

Работая с DWH все наверняка задавались хоть раз вопросами:
- «Что будет, если поменять поле в таблице?»
- «На каких ETL процессах это скажется?»
- «Какие отчеты будут затронуты?»
- «Какие бизнес процессы могут пострадать?»
Ответить на этот вопрос как правило непросто, т.к. нужно просмотреть дюжину ETL процессов, потом залезть в BI инструмент, найти нужные отчеты, что-то держать в голове, помнить о том, что что-то там строится ручным кодом и всё это выливается в большую головную боль.
Даже самое порой безобидное изменение может сказаться, например, на отчете, который каждое утро приходит на почту к председателю правления банка. Немного утрирую, конечно:)
Далее в статье я расскажу, как и с помощью чего можно уменьшить головную боль и быстро проводить impact-анализ в инфраструктуре DWH.
DWH в Тинькофф Банке
Прежде чем окунуться в impact-анализ, коротко опишу что из себя представляет наше DWH. По структуре наше хранилище более походит на Corporate Information Factory Билла Инмона. Есть много слоев обработки данных, группы целевых витрин и нормализованная модель представляют презентационный слой хранилища данных. Всё это работает на MPP СУБД Greenplum. ETL процессы построения хранилища разработаны на SAS Data Integration Studio. В качестве платформы отчетности в банке используется SAP Business Object. Перед хранилищем находится ODS, реализованный на СУБД Oracle. Из моей предыдущей статьи про DataLake в Тинькофф Банке известно, что ETL на Hadoop мы строим на Informatica Big Data Edition.
Анализ влияния
Как правило, задача анализа влияния внутри одного enterprise инструмента решается несложно. Все инструменты обладают метаданными и функциональными возможностями работы с этими метаданными, такими как, например, получить список зависимых объектов от выбранного объекта.
Вся сложность анализа влияния возникает тогда, когда процесс выходит за рамки одного инструмента. Например, в DWH окружение состоит из СУБД источников, СУБД DWH, ETL, BI. Здесь что бы уменьшить головную боль, нужно уметь консолидировать метаданные из разных инструментов и строить зависимости между ними. Задача неновая и на рынке существуют промышленные системы для её решения.
Нам важно было, что бы такая система смогла построить для нас всё сложное дерево, а точнее граф наших метаданных, начиная от таблиц Oracle в ODS и заканчивая отчетами в SAP (см. Рис. 1).
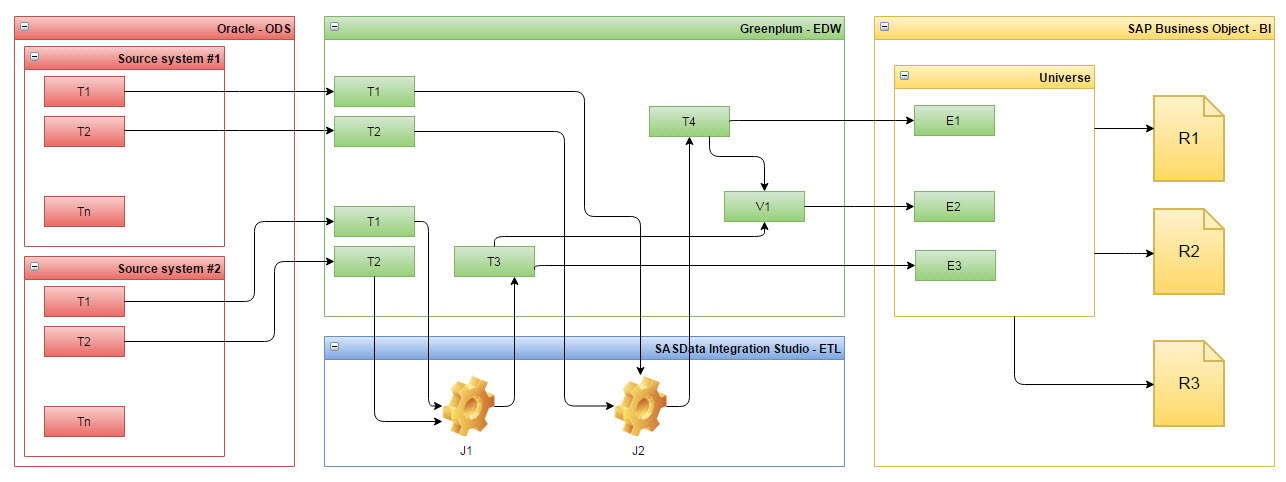
Рис. 1 Пример зависимостей метаданных из нескольких систем, на примере систем в Тинькофф Банке
Система должна была провязать объекты Greenplum между собой, как и через джобы SAS, в которых таблицы Greenplum выступают как источники и приемники данных, так и просто связать таблицы со строящимися на них представлениями.
