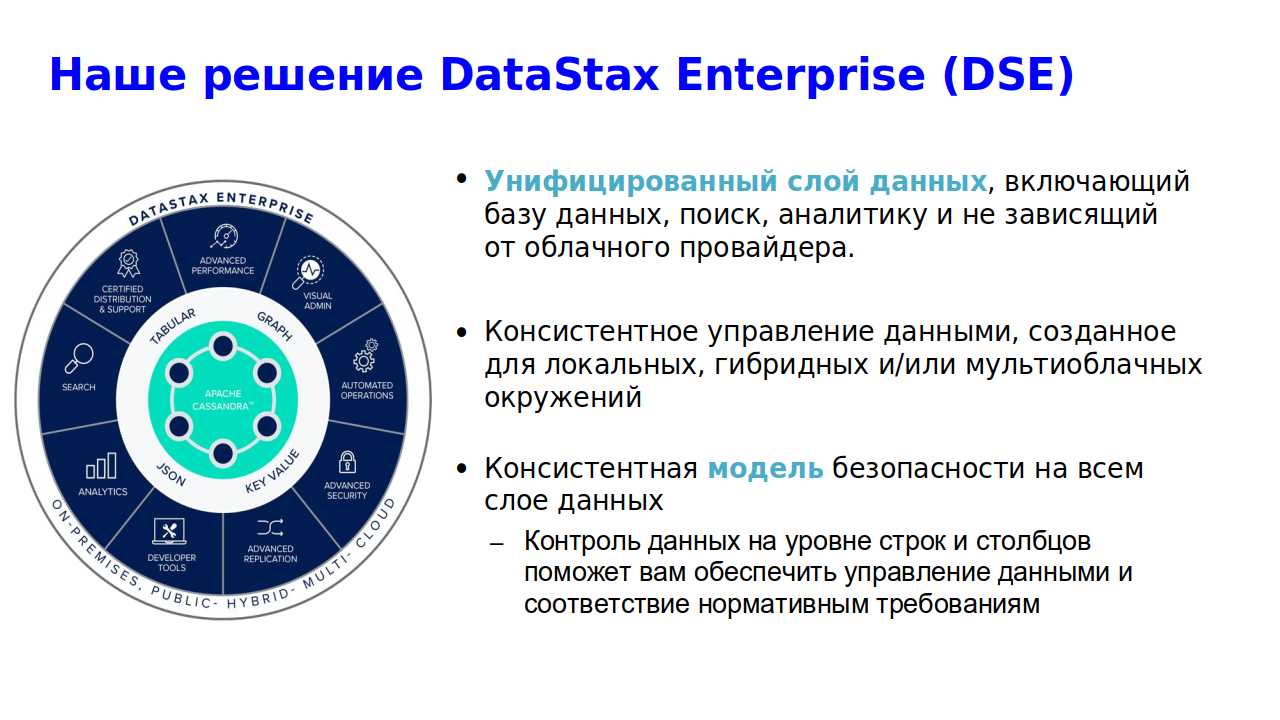
Рисунок 1. Возможности DataStax Enterprise (DSE).
Spark отлично подходит для анализа данных в DSE, поскольку распределяет нагрузку между узлами. А как система пакетной обработки (batch-processing system) Spark отлично справляется с большими объемами данных.
При получении задания (job) Spark worker загружает данные в память, используя при необходимости диск. Важный момент — отсутствие сетевого трафика. Spark worker понимает, как распределены данные в Cassandra и читает данные только с локального узла. О том, как включить Spark в DSE, смотрите в нашем туториале на YouTube.
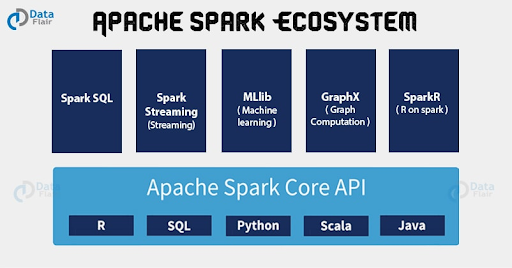
Рисунок 2. Экосистема Apache Spark.
Помимо простой интеграции с Cassandra, экосистема Apache Spark включает в себя следующие инструменты для машинного обучения:
Apache SparkR. Это фронтенд языка программирования R для создания аналитических приложений. SparkR интегрирован с DSE для поддержки создания фреймов данных (dataframe) из данных DSE. Также включает в себя инструменты визуализации данных и несколько пакетов со статистическими функциями и функциями машинного обучения.
GraphX. GraphX — это новый компонент в Spark, используемый для обработки графов. Он обеспечивает выполнение массово-параллельных алгоритмов и алгоритмов машинного обучения.
Machine Learning Library (MLlib). MLliB — это библиотека машинного обучения, построенная на основе Spark, с базовыми алгоритмами обучения и утилитами. Мы использовуем MLlib в практических упражнениях.
