
Код, который мы пишем, и который будет исполнен процессором, — две разные вещи. На уровне ассемблера существует миллион вариантов, в каком виде интерпретировать и запустить высокоуровневые команды. Более того, современные компиляторы сильно оптимизируют код, а результат этой оптимизации похож на магию.
Способ интерпретации исходного кода в ассемблерные команды зависит от версии и настроек компилятора, а также от целевой платформы. И только видя результат компиляции — итоговый машинный код — можно понять, как он будет работать. Если получается не оптимально, то внести соответствующие изменения в исходник, попробовать другой компилятор или другие настройки.
Для такой оптимизации хочется в реальном времени наблюдать, к каким изменениям в машинном коде приводит редактирование исходника. Есть специальные инструменты, которые выполняют такую трансляцию на лету, в том числе Compiler Explorer (многие называют этот инструмент Godbolt по доменному имени и фамилии автора), uiCA, Quick C++ Benchmark, а также Sharplab.io, который специализируется на быстрой компиляции C#.
Compiler Explorer
Известный ресурс Compiler Explorer (godbolt.org) от Мэтта Годбольта демонстрирует результат трансляции в машинный код для 46 языков программирования:
Список языков
Id | Name csharp | C# fsharp | F# vb | Visual Basic go | Go c | C c++ | C++ fortran | Fortran assembly | Assembly circle | C++ (Circle) circt | CIRCT hlsl | HLSL cppx | Cppx crystal | Crystal dart | Dart erlang | Erlang carbon | Carbon hook | Hook cppx_blue | Cppx-Blue cppx_gold | Cppx-Gold mlir | MLIR cuda | CUDA C++ analysis | Analysis python | Python racket | Racket ruby | Ruby typescript | TypeScript Native d | D ada | Ada cpp_for_opencl | C++ for OpenCL openclc | OpenCL C llvm | LLVM IR cpp2_cppfront | Cpp2-cppfront rust | Rust ispc | ispc java | Java kotlin | Kotlin nim | Nim pony | Pony scala | Scala solidity | Solidity clean | Clean pascal | Pascal haskell | Haskell ocaml | OCaml swift | Swift zig | Zig
На интересующий язык можно перейти сразу по прямой ссылке, указав его в поддомене, например, erlang.godbolt.org, rust.godbolt.org и т. д.
Интерфейс простой: в окошке слева вводим исходный код, в окошке справа появляется результат компиляции. Сверху выпадающее меню с выбором версии компилятора и аппаратной платформы, под которую генерируется машинный код. Там же можно указать настройки компилятора (включить разные оптимизации) и посмотреть, как это отразится на результате. По умолчанию код компилируется без каких-либо оптимизаций.
Интерфейс меняется по желанию пользователя: можно сравнить справа два компилятора, а можно добавить окошки для сравнения двух вариантов исходного кода:
Отобразить промежуточный язык LLVM:

Или препроцессор:
Удобно, что каждый пример кода можно расшарить с коллегами по прямой ссылке (кнопка Share):

Автор запустил проект в далёком 2012 году как маленький экспериментальный сайтик под названием GCC Explorer (тогда он поддерживал только один компилятор GCC), а сейчас он вырос в большой и полезный ресурс для изучения компиляторов C++ и других языков программирования, а также оптимизации кода. По статистике проекта, сейчас он выполняет более 200 000 компиляций в сутки, примерно по 3 компиляции в секунду. В основном на C++ и C.
