
Привет!
Если вы писали бенчмарки и пытались понять, что там ускорилось и на сколько, то наверняка вы пользовались утилитами вроде benchstat.
Мне очень нравится эта утилита, но временами я понимаю, что некоторые её особенности работают против меня. Сегодня я расскажу вам о своей обёртке над benchstat, которая добавляет улучшения, полезные в моей работе.

Точка старта, обычный benchstat
Если у вас ещё не установлен benchstat, стоит это исправить:
$ go install golang.org/x/perf/cmd/benchstatНапомню, что синопсис следующий:
benchstat [options] old.txt [new.txt] [more.txt ...]Мне не хочется придумывать бенчмарки и вымышленный код, который мы героически принялись бы ускорять, поэтому я возьму сэмплы, собранные при анализе производительности одного из моих проектов. Есть два набора сэмплов — старые (old.txt) и новые (new.txt). То есть до и после оптимизации. Бенчмарки идентичные.
Если мы запустим benchstat на них, то получим примерно такую картину:
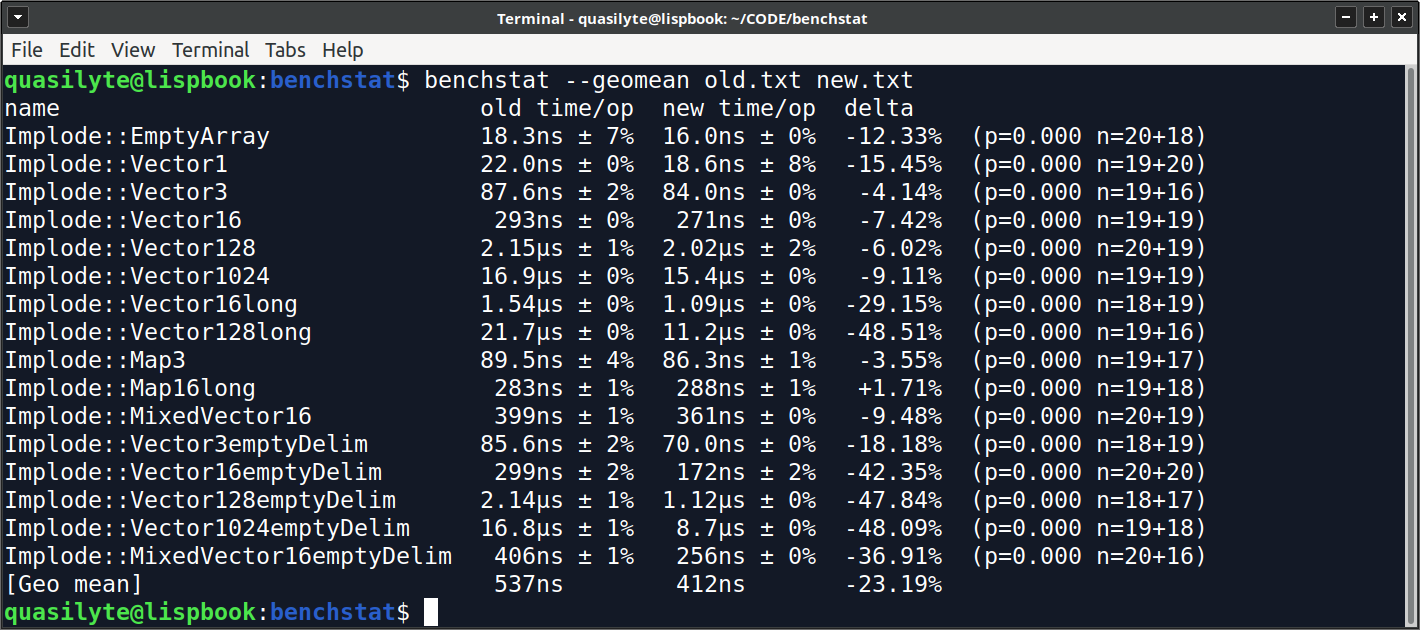
Я специально использую скриншоты, ведь в данной статье презентация результатов имеет ключевое значение.
Удобно? Информативно? Лучше, чем ничего, но приходится всматриваться в числа и пытаться понять, есть ли смысл собирать новые данные, настраивать машину для уменьшения шума и так далее.
Шаг первый: добавляем цвета
Я не очень люблю цветной вывод команд. С цветами очень легко переборщить. Я считаю, что если у утилиты есть цветной вывод, то хорошей практикой является флаг --no-color или что-то в этом стиле, чтобы было легко получить обычный plain text вывод без ANSI-последовательностей.
Тем не менее, это тот самый случай, когда цвета могут быть полезны.
