

Цепочка методов (или цепочка вызовов, method chaining) - это стиль записи кода, который позволяет выполнять несколько операций за один раз, в конечном счете экономя время и энергию.
Для тех, кто не знаком с этой концепцией, это, по сути, способ применения нескольких методов или функций к данным в одной строке кода. Традиционный подход к использованию pandas предполагает использование отдельных функций и команд по одной за раз. Это может стать довольно утомительным и трудным для запоминания. Кроме того, если что-то пойдет не так, может быть трудно устранить неполадки, поскольку было использовано несколько операций. У меня еще была привычка, прыгать с одной ячейке на другую, вот тогда точно можно не вспомнить, что ты делал и проще переписать все заново.
Метод цепочки поможет устранить эту проблему. Объединяя методы в цепочку, можно легко выполнять несколько операций одновременно. Это сокращает время, затрачиваемое на написание кода, а также облегчает чтение и его отладку.
Метод цепочки имеет несколько преимуществ:
позволяет одновременно манипулировать фреймами данных несколькими способами, что делает его отличным инструментом для решения сложных задач.
значительно упрощает отладку и чтение кода в будущем. Твой будущий Я скажет тебе спасибо!
снижает количество создаваемых переменных до минимума. Больше никаких головных болей про название переменных.
позволяет избежать проблемы SettingWithCopyWarning, которая может возникнуть при попытке изменить копию фрейма данных вместо оригинала.
считается, что цепочка методов более эффективна, чем отдельные шаги, поскольку операции могут выполняться последовательно без создания промежуточных фреймов, которые увеличивают использование памяти pandas.
Этот метод активно продвигает Matt Harrison (гуглится по Idiomatic Pandas, Effective Pandas: Patterns for Data Manipulation, есть интересные выступления на PyData). Так же цепочка методов упоминается в официальном cheetsheet pandas, но как по мне слишком вскользь и в незаметном левом углу, учитывая как этот метод прокачивает читаемость кода:
Важно понимать потенциальные недостатки и проблемам, прежде чем переходить к этому подходу:
наверное такой стиль может не подойти новичкам - хотя процесс объединения операций может показаться простым, но каждая операция изменяет данные, и эти изменения могут быть не совсем понятны пользователю если у него мало практики.
может быть неэффективным в вычислительном отношении. Если для анализа требуется много операций, стоимость их выполнения в рамках одной операции может быть довольно высокой.
Пролог: цепочка вызова методов в ООП
Цепочка вызова методов, является распространенным синтаксисом для вызова нескольких методов в объектно-ориентированных языках программирования. Каждый метод возвращает объект, что позволяет объединять вызовы в единую структуру, не требуя переменных для хранения промежуточных результатов.
это может уменьшить длину всего кода, поскольку не нужно создавать бесчисленное количество переменных.
это может повысить читабельность кода, поскольку методы вызываются последовательно.
Пример на простом классе Cat:
class Cat:
def __init__(self, name=None, breed=None):
self.name = name
self.breed = breed
def set_name(self, name):
self.name = name
def set_breed(self, breed):
self.breed = breed
def __repr__(self, ):
class_name = type(self).__name__
attr = ', '.join([f'{i}={v!r}' for i, v in self.__dict__.items()])
return f"{class_name}({attr})"Т.к. методы у нас не возвращают экземпляр класс (self), то мы последовательно применяем их, чтобы установить кличку и породу:
djon_the_cat = Cat()
djon_the_cat.set_name('Djon')
djon_the_cat.set_breed('Siamse')
>>> Cat(name='Djon', breed='siamse')Но если мы добавим return self в каждый метод, то уже сможем скомбинировать нашего кота в цепочку:
код с добавлением self
class Cat:
def __init__(self,name=None,breed=None):
self.name=name
self.breed=breed
def set_name(self,name):
self.name=name
#добавляем return self
return self
def set_breed(self,breed):
self.breed=breed
#добавляем return self
return self
def __repr__(self,):
class_name=type(self).__name__
attr=', '.join([f'{i}={v!r}' for i,v in self.__dict__.items()])
return f"{class_name}({attr})"djon_the_cat = Cat().set_name('Djon').set_breed('Siamse')
>>> Cat(name='Djon', breed='siamse')Так же и в pandas, наша цель уйти от этого:
df = pd.read_excel('./materials/бурение_2022.xlsm', header=None)
dict_replace_tpp = {'СП "предприятие_1"':"п_1",
'СП "предприятие_2"':"п_2",
'СП "предприятие_3"':"п_3",
'СП "предприятие_3"':"п_4"}
replace_type = {'Из них горизонтальных':'Г',
'Из них вертикальных и наклонно-направленных':'ННС',
'Из разведочного бурения':"Р"}
df = df[dict_columns.keys()].rename(columns = dict_columns)
df['итого добыча'] = pd.to_numeric(df['итого добыча'], errors='coerce')
df = df.dropna(subset=['итого добыча','объект']).reset_index(drop=True)
df['дата ввода факт'] = pd.to_datetime(df['дата ввода факт'], dayfirst=True)
df['дата ввода план'] = pd.to_datetime(df['дата ввода план'], dayfirst=True)
df['ТПП'] = df['ТПП'].replace(dict_replace_tpp)
df['тип'] = df['тип'].map(replace_type)
df['тип'] = df['тип'].mask(df['объект'].str.contains("СМД|смд"), 'СМД')
df = df.sort_values(by=['ТПП','месторождение','дата ввода факт'], ascending=False).reset_index(drop=True)
df['дата ввода план'] = pd.to_datetime(df['дата ввода план'].dt.date)
df['дата ввода факт'] = pd.to_datetime(df['дата ввода факт'].dt.date)
df = df[df['ТПП'] != "п_3"].reset_index(drop=True)К этому:
df = pd.read_csv('./materials/Обводненность ЛБ.csv')
(df
.query(...)
.pipe(lambda _df:_df ...)
.assign(**{'дата отбора':...})
...
.pipe(lambda _df:_df ...)
)Такая запись поможет существенно увеличить читабельность кода.
Три основных инструмента: pipe, assign и query.
Метод pipe:
pandas.DataFrame.pipe(func, *args, **kwargs)Метод pipe в pandas - это инструмент связывания воедино несколько функций с помощью одного вызова. Что позволяет выполнять несколько последовательных операций с одним и тем же фреймом без необходимости сохранять промежуточные результаты в отдельных переменных. Метод pipe особенно полезен при работе с большими наборами данных и сложными операциями, такими как преобразование, агрегирование данных и позволяет сделать все за один шаг.
Код для использования метода pipe относительно прост. Все, что нужно сделать, это передать функцию методу pipe(). Функции будут выполняться по порядку, и выходные данные каждой последующей функции будут входными данными следующей функции.
Как только метод pipe() завершит выполнение, результатом будет вывод последней функции в списке.
Рассмотрим простой пример того, как можно использовать метод pipe:
>>> d = {'col1': [1,2],'col2': [3,4]}
>>> df = pd.DataFrame(data=d)
>>> df
col1 col2
0 1 3
1 2 4
>>> df.pipe(lambda _df:_df + 1).pipe(lambda _df:_df + 1)
col1 col2
0 3 5
1 4 6▍Использование lambda дает серьезное преимущество, так как мы получаем текущий фрейм данных.
Вместо того чтобы писать несколько строк кода для выполнения нескольких операций, одни и те же операции могут быть выполнены в одной строке. Кроме того, поскольку метод pipe() возвращает фрейм, что поможет создавать сложные конвейеры функций, связывая их вместе.
Метод assign:
pandas.DataFrame.assign(**kwargs)Метод assign в pandas используется для назначения новых столбцов фрейму данных. Этот метод позволяет вам создавать новые столбцы или присваивать новые значения существующим столбцам для каждой строки фрейма. С помощью assign можно включать вычисления, константы и даже другие фреймы в качестве источника значений в новых столбцах.