Мы выбрали Informatica Metadata Manager и успешно внедрили первые модели метаданных у себя, в Тинькофф Банке. Далее в статье я расскажу, как и что мы научились делать при помощи этого инструмента.
Informatica Metadata Manager
Informatica Metadata Manager – это, по сути, большой репозиторий метаданных, который позволяет:
- Моделировать метаданные, т.е. создавать модели метаданных, например, СУБД, ETL инструментов или даже бизнес приложений
- На основе созданных или поставляемых в комплекте моделей создавать процессы загрузки/обновления метаданных у себя в репозитории
- Создавать правила связывания между объектами метаданных как внутри модели, так между моделями
- Создавать связи, которые нельзя подвести под правила, как и внутри модели, так и кроссмодельные
- Работать в визуальном веб-интерфейсе с загруженными метаданными ваших систем
Модели Informatica Metadata Manager
Теперь по порядку и более детально про то, что может инструмент и как готовить Informatica Metadata Manager.
В коробке с Informatica Metadata Manager поставляется некоторый набор моделей, с которыми, если у вас куплена лицензия, можно начинать работать сразу после установки продукта.
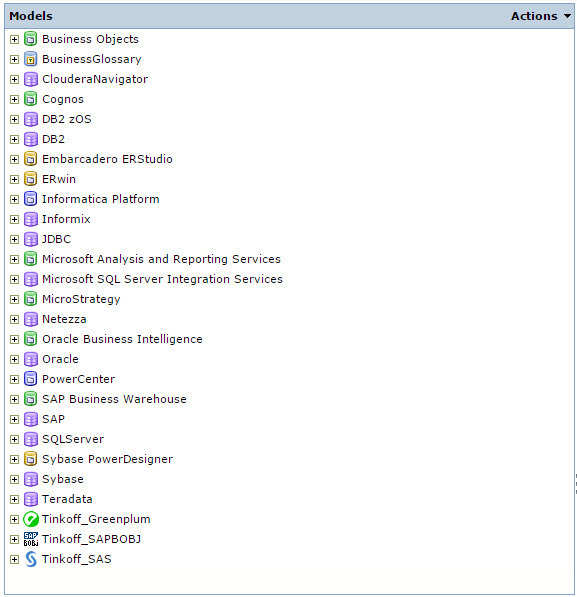
Рис. 2 Модели Informatica Metadata Manager
На Рис. 2 те модели что не начинаются с префикса Tinkoff идут из коробки. Модель в терминах Informatica Metadata Manager – это набор классов, из которых построена определенная иерархия, которая отвечает структуре метаданных источника, т.е. некоторой информационной системы. Например, модель метаданных СУБД Oracle в Informatica Metadata Manager выглядит следующим образом, см. Рис. 3. Думаю, те кто работал с СУБД Oracle в этой иерархии увидят много знакомого, из того с чем привыкли работать.