Spark Streaming. Позволяет получать потоки данных в реальном времени из разных источников, таких как Kafka, Akka и Twitter, с последующим анализом в Spark и сохранением в базе данных. Далее данные могут обрабатываться более сложными алгоритмами. Обработанные данные сохраняются в файловой системе, базе данных или отображаются на интерактивных дашбордах.
SparkSQL. С помощью SparkSQL можно выполнять реляционные запросы к данным, хранящимся в кластерах DSE, используя язык, похожий на SQL. Высокоуровневый API весьма лаконичный и позволяет выполнять структурированные запросы к распределенным данным. SparkSQL также позволяет выполнять реляционные SQL-запросы к Cassandra, в которой изначально отсутствует поддержка внешних ключей и связей.
Обучение с учителем и без учителя
Существует несколько видов машинного обучения. Давайте поговорим о двух часто используемых: с учителем и без учителя.
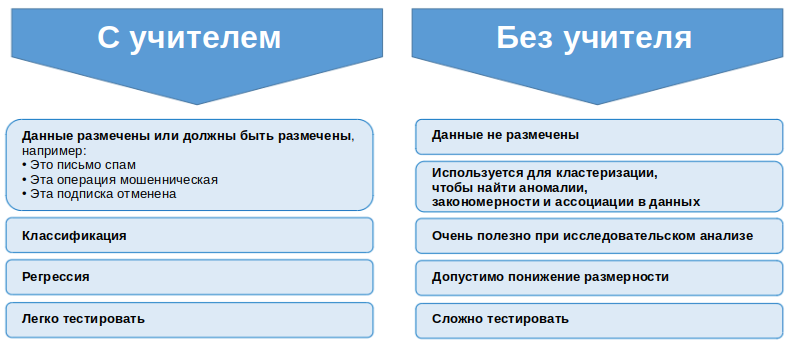
Рисунок 3. Обучение с учителем и без учителя
Примером обучения с учителем может быть детектор спама: обучение обнаружения спам-сообщений на основе существующей базы электронных писем. В дополнение к поиску по подозрительным словам, электронные письма могут помечаться пользователем как спам или не спам.
Когда электронное письмо было отправлено 100 000 раз и 100 раз помечено как спам, обучение с учителем помечает его как спам. Затем предсказывается, будет ли следующее письмо спамом.
Обучение с учителем означает разметку данных. Подобно выявлению мошеннических банковских транзакций машинное обучение должно просеивать огромную коллекцию различных операций и маршрутов для разметки и получения точных прогнозов.
Другие задачи обучения с учителем включают в себя классификацию и регрессию. Чтобы изучить эти алгоритмы, ознакомьтесь с нашим туториалом на YouTube или Jupyter-ноутбуками на GitHub.
Пара слов о метриках машинного обучения
Метрики также имеют важное значение для принятия решения об эффективности ваших моделей машинного обучения. В конце концов, вы не можете контролировать то, что не можете измерить. Некоторые из важных метрик машинного обучения:
Accuracy (правильность)
Precision (точность) vs Recall (полнота)
Accuracy
Accuracy — это метрика для оценки того, сколько прогнозов было сделано правильно. Это количество правильных прогнозов, деленное на общее количество прогнозов. Давайте посмотрим на реальный пример пациентов с опухолями.

Рисунок 4. Пример диагностики опухоли с использованием алгоритмов.
На рисунке 4 мы видим, что из 100 больных у девяти злокачественная опухоль, а у 91-го — доброкачественная. Важно вовремя выявлять злокачественные опухоли, потому что, если этого не сделать, люди могут умереть. Мы выделяем четыре категории в зависимости от типа результатов: ложноположительные (false positive), ложноотрицательные (false negative), истинно положительные (true positive) и истинно отрицательные (true negative) (рис. 4). Для расчета accuracy этой модели мы можем использовать следующее уравнение (по шкале от 0 до 1, где 1 соответствует максимальной точности):
TP (истинно положительный) + TN (истинно отрицательный) = 0,01 + 0,9 = 0,91
Результат близок к единице. Мы можем быть уверены, что наша модель достаточно точна? Не совсем.
На рисунке 4 вы можете увидеть восемь человек, у которых мы ошибочно идентифицировали доброкачественные опухоли, хотя на самом деле у них были злокачественные. Мы отправляем домой восемь человек с очень тяжелыми опухолями без какого-либо лечения. Давайте поговорим о метрике precision и почему она важна для нашего примера с опухолью.
Precision (точность) vs recall (полнота)
Precision (точность), также известная как прогностическая значимость положительных результатов, учитывает только истинные положительные результаты из всех истинных и ложных положительных результатов. В нашем примере precision составляет всего 0,5 (рис. 5), потому что не идентифицирован один истинно положительный результат из двух положительных. Мы в буквальном смысле можем получить лучшие результаты, бросая монету с вероятностью 50/50 вместо использования алгоритма.