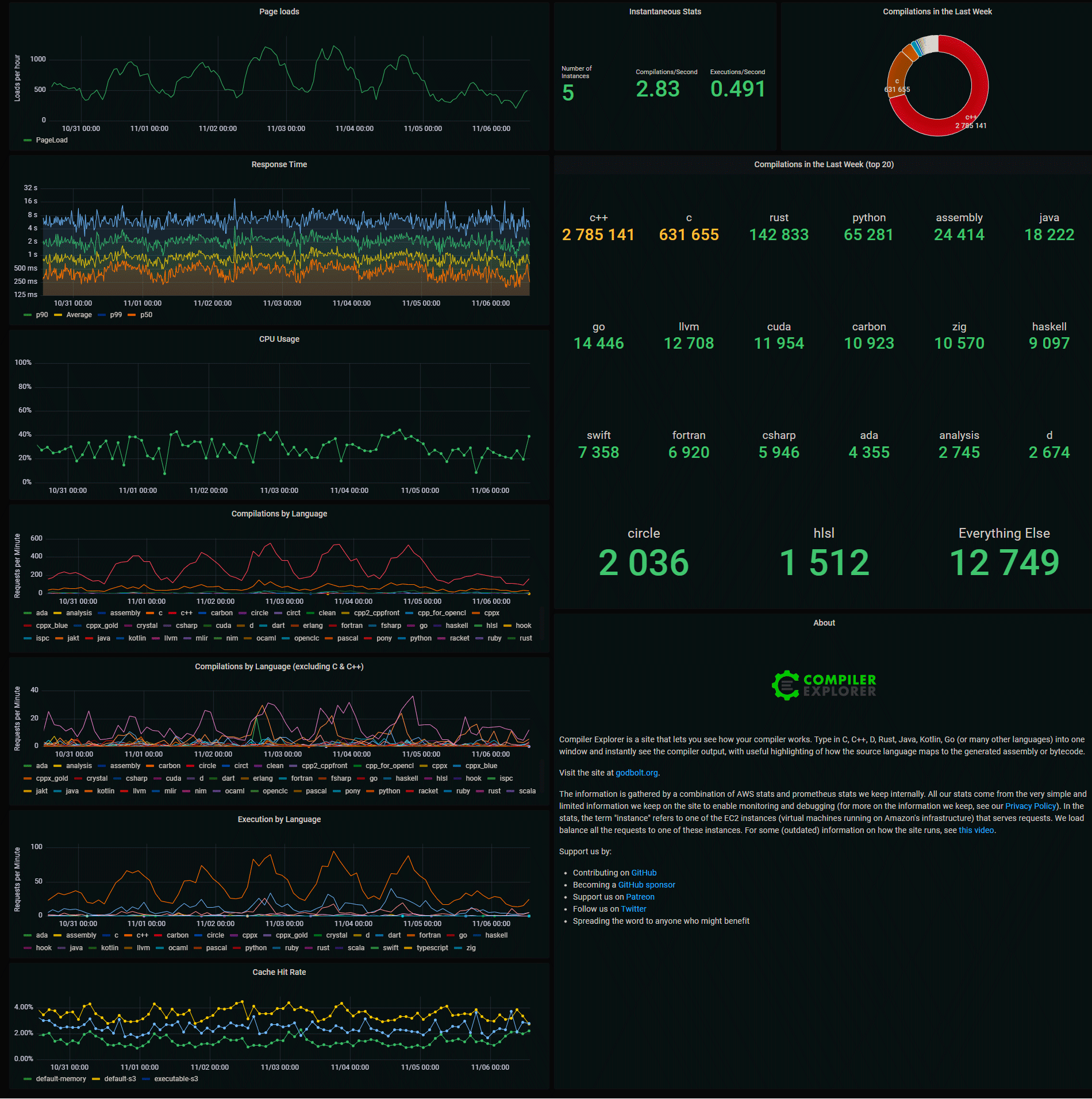
Любопытно, что на третье место по популярности среди языков программирования вышел Rust, хотя C++ и C остаются вне конкуренции.
Оптимизация кода
▍ Количество инструкций
По машинному коду в Godbolt можно примерно прикинуть производительность своего кода. Самая наивная метрика — количество инструкций. Чем их меньше, тем лучше. Хотя это не всегда так, потому что некоторые инструкции в современном ассемблере могут выполняться за сотни вычислительных циклов на CPU. Кажется, что если есть возможность изменить оригинальный исходник и количество инструкций в машинном коде уменьшится, это может быть полезно. Но по большому счёту это довольно бесполезная микрооптимизация, поскольку скорость выполнения разных инструкций отличается в разы. А сами вычислительные инструкции можно считать практически бесплатными по сравнению с обращениями в память.