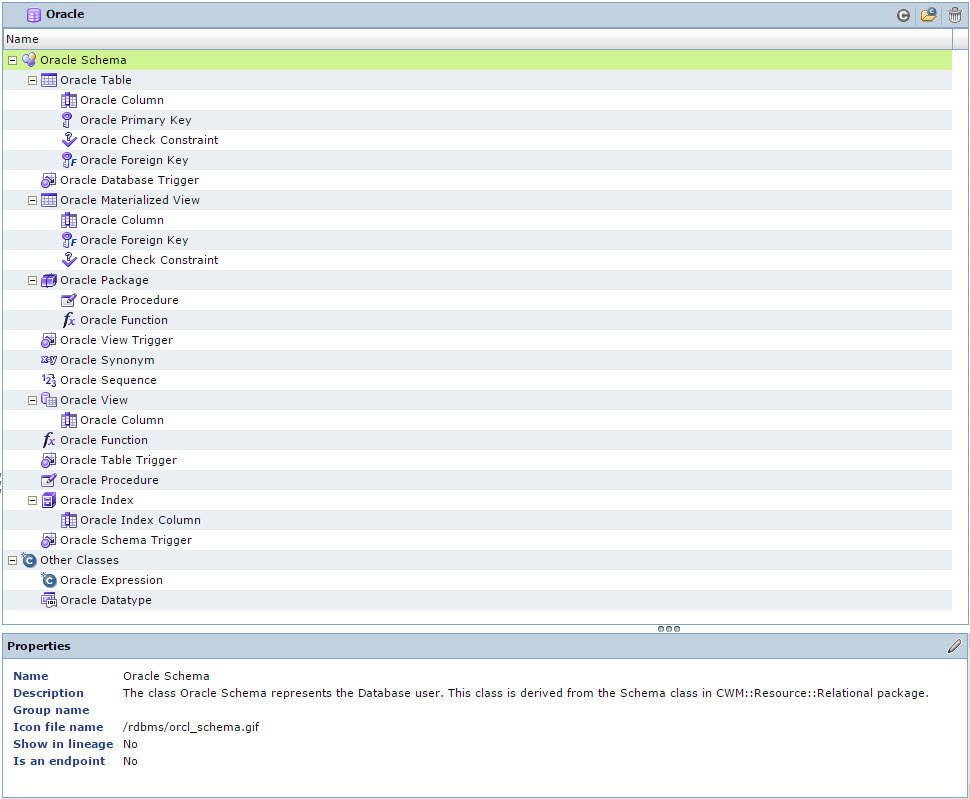
Рис. 3 Модель метаданных СУБД Oracle
Модели метаданных СУБД Greenplum или SAS Data Integration Studio в Informatica Metadata Manager из коробки не предусмотрены и мы сами их спроектировали под наши задачи. Очень важно понимать, какие задача должна решать модель, когда вы начинаете работать с готовой моделью или проектируете свою. У нас получились простые модели (см. Рис. 4 и Рис. 5), но в тоже время эти модели отвечали нашим требованиям. А основное наше требование – это уметь строить lineage от таблиц ODS, которые находятся в Oracle, до отчетов, которые построены на universe-ах в SAP Business Objects.
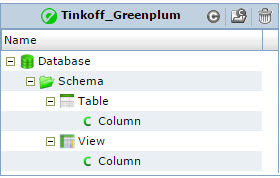
Рис. 4 Модель метаданных СУБД Greenplum
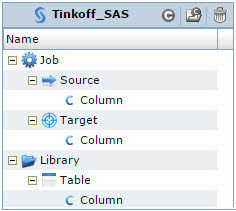
Рис. 5 Модель метаданных SAS Data Integration Studio
Относительно модели метаданных SAP Business Objects возникла дилемма – использовать преднастроенную модель или разработать свою.
Готовая модель, а точнее первый её уровень иерархии выглядит так – см. Рис. 6.
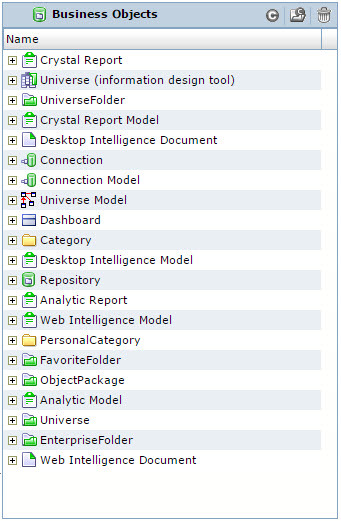
Рис. 6 Преднастроенная модель метаданных Business Objects
Провели сравнение:
| Критерий | Преднастроенная модель | Своя модель |
|---|---|---|
| Полнота модели | Избыточная | Оптимальная |
| Отвечает изначально сформулированным требованиям | Наверное, отвечает | Отвечает |
| Стоимость разработки загрузки/обновления метаданных | Бесплатно | Зависит от сложности модели и от знания структуры метаданных SAP Business Objects |
| Стоимость модели | Стоимость лицензии на metadata exchange options for SAP Business Objects | Бесплатно |
Один критерий не в пользу своей модели был факт сложности структуры метаданных SAP Business Objects. Но, у нас для аудита BI платформы используется сторонний продукт — 360eyes, который мы и взяли за источник метаданных SAP Business Objects для Informatica Metadata Manager. Модель получилось очень простой, см. Рис. 7, которая отвечала нашим сформулированным требованиям.
