
У нас есть задача постоянно компилировать тонны плюсового кода. Наш проект — почти 200 000 cpp- и h-файлов, множество Git-веток, сотни разработчиков, десятки билд-агентов: его нельзя единожды скомпилировать, приходится перекомпилировать постоянно, параллельно, разные версии.
Наш проект необычный. Потому что эти 200 000 файлов — это результат автогенерации. Потому что пишем мы на PHP, а потом через KPHP все PHP-исходники превращаются в плюсы. Именно так разрабатывается бэкенд ВКонтакте.
Компилировать тысячи объектников долго. Локально это занимает много часов. Мы использовали distcc — но всё равно медленно. Мы даже пропатчили distcc для поддержки precompiled headers — но даже тогда медленно. И решили написать своё — чтоб стало, наконец, быстро.
В итоге мы написали замену distcc — компилятор nocc. Он не имеет никакого отношения к PHP и даже к KPHP, а просто предназначен для компиляции .cpp → .o в промышленных масштабах.
Это техническая статья про параллелизацию, демоны и специфику С++. Ссылки на GitHub и видео приложу в конце статьи.
Как вообще можно ускорить компиляцию С++
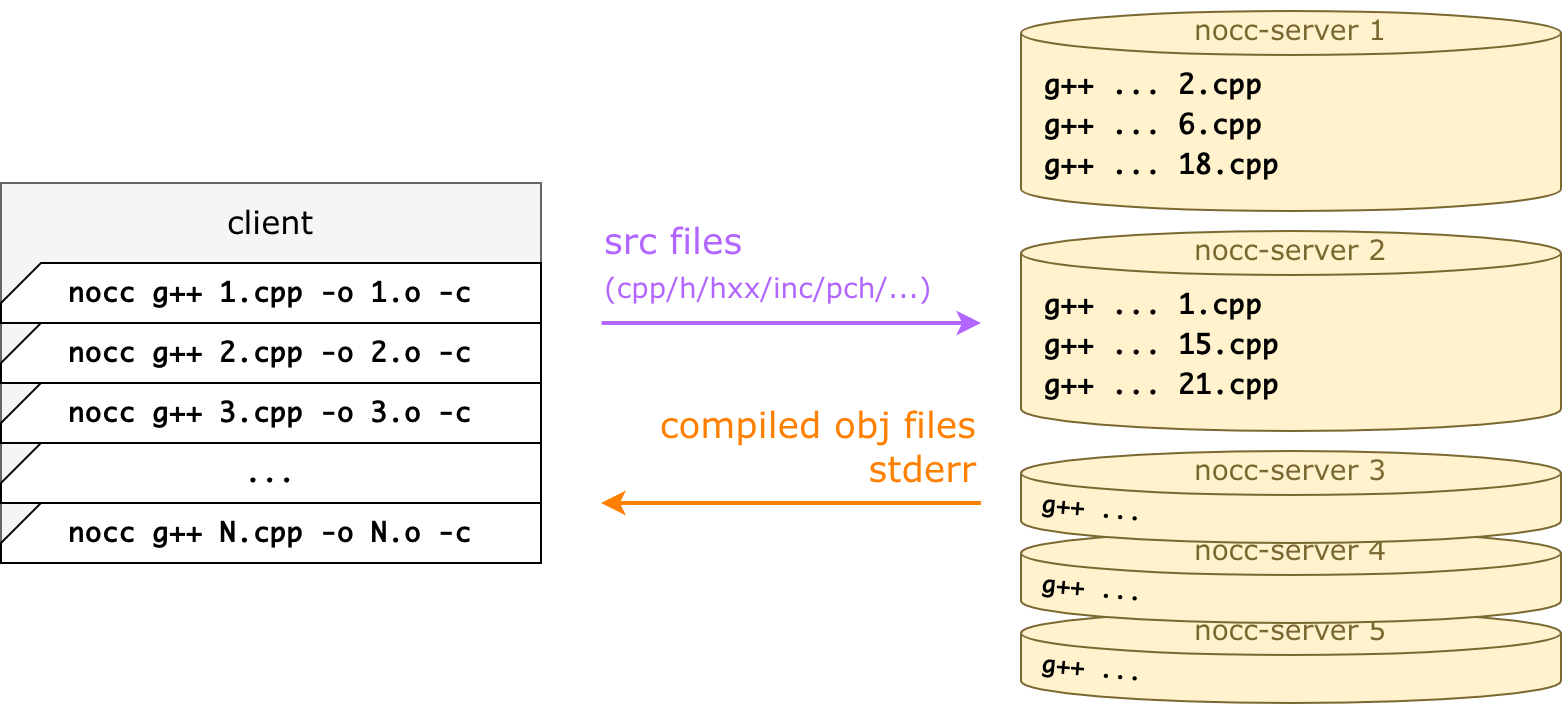
Основная идея у nocc и у distcc одинаковая: компиляция происходит не локально, а удалённо. То есть отдельно стоят серверы (компиляционные ноды, nocc-server), а клиент проксирует вызов g++/clang туда. Для этого клиенту вместо g++ 1.cpp ... достаточно вызвать nocc g++ 1.cpp ... — и файл будет скомпилирован не локально, а удалённо.
Скорость обеспечивается за счёт того, что серверов много (у нас 32 в бою, например). Получается, если локально можно было запускать, к примеру, make -j40, то теперь можно make -j400, и nocc-клиент равномерно размажет это по серверам.
То есть nocc — это такая тонкая прослойка, которая умеет загружать файлы и проксировать командную строку. А ещё это очень умный кеш, чтобы не загружать один и тот же файл заново. И даже не компилировать повторно.
Запуск nocc прозрачен для клиента
С точки зрения вызова, билд-система должна уметь всего лишь одну простую штуку: подставлять произвольную строчку перед плюсовым компилятором, чтобы получилось nocc g++ ....
Это можно сделать и в make, и в CMake, и в Ninja. Например, для CMake это выглядит так:
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/path/to/nocc ..И всё, nocc-клиент будет отсылать .cpp на серваки.
Если командная строка невалидна или её нельзя выполнить удалённо, nocc просто исполняет её локально, и всё. Например, форсирует локальное исполнение без изменения опций. Например, линковка происходит локально. Или -march=native происходит локально. Если сервак недоступен, то опять-таки фоллбечимся. Поэтому вызов nocc безопасен всегда.
Клиентский nocc-процесс завершается с тем же exitCode / stdout / stderr, что и удалённый g++, поэтому вывод консоли останется без изменений.
Что происходит при `nocc g++ 1.cpp`
Пусть есть 1.cpp:
#include "1.h"
int square(int a) {
return a * a;
}И простой 1.h:
int square(int a);Вот что происходит при запуске nocc g++ 1.cpp -o 1.o -c:
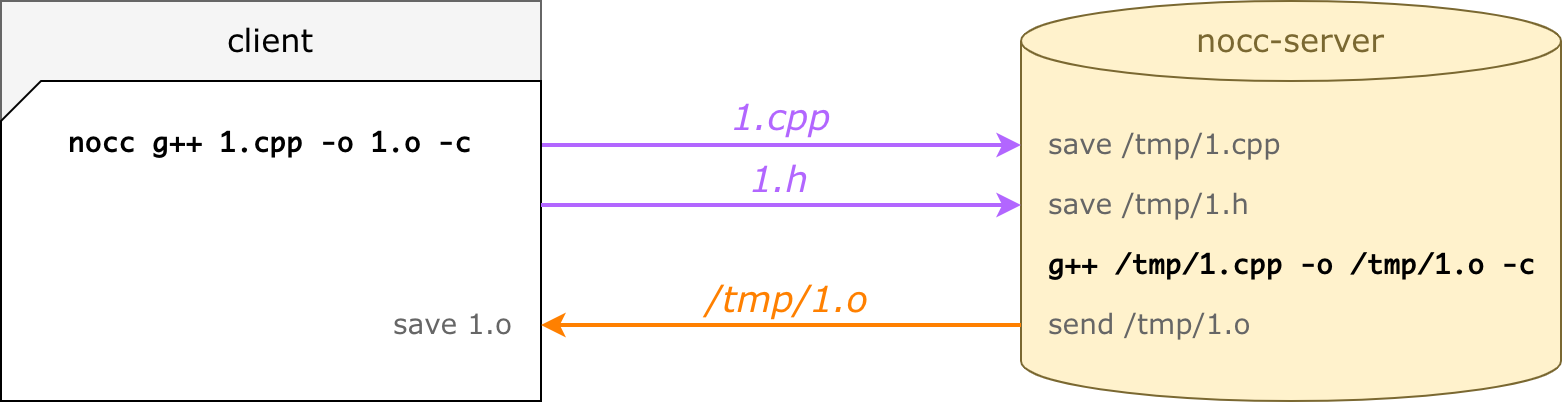
nocc парсит командную строку: входной файл, пути к инклудам, cxx-флаги и пр.;
для входного файла (1.cpp) nocc находит все зависимости, сканируя все
#includeрекурсивно (в примере это просто файл 1.h);nocc загружает файлы на выбранный сервер и ждёт;
nocc-server выполняет ту же командную строку (те же cxx-флаги, только пути подменены);
nocc-server пушит 1.o обратно;
nocc сохраняет 1.o — будто бы сделанный локально.
В реальности мы ставим много серверов для компиляции
На клиентской стороне запускается куча nocc-процессов одновременно. Каждый запуск — один .cpp → .o вызов, прозрачно для билд-системы. Он компилирует файл удалённо и умирает, ведь nocc это просто тонкая прослойка к ремоуту.
Для каждого cpp выбирается удалённый сервер, вычисляются все зависимости, недостающие загружаются, и сервер отправляет обратно готовый объектник. Это происходит параллельно для всех клиентов.
Для большей производительности все коннекты на самом деле держит один nocc-daemon:
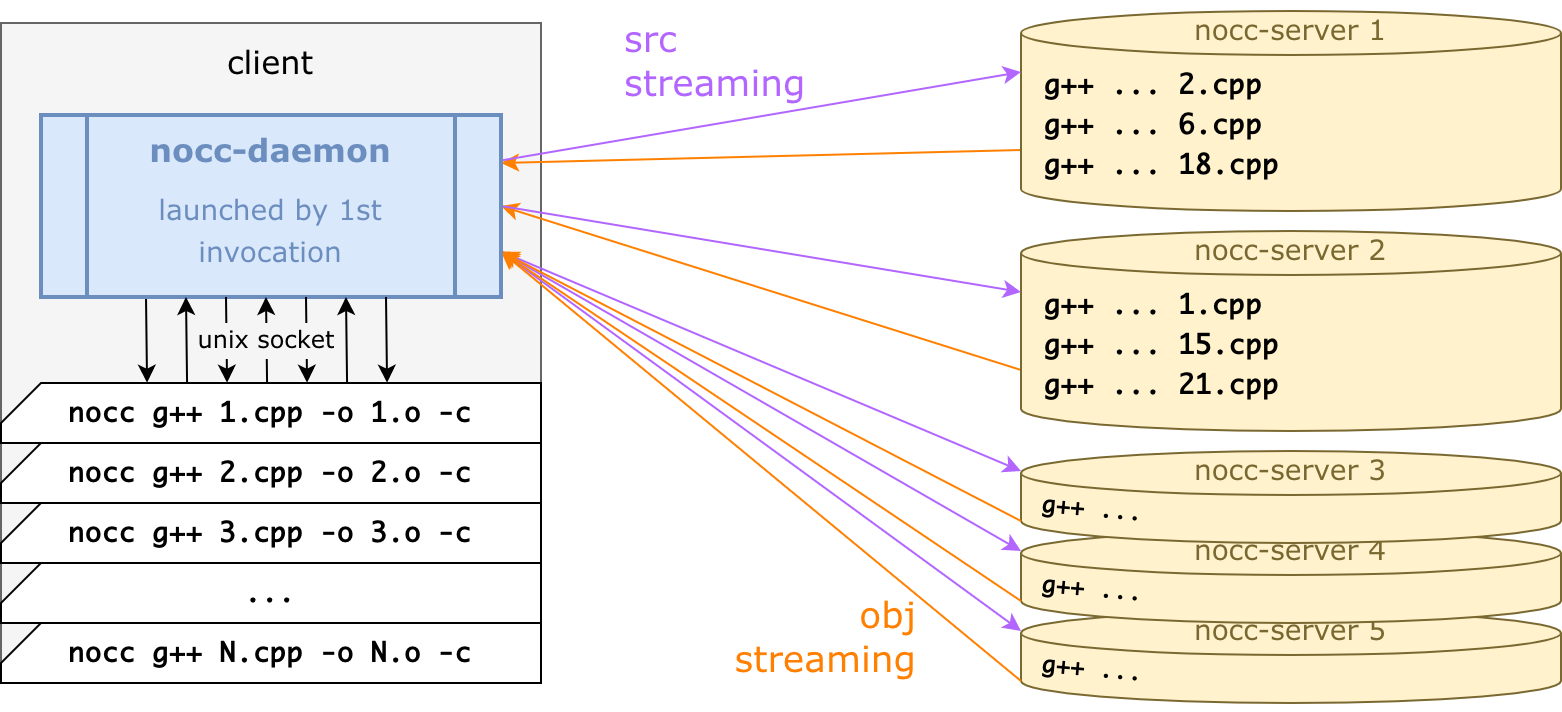
nocc-демон написан на Go — а nocc очень лёгкая обёртка C++ с единственной целью: передать командную строку в демон, дождаться ответа и умереть.
Получается, итоговая схема работы такая:
Самый первый запуск nocc стартует nocc-демон в фоне: демон коннектится по gRPC к сервакам и в целом делает всю работу.
Каждый nocc-вызов отправляет
g++ ...в демон через Unix-сокет, демон ждёт объектник, сохраняет его, и nocc-процесс умирает.nocc-процессы стартуют и умирают: билд-система сама запускает их, не задумываясь об этом.
nocc-демон умирает через 15 секунд (эвристическая оценка того, что процесс компиляции завершился).
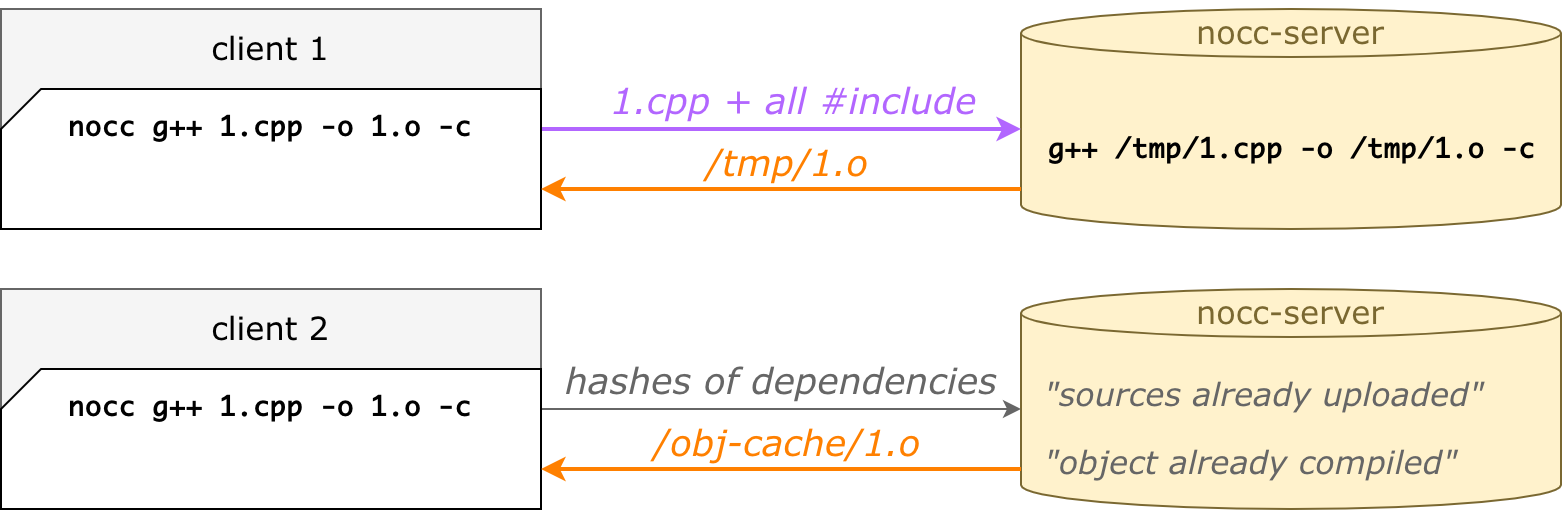
nocc — это очень умный распределённый кеш
Главная фишка на практике заключается в том, что второй, третий и последующие запуски быстрее, чем первый. Даже если почистить папку build, даже на другой машине, даже в другой папке.
Это всё благодаря удалённым кешам:
кеш исходников — nocc не загружает файл, если он уже был загружен;
кеш объектников — nocc не компилирует файл, если он уже был скомпилирован.
Такой подход значительно уменьшает времена сборок на различных билд-агентах, даже если локальные кеши дропнуты или билд-агент новый.
Более того, это прекрасно ложится на Git-разработку. Кто-то сбилдил свою ветку, а потом вмержился в мастер — а на сервере есть уже готовые объектники. И неважно, что у нас PHP, а С++ получается на выходе — это всё равно работает.
Кеш исходников работает на хешах от файлов. Когда nocc ищет #include рекурсивно, для всех файлов он считает SHA256. Изначально он отправляет серваку список хешей — а сервак отвечает, какие отсутствуют. Чаще всего при повторных компиляциях уже всё есть, и аплоадить ничего не нужно. Файлы вытесняются по LRU и не превышают заданный объём на диске.
Кеш объектников устроен похожим образом. Мы комбинируем хеши всех зависимостей, а также все cxx-опции — тоже получаем SHA256, которым индексируем объектник. Так что при повторной компиляции тех же исходников с теми же опциями объектник будет уже готов. Легко понять, что одному cpp-файлу могут соответствовать несколько объектников. Например, с дебаг-символами и без них — это разные опции командной строки, приводят к разным хешам, и оба объектника хранятся в объектном кеше, они оба готовы. Это не какой-то исключительный случай, так само получается, и получается хорошо.
Некоторые сведения из архитектуры и реализации nocc
Как nocc выбирает сервер для компиляции
Очень просто на самом деле: (хеш от имени файла) % N. Безо всякой там балансировки по нагрузке и так далее — просто хеш от basename, даже без папки.
Логика простая: на разных CI-машинах билд проекта идёт в разных tmp-папках, а мы хотим, чтобы одни и те же cpp (и их инклуды, что важно) попадали всегда на одни и те же ноды.
Даже если сам cpp изменился, вероятнее всего, большинство инклудов осталось прежними, зачем их лить заново. Даже если сервак недоступен, не нужно отправлять на другой, а лучше исполнить локально: сервак быстро поднимут, а мусор на других серваках не нужен.
Как происходит удалённая компиляция
Каждый демон имеет уникальный clientID, и все файлы, которые он заливает (cpp, h, inc, gch) складываются в отдельную папку (working dir), фактически зеркалируя файловую структуру клиента. Всё что нужно — это при запуске g++ подменить пути:

Когда файлы зависят от системных хедеров (типа <iostream>), они тоже проверяются, но загружаются только при различиях. Одинаковые системные файлы можно не загружать, #include <iostream> на сервере отработает так же.
Напомню, что на серваке есть кеш исходников. Те зависимости, которые уже загружались, берутся из кеша: просто делается хардлинка в тот же working dir. Это равносильно тому, что файл загружен, так что g++ его прекрасно увидит по нужному пути.
Кастомная парсилка
#include
Для каждого cpp нужно собрать рекурсивное дерево зависимостей.
Можно было бы сделать это через флаг g++ -M: он запускает только препроцессор (не компиляцию), а выдаёт список зависимостей (а не результат препроцессора).
Но в nocc встроен собственный парсер инклудов, который делает то же самое, только в разы быстрее. Он сам парсит cpp- и h-файлы, находит #include, резолвит их и продолжает рекурсивно. Он учитывает -I / -iquote / -isystem из командной строки, знает про системные пути и даже про #include_next. Быстрее это потому, что работает в демоне, и мы там можем всё кешировать: инклуды из разных cpp часто пересекаются, а при билде часто используются одни и те же пути в опциях. Получается, не нужно на каждый cpp вызывать препроцессор, и это ощутимо экономит время.
Конечно, в отличие от g++ -M, nocc ничего не делает с #ifndef и прочими. Поэтому он находит больше инклудов, чем нужно, и какие-то даже могут не существовать. Но это нормально, потому что потом при удалённой компиляции они будут просто недостижимы, и удалённый g++ невозмутимо отработает.
И кстати, параллельно с поиском инклудов считаются и хеши всех зависимостей, ведь контент файла мы уже загрузили.
Кастомная парсилка инклудов работает, только когда они могут быть статически зарезолвлены. Всякие там #include MACRO() не раскроешь, тут нужен честный препроцессор на клиентской стороне. Какой-нибудь boost активно это использует, поэтому с проектами на boost'е печаль. Есть опция, чтобы отключить кастомную парсилку. Отключение, конечно, замедляет, но в итоге всё равно получается выиграть у distcc по скорости.
Precompiled headers
nocc их поддерживает, причём по-хитрому. Когда клиентский код хочет сделать pch:
nocc g++ -x c++-header -o all-headers.h.gch all-headers.h… то nocc это перехватывает и делает all-headers.h.nocc-pch вместо .gch/.pch на клиенте — и потом компилирует на сервере в реальный .gch/.pch.