Примеры:
>>> d = {'col1': [1,2],'col2': [3,4]}
>>> df = pd.DataFrame(data = d)
>>> df
col1 col2
0 1 3
1 2 4
>>> df.assign(col3 = lambda _df:_df['col2']+1)
col1 col2 col3
0 1 3 4
1 2 4 5
# можно передовать и просто значение
>>> df.assign(col3 = 'pandas')
col1 col2 col3
0 1 3 pandas
1 2 4 pandas
# или с помощью словаря, если в названии колонки есть пробелы
>>> df.assign(**{"col 3":lambda _df:'pandas'})
col1 col2 col 3
0 1 3 pandas
1 2 4 pandasКак можно заметить, метод assign+lambda обеспечивает большую гибкость, когда дело доходит до добавления новых столбцов и данных во фрейм.
Метод query:
pandas.DataFrame.query(expr, *, inplace=False, **kwargs)Метод query в pandas позволяет извлекать определенные строки из фрейма на основе определенных условий. Метод принимает строку, содержащую допустимое выражение, которое может ссылаться на столбцы внутри фрейма. Это обеспечивает интуитивно понятный способ выбора и фильтрации строк из фрейма данных на основе определенных критериев. По сути, это создание сложных запросов для выбора конкретных данных.
>>> d = {'col1': [1,2,3,4,5,6],
'col2': [7,8,9,10,11,12],
'col3': ['a','b','a','b','a','g'] }
>>> df = pd.DataFrame(data = d)
>>> df
col1 col2 col3
0 1 7 a
1 2 8 b
2 3 9 a
3 4 10 b
4 5 11 a
5 6 12 g
# простое выражение с больше/меньше
>>> df.query('col1 < 5')
col1 col2 col3
0 1 7 a
1 2 8 b
2 3 9 a
3 4 10 b
# выражение с использованием методов pandas к столбцу
>>> df.query("col3.isin(['a'])")
col1 col2 col3
0 1 7 a
2 3 9 a
4 5 11 a
# можно с помощью @ обращаться к переменным
>>> filter_b = 'b'
>>> df.query("col3.isin([@filter_b])")
col1 col2 col3
1 2 8 b
3 4 10 bДопускается использование логических операторов, такие как "&", "|" и "~", для создания более специфичных фильтров. Кроме того, метод можно использовать для сравнения числовых значений между различными записями, операций со строками, логическими операциями и т.д. Что делает его особенно полезным, так как это возможность легко комбинировать несколько условий вместе.
Разбор на примере. Считаем нефть на предприятиях.
▍Так как все уже посчитали выживших на Титанике, лепестки Ириса, классифицировали пингвинов Палмера, то будем использовать реальные данные - найдем топ пять месторождений по добыче нефти на четырех производственных предприятиях.
Использовать будем реальную отчетную табличку с планами нефтяного общества на 2023, только немного зашифрованную:

Наша задача будет состоять в том, чтобы выделить топ пять месторождений с максимальной добычей нефти (оставшиеся определим как "остальные") и построить график среднесуточной добычи (по месяцам) по каждому предприятию использую цепочку вызовов:

Необходимые библиотеки:
import pandas as pd # version 1.5.3
import plotly.express as px # version 5.13.0Читаем наш excel файл и сразу смотрим на него:
df = pd.concat(pd.read_excel('./materials/oil_prod.xlsx',
sheet_name=None,
header=None), ignore_index=True)
df.head(10)Для того, чтобы не использовать "\" для переноса и перейти к chaining мы должны обернуть df в скобки:
# слеш используется для переноса, чтобы избавится от него, нужно df обернуть в скобки
df \
.loc[:,:](df.loc[:,:]
)
# или как кому нравится
(
df.loc[:,:]
)оставим только нужные нам столбцы (выведем их в отдельную переменную словаря) избавившись от кварталов и не заполненного факта, начнем создавать нашу цепочку методов:
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
)Далее нам нужно соотнести добычу нефти по предприятиям, месторождениям, объектам.