▍ Обращения к памяти
Обращения к памяти, в том числе к кешу L3 — на несколько порядков более медленная операция, чем любое вычисление в CPU. По идее, минимизация обращений к памяти (в том числе через исключения) — первая и главная цель оптимизации, а не простое количество вычислительных инструкций.
▍ Бенчмарк ассемблера
Для более наглядной оценки есть специальные инструменты визуализации и бенчмарки, которые помогают примерно оценить производительность машинного кода, такие как анализатор uiCA (The uops.info Code Analyzer). Копируем сюда фрагмент ассемблерного кода из предыдущего окна Godbolt и запускаем эмулятор.
Например, возьмём для анализа такой цикл:
loop:
add rax, [rsi]
adc rax, [rsi+rbx]
shld rcx, rcx, 1
shld rcx, rdx, 2
dec r15
jnz loopВыдача uiCA:
Throughput (in cycles per iteration): 4.00 Bottleneck: Dependencies M - Macro-fused with previous instruction ┌───────────────────────┬────────┬───────┬───────────────────────────────────────────────────────────────────────┬───────┐ │ MITE MS DSB LSD │ Issued │ Exec. │ Port 0 Port 1 Port 2 Port 3 Port 4 Port 5 Port 6 Port 7 │ Notes │ ├───────────────────────┼────────┼───────┼───────────────────────────────────────────────────────────────────────┼───────┤ │ 1 │ 1 │ 2 │ 1 1 │ │ add rax, qword ptr [rsi] │ 1 │ 2 │ 2 │ 0.66 1 0.34 │ │ adc rax, qword ptr [rsi+rbx*1] │ 1 │ 1 │ 1 │ 0.48 0.52 │ │ shld rcx, rcx, 0x1 │ 1 │ 1 │ 1 │ 1 │ │ shld rcx, rdx, 0x2 │ 1 │ 1 │ 1 │ 1 │ │ dec r15 │ │ │ │ │ M │ jnz 0xffffffffffffffec ├───────────────────────┼────────┼───────┼───────────────────────────────────────────────────────────────────────┼───────┤ │ 5 │ 6 │ 7 │ 1.13 1 1 1 1 1.87 │ │ Total └───────────────────────┴────────┴───────┴───────────────────────────────────────────────────────────────────────┴───────┘
Анализатор оценивает пропускную способность этого цикла на архитектуре Skylake в четыре цикла на итерацию (процессорную инструкцию), а бутылочным горлышком производительности называет зависимости.
Вот как выглядит трассировка исполнения для 25 первых итераций цикла:
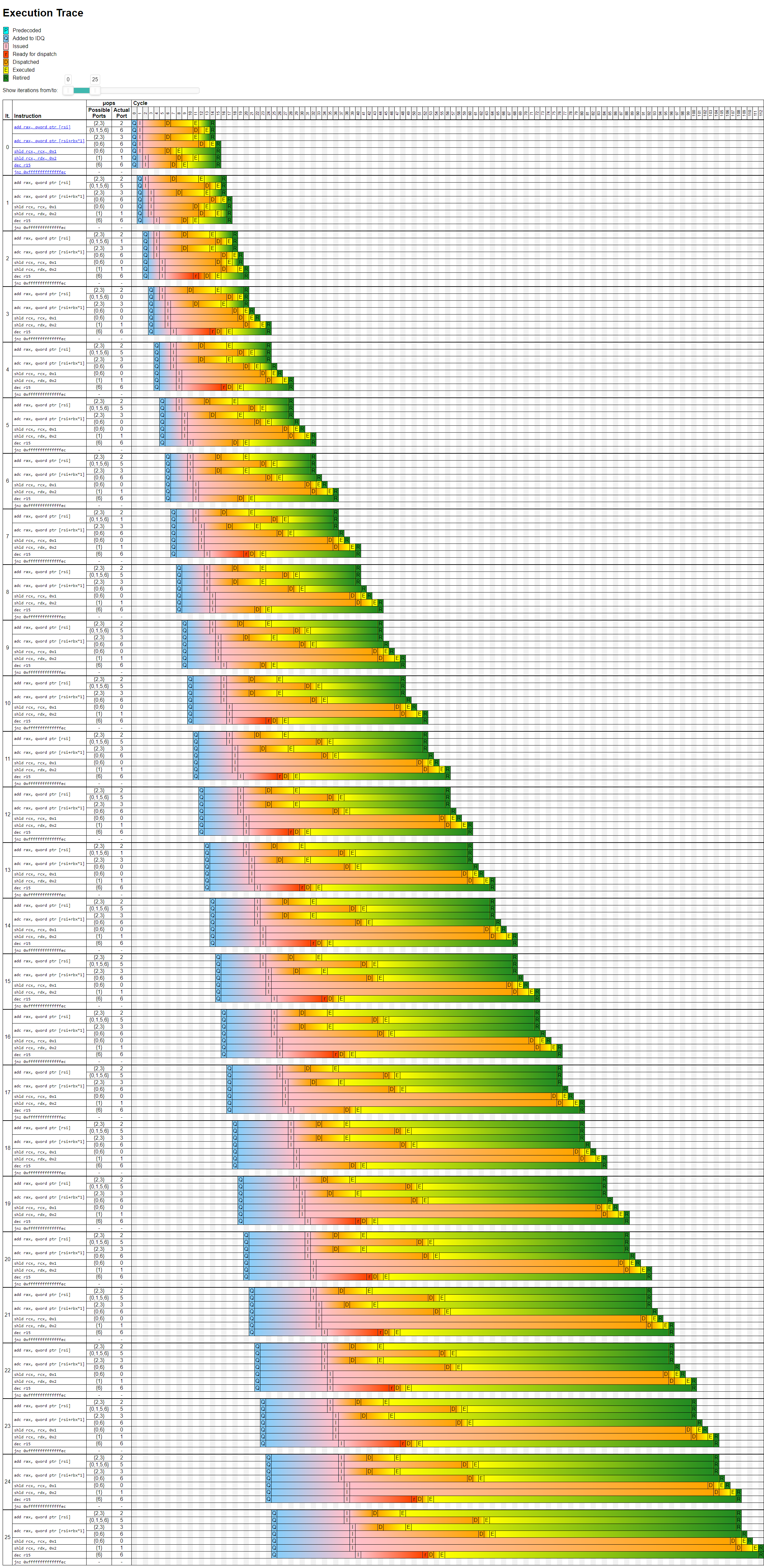
Кроме Skylake, можно посмотреть трассировку выполнения на всех последних микроархитектурах Intel: Sandy Bridge, Ivy Bridge, Haswell, Broadwell, Skylake-X, Kaby Lake, Coffee Lake, Cascade Lake, Ice Lake, Tiger Lake и Rocket Lake.