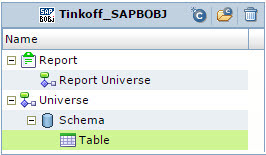
Рис. 7 Модель метаданных SAP Business Objects
Обновление метаданных в Informatica Metadata Manager
Модели созданы, теперь их надо наполнить метаданными. Модели, которые поставляются в коробке с Informatica Metadata Manager имеют свои преднастроенные загрузчики, которые уже знают, как извлечь, например, из словарей СУБД Oracle список таблиц и представлений. Для моделей метаданных, которые вы проектируете сами, загрузчик придется разработать самим. Но пугаться здесь не стоит, процесс довольно прозрачный, и напоминает разработку ETL процедуры по четко сформулированному ТЗ. На основе вами созданной модели Informatica Metadata Manager простой командой поможет вам создать шаблон загрузки и вот у вас готов набор CSV файлов которые надо наполнить метаданными вашей системы. Дальше всё зависит от вас и от того на сколько вы хорошо знаете и умеете работать с метаданными ваших систем. Кстати, процесс получение метаданных из ваших систем это, наверное, один из самых трудоемких шагов в построении всего процесса работы с метаданными в Informatica Metadata Manager.
Мы написали весь необходимый код, который собрал нам из pg_catalog Greenplum, из метаданных SAS и из репозитория 360eyes данные для созданных шаблонов загрузки и запустили регулярный процесс. Для обновления метаданных Oracle, на котором у нас работает ODS, мы использовали преднастроенную модель (см. Рис. 3). Метаданные в Informatica Metadata Manager обновляются каждую ночь.
Правила связывания в Informatica Metadata Manager
Метаданные систем регулярно обновляются в репозитории Informatica Metadata Manager, теперь надо связать объекты метаданных разных систем между собой. Для этого в Informatica Metadata Manager есть возможность написания правил (Rule Set), правила могут работать как внутри модели так и между моделями. Правила из себя представляют XML файл несложной структуры:
<?xml version="1.0" encoding="UTF-8"?>
<ruleSet name ="SAPBOBJ_to_SAPBOBJ_rules">
<sourceResource name="SAPBOBJ"/>
<targetResource name="SAPBOBJ"/>
<rule name="unv_to_rpt_unv" direction="SourceToTarget">
<sourceFilter>
<element class="Universe"/>
</sourceFilter>
<targetFilter>
<element class="Report">
<element class="Report Universe"/>
</element>
</targetFilter>
<link condition="source.Name = target.Name"/>
</rule>
</ruleSet>
Приведенное правильно говорит о том, что нужно построить связь внутри модели SAPBOBJ между объектами класса «Universe» и объектами класса «Report Universe» по условию равенства их наименования.
Бывают ситуации, что объекты метаданных нужно связать между собой, но правило под эту связь разработать не получается. Простой пример: Представление «A» построено на таблице «B» и «С». Для таких ситуаций в Informatica Metadata Manager есть возможность подгружать дополнительные связи, так называемые Enumerated Links. Enumerated Links представляет из себя CSV файл, в котором прописываются полные пути уже в репозитории Informatica Metadata Manager к двум объектам метаданных, которые необходимо связать. При помощи Enumerated Links у нас строится связь между таблицами и представлениями Greenplum.