Чувствительность (sensitivity), также известная как полнота (recall), представляет собой отношение количества истинно положительных результатов к общему количеству действительно положительных результатов. В нашем примере с опухолью recall равен 0,11 (рис. 5). По этим показателям можно сказать, что модель не так уж и хороша. Но нужно понимать, что в data science существуют серьезные ограничения в отношении метрик, которые противоречат друг другу.
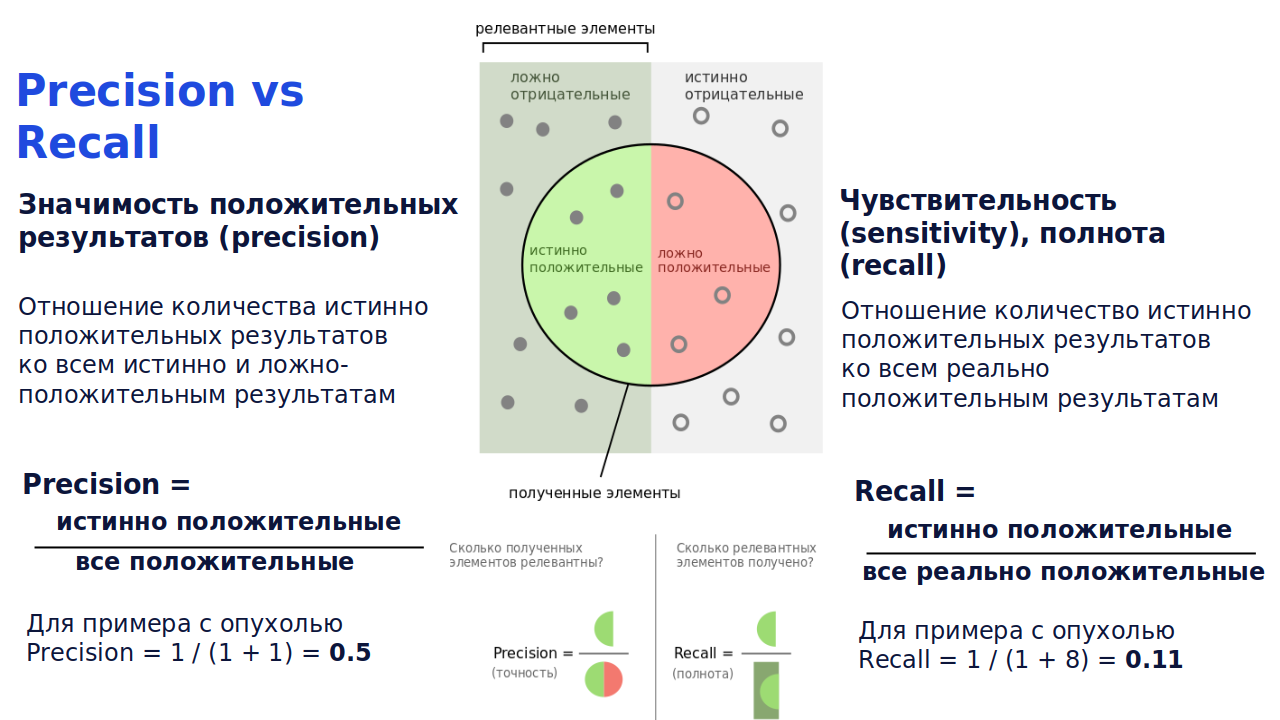
Рисунок 5. Машинное обучение — precision vs recall.
Выводы
В этой статье мы продолжили рассмотрение использования Cassandra для машинного обучения, и хотели показать вам, что Cassandra идеально подходит для машинного обучения, а также обратить ваше внимание на наш видео туториал, где вы можете изучить практический пример, иллюстрирующий концепции, которые мы представили в этих статьях. Примеры вы можете найти на GitHub.
Дополнительные материалы вы можете найти на нашем YouTube-канале DataStax Developers, а также подписаться на рассылку о предстоящих воркшопах для разработчиков. Кроме того, подпишитесь на блог DataStax на Medium для получения эксклюзивных постов обо всем, что связано с данными: Cassandra, стриминг, Kubernetes и многое другое!
Ресурсы
Real World Machine Learning with Apache Cassandra and Apache Spark (Part 1)
YouTube Tutorial: Machine Learning with Apache Cassandra and Apache Spark
GitHub Tutorial: Machine Learning with Apache Spark & Cassandra
Перевод статьи подготовлен в преддверии старта курса NoSQL. Также хочу пригласить всех желающих на бесплатный демоурок по теме: "Профилирование и оптимизация индексов в Elasticsearch".