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# выделяем предприятия из колонки показатель
# с помощью _df['показатель'].str.contains('ТПП|СП')
# возвращаем True если строка содержит ТПП или СП
# df['показатель'].where вытаскиваем название предприятия
# и fillna заполняет название вниз вниз
.assign(предприятие=lambda _df: (_df['показатель']
.where(_df['показатель'].str.contains('ТПП|СП')
.fillna(False)).fillna(method='pad')))
.set_index('предприятие')
.reset_index()
)чтобы исключить повторение кода (нам еще нужно вытащить месторождения и объекты) создадим функцию и вызовем ее с помощью метода pipe:
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
)все прошло как и ожидали - получили три новых колонки с предприятиями, месторождениями и объектами:
оставляем только месторождения, удаляем колонку объекты и фильтруем показатель по добыче нефти:
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
indicator_filter = ['добыча нефти за период']
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
# блок с применением метода query
.query("объект.fillna('-').str.contains('месторождение')")
.query('показатель.isin(@indicator_filter)')
.drop(columns = ['объект','показатель'])
)▍В новых версиях была расширена функциональность и теперь можно вызывать методы pd.Series из query. Не уверен как давно это было введено.
Превратим форму таблицы в длинную (long) и удалим слово месторождение из одноименной колонки. Через функцию _group_top_n_fields выделим топ пять месторождений, оставив себе пространство для маневра (вдруг потом захотим посмотреть не пять месторождений, а десять):
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
indicator_filter = ['добыча нефти за период']
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
def _group_top_n_fields(_df, n=5):
_df_top_n = _df.groupby(['предприятие', 'месторождение'],
as_index=False)['добыча нефти, тыс. тонн'].sum()
_df_top_n = (_df_top_n
.groupby(['предприятие'],
as_index=True, group_keys=False)
.apply(lambda df_:df_.nlargest(n=n,columns = ['добыча нефти, тыс. тонн'])))
_df = (_df
.assign(месторождение=lambda df_:df_['месторождение'].where(df_['месторождение'].isin(_df_top_n['месторождение']))
.fillna('остальные')))
return _df.groupby(['предприятие',"месторождение","месяц"], as_index=False).sum()
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
# блок с применением метода query
.query("объект.fillna('-').str.contains('месторождение')")
.query('показатель.isin(@indicator_filter)')
.drop(columns = ['объект','показатель'])
# сворачивание формы таблицы в длинную и выделяем топ 5 месторождений
.pipe(lambda _df: pd.melt(frame=_df,
id_vars=['предприятие','месторождение'],
var_name='месяц',
value_name="добыча нефти, тыс. тонн"))
.assign(месторождение=lambda _df:_df['месторождение'].replace(' месторождение', "", regex=True))
.pipe(_group_top_n_fields, n=5)
)Теперь давайте изменим столбец месяц так, чтобы его можно было сортировать от января до декабря, для этого используя функцию pd.date_range и свойство категориального типа в Pandas ordered=True (т.к. кода стало много, уберем его под спойлер для удобства):
общий код
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
indicator_filter = ['добыча нефти за период']
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
def _group_top_n_fields(_df, n=5):
_df_top_n = _df.groupby(['предприятие', 'месторождение'],
as_index=False)['добыча нефти, тыс. тонн'].sum()
_df_top_n = (_df_top_n
.groupby(['предприятие'],
as_index=True, group_keys=False)
.apply(lambda df_:df_.nlargest(n=n,columns = ['добыча нефти, тыс. тонн'])))
_df = (_df
.assign(месторождение=lambda df_:df_['месторождение'].where(df_['месторождение'].isin(_df_top_n['месторождение']))
.fillna('остальные')))
return _df.groupby(['предприятие',"месторождение","месяц"], as_index=False).sum()
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
# блок с применением метода query
.query("объект.fillna('-').str.contains('месторождение')")
.query('показатель.isin(@indicator_filter)')
.drop(columns = ['объект','показатель'])
