
Привет, Хабр! На связи Денис Киров, руководитель отдела тестирования компании «Цифровые Технологии» — мы отвечаем за качество продуктов Единой информационной системы жилищного строительства (ЕИСЖС), занимаемся функциональным тестированием, автоматизацией функционального тестирования и тестированием производительности информационных систем.
В современном конкурентном мире компании, разрабатывающие программные продукты, активно работают над повышением качества и стабильности работы информационных систем. Эта статья посвящена одному из вариантов контроля качества производительности информационных систем — мониторингу APDEX. Его основная цель — получение реальных данных о быстродействии системы глазами пользователя. Мы расскажем о методологии внедрения механизма мониторинга для портала наш.дом.рф.
Что такое APDEX?
Apdex (Application Performance Index) — индекс производительности приложений. Это открытый международный стандарт, разработанный с целью формирования объективной оценки показателей производительности корпоративных информационных систем. Индекс используется для измерения пользовательской удовлетворенности работой системы. Формулу расчета и интерпретацию результата мы распишем в другой части статьи.
Вводные
Однажды я наткнулся на статью на Хабре, в которой описывался мониторинг операций в 1С и дальнейшая интерпретация результатов при помощи расчета индекса APDEX. Замеры операций производились «из коробки» 1С. На этой основе возникла идея, сделать что-то подобное и для продуктов ДОМ.РФ силами отдела тестирования.
Задачу сформулировали так: настроить мониторинг производительности системы, чтобы можно было оценить текущее состояние и посмотреть, что было раньше. И чтобы это было удобно, доступно и понятно. Мониторить нужно два контура: препрод и прод.
Профиты, которые мы хотим получить:
Дополнительная метрика, которую можно анализировать и использовать в SLA, а также для отчетов бизнесу и руководству;
Возможность отслеживать теоретическую деградацию производительности в режиме 24/7, искать корреляции с поставками изменений на стенд или инфраструктурой;
Дополнение к эксплуатационному мониторингу недоступности модулей.
План работ:
Продумать технологический стек реализации задачи, понять и спроектировать процесс;
Проработать, что мы будем мониторить и согласовать выбранные метрики и показатели;
Запустить пилотный проект и отладить процесс.
Варианты реализации:
Мониторинг на основе логов из ELK. У нас реализовано единое хранилище логов при помощи ELK Stack, работающее по схеме, изображенной на рисунке 1.

Рисунок 1. Единое хранилище логов
Этот вариант показался очень интересным, но возникло несколько нюансов.
Первая проблема: логирование под задачу необходимо дорабатывать, а сделать это самостоятельно показалось невозможным, так как доступа к настройке продуктового Logstash у сотрудников отдела тестирования нет, пришлось бы привлекать смежные отделы, а для пилотного проекта это делать не хотелось.
Вторая проблема: на препрод-контуре не всегда есть пользователи, поэтому пришлось бы эмулировать нагрузку на систему, чтобы не было пробелов в мониторинге.
Ввиду этого вариант мы положили в пул задач «to be» и реализуем в будущем.
Анализ по “Яндекс.Метрике” и аналитике от Гугл. Вариант похож на первый и обладает схожими проблемами, например, отсутствием подключенных метрик на препрод-контуре, поэтому такое решение посчитали нецелесообразным.
Реализация «робота», который будет делать замеры с определенной интенсивностью по пользовательским сценариям. Такое решение показалось самым быстрореализуемым и интересным, каких-либо трудностей и нюансов мы не увидели, поэтому решили пойти по этому пути.
Проектирование технологического стека
Мы решили максимально переиспользовать то, что у нас есть и применяется для задач АФТ и нагрузочного тестирования.
Поскольку мы хотели измерять производительность «глазами пользователя», то было принято решение взаимодействовать с продуктом через UI-интерфейс (браузер). Полученные замеры необходимо где-то хранить, для этого отлично подходит time series DB - Influx, у нас она используется для хранения инфраструктурных метрик мониторинга, а также результатов нагрузочных тестов (так как Jmeter "из коробки" хорошо дружит с InfluxDB), а хотелось все хранить в одном месте.
Чтобы запускать роботов изолированно друг от друга в docker-контейнерах и легко масштабировать их количество, было принято решение использовать Selenoid. А для визуализации данных и построения аналитического дашборда — всем известный и очень удобный инструмент Grafana.
В итоге получился следующий технологический стек:
Фреймворк с роботом для замеров на Java 11 + TestNG + Selenide
Selenoid — для контейнерезированного запуска роботов
Хранилище данных — InfluxDB
Telegraf коллекторы на ВМ с продуктом
Grafana — для визуализации данных и дашбордов
Схема технологического стека изображена на рисунке 2.

Рисунок 2. Технологический стек мониторинга
Проработка метрик мониторинга и согласование
После того, как технологический стек реализации был определен, все настроено и ядро фреймворка написано, нас ожидал следующий пункт — выбор метрик мониторинга, их согласование и проработка методики расчета индекса APDEX и его корректной интерпретации.
Первое, что мы сделали — описали базовую методику на внутрикорпоративном Confluence (рисунок 3).