Две главных причины для такого:
Если делать gch локально, его всё равно нужно залить на все серваки. Но gch-файлы большие, и одновременный аплоад на N серверов упарывает сеть.
Если .gch-файлы (g++) могут работать после заливки, то .pch (clang) — уже нет. Clang не будет использовать файл, скомпилированный на другой машине, и хитрые опции типа
--relocatable-pchтут не помогут.
Файлик .nocc-pch — это просто текст с содержимым всех зависимостей. Клиентский nocc его делает быстро — значительно быстрее, чем клиентский g++ делает gch.
Когда работает кастомная парсилка инклудов, то, видя #include "all-headers.h", она находит all-headers.h.nocc-pch и загружает его как обычную зависимость. После загрузки сервер делает настоящий precompiled header и сохраняет all-headers.h и all-headers.h.gch до рестарта. А потом при использовании также делаются хардлинки в нужные места в working dir разных клиентов.
На клиенте gch не делается: если всё хорошо, он не нужен. Если же сеть недоступна и nocc пойдёт локально, компиляция отработает и без gch, ничего не сломается.
Что это дало и стоило ли всё это придумывать?
Да, стоило. Экономим много. VKCOM — гигантский монолит, и каждый разработчик постоянно хочет пересобирать свою версию.
Я говорил, что мы раньше использовали distcc. Он работает совсем по-другому, вообще не похоже на nocc, но это тоже удалённая компиляция. Разработчики distcc пишут, что есть pump mode, который делает немножко похоже, но нам не удалось заставить его работать. Возможно, на синтетических тестах он работает, а на реальных объёмах нет. Именно поэтому ещё три года назад мы пропатчили distcc, сделав ему поддержку pch-заголовков.
Поэтому будем сравнивать: оригинальный distcc, наш патченный distcc, первый nocc-запуск и последующие запуски nocc (в чистой клиентской папке).
Оригинальный distcc |
10077,2 с. |
Патченный distcc + pch |
660,9 с. |
nocc, 1-й запуск |
398,2 с. |
nocc, 2-й, 3-й и другие запуски |
72,6 с. |
Практически все наши кейсы соответствуют последней строчке, так как серваки запущены всегда, и чаще всего нам нужно докомпилировать небольшие изменения. То есть в большинстве случае имеем ускорение относительно оригинального distcc почти в 150 раз! И даже в менее экстремальном случае экономим минимум половину времени.
А ещё — то, что уже говорили:
скорость не зависит от build-агента;
быстрая пересборка при переключении веток;
быстрая пересборка мастера после мержа.
Обращу внимание, что это замеры лишь компиляции кучи .cpp → .o. Линковка сюда не входит. Так же, как и не входит другая локальная работа, которую nocc не ускоряет.
Скорее всего, в вашем случае профит будет не такой большой, но всё-таки будет. Например, если скомпилировать из исходников clang-компилятор через CMake, получаем ускорение только в 1,5 раза относительно distcc на полном цикле. Почему так мало? Потому что процесс выглядит как «быстрая компиляция, долгая линковка, быстрая компиляция, долгая линковка». Если вычесть время линковки, то ускорение будет, как и ожидается, очень приличным. Но там линковка занимает почти всё время. У KPHP-сборки просто более высокая степень параллелизма, без промежуточных этапов, так уж мы устроены.
Выводы
Да какие особо выводы? Хорошая, рабочая штука. Быстрая, потому что демон, потому что #include ищем без препроцессора. По факту, это очень умный remote cache с уклоном в С++. Нам экономит очень много вычислительных ресурсов и времени на сборку. Webpack собирает js-ки в 10 раз дольше, чем KPHP + nocc — миллионы строк кода.
Если вы используете distcc, попробуйте nocc. Вероятно, заработает, если нет макросов внутри инклудов. Кто хочет, почитайте обо всём на GitHub. И звёздочку поставьте :)
Кстати, на прошлом HighLoad++ я выступал с докладом, где рассказывал про всё это. Посмотреть его можно по ссылке ниже.
Полезные ресурсы
Комментарии (57)