# сворачивание формы таблицы в длинную и выделяем топ 5 месторож.
.pipe(lambda _df: pd.melt(frame=_df,
id_vars=['предприятие','месторождение'],
var_name='месяц',
value_name="добыча нефти, тыс. тонн"))
.assign(месторождение=lambda _df:_df['месторождение'].replace(' месторождение', "", regex=True))
.pipe(_group_top_n_fields, n=5)
# создаем категориальный столбец с возможностью сортировки от января до декабря
.assign(месяц=lambda _df: pd.Categorical(values=_df['месяц'].str.lower(),
categories=pd.date_range(start='01.01.2023',
end='12.01.2023',
freq='MS').month_name(locale='Ru').str.lower(),
ordered=True))
.sort_values(['предприятие','месторождение','месяц'])
.reset_index(drop=True)
)
Чтобы нивелировать кол-во дней в месяце (январь - 31, февраль - 28, апрель - 30), найдем среднесуточную добычу нефти (добычу нефти разделим на кол-во дней в месяце). Кол-во дней добавим через pd.Series.map({}) и чтобы не усложнять код, вынесем на словарь в отдельную переменную:
map_days_in_month = {i.month_name(locale='Ru').lower():i.daysinmonth
for i in pd.date_range(start='01.01.2023',
end='12.01.2023',freq='MS')}
>>> {'январь': 31,
'февраль': 28,
'март': 31,
'апрель': 30,
'май': 31,
'июнь': 30,
'июль': 31,
'август': 31,
'сентябрь': 30,
'октябрь': 31,
'ноябрь': 30,
'декабрь': 31}▍Интересно, что в pandas уже заложены имена месяцев на русском языке и просто добавив в month_name(locale='Ru') можно их оттуда забрать.
Все вместе:
общий код
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
map_days_in_month = {i.month_name(locale='Ru').lower():i.daysinmonth for i in pd.date_range(start='01.01.2023',
end='12.01.2023',freq='MS')}
indicator_filter = ['добыча нефти за период']
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
def _group_top_n_fields(_df, n=5):
_df_top_n = _df.groupby(['предприятие', 'месторождение'],
as_index=False)['добыча нефти, тыс. тонн'].sum()
_df_top_n = (_df_top_n
.groupby(['предприятие'],
as_index=True, group_keys=False)
.apply(lambda df_:df_.nlargest(n=n,columns = ['добыча нефти, тыс. тонн'])))
_df = (_df
.assign(месторождение=lambda df_:df_['месторождение'].where(df_['месторождение'].isin(_df_top_n['месторождение']))
.fillna('остальные')))
return _df.groupby(['предприятие',"месторождение","месяц"], as_index=False).sum()
(
df
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
# блок с применением метода query
.query("объект.fillna('-').str.contains('месторождение')")
.query('показатель.isin(@indicator_filter)')
.drop(columns = ['объект','показатель'])
# сворачивание формы таблицы в длинную и выделяем топ 5 месторож.
.pipe(lambda _df: pd.melt(frame=_df,
id_vars=['предприятие','месторождение'],
var_name='месяц',
value_name="добыча нефти, тыс. тонн"))
.assign(месторождение=lambda _df:_df['месторождение'].replace(' месторождение', "", regex=True))
.pipe(_group_top_n_fields, n=5)
# создаем категориальный столбец с возможностью сортировки от января до декабря
.assign(месяц=lambda _df: pd.Categorical(values=_df['месяц'].str.lower(),
categories=pd.date_range(start='01.01.2023',
end='12.01.2023',
freq='MS').month_name(locale='Ru').str.lower(),
ordered=True))
.sort_values(['предприятие','месторождение','месяц'])
.reset_index(drop=True)
# добавляем столбцы `кол-во дней в месяце` и `добыча нефти тыс.тонн/сут`
.assign(**{'кол-во дней в месяце':lambda _df:_df['месяц'].map(map_days_in_month)})
.assign(**{"добыча нефти тыс.тонн/сут":lambda _df:(_df['добыча нефти, тыс. тонн']/_df['кол-во дней в месяце']).round(1)})
)Все, наша табличка готова! Теперь, можно все действия определить или в функцию или в отдельный класс, кто как любит.