Рисунок 3. Описание методики
Формула расчета индекса была взята стандартная:

Интерпретация полученных результатов также стандартная:
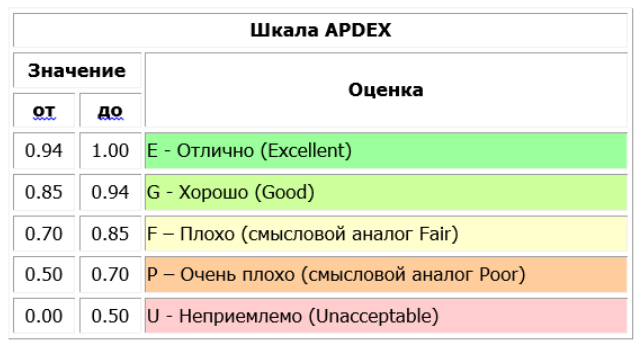
Пояснения по формуле:
Кол-во операций в зоне “довольны” — это то время выполнения, при котором пользователь думает “О, все летает, классный сервис”;
Кол-во операций в зоне “удовлетворены” — это то время выполнения, при котором пользователь думает “Сервис, конечно, не летает, но в целом пойдет”;
Все, что дольше, чем зона “удовлетворены” — потенциальный негатив пользователя по производительности продукта, отказы и т.д.
После того, как мы определились с методикой, начали составление метрик мониторинга для портала наш.дом.рф, а также описали все на Confluence (рисунок 4) и пошли согласовывать метрики с проектным менеджером.
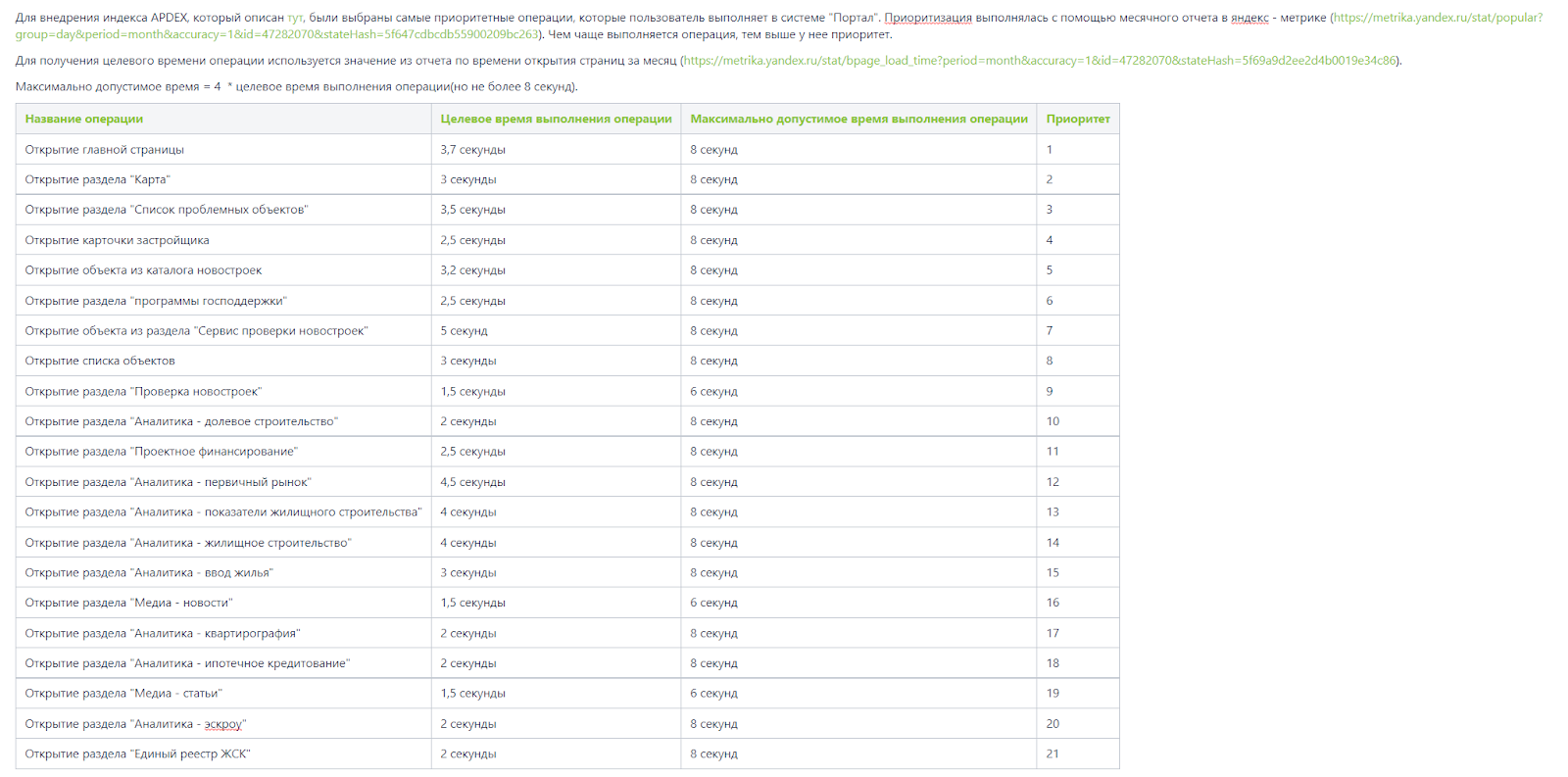
Рисунок 4. Согласованные операции для мониторинга продукта
Чтобы приоритизировать пользовательские операции, мы пошли на сервис “Яндекс.Метрика” и проанализировали статистику в разрезе месяца. Чем чаще выполняется операция, тем выше у нее приоритет.
Также мы определили целевое время выполнения операции (зона “довольны” при расчете индекса) и максимально допустимое время выполнения (зона “удовлетворены”).
Реализация мониторинга и запуск пилотного проекта
После реализации сценариев и отладки мы выбрали интервал запуска — 1 раз в 10 минут, закинули в cron запуск робота и стали собирать первую статистику.
Пока статистика накапливалась в хранилище данных, мы стали собирать аналитический дашборд, чтобы все полученные данные структурировать и обработать.
Пример полученного дашборда на рисунке 5:

Рисунок 5. Пример собранного дашборда
Здесь первый элемент — таблица с основными данными:
Название операции
Приоритет
Т(с) - согласованное граничное максимальное время из интервала “довольны”
N - общее кол-во операций за выбранный временной диапазон
NS - кол-во операций из зоны “довольны”
NT - кол-во операций из зоны “удовлетворены”
NB - кол-во операций из зоны “недопустимо”

Рисунок 6. Общая таблица с результатами
На остальных двух элементах выводится количественный расчет индекса и оценка показателя, в соответствии с методикой (рисунок 7).

Рисунок 7. Расчет индекса и оценка
Выводятся данные при помощи запроса к БД InfluxDB (рисунок 8). Выборка данных ограничивается выбранным временным диапазоном в Grafana.

Рисунок 8. Запрос для вывода информации в таблицу
Сам расчет индекса происходит также в Grafana на лету за выбранный временной интервал по формуле (рисунок 9).

Рисунок 9. Расчет индекса APDEX в Grafana
Визуализация оценки полученного результата реализована при помощи стандартных средств инструмента Grafana (рисунок 10)

Рисунок 10. Визуализация оценки
Внизу дашборда выведен график, на котором можно посмотреть результаты замеров по каждому из кейсов, что полезно при падении индекса и поиске причин и корреляций (рисунок 11).

Рисунок 11. Результаты замеров
Чаще всего при анализе всплесков мы ищем корреляции с повышенной утилизацией инфраструктуры, которую мы также поставили на мониторинг (рисунок 12).

Рисунок 12. Утилизация ресурсов, выделенных docker-контейнерам приложения
Также при помощи стандартного Alert Manager в Grafana мы настроили уведомления о падении индекса APDEX (за интервал 24 часа) ниже определенного значения в мессенджер Telegram (рисунок 13).

Рисунок 13. Уведомления о падении значения индекса в Telegram
И при отсутствии данных при замере также срабатывает алерт с префиксом [No Data] (рисунок 14).

Рисунок 14. Уведомление об отсутствии данных по замеру
Также в случае отсутствия данных робот присылает скриншот экрана, что позволяет идентифицировать проблему (рисунок 15).

Рисунок 15. Скриншот от робота при отсутствии данных по замеру
Основные проблемы, которые могут возникнуть при использовании индекса APDEX:
Некорректный выбор временного интервала, за который рассчитывается индекс APDEX. Например, при выборе небольшого временного интервала могут быть просадки по индексу, вызванные разовыми выбросами, которые могут быть связаны с различными работами и т.д., что не является критичным, поэтому при конфигурации отчета желательно выбирать временной интервал не менее 12 часов (при интенсивности замеров раз в 15 минут), чтобы индекс показал реалистичную картину;
Некорректный временной интервал расчета индекса, а также граничного значения для отправки алертов. Для настройки алертов по снижению индекса APDEX необходимо аккуратно подойти к выбору граничного значения и временного интервала, за который рассчитывается индекс, чтобы рассылка в эксплуатацию не превратилась в спам и сигнализировала только в случае реальных проблем;
Подготовка тестовых данных для мониторинга. Необходимо аккуратно подойти к подготовке тестовых данных для мониторинга и обеспечить «неприкосновенность» данных;
Отсутствие динамики и корректировок нормативных значений индекса. Мониторинг APDEX может быть настроен на ранних этапах реализации системы, и новая бизнес-логика может “утяжелить” какие-то операции. Необходимо допускать возможность корректировок нормативов индекса, Perfomance Engineer должен постараться проанализировать, как добавление нового тяжелого функционала может повлиять на мониторинг, и, основываясь на результатах проведенного нагрузочного тестирования, скорректировать с бизнесом нормативы, в случае, если оптимизация системы и увеличение ресурсов невозможна.
Вывод
Инструмент оказался достаточно полезным, а реализация его не сильно трудозатратной, поэтому этот пилотный проект мы посчитали успешным и планируем его развивать и расширять, а также можем порекомендовать попробовать внедрить такой мониторинг всем желающим.