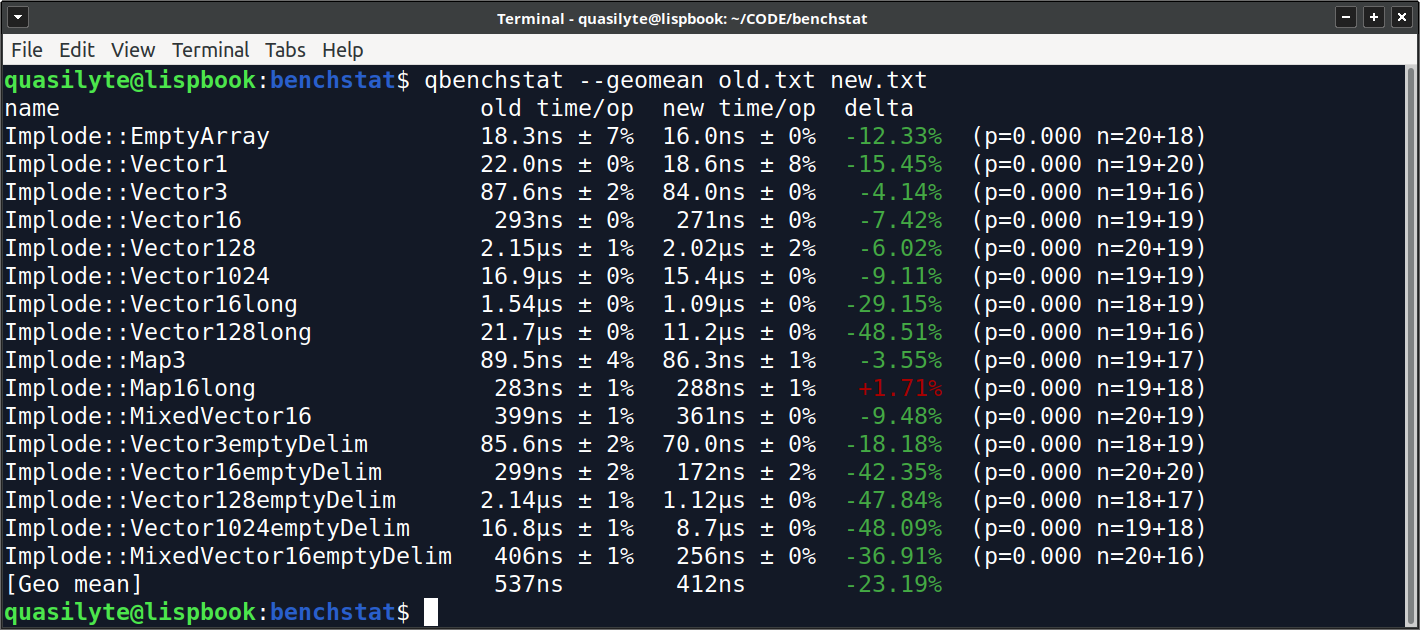
Теперь есть какие-то индикаторы, которые привлекают взгляд.
Чаще всего мы хотим не только сами посмотреть на эти завораживающие циферки, но и показать их нашем коллегам и друзьям (мои друзья часто получают от меня скриншот очередного benchstat результата, так что они уже даже не удивляются). Не каждый человек захочет тратить время на то, чтобы разобраться в данных, выдываемых benchstat по умолчанию. Цвета помогают людям, которые не использовали benchstat сами, проще догадаться какие результаты хорошие, а какие — отрицательно хорошие.
Шаг второй: убираем недостоверные результаты
Приятно, конечно, видеть больше зелёного текста, но нам стоит сохранять объективность. Обратите внимание на выделенные строки:

Implode::EmptyArray 18.3ns ± 7% 16.0ns ± 0% -12.33% (p=0.000)
Implode::Vector1 22.0ns ± 0% 18.6ns ± 8% -15.45% (p=0.000)Если верить машине, то это ускорение на 12-15%, ещё и p=0, что должно было означать значимость изменения.
Прошу не торопиться с выводами. Здесь стоит обратить внимание на две вещи:
- Значения времени исполнения очень низкие (порядка 20 наносек).
- Разброс значений не пару-тройку, а в целых 7-8 процентов.
Оба пункта связаны с тем, что сложно измерить столь малые значения и сравнить их. Различия в пару наносекунд дают разницу в 10%+ времени исполнения! Аналогично с разбросом значений, 1-2ns разброса на среднестатистической машине — это неплохой результат, но он же будет равен отклонению от медианы на несколько процентов.