общий код с определением функции
def processing_oil_table(path):
df_ = pd.concat(pd.read_excel(path,
sheet_name=None,
header=None), ignore_index=True)
columns_rename = {1:"показатель",5:'январь',7:'февраль',9:'март',
13:"апрель",15:"май",17:"июнь",21:"июль",
23:"август",25:"сентябрь",29:"октябрь",
31:"ноябрь",33:"декабрь"}
map_days_in_month = {i.month_name(locale='Ru').lower():i.daysinmonth for i in pd.date_range(start='01.01.2023',
end='12.01.2023',freq='MS')}
indicator_filter = ['добыча нефти за период']
def _pipe_column_filter(_df, column_name, text_filter='ТПП|СП'):
_df = _df.assign(**{column_name:(_df['показатель']
.where(_df['показатель'].str.contains(text_filter)
.fillna(False))
.fillna(method='pad'))})
_df = _df.set_index(column_name).reset_index()
return _df
def _group_top_n_fields(_df, n=5):
_df_top_n = _df.groupby(['предприятие', 'месторождение'],
as_index=False)['добыча нефти, тыс. тонн'].sum()
_df_top_n = (_df_top_n
.groupby(['предприятие'],
as_index=True, group_keys=False)
.apply(lambda df_:df_.nlargest(n=n,columns = ['добыча нефти, тыс. тонн'])))
_df = (_df
.assign(месторождение=lambda df_:df_['месторождение'].where(df_['месторождение'].isin(_df_top_n['месторождение']))
.fillna('остальные')))
return _df.groupby(['предприятие',"месторождение","месяц"], as_index=False).sum()
return (df_
.loc[:,columns_rename.keys()]
.rename(columns=columns_rename)
# блок с применением метода pipe
.pipe(_pipe_column_filter, column_name="объект", text_filter='ТПП|СП|месторождение|[Оо]бъект')
.pipe(_pipe_column_filter, column_name="месторождение", text_filter='ТПП|СП|месторождение')
.pipe(_pipe_column_filter, column_name="предприятие", text_filter='ТПП|СП')
# блок с применением метода query
.query("объект.fillna('-').str.contains('месторождение')")
.query('показатель.isin(@indicator_filter)')
.drop(columns = ['объект','показатель'])
# сворачивание формы таблицы в длинную и выделяем топ 5 месторож.
.pipe(lambda _df: pd.melt(frame=_df,
id_vars=['предприятие','месторождение'],
var_name='месяц',
value_name="добыча нефти, тыс. тонн"))
.assign(месторождение=lambda _df:_df['месторождение'].replace(' месторождение', "", regex=True))
.pipe(_group_top_n_fields, n=5)
# создаем категориальный столбец с возможностью сортировки от января до декабря
.assign(месяц=lambda _df: pd.Categorical(values=_df['месяц'].str.lower(),
categories=pd.date_range(start='01.01.2023',
end='12.01.2023',
freq='MS').month_name(locale='Ru').str.lower(),
ordered=True))
.sort_values(['предприятие','месторождение','месяц'])
.reset_index(drop=True)
# добавляем столбцы `кол-во дней в месяце` и `добыча нефти тыс.тонн/сут`
.assign(**{'кол-во дней в месяце':lambda _df:_df['месяц'].map(map_days_in_month)})
.assign(**{"добыча нефти тыс.тонн/сут":lambda _df:(_df['добыча нефти, тыс. тонн']/_df['кол-во дней в месяце']).round(1)})
)
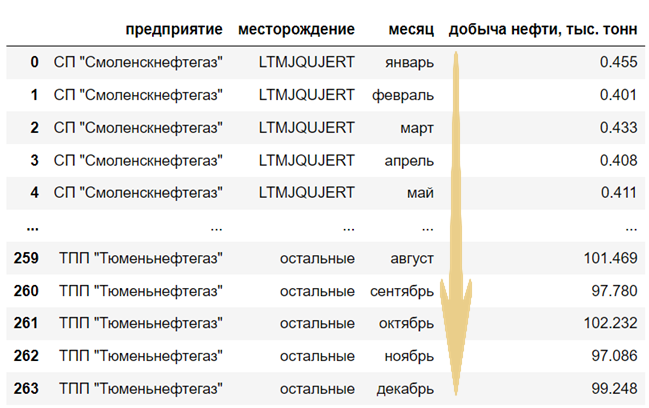
>>> processing_oil_table(path='./materials/oil_prod.xlsx')
предприятие месторождение месяц добыча нефти, тыс. тонн \
0 СП "Смоленскнефтегаз" LTMJQUJERT январь 0.455
1 СП "Смоленскнефтегаз" LTMJQUJERT февраль 0.401
2 СП "Смоленскнефтегаз" LTMJQUJERT март 0.433
3 СП "Смоленскнефтегаз" LTMJQUJERT апрель 0.408
4 СП "Смоленскнефтегаз" LTMJQUJERT май 0.411
кол-во дней в месяце добыча нефти тыс.тонн/сут
0 31 0.0
1 28 0.0
2 31 0.0
3 30 0.0
4 31 0.0 Рисуем графики.
