
Многим известно, что CUDA является наиболее часто используемой платформой для ускорения массовых параллельных вычислений, применяемых в различных практических и исследовательских областях.
В 2016 году AMD представила в буквальном смысле клон платформы CUDA — ROCm. Альтернативы модулей CUDA для ROCm можно увидеть в таблице с официального сайта AMD.
Таблица соответствия модулей платформ
Модуль платформы CUDA |
Модуль платформы ROCm |
cuBLAS |
rocBLAS |
cuFFT |
rocFFT |
cuSPARSE |
rocSPARSE |
cuSolver |
rocSOLVER |
AMG-X |
rocALUTION |
Thrust |
rocThrust |
CUB |
rocPRIM |
cuDNN |
MIOpen |
cuRAND |
rocRAND |
EIGEN |
EIGEN |
NCCL |
RCCL |
Данная библиотека позволяет в автоматическом режиме переносить исходный код предназначенный для платформы CUDA на ROCm и выполнять его компиляцию. Одним из недостатков данной платформы является исключительная ориентированность на ОС Linux.
Перейдем непосредственно к переносу кода и сравнению производительности платформ.
Тестовая конфигурация
ПК 1 |
ПК 2 |
|
Операционная система |
Windows 10 Pro 21H1 |
Ubuntu 22.04 5.15.0-53-generic |
CPU |
x2 Intel Xeon Gold 6132 |
i5-12600K |
RAM |
x4 DDR4 16GB |
x1 DDR4 32GB |
GPU |
GeForce RTX 3070 8GB |
Radeon RX 6800 XT 16GB |
1. Установка CUDA на ОС Windows
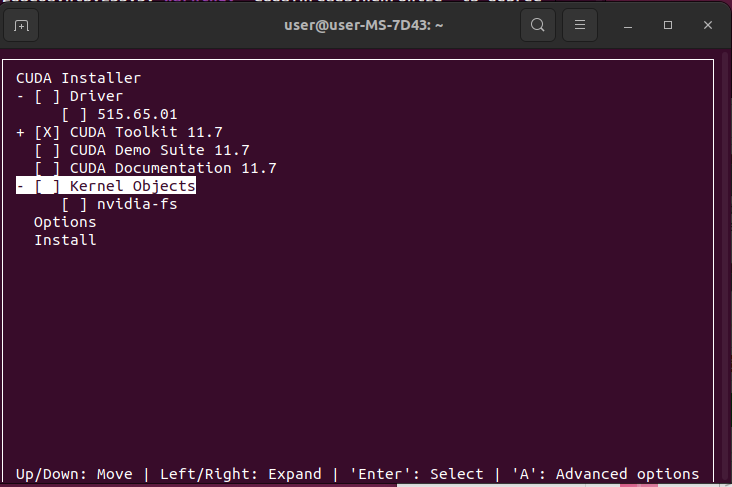
Переходим на сайт NVidia (https://developer.nvidia.com/cuda-downloads) и скачиваем последнюю версию CUDA Toolkit для необходимой платформы. На скриншоте ниже представлена минимально необходимая конфигурация для компиляции и запуска платформы CUDA на ОС Windows.
Минимально необходимая конфигурация установки

