
Введение
Столкнулся я как-то с проблемой распознавания упорядоченных последовательностей объектов на мобильных устройствах. Идея использовать YOLO пришла довольно быстро, так как модель хорошо подходила по многим параметрам. Я экспортировал обученную модель и с грустью осознал, что она выдает не прошедшие фильтрацию боксы, классы и скоры, а трудно поддающийся первичному визуальному анализу каскад детекций:

Во всех найденных мной туториалах на разных технологиях и языках предлагалось осуществлять постобработку на девейсе, для чего требовалось реализовать один из очень похожих друг на друга методов, изобилующих лишенными комментариев константами.
И, если с перспективой сортировать результаты на устройстве я в целом смирился, то реализовывать еще и пост-обработку совсем не хотелось. К тому же, если запустить YOLO скажем в Colab, модель выдаст объект класса Detections, содержащую все нужные результаты:
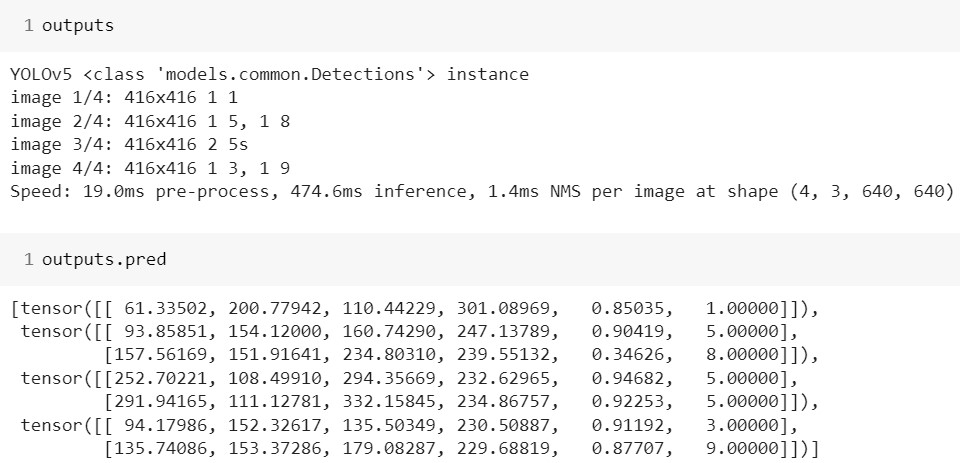
А значит, весь необходимый код уже находится в репозитории, его надо только заставить экспортироваться. Ведь мы же должны предоставлять в продакшн максимально готовую к использованию модель, не так ли?
Найти что-то по данному запросу не удалось. Пришлось разбираться самому. Далее я постараюсь кратко описать возникшие сложности, процесс их решения и получения результата.
Что я буду использовать
Исходный репозиторий модели: YOLOv5 от Ultralytics
Датасет для демонстрации: NUMBERS CV
Библиотека для запуска в приложении:
pytorch_android_lite для Java (соответственно формат экспорта ptl)
Проблемы и решение
Первым делом надо было понять, почему выходы экспортированной модели отличаются, и определить, куда и какие изменения необходимо вносить.
Для этого оказалось достаточным просто сравнить варианты:

Оказывается, DetectionModel является основным пакуемым в экспорт классом. Именно его функция forward вызывается экспортированной моделью, и именно она возвращает результат.
В то же время, просто загруженная из хаба модель возвращает объект Detections, который формируется в классе AutoShape. Думаю, уже многие догадались, что туда пакуются результаты расчетов non_max_suppression.