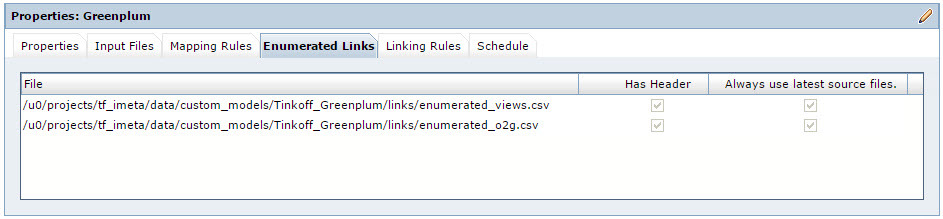
Рис. 8 Свойства Enumerated Links
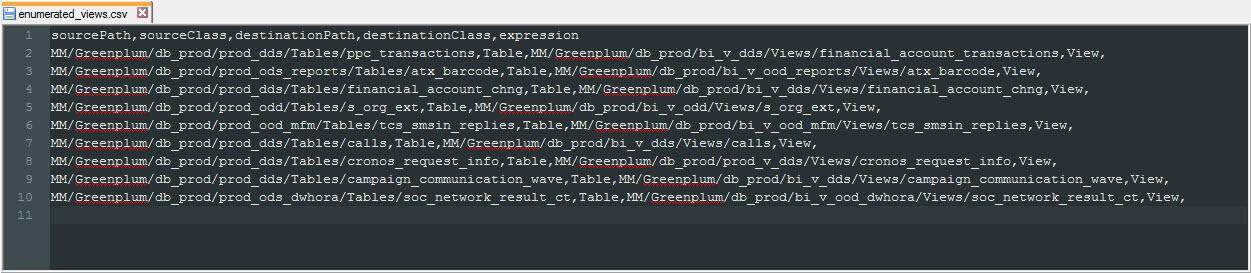
Рис. 9 CSV файл для загрузки Enumerated Links
В данном случаем CSV файл Enumerated Links мы формируем сами также, как и сами метаданные для загрузки, на основе pg_catalog. Через Enumerated Links мы связываем в модели Greenplum объекты класса «Table» с объектами класса «View». Связь формируем через указание полного пути к объекту метаданных уже в репозитории Informatica Metadata Manager.
Анализ влияния в Informatica Metadata Manager
Что мы получили? Основное что мы получили это возможность строить lineage по всем объектам метаданных входящих в инфраструктуру нашего DWH, т.е. производить анализ влияния, по двум направлениями: Impact Upstream и Impact Downstream.
Например, хотим посмотреть, что зависит от таблицы ODS. Находим нужную нам таблицу, или в каталоге моделей, или при помощи поиска и запускаем на этой таблице lineage. Получаем такую красивую картинку, см. Рис. 10. Здесь мы видим, что от выбранной таблицы зависит ряд ETL процессов на SAS-е, а также два Universe-а и семь отчетов в SAP Business Objects.
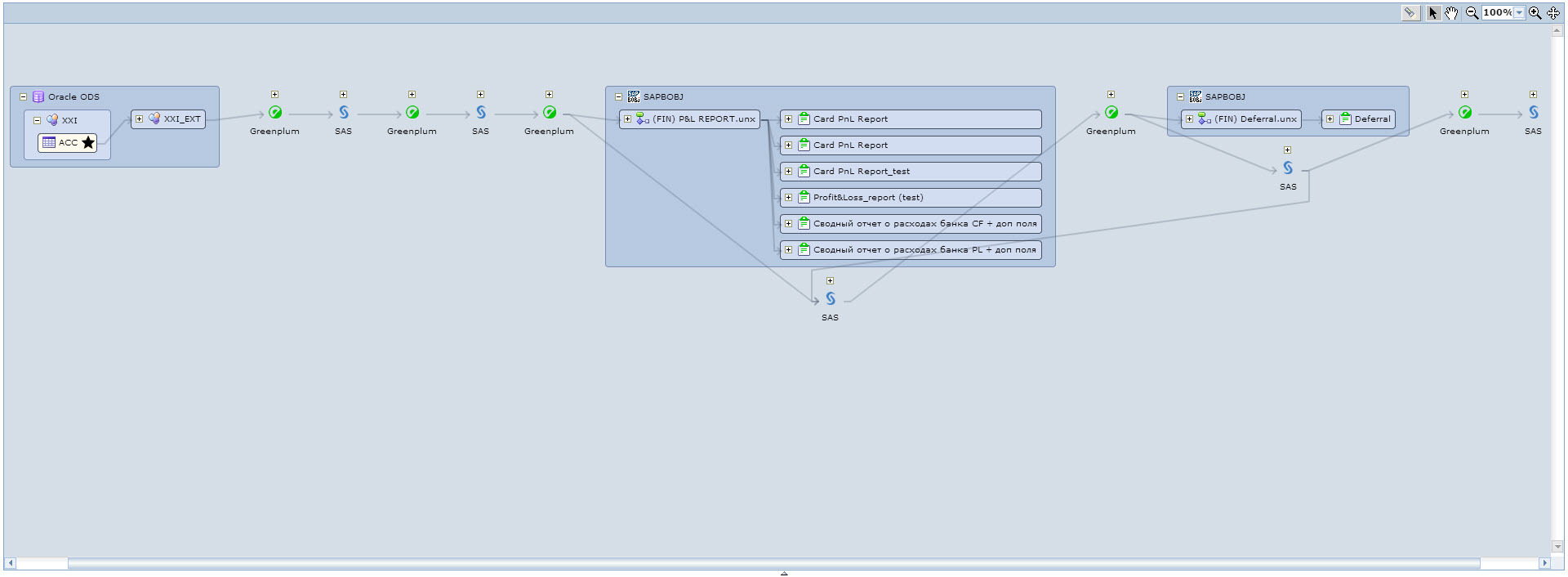
Рис. 10 Lineage от таблицы ODS
В веб-интерфейсе можно раскрыть каждую область полученного lineage и от каждого объекта на диаграмме можно запустить linage прям из этого окна.