Mishootk
25.10.2022 12:39Огромное количество файлов очень хорошо оптимизируется технологией, которая у нас проходит под псевдонимом UnityPack. Рассматривали? Это представление всех cpp файлов как одного единого файла. В идеале на выходе компилятора для линковки получается один объектник. Мы в результате добились примерно той же скорости сборки проекта, но избавились от терминов "разогретая" и "холодная" сборка (есть полный кэш или все новое).

thevlad
25.10.2022 14:13+2Эм, ну убить инкрементальную сборку, так себе вариант. И подозреваю, что проблема ни только в количестве файлов, но и количестве строк кода.
Mishootk
25.10.2022 16:21+1Замеры покажут, что дешевле, инкрементальная сборка или объединенный исходник. Мы на некоторых модулях были очень удивлены результатам. Пробовали распределенную компиляцию, разные кэширования, объединение исходников. Это все не серебрянные пули. Можно тонко настроить комбинацию всех этих способов.
thevlad
25.10.2022 16:30+1Для типичного кейса разработчика(один раз собрал, исправил или подтянул изменения из гита), инкрементальная сборка почти всегда будет быстрой. У меня был проект, который собирался полностью за 2 часа на 12 ядернике и M.2 SSD, и инкрементально за пару минут, но там был ninja.