Что же можно с этим делать? Вот моё мнение: нужно считать эти результаты нестабильными и не выводить их как ускорение (или замедление). Автоматизировать это можно следующим образом: разница в метрике должна вдвое превышать суммарный разброс обеих измерений. То есть:
(7 + 0) * 2 = 14; abs(-12.33) < 14 ==> не засчитываем
(0 + 8) * 2 = 16; abs(-15.45) < 16 ==> не засчитываемЭто, конечно же, существенная лавка гробовщика, но она позволяет во многих случаях отбросить вот такие нестабильные результаты. Если хочется доказать ускорение или замедление такого ювелирного бенчмарка, то надо или лучше настроить окружение и снизить разброс показаний, либо получить более высокое по модулю значение изменения. Например, ускорение на 30% уже было бы чем-то более стабильным.

Шаг третий: выпрямляем geomean
Не всегда geomean имеет смысл. А иногда он и вовсе вреден. По крайней мере, в стандартной реализации benchstat. Вот здесь мне нужно будет написать небольшой бенчмарк и показать вам фокус собственноручно.
package main
import (
"bytes"
"strings"
"testing"
)
//go:noinline
func example1(x, y string) bool {
return strings.ToLower(x) != strings.ToLower(y)
}
//go:noinline
func example2(s string) []byte {
return bytes.TrimSpace([]byte(s))
}
func BenchmarkExample1(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = example1("Hello", "HellO")
}
}
func BenchmarkExample2(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = example2(" hello world ")
}
}Соберём семплы. Меня в данном случае интересуют только аллокации.
$ go test --count 10 -bench=. -benchmem . | tee old.txtВнесём некоторые изменения в код.
//go:noinline
func example1(x, y string) bool {
return strings.EqualFold(x, y)
}
//go:noinline
func example2(s string) []byte {
return []byte(strings.TrimSpace(s))
}Соберём второй набор метрик.
$ go test --count 10 -bench=. -benchmem . | tee new.txtСравним результаты (я удалил cpu метрики из вывода):
$ benchstat old.txt new.txt
name old alloc/op new alloc/op delta
Example1-8 10.0B ± 0% 0.0B -100.00%
Example2-8 24.0B ± 0% 16.0B ± 0% -33.33%
name old allocs/op new allocs/op delta
Example1-8 2.00 ± 0% 0.00 -100.00%
Example2-8 1.00 ± 0% 1.00 ± 0% ~ Всё выглядит логично и понятно. А если добавим geomean?
$ benchstat old.txt new.txt
name old alloc/op new alloc/op delta
Example1-8 10.0B ± 0% 0.0B -100.00%
Example2-8 24.0B ± 0% 16.0B ± 0% -33.33%
[Geo mean] 15.5B 16.0B +3.28% # <---- triggered
name old allocs/op new allocs/op delta
Example1-8 2.00 ± 0% 0.00 -100.00%
Example2-8 1.00 ± 0% 1.00 ± 0% ~
[Geo mean] 1.41 1.00 -29.29% # <---- O_oТо есть, geomean утверждает, что стало хуже?
Знаете, вот в этом случае нам легко заметить что-то подозрительное. Но обычно бенчмарков много, десятки или сотни. Смотреть каждый результат глазами и перепроверять geomean совсем не хочется. Многие наверняка вообще относятся к этому значению как к вердикту.
Но любой нолик в столбике данных портит эту статистику.
Мой доработанный benchstat просто не показывает geomean, если в столбике есть нулевое значение:
$ qbenchstat -geomean old.txt new.txt
name old alloc/op new alloc/op delta
Example1-8 10.0B ± 0% 0.0B -100.00%
Example2-8 24.0B ± 0% 16.0B ± 0% -33.33%
name old allocs/op new allocs/op delta
Example1-8 2.00 ± 0% 0.00 -100.00%
Example2-8 1.00 ± 0% 1.00 ± 0% ~Не смотря на то, что мы просим показать нам geomean, он показан не будет. Скрывается он только для тех метрик, где встречаются нули. Чаще всего, это аллокации, так как время исполнения стремится к нулю разве что асимптотически, в наших самых смелых фантазиях.
Выводы
Думаю никто не будет говорить, что можно доверять утверждениям об ускорении или замедлении без бенчмарка с приложенным к нему benchstat-листингом. К сожалению, benchstat — это ещё не решение всех проблем. Трудности сбора правильных сэмплов всё ещё остаётся. Писать корректные бенчмарки тоже не так легко.
Мой qbenchstat решает лишь несколько из проблем, с которыми я чаще всего сталкивался. Сама идея улучшенного benchstat пошла из проекта ktest, которые реализует фреймворк бенчмарков для KPHP.
Установить qbenchstat можно так:
$ go install github.com/quasilyte/qbenchstat/cmdЕсли у вас есть идеи как ещё можно улучшить эту утилиту — создавайте тикеты, высылайте пулл-реквесты.