Или, например, хотим посмотреть данные каких таблиц участвуют в построении отчета. Находим нужный отчет и запускаем на нём lineage. Получаем следующую красивую картинку, см. Рис. 11. Здесь мы видим, что выбранный отчет строится на одном Universe, который использует таблицы Greenplum из четырех схем, которые в свою очередь наполняются из ODS и некоторыми ETL процессами на SAS.
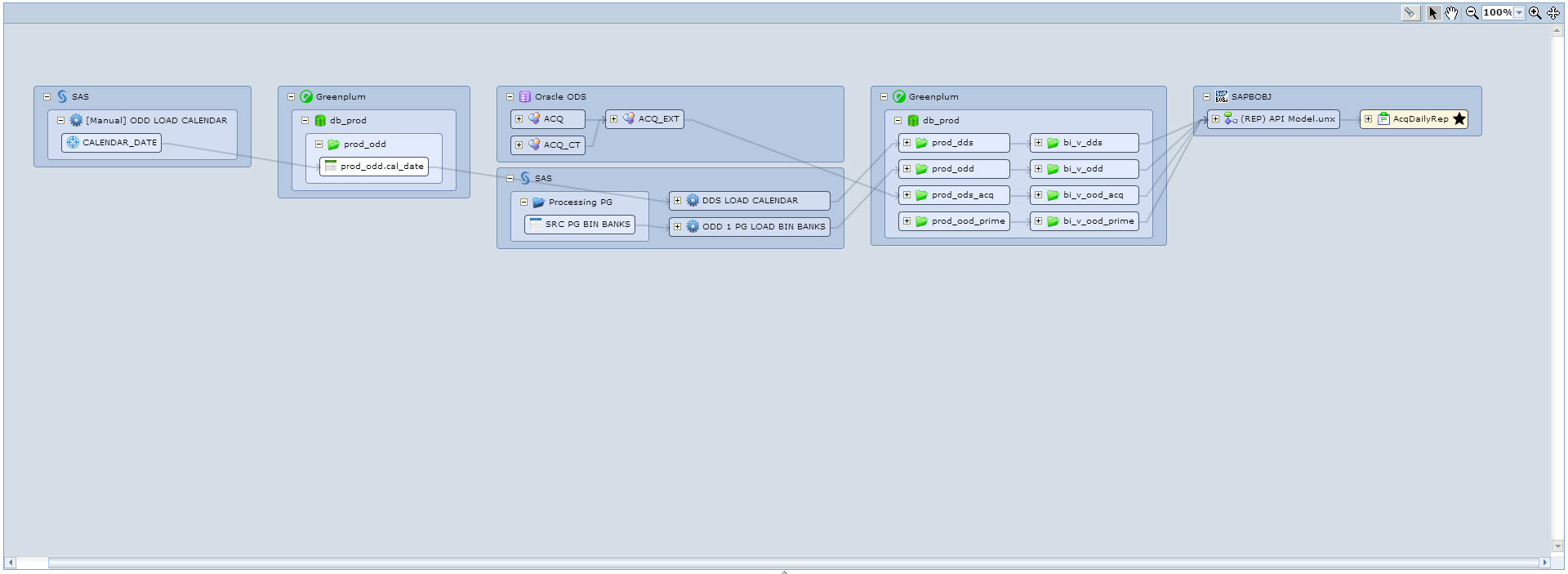
Рис. 11 Lineage от отчета в SAP Business Objects
Каждый результат lineage можно экспортировать в Excel, который в полном объем отражает все зависимости от выбранного объекта метаданных.?