0xd34df00d
27.10.2022 17:34+2Можно ваши 100500 cpp-файлов склеивать не в один большой, а в N << 100500. Тогда и профит от склейки все еще будет, и пересобирать совсем все при изменении одного файла не надо.
Кстати, ЕМНИП cmake так умеет.

equeim
25.10.2022 18:57Как это работает с конфликтами анонимных неймспейсов и static функций/переменных?

Izaron
25.10.2022 20:03+2Плохо работает - все файлы просто один за другим "склеиваются" в один большой файл, поэтому локальные имена конфликтуют.
Если через некоторое время отказаться от данного подхода, то придется руками написать овер9000 новых include, которые раньше не писали, потому что их подключал какой-нибудь другой файл, который в "склейке" идет раньше.
Mishootk
26.10.2022 14:31Плохо. Проект должен быть подготовлен для такой технологии. Если проект с нуля, то это просто гигиена. Если перевод, то некоторая работа плюс дальшейшая гигиена. От проблем отказа от данной технологии защищают инструменты непрерывной интеграции (сервер сборки без объединения и с объединением - ловятся единичные случаи нарушений).
Сборщик суперфайла можно настроить на игнорирование некоторых файлов по желаемым признакам (ручным или автоматическим) - на скорость сборки до определенного количества это сильно не повлияет, но облегчит этап преодоления внезапных несовместимостей.
Например для многопоточной сборки мы применяли сборку в несколько суперфайлов. Имеющийся у нас компилятор может собирать один объектник на одном ядре, поэтому выгоднее потерять немного на линковке и сборке нескольких суперфайлов, но выиграть на распараллеливании.



apro
25.10.2022 14:18+2А кэширование отрабатывает код типа:
#define OPTION_USED_IN_HEADER #include "header.h"?
В этом случае хэш "header.h" должен отличаться от хэша "header.h" без использования объявления (define) OPTION_USED_IN_HEADER




niklyaev
25.10.2022 14:43+6Рассматривали ли bazel и его удаленное исполнение? Если да, то чем он не подошёл?

unserialize Автор
26.10.2022 03:23+1Я могу быть неправ, но по-моему здесь немного другое. Bazel, вероятно, хорош для статичных проектов, но не для автогена.
Bazel это всё-таки система сборки, ВМЕСТО Cmake/make. В нашем случае, когда 200к файлов это автоген, то чтобы заюзать Bazel, помимо собственно cpp-шных исходников, пришлось бы генерить Bazel-проект (конфиг?), содержащий ссылки на эти все файлы или glob-выборки. И потом запускать Bazel для сборки бинарника.
Следовательно, Bazel стал бы анализировать автоген как отдельный плюсовый проект. Стал бы чекать, что изменилось, а что нет — для запуска инкрементальной компиляции. И если на перекомпиляции с нуля в чистой папке это допустимо, то в случае инкрементальной компиляции — уже долго.
В случае KPHP, поскольку он сам и так знает, что там за дифф (он же его генерит и записывает), он просто запускает CXX (g++ или nocc g++) для нужных cpp.
niklyaev
26.10.2022 11:25+1Если отображние PHP-файлов на плюсовые файлы фиксированное (одинаковое для всех PHP файлов), то можно написать макрос, включающий и правило генерации из PHP, и правила компиляции уже генеренного кода. Как бонус получаем ещё кеширование генерации и распараллеливание её на удаленных хостах.
Если же отображение зависит от исходного кода, то так не получится. Посмотрел немного доки KPHP - похоже, что набор генерируемых файлов зависит от набора функций и классов в исходном коде. Так что в текущем виде bazel и правда не подходит.

sbase
26.10.2022 21:44Эта зверюга, KPHP, генерит файлы по каждой функции. И хотя имя каждого файла уникальное, но оно зависит от сигнатуры методов. Иногда поменяешь в одном месте а в сборку уходит 8000 целей. Потому что класс наследуется....
Мы тут миграцию на KPHP сделали, теперь приходится работать в режиме "это почти С++" %)) Хотя быстрая проверка алгоритмов в режиме PHP тоже доступна. Во вторник статью выпущу про нашу миграцию.

event1
25.10.2022 16:06+3Если всё время компилируется всего несколько файлов, а связывание всё-равно происходит локально, то не проще сделать общий ccache? Только научить его различать файлы по хэшам.
Сами хэши, кстати, можно из git брать. Чтоб не пересчитывать постоянно

wataru
25.10.2022 19:08Интересно бы сравнить с гугловым gomacc.
Он тоже распределенный и с кешированием.unserialize Автор
26.10.2022 02:55+2О, не слышал про такой инструмент. Выглядит как что-то похожее, и правда.
Есть сомнения, что он сможет выиграть по скорости в нашем случае, всё-таки здесь мы очень постарались. Всякие там серверные pch-файлы и собственный типа препроцессор срезают очень много локального времени помимо remote-кешей. По доке пока непонятно, как он работает, совсем свежая тулза.
Но сравнить интересно, да. Звучит как задание для какого-нибудь стажёра в будущем :))

rjhdby
25.10.2022 19:56-5Зашёл сегодня во вконтактик, а там реклама ЧВК Вагнер в ленте.
И вот читаю статью и обуревают двойственные мысли. С одной стороны крутые штуки делаете, с другой стороны, для чего эти крутые штуки используются в итоге.

rPman
25.10.2022 21:03Как я понимаю, дерево исходников синхронизируется между нодами средствами самого nocc?
А если использовать кеширование средствами файловой системы nfs? т.е. централизованно дерево исходников на одном сервере, шарится по nfs, при чтении кешируется cachefile каждой нодой самостоятельно и прозрачноВероятно, заработает, если нет макросов внутри инклудов.
не понял про этот момент, ваш инструмент постройки дерева зависимостей не умеет препроцессор?unserialize Автор
26.10.2022 03:04Как я понимаю, дерево исходников синхронизируется между нодами средствами самого nocc?
Между серверными нодами ничего не нужно синхронизировать: для компиляции a.cpp на сервере S1 достаточно, чтобы все зависимости рекурсивно находились на сервере S1. Они не нужны на S2, S3 и т.д. Ведь a.cpp попадает всегда на S1 (по имени файла).
ваш инструмент постройки дерева зависимостей не умеет препроцессор?
Чтобы определить все зависимости #include рекурсивно (а это делается на клиенте, т.е. для каждого из 200к файлов), используется кастомная парсилка инклудов. `#include "some-file.h"` она зарезолвит, а вот `#include GENERATE_FILENAME(...)` уже нет: здесь без запуска препроцессора на стороне клиента обойтись никак. В нашем случае — и в большинстве случаев в целом — пути к инклудам статичные, без макросов. Кастомную парсилку можно отключить, что приведёт к вызову препроцессора локально на каждый cpp, но это конечно сразу будет дольше.
rPman
26.10.2022 17:03Между серверными нодами ничего не нужно синхронизировать
для того чтобы компилировать один .cpp, нужно чтобы компилятор имел под рукой (локальной в виде файлов или через stdin или через пайпы) сам этот файл и все его include по всему дереву зависимостей
на сколько я помню distcc каждый раз перемещает по сети все необходимые файлы и не кеширует их, что по сети очень накладно (возможно это дает дополнительный оверхед?)unserialize Автор
26.10.2022 17:08Конечно, для .cpp нужно скопировать все include по всему дереву. nocc ровно это и делает (1 .cpp + 49 .h загружает, например). Впоследствии, даже если сам .cpp изменится — большинство include'ов из дерева зависимостей окажутся уже загруженными (1 .cpp + 2 .h, условно, остальные 47 уже там).
distcc работает не так. distcc гоняет препроцессор локально. А препроцессор, он ведь вместо инклюдов вставляет реальное содержимое файлов на клиентской стороне. Поэтому из .cpp после препроцессора в итоге получится такая боооольшая простыня, и вот её distcc уже отправляет на удалённый сервер.
rPman
26.10.2022 18:09-1вот я и спрашиваю, что не лучше ли складывать все файлы включая результат прекомпиляции pch на сервере и пусть его кешируют slave ноды компиляции автоматически, а не транслируют по мере необходимости (а она 100% будет) каждый раз когда компиляция запускается?