Выдача стандартного
objdump:0000000000000000 <loop>:
0: 48 03 06 add rax,QWORD PTR [rsi]
3: 48 13 04 1e adc rax,QWORD PTR [rsi+rbx*1]
7: 48 0f a4 c9 01 shld rcx,rcx,0x1
c: 48 0f a4 d1 02 shld rcx,rdx,0x2
11: 49 ff cf dec r15
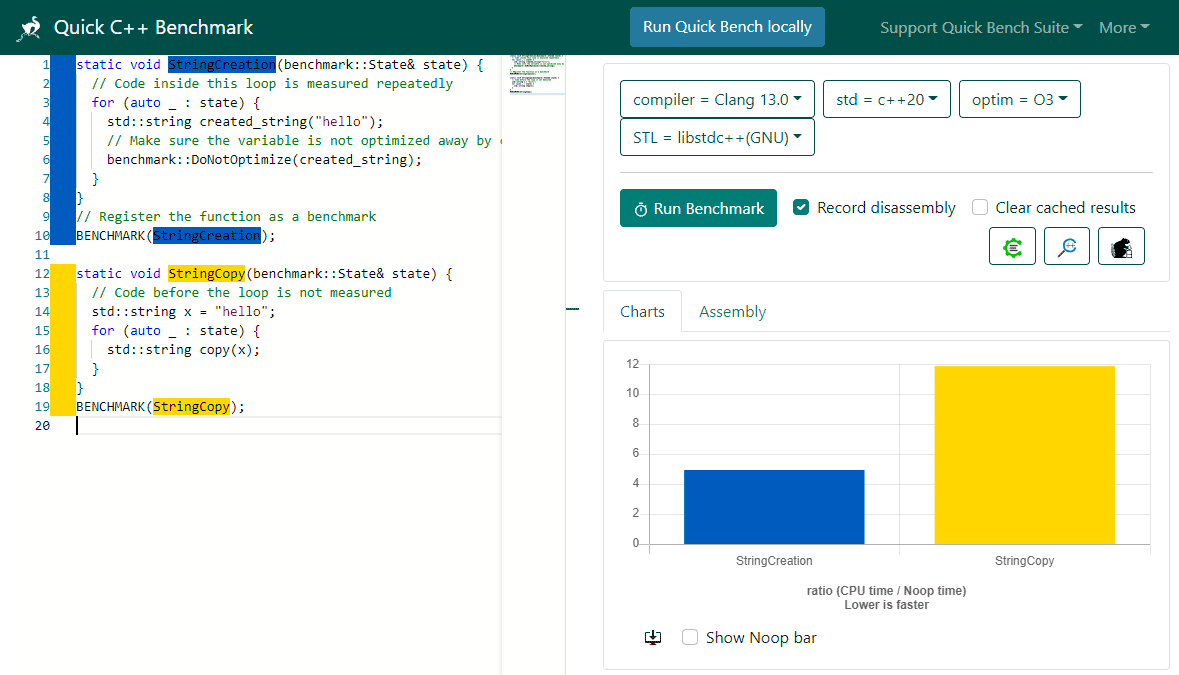
14: 75 ea jne 0 <loop>Другой полезный инструмент — Quick C++ Benchmark — быстрый бенчмарк кода С++. Сюда копируем фрагмент исходного кода на C++, выбираем компилятор и параметры и смотрим, что получается на разных опциях. Тут можно убедиться, что самые медленные фрагменты в программе — операции с памятью.
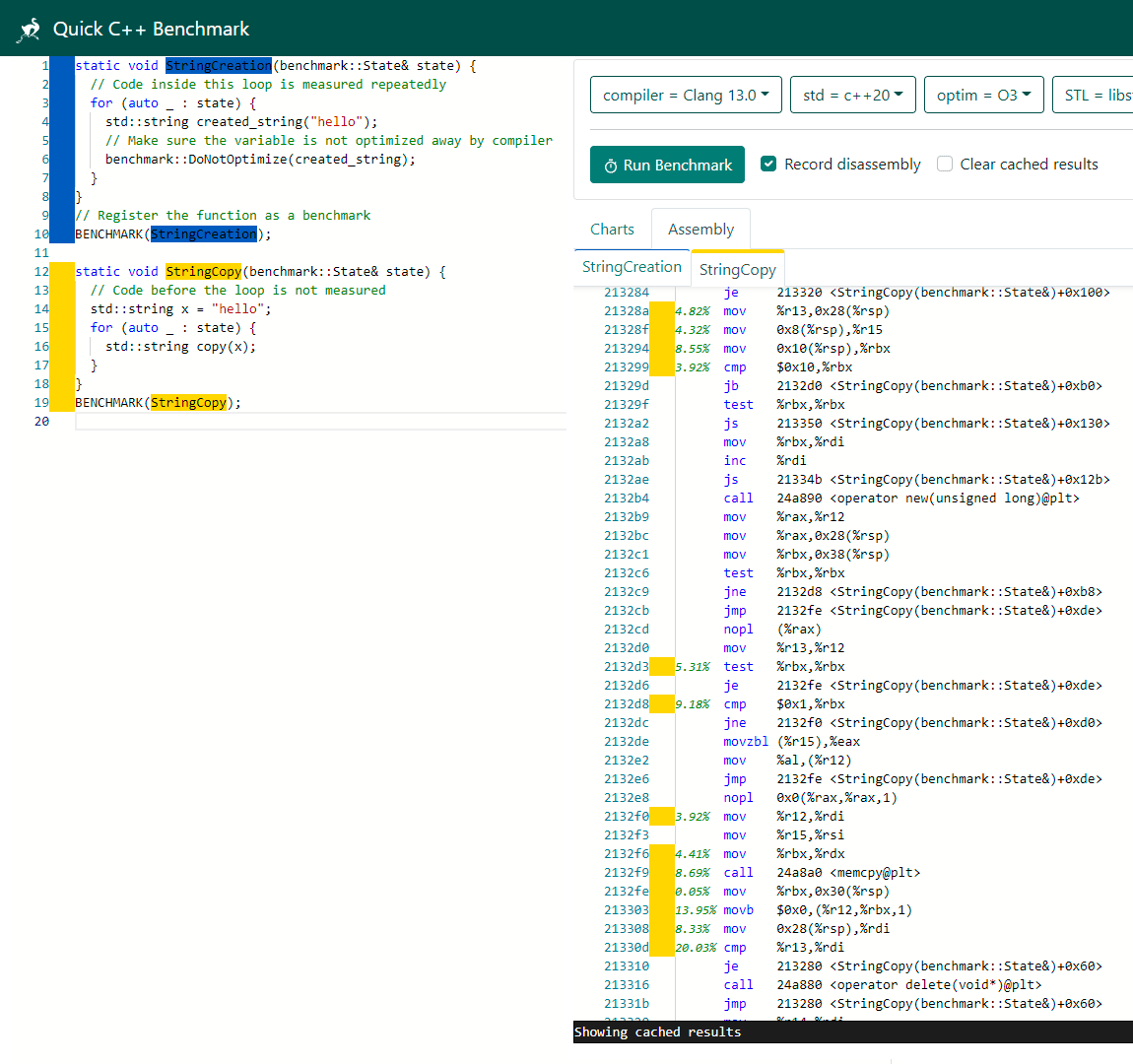
В отдельном окошке показывается и соответствующий машинный код, в том числе самые медленные операции.
В научной статье от 2019 года Мэтт Годбольт приводит примеры базовых оптимизаций, которые выполняет компилятор.
По его словам, многие оптимизации относятся к разряду упрощения выражений, когда мы берём более дорогие операции и преобразуем их в менее дорогие. Простейший пример — цикл с умножением и счётчиком:
for (int i = 0; i < 100; ++i)
{
func(i * 1234);
}Даже на современных CPU умножение гораздо медленнее, чем сложение, поэтому компилятор переписывает этот код следующим образом:
for (int iTimes1234 = 0; iTimes1234 < 100 * 1234; i += 1234)
{
func(iTimes1234);
}Самая дорогая арифметическая операция — деление, которое обычно в 20–50 раз дороже сложения и 5–10 раз дороже умножения. Поэтому компилятор старается по возможности убрать деление. Например, заменить его сдвигом с умножением.
Пример:
unsigned divideByThree(unsigned x)
{
return x / 3;
}Результат оптимизации:
divideByThree(unsigned int):
mov eax, edi ; eax = edi
mov edi, 2863311531 ; edi = 0xaaaaaaab
imul rax, rdi ; rax = rax * 0xaaaaaaab
shr rax, 33 ; rax >>= 33
retЕсть специальный алгоритм вычисления таких констант. Важно понимать, что на момент компиляции должен быть известен делитель. Если он выясняется в рантайме, то компилятор не сможет рассчитать константу и провести оптимизацию, поэтому такой код будет выполняться гораздо медленнее.