Для месторождений будем использовать Area plot(или диаграмма с областями), комбинировать вместе будем через функцию pipe, все также придерживаясь method chaining:
df_oil = processing_oil_table(path='./materials/oil_prod.xlsx')
(
df_oil
.pipe(lambda _df:px.area(_df, x="месяц",
y="добыча нефти тыс.тонн/сут",
color="месторождение",
facet_col="предприятие",
facet_col_wrap=2,
facet_col_spacing=0.05))
)
Первая часть нашей задачи выполнена. Теперь добавим суммарную добычу по каждому предприятию(сделаем это необязательным показателем) и уберем "предприятие=" из названий графиков. Можно это все провернуть с помощью lambda, но я выделю для этого отдельную функцию, чтобы не усложнять чтение кода в будущем:
def _plot_area(_df, add_sum_venture=False, path_save=None):
# переменные для построения графиков
x_month = "месяц"
y_oil_prod = "добыча нефти тыс.тонн/сут"
facet_col = "предприятие"
facet_col_wrap = 2
color = "месторождение"
# график по месторождениям
fig = px.area(_df,
x=x_month,
y=y_oil_prod,
color=color,
facet_col_wrap=facet_col_wrap,
facet_col=facet_col,
facet_col_spacing=0.05)
# суммарный график по предприятиям
if add_sum_venture:
fig.add_traces(px.line(_df.groupby([facet_col, x_month],as_index=False).sum(numeric_only=True).round(2),
x=x_month,
y=y_oil_prod,
facet_col=facet_col,
facet_col_wrap=2,
text=y_oil_prod).data)
(fig
.update_traces(textposition='top center')
.update_yaxes(range = [0,6]))
# удаляем "предприятие="
fig.for_each_annotation(lambda a: a.update(text=a.text.split("=")[-1]))
# сохраняем график, если включен показатель
if path_save:
fig.write_image(file=path_save,width=1_000,height=650)
return fig
(
df_oil
.pipe(_plot_area, add_sum_venture=True)
)Все готово:

Дальше можно еще шаманить, перекрасить, добавлять комментарии и т.д. и т.п.
Спасибо всем кто дочитал до конца. Выше показано как можно взять "традиционный код" и реорганизовать его при помощи chaining и функций. Может кто использует этот метод? Или есть еще какие инсайды?
Комментарии (12)

dyadyaSerezha
00.00.0000 00:00+1Упрощает отладку? Скорее наоборот. Я не могу поставить промежуточные print, чтобы посмотреть на данные, могу только увидеть конечный фрейм. И кто его знает, что где пошло не так в этой цепочке.
считается, что цепочка методов более эффективна, чем отдельные шаги, поскольку операции могут выполняться последовательно без создания промежуточных фреймов, которые увеличивают использование памяти pandas.
Кем считается? Фреймов будет создано ровно столько же, сколько и при одиночных операциях - это определяется самими функциями, в не способом их вызова.

lozy_rc Автор
00.00.0000 00:00+2Я не могу поставить промежуточные print
Сэр вы все можете, но зачем?!:
from IPython.display import display d = {'col1': [1,2,3,4,5,6],'col2': [7,8,9,10,11,12],'col3': ['a','b','a','b','a','g'] } df = pd.DataFrame(data = d) ( df .pipe(lambda _df:print(_df) or _df) .assign(col_4=lambda _df:_df['col2']) # ну или display например .pipe(lambda _df:display(_df) or _df) .assign(col_5=lambda _df:_df['col_4']*5) )Использование or _df в lambda позволяет пробросить фрейм дальше и продолжить цепочку!
Кем считается?
mr. Marc Garcia основная команда pandas https://www.youtube.com/watch?v=hK6o_TDXXN8, 6:52 цитата "Я думаю так должны выглядеть панды в будущем".