sev
26.10.2022 01:17+1А мне стало интересно, а сколько же времени занимает линковка 200 тыс. файлов и какой итоговый размер бинарника?
unserialize Автор
26.10.2022 03:10+2Долго :) Дольше, чем в итоге компиляция с нуля.
Мы используем partial linking: условно, эти 200к файлов разбиты на 100 папочек, по 2к каждов в каждой. Каждая папочка линкуется отдельно (получается 100 объектников) — это можно делать параллельно, делается весьма быстро. А потом 100 объектников линкуются в один большой. И вот это уже долго.
Мы используем lld. Итоговый бинарь линкуется почти 2 минуты, и не очень понятно, что с этим сделать. Когда был просто ld — было почти в 3 раза дольше, всё-таки lld значительно шустрее.
Пробовали завести новый модный mold linker (https://github.com/rui314/mold) — не срослось, он выдаёт закоррапченные бинарники, которые не запускаются, причём нестабильно, как повезёт.

Vest
26.10.2022 14:24+1Не секрет ли, какой размер итогового бинарника (с отладкой и без)? Просто любопытны масштабы.
unserialize Автор
26.10.2022 15:40+1Не секрет :)
С дебаг-символами около 6.5 ГБ.
Без дебаг-символов (стрипнутый) — 1.3 ГБ.
На продакшене крутится стрипнутый бинарь (именно он раскидывается на тысячи бекендов и обслуживает http-запросы). А бинарь с дебаг-символами лежит отдельно и нужен, чтобы запускать addr2line на нём в случае проблем (по адресам, полученным с продового бинарника).
Vest
26.10.2022 16:32+2Спасибо, было интересно узнать.
А ещё можете описать процесс как происходит разработка и сколько времени занимает посмотреть результат на машине разработчика?То есть человек правит строчку, компилирует бинарник - около 70-80 секунд, потом линковка под 100-200 секунд. А потом сам запуск бинарника (сколько это времени занимает с учётом подключения к какой-нибудь БД с данными)? Ну и докликать до результата (я думаю, что там разработчик сразу по ссылке куда-то переходит, чтобы посмотреть результат).
Как больно разрабатывать такой бекенд? :) Мне это любопытно. Может быть у вас есть какой-нибудь dynamic linking библиотек, чтобы не перезапускать бекенд каждый раз.
unserialize Автор
26.10.2022 16:58+4А вот здесь всё не так :)
Мы пользуемся тем, что мы написаны на PHP. Поэтому VK разрабатывается и прекрасно работает на обычном PHP тоже (только медленно).
Так что бекендер правит строчку в IDE — автоматически через SFTP зеркалится на сервер — и всё. Никакой компиляции. Только интерпретация, будто обычный PHP-сайтик.
Так что разрабатывается на PHP. Юнит-тесты тоже (PHPUnit это всякие там моки, рефлексия — в KPHP этого нет и не должно быть). А KPHP-сборка — это только для продакшена. Базовый флоу именно такой.
Ну и в гит хуках, когда создаёшь MR'ы всякие, там KPHP тоже прогоняется — но там просто трансляция PHP->C++, а это быстро (сборка и линковка не нужны). Предполагаем, что если KPHP на фазе трансляции не упал, то код валиден и конечный C++ на проде уже соберётся и будет работать ровно как изначальный PHP.
Поэтому — совсем не больно разрабатывать такой бекенд :)

vvzvlad
26.10.2022 23:18+1А где тогда используется такая сборка на nocc, если большинство разработчиков разрабатывают на php?
unserialize Автор
27.10.2022 12:50Ну, я чуть упростил картину, конечно. Разрабатывают действительно на обычном PHP. А вот когда нужно: если хотят полазить по быстрой версии сайта / если хотят убедиться, что на KPHP тоже работает так же (особенно что касается корутин, параллелизации и других штук, которые реализованных в PHP через полифиллы) / выложить ветку для тестировщиков — тогда и нужна полная сборка. Для тестировщиков, например, разные версии сайта от разных разработчиков деплоятся больше сотни раз за день.
Vest
27.10.2022 08:40+1Спасибо вам ещё раз. А можно последний вопрос?
Сколько по времени занимает запуск одного бинарника (в проде) такого размера (влияет ли на это время размер файла)? Наверняка, ещё там всякие соединения/кеши запускаются, что-то инициализируются, сколько ещё времени нужно, чтобы бекенд стал «готовым к работе»?
unserialize Автор
27.10.2022 12:53+1Запускается, на самом деле, достаточно быстро. Там скорее сложность другая, ведь нельзя погасить старый бинарник и запустить новый вместо него — ведь старый в режиме нон-стоп обрабатывает запросы. Вместо этого используется graceful restart: поднимается рядом новый бинарник и начинает постепенно "утягивать" новые коннекты со старого, а старый продолжает работать, пока не завершит последний скрипт, и потом умирает. Соответственно, за это время, пока коннекты плавно перетекают, сам собой происходит прогрев локальных кешей и другая предварительная инициализация.
А вот раскидывать бинарник такого размера на много тысяч бекендов, даже через gossip deploy — вот это и правда долго, несколько минут :(
vvzvlad
27.10.2022 16:34+1начинает постепенно «утягивать» новые коннекты со старого, а старый продолжает работать, пока не завершит последний скрипт, и потом умирает.
А как это реализовано?DrDet
27.10.2022 17:29+5У kphp сервера есть специальный файлик в разделяемой памяти (см. shm_open).
Когда новый сервер стартует, он через этот специальный файлик связывается со старым сервером, и начинается graceful restart.
Сначала старый сервер через UNIX сокет с помощью SCM_RIGHTS посылает новому открые файловые дескрипторы нужных серверных коннектов.
Затем старый сервер начинает плавно тушить своих воркеров (в kphp prefork сервер), в то время как новый поднимает своих.
В итоге, когда воркеров больше не остается, старый сервер завершается, и получается бесшовный рестарт.rPman
27.10.2022 19:12+1черт вот это интересно, речь именно о передаче текущих открытых соединений между двумя процессами, чтобы второй процесс продолжил их обрабатывать?
можно как то по подробнее что ли?