Другие ключевые оптимизации:
Инлайнинг. Компилятор заменяет вызов функции её телом. Это устраняет накладные расходы на вызов и часто открывает возможности для дальнейшей оптимизации, поскольку компилятор может оптимизировать объединённый код как единое целое.
Свёртывание констант. Компилятор берёт выражения, которые вычисляются во время компиляции, и заменяет их непосредственно результатом вычисления.
Распространение констант. Компилятор отслеживает происхождение значений и устанавливает, что определённые значения остаются постоянными для всех возможных исполнений.
Устранение общих подвыражений. Дублирующие вычисления переписываются так, чтобы вычисление выполнялось один раз, а результат дублировался.
Удаление мёртвого кода. После многих оптимизаций могут остаться участки кода, которые не влияют на результат, и их можно удалить. Сюда входят загрузки и сохранения, значения которых не используются, а также целые функции и выражения.
Выбор инструкций. Это не оптимизация как таковая, но поскольку компилятор использует внутреннее представление программы и генерирует инструкции процессора, у него есть выбор эквивалентных последовательностей инструкций для конкретной архитектуры CPU.
Перемещение кода из цикла. Компилятор распознаёт, что некоторые выражения внутри цикла являются постоянными на протяжении всего цикла, и перемещает их за пределы цикла. Кроме того, компилятор способен переместить инвариантную условную проверку цикла за пределы цикла, а затем дважды продублировать тело цикла: один раз, если условие истинно, и один раз, если оно ложно. Это может привести к дальнейшим оптимизациям.
Оптимизация по принципу peephole. Компилятор берёт короткие последовательности инструкций и ищет локальные оптимизации между ними.
Удаление концевой рекурсии. Рекурсивную функцию, которая в конце вызывает саму себя, часто можно переписать в виде цикла, что уменьшает накладные расходы на вызовы и снижает вероятность переполнения стека.
Для максимальной оптимизации кода рекомендуется указывать целевую архитектуру при компиляции, предоставить компилятору как можно больше информации (кода), включая зависимости, и установить флаг уровня оптимизации повыше.
Научная статья Мэтта Годбольта с примерами базовых оптимизаций опубликована 12 ноября 2019 года в журнале ACM Queue (doi: 10.1145/3371595.3372264). Большинство примеров в статье на C или C++, но актуальны для многих других компилируемых языков, а в эпоху популярности LLVM большинство этих оптимизаций работают аналогичным образом даже для таких языков, как Rust, Swift и D.
Весь код проекта Compiler Explorer открыт в репозитории на GitHub, также как конфигурация AWS-инфраструктуры для работы публичных инстансов и сборки более 400 компиляторов. Всего поддерживается 1500 комбинаций компиляторов/языков программирования и сотни дополнительных библиотек общим весом около 2 ТБ, так что облачная установка сайта довольно тяжеловесная.
Автор всегда рад пул-реквестам и спонсорам, обсуждение проекта ведётся в группе в Дискорде.
Sharplab.io
Некоторые разработчики предпочитают альтернативный инструмент Sharplab.io, который специализируется на C# и конкретно для него работает более шустро, чем Compiler Explorer.
Кроме C#, он поддерживает ещё три языка: Visual Basic, F# и IL (Intermediate Language), так называемый «высокоуровневый ассемблер» или «промежуточный язык» виртуальной машины .NET. Все компиляторы на платформе .NET должны транслировать код с языков высокого уровня на IL.
Дефолтный пример.