2. Установка ROCm на ОС Linux
Рассмотрим ход установки ROCm на ОС Ubuntu 22.04. (https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.3/page/How_to_Install_ROCm.html - на данном веб-сайте перечислены способы установки для некоторых других дистрибутивов Linux)
2.1 Загружаем пакет установщика и устанавливаем его.
sudo apt-get update
wget https://repo.radeon.com/amdgpu-install/5.3/ubuntu/jammy/amdgpu-install_5.3.50300-1_all.deb
sudo apt-get install ./amdgpu-install_5.3.50300-1_all.deb2.2 Установка необходимых компонентов ROCm
sudo amdgpu-install --usecase=dkms,rocm,rocmdevtools,lrt,hip,hiplibsdk,mllib,mlsdkВ процессе установки могут появиться ошибки, однако они никак не должны повлиять на работу платформы. На самом деле я на 100% не уверен, что это минимально необходимый набор модулей для установки, но путем проб и ошибок я пришел именно к этому набору.
2.3 Установка CUDA.
Для портирования кода CUDA на ROCm также необходимо установить CUDA Toolkit. Проще всего это сделать следующей командой. (Другие версии CUDA и методы установки можно найти на данной веб-странице https://developer.nvidia.com/cuda-downloads)
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.runКонфигурация установки CUDA
3. Компиляция исходного кода на ОС Windows
В качестве тестового примера возьмем код перемножения матриц случайных целых 32-битных чисел с Github (https://github.com/lzhengchun/matrix-cuda).
С помощью команд PowerShell представленных ниже скачиваем и компилируем исходные файлы. После выполнения приведенных ниже команд в директории с исходным кодом появится исполняемый файл "a.exe".
git clone https://github.com/lzhengchun/matrix-cuda
cd matrix-cuda
nvcc ./matrix_cuda.cu4. Преобразование кода CUDA в код ROCm и его компиляция на ОС Ubuntu
Преобразование кода CUDA в ROCm выполняется при помощи утилиты платформы ROCm HIPIFY(от HIP - язык программирования платформы ROCm)
git clone https://github.com/lzhengchun/matrix-cuda
cd matrix-cuda
/opt/rocm-5.3.0/bin/hipify-clang matrix_cuda.cuПосле выполнения данных команд в директории рядом с файлом matrix_cuda.cu появится файл matrix_cuda.cu.hip, который является файлом исходного кода для платформы ROCm.
Компиляция кода для платформы ROCm выполняется при помощи компилятора HIPCC. После выполнения приведенных ниже команд в директории с исходным кодом появится исполняемый файл "a.out".
/opt/rocm-5.3.0/bin/hipсс matrix_cuda.cu.hip5. Сравнение производительности платформ
Размер матриц |
Время выполнения CUDA |
Время выполнения ROCm |
1000x1000 |
2.536 мс |
5.812 мс |
10000x10000 |
195.123 мс |
297.219 мс |
В данном примере мы видим, что из-за особенностей архитектуры AMD (меньшее количество блоков для операций над 32-битными числами) наблюдается отставание в производительности в полтора-два раза.
Преобразуем исходные файлы для произведения операций над 16-битными числами и снова протестируем производительность платформ.
Размер матриц |
Время выполнения CUDA |
Время выполнения ROCm |
1000x1000 |
0.83256 мс |
1.421 мс |
10000x10000 |
153.241699 |
16.105 мс |
20000x20000 |
256.836761 мс |
52.155 мс |
В случае с операциями на 16-битными числами преимущество в скорости вычислений на стороне платформы ROCm.
6. Заключение
Таким образом у владельцев видеоускорителей AMD Radeon последнего поколения имеется возможность за пару кликов преобразовать код CUDA в код, который будет также быстро работать на "красных" видеокартах.
P.S.
Это моя первая статья на habr. Решил написать, так как очень долго сам провозился с настройкой всего этого дела. Может быть кто-то с её помощью сэкономит своё время.
Комментарии (15)

zzyxy
25.11.2022 23:36+1Непонятно, что автор хотел показать.
По части компилирования для AMD, HIP и CUDA в clang (а именно его использует AMD в последних версиях) используют один и тот же front-end, с незначительными изменениями имен макросов и функций рантайма. Так что портирование действительно относительно просто.
Но есть нюанс.
Переносимый код != переносимая производительность. Код быстро раборающий на NVIDIA не обязательно будет оптимальным для совершенно другой архитектуры. Особенно такой код, как умножение матриц, где авторы изощряются в использовании всех мелочей архитектуры.
Так что сравнение вышло яблок с апельсинами.

Evengard
26.11.2022 00:02+16Тем не менее, много есть решений построенных именно на CUDA. Возможность их запустить на amd железе - полезно хотя бы для опробования самой технологии. При необходимости оптимизировать можно на следующем этапе, поначалу же надо понять нужно ли оно вообще.
zzyxy
27.11.2022 01:20Я собственно, с "попробовать" как раз согласился.
за пару кликов преобразовать код CUDA в код, который будет также быстро работать на "красных" видеокартах.
Это вот эта часть и ее обоснование выглядят несколько оптимистично.

yamifa_1234
26.11.2022 00:20+1В целом производительность видеокарт одинаковая, но напрягает что разные сборки пк. Но в лбом случае есть над чем задуматься. а еще нужны различны тесты с одинаковыми исходными параметрами. Не только перемножение матриц но допустим нахождение определителя матриц или вычитание и сложение....

Daddy_Cool
26.11.2022 00:41+7Очень интересно и спасибо автору за статью!
Я вообще не понимал, что у АМД происходит.
Все научные вычисления делаются на Куде, либо на OpenCL, второго на два порядка меньше.
Nvidia проводит какие-то семинары, популяризирует Куду, а со стороны АМД - тишина.
Тем не менее вопрос - а что у АМД с двойной точностью? Для научных расчетов это важно.
Ktator
26.11.2022 02:00+4Тем не менее вопрос - а что у АМД с двойной точностью? Для научных расчетов это важно.
Она гораздо лучше, чем у Nvidia. У Nvidia в 64 раза медленнее 32-битных, а у AMD всего в 16. Я, как раз недавно для доклада на PiterPy делал таблицу сравнения производительности. AMD 6960XT в fp64 чуть быстрее Nvidia 4090.