firehacker
26.10.2022 18:07+3Выглядит, как какой-то сюр для меня. Я бы поверил, если бы речь шла о бинарнике, представляющем собой AI, не отличимый от человека. Какую-нибудь супер-СУБД с гениальным планировщиком запросов и оптимизатором.
Но какой такой логикой можно НАСТОЛЬКО раздуть бинарник бэкенда соцсети?
У браузера, про которые сейчас модно говорить, что они стали настолько сложными, что никто может ни начать писать свой с нуля и догнать мейджоров, ни найти человека, который разбирался во всём коде продукта. Дак и то, там размер бинарника на два порядка меньше.
Ядра ОС, опять таки, решают намного более сложные и разнообразные проблемы, а бинарники занимают не так много.
А у вас же просто по большей части CRUD с контролем доступа для не такого уж большого набора типов сущностей? Ну хорошо, балансировка нагрузки, составление вектора интересов и персонификация ленты. Ну как бы я не напрягал фантазию, я не могу предтставить, чем можно забить гигабайты секции кода. Может быть только если инлайнить абсолютно всё, то что-то подобное можно достигнуть.
sbase
26.10.2022 21:57О! Это элементарно! У нас как раз то, о чем говорите "планировщик, оптимизатор", и тд, но для расписания проектов. Общая сборка: 21.000 целей для сборки после KPHP. На выходе c -ggdb почти 2 гига бинарник, без этого 211M. Из них сам рантайм (реализация всех PHP-функций) где-то 70М весит.
Хотя на входе исходных файлов меньше, около 5000. При этом У нас автогенеренного кода еще много-много создаётся (ибо нету в KPHP рефлексии , пришлось написать).
Поэтому, основной объём идёт чисто от автогенерации кода, которая нужна для ускорения. А сам планировщик - там кода очень немного, всего 90 файлов.
unserialize Автор
27.10.2022 12:57Если уж честно, то я сам не понимаю, почему НАСТОЛЬКО много PHP-кода. Иногда поглядываю статистику и ужасаюсь: капец, за полгода ещё миллион строчек добавили, ну как??? Бедный, думаю, KPHP, как он вообще справляется. Но уж что имеем, то имеем. Проблема всех больших компаний, а также монореп с бесконечной цикломатичностью кода ( И уж явно не компилятора.

Kvento
26.10.2022 09:16Спасибо за статью. Подходит ли nocc для сборок с несколькими версиями компилятора? Например при сборке под несколько платформ: Intel, arm. Учитываете ли вы проверку контрольной суммы бинарника компилятора при составлении ключа для объектного файла, как ccache?
unserialize Автор
26.10.2022 14:05+1Предполагается, что на всех серверах компилятор одинаковый — ровно тот же самый, что и локально. То есть не важно, где исполнить `cxx 1.cpp` — локально или на сервере Х. Даже если везде g++, но разных версий — я считаю это undefined behaviour. Можно добавить какие-то проверки, но мне кажется, это должно решаться именно на уровне конфигурирования.
Поэтому, если nocc-server поставить на ARM'овые сервера, то всё заработает (проверяли).
Кросс-компиляцию тоже можно поддержать, добавив анализ -sysroot / -isysroot, поиск хедеров в нужных папках на клиенте и подмену этих опций на сервере. Я просто их не добавлял на данный момент, но это не сложно.

xabar
26.10.2022 14:06+1Статья вызывает у меня чувство гнева. К авторам вопрос к авторам - что за ДИЧЬ вы делаете? Ваша проблема лежит в другой плоскости - вы генерируете 200 000 (двести тысяч) фалов мусорных-исходников. При этом используете конвертацию из бедного и примитивного языка PHP в один из самых гибких и сложных языков C++. Зачем? Чтобы код на C++ был быстрым - он должен быть создан качественно изначально, с проработкой всех иерархических, структурных и архитектурных нюансов проекта и среды исполнения. И сейчас суть вашей проблемы - PHP->C++. Все остальное - ваши попытки натянуть сову на глобус.
P.S. Господа, не хочу никак никого оскорблять. Но тут на лицо эффект Даннинга-Крюгера у команды разработчиков. А другие читают подобное и, что самое страшное, могут ведь вдохновится и начать заниматься тем же самым - деградацией.
P.P.S. А потом участники таких проектов приходят на собеседование и не могут банально рассказать про то, как что такое BSS, TEXT, elf и чем отличается uint32_t* от void*. Зато они могут положить на лопатки 64 ядра с 5 ТБ ОЗУ на сборку проекта "рабасной" игры из ВК.
Всем добра!

quasilyte
26.10.2022 14:32+2Статья вызывает у меня чувство гнева.
Гнев - довольно сильное чувство. Забавно, что техническая статья может так триггерить.
Ваши нападки на меня и мою команду гнева у меня не вызывают, но вот демотивируют и вызывает некоторое удивление - да.
P.P.S. А потом участники таких проектов приходят на собеседование и не могут банально рассказать про то, как что такое BSS, TEXT, elf и чем отличается uint32_t* от void*. Зато они могут положить на лопатки 64 ядра с 5 ТБ ОЗУ на сборку проекта "рабасной" игры из ВК.
Как-то не очень похоже на "всем добра", какие-то осуждения и сомнения в квалификации. Для начала, я не считаю незнание чего-либо пороком, не знать что-то - это нормально. Я далеко не эксперт, но свой вклад сделал в более чем один компилятор (и язык программирования), сделал много статей и докладов, чтобы как-то делиться знаниями, веду более одного популярного open source проекта.
Ваши домыслы о людях, которых вы не знаете, весьма сомнительны на этом фоне. А ещё это не очень приятно и не вполне вежливо. Технологии и код подвергать критике - это ОК, за этим мы здесь и собрались. Но вот о людях так высказываться в этом контексте мне кажется лишним.
У всех бывает синдром самозванца и в целом быть уверенным в своих достижениях - это не так просто. Когда вы так обесцениваете всё, то лишь увеличиваете количество негатива. Вы же не думаете, что помогаете ими кому-то?
Меня уже больше, чем должна, напрягает подобная позиция некоторых хабравчан ("всё говно, вы дурачки, а вот у меня софт хороший"). Ваше мнение услышано, но если вы практически лично людей оскорбляете, то будьте готовы получить ответ.
Спасибо за внимание.
xabar
26.10.2022 15:12-1Вы уж извините меня за прямоту и грубость, но дополню. Суть поста не о том, что проблема у вас с командой и проектом - личное дело каждого как ему зарабатывать на хлеб - разбивая большие камни на маленькие, или пройдя ускоренные курсы гикбрейнс начать зарабатывать в IT. Суть поста - что авторы создали проблему из-за своей безграничной узколобости и потом начали решать проблему через задний проход. И писать об этом, как о достижении - это неуважение (профессиональное) к читателю (имхо).
Когда закипает молоко - нужно прикручивать огонь, а не дуть на пену и подставлять тряпки при этом создавая презентацию и статью на тему "методика многопоточного клининга варочной панели горенья в условиях форсмажорного приготовления борща командой интернациональных поваров-фрезеровщиков при пониженном атмосферном давлении и сильном боковым ветром с камнепадом (в паверпоинте)".
Выводы про людей я не делаю - я делаю выводы про специалистов. Это разное.