Однако если просто вызвать в DetectionModel non_max_suppression, реализованный в utils/general.py, то jit.trace выдаст ошибку. Причина кроется в нескольких строчках из этой функции, которые (вызывают у трейсера приступ паники) не получается уложить в скрипт. Чтобы определить, какие именно, пришлось «экспортировать построчно» эту функцию.
Например, уже строчка multi_label &= nc > 1 в самом начале функции, вызывает у трейсера стойкое несварение.
То же самое происходит и с [conf.view(-1) > conf_thres] в строчке x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres].
Я позволю себе воздержаться от подробного описания. Скажу лишь, что пришлось провести определенный рефакторинг и немного переписать функцию под свои нужды. Впрочем, все эти расчеты – лишь подготовка к главному действию. А именно: вызову torchvision.ops.nms, который и производит основную работу.
Забегая вперед, скажу, что с ним еще будут проблемы, т.к. инструкции по обращению к нему не пакуются в финальный скрипт (возможно, удаляются при оптимизации), и библиотеку придется импортировать в приложение.
Еще один важный момент: jit.trace способен экспортировать лишь функции возвращающие тензоры, кортежи тензоров и т.д. это постоянно приходилось учитывать.
Итак
В models/experimental.py я добавил две функции:
Облегченный nms:
def nms_lite(prediction, conf_thres=0.25, iou_thres=0.45, max_det=300, nm=0):
#nm - musk's number
if isinstance(prediction, (list, tuple)): # YOLOv5 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
device = prediction.device
mps = 'mps' in device.type # Apple MPS
if mps: # MPS not fully supported yet, convert tensors to CPU before NMS
prediction = prediction.cpu()
bs = prediction.shape[0] # batch size
nc = prediction.shape[2] - nm - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Checks
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
# Settings
max_wh = 7680 # (pixels) maximum box width and height
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.5 + 0.05 * bs # seconds to quit after
redundant = True # require redundant detections
merge = False # use merge-NMS
mi = 5 + nc # mask start index
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box/Mask
box = xywh2xyxy(x[:, :4]) # center_x, center_y, width, height) to (x1, y1, x2, y2)
mask = x[:, mi:] # zero columns if no masks
conf, j = x[:, 5:mi].max(1, keepdim=True)
x= torch.cat((box, conf, j.float(), mask), 1)
x= x[x[:, 4].argsort(descending=True)]
c = x[:, 5:6] * max_wh
boxes, scores = x[:, :4] + c, x[:, 4]
i = torchvision.ops.nms(boxes, scores, float(iou_thres))
output[xi] = x[i]
if mps:
output[xi] = output[xi].to(device)
return output
сортировщик:
def new_sorter(non_max, theshhold):
sort_result=non_max[non_max[:,0].sort()[1]]
sort_result=sort_result[sort_result[:,4]>theshhold]
sort_result=sort_result[:,5]
return sort_resultРаз уж вносить изменения, то почему бы уж и классы ни упорядочить, заодно оставив только нужное. Функция просто сортирует боксы по оси Х, убирает те предикты, скоры которых не удовлетворяют treshhold и возвращает тензор состоящих из распознанных классов.
Далее в класс DetectionModel в models/yolo.py я добавил:
Флаг: is_export=False
Он будет устанавливаться лишь при экспорте и активировать изменения. Это нужно на тот случай, если понадобится еще раз обучить модель, чтобы изменения не влияли на процесс обучения.
Константу: treshhold=0.8
Детакции ниже будет осекать сортер.
Функцию forward класса DetectionModel я подкорректировал так, чтобы новые значения возвращались только при установке флага is_export=True
if augment and not self.is_export:
return self._forward_augment(x) # augmented inference, None
out=self._forward_once(x, profile, visualize) #base return
if self.is_export: #and not augment
#a=nms_lite(out)[0]
return new_sorter(nms_lite(out)[0], self.treshhold)
else:
return outВ export.py корневой директории модели
Изменил строчку 120 в функции export_torchscript так, чтобы сразу получать файл с нужным мне расширением
с f = file.with_suffix('.torchscript')
на f = file.with_suffix('.torchscript.ptl')
В функции run после model.eval() (строка 541) добавил установку флага:
model.is_export=True
Теперь при экспорте будут применяться внесенные выше корректировки.
Я экспортировал модель, указав нужные настройки: размер изображения (обучающий сет был 416 на 416), размер батча (в приложении я буду подавать по 1 картинке за раз), включил оптимизацию (если этого не сделать, при загрузке модели появится ошибка), и указал формат экспорта.
!python export.py --data NUMBERS-1/data.yaml --weights runs/train/exp/weights/best.pt --imgsz 416 416 --batch-size 1 --optimize --include torchscript Добавил в приложение, запустил LiteModuleLoader.load и получил:
Following ops cannot be found. Please check if the operator library is included in the build. If built with selected ops, check if these ops are in the list. If you are a Meta employee, please see fburl.com/missing_ops for a fix. Or post it in https://discuss.pytorch.org/torchvision::nms ()
Выше я уже говорил об этом. И хотя, в целом, вроде бы, все понятно, найти конкретное решение оказалось не так просто, по-видимому, это не слишком распространенная проблема.
Для ее решения достаточно было добавить в build.gradle
implementation 'org.pytorch:torchvision_ops:0.13.1'
implementation 'com.facebook.soloader:nativeloader:0.8.0'И инициализировать torchvision_ops в соответствующем месте, например, в onCreate в MainActivity
if (!NativeLoader.isInitialized()) {
NativeLoader.init(new SystemDelegate());
}
NativeLoader.loadLibrary("torchvision_ops");Думаю, можно не говорить, что помимо приведения изображения к размеру изображений в тренировочном датасете и конвертации в тензор, никакая другая предобработка для данной модели не требуется. С полученным посредством камеры изображением достаточно сделать следующее:
bitmap = Bitmap.createScaledBitmap(bitmap, 416, 416, true);
final Tensor t = TensorImageUtils.bitmapToFloat32Tensor(bitmap, NO_MEAN_RGB, NO_STD_RGB); где NO_MEAN_RGB, и NO_STD_RGB массивы – заглушки.
Приложение запустилось:

Подробнее с описанным в статье можно ознакомиться по ссылкам:
Отредактированная модель
Ноутбук с обучением и экспортом
Приложение
В силу неопытности мог что-то упустить или неправильно интерпретировать. Невзирая на это, надеюсь, что статья будет кому-то полезна и поможет сэкономить много времени при использовании сети в приложении. Конструктивная критика приветствуется. Приглашаю всех к дискуссии.
Материалы:
Корректировка расширения экспорта, добавление .ptl
Фикс проблем с torchvision_ops (описание и решение на C++)
Фикс проблем с torchvision_ops (Java)
Снова про torchvision_ops (как я понял исходное решение, Java)
Статья про реализацию nms (Python), здесь не использовалась, но может быть полезно.