Итоги и планы на будущее
Готовить Informatica Metadata Manager мы научились. Дальше только работать, искать новые варианты его использования, реализовывать новые модели, подключать новых пользователей.
Какие новые модели хотим сделать:
- Банковские системы источники
- Informatica Big Data Edition
- Hadoop (HDFS + Hive)
- Flume
Каких пользователей подключили и планируем подключать:
- Системных аналитиков DWH
- Владельцев банковских систем источников
Развитие моделей:
- Доработать нашу модель SAP Business Objects, добавить такие объекты метаданных, как меры и показатели
Из минусов, с которыми мы столкнулись, это долгое построении полного lineage (>10 минут) на объектах с большим количеством связей (>1000). В целом, Informatica Metadata Manager — очень гибкий, удобный в работе инструмент и, на наш взгляд, хорошо умеет решать свои задачи.
Комментарии (14)


Stas911
10.11.2015 23:14Интересно, спасибо! А кроме lineage он что еще умеет?
Еще вопрос — а reverse engineering оно умеет или все надо ручками?
yuryemeliyanov
11.11.2015 12:36Спасибо. lineage это пожалуй основная его фишка. А что вы в контексте этого инструмента подразумеваете под reverse engineering?
Stas911
12.11.2015 21:38Я имел ввиду, что если есть работающая система с тьмой таблиц, вьюшех, SP и т.д. — этот прибор может построить lineage сам в каком-то виде или все строго ручками?
yuryemeliyanov
12.11.2015 22:45Ну смотрите. Например у вас система построена на Oracle. У вас куча таблиц, представлений и хранимой логики. У вас стоит Informatica Metadata Manager и в нем есть metadata exchange for Oracle. То, для того что-бы настроить процесс выгрузки/загрузки метаданных у вас займет 15-20 минут и linage этот прибор сможет построить сам. А вот если у вас более сложная инфраструктура, то тут ручками надо будет поработать. Но поработать рачками здесь не заключается в том, что бы прописывать все зависимости метаданных между собой, а в том что бы описать модель метаданных и написать некий код наполнения этой модели метаданными.
Stas911
13.11.2015 00:32То есть достаточно, грубо говоря, сказать ему где что искать, а остальное он сам подтянет

aml
11.11.2015 11:37Статья могла бы быть лучше, если была бы дополнена глоссарием — что такое DWH, EBL, BI, SAS и т.д. Гугление даёт слишком много неоднозначных вариантов. В результате, мне например вообще не понятно, какие задачи решаются. Хотя, возможно, статья и рассчитана только на тех, кто знает, что это.
yuryemeliyanov
11.11.2015 12:43Спасибо за комментарий. Согласен с вами, но эта статья в большей части специализирована на конкретную область — интеграция данных. И в этой области все эти аббревиатуры, как правило, на слуху.
А так, да:
DWH — Data Warehouse
EBTL — Extract, Transform, Load
BI — Business intelligence
SAS — SAS
:)
Wadime
Это крайне интересный инструмент!
Рассматривались какие-либо аналоги? Что можете сказать про политику лицензирования?
Wadime
Вдогонку вопрос от коллег — сколько времени заняло построение полной модели? Сколько человек этим занималось?
yuryemeliyanov
Полной модели чего? У нас сейчас построено четыре модели и они связаны между собой. Больше всего времени было потрачено на разработку модели SAS, т.к. сложная система метаданных. А так в среднем на одну модель уходит 2-3 недели. Это разобраться в метаданных истоника, спроектировать модель, ещё раз разобраться в метаданных источника, запрограммировать обновление метаданных, поставить на регламент. Ну или купить metadata exchange настроить регламент, связку с другими моделями. Одномоментно у нас Metadata Mamager занимался один человек. До текущего состояния внедрения мы дошли где то за 2,5-3 месяца.
yuryemeliyanov
Спасибо за комментарий. Аналоги если честно толком не трогали и не тестировали, толки читали. Есть аналоги у IBM и Oracle. По нашему мнению у Oracle ещё сыроватый продукт, а IBM не рассматривали т.к. у нас примерно год назад была закупка Informatica и Informatica Metadata Manager входит в Advanced Edition. Плюс дополнительно можно докупать metadata exchange к различным системам.