Danil42Russia
26.10.2022 16:29+2Суть поста - что авторы создали проблему из-за своей безграничной узколобости и потом начали решать проблему через задний проход.
И писать об этом, как о достижении - это неуважение (профессиональное) к читателю (имхо).
А на сколько это "профессионально" и "уважительно" писать об авторах о "безграничной узколобости"?
vvzvlad
26.10.2022 23:21. Суть поста — что авторы создали проблему из-за своей безграничной узколобости и потом начали решать проблему через задний проход.
Ну вы и мудак. Простите (нет)
wataru
26.10.2022 16:57+5Ну нет, не согласен. Проблема компиляции больших проектов все равно есть. Даже если бы тут все было руками на С++ изначально написано, компиляция была бы все также слишком медленной для одной машины. Возьмите chrome, например. Изначально он написан на С++, но без распределенного компилятора его собирать очень и очень долго. И предложенное тут решение — вполне хорошее.
Генерация кода С++ из PHP — не самое красивое решение, но оно работает. Если уж такой большой проект уже долго развивался на PHP, то переписать руками все просто невозможно, а весьма заметный припрост производительности это решение обеспечивает.
sbase
26.10.2022 22:14+3Переписать всегда можно, и даже инвестировать туда кучу ресурсов но... переход на С++ убьёт одну небольшую возможность: БЫСТРАЯ ПРОВЕРКА.
Мы после миграции на KPHP этим активно пользуемся, получается очень мощна связка: Быстрая проверка (вPHP режиме) и Быстрое исполнение (в KPHP сборке).
В С++ проекте чтобы проверить "А как оно выглядит" нужно ждать сборки, это даёт хороший эффект - архитектура становится лучше (потому что работает Закон Васильева). Но... замедляется проверка идей.
Закон Васильева о квалификации разработчика ПО: Время необходимое инженеру для достижения уровня "Профессионал" обратно пропорционально времени сборки сборки проекта.
Обоснование Закона: Чем дольше собирается проект, тем больше разработчик не хочет ждать этой сборки, тем тщательней он проектирует систему на бумаге. Тем быстрее растёт его квалификация в разработке ПО.
Доказательство Закона: сравните знания по ООП у С++ и веб-разработчика с трёх-летним стажем.wataru
26.10.2022 22:31Интересная мысль. В Хроме эта проблема решается разбиением тестов на маленькие бинарники. Какие-нибудь юнит-тесты можно запустить буквально сразу — компилироваться будет лишь маленькая часто прокета. Сам же хром для ручных тестов собирать придется целиком, да, но обычно программист не трогает все-все-все, а работает лишь с какой-то одной небольшой подсистемой. Тогда после одной долгой компиляции раз в несколько дней каждая следующая после локальных изменений происходит довольно бытсро из-за кеша. Поэтому эта проблема не стоит особо остро.
Но возможность тупо сразу запускать что угодно, хоть и медленнее — это реально круто.
0xd34df00d
27.10.2022 17:42+1Доказательство Закона: сравните знания по ООП у С++ и веб-разработчика с трёх-летним стажем.
Странное доказательство. А давайте сравним знания лямбда-исчисления у С++ и у хаскель-разработчика (где можно из репла с моментальной перекомпиляцией не вылезать) или у агда-разработчика (где код вообще не компилируют) с каким угодно стажем. Что это нам скажет?
vvzvlad
26.10.2022 23:32+9При этом используете конвертацию из бедного и примитивного языка PHP в один из самых гибких и сложных языков C++. Зачем? Чтобы код на C++ был быстрым — он должен быть создан качественно изначально, с проработкой всех иерархических, структурных и архитектурных нюансов проекта и среды исполнения.
Ваш С++ уже настолько разжирел из-за желания комитета впихнуть туда как можно больше новых фишек и нежелания ломать обратную совместимость, что для того, чтобы разрабатывать со всей этой гибкостью и сложностью надо лет пять просидеть, изучая все функции и то, в каких случаях их лучше применять, а потом еще и тратить ощутимую долю рабочего времени для того, чтобы отслеживать все новинки в языке, иначе не дай бог случайно использовать что-то устаревшее.
Не адепту уж плюсов писать тут о том, какой PHP бедный. По сравнению с последними плюсами и пайтон бедный. Мешает это делать на нем софт? Да нифига.
И желание писать на чем угодно, только не на плюсах, и использовать для ускорения этого пусть даже немного экзотические инструменты команды вк я легко понимаю — лучше когда разработчики логики ленты изучают «ограниченный» и «бедный» язык за пол-года, чет вляпываются в С++ на год-другой, разбираясь как им пользоваться, а потом еще год живут интернами, разбираясь как этим пользоваться правильно.
А тем кому интересно по-максимуму поковыряться в си и том, как именно правильно применить инструменты из нового релиза для скорости, коммитят в KPHP.
apro
27.10.2022 14:48К авторам вопрос к авторам - что за ДИЧЬ вы делаете? Ваша проблема лежит
в другой плоскости - вы генерируете 200 000 (двести тысяч) фалов
мусорных-исходников.Так можно же посчитать. Допустим использование KPHP дало им 600% ускорения, при этом их приложение запускается на N серверов. Для поддержания функционирования KPHP им нужно M серверов, на которых запущен обсуждаемый в статье nocc. Если N = 1000, а M скажем равен 10, то это кажется выигрышной стратегией.
Возможно если бы они сразу генерировали что-нибудь типа LLVM IR вместо C/C++, то вместо M=10 хватило бы M = 5. Но даже так это весьма выигрышная стратегия.
quasilyte
По традиции, продублирую ссылочку на сообщество KPHP:
https://t.me/kphp_chat