Код на C#:
using System;
public class C {
public void M() {
}
}Трансляция этого кода в JIT Asm:
; Core CLR 6.0.922.41905 on x86
C..ctor()
L0000: push ebp
L0001: mov ebp, esp
L0003: push eax
L0004: mov [ebp-4], ecx
L0007: cmp dword ptr [0x1a51c190], 0
L000e: je short L0015
L0010: call 0x71cc5060
L0015: mov ecx, [ebp-4]
L0018: call System.Object..ctor()
L001d: nop
L001e: nop
L001f: mov esp, ebp
L0021: pop ebp
L0022: ret
C.M()
L0000: push ebp
L0001: mov ebp, esp
L0003: push eax
L0004: mov [ebp-4], ecx
L0007: cmp dword ptr [0x1a51c190], 0
L000e: je short L0015
L0010: call 0x71cc5060
L0015: nop
L0016: nop
L0017: mov esp, ebp
L0019: pop ebp
L001a: retТрансляция в IL:
.assembly _
{
.custom instance void [System.Runtime]System.Runtime.CompilerServices.CompilationRelaxationsAttribute::.ctor(int32) = (
01 00 08 00 00 00 00 00
)
.custom instance void [System.Runtime]System.Runtime.CompilerServices.RuntimeCompatibilityAttribute::.ctor() = (
01 00 01 00 54 02 16 57 72 61 70 4e 6f 6e 45 78
63 65 70 74 69 6f 6e 54 68 72 6f 77 73 01
)
.custom instance void [System.Runtime]System.Diagnostics.DebuggableAttribute::.ctor(valuetype [System.Runtime]System.Diagnostics.DebuggableAttribute/DebuggingModes) = (
01 00 07 01 00 00 00 00
)
.permissionset reqmin = (
2e 01 80 8a 53 79 73 74 65 6d 2e 53 65 63 75 72
69 74 79 2e 50 65 72 6d 69 73 73 69 6f 6e 73 2e
53 65 63 75 72 69 74 79 50 65 72 6d 69 73 73 69
6f 6e 41 74 74 72 69 62 75 74 65 2c 20 53 79 73
74 65 6d 2e 52 75 6e 74 69 6d 65 2c 20 56 65 72
73 69 6f 6e 3d 36 2e 30 2e 30 2e 30 2c 20 43 75
6c 74 75 72 65 3d 6e 65 75 74 72 61 6c 2c 20 50
75 62 6c 69 63 4b 65 79 54 6f 6b 65 6e 3d 62 30
33 66 35 66 37 66 31 31 64 35 30 61 33 61 15 01
54 02 10 53 6b 69 70 56 65 72 69 66 69 63 61 74
69 6f 6e 01
)
.hash algorithm 0x00008004 // SHA1
.ver 0:0:0:0
}
.class private auto ansi '<Module>'
{
} // end of class <Module>
.class public auto ansi beforefieldinit C
extends [System.Runtime]System.Object
{
// Methods
.method public hidebysig
instance void M () cil managed
{
// Method begins at RVA 0x2050
// Code size 2 (0x2)
.maxstack 8
IL_0000: nop
IL_0001: ret
} // end of method C::M
.method public hidebysig specialname rtspecialname
instance void .ctor () cil managed
{
// Method begins at RVA 0x2053
// Code size 8 (0x8)
.maxstack 8
IL_0000: ldarg.0
IL_0001: call instance void [System.Runtime]System.Object::.ctor()
IL_0006: nop
IL_0007: ret
} // end of method C::.ctor
} // end of class CВ целом, для C++ самым полезным бенчмарком оценки производительности кода кажется Quick C++ Benchmark, в то время как классический Compiler Explorer (godbolt.org) — это более универсальный и академический инструмент, поддерживающий десятки языков. Он позволяет сравнить, как разные компиляторы по-своему интерпретируют один и тот же код.
Современные компиляторы — сложные интеллектуальные машины, которые становятся всё сложнее и умнее. Они делают огромную работу по оптимизации. Для межпроцедурной оптимизации (WPO и LTO) крайне важно предоставить компилятору максимум информации, включая максимальный объём кода, все модули приложения. Конечно, включение интеллектуальных режимов ведёт к замедлению компиляции. Зато на выходе мы получаем маленькие и быстрые бинарники.
Telegram-канал с полезностями и уютный чат


i__egor
Было бы полезно иногда посмотреть на сложность выполнения программы прям в редакторе, например в vs. Подсветкой, гистограмами прям по коду, относительной численной оценкой, чтобы учитывала все вложения, вызовы, возможная сложность типовых функций и тп