Я вообще не понимал, что у АМД происходит.
Ходят слухи, что ROCm делался для единственного заказчика (см. суперкомпьютер El Capitan). Тогда понятно, почему нет винды, почему забили болт на поддержку RDNA 1 (карты 5000 серии) и т. д.

Melirius
26.11.2022 04:21+3Винда уже: OpenCL рантайм виндошный перешёл на ROCm на новых картах.
Ktator
26.11.2022 19:07Винда ещё нет: https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.3.3/page/Introduction_to_ROCm_Installation_Guide_for_Linux.html#d5494e830
Никакой rocBLAS или другие библиотеки не поддерживают винду.Но ABI ядер на RDNA действительно такое же, как у ROCm.

AndrewSu
26.11.2022 11:35+1Так вы сравнивали с игровыми видеокартами. Для двойной точности у NVidia смотрите ускорители серии Tesla.
Ktator
26.11.2022 14:00+2Только она стоит как самолёт.
zzyxy
27.11.2022 01:39Так и считают на fp64 в основном как раз всякие физические модели. Те-же самолеты, ядренные бомбы и погоду. Для Machine Learning fp32 обычно более чем достаточно, bf16 - примерно оптимально, fp16 чуть хуже и тут часто не-Tesla GPU могут выигрывать.
NVIDIA сегментирует свой рынок весьма эффективно (или агрессивно?). Те-же Quadro и Titan карточки тоже стоят существенно дороже просто потому, что их покупатели готовы платить, даже когда железо практически то же, что и в игровых картах. Ну а за все фичи сразу, просто грех денег не взять. :-)

Ktator
26.11.2022 01:55+14Сравнение производительности платформ
Скажите, пожалуйста, на Nvidia использовались тензорные ядра или нет?
UPD: посмотрел в код, тензорных ядер нет, вопрос снят.Почему бы при сравнении платформ не указать сначала заявленную производительность вычислительных ядер GPU и памяти?
Nvidia RTX 3070: fp32: 20.31 TFLOPS fp16: 20.31 TFLOPS (1:1) fp64: 317.4 GFLOPS (1:64) Memory Bandwidth 448.0 GB/s.
AMD RX 6800XT: fp 32: 20.74 TFLOPS fp16: 41.47 TFLOPS (2:1) fp64: 1,296 GFLOPS (1:16) Memory Bandwidth 512.0 GB/s.
А ещё было бы хорошо в профайлере посмотреть, во что упирается производительность: в память или вычислительные блоки хотя бы на Nvidia (а то на AMD ужасный профайлер).
В данном примере мы видим, что из-за особенностей архитектуры AMD (меньшее количество блоков для операций над 32-битными числами)
Тем не менее, fp32 на обеих картах заявлено около 20 TFLOPS (см. techpowerup). Я полагаю, что у этого ядра на ROCm проблемы с оптимизацией.
В случае с операциями на 16-битными числами преимущество в скорости вычислений на стороне платформы ROCm.
У видеокарты 6800XT fp16 в два раза быстрее, чем на 3070. Но результат очень странный. Почему у AMD при размере матриц в сто раз больше время работы стало выше всего в десть раз? Было бы интересно поисследовать этот момент.
Это моя первая статья на habr.
Пишите ещё! Если добавить информации в сравнение, получится вообще отличная статья.
Sergey-S-Kovalev
Я правильно понимаю, что в взяли серверную платформу на серверных процах с десктопной вендой и картой nvidia, и сравнили в компьютером на убунте и проц которого наиболее эффективен с двумя каналами памяти, при том что у вас один модуль всего, и видеокартой амд?
Вас ничего не смущает? Например совершенно зазря потраченное время? Вы ничего не сравнили совершенно. Тест бесполезен чуть больше чем полностью.
vasyash Автор
Посмотрите внимательно исходный файл. Там учитывается время затраченное именно на вычисления, без пересылки данных. Эффективность ОЗУ как и процессора здесь роли практически не играет. Версия PCI-E на обеих системах одинаковая.
В плане ОС. Единственное на что она не существенно влияет, это время пересылки данных в GPU. Но это время опять же не учитывалось.