Ananiev_Genrih
00.00.0000 00:00надеюсь панда умрёт от старости в скором будущем освободив поляну для polars/arrow/DuckDB
lozy_rc Автор
00.00.0000 00:00Пандас вечен! Как и ексель) Реально, это уже стандарт, стандарт просто так уже не умрет. Скорее остальные команды будут копировать API пандас, и выделять это как преимущество. Например так уже поступает modine.
Ananiev_Genrih
00.00.0000 00:00+1Реально, это уже стандарт, стандарт просто так уже не умрет.
Если что, статья от Веса Маккини, создателя пандас
Apache Arrow and the "10 Things I Hate About pandas"
а здесь можно полюбоваться на горячо_любимый_пандас в бенчмарках от h2o
dyadyaSerezha
00.00.0000 00:00Ну хорошо, хоть про количество промежуточных фреймов не спорите ????
lozy_rc Автор
00.00.0000 00:00Хаха), вот тут например утверждается, что обычное сложение:
df['D'] = df['A'] + df['B'] df['E'] = df['A'] * df['C']Из-за внутренней работы pandas это приведет к копированию всего фрейма данных в новое место в памяти (для подробного объяснения ознакомьтесь выступлением Марка Гарсии, члена основной команды pandas), тогда как упаковка его в один .assign() помогает достичь этого в один шаг. Это имеет большое значение для больших наборов данных и нескольких новых столбцов.
dyadyaSerezha
00.00.0000 00:00Ха, ну во-первых, создание новой колонки ведет к копированию фрейма, это понятно. И так же понятно, что один вызов assign создает сразу обе колонки и экономит одно копирование фрейма. Но где же в assign() call chaining? А нету его. В-)

economist75
00.00.0000 00:00+3Статья понравилась, но кода местами чуть многовато. Цепные вызовы можно дергать без скобок и pipe, просто через точку: df.loc[...].query(...).assign(...) или ...eval(...) позволяют в одну строку, "налету", вычислить новый столбец и добавить его справа в df.
Но pipe и скобки из статьи позволяют в Jupyter/Lab/IDE нажатием на Ctrl+/ выборочно "комментировать" строки из "цепи", что удобно при отладке или аналитических итерациях (а весь анализ всегда и у всех именно такой, мелкими шажками, иногда откровенно тупыми). Хорошо что в Pandas можно комбинировать "длинный" и "широкий" код не под PEP8, а под собственные итерации, которые у каждого аналитика и на каждых новых данных - свои.
Кроме того, цепные методы проще в наборе. "Дописать" легче чем "обернуть" или залямбдить, сравните:
df.цена # даст столбец цен вида 12345.678901
df.цена.коп() # даст столбец цен вида 12345.68Чтобы это сработало, нужно заранее объявить новый метод Series:
коп = lambda n: round(n, 2)
pd.Series.коп = копЛюбые другие способы округления (df.цена.round(2) итд) - будут более многословны в наборе и потребуют переключения языка ввода. Таблицы с русскими колонками понятны всем, "русские методы" легко запоминаются аналитиками, визуально custom-методы df/Series отличимы от сотен встроенных и работают в Python/Pandas безупречно. Для порядка можно в UDF-лямбду добавить Docstrings:
коп.doc = 'Округляет в копейки. Можно df.коп(), df.col.коп(), df.apply(коп), df.col.apply(коп)'
cartonworld
Это неверное утверждение: операции выполняются последовательно. Ни время, ни энергия не экономятся. Цепочка методов экономит время программиста, упрощая чтение кода.
Запись методов в одну строчку в таких цепочках (как в вашем первом примере с котом, и далее несколько раз в тексте) усложняет отладку.
Можете пример привести?
lozy_rc Автор
Не ну моё же время и энергия экономится, чем не экономия)
По поводу второго, были случаи, что у меня система крашилась на фреймах больше 300кк строчек, но в связке при перехвате на переменную + with multiprocessing.Pool() as pool позволяло обойти ограничения. Возможно связано с внутренним устройством самих панд. Если не найду примеры, то подправлю текст. Но это будет еще один плюс в использование этого метода)